안녕하세요 허재연입니다. 첫 번째 X-Review입니다. 종강 이후 예전 논문부터 원복을 진행하고 있는데, 이전 ResNet 원복 이후 금주에는 DenseNet 원복을 진행했습니다. 이번 주 내내 이 논문을 읽었던 터라 X-Review에 남기고자 합니다. 리뷰 시작하겠습니다.
RCV 연구원분들께서는 ResNet에 익숙하실 텐데, DenseNet은 ResNet을 베이스로 발전시킨 느낌이 강하게 드는 모델입니다. 실험 세팅도 ResNet과 동일하게 되어있고, 실험 비교도 ResNet과 이를 기반으로 발전시킨 모델들이 사용됩니다. 예전 논문이라 요즘 나오는 모델들에 비해서는 구조가 복잡하지 않으니, 편하게 읽어주시면 되겠습니다.
Abstract
당시 연구에 따르면, convolutional network는 ‘input에 가까운 계층’과 ‘output에 가까운 계층’ 간 더 짧은 연결을 포함시키면 더 깊게 쌓을 수 있고, 더 정확하며, 훈련시키기에도 효율적일 수 있다고 합니다. 본 논문에서는 이런 관측을 받아들이고, 각 계층에서 다른 모든 계층에 feed-forward 방식으로 연결하는 Dense Convolutional Network(DenseNet)을 소개합니다. L개의 layer를 가지는 기존의 convolutional network는 L개의 연결(각 layer과 후속 layer 사이)을 가지는데, DenseNet은 L(L+1)/2개 (1부터 L까지의 합으로 생각하시면 됩니다) 의 direct connection을 가집니다. 각 계층에 대해, 선행하는 모든 계층의 feature map은 그 계층의 입력으로 사용되고, 해당 계층의 feature maps는 이후 모든 계층의 입력으로 사용됩니다. DenseNet은 vanishing-gradient 문제를 완화하고, feature propagation을 강화하고, feature reuse가 가능하게 하고, parameter 수를 수를 크게 줄이는 강력한 이점이 있다고 합니다. 저자들은 CIFAR-10, CIFAR-100, SVHN, ImageNet에 대해 성능을 평가했으며, DenseNet은 기존 SOTA모델보다 상당한 개선을 보였고, 동시에 적은 연산량이 필요하다고 합니다.
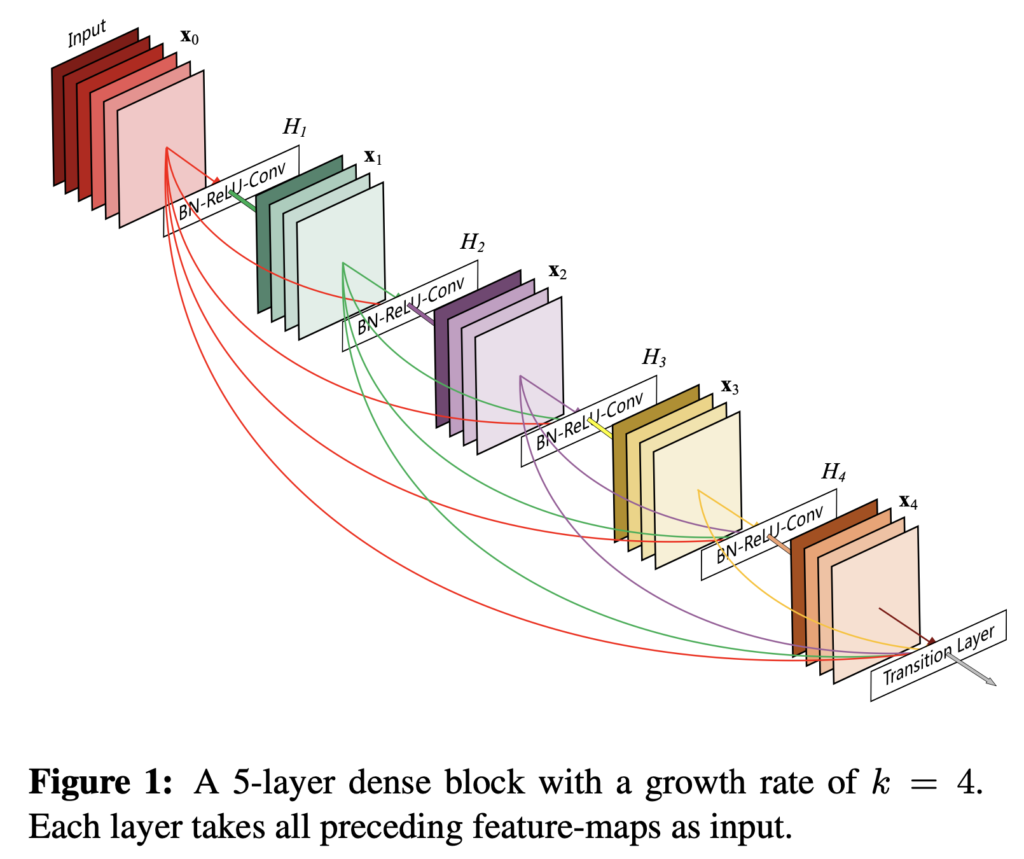
Introduction
CNN은 시각적 객체 인식을 위한 일반적인 머신러닝 접근법이 되었습니다. CNN도입은 20년 전의 일이지만, 컴퓨터 하드웨어와 네트워크 구조의 개선으로 이제야 깊은 CNN 훈련이 가능해졌습니다. 특히, 논문이 작성된 시기에 제안된 ResNet, Highway Networks는 identity connection을 이용해서 신호를 우회적으로 전달하는 기법을 이용해 image recognition에서 상당한 성능 개선을 이루었습니다. 이외에도 다양한 접근법들이 network topology나 훈련 과정에 따라 다양하게 제안되고 있기는 하지만, 이들 모델은 앞쪽 layer에서 뒤쪽 layer까지 short path를 만든다는 특징을 공유합니다.
