안녕하세요. 이번 주의 X-Review에서 소개해드릴 논문은 2023년도 CVPR에 게재된 <Boosting Weakly-Supervised Temporal Action Localization with Text Information> 입니다. 사실 세미나 때 발표드려 본 논문의 컨셉을 알고 계실 것 같은데, 워낙 아이디어가 참신하여 글로 남겨두고자 리뷰를 작성하게 되었습니다.

요즘들어 비디오를 이해하기 위해 action은 기본이 되는 의미론적 단위라는 생각이 듭니다. 정적인 이미지의 연속인 비디오에서 사람이 움직이거나 물체와 상호작용하며 action이 발생하고, 그러한 action이 모여 하나의 의미론적 장면을 만들어낸다고 볼 수 있습니다.
TAL task에서는 스포츠와 같이 동적인 action을 주로 다루지만 더욱 넓은 관점에서 보았을 때 긴 비디오 속 발생하는 상황을 모델이 인지하려면 순간순간 행해지고 있는 action을 잘 잡아낼 수 있어야할 것입니다. 그 이후엔 그렇게 잡아낸 action들을 더 큰 의미론적 단위로 aggregate 하는 과정도 잘 수행해야 하겠죠. 여기서 잡아낸다는 것은 넓은 관점에서 action의 특성을 잘 featurize 한다는 의미일 것입니다.
WTAL task는 temporal label 없이 video-level label만을 제공받아 untrimmed video 속 action을 학습하여 실제 action을 찾아내야 합니다. 자세한 소개는 건너뛰고 바로 논문으로 들어가겠습니다.
1. Introduction
제가 지금까지 본 WTAL task 방법론들은 99%가 Temporal-Class Activation Map(T-CAM)을 사용합니다.

위 그림을 통해 기존 WTAL 방법론들의 파이프라인을 알 수 있습니다. Raw video를 받아 I3D 등의 3D backbone network로 인코딩을 수행하고, 여러 개의 1D Conv 연산을 통해 T-CAM을 얻게 됩니다. 이 과정에서 실제 action 구간에 대한 label은 없지만 T-CAM이 최대한 실제 action 구간과 유사한 예측을 만들어내도록 각 방법론마다 다양한 장치들이 설계되는 것입니다.
최근에는 치밀하고 다양하게 설계된 방법론들이 등장하며 성능이 많이 오르긴 했지만, WTAL은 temporal annotation이 없는 상태로 localization을 수행해야 하기 때문에 근본적으로 Action Completeness 관련 문제에 시달리게 됩니다.
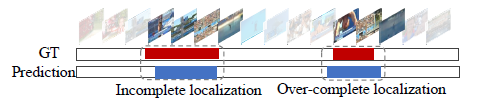
Action completeness 문제에는 위 그림에서 볼 수 있듯 incomplete와 over-complete localization이 포함됩니다. Incomplete localization은 실제 action 구간에 비해 모델이 예측한 action 구간이 앞뒤로 좁은 경우이고, over-complete localization은 그 반대의 경우를 뜻합니다.
그림 1-1에서 T-CAM을 추출하는 Classifier(여러 개의 1D Conv)는 Weakly-supervised 상황 상 video-level label로만 학습하기 때문에 명시적으로 실제 action 구간을 본 적이 없는 것입니다. 그러면 T-CAM으로부터 만든 예측 구간이 어떤 action 클래스를 갖는지에 대한 분류 과정 상에서만 localization 학습이 간접적으로 이루어지기 때문에 비디오의 조각인 segment들 중 해당 비디오가 특정 클래스로 분류되는 데에 큰 기여를 수행한 segment가 localization의 결과로 나타나게 되는 것입니다.
또한 Optical flow feature를 사용하긴 하지만 RGB feature도 사용하기 때문에 봐야할 motion 정보는 정작 못보고 뒷배경에 편향되어 제대로된 localization이 수행되지 않는 경우도 생기게 됩니다. Incomplete, Overcomplete localization과 같이 제대로 된 action localization을 수행하지 못하는 이유에는 여러가지가 있지만 결국 이것들은 temporal annoation의 부재라는 근본적인 문제로 귀결될 수 있습니다.
