제가 이번에 리뷰할 논문은 Coupled Iterative Refinement라는 논문입니다. 6D Pose Estimation 분야의 연구들을 살펴보고 있고, 그중 2022년 논문을 가져왔습니다. 6D pose는 pose를 추정한 뒤 추가로 refinement를 통해 예측 정확도를 높이는 방식으로, 해당 논문은 정밀도를 높이는 부분에 집중한 논문입니다.
Abstract
해당 논문은 6D multi-object pose를 예측하는 task를 다룹니다. RGB나 RGB-D 이미지가 주어질 경우, 6D Pose를 추정하는 것으로, 물체를 검출한 뒤, 각 객체의 pose를 추정합니다. 해당 방법론은 end-to-end의 미분 가능한 구조를 통해 기하학적 정보를 이용할 수 있도록 새로운 방식을 제안하였습니다. 해당 방법론은 pose와 correspondence를 반복적으로 refinement 하여 이상치를 동적으로 제거함으로써 정확도를 높일 수 있는 방식입니다. 또한, 미분 가능한 레이어를 통해 Bidirectional Depth-Augmented PerspectiveN-Point (BD-PnP)의 최적화 문제를 풀어 pose refinement를 수행하였고, 6D Pose Estimation 밴치마크에서 SOTA를 달성하였습니다.
Introduction
알려진 3D 형태(3D 모델 정보가 있다는 표현입니다)를 포함한 RGB나 RGBD 이미지가 주어질 경우, 6D Pose Estimation은 객체를 검출하고 객체의 pose를 추정합니다. 정확한 pose를 아는 것은, grasping 을 위한 정보를 제공할 수 있고, 객체의 pose를 기반으로 증강현실을 적용할 수 있는 등 어플리케이션 관점에서 중요합니다.
일반적으로 6D multi-object pose는 객체 인스턴스를 먼저 detect한 뒤, 각 객체의 pose를 추정합니다. 기존 연구는 3D 모델과 이미지 사이의 대응관계를 추정하여 2D-3D Correspondence를 생성한 뒤, PnP 알고리즘과 같이 반복적으로 수행하여 최적의 해를 찾는 알고리즘을 통해 pose를 추정하는 방식을 이용하였습니다. 그러나. 2D-3D correspondence로 6D Pose를 추정하는 방식은texture-less한 object의 경우 정확한 pose를 추정하기 어렵고, 실제 어플리케이션 관점에서 심한 occlusion, symmetric한 객체, 조명 변화에 대해서는 local feature를 찾아 matching을 하는 것이 거의 불가능하여 기존 시스템을 실세계에 적용하는 것은 어렵습니다.
이러한 이유로, 최근 많은 연구들이 딥러닝을 활용하여 문제를 해결하고자 하였으며, 간단한 방식은 6D Pose를 직접 regression으로 구하도록 네트워크를 학습합니다. 이러한 방식은 Direct 방식으로, 입력으로부터 바로 rotation과 translation을 추정하는 방식으로, 이미지가 3D 모델의 투영이라는 정보를 활용하지 않습니다.
딥러닝에 이미지와 3D 모델의 관계(3D 모델의 투영이 이미지라는 것)를 결합하기 위한 연구가 있고, 그중 한가지 방식은 3D object의 keypoint를 감지하도록 딥러닝 모델을 학습시켜 2D-3D correspondence 집합을 생성한 뒤, PnP solver를 이용해 pose를 추정하도록 합니다. 또다른 방식은 암시적으로 레이어에 기하학적 정보를 부여합니다. 이러한 연구들은 PnP가 end-to-end 방식으로 구현될 수 있음을 보였지만, 두 방식 모두 2D-3D 대응은 한번 구하고, PnP를 통해 pose를 추정하는 one-shot 방식이므로, 이상치와 오류에 민감하게 반응한다는 문제가 있습니다.
저자들은 이러한 기존 연구의 한계를 극복하기 위해 새로운 방식을 제안합니다. 우선 기하학적 지식을 이용할 수 있는 end-to-end의 미분 가능한 구조로 구성되며, 앞서 2D-3D 대응 관계를 한번 구하는 one-shot방식의 문제를 해결하기 위해 반복적으로 대응을 개선하여 동적으로 이상치를 제거하고 정확도를 향상시킬 수 있는 Coupled Iterative Refinement를 제안합니다.
