Introduction
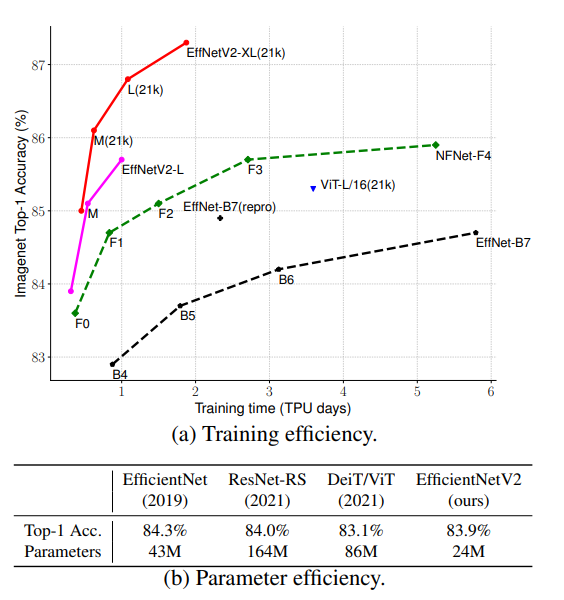
딥러닝 모델과 사용되는 데이터의 크기가 커짐에 따라 딥러닝의 training efficiency의 중요성 또한 증가하였으며, 관련 연구 또한 활발히 진행되었습니다. 대표적으로 CNN기반 모델에는 불필요한 batch norm을 제거한 NFNet, ResNet에서 레이어의 depth, width등의 scaling hyperparameter를 최적화한 ResNet-RS가 있으며, transformer 기반 모델에는 NLP의 transformer block을 사용한 ViT가 있습니다. 그러나 이러한 모델들은 training efficiency에 있어 각자 개선점을 보였으나, [그림1(b)]에서도 볼 수 있듯 모델의 크기가 크다는 한계가 있었습니다.
이에 논문의 저자들은 EfficientNetV1을 기반으로 기존에 다른 연구에서 제안되었던 training-aware neural architecture search(NAS)를 사용하여 training speed와 parameter efficiency를 모두 확보하였습니다.
저자들은 이전 연구인 EfficientNet을 기반으로 training time에 대해 모델의 depth, width, 입력 이미지의 resolution에 따른 비교 실험을 통해 세 가지의 bottleneck이 있음을 밝혔습니다. 첫 번째는 (1)large image 로 학습을 진행하면 training speed의 저하가 발생한다는 것, 두 번째는 early layer에서 진행되는 depthwise convolution은 연산이 느리다는 것, 마지막으로는 모든 stage에서 진행되었던 scaling up작업이 sub-optimal 하다는 것입니다. EfficientNetV2는 이러한 실험적 결과를 기반으로 Fused-MBConv, training-aware NAS 등의 기법을 사용하여 기존 EfficientNet보다 4배 빠르며 6.8배 적은 파라미터를 가지게 되었다고 합니다.
이 논문에서 training speed를 올린 핵심적인 방법은 progressive learning을 통해 training epoch에 따라 다른 regularization을 적용한 것입니다. 기존에도 다양한 regularization 방법론들이 존재했었는데요, 저자들은 기존 연구에서 training에 사용하는 image size가 달라짐에도 같은 정도의 regularization을 적용한 것이 모델의 accuracy drop을 가져온다고 주장하였습니다.
같은 네트워크를 사용한다고 가정할 때, small image는 small network capacity를 유도하므로 weak regularization이 필요하고, 반대로 이미지가 큰 경우에는 overfitting을 방지하기 위해 strong regularization이 필요하다는 것입니다.
논문의 contribution을 정리하자면 다음과 같습니다.
