안녕하세요. 다섯 번째 X-Review입니다. 이번 리뷰할 논문은 19년도 CVPR에 게재된 <Character Region Awareness for Text Detection> 논문입니다. Intro들어가기 전 간략히 해당 task에 대해 소개하고 들어가도록 하겠습니다. ?
OCR(Optical Character Recognition)은 광학문자인식으로써 이미지에 있는 text를 기계가 읽을 수 있는 text 형식으로 변환해주는 task입니다.
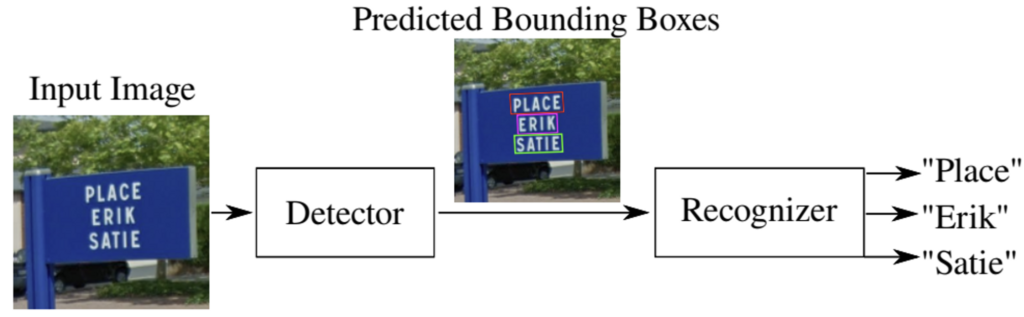
위 그림과 같이 OCR은 크게 문자가 있는 영역을 검출하는 text detection 과정과, 그 검출된 영역의 문자를 인식하는 text recognition 과정으로 구분할 수 있습니다.

이 text detection 과정은 크게 word-level detection과 character level의 detection으로 나눌 수 있습니다. 위 그림에서 상단이 글자를 기반으로 검출하는 것이며, 하단 그림이 단어 기반으로 검출하는 것으로 볼 수 있겠습니다. 금주 리뷰할 논문은 ocr flow 중 text detection에 관한 것이며, 그 중 character level의 detection에 관한 것입니다. 바로 시작하도록 하겠습니다.
Introduction
기존 scene text detection에서는 word-level의 bounding box를 localize하도록 학습해왔습니다. 하지만, 이 word-level의 detection은 아래 그림처럼 text가 곡선 형태거나, 혹은 변형되었거나 엄청 길다면 detect하는데 어려움이 있습니다.

이에 대한 대안으로 character level, 즉 단어가 아니라 문자 수준으로 text를 detect하는 방법이 있지만, 현존하는 text dataset은 대부분 character level의 annotation을 제공하지 않을 뿐더러 character level의 GT를 얻는 과정을 생각해보면 글자 하나하나마다 box를 쳐야하기에 cost가 굉장히 큽니다.
본 논문에서는 개별적인 문자 영역을 찾은 후, 그것들을 연결시켜 하나의 text로 묶어 detect하는 text detector(이하 CRAFT)를 제안합니다. 이 CRAFT는 input으로 넣은 이미지에 대해 픽셀마다 region score와 affinity score. 이렇게 두 값을 예측합니다. region score는 해당 픽셀이 문자의 중심일 확률을 의미하며, affinity score는 해당 픽셀이 인접한 두 문자의 중심일 확률을 의미합니다. 다시 말하자면 region score는 각각의 character를 localize하는데 사용하고, affinity score는 각 character를 하나의 instance로 묶는데 사용한다고 보면 되겠습니다.
방금 전 character level의 annotation된 dataset이 거의 없다고 했었는데, 본 논문에서는 이러한 점을 해결하기 위해 현존하는 word level dataset을 이용해 character level의 Ground-Truth를 추정해서 weakly supervised learning을 수행합니다.
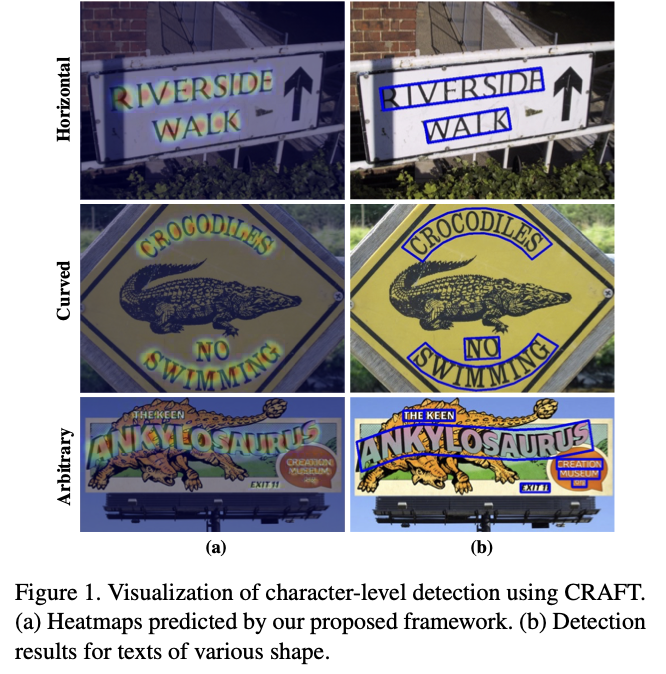
위 [Fig1]의 CRAFT 결과를 보면, horizontal text 뿐만 아니라, curved되어 있고 arbitrary형태의 text도 잘 detect한 것을 볼 수 있습니다. character level로 region을 검출했기 때문에 다양한 형태의 text를 쉽게 represent할 수 있다고 하네요.