본 논문의 방법론은 optical flow에서 사용되는 RAFT** 구조를 기반으로 구축되었다고 합니다. RAFT는 optical flow 알고리즘에 재귀적으로 오류를 최소화하도록 최적화를 진행한 방식을 추가한 방법론이라 합니다. 입력 이미지와 3D 물체를 렌더링 한 이미지 set 사이에서 flow를 추정하여 pose를 추정하기 위한 2D-3D correspondence를 생성하는 방식으로, RAFT 방식과 마찬가지로 GRU를 사용하여 반복적으로 poes를 업데이트합니다. flow와 pose 업데이트는 긴밀하게 결합되어있으며, flow는 현재 pose에 따라, pose는 flow에 따라 조건부로 업데이트를 수행하였다고 합니다. Pose를 업데이트하기 위해 저자들은 Bidirectional Depth-Augmented PnP (BD-PnP)라는 새로운 미분 가능한 레이어를 도입하였으며, 이에 관련한 내용은 Approach에서 다루도록 하겠습니다.
** Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. ECCV 2020
또한, 저자들은 6D Pose Estimation의 주요 밴치마크인 YCB-V, T-LESS, LineMode-Occlusion에서 SOTA를 달성하였다고 합니다.
Related work
Iterative Refinement
한번에 정확한 pose를 추정하는 것이 어렵기 때문에, 반복적으로 pose를추정하는 연구가 진행되었습니다. DeeIM 방식은 반복적으로 “rener-and-compare” 방식을 적용하여 3D 모델을 렌더링하여 이미지와 렌더링 이미지를 잘 맞추도록 pose 업데이트를 수행하였습니다. CosyPose는 모델 구조를 향상시키고, rotation을 파라미터화 하여 pose를 추정하였습니다.
저자들은 DeepIM 방식과 유사하게, 추정된 현재 pose를 사용하여 3D 모델을 다시 렌더링하는 방식을 포함하지만, pose를 업데이트 하는 것이 아니라 BD-PnP 레이어를 통해 기하학적 제약을 업데이트합니다. 특히, BD-PnP레이어는 현재의 flow 추정치를 기반으로 pose를 업데이트합니다.
또한, RAFT-3D는 장면의 flow를 맥락 관점에서 iterative refinement를 적용합니다. 본 연구도 optical flow refinement와 강체의 transformation을 반복적으로 업데이트합니다.
Approach
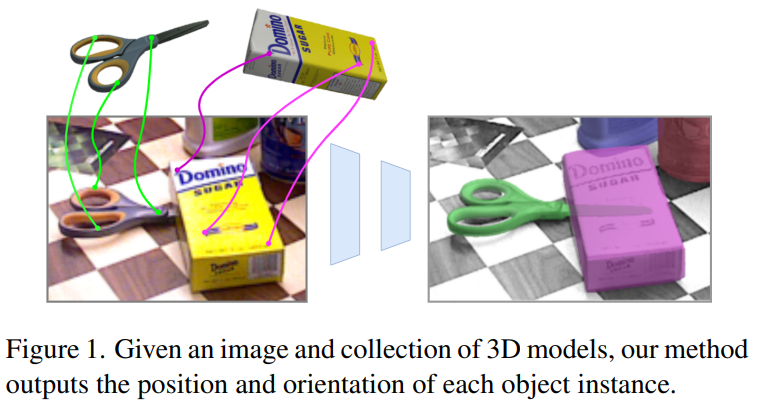
그림1에서 확인할 수 있듯이, 본 연구는 단일 이미지가 입력으로 들어왔을 때, 객체들의 pose를 추정하게 됩니다. 저자들은 RGB-D가 입력으로 들어온다고 가정하였으며, (1) 객체 탐지 (2) Pose 초기화 (3) Pose refinement 3단계로 구분합니다. 먼저 앞의 두 단계는 CosyPose의 방법을 따른다고 합니다. (이미지로부터 객체를 찾아 pose를 추정하는 단계는 기존 연구를 따랐다고 보시면 될 것 같고, 여기서 따른 기존연구인 CosyPose에 대해서는 추후에 리뷰로 다시 다뤄보도록 하겠습니다.. ) 해당 논문에서는 refinement를 어떻게 반복적으로수행하여 정확도를 올리는 지를 해결하는 것에 집중하였습니다.
Preliminaries
객체의 3D mesh 정보가 주어졌을 때, object를 여러 뷰포인트에서 렌더링하여 이미지와 depth map을 생성할 수 있으며, 아래의 식으로 intrinsic과 extrinsic 파라미터를 파라미터화 할 수 있습니다.
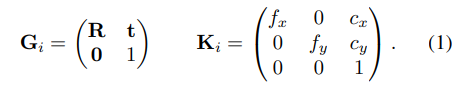
이때 \mathbf{G}_i는 카메라 좌표계에서의 개체의 pose를 나타내며 \mathbf{G}_0을 이미지의 pose, \{ \mathbf{G}_1, ..., \mathbf{G}_N \}을 여러 viewpoint에서 렌더링된 이미지의 pose라 하였을 때, 랜더링 포인트를 이미지의 포인트로 mapping하는 함수는 아래의 식(2),
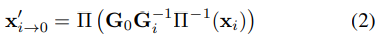
이미지에서 랜더링 포인트로 mapping하는 함수는 아래의 식(3)으로 정의할 수 있습니다.