그렇다면 저자는 Action completeness 문제를 해결하기 위해 어떠한 방법론을 제안했을까요?
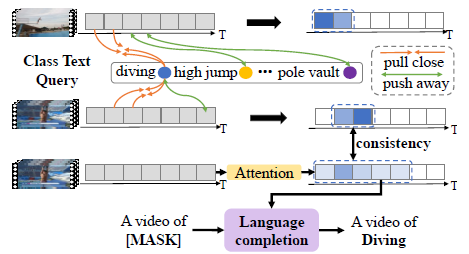
저자는 두 가지 모듈을 제안하였습니다. 첫 번째 모듈은 Text-Segment Mining(TSM) 모듈로 그림 1-3에서 위 두 행에 나타나 있습니다. 두 번째로 Video-Text Language Completion(VLC) 모듈입니다. 각 모듈에 대한 자세한 설명은 방법론 부분에서 하도록 하고, 기본적인 컨셉은 text 정보를 활용한다는 것입니다.
그림 1-3의 첫 번째 행과 두 번째 행 사이를 보시면 비디오의 각 segment들이 “diving”, “high jump” 등의 text를 하나의 기준으로 삼아 representation learning이 수행되는 것을 알 수 있습니다. 기존 방법론들은 20개의 클래스가 있다면 [0, 1, 0, \cdots{} , 0, 1]과 같이 0, 1로 구성된 이진 벡터를 label로 사용하는 것이 전부였습니다. 본 방법론에서도 학습을 위해 위와 같은 이진 벡터 형태의 라벨을 사용하긴 하지만, 단순히 class 라벨을 저렇게 이진화하는 것에서 멈추지 않고, GloVe word embedding 방식과 Transformer encoder, decoder를 통해 텍스트 자체에서 얻을 수 있는 feature를 추출해 action localization에 도움을 주는 것입니다.
저자가 제안하는 2가지 모듈에 대해 간단히 설명드리면, 먼저 TSM은 클래스 간 구별력을 갖는 것에 목적이 있습니다. THUMOS14 데이터셋을 예시로 들자면, 멀리 뛰기나 높이 뛰기 action은 둘 다 “도움 닫기”라는 subaction을 포함합니다. 이 때 각 클래스 명인 “High jump”와 “Long jump”를 임베딩하여 text query로 던져주고, 비디오 segment들과 쿼리의 유사도를 계산하여 명백히 구별력을 갖는 부분만을 찾아내는 것입니다. 쉽게 말하자면 두 action을 볼 때 도움 닫기 하는 부분에 집중하기보단, 실제로 높이 뛰거나 멀리 뛰는 segment들을 더욱 명시적으로 찾아내는 역할을 수행함으로써 클래스간 구별력을 최대화하기 위해 설계되었다는 것입니다.
다음으로 VLC는 생성적 목적을 갖습니다. 생성의 대상은 키워드가 마스킹된 문장에 해당하고, 앞서 TSM이 구별력을 갖는 segment들에만 집중했다면 VLC는 마스킹된 키워드를 찾기 위해 TSM보다 상대적으로 최대한 넓은 영역을 살펴보게 됩니다. 이러한 목적을 통해 한 클래스 내의 통합력을 더욱 높여줄 수 있을 것입니다. 세부 사항들은 뒤에서 더 설명하겠습니다.
TSM과 VLC가 각각 좁은 영역과 넓은 영역만을 본다는 점에서 over complete, incomplete 문제를 어느 정도 완화할 것으로 생각되지만 반대로 incomplete, over complete 문제를 야기할 수 있는것이 아니냐는 의문을 품으실 수도 있으실 것입니다. 저자는 이에 대응하기 위해 최종적으로는 TSM에서 보는 영역과 VLC가 보는 영역에 일관성을 부여해줄 self-supervised constraint까지 제안하게 됩니다.
Contribution
- To best of our knowledge, we are the first to leverage text information to boost WTAL. We also prove that our method can be applied to existing methods.