2. Methodology
2.1. Architecture
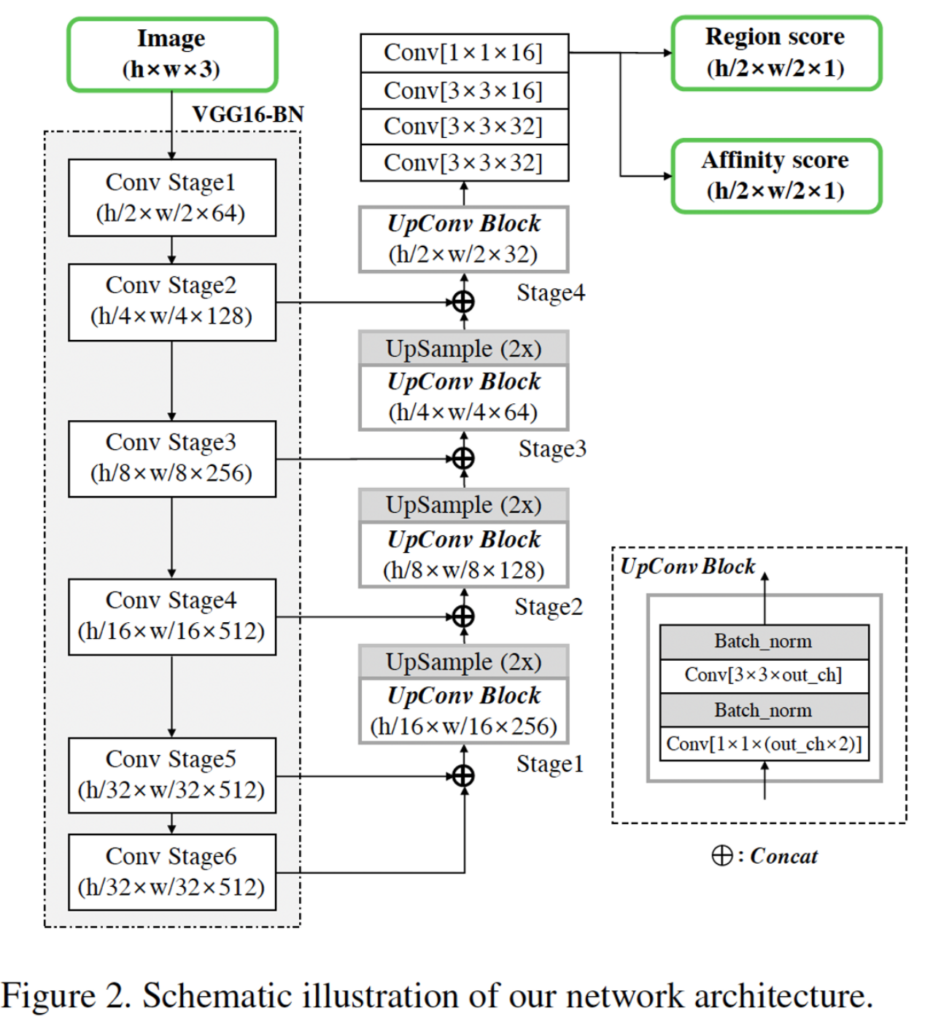
아키텍처는 굉장히 단순합니다.
- Fully convolutional network
- VGG16 with batch normalization
- skip connections in the decoding part
이것이 아키텍처의 전부로, decoder은 U-Net과 유사하게 low level의 feature를 aggregate하는 식으로 구성되어 있습니다. 또 앞에서 말한 것처럼 output으로 region score, affinity score 두 가지가 나온 것을 확인할 수 있네요.
2.2. Training
2.2.1 Ground Truth Label Generation
CRAFT모델을 학습하기 위해서는 character level bbox의 region score와 affinity score에 대한 gt가 존재해야 하겠죠.
- region score : pixel이 character center일 확률
- affinity score : 두 인접한 character 사이 center일 확률
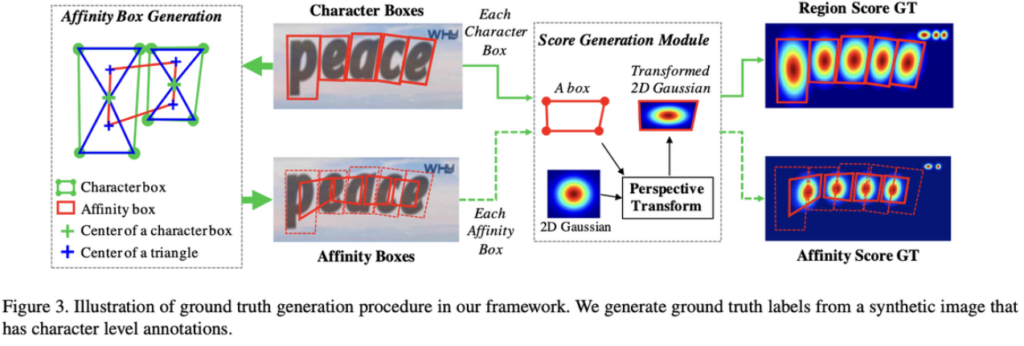
위 [Fig3]은 region score와 affinity score gt를 만드는 방법입니다. gt를 생성할 때 가우시안 히트맵을 사용하게 됩니다. text같은 경우 다양한 모양과 크기를 가지고, 배경과 유사한 색 또는 복잡한 패턴의 배경으로 인해 경계를 구분하기 어려울 수 있기에 binary segmentation map보다는 Gaussian heatmap 같은 연속 확률 분포를 사용한 것으로 볼 수 있습니다. 또 gaussian heatmap은 pixel간의 거리에 따라 가우시안 함수 형태로 픽셀 값을 할당하기 때문에 center에 가까운 픽셀일수록 높은 값을 갖게 되어 character의 region을 더 잘 표현할 수 있겠습니다.
