안녕하세요, 금주의 X-Review에서는 Self-Supervised Video Representation Learning 방법론을 소개해드리고자 합니다. 해당 논문은 <Learning From Untrimmed Videos: Self-Supervised Video Representation Learning With Hierarchical Consistency> (HiCo)라는 제목으로 22년도 CVPR에 게재되었습니다.
본 논문에 대한 리뷰는 이전에 조원, 임근택 연구원님께서 다루신 적이 있지만 HiCo를 이번 년도 ETRI 과제의 베이스라인으로 삼게 될 확률이 높아 저도 자세히 읽어보고 다시 한 번 리뷰하게 되었습니다.
Video representation learning의 사전학습이, 대용량이지만 trimmed video 데이터 셋인 Kinetics만을 대상으로 이루어지던 상황 속에서 처음으로 pretrain 시 untrimmed video를 적절하게 활용할 수 있는 방법론을 제시한 논문입니다.

본 논문에서 수행하는 task인 Self-supervised video representation learning의 목적은, 비디오의 추가 annotation을 활용하지 않고 visual 정보만을 통해 표현력 좋은 backbone network를 학습시키는 것에 있습니다. 비디오에 내재된 정보를 효과적으로 모델링하여 목적에 맞는 loss를 설정하고, 이를 통해 backbone network가 비디오를 잘 표현하는 feature를 추출해내도록 학습시키는 프레임워크를 제안하는 것입니다.
이후에는 학습을 마친 backbone network가 좋은 표현력을 가지고 있는지 평가해보아야겠죠. 이는 backbone을 고정시키고 추출한 feature를 이용해 video recognition(classification), temporal action localization, video retrieval의 기본적인 downstream task의 성능으로 판단하게 됩니다. 물론 각 task를 수행하기 위해 모델 마지막에 FC layer를 붙여 평가 데이터 셋의 학습 데이터에 대한 fine-tuning하는 과정도 필요합니다.
만약 3가지 task 모두에서 다른 방법론들보다 좋은 성능을 보여준다면 저자의 프레임워크를 따라 학습한 backbone이 상대적으로 더욱 일반성을 갖는, 즉 좋은 feature를 추출할 수 있게 되었다고 볼 수 있을 것입니다.
더욱 자세한 내용은 논문과 함께 이어가겠습니다.
1. Introduction
Self-supervised learning은 데이터의 라벨이 없는 채로 학습함에도 불구하고 놀라울정도로 높은 성능을 보여주며 컴퓨터 비전 분야에서 각광받고 있는 추세입니다. 이미지 분야에서 뿐만 아니라 비디오 분야에서도 마찬가지인데, 비디오의 특성을 생각해보았을 때 대용량 비디오 데이터 셋에 대한 개별적 video-level annotation이나 temporal annotation을 부여하기엔 이미지보다 훨씬 더 많은 시간적, 경제적 비용이 수반되게 됩니다.
그렇기 때문에 비디오 분야에서도 더더욱 self-supervised learning의 중요성이 강조되며 다양한 연구가 진행되고 있고, 본 연구도 이러한 흐름에 맞춰 Self-Supervised Video Representation Learning(SSVRL) 방법론 HiCo를 제안하게 됩니다.
이 당시의 SSVRL SOTA 방법론들은 기본적으로 영상 분야의 SSL 프레임워크를 비디오 레벨로 올려 가져다 쓰는 방식으로 이루어졌습니다. 즉 같은 비디오로부터 얻은 클립을 positive 샘플, 다른 비디오로부터 얻은 클립을 negative 샘플로 두고 contrastive learning을 수행하여 구별력을 갖는 feature를 만들도록 학습하는 것이었습니다.
SOTA 방법론들이 이러한 방식을 기본 프레임워크로 두고 여러가지 추가 모듈이 붙어 좋은 성능을 내고 있던 상황입니다. 하지만 저자는 대부분의 이전 방법론이 사람이 직접 편집한 trimmed video를 대상으로만 잘 pretrain 되는 방식이라는 문제점을 지적합니다.
우선 trimmed video와 untrimmed video의 차이는 아래 그림 1을 통해 쉽 이해할 수 있습니다.
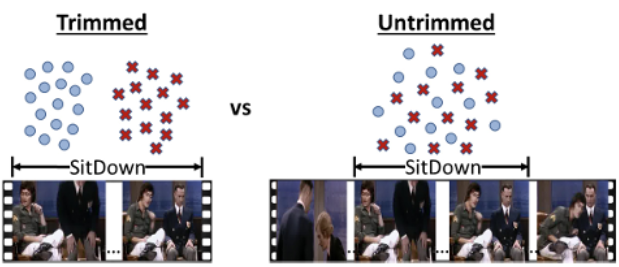
오른쪽 untrimmed가 원본 영상이고 중간에 ‘앉기’ action을 취하는 장면을 포함하고 있다면, 왼쪽의 trimmed는 ‘앉기’ 장면만 사람이 직접 편집한 상대적으로 길이가 짧은 비디오에 해당합니다. 이렇게 untrimmed video로부터 action이 발생하는 구간만 떼어낸 trimmed video는 ‘앉기’라는 하나의 주제를 가진, 편집된 짧은 비디오가 되겠죠.
