안녕하세요. 열 다섯번째 X-Review입니다. 하계 방학의 첫 X-Reivew이자, 이번 방학은 바삐 살며 성과를 내고자 악착같이 매달리고자 다짐하였는데, X-Review를 빠트리지 않고 쓰는 것도 그 중 하나가 되겠네요. 현재 연구실 내, 모든 인원이 경험해 본 URP의 태스크인 2D object detection을 연구로 이으며 담당하던 자로 SoTA 수준의 논문을 읽다보면 최근 연구 트렌드, 해당 분야에 관심을 가지는 정도를 알 수 있는데, 많은 분들이 이제 2D의 Object detection 혹은 Pedestrian detection은 Stauration, 성능이 포화되어 레드 오션이라고 인지하지만, 본 리뷰를 읽다보면 누구나 당연히 생각해볼 수 있던 일이였지만 연구하다보니 인공지능의 본질을 일종의 성능 끌어올리기에 몰두한 모습을 발견하여 새로운 시각으로 바라볼 수도 있을 것 같습니다.
대표적으로 본 논문은 최근 Pedestrian detection의 SoTA에 준하며, 근래 사용되는 보행자 데이터 셋에서 성능적으로 2등 수준 (2023년 CVPR에 개재된 본 논문 저자의 신작이 대부분의 데이터 셋에서 가장 낮은 MR을 보입니다)이지만, 저자가 본 논문을 통해 하고자하는 말을 들은 이후에는 뒷통수를 맞은것 처럼 얼얼할 수도 있을 것 같습니다. 제가 그랬기 때문이죠. 무려 약 2년 전쯤 김지원 연구원님이 본 논문의 리뷰를 작성해주셨으며 논문의 방법이 특별하거나 내용이 어렵지는 않으니 논문의 제목을 통해 영어 공부하는 것 처럼 분위기를 환기한 후 리뷰 작성을 시작하겠습니다.

The Elephant In The Room
2년 전이지만 2D Pedestrian Detection (이하 PD)의 SoTA급 논문이며 논문의 제목이 재미있습니다. 저는 처음에 읽었을 때 Elephant만 보고서 대충 “냉장고에 코끼리 집어넣기”로 이해했지만 찾아보니 다른 뜻이 있더군요. 방 안의 코끼리, 풀어보면 방 안에 코끼리가 있다고 하면 누구나 방 안에 코끼리가 있음은 알아도 그 누구도 건드리기 껄끄럽습니다. 한마디로 다루기 힘들고 껄끄러운 문제를 의미하며 아래 주토피아 영화의 예시를 보며 왜 저자가 Pedestrian Detection, 정확히는 Generalizable Pedestrian Detection이 껄끄러운 문제라고 표현한지는 아래에서 알아보겠습니다.
코뿔소? 버팔로의 국장이 “First, we need to acknowledge the elepahnt in the room”이라고 말하니, 다른 동물들이 벌써 껄끄러운 문제에 대해 두려워하겠죠. 그리고서 “Francy, Happy birthday”라고 하는데, 이 때 Francy가 생일 축하를 받는 코끼리인 것 같네요. 즉 코끼리가 우리 방에 있다는 것을 인지해야한다며 무거운 분위기를 조장하고서, 코끼리야 생일 축하해라는.. 미국식 조크네요.. 본 내용은 세미나때 들고 가기엔 저도 한국인으로써 본 조크가 재밌지는 않아서 두렵지만 분위기가 환기되었다면 그것으로 다행입니다. 그럼 논문 내용을 살펴보겠습니다.
Introduction
PD는 CCTV (video surveilance), Action recognition 등의 실 세계 응용 태스크의 상당 부분을 차지합니다. 그 중에서도 관심을 갖는 핵심 분야는 자율 주행입니다. 누구나 알고 있죠. CNN의 발달과 함께, ViT의 등장과 함께 PD는 성능에서 굉장한 성과를 보여주었습니다. 실제로 인공지능 모델의 성능을 평가할 때는 각 태스크에 맞는, 예를 들어 Classification은 accuracy를, Object detection은 주로 mAP를 측정하는 반면 PD는 MR (Miss-Rate)를 측정합니다. 우리는 PD 태스크를 Kaist 데이터를 통해 경험해보았으므로 MR에 대해 다루지는 않으며, 이 말을 하는 이유는 성능 평가 지표가 있지만 이들 모두 결국 실 생활에서 인공지능이 응용되고자, “인공지능이 사람이 인지하는 만큼 잘 인지하는지”를 평가하기 위해 고안해낸 지표입니다. 사람이 인지하는 만큼이라고해서 MR이 0은 아닙니다. Annotator마다 Bounding box를 Annotation하는 인지 수준이 다르기 때문이며, 보통 PD에서는 약 2% 수준을 사람이 인지하는, Human baseline이라고 명합니다. 사실 이는 데이터 셋에 따라 달라지기도 합니다. 영상 내 보행자가 한 두명 있다면 모를까, challenge한 데이터 셋에서는 사람이 인지하는 수준도 그만큼 달라집니다. 인공지능 모델이 학습 데이터의 분포를 학습한다고 생각할 때, Annotation의 중요성이 여기서 다시 강조되겠네요.