저자들은 이런 구조에서 인사이트를 얻어 간단한 연결 패턴을 통해 네트워크 안에 있는 계층 간 정보 흐름을 극대화시키는 구조를 제안합니다. 말 그대로 featuremap size가 동일한 모든 계층을 전부 연결해 버립니다. feed-forward 특성을 보존하기 위해, 각 계층은 이전의 모든 계층에서 추가적인 input을 받은 뒤 그 뒤에 있는 모든 계층에다 전달합니다(위의 Figure1을 참고하면 이해가 쉬울 것입니다). 특히 ResNet과 다른 점은 정보를 뒷단 계층에 넘길 때 단순히 합하는(summation) 방식을 사용하지 않고 concatenating하는 방식으로 featuremap을 쌓아서 전달한다는 점입니다. 그럼 l번째 계층은 이전 모든 convolutional block의 featuremap으로 구성된 input을 받을 수 있습니다. 이렇게 빽빽히 계층간을 연결한 구조에서 DenseNet이라는 이름을 붙이게 되었다고 합니다.
Densely connectivity pattern을 보면 연산량이 굉장히 많아질것처럼 보이지만, DenseNet구조는 중복되는 featuremap을 재학습할 필요가 없어 더 적은 파라미터가 필요하다고 합니다. 이전의 feed-forward 구조는 layer에서 layer에서 전달되는 state(처리되는 정보 정도로 생각하시면 될 것 같습니다)로 볼 수 있는데, 각 계층은 바로 이전 계층에서 전달된 state를 읽고 재작성해서 뒷단의 계층으로 전달합니다. 각 계층은 state를 계속 변화시키는데, 동시에 state는 보존될 필요성도 있다고 합니다(뒷단으로 갈수록 원본 정보가 변형되니 원본 정보 또한 유지할 수 있으면 좋겠죠). 이런 정보 보존을 additive identity transformation로 해결한 모델이 바로 우리가 익히 알고 있는 ResNet입니다. 하지만 저자들은 ResNet의 파라미터가 너무 많다고 합니다. DenseNet은 추가되는 정보와 보존되는 정보가 명시적으로 구별되고, 각 layer에서 새로 뽑아내는 channel이 많지 않음에도 불구하고 좋은 성능을 보인다고 합니다(convolution을 한번 거칠 때 출력 채널 수를 12나 24로 설정합니다)
파라미터 효율성 이외에도 , DenseNet 의 장점으로는 네트워크 전체의 정보 흐름이 개선되어서 학습이 훨씬 용이하다는 것입니다. 각 계층은 loss function으로부터의 gradient와 input signal에 직접 접근할 수 있어서 학습에 강점을 보인다고 합니다. 추가적으로 저자들은 dense connection의 regularizing effect까지 관측해서 작은 training set의 overfitting을 막을 수 있었다고 합니다 (구체적으로 어떻게 regularizing effect를 확인한건지 찾아보았는데 그에 관련된 추가적인 설명은 못 찾았습니다..)
DenseNet은 CIFAR10, CIFAR100, SVHN, ImageNet 4가지 벤치마크 데이터셋에서 평가되었고, 기존 알고리즘보다 훨씬 적은 파라미터로 더 좋은 성능을 달성했다고 합니다.