- To leverage text information, we devise two objective: the discriminative objective to enlarge the inter-class difference, thus reducing the over-complete; and the generative objective to enhance the intra-class integrity, thus finding more complete temporal boundaries.
- Extensive experiments illustrates our method outperforms current methods on two public datasets.
이제 실질적인 방법론을 자세히 알아보겠습니다.
2. The Proposed Method
2.1 Overall Architecture
Problem formulation.
우선 논문에서 기본적으로 사용하는 notation에 대해 알아보겠습니다.
총 N개의 비디오를 받고 각각은 \{\mathcal{V}\}_{j=1}^{N}으로 표현합니다. 각 비디오에 대한 video-level label은 \{y_{j}\}_{j=1}^{N}입니다. y_{j}는 앞서 말씀드린 이진 벡터로 클래스 존재 여부를 나타냅니다.
하나의 비디오 \mathcal{V} = \{v_{t}\}_{t=1}^{\mathcal{T}}이고 이는 각 비디오마다 \mathcal{T}개의 segment를 포함함을 나타냅니다.
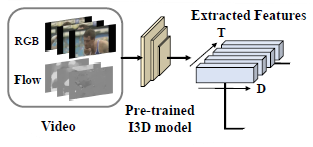
위 그림처럼 I3D backbone을 통해 RGB와 Optical flow feature인 X_{r} \in{} \mathbb{R}^{\mathcal{T} \times{} 1024}와 X_{f} \in{} \mathbb{R}^{\mathcal{T} \times{} 1024}를 추출합니다. 추출한 비디오 feature에 대한 분류와 localization을 통해 \{c_{i}, s_{i}, e_{i}, {conf}_{i}\}를 예측하게 됩니다. 각각은 예측한 클래스, 구간 시작 지점, 끝 지점, confidence score에 해당합니다.
아래 그림 2는 해당 방법론의 Overview입니다.
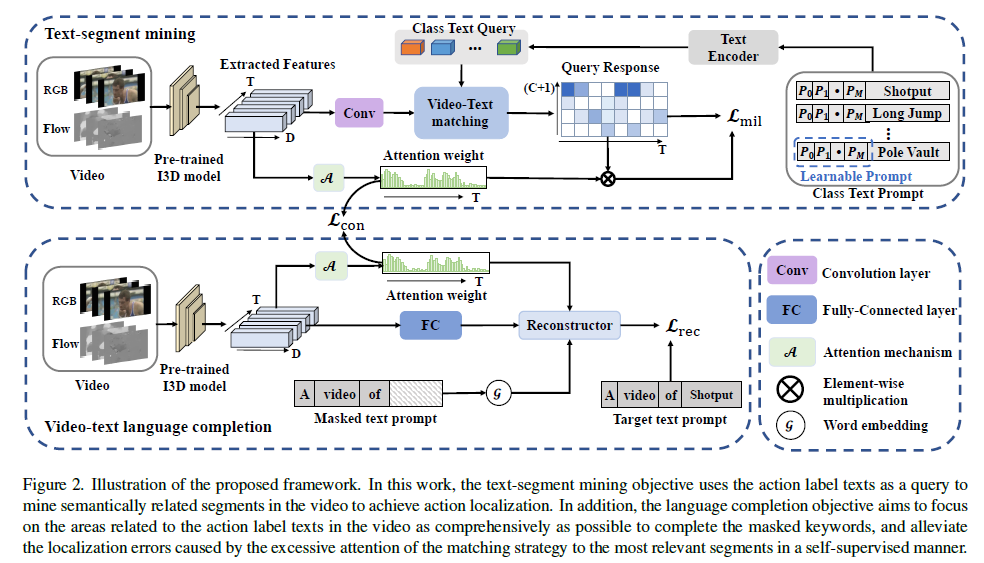
2.2 Text-Segment Mining (TSM)
TSM은 그림 2의 윗부분에 해당하고 아래 3가지 단계로 이루어져있습니다.
