안녕하세요 ! 여섯번째 X-review로 VoteNet에 이어 ImVoteNet을 읽어보았습니다. VoteNet의 구조를 기반으로 하는 논문이라 관련 내용은 지난주에 제가 작성한 리뷰를 참고해주시면 감사하겠습니다. 그럼 리뷰 시작하겠습니다.

1. Introduction
당시 VoteNet이나 VoxelNet과 같은 3D object detection 방법론의 경우 3D point cloud만을 input으로 사용하여 SOTA를 달성했었습니다. 그 중에 VoteNet은 이전의 RGB-D를 모두 활용한 방법론에 비해 월등한 성능을 보였었죠. 이러한 상황에서 저자들은 의문점 한 가지를 제시합니다. “정말 point cloud만을 3D detection에 사용하는 것이 충분할까?” 결과적으로 저자들이 본 논문을 통해 내놓은 대답은 “RGB image는 3D Object Detection에 사용할 가치를 가지고 있다” 입니다. RGB image에서는 point cloud에서 얻을 수 없는 object의 풍부한 texture와 high resolution image로 이루어져 있죠. 심지어 depth sensor에서 반사되어 보이지 않는 일명 “blind region”에 대한 부분까지 RGB image는 포함하고 있습니다. 저자의 주장은 결국 RGB image는 object의 depth 정보를 측정할 수 없다는 한계가 존재하기에 단독으로 3D Object Detection에 사용하지 못하는 것 뿐이니 point cloud와 함께 사용하면 RGB image를 사용하지 않을 이유가 없다는 것 입니다. 그러나 가장 중요한, 어떻게 효과적으로 2D image를 3D detection에 사용할 것인지는 여전히 challenge한 문제로 남아있다고 합니다. 사실 가장 나이브한 방식으로는 point cloud를 2D image로 projection해서 매칭되는 raw한 rgb pixel 값을 그대로 사용하면 됩니다만 이 방법은 point cloud가 sparse하기 때문에 point가 존재하는 부분을 제외한 rgb image의 픽셀 정보를 전혀 사용할 수 없습니다. 그래서 조금 더 나아가 2D Detector을 사용하여 frustum 형태에서 초기 proposal을 진행하는 방법론들이 존재하는데, 이는 초기 검출에 3D point cloud를 사용하지 않아 2D image에서 object를 검출하지 못하면 point cloud에서는 detection할 기회조차 생기지 않아 2D detector에 너무 많은 의존을 하게 된다는 단점이 있습니다. 그래서 3D에 좀 더 초점을 맞춘 방법론들은 2D image를 localization에 직접적으로 사용하지 않고 2D convolution에서 중간 feature map을 3D point로 연결하여 더 풍부한 3D feature을 생성하여 detection에 도움을 주는 용도로 사용하고 있습니다.
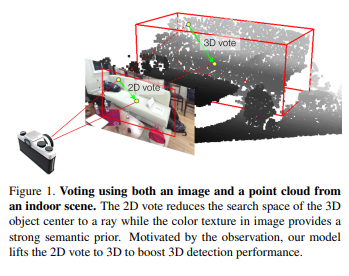
본 논문에서는 위에 언급한 RGB를 사용하는 방식들의 단점을 최대한 보완한하고자 VoteNet을 기반으로 2D와 3D에서 voting 기법을 사용하는 3D Object Detection task를 수행하는 ImVoteNet을 제안하며, Figure1이 본 논문의 가장 큰 Motivation이라고 합니다. 아래에서 더 자세하게 설명하겠지만, 간략하게 이야기해보자면 2D detector에서 bounding box를 만들면 이미지 차원에서 2D voting을 하고 2D vote point를 3D로 전달하기 위해서 카메라 내부 파라미터와 3차원 좌표를 이용하여 transformation을 거쳐 pseudo 3D vote point을 만들게 됩니다. 2D vote point와 함께 pixel마다의 semantic, texture cues를 전달하게 됩니다. 이러한 정보들은 seed point로 전달된 후 VoteNet pipeline을 따르게 되며 seed point는 object에 대한 더 많은 feature을 가지고 point cloud만으로는 구별하기 어려웠던 유사한 object까지 구분할 수 있게 됩니다. 또한 ImVoteNet은 두 모달리티의 feature을 모두 사용하기 때문에 모달리티 간의 balance를 맞추기 위해서 multi-towered network을 추가적으로 제안하고 있습니다. 해당 방법론으로 SUN RGB-D Dataset으로 실험한 결과 기존 point cloud만을 사용하던 VoteNet 대비 SOTA를 달성하면서 2D feature을 사용해야하는 타당성을 입증하였다고 합니다. 즉 본 논문의 main contribution을 정리하면 다음과 같습니다.