DenseNet
표기상 ℓ번째 layer에서 비선형 변환을 Hℓ(·) (배치 정규화, ReLU, Pooling, Conv같은 연산으로 구성) → ℓ번째 층의 output을 xℓ이라 합니다. 참고하시면 되겠습니다.
DenseNet의 Hℓ(·)는 배치 정규화, ReLU, 3×3 Conv 3가지 연속 연산의 합성함수입니다.
ResNet
ResNet은 identity function을 이용해 비선형 변환을 우회하는 skip-connection을 추가했습니다.
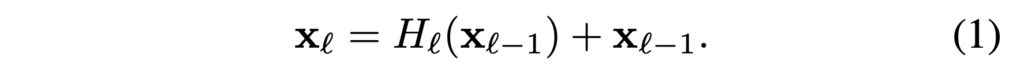
ResNet의 장점은 identity function을 통해 gradient가 뒤쪽 layer에서 앞쪽 layer로 흘러갈 수 있다는 것입니다. 하지만, identity function과 Hℓ의 출력은 덧셈(summation)으로 결합하는데, 이는 네트워크에서 정보의 흐름을 방해(impede)할 수 있다고 합니다.
Dense connectivity
계층 간 정보 흐름을 더욱 개선하기 위해 저자들은 모든 layer에서 모든 후속 layer로 direct connection을 도입합니다. 결과적으로, ℓ번째 layer은 이전의 모든 layer로부터 feature-map x0, . . . , xℓ−1를 input으로 받습니다.
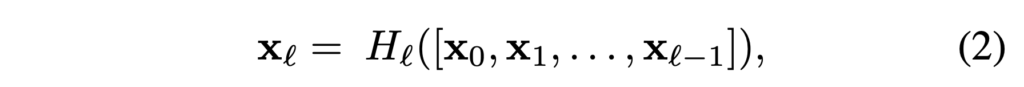
[x0, x1, ., xℓ-1]은 0, … , ℓ-1 계층에서 생성된 feature-map을 concatenate한 것입니다. 구현의 편의를 위해, Hℓ(·)의 multiple input을 하나의 텐서로 concatenate한다고 합니다.
Pooling layer
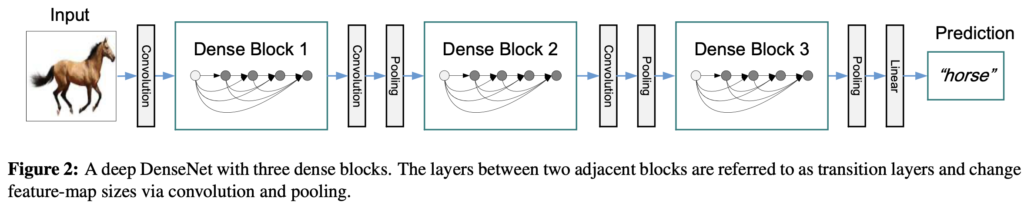
(2)번 수식의 concatenation연산은 feature-map 크기가 바뀌면 실행이 불가능합니다. 하지만, convolution network에서 feature-maps의 사이즈를 조정하는 down-sampling layer는 필수적인 부분입니다. 네트워크 구조 안의 down-sampling을 위해서, 저자들은 네트워크를 dense blocks로 나눠 구현합니다. (한 블럭 안에서 그림과 같이 dense connection이 이루어집니다) 그리고, block 사이에 convolution과 pooling을 수행하는 transition layers를 배치합니다. 실험에 사용된 transition layers는 배치 정규화, 1×1 convolution layer, 2×2 average pooling layer로 구성되었습니다.
Growth Rate(k)
각 함수 Hℓ가 k개의 feature-maps를 생성하면, ℓ번째 계층은 k0+k×(ℓ−1)개의 input feature-maps를 갖게 됩니다(k0은 input layer의 채널 수). DenseNet과 기존 네트워크 구조의 중요한 차이점은 DenseNet이 k=12와 같은 매우 좁은(논문에서는 narrow라고 표현하는데, output 채널이 크지 않다고 생각하시면 되겠습니다) layer를 가질 수 있다는 것입니다. 저자들은 하이퍼파라미터 k를 네트워크의 성장률(growth rate)이라고 부릅니다. k개 개수만큼 concatenation할때 feature map tensor가 얼마나 커지는지 달라지기 때문이죠. 실험 결과 작은 growth rate도 SOTA를 얻기에 충분했다고 합니다(이는 파라미터 수 감소로 이어집니다). 각 계층은 block 안에 모든 선행하는 feature-map(collective knowledge라고 함)에 접근할 수 있으며, 이런 feature maps를 network의 global state라고 볼 수 있다고 합니다. growth rate는 각 계층이 global state에 기여하는 새로운 정보의 양을 조절하게 됩니다. global state는 (모든 계층이 서로 연결되어 있으므로)한번 작성되면 네트워크의 어디서든 접근이 가능하며, 전통적인 네트워크 구조와 달리 계층 간에 replicate될 필요가 없다고 합니다.