잡설은 각설하고, 이 때 저자는 현 SoTA라고 불리는 PD 모델의 단점을 말합니다. 이 말을 제가 느낀 방식으로 말하자면 이렇죠, “과연 너희 모델들이 정말 자율주행 시점에서의, 그러니까 실 생활에 응용 가능한 일반적인 모델이야?” 저자가 이렇게 말한 이유는 다음과 같습니다. 몇몇의 최근 PD 방법은 목표로 하는 학습 및 평가 데이터 셋에 과적합되어 있다. 즉, 성능 올리기에만 급급하여 해당 모델들이 그 데이터 셋에서는 잘 작동할지언정, 일반화되어있지 않고 실 생활에 응용 시에도 항상 동일한 수준의 성능을 낼만큼 잘 작동할지는 의문입니다. 그렇기에 본 논문의 제목이 PD를 Generalizable, 일반화하는 것은 까다로운 일이라고 명합니다.
사실 바로 위의 문단이 본 논문의 전부이자 제가 이 논문의 리뷰를 쓴 이유입니다. 우리는 보통 베이스라인을 산정하고, 실험을 하고자하는 데이터 셋을 정하여 특성을 분석하기도 합니다. 물론 이는 당연히 중요합니다. 더 쉬운 예를 들어 한 데이터 셋의 보행자가 COCO 평가 기준 Small object(32×32 area)만 존재한다면, 모델의 성능을 향상할 수 있는 직관적인 방법은 Small object를 잘 찾는 것입니다. 보통은 아니지만 몇몇 논문을 읽다보면 본인의 연구 결과에 대해 이를 합리화하고자 서두를 작성하는 것을 보곤 합니다. 아래의 예시는 읽었을 때 틀린 말들도 아니며 어느 누구는 충분히 이해가지만, 조금 더 생각해봤을 때 의문점이 들기도 합니다. 제가 임의로 예시를 만들어보겠습니다.
만약 논문의 시작이 다음과 같이 시작한다고 합시다. “CNN의 발달과 함께 자율 주행 관점에서 PD의 성능이 오르고 있지만, 여전히 최근 방법론들은 일부가 폐색된 (occlusion) 보행자를 잘 찾아내지 못하여 성능이 낮다.” 이는 사실에 기반하였으며 자명하기도 합니다. 그렇지만 다른 시선에서는 이렇게 볼 수도 있습니다. ‘가려진 보행자의 한 명 한 명을 잘 찾아내는 것이 PD의 궁극적인 목표인 보행자와의 충돌을 피하는 것에 큰 도움이 될까? 사실 사람 한 명 한 명이 아닌 군중 집합으로 찾아내도 큰 무리가 없지 않을까?’라고 말이죠. 사실 이러한 생각에 대해 반감이 들 수도 있고 다른 시각으로 바라볼 수도 있으나 결국 인공지능의 궁극적인 실 생활에서의 응용 측면을 생각했을 때, 몇몇의 연구들이 데이터 입출력에 따른 성능에만 목 매달고 있지는 않나 생각이 듭니다. 물론, 그렇다고 저도 예외는 아닙니다.
이러한 생각이 일 년이 안된 연구원의 입장에서 옳은 것일지는 모르겠네요. 다시 리뷰를 돌아와, 저자는 많은 방법론들이 사용하는 데이터 셋에 맞춤화되어 디자인되어 있다고 합니다. 두 번째로는, 학습 데이터들이 일반적으로 보행자의 비율이 부족하며 실제 주행 상의 다양한 시나리오들을 담아내고 있지 않다고 지적합니다. 첫 번째 주장이 “너네가 만든 모델들은 학습 데이터에 편향되어 성능 끌어 올리기에 급급하잖아”라고 지적하는 반면, 두 번째 주장은 “너네가 사용하는 데이터 셋들은 사실 실 생활에 도움될만큼 보행자가 많은 등의 challenge한 상황을 많이 담고 있지 않잖아”입니다. 서론 부분에서 말하고 있지만, 저자는 두 번째 주장에 대해 또 다음과 같이 말합니다. “그럼 내가 힌트를 줄께, 현 시점에서 모델들은 딥러닝에 기반을 두고 있고, 쉬운 태스크로 분류되는 이미지 분류 문제를 살펴보면, 딥러닝에 기반을 두고 있다는 사실에서 모델이 학습 이미지의 분포를 학습한다는 것을 아니 양질의 데이터가 많으면 많을 수록 성능이 높아지는 것도 자명하다는 사실이야”
이 다음 지점이 굉장히 납득하기 어려울 수도, 어쩌면 쉬울 수도 있습니다. 저자가 바로 위에서 말한, 사실은 저자의 말로부터 제가 내포한 의미를 담았지만 딥러닝 모델이 학습 데이터의 분포를 학습한다는 사실과 더불어 딥러닝 모델이 일반적이고 입력받는 데이터들에 강건해야함은 당연합니다. 그렇다면 Clatech, CityPerson, Kaist, 지난 번에 리뷰한 NIRPed와 같은 데이터 셋들은 하나의 공통점을 가지고 있습니다. 바로 데이터 수집 시 자동차에 카메라, LiDAR와 같은 장비를 부착하여 실제 주행 환경에서의 도로 위 주행자의 특성을 포착하고자 합니다. 이는 실제 주행 환경이라는 조건만으로 자율 주행 관점에서 양질의 데이터임에는 분명합니다만, 또 다른 시각에서는 수집시의 환경이 제한적입니다. 이를 아주 쉽게 말해 고정된 위치의 카메라에서 촬영된 사람들을 담고 있습니다.