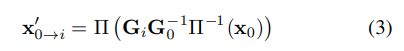
\Pi 및 \Pi ^{-1}는 이미지 좌표 뿐만 아니라 depth정보도 변환하는 depth-augmented pinhole projection 함수를 나타낸다고 합니다.
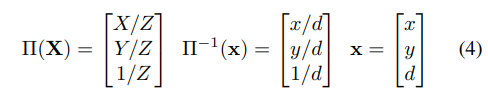
목표는 식(2)가 이미지와 렌더링 사이의 point를 정확하게 매핑할 수 있도록 하는 pose \mathbf{G}_0를 찾는 것입니다.
Object Candidate Detection
입력 이미지가 주어졌을 때, Mask-RCNN을 이용하여 인스턴스들을 감지하고, 관련 label을 생성합니다.(참고로 CosyPose의 Mask-RCNN 가중치를 그대로 사용하였다고 합니다.) 그다음, bounding box만큼 잘린 이미지와 segmentation 마스크, depth map을 생성한 뒤, 320×240의 크기가 되도록 조정하고 그에 따라 intrinsic도 조정하였다고 합니다.
Pose Initialization
detection을 적용한 뒤, 각 객체 후부에 대해 병렬적으로 다음 과정을 수행합니다. 먼저 초기 pose \mathbf{G}^{ (0) } 를 생성합니다. translation은 bounding box와 mesh object마스크를 정렬하여 mesh가 투영된 bounding box와 크기가 맞도록 하는 \mathbf{t}_{bbox}를 계산합니다. 그 다음, 추정된 translation을 이용하여 3D 모델을 렌더링하고, 렌더링 이미지를 crop 이미지와 concat합니다. concat된 데이터는 파라미터화를 통해 rotation을 예측하는 모 델의 입력으로 들어가 pose를 추정하게 되며, 최초 pose는 4×4 행렬로 나타낼 수 있습니다.
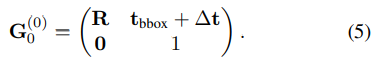
Feature Extraction and Correlation
초기 pose가 주어지면 각 축에 대해 ±22.5° 회전시켜 7개의 view-point에 대한 렌더링을 수행합니다. 각 렌더링과 crop된 이미지 사이의 양방향의 dense한 correspondence를 예측하며, 각 랜더링의 object pose는 알고있으므로, 이미지의 객체의 pose를 추정해야합니다.
모든 N개의 렌더링ㄹ으로부터 dense한 {H\over{4}} ⨉ {W \over{4} } feature map을 추출하고, 동일 가중치를 이용하여 crop된 이미지로부터 feature를 추출합니다. 추출된 두 feature를 이용하여 이미지와 렌더링 쌍에 대해 양방향으로 correlation volume을 구축합니다. 이때 correlation volume은 두 feature vector쌍 사이의 요소곱을 적용하여 계산하며, 각 correlation volume은 마지막 두 차원을 pooling하여 4-level의 correlation 피라미드를 생성합니다.
Coupled Iterative Refinemenet
GRU 기반의 업데이트 연산자를 이용하여 pose 추정치에 대한 업데이트 sequence를 생성하며 각 반복마다 hidden state도 업데이트합니다. 참고로 GRU는 LSTM을 발전시킨 방법으로, LSTM보다는 더 간단한 구조를 가지는 방식입니다.
\mathbf{G}를 모든 pose의 집합이라 할 때, 렌더링 pose는 고정되지만 이미지의 pose인 \mathbf{G}_0는 변수로, 반복적인 refinement를 \mathbf{G}_0를 구하는 것입니다. correspondence field \mathbf{x}_{i→0}를 구하기 위해 식(2)를 이용하였으며, \mathbf{x}_{0→i}를 구하기 위해 식(3)을 활용합니다. correspondence field \mathbf{x}_{i→0} ∈\mathbb{R}^{H⨉W⨉3}는 렌더링 i의 모든 픽셀이 2D 이미지에서의 위치를 알려주며, correspondence field가 inverse depth로 증강됩니다.