엄청나게 많은 개수의 비디오에 대해 trimming 과정을 거치는 것은 여러모로 cost가 크기도 하고, 이 과정에서 데이터에 특정 human bias가 주입될 수도 있습니다. 따라서 저자는 상대적으로 얻기 쉬운 untrimmed video를 pretrain에 활용할 수 있는 video representation learning 방법론을 제안합니다. 또한 이는 편집되지 않은 비디오이기 때문에 방법론을 잘 설계해준다면 오히려 풍부하고 다양한 정보를 얻어낼 수도 있을 것입니다.
여기까지 읽는 동안 궁금한 점이 하나 생기셨을 수도 있는데요. 기존의 SSVRL 방법론들이 untrimmed video를 pretrain에 사용하는 것은 안될까요? 이에 대해 저자는 하나의 분석을 제시합니다.
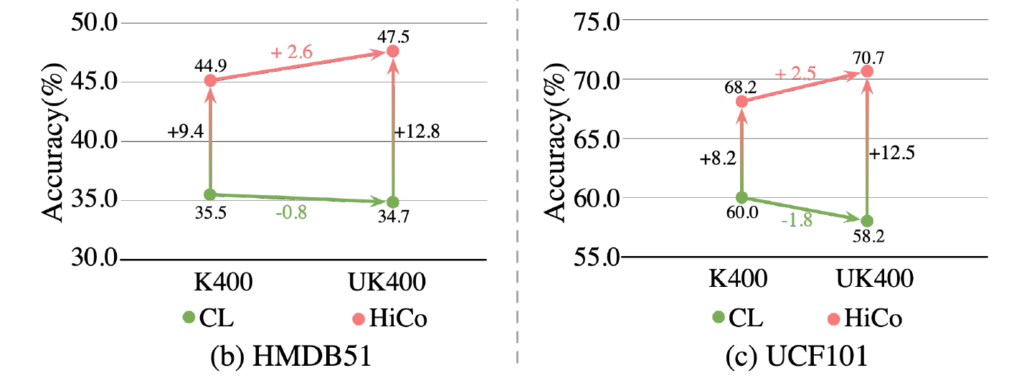
우선 그림 2는 trimmed video 데이터 셋인 K400과 untrimmed video 데이터 셋인 UK400으로 각각 pretrain 후 Action classification에 대한 정확도 성능입니다. 초록색 점인 CL은 trimmed video만을 다루던 기존 방법론들이고, 분홍색 점이 저자가 untrimmed video를 pretrain에 활용할 수 있도록 제안한 방법론 HiCo입니다.
성능을 보면 trimmed이든 untrimmed이든 기본적으로 기존 방법론에 비해 HiCo가 높은 정확도를 보이는 것을 알 수 있습니다. 주목할 점은, 기존 방법론인 CL의 성능이 K400으로 pretrain하는 것보다 UK400으로 pretrain하는 경우 오히려 떨어진다는 것입니다. 이것은 곧 기존 방법론의 Contrastive Learning 방식을 하나의 비디오 내에 다양한 콘텐츠를 포함하는 untrimmed video에 적용하는 경우 오히려 표현력에 저해를 일으킨다는 것을 의미합니다.
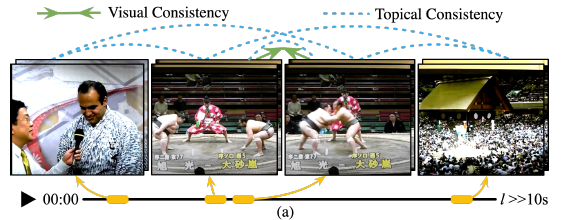
저자는 이에 대해 trimmed video를 pretrain에 사용하는 기존 방법론들에는 temporally-persistent hypothesis라는 가정이 깔려있기 때문이라고 주장합니다. 이는 하나의 비디오 내에 시각적으로 유사한 장면들만 등장할 것이라는 가정입니다. 이를 바탕으로 같은 비디오 내 두 클립의 representation을 서로 유사하게 만들어주었던 것이었습니다.
하지만 untrimmed video의 경우 위 그림 3처럼 시각적으로 유사하지 않은 장면들이 많이 등장하는 것을 볼 수 있습니다. 이렇게 시각적으로 다른 장면을 같은 비디오에 속한다는 이유만으로 서로 유사한 representation을 갖도록 학습하는 것이, 오히려 성능 측면에서 부정적으로 작용하였다는 것입니다.
이제 왜 pretrain 데이터 셋이 trimmed video로 구성되는지, untrimmed video로 구성되는지에 따라 다른 전략을 취해야하는지에 대한 설명은 이해가 되셨을 것입니다. 그러면 지금부터는 저자가 제안하는 학습 방식에 대해 알아보겠습니다.