Bottleneck Layer
1×1 Conv는 3×3 Conv 이전에 bottleneck으로 도입되어 입력 featuremap의 수를 줄이고, 계산 효율을 높일 수 있습니다. 저자들은 (BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3) 버전 Hℓ의 Bottleneck layer를 가진 네트워크를 DenseNet-B라고 부릅니다. 실험에서는 1×1 convolution이 4k feature-map을 생성하도록 합니다.
Compression
모델의 간결성을 개선하기 위해 transition layer에서 feature-maps 수를 줄일 수도 있습니다. dense block이 m개의 feature-maps가 포함하면, 이어지는 transition layer가 ⌊θm⌋개의 output feature-map를 생성하게 합니다( (0 <θ ≤1)은 여기서 압축 계수입니다 θ=1일 때, transition layers의 feature-maps의 수는 바뀌지 않습니다)
저자들은 θ<1의 DenseNet을 DenseNet-C라고 부르고, 실험에서 θ=0.5로 세팅합니다. Bottleneck과 θ<1의 transition layers가 모두 사용된 모델을 DenseNet-BC 라고 부르고, 실험에서도 사용됩니다.

위의 표를 참고하면 4개의 dense block, 3개의 transition layer로 구성되었으며, bottleneck이 적용된것을 확인할 수 있습니다. ResNet도 그렇고, 첫번째 convolution은 7×7, stride 2로 설정하고 이후에 풀링을 적용해 featuremap size를 작게 조정하고 시작하는건 ImageNet dataset에 대한 공통적인 사항인것 같습니다.
Experiment
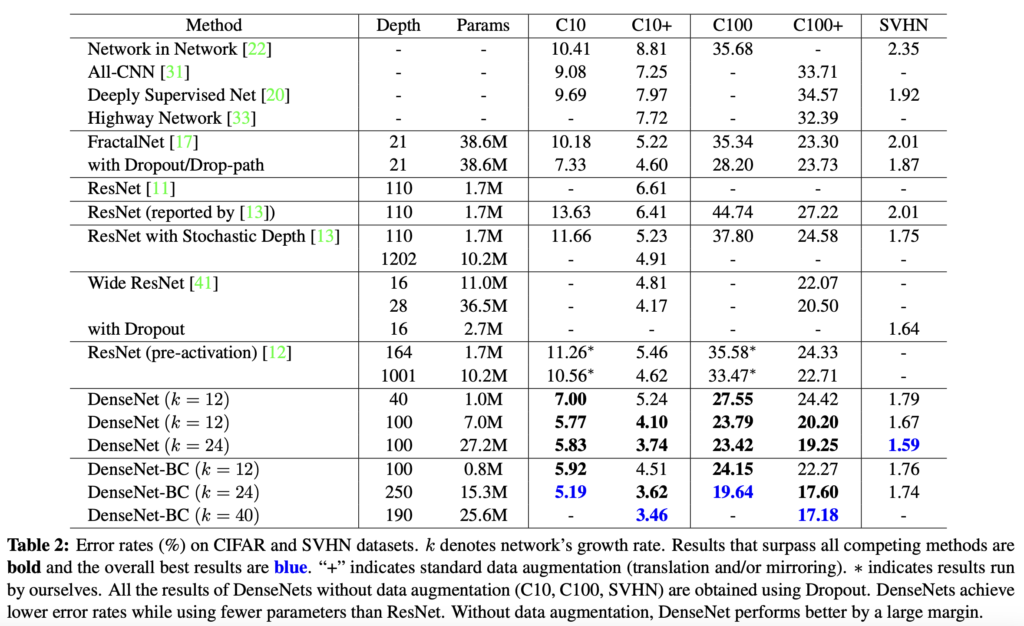
실험은 CIFAR, SVHN, ImageNet 데이터셋으로 수행되었습니다. data augmentation에 관련해서는 널리 사용되는 기법을 사용했다고 하고 이전 SOTA 모델 논문들을 citation 걸어버렸습니다 (..) random crop, 정규화, horizontal flip을 생각하시면 될 것 같습니다.