- Video embedding module
- Text embedding module
- Video-text feature matching
Video embedding module
앞서 얻은 RGB feature X_{r}과 Flow feature X_{f}를 \text{CO}_{2} 모듈에 통과시켜 feature X \in{} \mathbb{R}^{\mathcal{T} \times{} 2048}을 얻습니다. \text{CO}_{2} 모듈은 2021년도에 제안된 방법론에 포함된 모듈로, 자세한 내용은 이전 리뷰의 2.2절을 참고하시기 바랍니다.
이후 2개의 1D Conv-ReLU-Dropout으로 이루어진 video embedding module emb()에 X를 통과시켜 embedded feature X_{e} = emb(X)를 얻습니다. 또한 video embedding module과 유사하게 구성된 attention module에 X를 통과시켜 Actionness score인 att_{m} = \sigma{}(\mathcal{A}(X)) \in{} \mathbb{R}^{\mathcal{T} \times{} 1}을 얻습니다. 이는 특정 클래스에 관계없이 \mathcal{T}개의 segment 각각이 action일 확률값(0~1)을 담고 있습니다. (\sigma{}() = sigmoid())
Text embedding module
본 논문의 핵심은 클래스 명인 text를 단순 이진 벡터로 활용하지 않고, embedding을 통해 얻은 의미론적 관계를 활용한다는 것이었습니다. TSM에서는 C개의 클래스 별 learnable prompt를 두어 Transformer encoder를 통해 text feature를 만들어냅니다.
Transformer encoder의 입력으로 들어갈 L_{q}는 아래와 같습니다.
- L_{q} = [L_{s};L_{p};L_{e}]
L_{s}는 임의로 초기화된 시작 토큰이고, L_{p}는 learnable textual context를 의미합니다. 마지막으로 L_{e}는 각 클래스 단어를 GloVe로 임베딩한 feature입니다. 이렇게 learnable한 prompt를 encoder의 입력으로 주어 self-attention 연산을 거침으로써 class text query X_{q} = trans(L_{q}) \in{} \mathbb{R}^{(C+1) \times{} 2048}을 얻어냅니다.
Video-text feature matching
위 과정을 통해 video feature X_{e}와 text feature X_{q}를 얻었는데, 두 feature를 matching하는 과정은 상대적으로 단순합니다.
둘을 내적하면 video-text similarity matrix S \in{} \mathbb{R}^{\mathcal{T} \times{} (C+1)}을 만들어낼 수 있고 이는 이름 그대로 각 비디오 segment가 각 클래스에 해당할 확률값을 매트릭스 원소로 담고 있다고 볼 수 있습니다. 이 개념은 WTAL 방법론에 반드시 등장하는 T-CAM과 같다고 볼 수 있겠죠.
기존 방법론들이 단순히 1D Conv와 기타 장치에 기대어 구간을 잘 찾아내는 T-CAM이 만들어지길 기대했다면, 본 방법론에서는 text feature와 video feature의 유사도를 계산해 조금 더 명시적인 구간을 찾아낼 수 있게 됩니다. 이 때 text feature는 word embedding이기 때문에 클래스마다 뚜렷하게 구별되는 특성을 갖고있을텐데, 이러한 text feature와의 matching을 수행하였으니 처음에 말씀드린대로 action 간 구별력을 갖게하고 정말 특정 action에서만 등장하는 장면과의 값이 높게 나올 것이라고 생각해볼 수 있습니다.
이렇게 video-text similarity matrix S를 얻었다면 기존 방법론들과 같이 top-k mean pooling 과정을 거쳐 video-level class score를 만들어내고 저희가 가지고 있는 video-level label과의 CrossEntropy Loss를 통한 분류 학습을 수행하게 됩니다. 또한 앞서 얻은 att_{m}을 segment-wise로 S에 곱해주면 background segment들은 값이 죽고 action에 가까운 segment들만 살아남게 되는데, 이를 \bar{S}로 두고 학습에 같이 활용합니다. 아래 수식 (3)과 (4)는 top-k mean pooling 과정과 방금 말씀드린 Multiple Instance Learning 학습 과정을 뜻합니다. 수식 (4)에서의 라벨 y_{j}와 \hat{y}_{j}은 background 포함 여부가 다릅니다.