앞서 이야기한 흐름에 따르면 untrimmed video는 temporally-persistent hypothesis가 성립하지 않기 때문에 이에 대처할 수 있는 방식이 도입되어야 할 것입니다. 저자는 그림 3과 같은 untrimmed video를 관찰하며 두 가지 consistency를 가정하게 됩니다. 첫 번째는 그림 3 위의 초록색 화살표와 같이 가까운 클립 간 visual consistency이고, 두 번째는 멀지만 한 비디오 내에 있는 클립 간의 topical consistency입니다. 특히 topical consistency는 비디오 내 모든 클립 간에 성립하는 것을 볼 수 있습니다.
사실 untrimmed video야 말로 길이가 길고 너무나도 다양한 컨텐츠를 포함하고 있기 때문에 비디오 내에서 핵심적으로 표현해야 할 구간과 그리 중요하지 않은 구간의 특성을 명시적으로 모델링하기가 힘듭니다. 이렇듯 모든 비디오 샘플에 통용되는 명시적 모델링을 수행할 수 없기 때문에, 저자는 특정 클립을 기준으로 temporal distance가 가까운 클립은 visual consistency와 topical consistency가 보장되고, 비디오 내 임의의 거리의 어떤 두 클립이든 topical consistency가 보장된다는 가정을 깔고 이를 이용한 학습 방식을 제안합니다. 또한 방금 말한대로 두 클립 간 거리에 따라 보장되는 consistency끼리의 계층이 존재하기 때문에 저자가 제안하는 방식을 HiCo (Hierarchical Consistency)라고 부르겠습니다.
논문의 Contribution을 정리한 후 HiCo 방법론을 자세히 알아보겠습니다.
Contribution
- By exploiting the hierarchical consistencies existing in untrimmed videos(the visual consistency and the topical consistency), HiCo learning can leverage the more abundant semantic patterns in natural videos.
- Visually consistent learning(VCL), apply standard contrastive learning on clips with a small maximum temporal distance, and encourage temporally-invariant representations.
- Temporally consistent learning(TCL), propose a topic prediction task, instead of a strict invariant mapping, the representations are only required to group difference topics. Considering the hierarchical nature of consistencies, we also include visually consistent pairs in TCL, while exclude topically consistenct pairs for VCL.
- We further introduce a gradual sampling that gradually increases the training difficulty for postivie pairs to help optimization and improve generalization.
2. Hierarchical Consistency Learning
Untrimmed video에서 추출한 두 클립의 temporal distance에 따라 두 가지 consistency의 보장 여부가 달라졌었습니다. 두 클립의 거리가 가깝다면 사실 상 trimmed video에서 샘플링한 두 클립이라고 봐도 무방할정도로 visual consistency와 topical consistency가 보장되며 임의로 두 개의 클립을 샘플링하는 경우 한 비디오 내에 속한다는 공통점만 존재하므로 visual consistency는 보장될 수도, 되지 않을 수도 있지만 topical consistency는 보장됩니다.
Visual consistency와 topical consistency가 보장되는 가까운 클립 쌍을 학습하는 VCL(Visual Consistency Learning) 모듈은 기존 trimmed video를 대상으로 삼던 기존 방법론들과 크게 다르지 않을 것입니다. 반면 topical consistency만 보장되는 두 클립에 대한 표현력을 학습해야 하는 TCL(Topical Consistency Learning) 모듈은 기존과 다르게 untrimmed video의 특성을 잘 살려 설계되어야 할 것입니다.
그리고 두 가지 모듈에서 복잡한 비디오를 효과적으로 학습하기 위해, 저자는 Gradual Sampling 전략도 제안합니다.
아래 그림 4에 VCL, TCL, Gradual Sampling이 나타나있고, 각 모듈들을 이제부터 하나씩 알아보겠습니다.
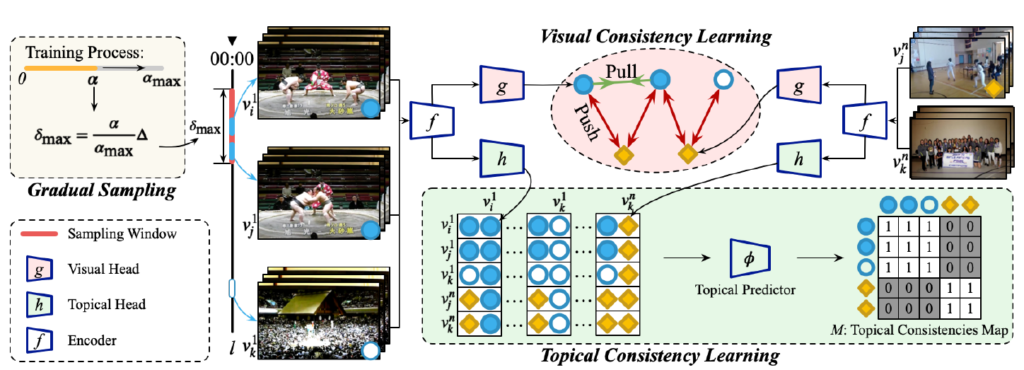
2.1 Visual Consistency Learning
VCL은 SimCLR의 프레임워크를 바탕으로 학습이 이루어집니다. 즉, 같은 비디오에서 얻은 클립은 서로 positive, 다른 비디오에서 얻은 클립은 negative pool에 두고 NT-Xent loss를 적용하게 됩니다.
