안녕하세요. 여섯번째 X-Review입니다. 이번 리뷰는 2018년도 CVPR에 게재된 <FOTS : Fast Oriented Text Spotting with a Unified Network> 논문입니다. 바로 시작할게요 ! ?

Introduction
OCR은 크게 문자가 있는 영역을 검출하는 text detection 과정과, 그 검출된 영역의 문자를 인식하는 text recognition 과정으로 구분할 수 있습니다. 과거에 대부분의 방법론들은 이 text detection과 text recognition task를 분리해서 다뤄왔습니다. text detection에서는 보통 CNN을 사용해 feature map을 추출한 다음 각 방법론마다 다른 decoder를 사용해 text region을 detect해왔으며, text recognition은 detection 단에서 검출한 text region을 하나하나 예측하는 sequential prediction을 수행하는 network였습니다. 이 two stage 모델이 이전까지 많이 발전했다면, 이 두 과정을 end to end로 한번에 수행하는 모델들이 나오기 시작했고 이를 text spotting이라고 부릅니다. 오늘 리뷰할 논문 제목을 보면 text spotting이라는 단어가 들어가 있는데, 이 text detection, text recognition을 end-to-end로 수행한 논문이라고 보면 되겠습니다.
text detection과 text recognition을 2 stage로 수행할 때 생기는 2가지의 단점은 아래와 같습니다.
- heavy time
- cost text detection과 recognition 둘 다에서 text region을 각각 다루기 때문에 계산량이 많아져 처리 시간이 길어집니다.
- Ignores the correlation in visual cues shared in detection and recognition
- detection과 recognition이 각각 수행되다 보니 이들이 가지는 visual cue(시각적 단서)들을 공유하지 못하게 됩니다. 정보의 양이 떨어진다고 볼 수 있겠죠.
이런 단점이 있기에 본 논문에서는 text detection과 recognition을 동시에 수행하는 end-to-end 네트워크(FOTS)를 제안하게 된 것이며, 2번째 단점을 해결하고자 text detection과 text recognition 사이에 CNN으로 뽑은 feature들을 공유함으로써 서로간의 정보 공유를 하도록 하여 성능을 높였습니다.

그래서 위 그림의 빨간색 박스 친 부분이 기존 2 stage text spotting 이고, 파란색 박스가 본 논문의 FOTS인데, text detection network의 시간을 비교해보자면 빨간색 single text detection network가 41.7ms, FOTS가 44.2ms로 약간 느리지만 전체 2 stage method로 비교해보면 44.2ms vs 84.2ms 로 거의 두 배 정도의 속도 차이가 나는 것을 볼 수 있네요.
본 논문의 contribution은 다음과 같습니다.
- end-to-end trainable framework 제안
- sharing convolution을 통해 계산량 줄이고, real-time speed 가짐
- RoIRotate 제안
- SOTA
Related Work
Text Spotting
본 논문이 나온 시기 직전에 [Towards end-to-end text spotting with convolutional recurrent neural networks] 논문에서 end-to-end의 text spotting 방법론을 제안했는데, 이 방법론은 text detection에서 RPN을 사용하고 text recognition에서 LSTM과 attention 을 사용하였습니다. 저자는 이 방법론과 비교하여 2가지 주요 장점을 가지고 있다고 하는데 이는 아래와 같습니다.
- 본 논문은 RoIRotate를 포함하여 이전과 다른 text detection 알고리즘을 도입하였기에 검출하기 어렵고 복잡한 이미지에 강인하게 동작한다. 저 방법론은 horizontal의 text에만 적합하였지만, 내 방법론은 그렇지 않다.
- 성능과 속도 측면에서 훨씬 우수하다. text recognition과정에서 추가적인 cost가 거의 발생하지 않기 때문에 우리 text spotting system은 real time으로 동작한다.
Methodology

프레임워크 구조는 다음의 4 모듈로 구성되어 있습니다.
- shared convolutions
- The text detection Branch
- RoIRotate operation
- the text recognition branch
Text Detection branch와 recognition branch는 convolution feature를 공유하며, 이 feature를 추출하는 shared convolution의 구조는 아래와 같습니다.
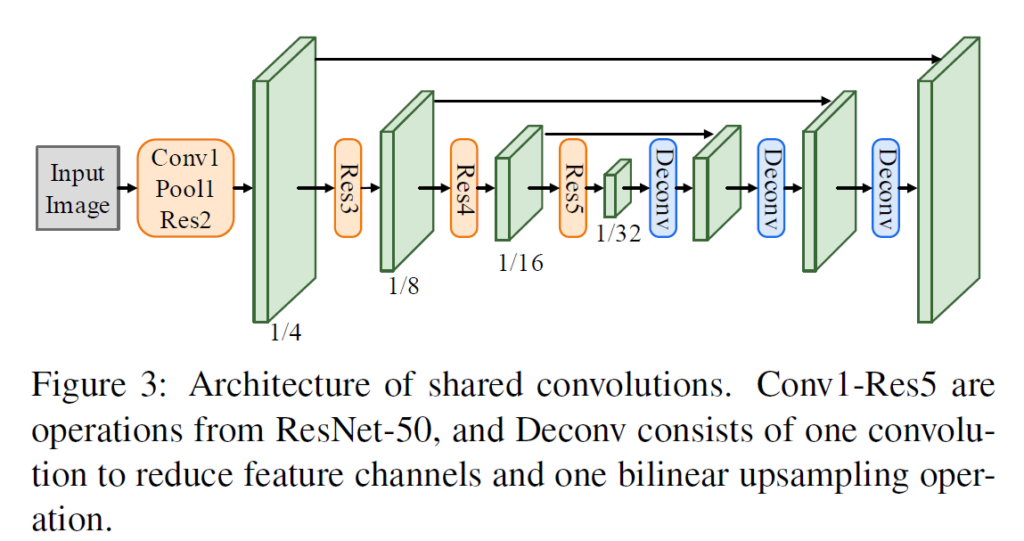
shared convolution은 backbone으로 ResNet50을 사용했습니다. 또, Feature Pyramid Network(FPN)에서 영감을 받아 low level feature map과 high-level semantic feature map을 concat한 것을 볼 수 있습니다.