- training-aware NAS와 scaling을 통해 training speed와 parameter efficiency를 모두 확보한 모델인 EfficientVetV2를 제안
- image size에 따라 regulization의 정도를 조절하는 improved progressive learning 제안
- ImageNet, CIFAR, Cars, Flowers 데이터셋의 prior art에 비해 11배 빠른 학습 속도와 6.8배 적은 파라미터 수를 보임
Architecture Design
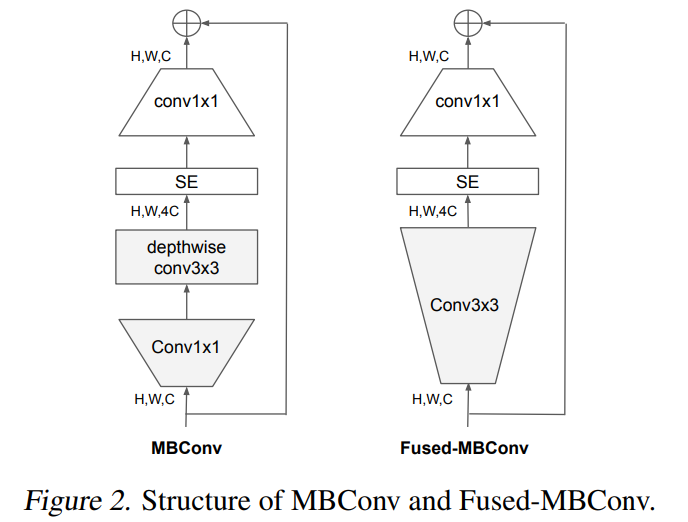
기존 EfficientNet은 [그림2]에 나타는 MBConv블록으로 구성되어 있으며, depth wise convolution을 사용하였습니다. depthwise convolution은 MobileNetV1에서 제안된 연산으로, 각 채널에 depth가 1인 convolution연산을 사용하고 그 결과를 concat하는 방식으로 계산됩니다. 이를 통해 기존에 사용되던 convolution연산에 비해 더 적은 메모리와 연산량을 확보할 수 있었습니다.
그러나 depthwise convolution은 일반적인 convolution에 비해 최신 accelerator에서 잘 동작하지 못하고 overhead가 발생하였습니다. 저자들은 이를 보완하기 위해 MBConv의 depthwise 3×3 convolution 연산을 3×3 convolution 연산으로 전환한 Fused-MBConv 블럭을 이용하였습니다.
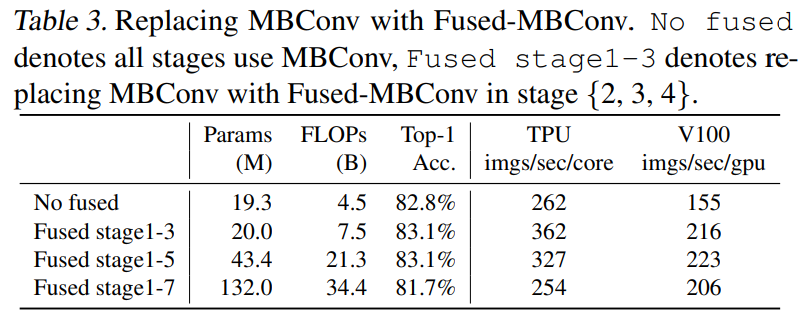
[표3]은 EfficientNet-B4에서 MBConv를 Fused-MBConv로 대체하였을 때의 결과를 나타낸 것입니다. [표3]을 보면 MBConv 블럭만 이용했을 때보다 Fused-MBConv 블럭을 이용했을 때, parameter 수와 FLOPs 측면에서는 손해를 보지만 학습의 정확도와 속도 측면에서는 오히려 효율적임을 알 수 있습니다.
저자들은 모델의 어느 부분에 Fused-MBConv블록을 사용해야 효과적인 모델을 설계할 수 있을지 알아내기 위해, 강화학습을 이용한 Neural Architecture Search를 사용하였습니다. 이때 보상 함수는 accuracy와 training time, 모델의 parameter 개수로 구성하였습니다.
