안녕하세요.
오늘 리뷰드릴 논문은 제가 자주 리뷰하는 Distillation, Mutual 분야의 논문입니다.
하지만 논문 제목에서 보시다시피 Medical 이미지에 대한 Segmentation을 수행하는 논문입니다.
Segmentation 분야에서 Mutual 한 학습 방식을 적용하는 타 논문들을 읽어야겠다는 필요성을 느꼈고 관련된 논문들을 찾아보고 있었는데 Medical 분야에서 Segmentation을 수행하는 논문들이 꽤나 많더라구요.
물론 데이터 도메인 자체가 저희랑은 다르기도 하고, 2020년 논문이기도 합니다만 learning 기법에서 아이디어를 얻을만 한 부분이 있을 수도 있겠다는 생각이 들어서 본 논문을 읽어보게 되었습니다. 그럼 리뷰 시작하도록 하겠습니다.
Introduction
제가 현재 실험하고 있는 task는 학습 시에 RGB와 Thermal 이미지를 mutual하게 함께 사용하여 학습하고, 평가 단계에서는 thermal 단일 모달로 예측을 수행합니다.
본 논문의 경우도 이와 결이 비슷한데요, 학습 시에는 MRI (Magnetic Resonance Imaging) 이미지와 CT (Computed Tomography) 이미지를 모두 사용하고, 평가 시에는 CT 단일 모달 이미지를 사용하게 됩니다.
MRI와 CT에 대해선 다들 병원 등에서 들어 보셨을 것이라 생각이 드는데요, 본 논문에서 사용한 데이터셋은 아래처럼 생겼다고 합니다.
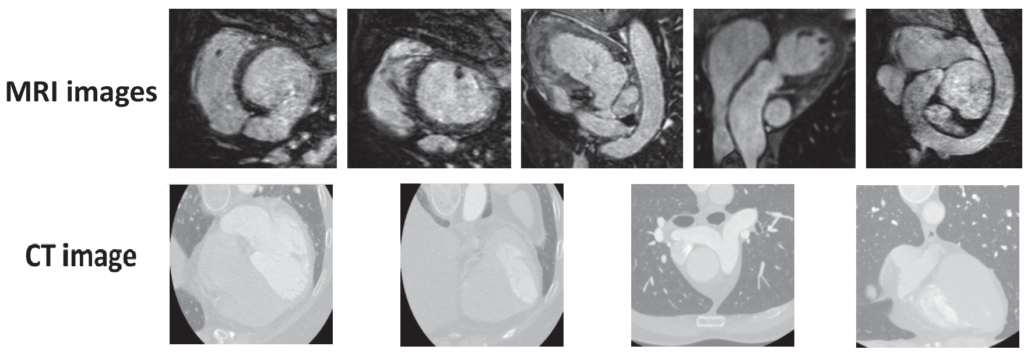
본 논문에서는 target 모달인 CT에 대한 segmentation 성능을 향상시키기 위해 source(보조) 모달인 MRI를 활용하게 됩니다. 이를 위해 mutual 기반의 Distillation 전략인 MKD(Mutual Knowledge Distillation) 이라고 하는 학습 기법을 설계하게 됩니다. 이에 대해선 Method 의 그림과 함께 설명 드리도록 하겠습니다.