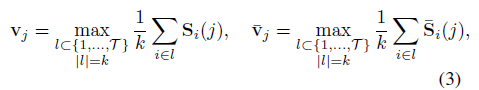
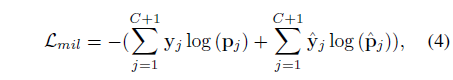
2.3 Video-Text Language Completion (VLC)
저자가 제안하는 두 번째 모듈인 VLC 입니다.
VLC 모듈에도 TSM과 마찬가지로 Video embedding module, Text embedding module이 존재하는데, 마지막에 두 feature를 이용해 마스킹된 문장을 채우는 Transformer reconstructor 부분이 달라지게 됩니다.
Video embedding module
여기에선 TSM의 Video embedding module과 구조가 동일한 층들에 X를 통과시켜 X_{v}를 얻고, 마찬가지로 actionness score인 att_{r}을 뽑아냅니다. 전반적인 과정이 동일하여 자세한 설명은 생략하겠습니다.
Text embedding module
VLC의 Text embedding module은 TSM에서와 조금 다른데요, 아깐 learnable prompt를 Transformer의 입력으로 주었다면 이번엔 고정적인 문장을 만들어 마스킹한 후 Transformer encoder-decoder 연산을 통해 비어있는 부분을 예측하는 형태로 모델이 학습됩니다.
먼저 “a video of [CLS]”라는 문장을 prompt로 두고 각 단어들을 GloVe로 embedding한 뒤 FC layer에 태워 문장 feature \hat{X}_{s} \in{} \mathbb{R}^{M \times{} 512}를 얻습니다. M은 단어의 개수입니다.
Transformer reconstructor
위에서 언급한 prompt인 “a video of [CLS]” 중 1/3을 랜덤으로 마스킹합니다. 이렇게 되면 꽤나 높은 확률로 keyword가 마스킹될 것입니다. 이렇게 비어있는 단어를 채우기 위해 Transformer encoder-decoder 구조를 사용합니다.
먼저 아래 수식 (6)과 같이 video feature에 대한 self-attention 연산을 수행합니다. 이를 통해 foreground video feature F \in{} \mathbb{R}^{M \times{} 512}를 얻게 됩니다.
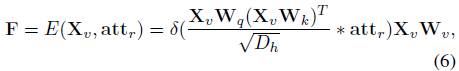
수식 (6)에서 E()는 Transformer encoder이고, 입력으로 video feature와 VLC에서 뽑은 actionness score가 들어갑니다. 뒤 수식은 단순히 video feature에 대한 self-attention 연산이고 중간에 attention을 추출할 때 actionness score att_{r}이 함께 고려된다는 점만 참고하시면 될 것 같습니다. 바로 이 att_{r}이 곱해짐으로써 F가 foreground video feature가 될 수 있는 것입니다.
다음으로 수식 (7)은 Transformer decoder 연산을 통해 문장을 reconstruction 하는 과정입니다.
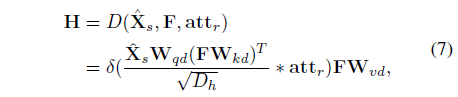
문장 embedding인 \hat{X}_{s}와 수식 (6)에서 얻은 foreground video feature F 간 cross-attention을 통해 multi-modal representation H \in{} \mathbb{R}^{M \times{} 512}를 얻게 됩니다.
이후에는 아래 수식 (8)을 통해 마스킹 된 단어 w_{i}를 분류하고, 수식 (9)를 통해 reconstruction 학습을 수행합니다. 수식 (9)에서 \Sigma{}와 log 사이 저희가 알고 있는 마스킹된 단어의 라벨이 들어가면 확실한 학습의 방향을 알 수 있을 것 같은데, 수식 (8)로 얻은 모든 단어들이 실제 답이든 아니든 모두 확률값이 커지는 방향으로 학습되는 것처럼 수식이 작성되어 있어 의문이 듭니다. 여러 방면으로 검색을 해봐도 쉽게 해결되지가 않네요.