Training-Aware NAS and Scaling
Neural Architecture Search란 신경망을 자동으로 설계하는 알고리즘으로 모델에 들어갈 요소들을 파라미터로 설정하고, 모델의 성능이나 training time등을 보상함수로 설정하여 강화 학습 기반으로 최적의 신경망을 설계할 수 있는 기술입니다. NAS에 관해 자세히 아는 것은 아니지만… 대략적으로는 convolution 신경망을 설계한다고 할 때, 사용될 layer block(이 경우에는 [그림2]의 MBConv 혹은 Fused-MBConv), 레이어의 개수, 커널의 크기(3\times 3, 5 \times 5, …)를 어느 정도 범위까지 사용할 것인지를 미리 정해두면 가능한 경우의 모델을 sampling하고 최적의 모델을 search합니다.
EfficientNetV2는 이러한 자동 탐색 알고리즘을 통해 만들어졌는데요, 앞서 언급했다시피 training efficiency와 parameter efficiency를 모두 고려하기 위해 두 가지를 모두 보상 함수에 포함시켜 설계를 진행하였습니다.
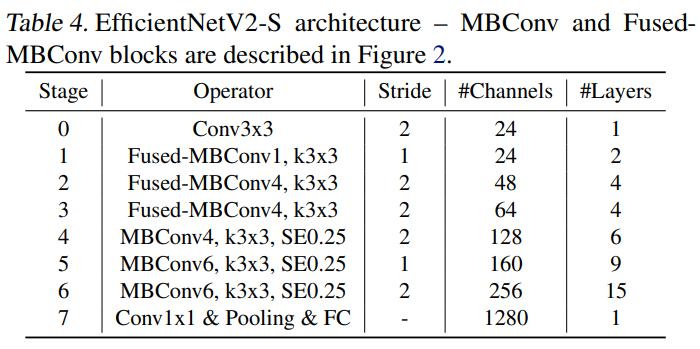
최종적으로 생성된 EfficientNetV2의 구조는 아래의 [표4]와 같습니다. 앞 부분에는 Fused-MBConv를 사용하였고, feature의 채널 수가 증가하는 4stage이후에는 MBConv를 사용하여 연산의 정확도와 효율성을 둘 다 고려하였습니다.
Progressive Learning

EfficientNet V1의 B0와 B7 모델은 각각 224×224와 600×600 해상도의 이미지로 학습을 진행하였습니다. CPU/GPU 메모리 등 학습 환경이 동일한 경우, 큰 이미지를 사용하면 작은 이미지를 사용하는 것에 비해 batch size가 작아지고, 이로 인해 training speed가 감소합니다. [표2]는 EfficientNetB6에 서로 다른 해상도의 이미지를 사용하였을 때 이미지 당 처리 시간을 나타낸 것으로, 이미지 크기가 512인 경우가 380인 경우보다 단위 시간동안 적은 수의 이미지를 학습한다는 것을 보여주고 있습니다.
이러한 문제를 개선하기 위해 progressive resizing이라는 학습 방법이 제안되기도 하였습니다. Progressive resizing은 작은 크기의 이미지에서 큰 크기의 이미지의 순서로 모델을 학습하는 방법으로, 학습 도중에 학습 이미지의 크기를 동적으로 조절하였습니다. 대표적인 것이 Three layer cake model 이라고 불리는 형태의 모델인데, 먼저 48×48 크기의 이미지로 모델을 학습한 후에, 모델의 맨 앞 layer에 96×96 크기의 이미지를 받을 수 있는 convolution layer와 48×48 크기로 변환해주는 pooling layer만을 붙여서 96×96 크기의 이미지로 학습을 이어가는 형식의 방법입니다.
이렇게 학습하면 작은 이미지를 큰 이미지로 크기 변환해서 학습할 필요가 없기 때문에, 평균적인 이미지 크기를 줄일 수 있고 결과적으로 학습의 효율성을 높이게 됩니다. 또한 작은 크기의 이미지에서 큰 크기의 이미지의 순서로 학습이 진행되기 때문에, 처음에 쉬운 시각 정보를 먼저 학습하고 이후에 이를 바탕으로 어려운 시각 정보를 학습할 수 있어 모델이 더 빠르게 수렴하게 됩니다. 하지만 실제로 progressive resizing을 적용하면 모델의 정확도가 기존보다 조금 떨어지는 문제가 있다고 합니다.