- point cloud 기반 3D detection pipeline과 2D detection 정보를 합친 새로운 방식을 제안
- SUN RGB-D Dataset에서 SOTA 달성
- 제안하는 구조에 대한 정량적/정성적 분석
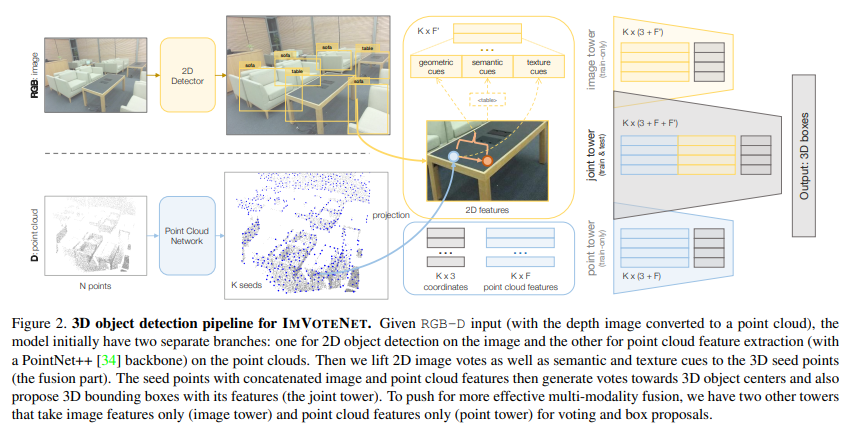
2. ImVoteNet Architecture
2.1. Image Votes from 2D Detection
backbone을 거친 seed point에서 구한 vote point만을 사용하던 VoteNet과 다르게 ImVoteNet에서는 2D detector을 거친 box로부터 image vote까지 생성합니다. image vote라는 것은 단순히 box 내 image pixel과 box의 중심을 연결한 vector라고 생각해주시면 됩니다. 여기서 2D Detector는 RGB-D dataset에서 color channel로 사전학습된 Faster-RCNN을 사용하며, 그에 대한 output은 M개의 2D bounding box와 각 박스의 class가 되겠죠. image vote를 위해서 박스 내 모든 image pixel에 대한 voting을 하게 되는데 한 픽셀이 여러 bounding box에 겹칠수도 있고, 어떤 bounding box에도 포함되지 않을 수 있습니다. 전자의 경우, 여러번 voting을 해주면 되고 후자의 경우에는 zero padding을 시킵니다. Image vote는 크게 geometric cues, semantic cues, texture cues 3가지로 agment 되기에 이제부터 3가지를 차례대로 알아보도록 하겠습니다.
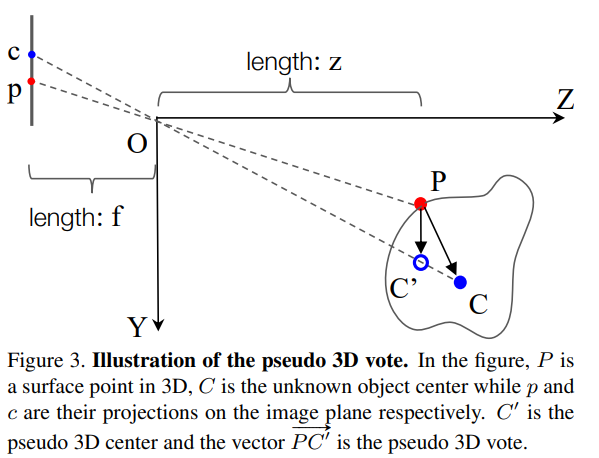
Geometric cues: lifting images votes to 3D
image vote는 3D object proposal 위한 geometric 정보를 제공해줄 수 있는데, camera intrinsic parameter가 주어지면 Fig1처럼 2D Object center – 3D Object center – camera optical center를 일직선에 위치하도록 ray를 만들게 됩니다. 이 정보가 backbone을 거친 seed point에 추가되면 원래 3D 공간에서 찾아야 했던 center 정보를 1D의 ray로 범위를 좁혀 찾을 수 있게 됩니다.