Method
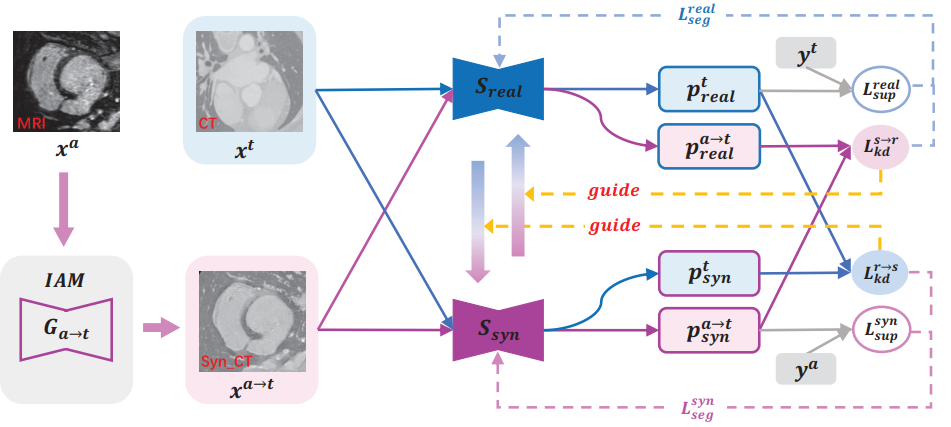
IAM(Image Alignment Module)
본 논문에서는 Mutual Knowledge Distillation 프레임워크 설계에 있어서 IAM 이라고 하는 추가적인 모듈을 설계하게 됩니다. 위 그림의 좌측에 해당하는데요, 이는 GAN 의 Generator를 통해 Synthetic CT 이미지를 생성하는 모듈입니다.
target 모달인 CT 이미지는 그대로 두고, 보조 모달인 MRI 이미지를 합성 CT 이미지로 만들어 내는 것입니다. Discriminator를 활용해서 최대한 CT 영상 틱한 합성 영상을 만들어 내는 것이지요.
그렇다면 왜 이렇게 합성 이미지를 생성해서 학습에 이용하게 될까요?
위 모델의 각 모달 사진을 보시면 서로 다른 곳이 촬영된 이미지인것을 볼 수 있습니다. 실제로 본 논문에서 실험에 사용한 dataset의 경우도 MRI-CT가 unpair한 이미지라고 합니다.
사실 이미지가 동일한 곳이 촬영된 pair한 이미지라면 우리가 흔히 아는 학습 기법처럼 CT stream, MRI stream 이렇게 2개의 stream을 구성하고 서로의 예측을 cross supervision 형태로 학습하면 될 것입니다.
하지만 본 논문에서 사용한 데이터셋은 unpair한 상황이기 때문에 각 모달의 예측을 mutual learning에 사용하지는 못하게 됩니다. 그래서 본 논문에서는 GAN을 통해 MRI 영상을 CT 스타일의 영상(x^{a->t})으로 합성하고 real CT 영상(x^t)과 함께 학습에 활용하였습니다.
MKD(Mutual Knowledge Distillation)
그림에서 보시다시피 segmenation 모델은 S_{real}과 S_{syn}으로 구성되어 있고 두 영상 x^{a->t}와 x^t는 어쨋든 모두 CT 스타일의 영상이기 때문에 동일한 모델에 통과시켜도 무방합니다. 도메인이 동일하기 때문이죠.
우선 S_{real}과 S_{syn} 는 각각 x^t와 x^{a->t}로부터 직접적인 학습이 일어나게 됩니다. 한마디로 gt를 통해 학습이 일어난다는 뜻이고, 위 그림에선 L_{sup}가 이에 해당합니다. 그리고 계산 식은 아래와 같습니다. Cross Entropy loss와 dice loss의 결합으로 이루어 져 있습니다.
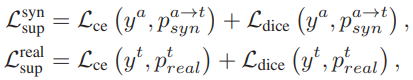
Dice loss란 segmentation task에서 가끔 사용되는 loss이며, 아래 Dice coefficient를 구한 뒤 (1-Dice coefficient)로 구한다고 합니다. Dice Loss의 경우 class imbalance 문제를 해결하기 위해 적용된다고 하네요.
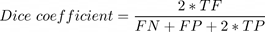
또한 이런 직접적인 학습 뿐만 아니라 반대쪽 segmentation 모델의 예측을 사용해서 간접적인, mutual한 학습을 하게 됩니다. 위 그림에선 L_{kd}가 이에 해당하게 됩니다.
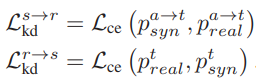
흥미로운 점은 KD loss가 흔히 사용하는 kl divergence loss가 아닌 그냥 cross entropy loss를 사용했다는 점이네요. 사실 mutual 기법에서 kl divergence 를 사용하는 것은 통상적으로 모두 적용하는 것이라 생각했었는데, CE를 사용했네요. 이에 대한 고찰은 없어서 저자의 의도는 알 수 없었습니다.