여기서 저자들이 하나의 가설을 세웠는데요, 바로 이미지의 크기가 달라지는데 매번 동일한 정도의 regularization을 적용한 것이 모델의 성능을 저하시키는 결과를 가져왔을 것이라고 생각했습니다.
이미지의 크기에 따라 augmentation의 정도를 조절해햐 함을 보이기 위해 저자들은 하나의 실험을 진행하였습니다. [표5]는 이미지의 크기와 augmentation 정도를 달하며 실험했을 때의 accuracy를 나타낸 것으로 이미지의 크기가 작으면 약한 augmentation이, 크면 강한 augmentation이 더 좋은 결과를 보여주는 것을 확인할 수 있습니다.

이러한 결과를 저자들은 바탕으로 학습 도중 변화하는 이미지의 크기에 따라 유동적으로 regularization정도를 조절하는 improved progressive learning을 제안하였습니다.
Progressive Learning with adaptive Regularization
improved progressive learning의 process는 아래의 [그림4]와 같습니다. early epoch에서는 작은 이미지와 약한 regularization을 사용하고, 학습이 진행됨에 따라 점점 이미지의 크기와 regularization을 증가시키며 학습을 진행합니다.

EfficientNetV2는 세 가지의 regularization기법을 사용하였습니다. 먼저 뉴런의 일부를 학습 가능하지 않은 상태로 두는 dropout을 이용하였고, 이외에도 여러 이미지 왜곡 기법들을 임의로 선택하여 임의의 강도로 적용하는 RandAugment와 서로 다른 두 이미지를 mixup 비율에 따라 합치는 Mixup을 이용하였습니다.
Experiments
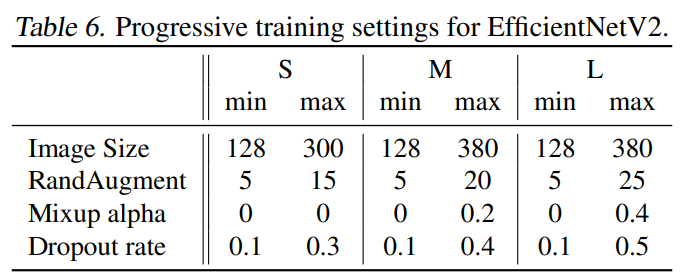
학습은 ImageNet-ILSVRC2012와 ImageNet21k로 진행되었으며 총 training epoch인 350을 네 단계로 나누어 87epoch마다 image의 크기와 regularization magnitude를 아래의 [표6]과 같이 조절하였다고 합니다.
Main Results
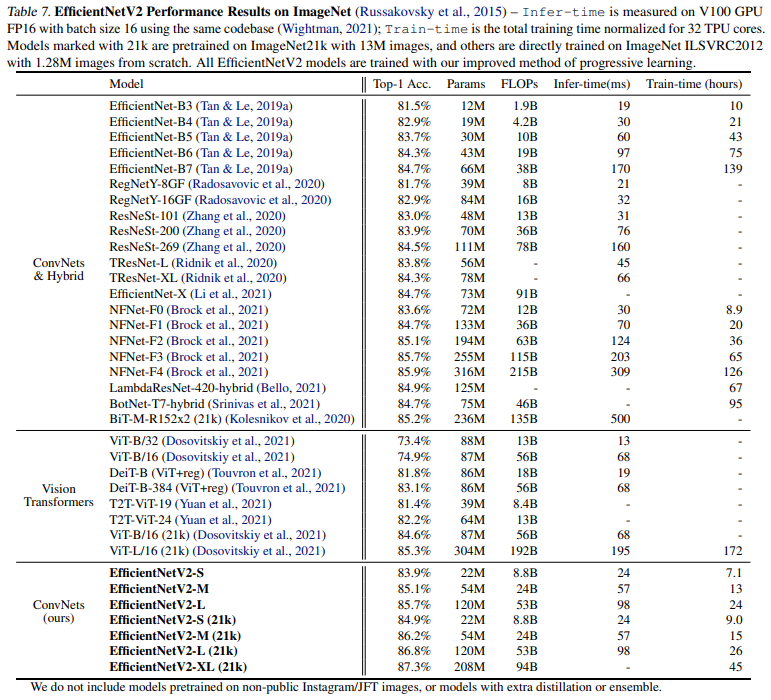
[표7]은 ImgeNet1k결과를 나타낸 것으로 EfficientNetV2와 기존 sota 모델과의 비교를 수행한 것을 볼 수 있습니다. EfficientNetV2가 기존 convolution, transformer기반의 모델보다 적은 training time을 보이며 특히 비슷한 accuracy인 EfficientNetV2-M과 EfficientNet-B7을 비교해보면 EfficientNetV2가 training time이 11배나 빠른 것을 확인할 수 있습니다.