그렇다면 이것이 왜 문제냐고 할 수도 있습니다. 저도 사실 저자가 말하는 “다양성 (diveristy)이 적다”라는 말을 쉽게 받아들이긴 어려웠는데, 제 생각에서 만약 모델이 모든 데이터에서도 강인하고자 한다면, 예를 들어 pixel height 기준 30 ~ 50 수준이 아닌 영상 내 전체로 담기는, 그런 특수한 상황에서도 강인해야한다는 것을 의미하지 않을까 합니다. 그 이유로는 저자는 유튜브나 페이스북 등에서 데이터를 수집하는 것이 다양성을 늘릴 수 있는 방법 중 하나라고 말하기 때문입니다. 실제로 CrowdHuman, WiderPerson, Wider Pedestrian과 같은 데이터 셋은 웹, 감시 카메라 등에서 크롤링하여 구성한 데이터 셋이며 저자는 해당 데이터 셋을 활용하는 것도 중요하다고 언급합니다. 해당 데이터들은 실제로 사람 수가 훨씬 많고, 가려진 사람의 비율 또한 월등히 많습니다.
main contribution
저자가 하고자 하는 말과 그에 따른 실험을 미리 언급하고 넘어가겠습니다. 서두가 길었지만 이를 한 줄로 축약하면 “실 생활에서 응용될 수 있도록 하고자 어떤 데이터에도 일반화된 모델이 중요하다”입니다. 그렇기에 저자는 현존하는 PD 방법을 그대로 가져와, 교차 검증을 수행합니다. 이 때 수행하는 교차 검증은 다음과 같습니다. A 학습 데이터로 학습한 모델을, B 평가 데이터로 평가합니다. 혹은 A + B 학습 데이터로 학습한 모델을, C 평가 데이터로 평가합니다. 해당 방법이 일반화성을 검증할 수 있는 하나의 방법임에는 충분히 납득될 수 있습니다. 이를 통해 저자는 다음의 충격적인 말을 합니다. “내가 해봤더니, PD 모델들을 사용하는 것보다 SoTA인 Object detection 모델을 적절히 학습시키는 것이 교차 검증 시 성능이 훨씬 낫더라”. 그리고 “지금처럼 A 학습 데이터로 학습, A 평가 데이터로 평가하는 방법보다 제안하는 Progressive training pipeline을 통해 학습하는 성능이 더 좋아지더라”. 사실 많이 충격적이였습니다. PD 기반 SoTA 논문들을 주 1편 이상 읽어왔지만 2021년의 지금 이 논문을 읽고 그 논문들을 읽었더라면, 그 때 해당 논문들을 바라보는 시각은 달랐을텐데요..
사실 위 문단에서 알 수 있듯, 저자는 새로운 모델을 설계한 것은 아닙니다. 실제로 Object detection 모델도 Cascade HRNet을 가져옵니다. 그렇기에 본 논문의 Method 파트는 없으며 바로 Experiments로 넘어갑니다. 따라서 위 몇 문단을 통해 저자가 하고 싶은 말을 몇 번 반복해서 말하며 그 떄의 제 생각들도 담았습니다. 저는 꽤 큰 충격을 받긴 했습니다만, 이제 실험을 통해 바로 살펴보기 이전 저자가 사용한, 그리고 위에서 말한 데이터 셋의 예시를 사진 몇 장으로나마 살펴보고 넘어가겠습니다. 이해에 도움이 될까 말이죠.
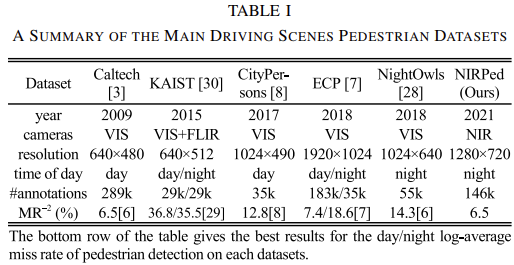
위는 최근 NIRPed 논문에서 발췌해 온 기존 보행자 데이터 셋의 사양 및 예시입니다. 이 때 살펴볼 점은 #annotations, 즉 보행자의 수와 MR입니다. 이번 리뷰하는 논문에서는 이 중 Caltech, CityPerson, ECP (EuroCity Persons), 추가적으로 CrowdHuman, Wider Pedestrian을 가지고 오며 두 데이터 셋은 표 1에서 확인할 수 있지만 웹 크롤링을 통해 수집한 데이터 셋 입니다.