그리고 위의 직접 학습과 간접 학습을 결합하여 S_{real}과 S_{syn}를 학습시키는 LOSS는 아래 식과 같습니다.
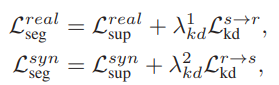
segmentation network 뿐만 아니라 합성 CT 이미지를 생성하는 Generator도 학습에 사용해야 하는데요,
그리하여 이를 최종적으로 합한 loss는 아래와 같고 한꺼번에 학습이 진행됩니다.
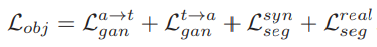
GAN과 관련된 loss가 a->t 말고 t->a도 적용된 이유는 MRI 이미지를 G_{a->t}에 통과시켜서 합성 CT 이미지를 생성한 뒤 이를 다시 G_{t->a}에 적용시켰을 때 MRI 이미지 도메인이 잘 생성되도록 하기 위함이라고 합니다.
Experiment
본 논문에서는 MM-WHS 라는 challenge에서 사용한 dataset을 사용했다고 합니다, 이는 짝을 이루지 않는 unpair한 MRI, CT 영상으로 이루어져 있습니다.
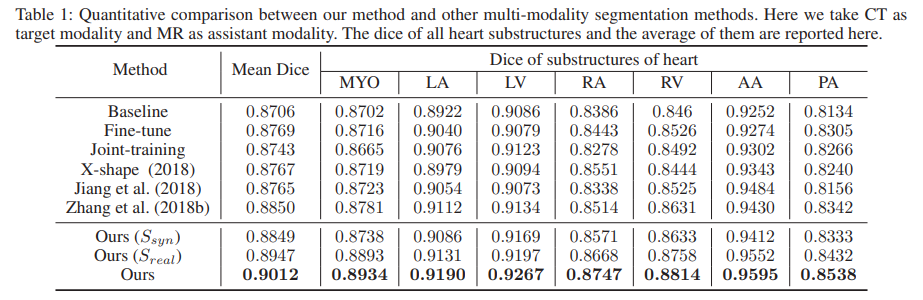
본 논문에서는 자신들의 학습 기법의 효과를 보이기 위해 Baseline으로 단일 CT 데이터만을 사용해서 학습한 모델을 선정하였습니다. 그리고 Ours 성능의 경우 3가지가 있는것을 볼 수 있는데 제일 아래 row의 세번째 성능은 두 Segmentation 모델의 예측을 합친 성능입니다.
성능의 경우 7개의 class (좌심실 혈강(LV), 우심실 혈강(RV), 좌심방 혈강(LA), 우심방 혈강(RA), 좌심실 심근(MYO), 상행 대동맥(AA), 폐동맥(PA) ) 에 대한 각 성능과, 이들의 평균인 Mean Dice 를 나타낸 것입니다.
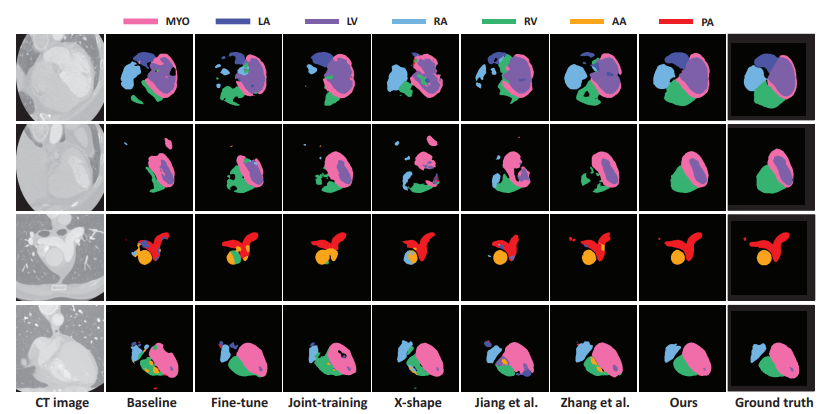
그리고 위는 정성적 결과입니다.