Correlation Lookup
RAFT에서 정의된 lookup 연산자를 이용하여, 해당하는 correlation pyramid의 인덱싱을 구하기 위해 \mathbf{x}_{i→0}를 사용합니다. lookup 연산자는 각 포인트로부터 반경 r이 되도록 local 그리드를 구성하고, 이 그리드를 이용하여 correlation pyramid의 각 level에서 인덱스를 생성하여 총 L개의 correlation feature를 생성합니다. lookup 연산자의 결과는 correlation feature의 map \mathbf{s}_{i→0}∈\mathbb{R}^{H⨉W⨉L}으로 이와 유사하게 \mathbf{x}_{0→i}를 이용하여 correlation feature인 \mathbf{s}_{0→i}∈\mathbb{R}^{H⨉W⨉L}를 생성합니다.
GRU Update
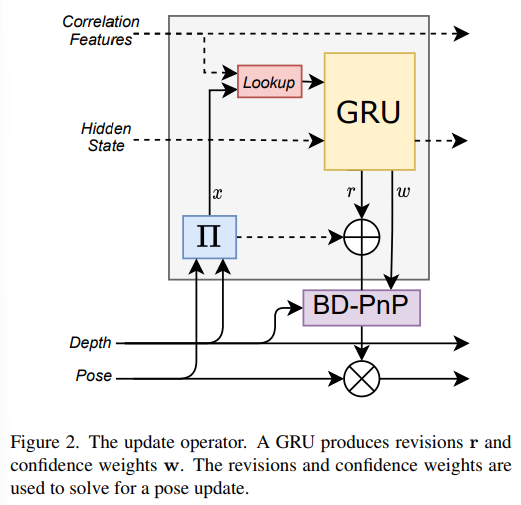
각 image-render 쌍에 대해서 correlation features \mathbf{s}_{i→0}와 hidden state \mathbf{h}_{i→0}가 context feature와 depth feature와 함께 3×3 convolution GRU의 입력으로 들어가 다음 3가지를 출력으로 반환합니다 :(1) 새로운 hidden state, (2) 각 dense correspondence fields에 대한 revision \mathbf{r}_{i→0}∈\mathbb{R}^{H⨉W⨉3} (3) 예측된 revision에 대한 dense한 confidence \mathbf{w}_{i→0} map.
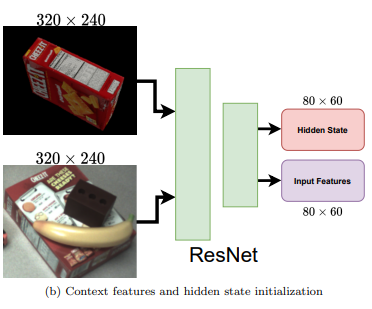
- Context Featue: 이때 context feature는 Resnet기반의 feature extractor를 이용하며, 모든 이미지에 대한 context feautre와 초기 hiddenstate를 생성합니다. 여기서 구한 hidden state는 GRU를 통해 업데이트되지만, context feature는 그대로 유지됩니다.
- Depth feature: 이미지 pair (i,0)에 대해 inverse-depth map인 \mathbf{z}_{i}^{-1}, \mathbf{z}_-^{-1}를 가지고 있고, \mathbf{x}_{i→0}를 이용하여 invers-depth map \mathbf{z}_{i→0}^{-1}를 구하고, (\mathbf{z}_{0}^{-1}, \mathbf{z}_{i→0}^{-1}) 를 GRU에 입력으로 넣어 depth가 얼마나 잘 정렬되었는지를 알 수 있도록 한다고 합니다.
revision \mathbf{r}_{i→0}은 현재 pose 추정치로부터 생성된 correspondence에 적용해야하는 dense한 correction map의 새로운 flow를 나타냅니다. 이때 \mathbf{r}_{i→0}는 2D 좌표에 대한 correction 뿐만 아니라 inverse-depth에 대한 correction도 포함합니다. depth에 대한 correction을 포함하여 깊이 센서에 노이즈가 있거나 해당 포인트가 가려지는 경우에 보정을 할 때 사용합니다. 즉, 해당 과정은 2D 좌표와 depth의 correction map을 통해 수정할 수 있도록 하는 것으로 이해하면 될 것 같습니다.
또한, image-render 쌍에 대해 반대 방향(0→i)으로도 적용하여 correlation feature\mathbf{s}_{0→i}를 이용한 revision \mathbf{r}_{0→i}과 confidence map \mathbf{w}_{0→i}을 생성합니다.
Bidirectional Depth-Augmented PnP(BD-PnP)
BD-PnP 레이어는 예측된 revision \mathbf{r}과 confidence \mathbf{w}를 카메라 pose를 업데이트 \Delta \mathbf{G_0}로 변환합니다.
먼저, revision을 더하여 correspondence fields를 업데이트합니다.
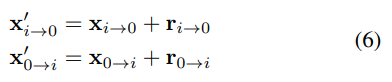
다음으로 수정된 correspondence와 재투영된 좌표의 disdtance가 줄어들도록 아래와 같이 loss 함수를 정의합니다.