이렇게 추출한 feature이 text detection branch의 input으로 들어가 output으로 pixel level의 prediction을 하게 되며, 여기서 나온 oriented text region proposal들은 RoIRotate를 통해 이 region에 상응하는 shared feature들을 고정된 height로 표현해줍니다. 이렇게 하는 이유는 text recognition branch의 input으로 사용할 수 있도록 input size를 고정시켜 주는 것입니다. 마지막으로 text recognition branch는 region proposal안의 단어들이 뭔지 인지하면서 끝나게 되겠죠. text recognition 과정에서는 CNN과 LSTM이 encoding과정에서 사용되었으며 decoder로 CTC를 사용하였습니다.
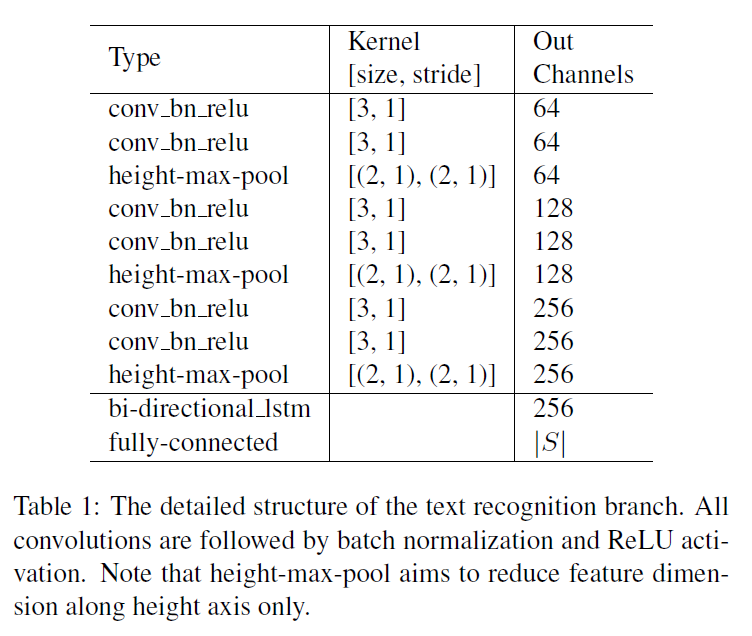
이 그림이 text recognition branch의 구조가 되겠습니다.
이제 각 모듈을 하나씩 자세히 알아봅시다. ..
Text Detection Branch
natural scene image에는 작은 text box들이 많으므로 shared convolution을 통해 나온 원본 이미지의 1/32크기의 feature map을 1/4 크기로 키워 text detection branch의 input으로 사용하였습니다.
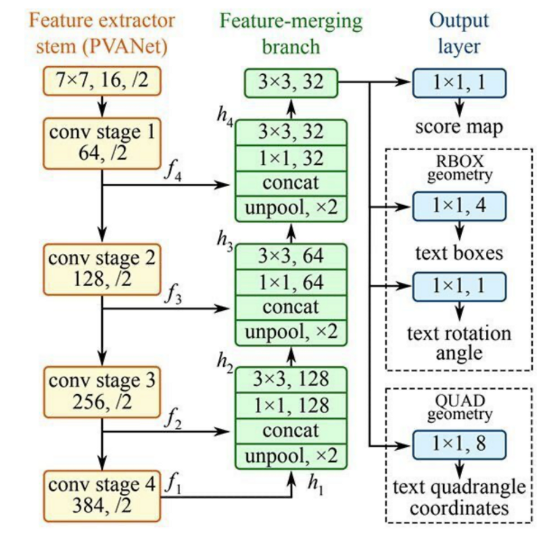
Text detection branch는 기존 text detection 방법론인(위 그림 참고) EAST: An Efficient and Accurate Scene Text Detector 논문에서 소개된 방법론을 그대로 착안한 것으로 보입니다.
이는 Fully convolutional network 기반이며 앞단에서 추출한 input에 가까운 Feature map들을 Concat하는 방식으로(like U-Net), 글자가 있는 영역을 좀 더 잘 Localization할 수 있게 됩니다. decoder를 거치고 나면 최종적으로 Input Size의 1/4 정도 크기의 pixel level Score map과 multi-channel geometry map이 생성됩니다.
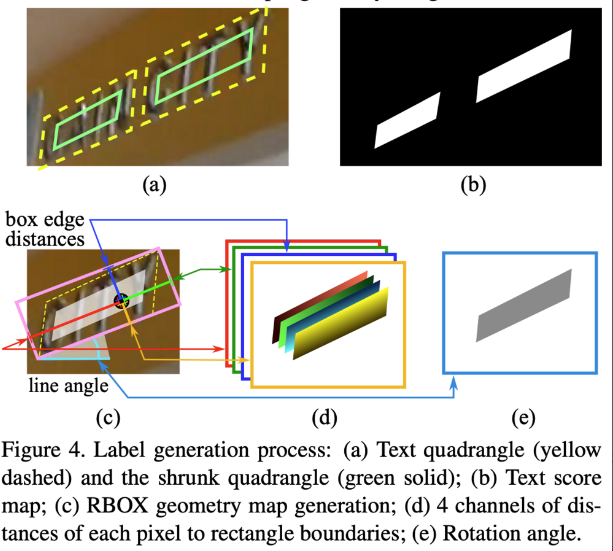
위 그림에서 (b)가 output으로 나온 score map에 해당합니다. 이 score map은 image의 각 pixel이 text region 내에 있을 확률이 담긴 map으로 볼 수 있는데, 확률이 높을수록 1에 가까우므로 흰색으로 나타납니다. 각 pixel값은 0~1의 범위를 갖게 되겠죠. 이와 마찬가지로 (a)이미지에서 text가 있는 region 위치에 (b)score map에 흰색으로 표현된 것을 볼 수 있습니다. 하지만, 이 score map이 정확히 흰색과 검은색으로 나타나는 것은 어렵기 때문에 추가로 5개의 geometry 정보를 사용하여 최종적으로 text region을 proposal 하게 됩니다. 이 5개 channel의 geometry는 text box와 text가 회전된 각도 정보가 담겨있습니다. geometry 4개의 채널은 (d)에서 살펴볼 수 있는데, 이는 각 pixel과 직사각형 경계(box의 네 변)와의 거리를 나타냅니다. 예를 들어 첫번째 채널은 pixel과 box 윗 변과의 거리, 두번째 채널은 pixel과 오른쪽 변과의 거리 .. .. 가 되겠습니다. 그리고 마지막 1개의 채널은 그림(e)과 같이 rotation angle 정보를 담고 있습니다. 이는 bbox의 orientation 정보와 같은 것으로 생각하면 되겠습니다.