이제 Fig3을 보면서 어떻게 1D에서 center을 찾을 수 있는 것인지 알아보도록 하겠습니다. Fig3에서 왼쪽이 image plane의 2D bounding box이고 오른쪽이 3차원 공간의 3D Object로 C는 3D Object의 center point, P는 object 표면 위의 점 입니다. image plane 위의 c, p는 각 P와 C가 projection된 점들로 Figure1와 같은 형태를 이루게 됩니다. 여기서 image vote를 알고 있으면 3차원 공간에 존재할 center point C’를 1차원 ray OC 위에서 찾을 수 있습니다. 그렇다면 3D seed point에 추가해줄 ray 정보는 어떻게 구할 수 있을까요?
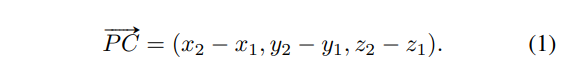
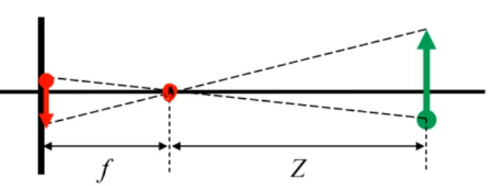
pinhole camera의 3D-2D transformation을 생각해보며 P를 카메라 좌표계 P = (x_1, y_1, z_1), p와 c를 이미지 좌표계로 p = (u_1, v_1), c = (u_2, v_2)로 정의해보겠습니다. 찾고자 하는 것이 GT object center C = (x_2, y_2, z_2)와 가까워지는 vote point C’를 찾는 것으로 실제 seed point P와 C의 차이는 식(1)과 같습니다.
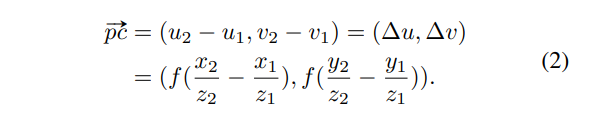
이미지 차원에서 중심 c와 pixel p와의 거리를 구하면 (u_2 - u_1, v_2 - v_1)이고 이를 위에서 pinhole camera로 가정하고 카메라의 내부 파라미터를 이용한다고 언급하였듯이, focal length f를 가진 pinhole camera라고 가정하였기 때문에 위의 삼각비를 표현한 그림을 토대로 생각을 해보면 식(2)같이 정의할 수 있음을 알 수 있습니다. 여기서 새로운 가정을 하나 더 추가할텐데요, 물체의 표면 위에 존재하는 포인트인 P의 depth와 center point C의 depth가 비슷하다고 가정하는 것 인데 이는 카메라와 물체가 너무 가까이 있는 경우가 아닐 때 합리적인 가정이라고 합니다.
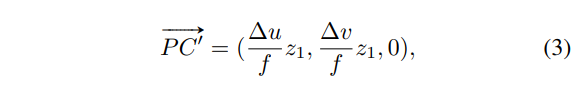
그러면 또 다시 계산을 해보면 식(3)과 같이 3차원에서 vote point C’를 구할 수 있게 됩니다. C’는 OC위에 존재하며 seed point에 대한 vote point로 pseudo 3D vote로 정의합니다. z 좌표가 0이 되는 것은 표면 위의 point P와 center의 depth를 같다고 설정했기 때문에 둘 사이의 좌표 차이가 나지 않아 0이 됩니다. 다만 이렇게 depth를 같다고 approximation 한다면 잘못된 C’를 vote 할 가능성도 존재하기에 발생할 에러에 대비하여 본 논문에서 이를 ray에 방향을 부여해주었습니다.