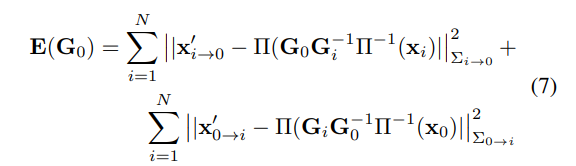
이때 ||·||_{\Sigma}는 마할라노비스 distancve를 나타내고 \Sigma_{i→0}=diag \mathbf{w}_{i→0} (diag는 대각선 요소로, confidence의 대각선에 해당하는 요소들을 모두 더한 것을 의미합니다.)가 됩니다. 식(7)의 목표는 reprojection된 포인트가 수정된 correspondence \mathbf{x}'_{ij}와 일치하도록 하는 카메라 pose \mathbf{G_0}를 구하는 것으로, reprojection 오류를 최적화하는 것이므로 기존의 PnP와 유사합니다. 그러나 하나의 2D-3D correspondences를 최적화하는 기존 PnP와는 다르게 렌더링과 이미지 각각에 대해 구한 2 세트의 correspondences를 최적화하는 것으로 양방향으로 작동하며, inverse-depth도 오차에 포함합니다. 이를 통해 보다 정확한 pose를 예측할 수 있었다고 합니다.
저자들은 고정된 횟수(학습시 3번, inference시 10번)의 Gauss-Netwon 업데이트를 수행하여 pose를 추정하였다고 합니다.
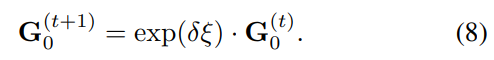
Inner and Outer Update Loops
주어진 렌더링 세트에 대해 update 연산자는 40회 반복하여 실행하였다고 합니다. 이후 개선되 pose 추정치를 이용하여 7개의 viewpoint로 구성된 새로운 set을 다시 렌더링하여 이 과정을 반복하였다고 합니다. 저자들은 실험을 통해 inner와 outer 업데이트를 반복하는 횟수를 늘릴수록 정확도가 높아지고 당연하게도 속도는 줄어드는 것을 확인하였습니다.
Experiments
Evaluation Metrics
BOP challenge(6D Pose Estimation을 위한 challenge)의 밴치마크 평가 방식을 따라 Recall성능을 타나내었으며, 세부적으로 Maximum Symmetry-Aware Surface Distance (MSSD) Recall, Maximum Symmetry-Aware Projection Distance (MSPD) Recall, Visible Surface Discrepancy (VSD) Recall 3가지 항목과 이 3가지 recall의 평균을 평가지표로 이용하였습니다. 아래의 세가지 기준으로 오차 거리를 측정한 뒤, threshold를 기준으로 recall을 계산하여 0~1 사이의 값으로 나타냅니다.
- MSSD(Maximum Symmetry-Aware Surface Distance)
예측 pose와 GT Pose에 연결된 mesh들의 point사이의 거리 중 최대 유클리드 거리 - MSPD(Maximum Symmetry-Aware Projection Distance)
예측 pose와 GT Pose에 연결된 모든 point 사이의 최대 re-projection오차 - VSD(Visible Surface Discrepancy)
예측 pose와 GT Pose에서 렌더링된 Mesh 사이의 depth 불일치로, 모델의 모든 point가 아닌, 이미지에서 보이는 픽셀에 대해서 측정됨
Dataset
여러 instance가 포함된 단일 RGB-D 이미지로 구성된 6D Pose Estimation 밴치마크를 이용합니다. BOP Challenge에 있는 YCB-V, T-LESS, LM-O데이터를 이용하였습니다.
- YCB-V
textuer와 색상이 있는 21개의 가정용 객체로 구성 - T-LESS
textuer와 색상이 거의 없는 30개의 유사한 산업 관련 객체로 구성 - LM-O
textuer가 없고 색상이 있는 15개의 가정용 객체로 구성
900개의 YCB-V 테스트 이미지, 1000개의 T-LESS 테스트 이미지, 200개의 LinemodOccluded 테스트 이미지를 이용하였고 각 이미지는 3~8개의 object가 포함되어있습니다.