또 하나, 교차 데이터 셋 평가 방식에 대해 다루긴 했지만 평가 프로토콜과 함께 짧게만 살펴보고 넘어가겠습니다. 평가 프로토콜은 모든 연구원 분들이 알고 있듯, Reasonable, Small, Heavy, All을 MR로 평가합니다. PD에서의 평가 방식이며, 교차 데이터 셋 평가는 A->B로 쓰여졌다면 A 데이터로 학습 후 B 데이터로 검증 및 평가를 진행하는 방식입니다. A+B는 두 데이터 셋의 학습 데이터 셋을 합친 것으로, 단순히 두 데이터 셋 모두를 학습한 방법입니다. 뒤의 Progressive Training Pipeline에서 등장하긴 하지만, 그 때의 A->B는 지금의 교차 데이터 셋 평가 (Cross-dataset evaluation)와는 다르기에 혼동이 오지 않았으면 합니다.
Experiments




위 다섯 데이터 셋 예시를 보면, CrowdHuman과 Wider Pedestrian은 촬영 장소나 시점이 다름을 눈치챌 수 있습니다. 그 이유는 앞서 말한 것과 같이 웹 크롤링과 CCTV 촬영 영상이므로 사람의 일반적인 패턴을 학습할 수 있음에 장점이 있습니다. 그럼 해당 이미지의 수, 총 객체 (사람) 수, 이미지 내 사람이 차지하는 비율 등을 살펴보겠습니다.
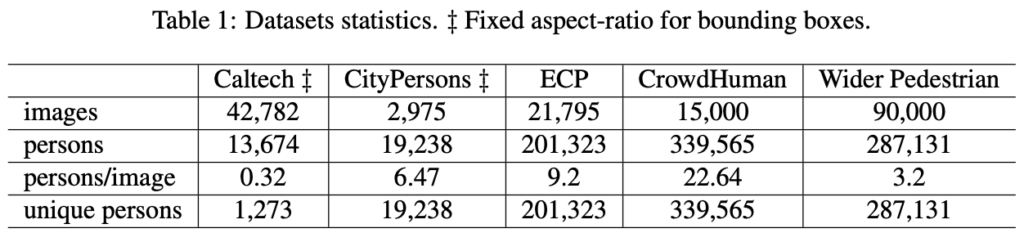
CrowdHuman의 경우는 이미지 당 평균 22명 이상의 사람을 포함하고 있네요. 그 말인 즉 해당 데이터 셋은 occlusion, small object 등의 challenge한 상황을 담아 보행자 이상의 사람에 대한 일반적인 표현력을 학습할 수 있습니다.
저자는 베이스라인 Detector로 Cascade R-CNN을 선택했습니다. 그 이유는 Clatech, CityPersons와 ECP의 SoTA 모델들이 Faster/Mask R-CNN의 확장이며 이 때의 Backbone 네트워크는 Small object에서 강점을 가지고자 HRNet으로 선정한, Cascade HRNet을 선정하였습니다. 이 때 특이한 점으로는 위 세 데이터 셋에서 SoTA 모델들을 각각 가져다 쓰지 않고, 저자가 지적한 데이터 셋 맞춤용 Trick을 배제한 기본적인 Object detector를 사용했단 점입니다. 즉 저자는 이 때부터 Object detector와 Pedestrian detector를 분리해서 말합니다.
그렇다면 이제 가장 중요한 Cross-dataset Evaluation의 결과를 살펴보겠습니다. 저자가 계속 언급하는 주장은 기존 PD 모델들은 데이터 셋에 편향적으로 설계되었단 것인데, 과연 실제로 그런지 살펴보겠습니다.