Ours 방식이 타 방법론들에 비해 특히 edge 등의 윤곽에 대해 훨씬 더 정확하게 예측을 수행하고 있네요.
어쩌다 보니 medical 도메인의 논문을 읽게 되었네요.
Mutual Learning을 수행할 때에 kl divergence loss가 아닌 Cross Entrophy loss를 사용한 저자의 의도가 궁금하지만,, 서술되어있지 않네요. ㅠ
그럼 리뷰 마치도록 하겠습니다. 감사합니다.
질문 드립니다.
1. Unpair 상황이라 GAN을 이용해서 MRI를 CT로 변환하였다고 하셨는데, 본인이 말하는 unpair라는 의미가 domain에서의 unpair를 의미하는 것인가요? 보통 unpair하다라는 의미는 두 도메인의 이미지가 동일한 장면 혹은 대상을 보지 않는 상황(예를 들어 한장의 사진은 수영을 하고 있는 얼룩말이, 다른 한장의 사진은 도로를 질주하는 검을 말을 가지고 변환을 수행.)을 의미하는데, 그런 의미에서 unpaired인 것이 아닌가요?
unpair라는 단어가 의미하는 바가 제가 말하는 상황이 맞다면, GAN을 통해 MRI를 CT로 변경을 시켜봤자 무의미한 것 아닌가요? GAN은 그저 도메인의 차이를 극복하는 것 뿐이지 서로 다른 장면의 영상을 하나의 동일한 장면으로 변환해주는 역할로는 사용될 수 없지 않나요? 즉 MRI 영상을 아무리 CT영상으로 잘 변환했다고 할지라도, 영상 내 대상 자체가 서로 다른 상황이니 모델에게 정보를 전이하기는 여전히 어렵다고 보여지는데 아닌가요?
2. 또한 실험 결과에 대한 설명이 너무 부족합니다. Ours 실험에서 제일 마지막(즉 3번째) 결과물이 Sync와 Real 모델의 결과물을 합쳤다고 하셨는데 이게 무슨 말인가요? 두 모델의 추론 값을 어떻게 합칠 수가 있는 것이죠? 두 모델 중 하나의 결과물이라도 GT와 정답을 맞췄다면 정답으로 인정하겠다는 의미인가요? 아마 아닐 것 같은데 만약 맞다면 그런식으로 평가하는 것이 무슨 의미가 있나요? 그리고 각각의 평가 지표와 항목이 무엇인지에 대해서도 간략하게 소개를 해주면 좋겠습니다. 평가 지표가 MIOU인가요?
3. 그리고 베이스라인 밑에 Fine-tune과 Joint training은 무엇을 의미하는 것인가요? 또한 Ours(sync), Ours(real) 역시 설명을 해주면 좋을 것 같습니다. 혹시 방법론에서 소개한 방식으로 모델을 학습한 후 각 스트림 별 성능을 평가한 것인가요?
4. Ablation study는 없나요? 방법론 자체가 (물론 3년전이긴 하지만) 너무 단순한 것 같은데 실험 마저도 이렇게 다순하게 타 방법론과의 비교만 하고 끝내지는 않았을텐데요.
5. 마지막으로 이 논문을 읽은 목적과 리뷰로 작성하신 이유는 무엇인가요? 본인 연구에 영감을 얻고 싶어서 이 논문을 읽으신 것 같은데, 그러기에는 해당 리뷰에 방법론 자체에 대한 설명과 해당 방법론들의 효과에 대한 실험 결과 등이 너무 부족해보입니다.
가치있다고 생각했지만 막상 읽어보니 논문의 내용이 본인의 생각과 달리 동작하거나 매력도가 떨어질 수는 있습니다만, 만약 그러하여 리뷰에 쓸 내용이 부족하다고 느꼈더라도 본인이 잘 알면서 동시에 해당 논문과도 관련 있는 지식(mutual learning 의미 및 장점, 혹은 관련 연구들은 없는지)을 추가하여 짜임세 있는 리뷰를 작성했으면 좋겠습니다. 정 그러할 내용조차도 넣을 수 없다면 다른 논문을 읽고 리뷰를 작성해야만 하는 것이 아닐까 생각하네요.