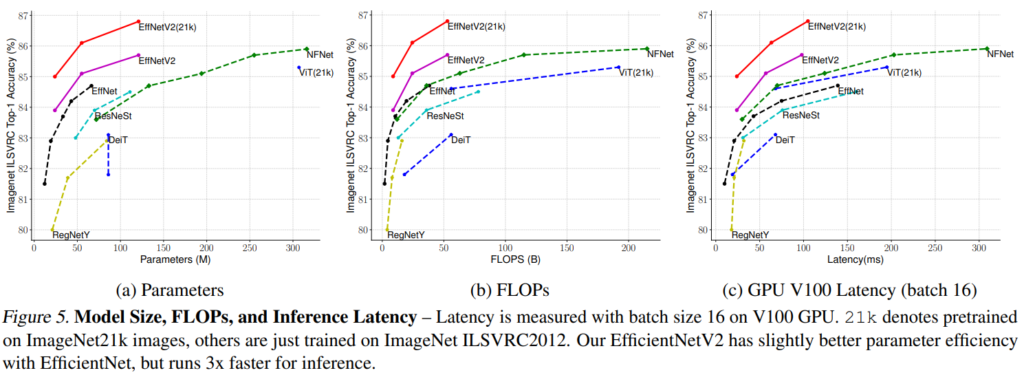
[그림5]는 EfficientNetV2의 parameter 수, 연산량(FLOPs), 그리고 latency를 다른 모델과 비교한 것입니다.
학습의 효율성 차원에서 최적화된 모델인 EfficientNet V2는 inference에서 발생하는 latency에서도 기존 EfficientNet V1의 1/3 수준으로 줄어든 것을 확인할 수 있습니다. .
Ablation Studies
Comparison to EfficientNet
EfficientNet V2의 구조적 우수성을 확인하기 위해, EfficientNetV2-M 모델과 EfficientNet-B7 모델을 동일한 조건에서 progressive learning with adaptive regularization을 적용하여 학습하고 그 결과를 비교하였습니다.
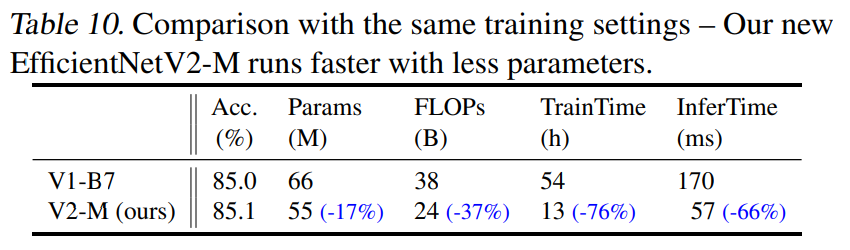
[그림 10]을 보면 EfficientNetV2의 구조를 사용했을 때, 모델 크기와 연산량 차원이 개선되었으며 training, inference time이 크게 감소한 것을 확인할 수 있습니다. 이를 통해 Fused-MBConv 블럭과 NAS로 탐색한 EfficientNetV2 구조의 우수성을 확인할 수 있습니다.