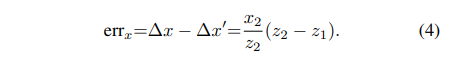
식(4)는 x 방향에 대한 error 식으로 y 방향에 대해서도 동일하게 구할 수 있습니다. 만약 이렇게 OC에 (x_2/z_2, y_2/z_2)라는 방향 정보를 준다면 실제 GT center의 depth z_2와 pseudo vote point C’의 depth z_1 차이를 구하기 위해서 추가적인 정보가 필요할 것 입니다.
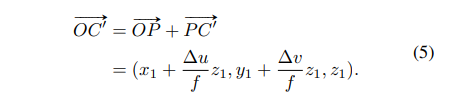
그러나 실제 3차원에서 object center인 C를 알 수 없기 때문에 식(5)처럼 OC를 대신해서 OC와 같은 방향인 OC’의 방향을 사용하게 되죠.
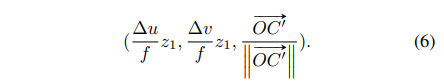
따라서 식 (3)에서 z 좌표를 OC’에 대해 normalize한 좌표를 할당해주면 식(6)이 최종적으로 seed point P로 전달될 image의 geometric feature라고 정의할 수 있습니다.
Semantic cues
geometric feature는 공간적인 좌표를 제공해주긴 하지만 bound box 내의 존재하는 것이 무엇인지 RGB 이미지로부터 얻을 수 있는 semantic한 정보를 얻었다고는 할 수 없습니다. 가령 테이블과 책상이나 nightstand와 서랍 같은 경우에는 point cloud만으로는 구별하기 어려운 물체들로 이러한 object들을 구별해줄 수 있는 semantic 정보를 rgb image에서부터 얻어오고자 하는 것 입니다. 이를 위해 논문에서는 boundinb box마다 추출되는 region level의 feature을 추가적으로 제공하는데요, 모든 3D seed point를 2D box로 projection을 시켜 box에 대한 semantic 정보를 담은 벡터를 포인트로 전달하게 됩니다. geometric cues와 마찬가지로 한개의 포인트가 여러개의 2D box에 속하는 경우엔 포함된 모든 box에 대해 semantic 정보를 받도록 하고 어떤 box에도 속하지 않는다면 모든 값이 0인 feature vector을 전달합니다.
그렇다면 여기서 전달한다는 semantic 정보라는 것은 어떤 것일까요? region-level feature라고 명칭하였지만 그렇다고 해서 전달하는 feature의 수준이 2D detector의 ROI pooling으로 추출된 특징만을 뜻하지는 않습니다. 오히려 클래스에 대한 confidence score을 가진 one-hot class vector을 가지고 간단하게 semantic 정보를 제공할 수 있다고 합니다. one hot class vector을 semantic 정보로 넘겨줌으로써 만일 2D detector을 Faster-RCNN을 사용하지 않고 1-stage detector을 사용할 경우에도 ROI pooling 단계에서의 특징에 의존하지 않기 때문에 더 일반화할 수 있음으로 해당 vector을 semantic cues로 사용합니다.
Texture cues
pixel level의 2D RGB image는 point cloud의 depth 정보와 다르게 dense하고 high resolution의 정보를 제공할 수 있습니다. semantic cues를 통해 high level의 semantic 정보를 전달했지만, 저자들은 semantic만큼 low level의 풍부한 texture 또한 동일하게 제공해주어야 한다고 주장합니다. 이는 간단한 mapping을 통해 가능한데, seed point를 2D projection 했을 때 대응되는 pixel 정보를 사용하는 것 입니다. 사실 convolutional feature map을 사용해도 되지만, texture 정보로 어쩌면 굉장히 원초적으로 raw level의 RGB pixel 값을 그대로 사용하고자 하였습니다.
semantic cues와 texture cues에서 모두 특징을 경량화하여 사용하는 경향을 보였는데 그렇다면 더 많은 feature들을 RGB image에서부터 얻어오는 것이 좋지 않을까라는 의문이 생길 수도 있습니다. 그러나 저자는 최소화된 semantic, texture 정보를 받아왔음에도 우수한 성능을 보일 수 있었으며 이는 바로 다음으로 다룰 multi-tower training 방식에서 나온 것이라고 이야기합니다.