이렇게 나온 score map과 5channel의 geometry 정보에 thresholding과 NMS를 거쳐 최종 detection 결과를 도출해내게 됩니다.
저자들은 실험과정에서 울타리나 격자와 같이 text 획과 유사한 패턴들을 text로 오검출 하는 것을 발견하였고, 이러한 패턴을 잘 구별하기 위해 online hard example mining을 적용하였고, 이는 class 불균형의 문제도 해결할 수 있었습니다. OHEM을 통해 ICDAR 2015 dataset에서 약 2%의 F-measure 성능이 오른 것을 확인할 수 있었다고 합니다.
detection branch에서의 loss 함수는 2가지로 구성되는데 text classification 부분과 bbox regression 부분입니다. text classification 부분은 down sampling된 score map의 pixel wise classification loss로 볼 수 있는데, 이 말인즉슨 score map의 각 픽셀이 positive area(텍스트 영역)에 대항하는지 여부를 보겠다는 것으로 이해하면 되겠습니다. 이 과정에서 bbox와 text 영역 사이에 위치하는 영역은 “NOT CARE” 영역으로 loss를 계산할 때 고려하지 않습니다.
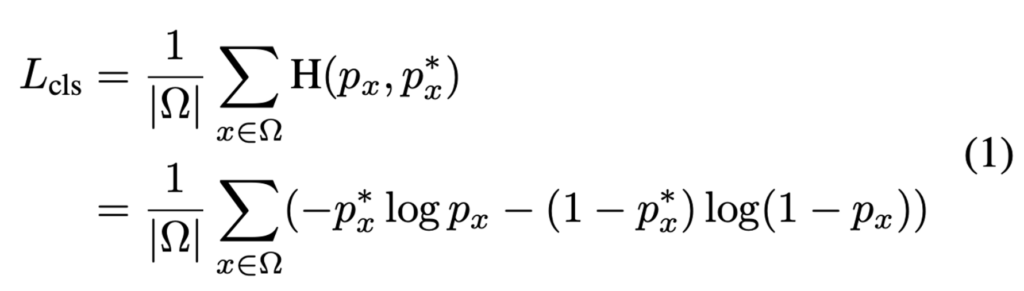
- |Ω| : OHEM에 의해 score map에서 선택된 positive element 개수
- H(p_x, p^∗_x) : cross entropy loss between p_x, p^∗_x
- p_x : the prediction of the score map
- p^∗_x : the binary label that indicates text or non-text
아까 score map은 pixel 단위로 해당 pixel이 text일 확률을 의미하는 map이라고 하였습니다. 또 OHEM은 이 score map에서 text로 분류되어야 할 pixel 중 model이 예측한 값과 실제 label 값 사이에 오차가 큰 pixel(hard example)을 선택하게 되겠죠. 따라서, loss 식에서 Ω는 이 OHEM 과정에서 선택된 pixel(hard example)의 수를 의미합니다.
또한, score map의 예측값인 p_x와 pixel이 text인지 text가 아닌지 값을 가지고 있는 binary label p^∗_x 사이의 Cross Entropy loss가 사용되고 있습니다.
즉, 정리해보자면 OHEM에 의해 선택된 pixel들에 한하여 loss를 계산하며 최종 cls Loss는 각 positive element loss의 합이라고 할 수 있겠습니다.
classification loss를 알아봤으니, 이제 regression loss를 살펴보겠습니다. regression loss 식은 아래와 같으며, IoU loss와 rotation angle loss를 사용했습니다.
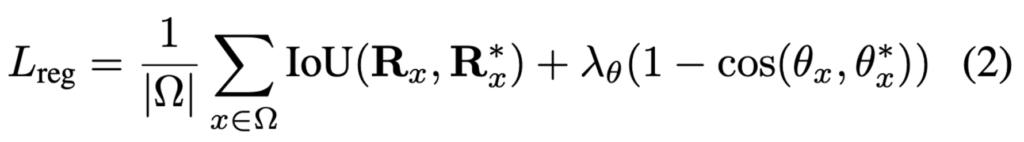
- |Ω| : OHEM에 의해 score map에서 선택된 positive element 개수
- R_x : the predicted bounding box
- R^*_x : the ground truth
- θ_x : the predicted orientation
- θ^*_x : the ground truth orientation
하이퍼 파라미터 λ_θ는 실험에서 10으로 설정하였습니다.
최종 detection loss는 아래와 같이 나타낼 수 있겠습니다.
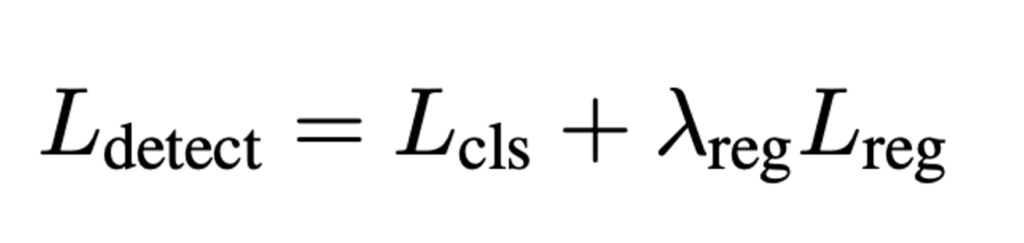
하이퍼파라미터 λ_{reg}는 두 loss 사이의 균형을위한 것으로 실험에서는 1로 설정하였습니다.
RoIRotate
RoIRoate는 방향을 가지는 feature map들을 축을 고정시켜 정렬시키는 과정이라고 보시면 됩니다. detection 과정에서 예측된 box들은 rotate 되어 있고 길이도 제각각 다르기 때문에 text의 variance를 처리하기 위해 높이도 고정하고 aspect ratio도 고정하는 방식으로 동작하는 것입니다. 아래 그림을 참고하면 되겠습니다.

RoI Pooling과 RoIAlign에 비하여 RoIRotate는 RoI에서 feature를 추출하기 위한 더 general한 작업을 한다고 합니다. RoI Polling과 RoIAlign은 일반적으로 사각형 형태의 RoI를 처리하기 위해 사용되지만 RoIRotate는 회전된 text region을 처리하기 위해 설계되었기에 text의 rotation과 length에 대해 더 유동적으로 대응할 수 있기 때문이라고 보면 됩니다.