하나의 미니 배치 내 총 N개의 비디오가 있을 때, 각 비디오 당 2개의 클립 v_{i}, v_{j}를 샘플링합니다. 이 때 두 클립 v_{i}, v_{j} 간에는 visual consistency가 보장되어야 하므로 아래 수식 (3)과 같은 조건을 두 샘플링합니다.
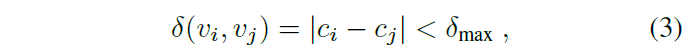
수식 (3)에서 c_{i}, c_{j}는 각각 v_{i}, v_{j}의 center frame 지점을 의미하고, 이는 결국 사전에 지정한 최대 거리 \delta{}_{max}보다 가깝게 위치하는 두 클립을 샘플링하여 visual consistency를 보장하겠다는 것입니다.
이후 각 클립을 backbone network f(), SimCLR의 contrastive projection head g()에 태워 feature를 얻고 두 유사도를 활용해 총 2N개의 클립에 대한 contrastive learning을 수행합니다.
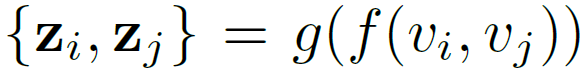
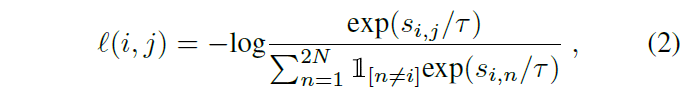
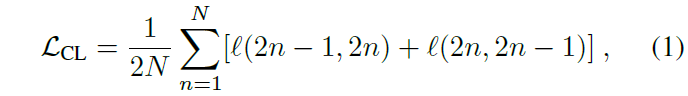
위 수식 (2)에서의 s_{i, j}는 latent vector z_{i}, z_{j} 간 cosine 유사도를 의미하고, 결국 수식 (1), (2)는 SimCLR의 NT-Xent loss와 동일합니다. Loss의 학습 방향을 살펴보면 같은 비디오로부터 샘플링한 두 클립 v_{i}, v_{j}는 서로만을 positive pair로 두고, 나머지 비디오에서 온 클립들은 모두 negative sample로 두어 각각 유사도를 최대화, 최소화하 방향으로 학습되게 됩니다.
2.2 Topical Consistency Learning
앞서 Introduction에서 봤던 그림 3입니다.
왼쪽 클립부터 시간 순서대로 클립 1, 2, 3, 4라고 했을 때, untrimmed video에서는 클립 2, 3의 관계와 같이 visual consistency가 존재하는 상황 이외에도 클립 1, 2 또는 클립 3, 4와 같이 시각적으로는 유사하지 않지만 의미론적으로는 “스모”라는 큰 대주제 내에 포함(스모 선수의 인터뷰, 스모 경기장 광경)되는 topical consistency가 유지되는 상황도 있습니다.
사실 하나의 비디오에서도 아예 다른 컨텐츠가 계속 등장하며 모든 클립들이 한 대주제로 묶이지 않는 상황도 있겠지만, 수많은 비디오에 대한 모든 다양성을 고려하여 모델링하는 것은 불가능하기에 저자는 이러한 가정을 깔고 시작하는 것으로 생각됩니다.
이전에 trimmed video만을 다루던 방법론을 그림 3과 같은 untrimmed video에 적용하면, 시각적 편차가 큰 클립 1, 2, 3, 4의 representation이 모두 같아지며 비디오 내 장면 별 의미론적 특성을 구별력있 담아내지 못하게 됩니다. 이렇게 이전 방법론에서는 고려되지 않던 untrimmed video 내 먼 클립 간 topical consistency를 저자는 어떻게 모델링하는지 알아보겠습니다.
우선 visual consistency는 보장될 수도, 안될 수도 있지만 topical consistency는 보장되는 클립 v_{k}를 비디오 내 임의의 위치에서 샘플링합니다. 만약 v_{k}가 v_{i}, v_{j}와 거 비슷한 위치에서 샘플링되었다면 visual consistency가 발생할 수도 있겠죠.
아무튼 저자는 topical consistency를 다루기 위해 v_{k}를 활용하는 두 가지 방식을 제안하는데요,
2.2.1
첫 번째는 아래 수식 (4)의 NT-Xent loss입니다.
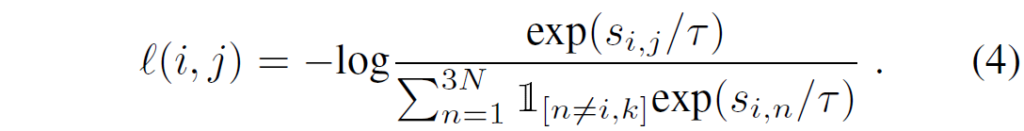
일단 배치 내 N개의 비디오마다 v_{i}, v_{j}, v_{k}를 샘플링하였기 때문에 총 3N개의 클립을 다루게 됩니다. Postive sample은 VCL과 동일하게 v_{i}, v_{j}로 구성되며 negative sample은 indicator를 통해 알 수 있듯 v_{k}만 포함됩니다.