2.2. Feature Fusion and Multi-tower Training
2D image로부터 얻은 geometric cues, semantic cues, texture cues와 원래 seed point로 3D vote point를 만들고 object proposal까지 진행할 수 있습니다. 그러나 여기서 문제는 두 modality의 feature을 함께 사용하는 것이기 때문에 network를 최적화해주어야 한다는 것 입니다. multi-modal을 학습시킬 때 최적화 과정이 없다면 한 modality에 치중되거나 overfitting되어 오히려 single modality보다도 좋지 않은 결과가 생길 수도 있기 때문입니다. 그래서 ImVoteNet에서는 각 모달리티 타워마다 가중치를 부여해주는 gradient blending 방식을 사용합니다.
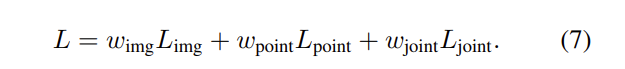
본 논문은 총 3가지의 타워를 제시하는데 Figure2에서 point tower, image tower, joint tower로 앞의 두 tower는 train에서만 사용하며 joint tower의 경우에만 inference에서까지 사용한다고 합니다. image tower의 경우 semantic cues와 texture cues, 즉 image feature만으로는 3D bounding box proposal을 수행할 수 없기 때문에 앞서 이야기한 것처럼 pseudo 3D votes를 생성할 수 있도록 seed point를 제공하게 됩니다. 결국 image tower의 input은 3D 좌표와 2D feature가 될 것이고 pseudo 3D vote point와 semantic, texture cues를 통해서 3D box proposal이 가능합니다. point tower는 3D 좌표와 3D feature가 input으로, joint tower는 모든 좌표와 feature가 모두 input으로 들어가게 됩니다. 그래서 3개의 각 tower에 가중치를 부여한 전체 Loss는 식(7)로 정의할 수 있습니다.
3. Experiments
실험은 SUN RGB-D Dataset으로 진행하였습니다.
3.1. Comparing with State-of-the-art Methods
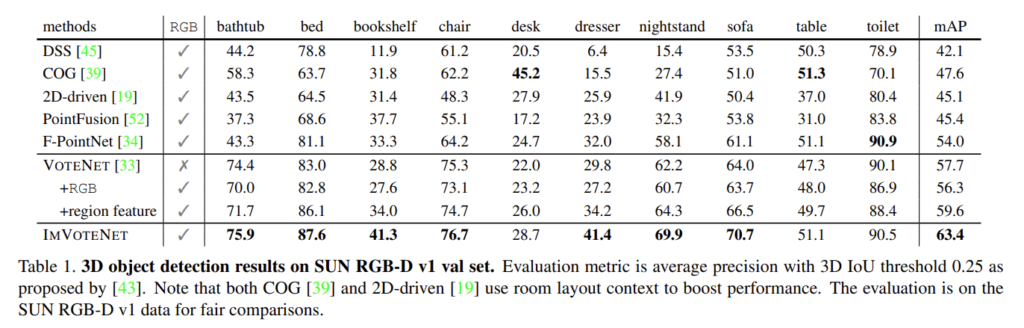
Table1은 이전의 RGB+point cloud를 사용하는 방법론들과 당시 SOTA 방법론인 VoteNet과의 비교로 진행을 하였습니다. 방법론의 우수함을 강조하기 위해서 VoteNet을 확장한 2개의 베이스라인을 더 설정하였습니다. 먼저 +RGB라고 표시되어 있는 baselien은 RGB 세 개의 픽셀 값을 3차원 벡터로 표현하여 point cloud처럼 seed point로 사용한 것이고, +region feature는 본 논문의 semantic cues처럼 region level의 one-hot class confidence feature을 seed point로 함께 사용하였습니다. 실험이면서 동시에 ablation study를 수행하는 느낌으로 진행한 것 같습니다 ..
결과적으로 기존 VoteNet, 그리고 추가한 2개의 baseline을 뛰어넘는 성능을 보이며 SOTA를 달성하였습니다. 특히 앞서 point cloud만으로 검출했을 때 구분하기 어렵다고 언급했던 dresser/nightstand에서 눈에 띄는 성능 향상이 있음을 볼 수 있습니다.