실험 결과를 보시면 DenseNet이 기존의 다른 모델들보다 압도적으로 작은 error rate를 보이는것을 확인할 수 있습니다. 특히 CIFAR-100에 대해서는 pretrained된 ResNet보다 10%에 가까운 개선을 보였습니다.
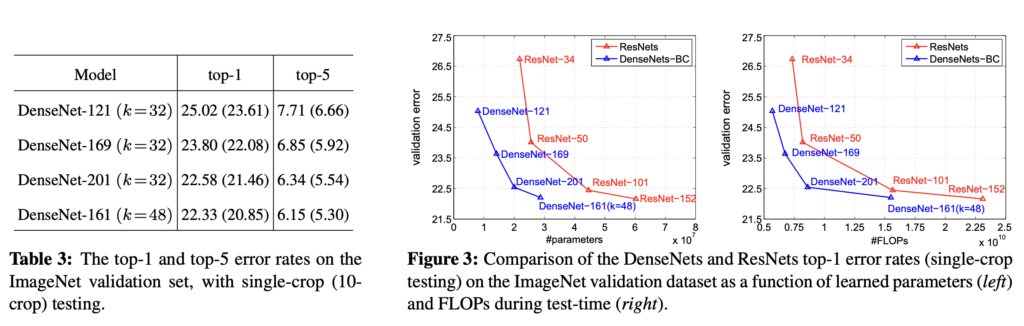
ImageNet 데이터셋에 대한 실험 결과입니다. Figure3을 보면 동일한 validation error에 대해 DenseNet의 파라미터 수가 ResNet의 파라미터 수보다 상당이 작은 것을 볼 수 있습니다. ResNet도 이전 모델보다 상당히 깊게 쌓을 수 있었는데, DenseNet은 ResNet보다도 훨씬 깊으면서 동시에 파라미터 수도 적게 구현될 수 있었습니다.
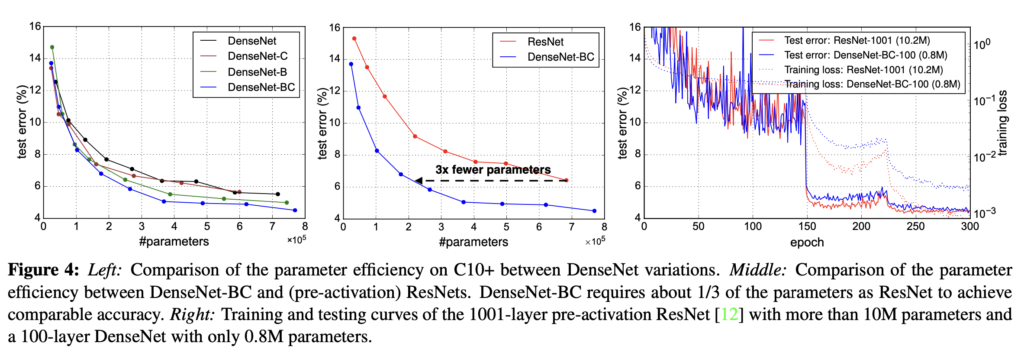
CIFAR10에 대한 실험결과입니다. 기본적인 DenseNet과 이에 compression, bottleneck 구조를 추가한 DenseNet-BC를 비교하고, ResNet과 파라미터 수를 비교합니다. 가운데 그래프에서 DenseNetBC가 ResNet보다 3배나 적은 파라미터를 가지고 있는게 눈에 띕니다.
오른쪽 그래프는 epoch수에 따른 test error입니다. 총 300epoch 학습되었으며, 중반까지는 error가 fluctuate한 모습을 보이다 50%, 75% 구간에서 안정되는것을 확인할 수 있습니다. 실험의 하이퍼파라미터 설정을 참고하면, 초기 learning rate를 0.1로 매우 크게 설정하고, 50%, 75%구간에서 10분의 1씩 learning rate를 줄여나갑니다. 개인적으로 초기 learning rate를 더 작게 설정해도 되지 않나, learning rate가 너무 큰 것 아닌가 하는 생각이 들었는데, CIFAR-10 데이터셋 자체가 한 장당 32×32픽셀의 크기를 가지는 비교적 덜 복잡한 데이터셋이어서 이와같은 설정을 했다고 받아들였습니다.
Conclusion
저자들은 DenseNet에서 모든 계층을 서로 연결시켜 학습을 용이하게 하고, 파라미터도 크게 줄일 수 있었습니다.
URP때 모델 성능을 올리기 위해 참조하던 다양한 기법들이 오랜만에 보이기도 해서 신기했습니다. 처음으로 써 본 X-Review인데, 부족한 점 있다면 피드백 주시면 앞으로 계속 리뷰 작성할 때 참고하도록 하겠습니다.