본 모델이 학습할 때 사용한 데이터셋은 크게 synthetic dataset과 Real-word dataset으로 나눌 수 있습니다. 앞단에서 현존하는 대부분의 데이터셋은 character-level의 annotation을 제공하지 않는다고 언급하였지만 Synthetic dataset은 컴퓨터가 합성을 통해 제작한 텍스트 데이터셋이기에 character-level의 annotation이 존재합니다.
그래서 다시 [Fig3]이미지를 보면 character boxes가 존재하는 synthetic이미지에 대해 gt를 생성하는 파이프라인임을 확인할 수 있습니다. character box내의 각 pixel에 대해 일일이 gaussian 분포 값을 직접 계산하는 것은 시간이 많이 소요되며, perspective projection 과정에서 생기는 character bbox의 왜곡 때문에 다음과 같은 step을 통해 gt를 생성합니다.
How to generate GT for the region score
- 2D isotropic Gaussian map 준비
- Gaussian map region과 각 character box 사이 perspective transform 계산
- 변형된 Gaussian map을 원본 이미지의 bbox 좌표와 대응되는 label map 좌표에 warpping
How to generate GT for the affinity score
affinity box에 대한 annotation은 없기 때문에 affinity score gt를 생성하기 위해서는 먼저 affinity box부터 정의해야 합니다. [Fig3] 왼쪽 그림을 보시면 두 인접한 character box를 가지고 affinity box를 생성하는 것을 볼 수 있습니다.
- 각 character box에 대각선을 긋게 된다면 상하의 삼각형이 생기는데, 이 위쪽 삼각형과 아래쪽 삼각형의 중심점 구하기
- 인접한 두 문자에 대해 삼각형 중심점을 이었을 때 만들어지는 사각형이 affinity box
- 이 Box 가지고 위의 region score gt 만드는 방식 1, 2, 3 동일하게 진행
결국 character level의 bbox만 있다면 region score map과 affinity score map을 생성할 수 있겠습니다. 이전 word-level의 방법론들은 크기가 크거나 길이가 긴 text에 대한 box를 regression하기 위해 큰 receptive field가 필요했지만, 이런 방식으로 gt를 생성하게 된다면 작은 receptive field만으로도 잘 detect할 수 있습니다. character level의 detection은 convolution filter가 전체 text instance 대신에 오직 intra-character와 inter-character에 집중한다고 볼 수 있겠네요.
2.2.2 Weakly-Supervised Learning
character level의 annotation이 존재했던 synthetic dataset과는 다르게, real image dataset은 보통 word-level annotation만 존재합니다. 그렇기에 아래 [Fig4] 윗부분 회색 박스를 보시면 word-level의 annotation으로부터 character box를 생성하는 것을 볼 수 있습니다. Synthetic Image로 학습한 모델을 중간 모델이다 하여 Interim model이라고 칭하는데, 이 interim model을 이용해서 real image의 word-level annotation을 가지고 character level의 bounding box를 생성해내는 과정입니다.
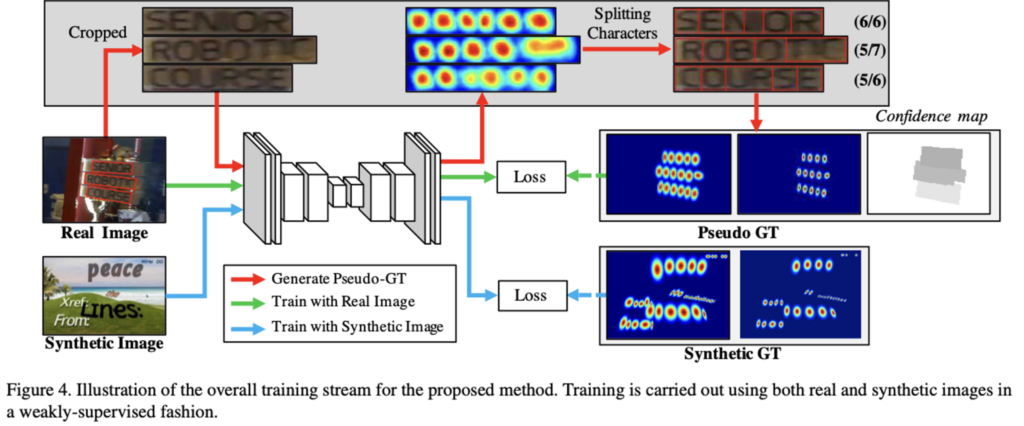
학습한 interim model을 이용해 word를 character로 split하는 과정을 좀 더 자세히 알아봅시다.