또, RRPN에서 제안한 RRoI Pooling과 RoIRoate를 비교했을 때도 RoIRotate가 text를 다룰 때 더 적합한데, 그 이유로는 RRoI pooling은 회전된 영역을 max pooling을 통해 고정된 크기로 변환하는 반면에, RoIRotate는 bilinear interpolation을 사용하기 때문에 RoI와 추출된 feature 사이의 misalignment를 피할 수 있고 output feature의 길이를 가변적으로 만들기 때문입니다.
RoIRotate과정은 크게 두 step으로 나눌 수 있습니다.
- predicted text proposal의 좌표와 gt 좌표 사이의 affine transformation parameters 계산
- 1에서 구한 affine transformation parameter를 사용해 shared feature map에 affine transform 적용
이 과정을 통해 text region의 feature map을 수평으로 정렬할 수 있게 됩니다.
첫번째 step의 수식은 아래와 같습니다.
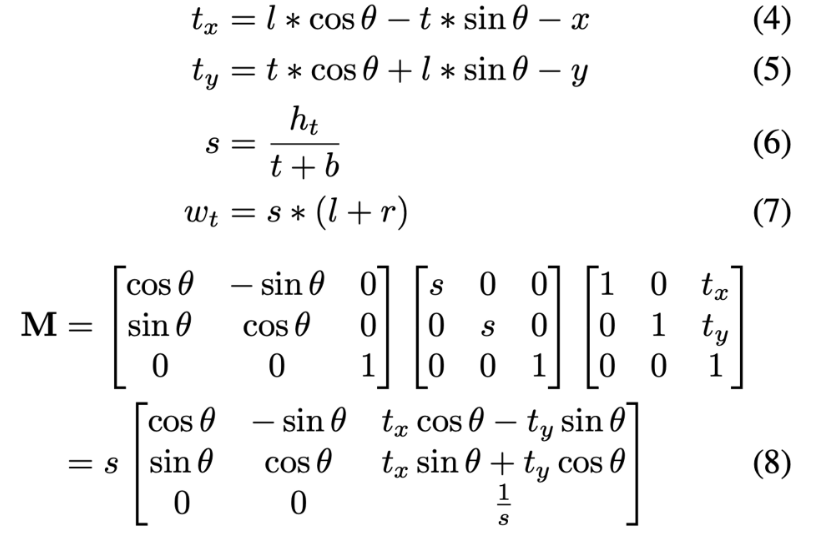
- M : The affine transformation 행렬
- h_t : affine transformation 이후 feature map의 height
- w_t : affine transformation 이후 feature map의 width
- (x, y) : shared feature map의 좌표
- (t, b, l, r) : text proposal과 상하좌우간의 각 거리
- θ : the orientation
(t, b, l, r)과 θ는 ground truth가 존재하며, detection branch에서도 예측되어 나오는 값입니다. 또 고정된 height로 변환시켜준다 했는데, 본 논문에서는 h_t를 8로 설정하였습니다.
식 (4)와 (5)를 보면, detection을 거치고 나온 text region의 좌상단 x, y좌표를 구하는 식이며 식(6), (7)은 각각 글자 영역의 세로, 가로 scale을 계산하는 식으로써 height의 크기, width의 크기를 조정하는데 사용됩니다. height를 8로 고정하였기에 가로는 그에 맞는 비율로 줄어들거나 늘어나므로 w_t를 구하는 식에 세로 scale값이 들어간 것을 확인할 수 있습니다.
이렇게 구한 t_x, t_y, s, w_t를 가지고 만든 변환행렬이 식(8) M입니다. 식을 보면,, rotation, scailing, translation을 조합한 행렬이죠. 먼저 θ만큼 text region을 회전시킨 후, s(scale)만큼 가로, 세로 방향으로 확대 혹은 축소합니다. 마지막으로 t_x, t_y만큼 이동시키면 결국 높이는 8로 고정시키고, 가로는 8로 고정시킨 세로 비율에 맞춰 변환하여 rotate하는 것입니다. 이때 8로 고정시킨 height에 맞춰 변환한 width는 길이가 다를 것인데, 가장 긴 width 길에 맞춰 남는 부분을 padding하게 되고, recognition loss function 계산 과정에서 padding한 부분을 무시하는 식으로 동작하게 됩니다.
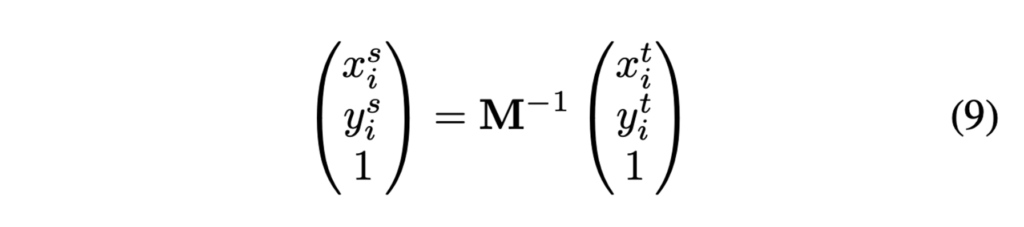
이렇게 affine행렬을 구했으면 아까 언급한 2번째 step. shared feature map에 affine transform을 적용시켜 주어야겠죠. transformation matrix M의 역행렬을 이용해 RoI의 좌표를 변환합니다.
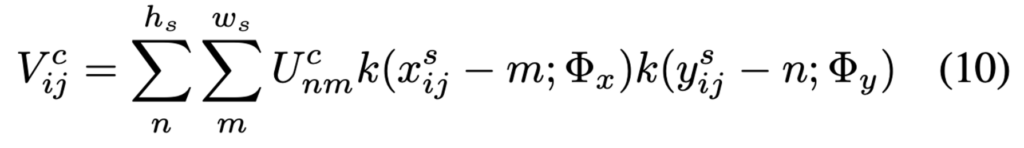
- U^c_{nm} : 채널 c에서 (n, m)위치에 해당하는 pixel값
- \Phi_x, \Phi_y: interpolation 방법 정의
- h_s, w_s : detection과정에서 나온 RoI의 height, width
- k() : 좌표 (x^s_{ij} – m, y^s_{ij} – n)에서의 sampling kernel
식 10은 단순하게 식(9)에서 변환한 좌표를 사용해 bilinear interpolation을 하는 과정입니다.