즉, 수식 (4)에서는 VCL에서의 수식 (2)와 같이 v_{i}, v_{j}만이 positive pair로 지정되지만, negative sample로 같은 비디오에서 샘플링한 v_{k}까지 포함시켜 기존 방법론들이 시각적으로 다름에도 representation을 유사하게 가져가는 문제점을 완화하고자 한 것입니다. 정말 시각적으로 유사한 클립들만 유사한 representation을 갖도록 기대하는 것이죠.
2.2.2
두 번째는 learnable topic predictor 입니다.
비디오 하나마다 추출한 3개의 클립 v_{i}, v_{j}, v_{k}을 backbone f()와 topical project head h()에 태워 topical representation \{t_{i}, t_{j}, t_{k}\}를 얻어냅니다.
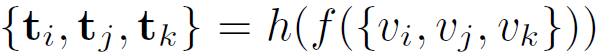
그럼 총 3N개의 topical representation을 얻을 수 있고, 아래 수식 (5)와 같이 모든 비디오에서 얻은 클립을 한 pair 씩 concat하여 pair-wise feature set U \in{} \mathbb{R}^{3N \times{} 3N \times{} 2C_{T}}를 얻어줍니다. 여기서 2C_{T}는 topical representation의 차원을 의미합니다.
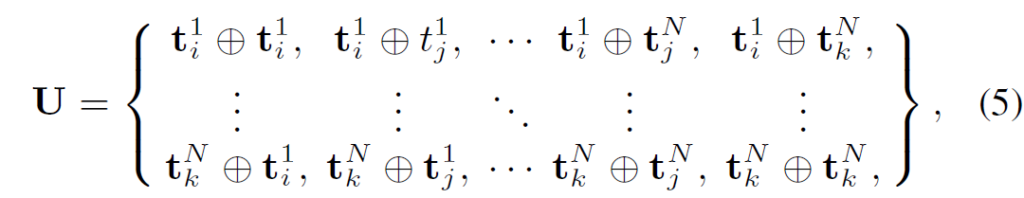
다음으로 U를 MLP인 topical predictor \phi{}에 태워 수식 (6)과 같은 topical consistencies M을 예측합니다. 3N \times{} 3N개의 각 원소를 구성하는 pair가 같은 비디오 내에 속해 topical consistency가 유지된다면 1, 아니면 0을 예측하도록 학습됩니다.
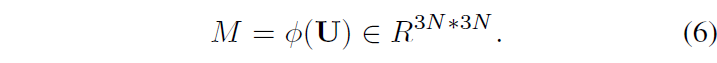
M에 대한 GT G \in{} \mathbb{R}^{3N \times{} 3N}는 저희가 concat한 pair를 알고 있으니 0 또는 1로 할당하여 만들어줄 수 있겠죠.
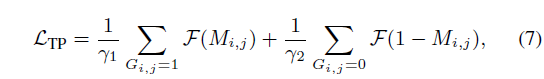
이후에는 topical predictor에 대한 학습을 위해 예측값 M과 실제 정답 G의 이진 분류 loss를 설계하고, 아무래도 0과 1 라벨 간 클래스 불균형이 크기 때문에 focal loss \mathcal{F}를 사용했다고 합니다.
이에 따라 HiCo의 최종 loss는 \mathcal{L} = \mathcal{L}_{CL} + \mathcal{L}_{TP}로 구성됩니다.
2.3 Gradual Sampling
Curriculum learning은 모델 학습 시 샘플들이 임의의 순서로 입력되는 것보다, 샘플의 특징을 파악해 유의미한 순서대로 입력해주면 더 좋은 표현력을 갖는 모델을 만들 수 있다는 점을 기반으로 연구되고 있습니다. 그 유의미한 순서에는 ‘쉬운 샘플부터 어려운 샘플 순서대로’ 입력해주는 방식이 존재합니다.
Untrimmed video가 시각적으로나 의미론적으로 굉장히 다양한 클립을 포함하고 있다는 점을 생각했을 때, 불안정한 학습 초반에 랜덤으로 샘플링한 클립을 positive pair로 던져주는 것은 악영향을 줄 수 있습니다. 따라서 저자는 현재 학습 epoch에 따라 VCL과 TCL의 positive를 샘플링하는 temporal distance \delta{}_{max}를 아래 수식 (8)과 같이 조절해줍니다.
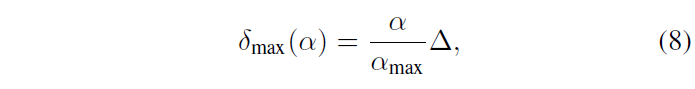
\alpha{}는 현재 epoch이고 \vartriangle{}은 사전에 정의한 최대 temporal distance입니다. 즉, epoch에 따라 학습 초반에는 굉장히 가까운 거리 내에서만 positive sample을 추출하여 쉬운 positive를 학습하다가, 어느정도 모델이 표현력을 갖게 되면 점점 positive sample이 추출될 수 있는 거리 범위를 넓히며 시각적으로 조금씩 달라져도 positive sample로서 안정적으로 학습할 수 있는 장치를 마련해둔 것입니다.