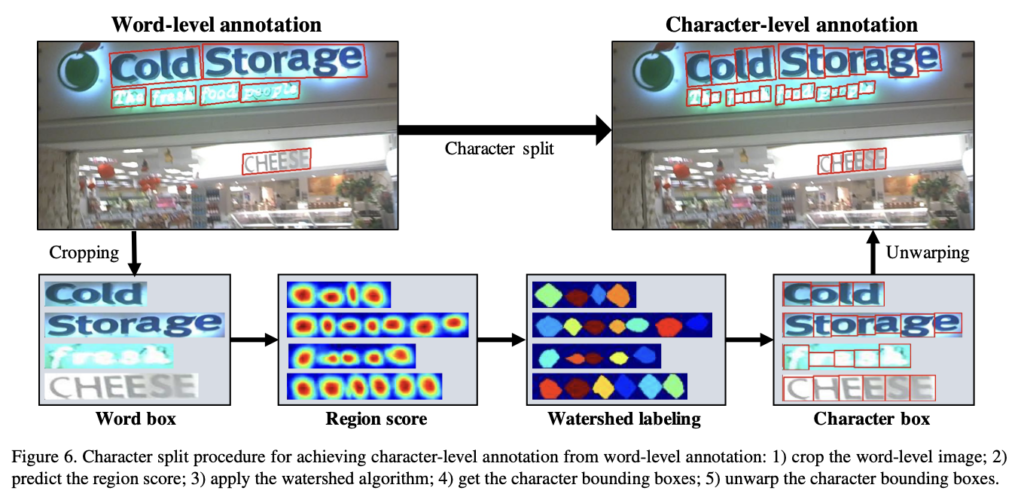
먼저 word-level로 annotation 되어 있는 real image를 word box 단위로 crop합니다. 그 다음 synthetic image로 학습한 interim model을 통해 word box의 region score를 예측하고 watershed 알고리즘을 이용해 character region으로 split한 후, 마지막으로 원래 이미지 좌표계로 되돌리기 위해 crop할 때 수행된 transform을 역으로 적용합니다. (character box의 좌표를 original image 좌표로 back transform)
watershed 알고리즘이란 영상의 pixel값을 높이로 생각하고 영상을 2차원 지형으로 가정한 후, 물을 붓는다면 물이 섞이는 부분이 생길 것인데, 그 부분에 경계선을 만들어 서로 섞이지 않게 할 때 그 경계선을 이미지의 구분지점으로 파악해 이미지를 분할하는 알고리즘입니다.
이렇게 word box를 character box로 split했다면, 아까 [FIg3]을 거쳐 region score, affinity score의 pseudo GT를 생성해 낼 수 있겠습니다.
이 방법으로 얻은 pseudo-GT는 interim model에 의해 얻은 것으로 불완전합니다. 이 부정확한 pseudo GT로 학습하게 된다면, 학습할 때에도 영향을 미치겠죠.(output character region이 blur하게 된다고 함.) 이를 막기 위해 pseudo gt에 대한 quality를 계산하여 학습에 반영하게 됩니다.
대부분의 text dataset의 annotation에는 단어의 길이 정보를 제공하는데, 이걸 가지고 pseudo gt의 confidence를 평가합니다. confidence score 계산 방법은 다음과 같습니다.
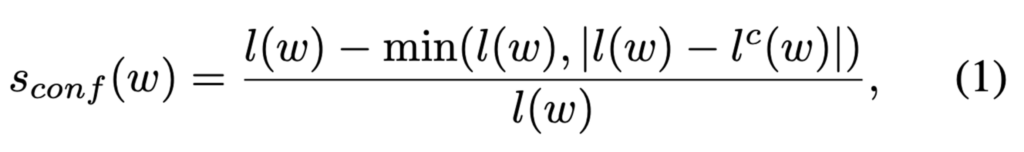
- l(w) : word 길이
- l^c : [Fig6]의 character split과정에서 얻은 character box 개수 (분할된 개수가 곧 word 길이)
결국 위 식(1)은 실제 단어 개수와 interim model에 의해 split된 character 개수 사이의 오차 비율을 계산한 것으로 볼 수 있습니다.
예를 들어 흐릿해서 잘 안보이지만,, 아래 ‘ROBOTIC’이라는 7의 단어길이(l(w) = 7)를 가지는 word box를 5개의 character box로 split했을 때의 confidence score를 계산해 본다면,

l(w)는 7, l^c(w)는 5로 식에 대입해보면
{7 – min(7, |7 – 5|)}/7이 되겠습니다. 정리해보면 위 그림에도 나와있듯이 5/7이 되겠네요 !
만약 confidence score가 0.5이하가 된다면 model학습에 부정적인 영향을 미칠 수 있으므로 interim model에 의해 예측된 character box를 그대로 사용하는 대신에 단순히 word box(R(w))를 단어 길이(l(w))로 나누어 사용하고, confidence score는 0.5로 설정합니다.
이미지의 각 word box에 대한 confidence score를 계산했다면 이를 이용해 pixel-wise confidence map을 만들어냅니다.
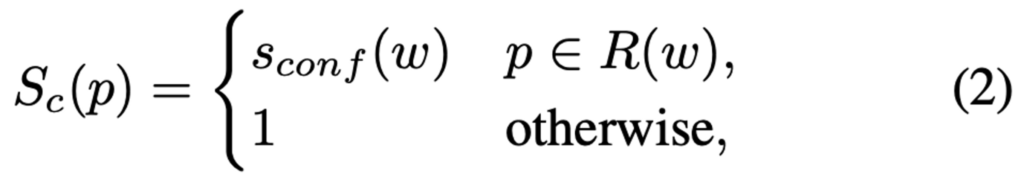
- R(w) : word의 bounding box region
- p : pixel
간단하게 이미지의 pixel이 word box내에 있다면 그 word box의 confidence score로 설정하고, 나머지는 전부 1로 설정하는 식이 되겠습니다. 이 confidence map은 loss에 들어가 있는데, pseudo gt에 대한 신뢰도를 반영하기 위한 것이기에 real gt가 존재하는 synthetic data로 학습할 때는 confidence map은 전부 1로 설정됩니다.