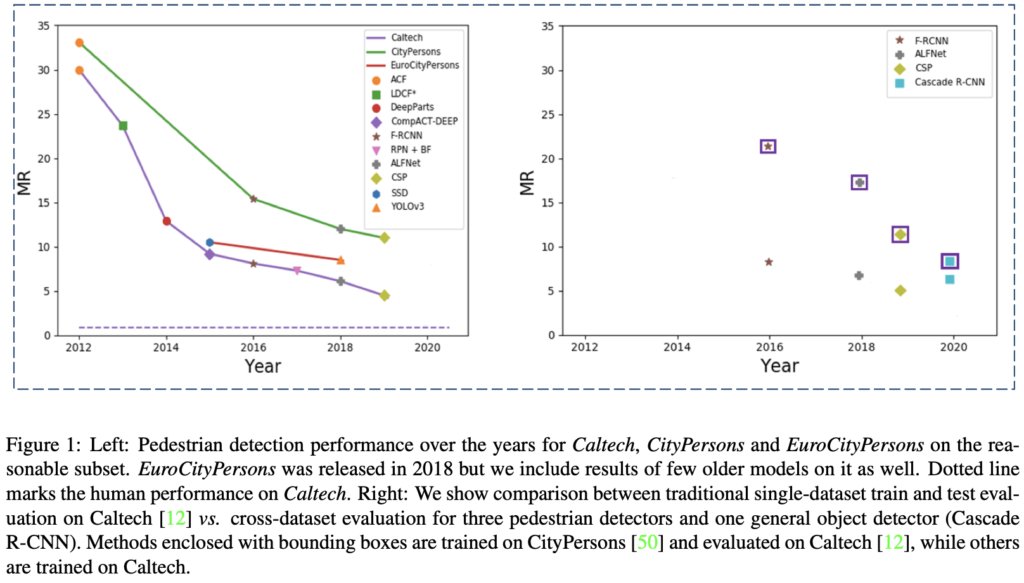
위 표가 본 논문의 핵심입니다. 왼쪽 표의 실선은 데이터 셋을, 실선 위 점들은 예전부터의 (ACF부터 최근까지 발전해온) Pedestrian detector들입니다. 왼쪽 표를 통해 저자는 Pedestiran detector들의 성능이 발전해오고 있음을 언급합니다. 그럼 오른쪽 표의 Cross-dataset evaluation 결과는 어떨까요? 대표적 예시를 든 F-RCNN과 ALFNet, CSP는 Pedestrian 맞춤형으로 고안된 detector로, CityPersons에서 학습 후 Caltech으로 평가한 네모 박스에 둘러쌓인 결과를 살펴보면 Caltech에서 학습하고 평가한 그 아래에 비해 성능이 100% 이상으로 떨어짐을 확인할 수 있습니다. 이에 반면 Cascade R-CNN은 성능 하락 폭이 적습니다. 바로 오른쪽 표가 저자의 본 논문 저술 이유를 말하는데, 결국 “너네 좋은 성능 보인다고 했지만, 사실 알고보니 다른 입력 들어오니 성능 낮은 것을 보아 일반화되지는 않잖아?”라고 말하는 것 같네요. 이제 정량적 표들로 살펴보겠습니다.
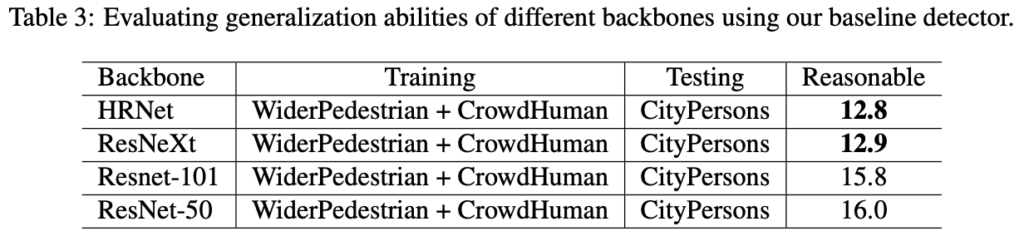
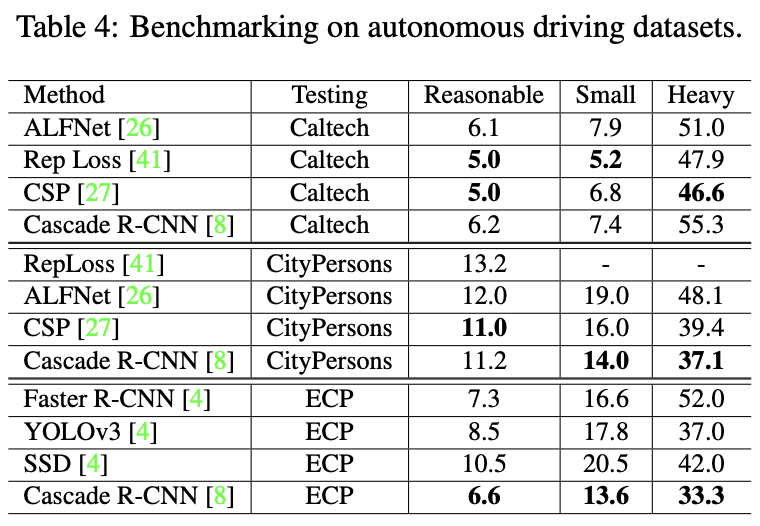
테이블 3은 Cascade R-CNN에서 Backbone을 변경한 채 Training, Test 데이터 셋을 교차 평가한 결과를 (HRNet을 사용한 이유를 언급합니다), 테이블 4는 다양한 데이터 셋에서 교차 평가하지 않고 그 자체로 학습 및 평가했을 때의 성능을 보여줍니다. 이 때 테이블 4를 보며 저자는 Cascade R-CNN (HRNet)은 다른 Pedestrian detector (사실 SSD와 YOLOv3는 Pedestrian detector로 설계되었기 보다는 Object detector지만, 아마 Aspect ratio를 알맞게끔 조정한 것을 언급하는 것 같습니다.) 에 비해 성능이 많이 낮지도, ECP의 경우는 가장 높기도 하며 이 때 특별한 Trick (Bells and whistles) 없이도 좋은 성능을 보임을 언급합니다. 곧 즉, 학습 데이터가 증가함에 따라 일반적인 모델이, 일반적인 표현력을 학습하기에 더욱 용이함을 의미합니다.