좀 더 구체적으로 과정을 살펴보자면 다음과 같겠습니다.
- affine transformation matrix를 구한 후 이를 이용해 RoI 좌표 변환하여 새로운 좌표 (x^s_i, y^s_i)구하기
- 모든 (i, j)를 돌며 다음의 과정 반복
- 변환된 좌표 (x^s_i, y^s_i)에서 가장 가까운 4개의 pixel 찾기
- 그 pixel 값은 U^c_{nm}에 저장
- 변환된 좌표와 해당 픽셀 위치 사이 거리에 따라 가중치 계산
- 가중치를 사용해 U^c_{nm}을 V^c_{ij}에 누적
Spatial Trnasformer Network에서도 이렇게 affine transformation을 사용하였지만 이는 이미지 도메인에서 이미지 자체를 변환하는데 사용하였습니다. 반면, RoIRotate는 shared convolution에 의해 생성된 feauture map 자체를 입력으로 사용해서, 이 feature map을 변환하는 것입니다.
object classification과는 달리 text recognition 과정은 굉장히 detection noise에 민감합니다. 예측한 text region의 작은 오차가 몇 글자를 잘라낼 수도 있겠죠. 그렇기에 training과정에서는 detection단에서 예측한 text region대신 실제 text region(GT)를 사용하여 학습합니다.
Text Recognition Branch
이제 마지막 text recognition 부분입니다. text recognition branch는 shared convolution에 의해 추출한 region feature와 RoIRotate에 의해 변환된 feature를 사용하여 어떤 글자인지 인식하는 과정입니다.
recognition branch의 구성은 다음과 같습니다.
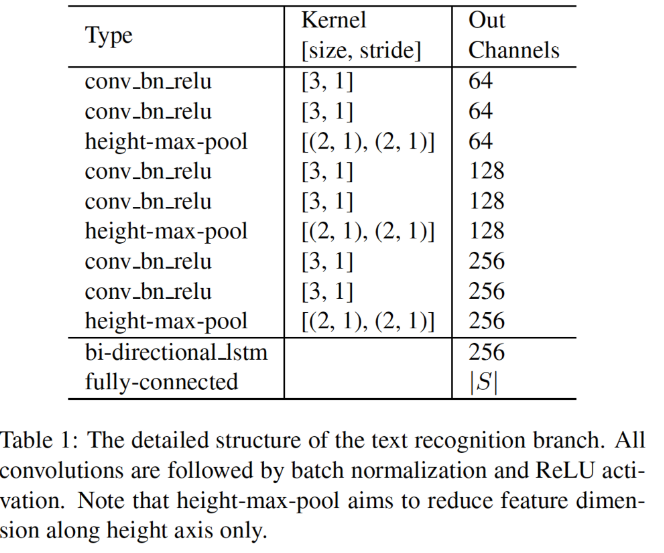
- VGG-linke sequential convolutions
- 가로 축을 기준으로 feature map 크기 축소 (pooling)
- bi-directional LSTM
- fully connection layer
- CTC decoder
이렇게 CNN-LSTM-CTC 순서로 동작하는 과정은 아래 그림의 CRNN과 동일합니다.
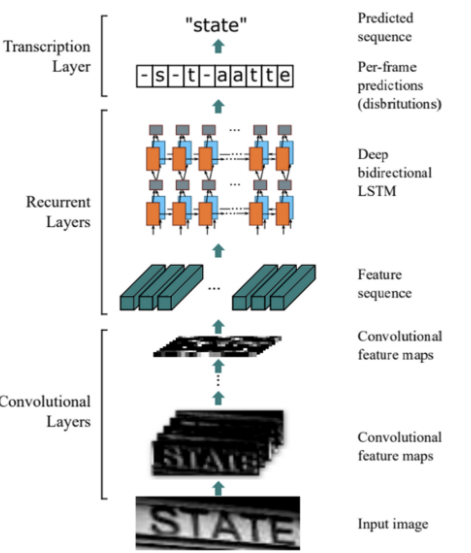
먼저, 아래 그림의 vgg와 유사한 sequential convolution과 pooling층을 통과하여 higher level의 feature들을 추출합니다.
다음으로 추출된 high level feature map L \in \mathbb{R}^{CxHxW}는 time major형태의 sequence인 l_1, … , l_w \in \mathbb{R}^{CxH}로 변환됩니다. 이 시퀀스는 RNN에 입력으로 들어가 인코딩되는데, 본 논문에서는 bi-LSTM을 사용하였습니다. 앞의 정보 뿐 아니라 뒤의 정보까지 고려하여 text recognition해야 하기 때문에 bidirectional로 동작하는 bi lstm을 사용한 것입니다. bi-LSTM을 거친 후 나온 output은 fully connection layer에 들어갑니다. fc layer를 통과하게 되면 어떤 Class일 확률이 높은지가 결과로 나오게 되며, 마지막으로 CTC(Connectionist Temporal Classification)을 사용함으로써 recognition 과정이 마무리 됩니다.
fc layer를 거쳐 예측된 결과는 output과는 다른 lenth의 길이는 sequence입니다. 예를 들어 아래 그림처럼 “hello”라는 결과가 나와야 하지만 fc layer를 거쳐 나온 결과는 “hhe lll llo”가 나오는 경우에 해당하겠죠. 이렇게 나온 결과를 실제 recognition result로 바꾸기 위한 과정입니다.

“hhe lll llo”를 hello로 바꿔주기 위해서는 중복되는 글자를 하나로 줄이면 되겠죠, 하지만 그렇게 되면 l도 하나로 줄어들어 “helo”가 될 것입니다. 이렇게 l이 두 번 중복되는 경우를 구분하기 위해 공백을 사이에 끼워넣어 준 것입니다. 공백 기준으로 연속되고 중복되는 글자를 하나로 줄이고, 공백도 제거한 후 이어붙이면, 최종적으로 “hello”가 완성되겠습니다.
아무튼 이 CTC 알고리즘까지 사용하여 최종적으로 text recognition 과정이 끝나게 되는 것입니다.
text recognition loss에 대해 알아봅시다.