3.2. Qualitative Results and Discussion
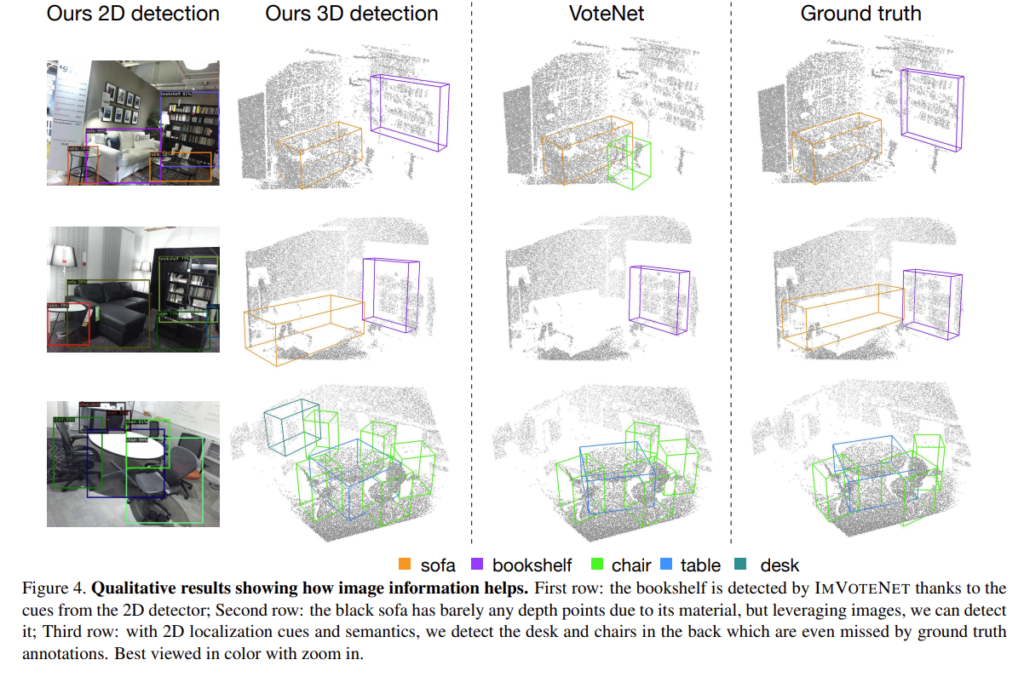
Figure4는 실험 결과를 정성적으로 보여주는 것으로 첫번째 행과 두번째 행에서 기존의 VoteNet에서는 검출하지 못하던 bookshelf나 sofa를 detection하고 VoteNet에서 FP로 검출되던 chair 또한 사라져 있는 것을 확인할 수 있습니다. 심지어 마지막 행을 보게 되면 dataset에서 GT로 설정한 object 이외에 2D image에서 검출된 나머지 chair나 desk까지 검출하면서 2D image를 사용하는 것의 효과를 강조하고 있습니다.
3.3. Analysis Experiments
해당 파트는 ablation study로 제안한 geometric, semantic, texture cues 각각이 성능에 얼마만큼의 영향을 주는지 리포팅합니다.