안녕하세요. 리뷰 잘 보았습니다.
리뷰를 보면서 생긴 질문들 남깁니다.
리뷰 내용 중에 “Densely connectivity pattern을 보면 연산량이 굉장히 많아질것처럼 보이지만, DenseNet구조는 중복되는 featuremap을 재학습할 필요가 없어 더 적은 파라미터가 필요하다고 합니다.” 라고 말씀해주셨는데 이부분에 대해서 보다 구체적인 설명이 가능하신가요? 중복되는 feature map이라고 함은 이전 layer에서 계산된 feature map을 의미하는 것 같은데 해당 feature map들이 concat하여 현재 layer의 입력으로 사용되게 된다면 결국 해당 feature map들이 모델 학습에 사용되는 것 아닌가요? 재학습을 할 필요가 없다 라는 표현을 놓고 보면 마치 모델 학습에 사용되지 않는 것으로 보여지기 때문에 명확하게 표현을 해야할 것 같습니다.
두번째로 “global state는 (모든 계층이 서로 연결되어 있으므로)한번 작성되면 네트워크의 어디서든 접근이 가능하며, 전통적인 네트워크 구조와 달리 계층 간에 복사될 필요가 없다고 합니다.” 라는 내용은 무슨 의미인가요? global state라는 것이 이전의 모든 계층에서 출력된 feature map들의 집합이라고 이해를 했는데, 이러한 feature map(global state)가 계층 간에 복사가 필요없다는 말은 어떤 의미로 받아들이면 되나요? 이전 방법론들(전통적인 네트워크 구조?)은 계층 간에 복사를 한다는 것처럼 들리는데 계층 간에 복사의 의미 및 이전 방법론들과의 예시를 비교하면서 설명해주면 좋겠습니다.
세번째로, bottleneck layer 부분에서 설명으로는 3×3 conv layer 전에 1×1 conv layer를 통하여 feature map의 채널을 줄여주는 역할이 수행되는 것을 bottlectneck layer라고 하셨습니다. 근데 densenet에서는 bottlectneck layer 역할을 수행하는 1×1 conv가 feature map의 채널을 4*k로 바꿔준다고 말씀해주셨는데, 이게 원래 어떤 값에서 4*k로 됐다는 것인가요? bottleneck layer의 의미로 보았을 때는 기존에 8*k, 16*k 정도의 값이었는데 이를 4*k 수준으로 줄였다는 것인가요? 아니면 k에서 4*k로 늘어났다는 의미인가요?
마지막으로, 실험 섹션에 대해서 조금 더 친절하게 작성해주면 좋을 것 같습니다. 현재 실험섹션은 표와 그림만 존재하고 추가적인 설명 등은 없는 것 같습니다. 실험 결과에 대한 (저자 혹은 본인의) 분석이라던지, 저자가 논문에서 densenet이 resnet보다 더 좋은 이유에 대한 분석 혹은 보다 강조하고 싶은 점(e.g., 정확도 뿐만 아니라 모델 크기나 속도에서 몇배 차이나는지) 등을 설명해주면 좋은 리뷰가 되지 않을까 싶네요.
댓글 감사드립니다. 하나씩 답변 드리겠습니다.
1. 해당 부분은 논문의 ‘it requires fewer parameters than traditional convolutional networks, as there is no need to relearn redundant feature-maps’ 라고 쓰여져 있는 부분을 직역한 것인데, 설명이 부족했던 것 같습니다. 저자는 DenseNet 의 구조를 ResNet과 비교하며, DenseNet은 이전 레이어의 정보를 온전히 보존하며 새로운 정보를 더하므로 다른 모델과 비슷한 성능을 내기 위해 필요한 convolution의 output 채널수가 비교적 적게 필요해 파라미터 수를 줄였다고 합니다. 저는 여기서 output channel수를 획기적으로 줄였으므로 이를 중복되는 정보를 재학습시키는걸 완화시켰다는 맥락으로 이해했습니다.
2. global state는 신정민 연구원님이 말씀하신것과 같은 의미로 이해했습니다. 각 layer는 block 안에서 이전 feature-map을 전부 받는데, 이를 “collective knowledge”라고 부르며 network의 global state라고 말합니다. 복사는 replicate를 직역한 것인데, 복사라는 말 보다는 반복이라는 용어가 더 알맞은 것 같네요. layer to layer로 (기존 네트워크 같은 경우는 반복적으로 layer 순서대로 featuremap이 전달되었죠) 건내주는것이 아니라, 서로 떨어져있는 layer간에도 연결되어 있어서 정보를 전달할 수 있다는 뜻으로 이해했습니다.