Gradual sampling의 효과에 대한 이론적 증명이 supplementary에 나와 있으니 필요하신 분들은 찾아보시면 좋을 것 같습니다.
방법론에 대한 설명은 이렇게 마치고 실험 결과 부분으로 넘어가겠습니다.
3. Experiments
Pre-training dataset
리뷰 맨 처음에 말씀드렸듯, SSVRL은 대용량 데이터셋을 이용한 backbone pretrain 부분과 학습을 마친 backbone을 활용한 downstream task 부분으로 구성됩니다.
일반적으로 video backbone의 pretrain에 활용되는 대표적 데이터 셋은 대용량 데이터셋인 Kinetics-400(K400)이고 이는 10초 짜리 비디오 약 240,000개로 이루어져 있습니다. HiCo는 untrimmed video에 더욱 적합한 pretrain 방식을 제안한 것이므로 저자가 직접 K400의 untrimmed 버전 비디오들을 수집하여 이를 Untrimmed Kinetics-400(UK400)이라고 칭하게 됩니다. 원본을 찾을 수 없는 비디오들도 많기 때문에 약 157,000개만 다시 얻을 수 있었다고 하네요. 이 뿐만 아니라 약 37,600개의 untrimmed video인 HACS 데이터 셋도 사전학습에 사용했습니다.
Pre-training settings
HiCo의 베이스라인은 SimCLR이고 backbone은 S3D-G, R(2+1)D-10, R3D-18을 대상으로 실험하였습니다.
3.1 Ablation Study
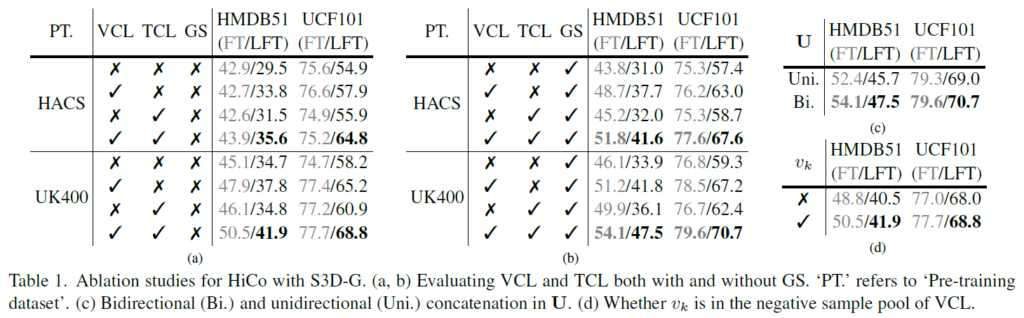
우선 표 1의 (a), (b)는 HiCo의 구성요소인 Visual Consistency Learning, Temporal Consistency Learning, Gradual Sampling에 대한 ablation 성능입니다. 사전학습 데이터 셋은 untrimmed video로 구성되어 있는 것을 알 수 있습니다.
표 1의 (a)와 (b)를 봤을 때 타 모듈의 적용 여부에 따라, 모듈을 붙인다고 해서 무조건 성능이 오르지는 않아 모듈 간 어느정도 의존성이 있는 것으로 보입니다.
VCL을 사용하지 않으면 positive sampling 시 untrimmed video의 아무 영역에서 뽑히게 되고, VCL을 적용하면 일정 거리 내의 샘플을 대상으로 visual consistency를 학습하게 되는데, 이렇게 untrimmed video의 특성을 잘 다뤄주는 VCL을 추가하는 대부분의 경우에서 큰 성능 향상을 일으키는 것을 볼 수 있습니다.
또한 TCL은 VCL보다는 성능 향상 폭이 적긴 하지만, 같은 비디오에 속함에도 negative로 두고 representation을 학습한다는 특성을 통해 VCL과 함께 붙였을 때 각 모듈의 향상 폭보다 더 크게 성능이 오르는 것을 볼 수 있습니다.
Gradual Sampling 기법은 개인적으로 생각한 것보다 성능 향상 기여도가 컸습니다. (a)와 (b)의 가장 마지막 행 끼리 비교해보시면, UK400에서 GS의 적용 여부만으로 5% 이상의 향상 효과가 있었습니다.
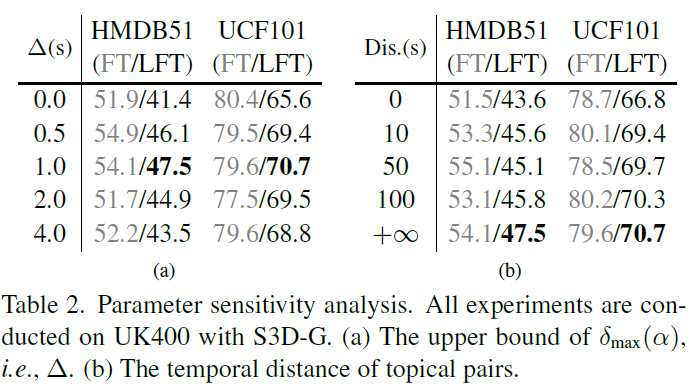
표 2 (a)는 positive pair sampling 시 최대 거리, (b)는 topical pair v_{k} sampling 최대 범위에 대한 ablation 성능입니다.