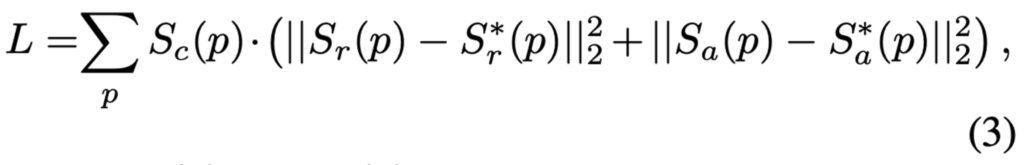
- S_r(p) : model이 예측한 region score
- S_a(p) : model이 예측한 affinity score
- S^*_r(p) : pseudo-gt region score
- S^*_a(p) : pseudo-gt affinity map
loss 식을 보면 pixel p에 대해 predicted region score와 pseudo gt region score 사이의 유클리드 거리 + predicted affinity score와 pseudo GT affinity map사이의 유클리드 거리가 최소화 되는 방향으로 학습하고자 함을 알수 있습니다. confidence score도 loss 계산에 사용되는데, 이는 즉 word box에 대응되는 pixel들에는 interim model이 예측한 character region의 정확도를 가중치로 부여한 것으로 보면 되겠습니다.
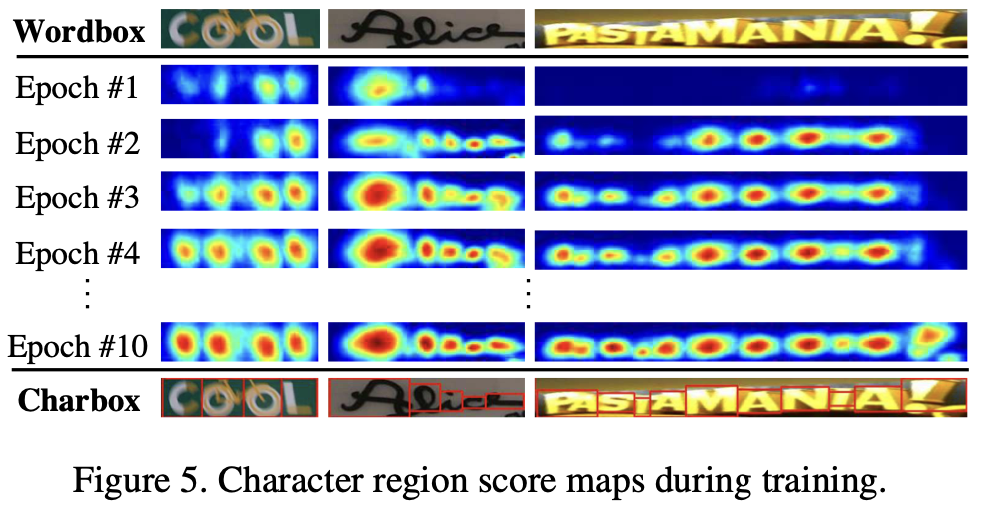
[Fig5]는 학습을 해 나갈수록 CRAFT 모델이 문자를 더 정확하게 예측하고 confidence score도 점차 증가하는 것을 보여줍니다. 학습 초기에는 상대적으로 text를 잘 인지하지 못하지만 학습을 진행하면서 불완전한 폰트나 합성된 text와 같이 새로운 모양의 text를 배우게 되는 것이죠.
학습 과정을 정리해보자면 character level의 annotation이 존재하는 synthetic dataset으로 interim model을 학습한 후, word level의 annotation으로부터 character level의 pseudo-gt를 생성해 weakly supervised learning을 하는 것이 되겠습니다.
2.3. Inference
이제 CRAFT model이 예측한 region score와 affinity score로 bbox를 생성하는 inference 과정입니다.
최종 output은 word box형태나 character box, polygon으로 나올 수 있는데 이는 test Dataset에 맞춰 각자 다른 형태의 box를 생성해내면 됩니다. 예를 들어 ICDAR과 같은 dataset의 경우 평가과정에서 IoU를 사용하기 때문에 word level의 bbox인 QuadBox를 생성하면 되겠습니다.
그럼 먼저 region score와 affinity score를 가지고 word level의 BBox(QuadBox)를 예측하는 과정을 알아봅시다.
QuadBox Inference
먼저 0으로 초기화된 binary map(M)을 준비하고, region threshold보다 region score가 큰 것들, affinity threshold보다 affinity score가 큰 pixel들에 한하여 M(p)를 1로 설정합니다. 이후 binary map M에 대해 Connected Component Labeling과정을 수행하고 이렇게 연결된 것들 중 최소한의 영역을 갖는 회전된 직사각형을 찾음으로써 QaudBox를 예측할 수 있게 됩니다. (여기서 CCL은 바이너리 맵에서 연결되어 있는 객체를 찾는 알고리즘입니다. CCL을 통해 각 word 영역을 구분하고 해당 영역을 둘러싸는 사각형을 최종 bbox로 사용한다고 보면 되겠습니다.)
CRAFT의 장점이라고 하면 여러 anchor box가 필요하지 않기 때문에 NMS와 같이 어떠한 후처리 작업이 필요없다는 점을 들 수 있겠네요.
다음은 polygon 형태의 bbox를 생성하는 과정입니다.