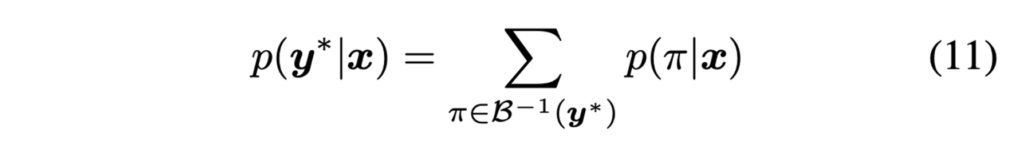
위 식(11)은 각 time에서 문자 class S에 대한 확률분포 x_t가 주어졌을 때 이 확률 분포에 맞는 label 분포를 계산하고, 계산한 label distribution이 실제 recognition label y^*와 일치하는 경우의 확률을 계산한 것입니다.
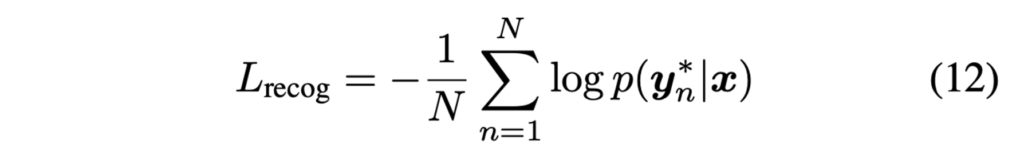
- N : input image에서 text region 수
- y^*_n : The recognition label
loss 식을 보면 전체 train dataset에 대해 식(11)의 확률 합의 log likelihood를 최대화하도록 학습하는 것을 목표로 하는 것임을 알 수 있습니다.
최종적으로 앞단의 text detection branch과정의 loss인 L_{detect}와 결합하여 나온 최종 로스 함수는 아래와 같겠습니다.
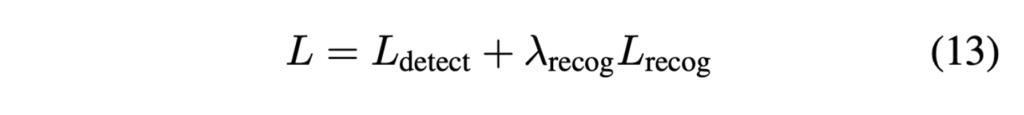
두 loss간의 trade off를 조절하는 하이퍼 파라미터인 \lambda_{recog}는 experiment과정에서 1로 설정하였습니다.
정리해보자면, text detection과 recognition에서 convolution을 공유하여 feature를 한번만 뽑을 수 있도록 해 속도 측면에서 이점을 가져갔으며, RoIRotate를 사용함으로써 detection과 recognition을 end-to-end로 학습 가능하게 한 모델이라고 보면 되겠습니다. text detection은 기존에 존재하던 EAST 모델과 구조가 거의 유사하며 recognition은 CRNN과 전 과정이 동일한 것으로 그저 RoIRotate를 새로 제안하여 둘을 이은 것이 메인인 것 같습니다.
Experiments
실험 과정에서 ImageNet으로 사전학습한 모델을 사용하였습니다. train 과정은 두 단계로 이루어지는데, 먼저 Synth800k dataset으로 10 epoch 동안 학습한다음, real image data를 사용해 모델을 이어 학습하게 됩니다.
text detection branch에서 성능 향상을 위해 OHEM을 사용하였다고 하였습니다. 이미지에 대해 512개의 negative sampler과 512개의 random positive, negative smaple을 뽑아 사용하였는데, 이 과정을 통해 positive와 negative의 비율이 1:60에서 1:3으로 증가시킬 수 있었습니다.
실험은 ICDAR2015, ICDAR2017 MLT, ICDAR2013에서 진행하였습니다.
ICDAR2013, 2015
이 dataset은 “Strong”, “Weak”, “Generic”이라는 3가지 사전(lexicon)을 제공합니다. “Strong”은 이미지당 100개의 단어를 제공하며 이미지에 나타나는 모든 단어를 포함한 사전이며, “Weak”는 전체 test set에 있는 모든 단어가 포함되어 있습니다. 마지막으로 “Generic”은 9만개의 단어를 가지고 있습니다.
ICDAR2017
앞의 두 데이터셋은 크기가 굉장히 작은 dataset입니다. 2015의 경우 train datset이 1000개, test datset이 229개이며, 2013의 경우 train, test 개수가 각각 229, 223개입니다. 반면 2017 dataset의 경우 다국어 text를 포함한 대규모 text datset으로 7200개의 train image, 1800개의 valid image, 9000개의 test image로 구성되어 있습니다.
2013 dataset은 수평 text만 포함하고 있지만, 15와 17dataset은 여러 방향을 가지는 text가 존재합니다.
Comparison with Two-Stage Method
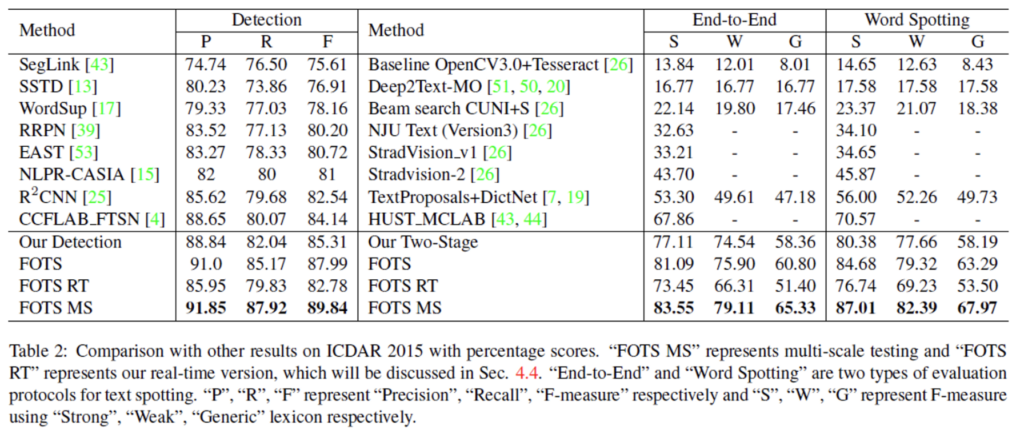
text detection과 recognition을 각각 수행하는 2 stage model과의 성능을 비교해봅시다. 위의 표는 ICDAR2015에서의 결과입니다. FOTS MS는 multi scale testing을 의미하며 FOTS RT는 real time 버전입니다. P, R, F는 각각 Precigion, Recall, F-measure를 의미하여, S, W, G는 앞에서 dataset설명할 때 언급한 Strong, Weak, General을 사용한 F-measure입니다. 결과를 보면, 2 stage 방법론들과 성능 차이가 꽤 나고 있네요. 특히 text spotting을 보면 이전 SOTA성능인 70.57보다 15%이상 차이나는 성능을 보여줍니다.