BOP Benchmark Results
- RGB-D Results
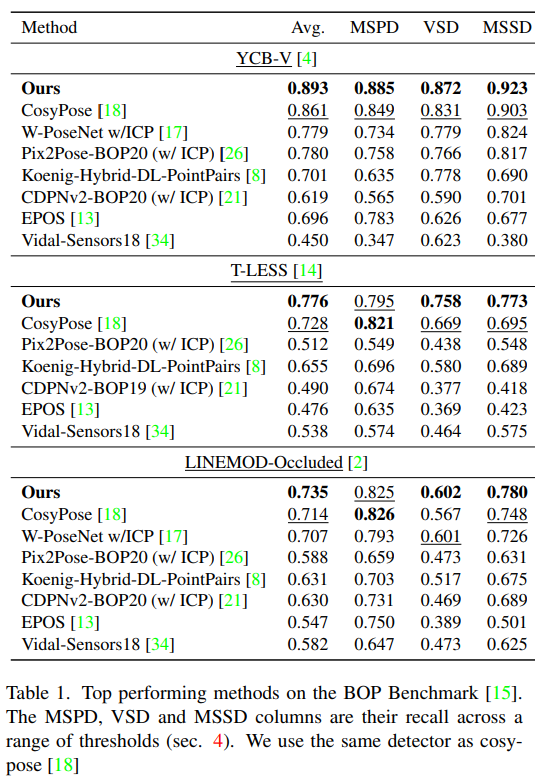
기존 연구의 경우 ICP(6D에서 많이 사용하는 refinemente 방식)를 사용하거나 안 한 것 중 가장 좋은 성능을 나타내는 것들을 리포팅하였고, 저자들은 ICP를 이용하지 않았다고 합니다. Table1을 통해 모든 데이터셋에서 해당 논문이 잘 작동하는 것을 확인할 수 있습니다.
- RGB Only Results
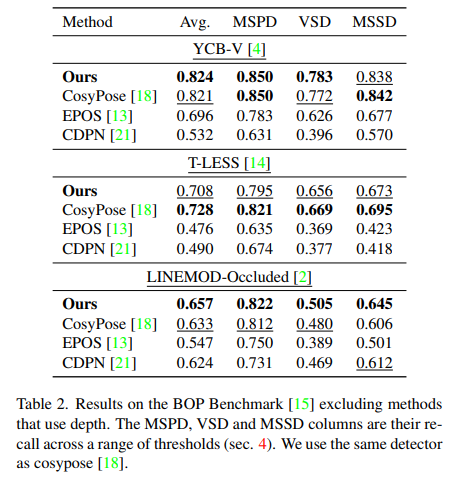
YCB-V와 LM-O에 대해서 뛰어난 성능을 보이고 T-LESS의 경우 성능이 CosyPose보다는 낮은 성능을 보였지만 다른 방법론에 비해서는 상당히 좋은 성능을 보였습니다. CosyPose보다 낮은 성능을 보이는 이유에 대한 설명이 없어 아쉽습니다.
Ablation Experiments
RGB-D 세팅에서 ablation study를 수행하였습니다.
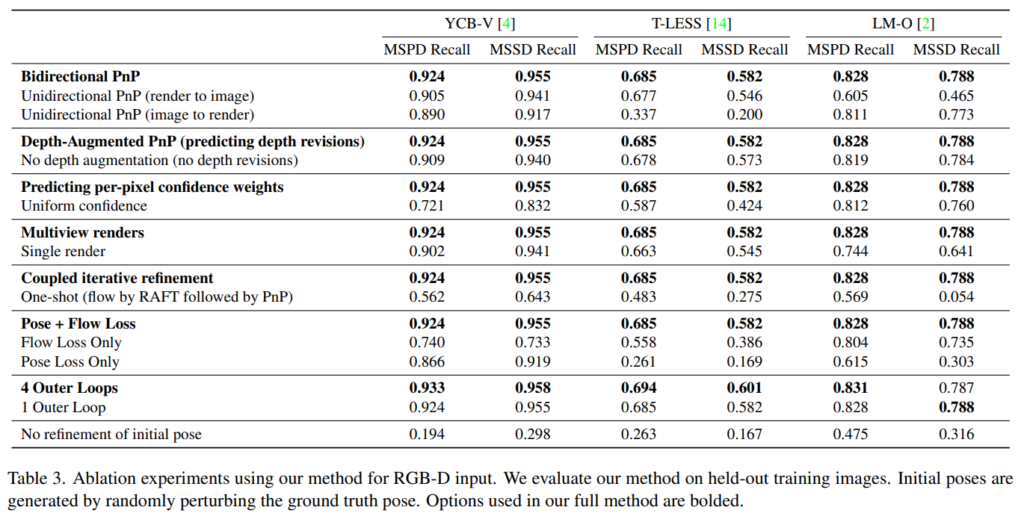
Table3을 통해 결과를 확인할 수 있습니다. 대부분의 모든 요소들이 모든 데이터셋에서 유효성을 보였습니다.