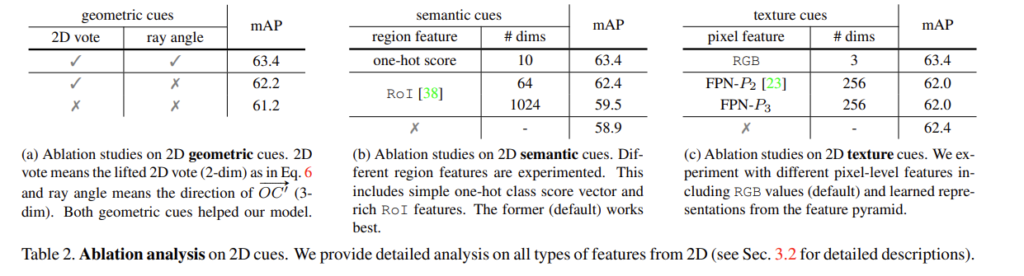
먼저 Table2.(a)를 보면 1행과 3행을 비교하였을 때 2D vote를 사용하지 않았을 경우 사용한 결과 대비 2.2%의 성능 하락을 보이고 있습니다. 앞서 이야기하였듯이 ROI pooling feature가 아닌 one-hot score을 사용하여 경량화를 시도하였고 차원을 보았을 때 ROI Pooling feature가 1024, 64차원인 것에 비해 one-hot score는 dimension이 10으로 훨씬 적은 차원이지만 mAP를 비교해보면 가장 높은 성능을 달성하며 작은 차원으로 높은 성능을 보일 수 있음을 입증하였습니다. 마지막으로 다른 pixel level의 feature와 비교했을 때 RGB row pixel 정보를 texture cues로 사용하는 것에 대한 실험 결과 입니다. 비교군으로 가져온 다른 pixel feature들은 overfitting 되어 오히려 어떤 feature도 texture cues로 사용하지 않았을 때보다 낮은 성능을 보입니다. 즉 3개의 cues는 RGB image와 point cloud를 함께 사용하는 ImVoxelNet의 성능을 향상시키는 데 기여하는 것을 확인하면서 리뷰 마치도록 하겠습니다.
좋은 리뷰 감사합니다.
우선 Figure 1에서 C가 object center라고 하는데 그럼 실제 center gt로 이해하면 되나요? 만약 그렇다면 왜 C’이라고하는 pseudo center는 왜 고려하는건가요?
그리고 loss부분에서 multi-modal을 학습시킬 때 최적화 과정이 없다면 한 modality에 치중되거나 overfitting되는 문제가 발생할 수 있어 modality tower마다 가중치를 부여하는 gradient blending 방식을 사용한다고 하셨는데 그럼 이 말이 곱해지는 가중치가 학습하는 과정에서 adaptive하게 설정된다는 건가요? 아니면 그냥 그냥 tower마다 가중치를 다르게 줬다는 걸 의미하는건가요?
감사합니다.
안녕하세요 ! 댓글 감사합니다.
우선 Figure 1.에서 C는 말씀하신 것처럼 GT 3D bounding box의 center로 이해해주시면 됩니다. vote point를 생성하는 것 자체가 surface 위의 point가 GT center와 최대한 가까워지도록 새로운 point를 만드는 것이기 때문에 2D 공간에서 중심과 픽셀 사이의 거리를 구한 2D vote 결과를 3D 에서 활용하기 위해서 ray 위의 psuedo center라는 것을 정의하게 되는 것 입니다.
두번째 질문에 대해서는 후자를 의미하는 것이 맞습니다. 제가 리뷰에 가지고 오진 않았지만 ablation study에 multi-tower에 대한 가중치를 어떻게 부여하는지에 따른 실험 결과가 있기 때문에 하이퍼파라미터로 가중치를 설정할 수 있는 것으로 보입니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
리뷰에서 semantic cues를 ROI Pooling에 제한되지 않고 one hot class vector라고 말씀해주셨는데 그렇다면 ROI Pooling feature는 아예 사용하지 않는것인가요 ?
또 Ablation study를 보았을 때 각각 사용한 실험 결과가 존재하는 것 같은데 혹시 함께 사용한 실험은 없었는지 궁금합니다.
마지막으로 궁금한점은 2D image에서의 detection 결과도 중요한 것 같은데 Faster RCNN 이외의 detector을 사용한 실험은 없었는지 궁금하네요.
감사합니다!!
안녕하세요 ! 댓글 감사합니다.
방법론 상에서는 ROI Pooling feature을 semantic cues로 사용하고 있지 않는 것이 맞습니다. 아쉽게도 ablation study에서 ROI Pooling feature와 함께 사용한 실험 결과는 없었습니다.
마지막으로 질문해주신 부분은 저도 궁금했던 점이기도 한데요, 이 부분에 대해서도 다른 detector와의 일반성을 고려했기 때문에 다른 detector를 무리없이 사용할 수 있다는 언급만 있을 뿐 따로 실험을 하지는 않은 것 같습니다.
감사합니다.