본 방법론 FOTS의 text detection 단은 EAST[53] model을 거의 그대로 가져왔다고 했었는데, detection 단에서 precision 차이가 0.5정도 나는 것을 확인할 수 있었습니다. . .이에 대한 정확한 이유는 잘 모르겠네요.
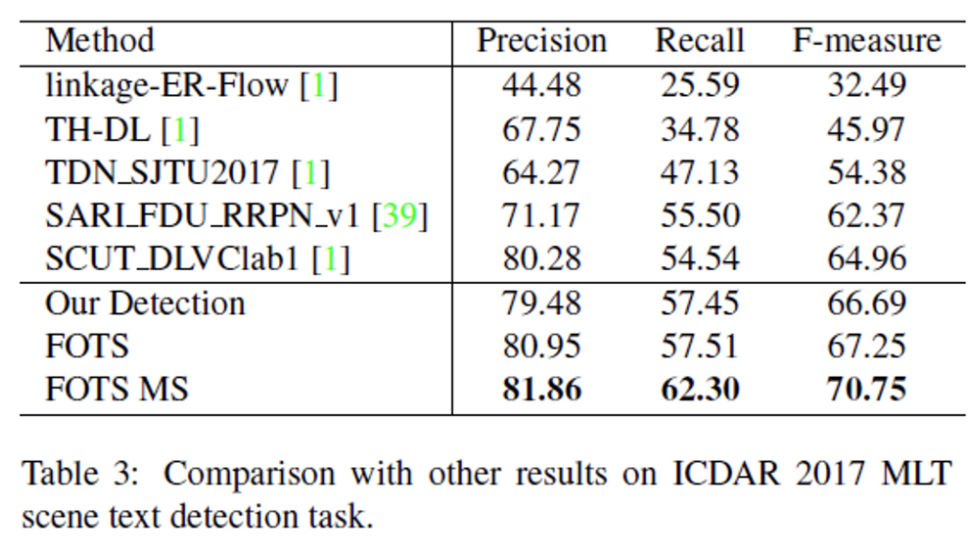
ICDAR2017 결과를 봐도 마찬가지입니다. FOTS의 detection 결과만 봤을 때는 precision 성능이 SCUT_DLVClab1이 조금 더 높긴 합니다.
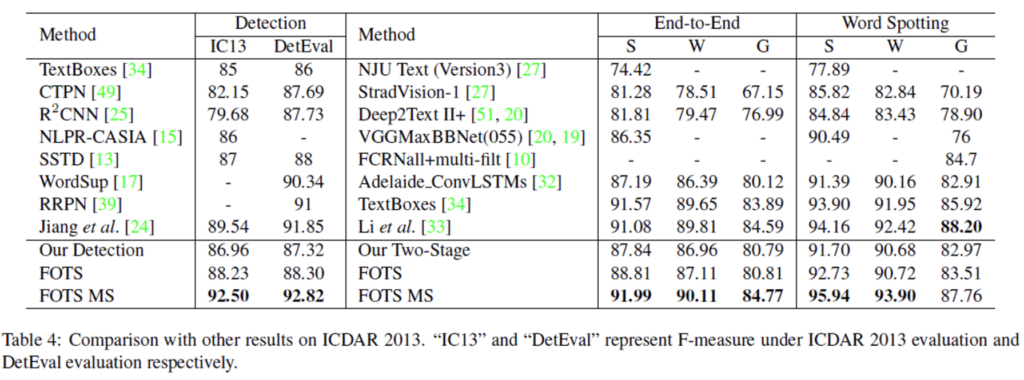
ICDAR2013에서도 마찬가지로 SOTA를 달성하였습니다.

FOTS가 text detection에서 타 방법론보다 더 좋은 성능을 보이는 이유로 text recognition supervision이 세세한 글자의 detail을 학습하도록 도와주기 때문이라고 합니다. Text detection에서 일반적으로 나올 수 있는 오검출로는 4가지가 있습니다.
- Miss : text region을 검출하지 못하는 경우
- False : text가 아닌 영역을 text로 검출한 경우
- Split : text region을 잘못 분할한 경우
- Merge : text region을 잘못 합친 경우
[Fig5]를 보시면, 타 detection 결과에 비해 FOTS는 이러한 오검출이 적은 것을 확인할 수 있습니다.
Speed and Model Size
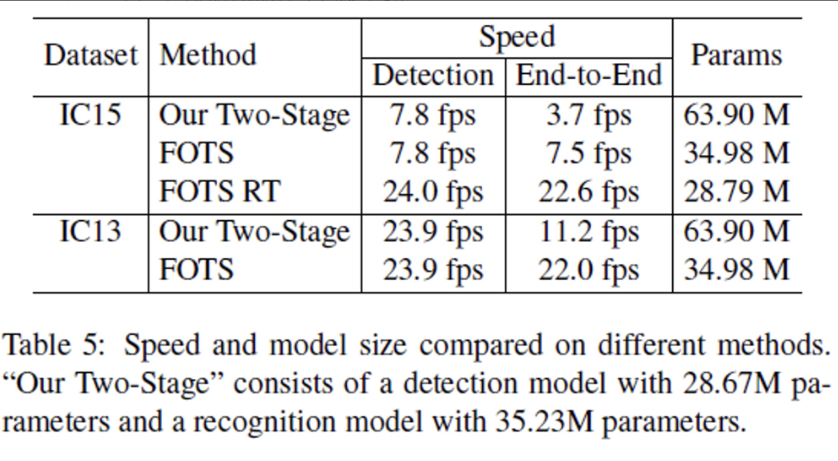
위 표[Table 5]에서 볼 수 있듯 FOTS는 shared convolution 때문에 단일 text detection network와 속도 측면에서 비교해봐도 거의 추가적인 cost가 들지 않는 것을 확인할 수 있습니다. IC15에서 FOTS의 detection 속도는 7.8fps인데, end-to-end로 recognition까지 수행해도 7.5fps로 거의 동일한 fps를 보이고 있습니다.