Speed vs Accuracy Trade-off
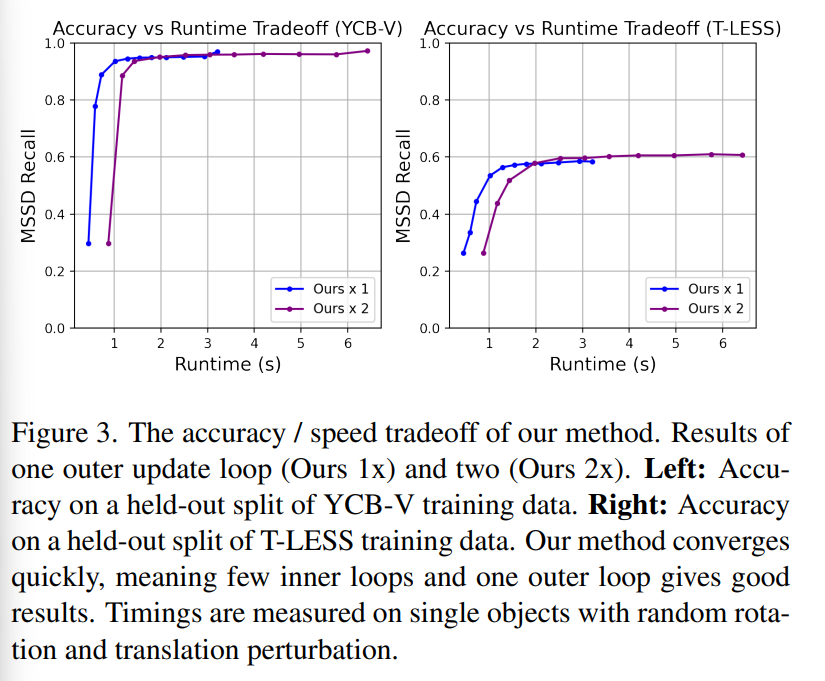
위의 Figure3은 속도와 정확도의 trade-off 관계를 나타낸 것입니다. outer loop 1개와 2개에 대해 실험을 하였고, 해당 실험을 통해 outer loop가 1개만 있어도 빠르게 수렴이 가능하다는 것을 확인하였습니다.
Robustness
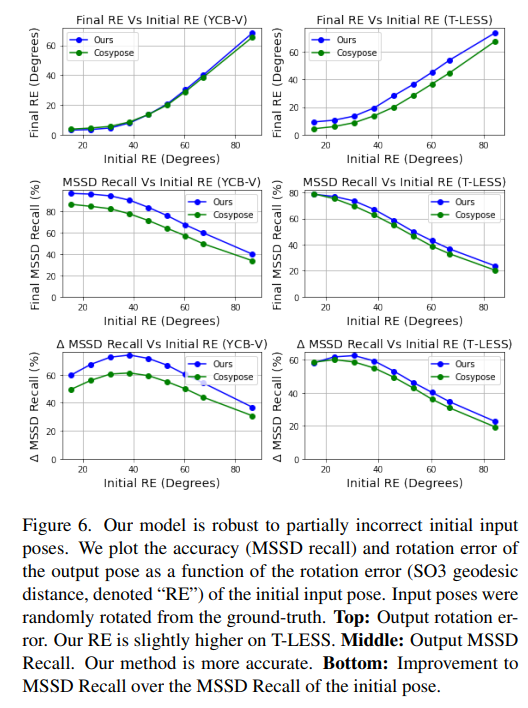
부정확한 초기 pose 추정에 대한 강인성을 평가하기 위한 실험 결과는 Figure6을 통해 확인할 수 있습니다. 저자들은 CosyPose를 베이스라인으로 하여 초기 pose를 추정한 뒤, refinement 부분을 제안하였습니다. 따라서 CosyPose와의 비교를 통해 초기 pose보다 정확도가 얼마나 증가하였는지 확인할 수 있습니다.
6D Pose Estimation 중 refinement 부분에 대한 개선 방식을 제안한 논문으로, 학습을 통해 refinement를 수행하여 보다 정확한 pose를 예측할 수 있도록 하였습니다. 그러나 실제 application 관점에서는 real-time이 어렵지 않을까 합니다.
안녕하세요, 좋은 리뷰 감사합니다.
기존의 LSTM 모델에 대해 개선을 한 GRU는 파라미터가 적어 computational cost 대비 적으면서 속도가 빠른 장점이 있다는 것을 알게되었습니다.
1. Correlation Lookup에서 사용하는 Lookup이라는 연산자는 cosine similarity와 같은 방법을 사용하여 correlation을 계산하는 건가요??
2. 식(8)의 exponential term의 의미가 궁금합니다.
감사합니다.
리뷰 읽어주셔서 감사합니다.