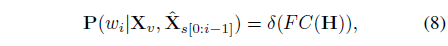
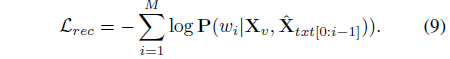
저자는 수식 (9)의 reconstruction loss를 활용한 contrastive loss \mathcal{L}_{c}도 제안합니다. 이는 아래 수식과 같습니다.
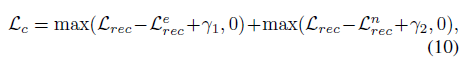
위에서 \mathcal{L}_{rec}^{e}와 \mathcal{L}_{rec}^{n}은 각각 수식 (6)~(9)를 계산할 때 att_{r} 대신 모두 1을 사용하거나 1-att_{r}를 사용하여 얻은 \mathcal{L}_{rec}에 해당합니다. 비디오의 모든 segment를 보는 경우와 background segment를 보는 경우가 foreground를 보고 reconstruction을 수행하는 \mathcal{L}_{rec}과는 거리를 두고자 설계한 것입니다.
2.4 Self-Supervised Consistency Constraint
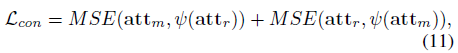
방법론 가장 처음 말씀드렸듯, TSM과 VLC가 보는 영역에는 좁고 넓다는 차이가 존재합니다. 이렇게 살펴보는 영역의 차이를 줄이며 조금 더 complete한 action 경계의 예측을 위해 각 모듈에서 추출한 att가 서로 닮아가도록 mutual loss를 추가해줍니다.
\psi{}는 “stop gradient”의 역할이고 MSE loss를 통해 각 모듈에서의 att가 서로 닮아가는 방향으로 학습이 이루어질 것입니다.
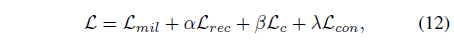
이 과정에 따른 최종 loss \mathcal{L}은 위와 같습니다.
3. Experiments
3.1 Comparison with the State-of-the-Arts
THUMOS14 데이터셋과 ActivityNet v1.3 데이터셋에 대해 벤치마킹을 수행하였습니다.
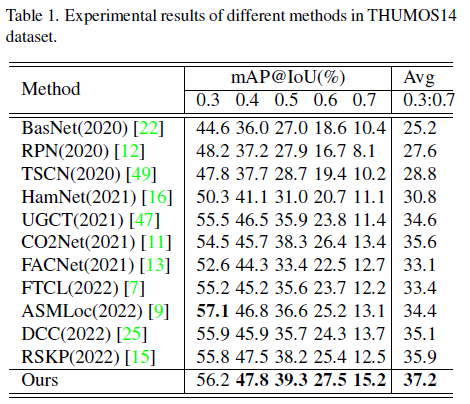
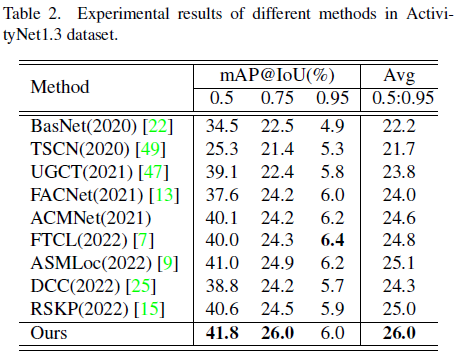
표 1, 2에서 볼 수 있듯 22년도 방법론들의 성능을 큰 차이로 뛰어넘고 있습니다.
저자도 벤치마크에선 별다른 분석을 하고있진 않고, ablation 쪽에서 살펴볼만한 실험들로 넘어가도록 하겠습니다.