또한 FOTS의 detection, recognition 단을 two-stage network로 동작한 결과 end-to-end는 3.7fps가 나왔지만, FOTS는 7.5fps로 거의 2배 빠르게 동작함을 확인할 수 있습니다.
안녕하세요. 리뷰 잘 보았습니다. 질문을 좀 드리자면,
맨 첫번째 그림에서 기존에 2stage 방법론은 Detection하는데 41.7ms, Recognition하는데 42.5ms 총 84.2ms가 소요된다고 하셨습니다. 근데 제가 생각했을 때는, 검출된 영역에 대해서 모델이 인식만 하면 되는거라 서칭해야할 영역이 없어지기에 추론 속도가 42.5ms까지 걸릴 것 같지는 않은데 recogntion에서 42.5ms나 잡아먹는 이유는 무엇일까요?
그리고 리뷰의 표현들이 어색한 부분이 여러 존재합니다. 구체적으로 “저 방법론은 horizontal의 text에만 적합하였지만, 내 방법론은 그렇지 않다.” 라고 작성하신 부분 있는데, 앞으로 리뷰 쓸 때는 “이전 방법론들(혹은 베이스라인 방법론)은 ~~하지만, 저자가 제안하는 방법론(혹은 방법론의 이름(FOTS))은 ~~하다” 라는 식으로 작성해주세요. 주어 목적어에 대하여 명확한 지칭을 해주어야 독자가 리뷰를 읽고 이해하기 쉽습니다.
그리고 해당 논문에서는 text detector의 출력 값이 segmentation으로 나오나요? 리뷰 내용 중에 ” 추출한 feature이 text detection branch의 input으로 들어가 output으로 pixel level의 prediction을 하게 되며…”로 적혀있는데 pixel level prediction이면 단어가 존재한다 안한다라는 binary mask를 추출한다는 의미인가요?
근데 overall framework에서는 Text Detection Branch가 BBox를 예측한다고 나와있는데, 무엇이 맞는지 확인 한번 해줄래요? bounding box를 통해서 binary mask를 만드는 것인지, binary mask를 통해서 bounding box를 계산한 것인지가 궁금하네요.
그리고 위 질문의 연장선으로 만약 검출기 쪽 학습이 bbox 예측이라면 anchor based 방식으로 방법론이 설계되나요? 아니면 segmentation으로 예측하는 것이기 때문에 anchor를 활용하지 않나요?
그리고 loss 계산할 때 classification loss에 대한 설명 중 “이 과정에서 bbox와 text 영역 사이에 위치하는 영역은 “NOT CARE” 영역으로 loss를 계산할 때 고려하지 않습니다.” 라는 내용이 있는데 여기서 NOT CARE 영역은 어떻게 알 수 있나요? GT가 따로 제공되나요? 그리고 이러한 classification loss 계산을 bounding box가 아닌 pixel level로 수행한다는 것은 segmentation을 의미하는 것인가요?
결국 모든 질문들의 핵심은 detection branch가 bbox 예측인 것인지 pixel-level에서의 segmentation인지를 명확하게 알면 해결될 것 같네요.
안녕하세요 ! 댓글 감사합니다.
1. 2 stage 방법론의 recognition단에서 42.5ms의 추론 속도가 걸리는 이유는 recognition을 할 때도 detection과 동일하게 cnn을 이용해서 feature를 extract하는 과정이 있기 때문입니다. 본 논문에서는 이 feature를 추출하는 convolution을 공유하도록 해서 시간을 줄인 것으로 보면 됩니다.
2. 넵 ㅠㅠ 명확한 지칭하도록 할게요 !
3. text detection branch에서 최종 output은 bbox가 맞습니다. 다만, 모델을 통과하면 output으로 나오는 score map과 geometric map은 pixel level map으로 segmentation으로 나오는 것이 맞습니다. 이 둘을 가지고 thresholding과 NMS를 거쳐 RoIRotate로 들어가기 전 최종 output bbox를 생성해내게 됩니다.
즉, binary mask를 통해 bounding box를 계산한 것으로 보면 되겠습니다.
4. anchor based 방식의 방법론은 아닙니다. pixel level의 output(score map, geometric map)이 도출된 후 이를 가지고 bbox를 만드는 것이기에 anchor free detector입니다.
5. ICDAR 2015와 ICDAR 2017 MLT dataset에는 육안상 알아보기 힘든 글자의 text region에 “NOT CARE”가 labelled된 GT가 존재합니다. 또, classification loss계산을 pixel level로 수행한다는 것은 segmentation을 의미하는 것이 맞습니다. text일 확률을 나타내는 binary mask인 score map이 잘 생성되었는지 확인하는 것으로 생각하면 되겠습니다. 이 score map, geometric map을 가지고 bbox를 생성한 후 이에 대한 loss가 detection branch에 regression loss에 해당하겠습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
Text recognition과정에서 rnn의 일종인 lstm을 사용하는 이유가 있나요? 또 bi lstm을 거친 후 CTC 알고리즘을 통해 중복되거나 공백을 제거하는 과정을 거쳐 최종 text를 인식한다고 하셨는데 이게 text recognition task의 일반적인 과정인건지 궁금합니다.
또 마지막으로 실험 단에서 synth80k dataset으로 10 에포크 학습한 후 그 다음 real image로 학습을 이어서 한 이유가 있을까요?
안녕하세요. 댓글 감사합니다.
1. image마다 글자의 크기와 배치가 다르기 때문에 word 형태의 이미지를 하나하나 글자 단위로 나누는 것은 거의 불가능하겠죠. 그래서 feature map의 부분적인 정보만을 이용해 text를 예측하기 위해서는 앞뒤의 다른 정보를 종합적으로 고려해야 합니다. 그렇기에 feature map을 sequence data로 나눈 다음 처리할 때 이 시퀀스를 반영할 수 있는 rnn 모델을 사용하는 것입니다.
2. text recognition의 일반적인 과정은 아니고, attention이나,, TPS(Thin-Plate Spline) 등을 이용한 방법도 존재합니다.
3. experiments에 적어뒀듯 dataset자체가 크기 않기 때문에 합성 데이터셋으로 미리 학습 후 real dataset으로 fine tuning하는 것으로 이해하면 되겠습니다.