1. unpair하다는 뜻은 말씀하신 거 처럼 domain의 unpair가 아닌 서로 다른 곳을 보고있는, align 자체가 맞지 않는 쌍의 MRI-CT 이미지를 뜻합니다. 그럼에도 GAN을 통해 합성 CT 영상을 생성하여 real CT 영상과의 학습이 가능한 이유는 real CT와 Synthetic CT 사이에 특별히 직접적인 전이가 이루어지지 않기 때문입니다. real CT와 Synthetic CT는 unpair한 상황이기에 각각의 gt가 존재합니다. 그리고 각 모델 (S_real, S_syn)은 자신의 gt를 통해 supervised 방식으로 학습되게 됩니다. 여기에 추가적으로 kd 방식이 적용되게 되는데 이는 모델의 화살표 색깔을 보시면 이해하기 수월합니다. 파랑색 화살표 기준으로 real CT 이미지는 S_real과 S_syn에 통과되어 예측을 수행하게 되고 이 둘 사이에 KD loss가 계산되게 됩니다. 반대의 경우도 마찬가지입니다. 정리하자면 unpair한 real CT와 Synthetic CT 사이의 직접적인 distillation 과정은 없는 것입니다.
2. 두 모델 S_real과 S_syn 은 CT 도메인의 이미지를 학습때 봤기 때문에 test 시에도 CT 도메인의 이미지를 입력으로 받을 수 있습니다. Ours(S_real)과 Ours(S_syn)은 입력 CT 이미지를 각 모델에 통과시킨것을 의미하고, 최종적인 Ours는 입력 이미지를 두 모델에 모두 통과시킨 뒤 ensemble 방식으로 합친 것이라고 합니다. 합치는 과정에 대한 구체적인 설명 없이 그냥 ‘ensemble로 두 예측을 합쳤다’ 라고 표기되 어 있네요.. gt와 비교해서 정답으로 인정하는건 아마 아닐듯합니다. 평가지표의 경우 loss에 적용된 Dice 지표가 사용되는데, 7개 각 클래스에 대한 Dice를 계산하고 이들의 평균(Mean Dice) 치를 사용하게 됩니다.
3. Joint-training과 fine-tune 방식은 하나의 seg 모델을 사용하는 공통점이 있긴 하다만, Joint-training의 경우는 CT와 MRI 이미지를 한꺼번에 학습시키는 방식이고 fine-tune 방식은 MRI 데이터로 학습을 시킨 뒤 target인 CT 데이터로 fine tuning을 하는 방식입니다. Ours(sync), Ours(real)는 2번에서 설명 드리긴 했지만, 이해하신 내용이 맞습니다. 본 논문의 기법으로 학습 시킨 뒤 각 stream별로 예측을 수행한 결과입니다.
4. loss term별 ablation이 있긴 합니다만 이를 첨부하지 못한 점은 죄송합니다..
5. 본 논문의 핵심은 unpair한 서로 다른 도메인의 이미지가 있을때 이를 gan 기법을 통해 cross하게 지식을 주고받는다는 점이라고 생각합니다. 사실 영감을 얻고 싶어서 서베이 하다가 본 논문을 읽게 되었습니다만 전제 자체(unpair)가 제 세팅과는 조금 달라서 리뷰 작성에 조금 소홀했던 거 같습니다. 다음 턴에는 조금 더 노력을 기하도록 하겠습니다
안녕하세요. 좋은 리뷰 감사합니다.
저도 신정민 연구원과 동일하게 질문이 있는데요. 분명 MRI와 CT가 unpair하다는 것을 저는 A라는 사람에 대해서 MRI를 찍었다면 B라는 사람의 CT가 있다는 식으로 생각하였는데요. 이해가 가지 않는 부분이 MRI를 이용하여 CT영상 틱한 것을 왜 만드는 건가요..?? 이것이 왜 unpair와 관련이 되는지 모르겠습니다.
위 1번 답변을 참고해주시길 바랍니다.