Polygon Inference
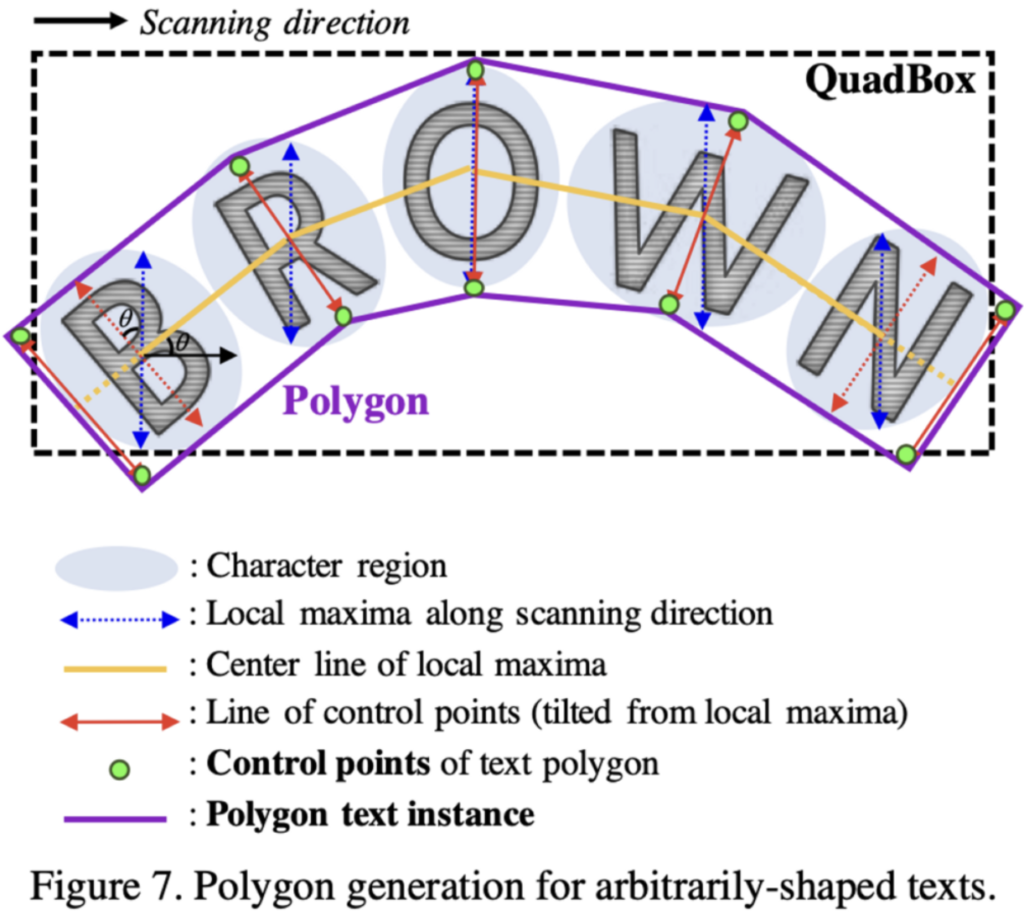
- 수직 방향을 따라 character region의 local maxima line을 찾습니다. (파란선)
- 최종 결과가 불균형해지는 것을 막기 위해 local maxima line은 quadbox내의 최대 길이로 동일하게 설정합니다.
- local maxima line의 중심점들을 연결합니다. (노란선 center line)
- text의 기울어진 각도를 반영하기 위해 center line에 수직하도록 local maxima line을 회전합니다. (빨간선)
- local maxima line의 endpoint는 다각형 control point의 후보점들이 됩니다. (연두색 점)
- text region을 완전 커버하기 위해 두 개의 가장 바깥쪽으로 기울어진 local maxima line들을 center line(노란선)을 따라 바깥쪽으로 이동시켜 최종 control point를 결정합니다.
지금까지 CRAFT의 학습 과정과 그로부터 나온 region score, affinity score를 가지고 quadbox와 polygon box를 생성하는 inference 과정을 알아보았습니다.
3. Experiment
실험에 사용된 데이터셋은 ICDAR13, 15, 17, MSRA-TD500, TotalText, CTW-1500입니다. 학습 과정에서 synthetic dataset과 real image dataset을 사용한다고 했었습니다. 합성 데이터셋인 synthText를 사용해 50000 iteration학습한 후, real image dataset을 사용해 모델을 fine-tuning했는데, 이 fine tuning과정에서도 SynthText 데이터셋을 1:5비율로 같이 사용하였습니다.