3. 채널을 4k로 줄인다는 말은.. bottleneck을 사용하지 않는 구조에서는 convolution이 k0+k(l-1)개의 채널을 받아서 k개의 output channel을 만드는데, bottleneck구조 같은 경우 1×1 convolution에서 k0+k(l-1)개의 input channel을 받아 4k의 channel을 바로 뒤의 3×3 convolution에 넘겨주고, 3×3 convolution은 k개의 output을 만들어서 결국 bottleneck구조에서의 입장에서 보면 k0+k(l-1)개의 input channel, k개의 output 채널을 만들게 됩니다. bottleneck 내부에서 4k개의 채널을 만드는 부분이 있다고 보시면 됩니다.
추가적으로, Experiment에 대한 설명을 추가했습니다. 앞으로는 이런 부분도 꼼꼼히 챙기도록 신경쓰겠습니다. 좋은 피드백 감사드립니다 !
안녕하세요 허재연 연구원님 리뷰 잘 읽었습니다.
각 계층은 loss function으로부터의 gradient와 input signal에 직접 접근할 수 있어서 학습에 강점을 보인다고 설명이 되어있는데, 블록 내부에서 feature맵이 연결된다고 하더라도 블록 넘어갈때, 풀링을 수행하기 때문에 이 부분이 어떻게 작동하는지 잘 모르겠습니다. 이 부분에 대한 추가 설명 부탁드립니다
사실 저도 이해하기 힘든 부분 중 하나였습니다. introduction에서는 모든 layer가 loss function에 direct로 연결되어 있다고 해서 마치 transition layer를 거치기 이전의 layer들도 featuremap을 그대로 output쪽으로 전달하는 것처럼 표현합니다. 하지만 사실 concatenation으로 feature map을 그대로 연결하는 구조는 각 block 내부에서만 일어납니다. (concatenation하기 위해서는 featuremap size가 일치해야 하므로 다른 block간 concatenation은 불가능합니다). 저는 해당 부분을 읽을 때 block간 단절이 두번 있긴 하지만 block 안에서는 완전히 연결되어있으므로 signal의 forward pass나 gradient의 backward pass가 전체 네트워크에서 (비교적)매우 긴밀하게 일어난다는 뜻으로 받아들였습니다. 해당 부분에 대한 부연 설명을 했으면 좋았을 것 같습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
[ResNet, Highway Networks는 identity connection을 이용해서 신호를 우회적으로 전달하는 기법을 이용해 image recognition에서 상당한 성능 개선을 이루었습니다] 라고 하셨는데 여기 identity connection이 제가 아는 resnet의 skip connection과 동일한 것일까요 .. ?
또, transition layer에서 theta parameter를 이용해 feature map 수를 줄일 수도 있다고 하셨는데, 그럼 이 채널 수를 줄이는 과정은 transition layer의1×1 conv를 통해 이루어지는 것이라고 보면 될까요 ?
마지막으로 densenet에서 사용되는 bottleneck layer는 resnet의 bottlenect layer 구조와 동일한가요 ? 기억하기로는 resnet의 bottlenect layer는 1×1 conv, 3×3 conv 후 1×1 conv가 추가적으로 있었던 것 같은데 densenet은 마지막 1×1 conv가 없는 것 같아 이에 대한 이유나, 구조를 바꿈으로써 얻은 이점같은게 있는지 궁금합니다. .
감사합니다 ! !
정윤서 연구원님, 댓글 감사드립니다.
1. identity mapping은 resnet의 shortcut connection의 한 종류입니다. resnet의 skip connection이 맞습니다. ResNet은 shortcut path를 통해 앞쪽 정보를 뒤쪽에 더하게 되는데, 이 때 단순 덧셈을 하는것이 identity mapping입니다(단순 덧셈이므로 여기에는 parameter가 없습니다). shortcut path를 통해 뒤쪽으로 가져온 텐서와 더해야 하는 텐서의 차원이 맞지 않는 경우에는 linear projection을 통해 차원을 맞춰주게 됩니다.
2. 네 맞습니다. transition layer는 BN, 1x1conv, avg pooling으로 이루어지는데 여기서 theta를 이용한 조정은 conv를 통해서, downsampling은 avg pooling을 이용합니다.