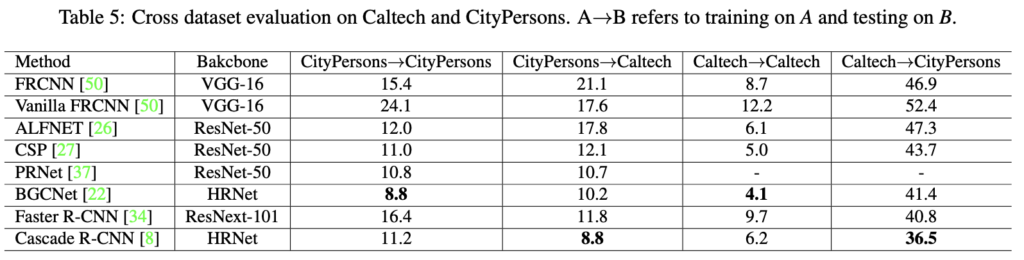
테이블 5는 다양한 방법에 대한 cross-dataset evaluation 결과를 나타냅니다. BGCNet은 Baseline과 같이 HRNet을 Backbone 네트워크로 사용한 모델로, 교차 검증 시에도 괜찮은 성능을 보여줍니다. 반면 FRCNN, CSP와 같은 모델은 cross dataset evaluation 시 성능 하락의 폭이.. 2배가 넘네요. 심지어 Caltech->Caltech에 비해 Caltech->CityPersons와 같은 경우는 무려 MR이 8배 이상 상승한 모습을 볼 수 있습니다. 그렇다면 CSP와 Baseline 모델을 더욱 다양한 데이터 셋에서 cross-dataset evaluation한 표를 살펴보겠습니다.
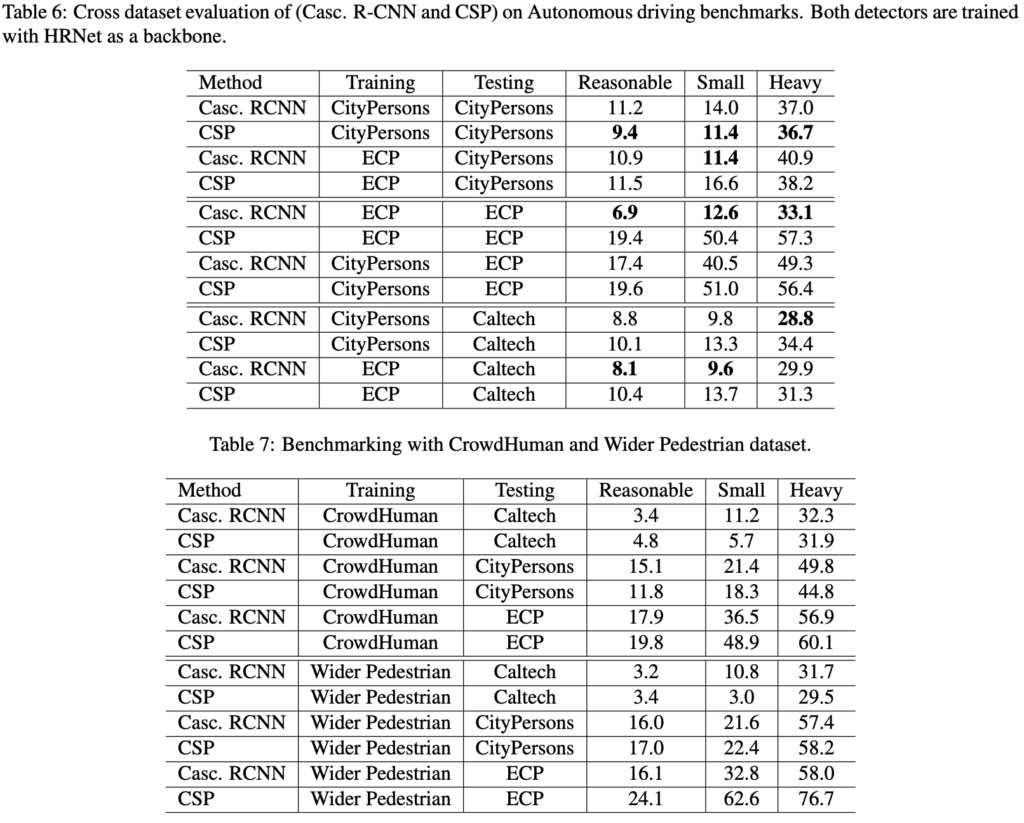
테이블 6, 7을 살펴보면 Casc. RCNN과 CSP를 cross-dataset evaluation 시, 성능이 웬만하면 다 Casc. RCNN이 우수한 모습을볼 수 있습니다. 이로써 저자가 주장한 내용의 설득력이 짙어지네요. 여담이지만, 저도 한번 학습을 시켜보려 저자의 코드를 받아 시도해봤지만, Training cost만 따지고보면면 Casc. RCNN은 240 Epoch를 돌릴 시 17일 정도 걸리는 것을 보고서는.. 그냥 포기했습니다. 뭐 그렇다할지언정 Training cost가 전부는 아니니까요. 일반적인 Object detecto의 경우이니 이해됩니다.