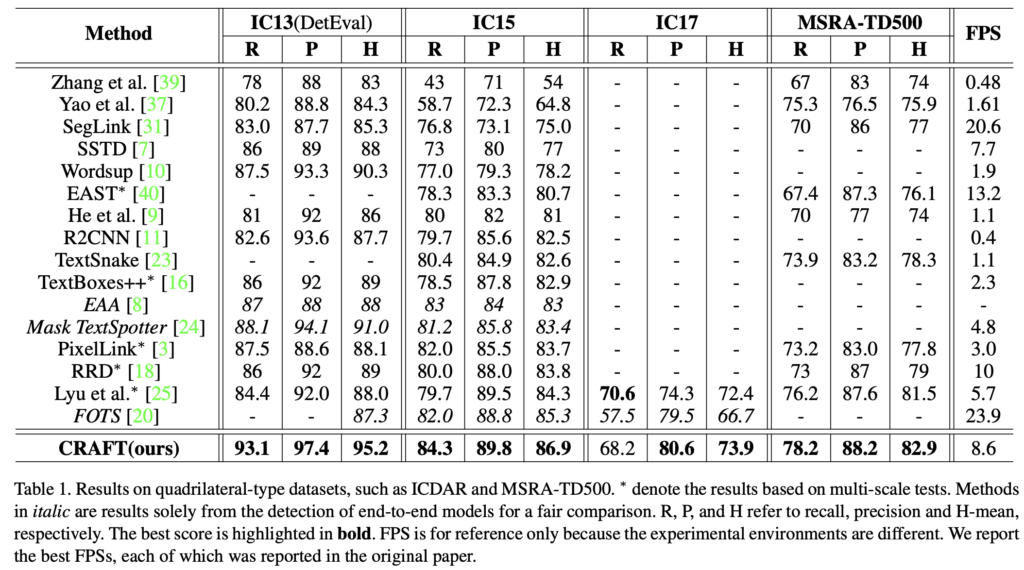
[Table 1]은 Quadilateral type dataset입니다. CRAFT가 모든 데이터셋에 대해 SOTA를 달성한 것을 볼 수 있습니다. 또 FPS를 보면 8.6으로 NMS 과정이 없기 때문에 비교적 빠른 속도로 동작함을 볼 수 있네요.
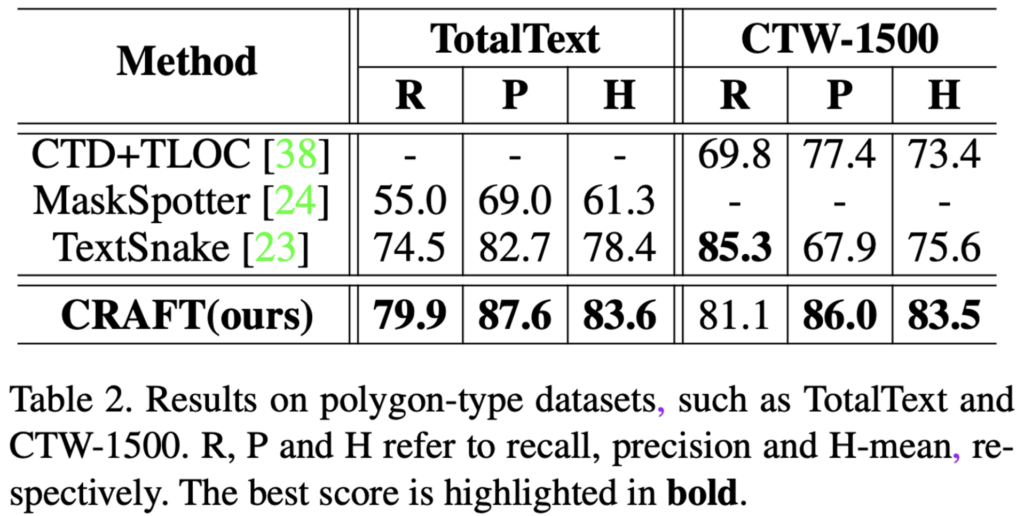
다음은 polygon type dataset인 TotalText와 CTW-1500에 대한 실험 결과입니다. 두 데이터셋의 annotation이 polygon 형태로 제공되기 때문에 weakly supervised learning으로 학습하는 과정에서 text region을 character box로 split하는 과정 등에 어려움을 겪었다고 하네요. 그렇기에 IC13, IC17의 train image를 추가로 사용했다고 하는데 공정한 비교가능한지는 잘 모르겠지만, CTW-1500의 recall을 제외하고 SOTA를 달성한 결과를 보여줍니다.
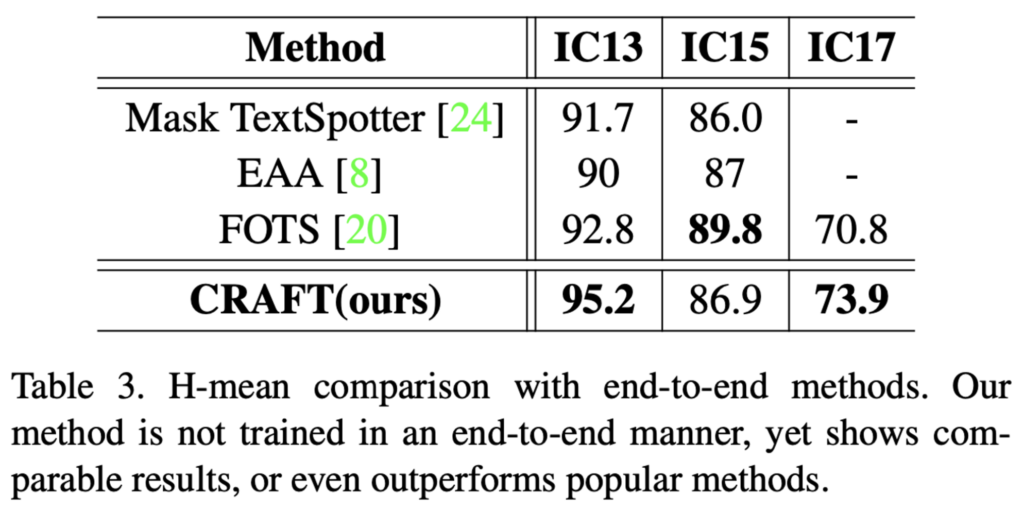
마지막으로 end-to-end 방법론들과 비교한 결과입니다. ocr task는 크게 text detection이랑 text recognition으로 나눌 수 있는데 본 CRAFT 논문은 text detection만 수행하는 모델이며, 여기서 end-to-end 방법론은 text detection과 text recognition을 같이 수행한 모델으로 보면 되겠습니다. IC15를 제외한 두 데이터셋에서 CRAFT의 성능이 가장 좋네요.