Progressive Learning for Different Networks
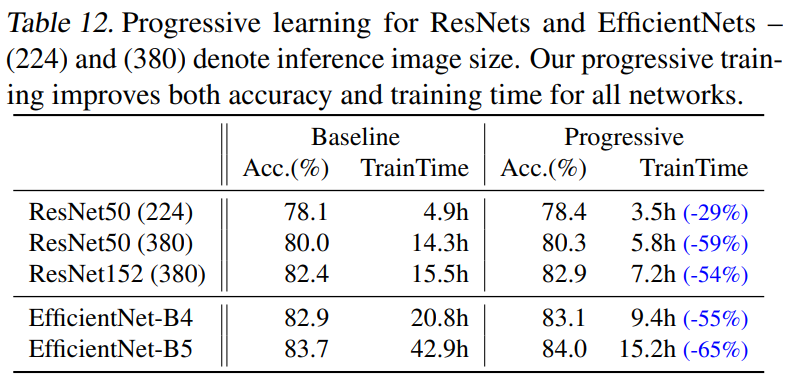
Progressive learning이 일반적인 경우에도 training efficiency를 확보할 수 있다는 것을 보여주기 위해, EfficientNetV2이외의 모델에 progressive learning을 적용하며 training time을 비교하였습니다. [표12]를 통해 Progressive learning을 사용한 경우 학습 시간이 크게 줄어든 것을 확인할 수 있습니다.
Importance of Adaptive Regularization
저자들은 마지막으로 이미지의 크기에 따라 regularization의 강도를 조절하는 adaptive regularization의 중요성 또한 실험을 통해 증명하였습니다. 일반적으로 augmentation을 위해 이용하는 random resizing과 이미지의 크기를 점차적으로 키우는 progressive resizing에 각각 adaptive regularization을 적용한 후 결과를 비교하였습니다.
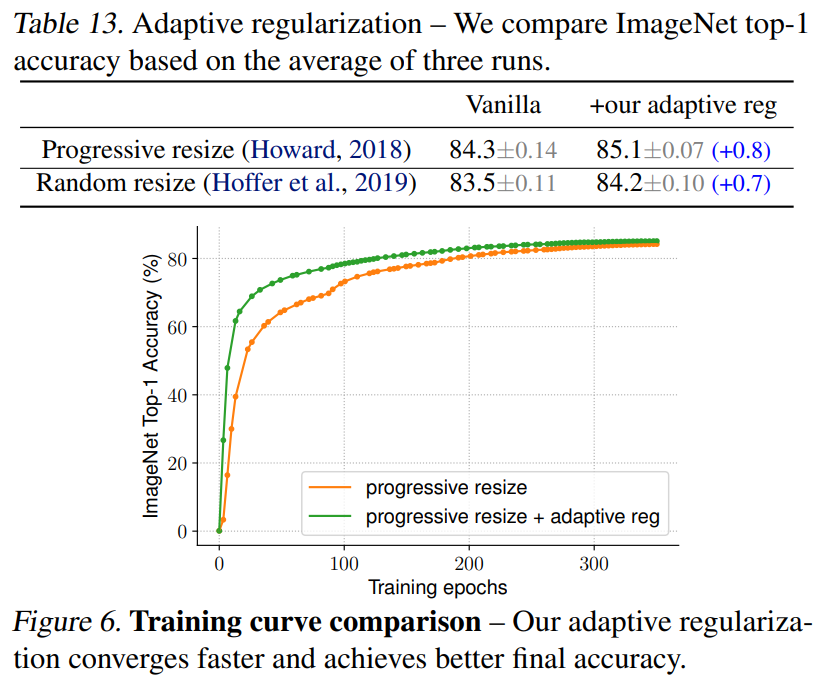
[표13]과 [그림6]을 통해 두 경우 모두 adaptive regularization을 적용했을 때의 정확도가 향상된 것을 확인할 수 있습니다. 결과적으로 progressive learning과 adaptive regularization을 동시에 사용하면, 학습의 정확도를 어느정도 유지한 채 효율성을 극대화시킬 수 있다는 것을 확인할 수 있습니다.
안녕하세요, 좋은 리뷰 감사합니다.
EfficientNetV2를 리뷰해보고 싶었는데, 강화학습 이야기도 나오고 해서 좀 어려웠던 기억이 있습니다.