이제 저자가 말한 Progressive Training Pipeline입니다. 특별한 것은 없으며, A->B는 A 데이터 셋으로 pretraining한 이후 B 데이터셋으로 fine-tuning하는 것을 의미하며 A + B는 단순히 두 데이터 셋을 함께 합쳐 학습하는 것을 의미합니다. 위에서 이미지 분류 예시를 들며 단순히 학습 데이터 셋을 늘리는 것 조차 일반적인 표현력을 학습할 수 있어 도움된다고 말했는데, 그것을 보이고 싶은가 봅니다. A->B는 일반적이고 다양한 데이터 셋으로 부터 학습하여, 즉 Target domain에 멀리서 학습한 이후, dataset에 대해 Fine-tuning을 통해 Target domain을 미세 학습할 수 있습니다. 특이한 점으로 아래 테이블 8을 살펴보면, Fine tuning 이후에도 Fine tuning한 데이터 셋이 아닌 다른 데이터 셋으로 cross-dataset evaluation을 진행하는데, 이 떄의 성능이 꽤나 우수함을 보입니다. 심지어 아래 두 줄은 Human baseline 수준입니다. 이 테이블 8을 위 테이블들과 비교하여 살펴봐야하지만, 저자가 하고 싶은 말은 결국 “데이터 셋을 단순히 늘리는 것도 좋은 방법이고, 아니면 Pretraining-Fine tuning과 같은 어렵지 않은 기법만으로도 (일종의 bells and whistles가 아닌 누구나 쓸법한 기법) 성능 향상을 이뤄낼 수 있다고 주장합니다.
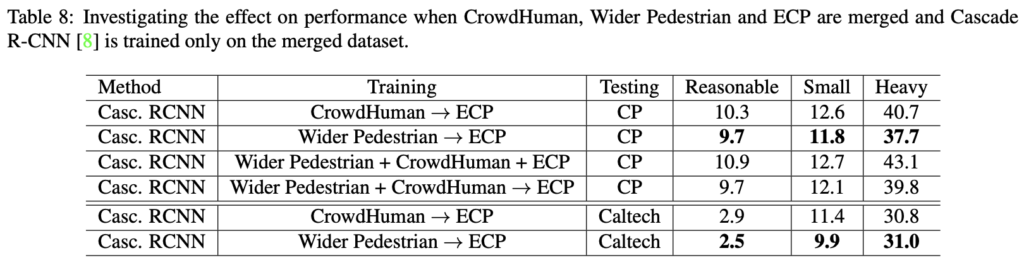
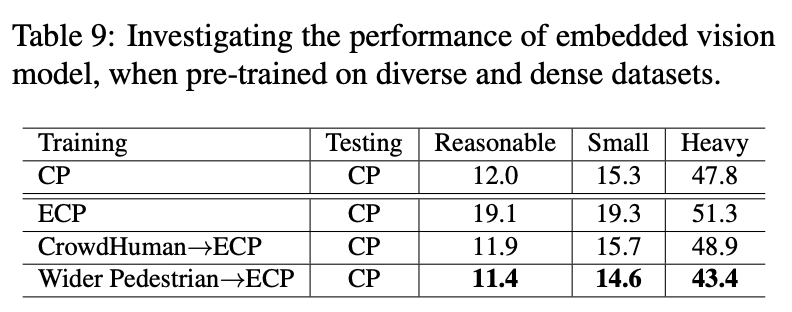
마지막으로 테이블 9는 실 생활에서의 사용성을 중시한 만큼, MobileNet을 백본으로 두어 Embedded computer에 실을 수 있을 만큼 경량화 시 성능 하락이 크게 일어나는 지를 살펴봅니다. 이로써 위에서 정리한 저자가 하고 싶은 말을 하나하나 검증했음을 알 수 있습니다. “실생활에서 사용 가능할만큼 / 일반적인 PD 모델 / 특별한 기법을 사용하지 않은 채”. 일종의 분석 논문인데, 재밌게 봤네요.
Conclusions
최근 SoTA라고 주장하는 PD 방법들을 cross-dataset evaluation을 통해, 해당 모델들은 Source dataset에 맞춤화 되어 있는 (tailored, bells and whistles, targeted 등의 다양한 표현을 사용했네요) 일종의의 Trick 모델인 반면, 오히려 일반적인 Object detector 모델을 학습하는 것이 어쩌면 자율주행 관점에서는 더 납득될만함을 다양한 실험을 통해 보입니다. 저로써는 꽤나 충격받은 논문이며 2년 전의 논문을 늦게나마 지금 읽어본 것이 꽤나 아쉽습니다. 흠.. 그래도 다시 내일부터 실험은 열심히 돌려봐야겠죠ㅎㅎ. 논문 리뷰 읽어주셔서 감사합니다.