3.2 Ablation Study
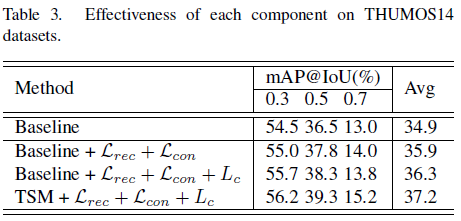
먼저 표 3은 각 component 별 ablation 성능입니다. Baseline은 기존 WTAL 방법론들처럼 T-CAM을 추출할 때 여러 개의 1D Conv에 의존하는 방식입니다. 이에 따라 3번째 행과 4번째 행을 비교해보았을 때, 확실히 text 정보를 임베딩하여 이와 비디오 feature의 유사도를 계산하여 T-CAM을 만드는 방식이 0.9%의 평균 mAP 성능 향상을 일으키며 유의미했다는 점을 알 수 있습니다.
VLC 모듈의 성능은 1, 2행 간 및 2, 3행 간의 성능 차이를 통해 알 수 있는데요, VLC에서 설계된 loss들이 모두 저자의 의도대로 성능을 효과적으로 올려주고 있음을 알 수 있습니다.
사실 저자가 개선하고자 했던 문제점은 action completeness였습니다. 하지만 단순히 IoU에 따른 mAP만으로는 각 모듈에서 의도했던대로 TSM에선 Over-completeness, VLC에선 Incompleteness가 해결되었는지 뚜렷하게 알 수는 없겠죠.
그래서 저자는 아래 표 4와 같이 FP와 FN의 비율을 통해 각 모듈의 효과를 보여주고자 하였습니다.
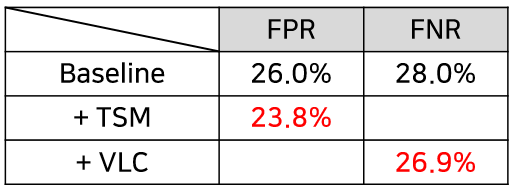
Baseline에 TSM을 붙이는 경우 FP의 비율이 낮아졌는데, 이는 FP의 의미를 생각해보았을 때 Over-completeness 문제를 완화시켰다고 이해할 수 있습니다. 또한 VLC를 붙이는 경우 FN의 비율이 낮아지며 제대로 잡지 못한 action 앞뒤 구간도 이전보다 더 잘 잡아낸다는 점을 알 수 있었습니다.
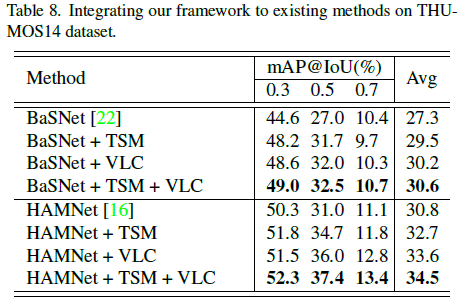
표 8은 이전 WTAL 방법론인 BaSNet과 HAMNet에 저자의 모듈을 붙이는 실험에 대한 성능입니다. 사실 저자의 두 모듈을 붙였을 때 성능이 많이 향상되긴 하지만 결국은 TSM과 VLC가 각각 모델 구조를 가지며 모델 크기가 2배가 된다고 볼 수 있기 때문에 어느정도 효율성 측면에서는 한계가 있다고 저자도 이야기하고 있습니다. 결과적으로 성능은 많이 오르긴 하네요.

마지막으로는 두 비디오에 대한 정성적 결과로 실험 부분을 마무리하고 있습니다. 다른 방법론이랑 비교하기보단, 각 모듈을 붙여가며 Action completeness 측면에서 개선을 이뤘다는 점을 보여주고 있습니다.
4. Conclusion
Weakly-Supervised 기반의 Temporal Action Localization에는 연구의 주류를 이루는 video-level label을 사용하는 방식 뿐만 아니라 비디오의 음성 정보를 활용한다거나, 한 비디오가 가지고 있는 action이 몇 번 등장하는지 등 temporal annotation이 아닌 추가 annotation을 활용하는 방식이 존재합니다.
하지만 본 방법론은 video-level lable만을 활용하는 그 범주를 벗어나지 않으면서, 가지고 있는 정보를 최대한 활용해보겠다는 새로운 시각과 이를 뒷받침하는 실험 결과와 분석이 탄탄하여 참신하면서도 어렵지 않은 좋은 논문이었다는 생각이 듭니다.
이상으로 리뷰 마치겠습니다.