3. ResNet과 DenseNet의 bottleneck 구조에는 차이가 있습니다. 말씀하신 것처럼 resnet의 bottleneck 구조는 1×1,3×3,1×1 convolution이 순차적으로 일어납니다.(ResNet 논문에는 training time에 대한 이슈로 인해 building block을 bottleneck 구조로 바꾸었다고 합니다). 앞쪽과 뒤쪽의 1×1 convolution은 차원을 줄였다가 다시 복구하는 역할을 합니다. 여담으로 ResNet의 bottleneck구조에서는 identity shortcut을 사용하는것이 효율적이라고 합니다(identity가 아닌 projection을 사용하면 shortcut이 고차원 끝단으로 연결되어 시간복잡도 및 모델 사이즈가 두배 가까이 증가한다고 하네요). 반면, table1의 모델 구조에서 확인할 수 있듯 DenseNet의 bottleneck은 1×1, 3×3 convolution으로 구성되어 있습니다. 정확히는 Hℓ이 BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3)로 구성되었다고 이해하시면 될 것 같습니다.
안녕하세요. 허재연 연구원님의 첫 번째 리뷰 잘 읽었습니다.
리뷰 글에 대해서는 위 많은 연구원 분들께서 친절히 설명해주신 것 같아 간단한 질문 하나 남기며 마무리하겠습니다.
당연한 듯 받아들이고 넘어갈 수도 있는 부분인데, 처음에 설명해주신 “‘input에 가까운 계층’과 ‘output에 가까운 계층’ 간 더 짧은 연결을 포함시키면 더 깊게 쌓을 수 있고, 더 정확하며, 훈련시키기에도 효율적일 수 있다”는 말의 의미가 완벽히 와닿지는 않아 궁금합니다. 이 때 말하는 짧은 연결이란 무엇을 의미하나요? 단순히 input에 가까운 계층과 output에 가까운 계층 간 연결인가요?
이상인 연구원님의 질문은 ‘당시 연구에 따르면, convolutional network는 ‘input에 가까운 계층’과 ‘output에 가까운 계층’ 간 더 짧은 연결을 포함시키면 더 깊게 쌓을 수 있고, 더 정확하며, 훈련시키기에도 효율적일 수 있다고 합니다. 본 논문에서는 이런 관측을 받아들이고, 각 계층에서 다른 모든 계층에 feed-forward 방식으로 연결하는 Dense Convolutional Network(DenseNet)을 소개합니다.’ -> 이 부분에 대한 질문인듯 합니다.
해당 부분은 shortcut path를 도입한 ResNet 이후 backbone model들의 발전 맥락에서 이해하시면 될 듯 합니다. ResNet 이후 많은 모델들이 네트워크의 앞단과 뒷단을 직접적으로 연결하는 구조를 발전시키고 있었고, 이는 계층간의 거리가 가까워졌다고도 볼 수 있습니다. 여기서 말하는 ‘짧은 연결’은 실제로 input쪽과 output쪽 layer가 가까이 붙어있다는 뜻 보다는, 직접적인 연결을 통해 앞단-뒷단 간의 정보나 gradient의 흐름이 용이해졌다는 의미로 받아들이시면 좋을 것 같습니다.
안녕하세요 허재연 연구원님 좋은 리뷰 감사합니다.
densenet과 resnet의 구조를 비교하면서 리뷰를 읽어보았는데요, 단순히 두 모델의 구조를 단순히 비교하였을 때는 당연히 skip connecton이 많고 feature들을 전부 concat하여 channel 수가 증가한 densenet이 더 많은 파라미터를 가지고 있을 것이라 생각했는데 growth rate를 통해 conv의 output channel을 줄여서 concat을 진행해도 그렇게 크지 않은 feature를 가져갔다는 점이 인상깊었습니다.
리뷰를 읽던 중 궁금한 점이 있어 질문드리자면 설명해 주신 부분 중 ‘featuremap을 재학습할 필요가 없어 파라미터 수가 적다’라는 언급이 있었는데요, 이 부분에 대해 조금 더 설명해 주실 수 있으실까요?
댓글 감사드립니다.
해당 부분은 논문의 ‘it requires fewer parameters than traditional convolutional networks, as there is no need to relearn redundant feature-maps’ 라고 쓰여져 있는 부분을 직역한 것인데, 설명이 부족했던 것 같습니다. 저자는 DenseNet 의 구조를 ResNet과 비교하며, DenseNet은 이전 레이어의 정보를 온전히 보존하며 새로운 정보를 더하므로 다른 모델과 비슷한 성능을 내기 위해 필요한 convolution의 output 채널수가 비교적 적게 필요해 파라미터 수를 줄였다고 합니다. 저는 여기서 output channel수를 획기적으로 줄였으므로 이를 중복되는 정보를 재학습시키는걸 완화시켰다는 맥락으로 이해했습니다.