설명하신 Progressive Learning 섹션에서
” 작은 크기의 이미지에서 큰 크기의 이미지의 순서로 학습이 진행되기 때문에, 처음에 쉬운 시각 정보를 먼저 학습하고 이후에 이를 바탕으로 어려운 시각 정보를 학습할 수 있어 모델이 더 빠르게 수렴하게 됩니다. ”
라고 설명을 해주신 부분이 있습니다.
1. 제가 알기로는 작은 이미지는 큰 이미지 보다 학습이 어려울 것 같은데 쉬운 시각 정보를 먼저 학습하도록 하는 설계가 있는 건가요?
2. 이미지의 작고 큰 기준은 표(5)를 기준으로 하는지 궁금합니다.
감사합니다.
1. 작은 크기의 이미지에 존재하는 ‘쉬운 시각 정보’라는 것은 학습이 쉽다는 의미는 아니고 이미지 분류에서 포괄적인 정보를 통해 이미지를 분류하는 것을 의미합니다. 원문에서는 ‘simple representation’이라 표현하였는데요, 예를 들어 자동차와 고양이 이미지를 분류하는 경우에는 작은 사이즈의 이미지가 가진 simple representation만으로 구분이 가능하지만 고양이의 종을 분류하기 위해서는 보다 큰 사이즈의 이미지를 사용하여 detail한 정보를 고려해야 하겠지요. 보다 자세한 설명은 해당 블로그를 참고하시면 좋을 것 같습니다.
2. 넵 맞습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
depthwise convolution이 일반적인 convolution에 비해 최신 accelerator에서 잘 동작하지 못하고 overhead가 발생하는 이유가 궁금한데, , , 이에 대한 구체적인 설명이 논문에 언급되어 있나요 ?
또 위의 overhead가 발생한다는 점을 보완하기 위해 depthwise 3×3 conv에서 3×3 conv연산을 전환한 fused MBconv block 실험 결과를 보면 parameter 수와 연산량은 많아졌지만 속도가 빨라졌다는 결과가 나왔는데 오히려 전부 Fused-MBConv로 교체하면 MBConv를 사용한 것보다 성능이 내려간 것을 볼 수 있습니다. 앞단만 Fused-MBConv를 사용했을 때 가장 성능이 좋은 이유는 무엇 때문인가요 ?
감사합니다 !
댓글 감사합니다.
– 논문에는 depthwise가 최신 가속기에를 잘 활용하지 못한다는 언급만 있고 구체적인 이유에 관한 언급은 없었습니다. 제 생각에는 사용되는 라이브러리와 생산되는 하드웨어 자체가 기존 conv 연산에 최적화되어 있어 Fused-MBConv가 좀더 잘 동작하는 것이 아닐까… 라고 생각합니다.
– [표4]를 보시면 뒤 stage로 갈수록 채널 수가 앞 부분에 비해 크게 증가한 것을 볼 수 있는데요, 이로 인해 뒷 레이어의 output feature의 채널 수 또한 증가함을 알 수 있습니다. 이러한 경우에는 오히려 일반적인 convolution의 연산량이 overhead가 발생한 depthwise convolution보다 크게 증가하게 되므로 모델 전체에 fused를 사용하는 것 보다 fused MBConv와 MBConv를 혼합하는 것이 더 좋은 성능을 낸 것이라고 이해하였습니다.
안녕하세요 좋은 리뷰 감사합니다.
궁금증이 있는데요. 왜 early layer에서 진행되는 depthwise convolution은 연산이 느린가요?? 제 생각에 depthwise convolution이 느리다면 early layer에서든 뒷단에 있는 layer에서든 둘다 느려야할 것 같은데 잘 이해가 가지 않습니다.
안녕하세요 댓글 감사합니다.
이 질문은 위의 정윤서 연구윈님의 두 번째 질문과 유사하여 해당 설명을 참고하시면 좋을 것 같습니다.
[표4]를 보시면 뒷부분의 레이어의 경우 채널 수가 크게 증가한 것을 확인할 수 있는데요, 이 경우 standard convolution보다 depthwise convolution의 연산 효율성이 더 커지기 때문에 Fused-MBConv보다 MBConv가 더 빠르게 동작한 것이라고 생각합니다.