1. Lookup 연산자는 RAFT라는 optical flow 연구에서 제안된 것으로 RAFT는 입력된 RGB쌍으로부터
(1) Feature Extraction→(2) Visual Similarity→Iterative Updates 3단계를 거쳐 optical flow를 계산합니다.
correlation lookup은 Visual Similarity를 계산하는 단계에서 제안된 것으로 flow의 출발과 도착점에 대한 정보를 함축적으로 담고있는 부분이라 합니다.
작동 방식은 위에서 설명드렸듯이 각 포인트로부터 반경 r이 되도록 local 그리드를 구성하고, 이 그리드를 이용하여 correlation pyramid의 각 level에서 인덱스를 생성하여 총 L개의 correlation feature를 생성합니다.
즉, 이미지에서 렌더링 이미지, 렌더링 이미지에서 이미지로의 flow feature를 생성한 것으로 보입니다.
2. 또한 식 (8)은 Gauss-Newton 업데이트 방식을 이용하여 현재 pose 추정치를 update를 수행하는 과정으로 δξ∈se(3)입니다. 참고로 se(3)은 SE(3)군의 Lie algebra로, 4×4 크기의 행렬로 정의되며, rotation과 translation과 관련된 6개의 생성자들의 선형결합으로 se(3)의 각 원소를 표현할 수 있습니다. ξ는 3차원 공간상에서 물체의 속도를 의미하는 twist이며 여기에 exponential 연산자를 활용하면 SE(3)으로 매핑이 가능하다고 합니다.
(?참고 링크: https://alida.tistory.com/9 )
좋은 리뷰 감사합니다.
논문을 이해하는데에 있어 이해하기 어려운 부분이 있어 몇 가지 질문드립니다.
1. Pose Initialization에서 G_0를 정의할 때, 4×4 행렬이라고 말씀해주셨습니다. 근데 여기서 bbox에 대한 translation을 활용하는 것 같은데 차원이 어떻게 적용되는지 이해가 되지 않네요. t_bbox가 의미하는 정보가 무엇인지 조금 더 자세한 설명 부탁드리겠습니다.
2. Feature Extraction and Correlation에서 일정 각도 간격으로 렌더링을 수행한다는 의미가 단일 영상으로부터 각도를 틀었을 때의 뷰 포인트를 생성하는 것인가요? 아님 주어진 데이터가 그렇다는 건가요? 만약에 생성하는 거면 이에 대한 정성적인 결과물이 있는지 궁금합니다. 그리고 여기서 말하는 object는 cad model를 칭하는 것이 맞는거죠?
3. 그럼 해당 기법은 렌더링을 여러 방향으로 돌려서 가장 유사한 i번째를 한번에 찾는 것이 목적인 것 같은데… 한방향으로 회전시킨 렌더링 정보로만으로 충분한지 궁금하네요. 아니면 여러 방향으로 생성하는 걸까요?
리뷰를 읽어주셔서 감사합니다.
1. 우선 Pose Initialization 과정은 detection 모델(여기서는 Mask-RCNN)로부터 예측된 boudning box와 3D 모델을 2D로 투영시켜 bounding box의 이미지의 크기가 같아지도록 하는 translation 값이 t_bbox에 해당합니다.
즉, t_bbox는 bounding box와 3D 모델을 투영시킨 이미지의 크기를 맞추는 과정입니다.
또한 차원에 대해서는 최초 pose인 G^(0)_0은 4×4 행렬이고, R은 3×3, t_bbox +△t는 3×1, 0는 1×3, 1은 1×1입니다.
2. 초기 pose에 대해 x,y,z축으로 ±22.5° 회전시켜 6개의 렌더링 이미지와 1개의 원본 이미지 즉, 7개의 view-point에서 물체를 바라본 이미지를 만들어냅니다. 또한, 렌더링 이미지에 대한 정성적 결과물은 논문의 figure 7에서 확인하실 수 있습니다.(각 입력 이미지에 대해 하나의 렌더링 이미지를 나타낸 것으로, 6가지 방향으로 렌더링한 모든 이미지를 모아둔 결과는 확인이 안됩니다.)
논문 링크: https://openaccess.thecvf.com/content/CVPR2022/papers/Lipson_Coupled_Iterative_Refinement_for_6D_Multi-Object_Pose_Estimation_CVPR_2022_paper.pdf
3. 제가 이해하기로는 가장 유사한 렌더링 이미지를 찾는다기보다 이미지로부터 예측된 pose를 정밀화 하기 위해 여러 렌더링 이미지를 활용한 것으로 보입니다. 즉, 입력 이미지의 pose인 G_0를 정밀하게 예측하기 위해 입력 이미지와 6개의 렌더링 이미지를 매칭하는 과정을 반복하는 방법론입니다.