정성적 결과 보여주며 리뷰 마치도록 하겠습니다.
리뷰 잘 읽었습니다.
Synthetic 이미지로 1차적으로 학습한 뒤, 2차적으로 학습할때 real 이미지만 사용하는 것이 아닌 1:5의 비율로 섞어서 사용하는군요. 해당 부분에 대해서 궁금증이 있는데, real 이미지에 왜 굳이 조금의 synthetic 이미지를 섞어서 사용하는 것인가요??? 그냥 real 이미지로만 학습하는 것 대비 어떤 장점이 있을지 궁금합니다. 만약 저자의 견해가 없다면 윤서님의 개인적인 의견도 궁금하네요
안녕하세요 댓글 감사합니다.
fine tuning과정에서 synthText datset을 1:5 비율로 같이 사용하는 이유는 character region을 좀 더 확실하게 분리하도록 하기 위함입니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
affinity score라는 것을 구하는 이유는 결국 detection 결과를 word level bbox로 표현해야되기 때문에 인접해있는 두 character level bbox가 하나의 단어인지를 판단하기 위함이라고 이해해도 되는 걸까요?
네 그렇습니다.
안녕하세요 정윤서 연구원님 리뷰 잘 읽었습니다.
OCR에 대해서 관심이 생겨서 읽어봤는데요. 먼저 이 질문은 그냥 호기심에 질문드리는데… 글자(캐릭터)단위 예측을 수행할 때, 뒤집어도 같은 모양의 문자가 생기는데 이러한 경우에는 구분할 수 있는 방법이 있나요?
두번째로는 폴리곤을 형성하는 방식에서 연결된 유무는 어떻게 파악하는지를 따라가고 있었는데요. 갑자기 Connected Component Labeling과정이라고 하고 넘어가서… 영역 자체는 특정 알고리즘에 따라 찾는 것으로 보이는데 글자들이 연결되어 있다는 것은 어떻게 찾는건가요?
(세미나 듣고 추가 질문) 세미나에서 문제 정의로 캐릭터 단위의 예측을 수행하는 이유로 글자의 구분이 안가서 그렇게 한다고 했는데, quad box를 만드는 과정에서 affinity score를 이용해서 단순하게 결합 유무를 체크하는 것 같은데요. 이렇게 체크하면 문제 정의했던 부분이 해결이 되나요? (글자가 붙어있는 경우에는 여전히 인식이 어렵다는 문제가 있는거 아닌지?)
안녕하세요 ! 댓글 감사합니다.
1. character level 예측을 수행할 때 뒤집어도 같은 모양의 문자가 생긴다는 것이 어떤 의미인지는 잘 모르겠으나.. 뒤집어도 같은 모양이 나온다면 같은 것으로 예측할 것으로 추정됩니다.
2. 원본이미지와 같은 사이즈를 갖는 0으로 초기화 된 binary map에서 region score(p), affinity score(p)가 각각의 threshold보다 클 경우 해당 pixel을 1로 설정하게 됩니다.
그럼 문자가 있다고 예측한 부분 + 두 문자 사이라고 예측한 부분은 이진 맵에서 1의 값을 가질 것입니다. 이 binary map에 CCL 알고리즘을 적용하여 1로 연결되어 있는 pixel들을 동일한 객체로 봄으로써 text 영역을 구분한다고 보면 되겠습니다.
안녕하세요 좋은 리뷰 감사합니다.
중간에 weak-label의 quality를 계산해주기 위해 수식 (1)과 같은 loss를 두는데, 이러한 loss가 없이 noisy한 weak-label을 그대로 사용했을 때 output character의 경계가 blur해지는 이유는 여러 character가 묶여있는 박스를 하나의 character로 보고 학습하는 상황 때문인가요?
그리고 벤치마크 표 1에서 방법론마다 FPS의 스케일이 많이 다르긴 하지만, OCR task의 데이터 셋은 character 단위의 annotation을 제공하지 않다고 하신 점을 생각해 보았을 때 표 1의 방법론들은 전부 다 word 단위의 detection을 수행하는 것인가요? 그리고 multi-scale test를 수행한 방법론들은 *표시 되어 있는 것을 볼 수 있는데, 성능을 비교할 때 어떤 점을 고려하면 되는 것인가요?
표 2 캡션에 R, P, H가 무엇인지 쓰여있긴 하지만 나중 리뷰에서는 평가 지표가 무엇인지 간단히 적어주시면 좋을 것 같습니다.
안녕하세요. 댓글 감사합니다.
1. noisy한 weak label을 그대로 사용했을 때 output 경계가 blur해지는 이유에 대한 언급은 없었지만 ,, 현우님이 말하신 것처럼 실제 gt는 여러 character로 나눠져 있지만 그 박스를 하나로 보고 학습하기 때문이라고 볼 수 있겠습니다.
2. 아니오. method 중 zhang et al. Yao et al. SegLink, SSTD는 character level text detection입니다. 또 *표시된 multi-scale test를 수행한 방법론이랑 single scale 성능을 비교할 때는 어떤점을 고려하는지는 정확히 모르겠네요 . . 저는 그냥 성능 수치만 보고 비교하긴 했습니다만 …
3. 넵 다음부터 적도록 하겠습니다. 감사합니다.