안녕하세요 좋은 리뷰 감사합니다. Object Detection이나 PD의 최근 방법론들 detail을 거의 모르기 때문에, 리뷰 자체에 대한 이해도가 좀 낮아 생기는 질문일 수도 있습니다.
결국 저자는 최근 sota 방법론들이 학습시킨 데이터 셋에만 최적화가 되어있고, 그건 자율주행을 위한 PD 관점에서 실제로 활용하긴 어렵고 성능 수치만에 집중한 연구다.. 이런 주장을 하는 것으로 이해했습니다.
그것을 입증하기 위해 데이터 셋들을 학습과 테스트에서 교차해가며 모델 별 성능을 보여주셨습니다. 실험에 대한 분석으로 실험 결과가 저자의 주장과 일치하는 경향을 보이는 것을 언급해주셨는데, 최근 sota들이 일반성을 갖지 못하는 이유에 대한 조금 더 자세한 방법론 측면의 분석은 언급되어있지 않나요?
리뷰에서도 언급하신 “저자가 지적한 데이터 셋 맞춤용 Trick을 배제한 기본적인 Object detector”에서 “맞춤용 trick”이 왜 모델의 일반성을 오히려 저해하는지의 관점으로 실험 결과를 분석한 내용이 있는지 궁금합니다.
사실 방법론마다의 디테일함은 저도.. 아는 detector가 많지 않았지만 리뷰에서 저자가 하고픈 큰 말만 이해했습니다. 그럼에도 꽤나 뒷통수를 맞은 느낌이여서 소개하고자 한 논문이며 두 번째 문단에서 말씀하신 “저자는 최근 sota 방법론들이 학습시킨 데이터 셋에만 최적화가 되어있고, 그건 자율주행을 위한 PD 관점에서 실제로 활용하긴 어렵고 성능 수치만에 집중한 연구다”는 정확하게 이해하셨습니다. “최근 sota들이 일반성을 갖지 못하는 이유에 대한 조금 더 자세한 방법론 측면의 분석은 언급되어있지 않나요?”에 대한 답변으로는 일반성을 갖지 못하는 몇몇 Trick들로 인함도 있지만 그 보다도 지금 사용하는 데이터 셋들이 Challenge한 상황을 많이 담고있지 않으며 또한 데이터 셋들의 도메인이 그 데이터 셋 내에서 비슷하기에 기인하지 않았나합니다.
질문해주신 “저자가 지적한 데이터 셋 맞춤용 Trick을 배제한 기본적인 Object detector”에서 “맞춤용 trick”이 왜 모델의 일반성을 오히려 저해하는지의 관점”이 바로 Cross dataset evaluation이라고 봅니다. 저자의 Faster-RCNN, Cascade RCNN은 곧 즉 Pure한 object detector인 반면, SoTA의 PD 방법론이 그 마다의 Trick들로 인해 다른 데이터 셋에서 성능이 낮다면, 그것만으로도 General하지 않다고 납득시키는 것에 일리가 있다고도 생각합니다.
리뷰 잘 읽었습니다.
뭔가 되게 새로운 시각의 논문을 읽은 거 같네요. 저같은 경우도 현재 특정 dataset에 대해서만 성능을 올리기 급급한 상황인데 제 자신도 한번 되돌아보게됩니다…
결국 제 생각해 일반화 성능이 높은, 그리고 실생활에서 잘 동작하고자 하는 detection 모델을 위해선 여러 상황이 복합적으로 포함되어 있는 다양한 종류의 데이터셋을 함께 사용하면 될 거 같다는 생각도 드는데 이에 대해선 어떻게 생각하시나요 ??
“다양한 종류의 데이터셋을 함께 사용하면 될 거 같다는 생각”에 대해 꼭 그렇지만은 않다는 것을 보여준 것이 테이블 8이 아닌가 싶습니다. 결국 저자가 주장하는 바에 대한 실험은 오늘 세미나를 하고 나니 아쉽네요. 그렇지만 저자가 하고 싶은 말은 대용량의, 혹은 다른 데이터 셋으로 학습한 후 데이터 도메인을 생각해 Fine tuning하는 방법을 사용하면 성능에 효과적일 수 있음을 보인다고 생각합니다.
안녕하세요. 리뷰 잘 읽었습니다.
본 논문에서 저자가 하고 싶은 말이 ‘pedestrian detection은 대용량의 데이터를 학습하고자 한다’ 인거같은데 맞나요? 각 데이터들은 어떤 특성이 있길래, train, test 등에서 데이터를 합쳐서 학습하고, 또 다른 데이터로 평가하고 그러나요? ? ? ?
또,, 저자가 내세우는 방법론 자체는 사실 없는 거 같은데, 이에 대해서는 어떻게 생각하시는지 궁금합니다.
ㅎ ㅅ ㅎ
감사합니다.