(b)의 경우 v_{k}를 샘플링하는 범위의 영역을 비디오 전체로 지정하는 경우 가장 높은 성능을 보이며 저자는 이 방식을 채택했습니다. 개인적으로는 실험 (b)를 통해 왜 untrimmed video를 다루는 것이 어려운지 간접적으로 느낄 수 있었는데요, 샘플링 범위를 늘림에 따라 성능이 일관되게 오르지 않고 50초 지점에서만 올랐다가 다시 떨어지게 되는 것을 볼 수 있습니다.
이렇듯 너무나도 불규칙적인 untrimmed video들에 대해 visual consistency는 유지되지 않지만 topical consistency가 유지되는 최적의 범위를 절대값으로 지정하는 것은 일관적인 경향성이 없어 그리 효과적이진 않은 것 같고, 무언가 단순 거리가 아닌 visual consistency에 대한 학습 기반의 기준을 만들고 이를 바탕으로 topical consistency의 특성 비디오별로 adaptive하게 적용하는 방식이 도움이 될 수 있겠다는 생각이 들었습니다. 물론 그것을 모델링하는게 쉽지 않아 절대적인 기준치로 영역을 지정했던 것이겠죠…
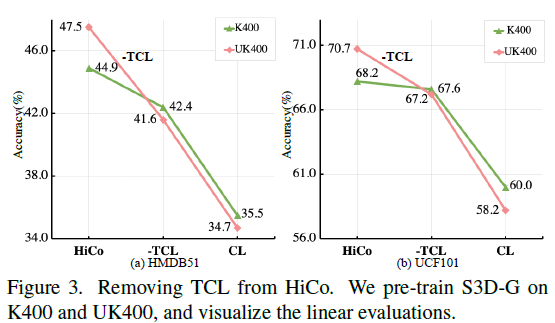
다음은 그림 3입니다. HiCo의 VCL과 TCL 모두 trimmed -> untrimmed로 넘어가는 상황을 잘 고려해 설계되었다고 볼 수 있는데요, 그림 3은 그 중 TCL이 실제로 untrimmed video에 대해 강인하게 표현력을 학습하는지에 대한 분석 실험입니다.
우선 HiCo에서 TCL 모듈을 제외하는 경우와 일반 Contrastive Learning 프레임워크인 SimCLR의 방식에선 UK400보다 K400의 표현력이 더 좋음을 알 수 있습니다. 하지만 HiCo 방식으로 pretrain을 수행하면, TCL을 제외하거나 SimCLR 방식에 비해 절대적인 성능이 높을 뿐만 아니라 pretrain하는 각 데이터 셋에 따른 성능 경향이 크게 역전되는 것을 볼 수 있습니다. 이는 TCL이 untrimmed video의 풍부한 temporal context를 잘 활용해 모델이 좋은 표현력을 갖도록 도와주었음을 의미합니다.
3.2 Evaluation on downstream tasks
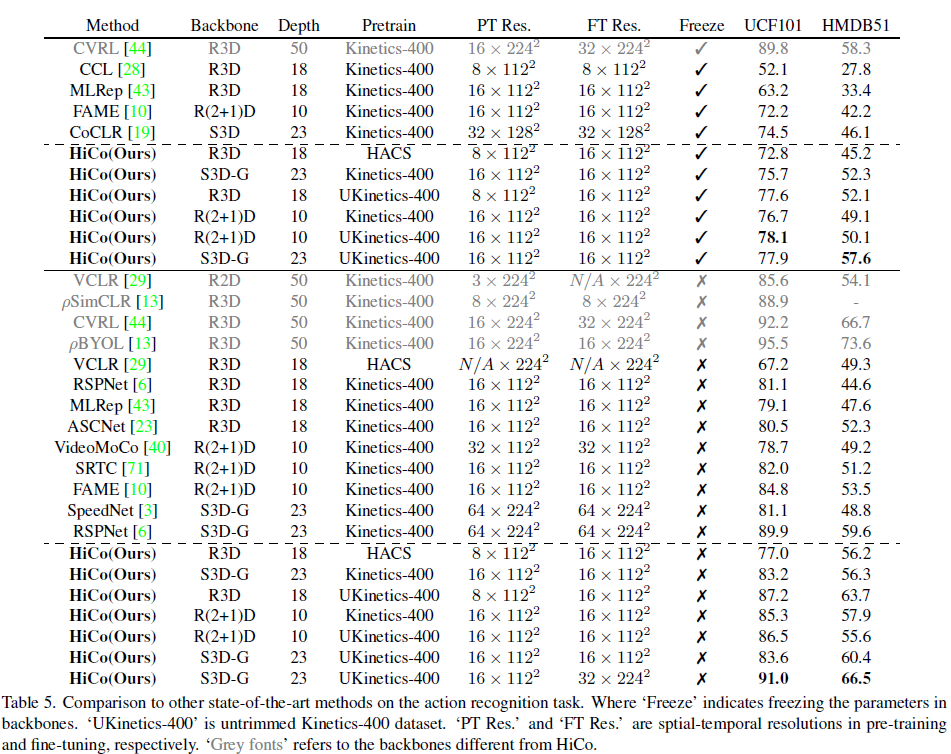
표 5는 Action recognition(classification)에 대한 벤치마크 성능입니다. 방법론별로 디테일이 다들 조금씩 다르긴 하지만 그래도 동일 조건 상의 방법론끼리 비교해보면 대체적으로 HiCo가 다른 방법론들보다 높은 성능을 보여주고 있는 것을 알 수 있습니다.
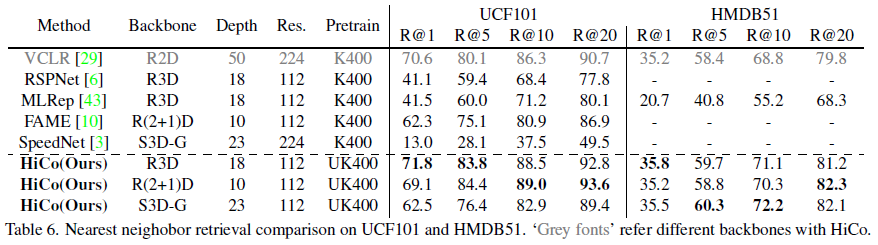
표 6은 Video retrieval에 대한 성능입니다.
UK400으로 pretrain한 HiCo와 K400으로 pretrain한 다른 방법론들의 retrieval 성능을 비교하고 있습니다. UK400이 K400에 비해 비디오 개수가 훨씬 더 적지만, 또 길이는 더 길기 때문에 이렇게 다른 pretrain 데이터 셋을 기준으로 성능을 비교하는 것이 맞는지는 좀 더 고민해봐야 할 것 같습니다. 어찌됐든 UK400으로 사전학습한 HiCo가 상대적으로 일반성있는 표현력을 가지고 있다는 것은 입증되었다고 생각합니다.
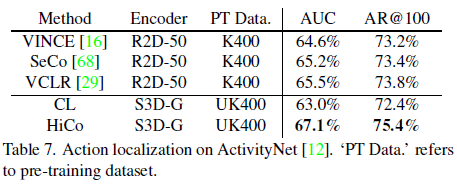
마지막으로 표 7은 Action localization 성능이고, UK400으로 pretrain하는 경우 기존 SimCLR보다 HiCo가 여러 모듈을 통해 긴 untrimmed video 데이터 셋인 ActivityNet에서 훨씬 높은 성능을 보이는 것을 알 수 있습니다.
4. Conclusion
SSVRL task에서 untrimmed video를 효과적으로 활용하려는 연구는 본 논문을 출발점으로 더욱 활발하게 이루어질 것이라고 생각합니다. 저자가 본 논문에서 제안한 방법론들 하나하나 간단하면서 효과적이었다고 생각합니다. 특히 논문의 실험 부분에서 많은 것을 배워갈 수 있었는데, 본인들의 주장을 뒷받침하기 위해 K400, UK400에 대해 내놓은 여러 가지 논리적인 비교실험과 분석을 통해 논문을 읽는 내내 저자의 주장에 설득되었던 것 같습니다. 물론 계속 파고들며 문제점을 찾을 수 있겠지만, 저자가 주장하는 바에 따른 근거와 분석의 논리성을 확보하려는 과정이 인상깊게 느껴졌던 논문이었습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요.
좋은 리뷰 감사합니다. 들을 읽어보니 비디오 연구에 중요한 논문이라는 생각이 들어, 언젠가 읽어봐야겠습니다.
Topical consistency와 visual consistency를 저자들이 잘 정의하였고, 실험을 통해 잘 증명하였다는 생각이 들면서도 영상들이 각각 차이가 워낙 크기에, 이렇게 어떤 가정을 하고 표현을 뽑을 수 밖에 없다는 것이 참 어렵게 느껴집니다…
현우님이 언급하신 것처럼 영상에 맞게 가변적으로 샘플링 반경 등을 조절하여 적절한 표현을 뽑을 수 있는 모델을 만들어보고 싶다는 생각이 드네요
이외에 curriculum learning이란 개념도 신기하였는데, 혹시 이런 방법은 이 논문에서 처음 제안하는 것인가요? 혹은 다른 논문에서 먼저 사용한 경우가 있나요?
감사합니다!
Curriculum learning은 마치 Active learning이나 Self-supervised learning과 같이 여러 task에 적용할 수 있는 연구의 한 분야에 해당합니다. 따라서 본 논문에서 처음 제안한 아이디어는 아니고 이미 연구되고 있는 방향성으로부터 도움을 받고자 저자가 HiCo 프레임워크에 적용했다고 생각하시면 됩니다.
Curriculum learning은 인간이 학습할 때에도 쉬운 것부터 풀어나가며 점점 어려운 샘플을 배우는 학습 방식을 모방한 것으로, Curriculum learning에서 연구되고 있는 self-paced learning의 경우 학습과정에서 발생한 loss가 크다면 어려운 데이터로 판단하여 넘기고, 추후에 어느 정도 모델이 학습되면 그 때 해당 샘플을 학습하는 방식이 존재한다고 합니다.