이번에 소개드릴 논문은 cvpr21년도에 게재된 LoFTR이라고 하는 방법론입니다. 해당 방법론은 Place Recognition, Localization task에 관심이 있으신 분들이라면 아실법한 superpoint & superglue와 비슷한 결의 논문이라고 생각하시면 될 것 같습니다.
보다 디테일하게는 밑에서 더 자세하게 다루겠지만 SIFT, SURF, superpoint와 같은 keypoint detection 과정은 생략한 채, Descriptor 추출 및 Local descriptor들 간에 matching을 수행하는 2step 기반 방법론입니다. 참고로 기존 방식들은 이러한 2step 전에 keypoint 추출이라고 하는 첫번째 단계가 한차례 더 수행됩니다.
그렇다면 해당 논문에서는 왜 Keypoint에 대해서 검출을 하지 않을까요? 논문의 자세한 내용을 밑에서 함께 보시죠.
Intro
먼저 두 영상 사이에 Local Feature Matching은 Structure From Motion(SFM), SLAM, Localization 등 3D Computer Vision task에서 빠지지 않고 등장하는 기술 단계입니다. 보다 구체적으로는 두 장의 영상이 입력으로 제공되었을 때, 두 영상으로부터 1)keypoint를 검출하고, 2)해당 keypoint에 해당하는 Descriptor를 추출합니다. 마지막으로 3)추출된 descriptor들 간에 유사도를 하나하나 계산하여 두 영상 사이에 대응되는 keypoint를 매칭하는 것으로 끝이 납니다.

여기서 저자는 첫번째 단계인 Keypoint Detection 부분에 효용성에 대해서 의문을 품습니다. Keypoint Detection은 결국 영상에서 유의미한 포인트를 검출함으로써 매칭을 수행하기 위한 후보군을 간추리는 관점에서 어찌보면 중요한 역할을 수행한다고 볼 수도 있겠습니다. 가령 두 영상에 대해 모든 픽셀레벨 혹은 패치레벨에 대하여 하나하나 다 비교하게 되면 너무 많은 연산량이 필요로 하기 때문에, 영상 내에서 중요하다고 생각되는 부분들(e.g., corner, edge)을 관심점으로 뽑아 해당 점들끼리 매칭을 비교하는 것이 더 효율적이라고 보는 것이죠.
이러한 keypoint의 필요성을 부정할 수는 없지만, 때로는 이러한 후보군이 잘못 선정되어서 매칭에 안좋은 결과를 보여줄 수 있는 경우도 빈번합니다. 보다 자세하게 설명드리면, 그림2의 예시와 같이 시점과 조도의 변화, 텍스쳐가 너무 없거나 반복적인 경우, 혹은 모션블러 등등 다양한 악조건들로 인하여 keypoint가 반복적으로 검출되지 않는 현상(즉 repeatable interest points)이 흔하게 발생합니다. 그리고 이러한 잘못된 keypoint 사이에서 매칭을 수행하게 되다 보면, 잘못된 매칭 결과가 나올 수 밖에 없게 되는 것이지요.

이러한 keypoint 검출의 문제점을 해결하기 위해, 최근에 연구들은 애초에 keypoint 단계를 생략해버리는 방식을 선택했습니다. 즉 keypoint를 검출하려고 노력하는 것이 아니라, pixel-wise로 dense level의 descriptor 추출하고 높은 confidence score를 가지게 되면 해당 값들을 매칭의 결과값으로 활용하겠다는 것이죠.
하지만 기존의 연구들은 CNN 기반 모델들을 활용했기 때문에 두 입력 영상 사이에 dense level matching을 수행하기에는 receptive field의 한계로 인하여 종종 올바른 매칭이 어려운 상황이 발생하였습니다. 이러한 내용은 실제로도 맞는 말이긴 하지만, 해당 논문이 게재된 21년도는 다양한 vision task에 Vision Transformer를 많이들 활용하던 시기인지라 Transformer 사용을 contribution으로 가져가기 위한 흔한 레퍼토리로써 수용영역의 한계 등을 언급한 것이 아닐까라는 생각도 들긴 합니다.

논문에서도 이를 의식하였는지 그림3에서의 매칭 결과를 함께 보여줍니다. 보시면 실내 환경에서 view point가 크게 어긋난 상황(좌측 영상에서는 중앙~우측 부분이, 우측 영상에서는 좌측 구석 부분이 서로 공통적으로 보이는 영역임)에서는 대응되는 영역들이 매우 멀리 존재하는 large displacement에 해당하기 때문에 모델이 local한 부분만을 보게 된다면 두 영상 사이에 대응관계를 확인하는 것이 매우 어렵게 됩니다.
반면에 Transformer와 같이 Global receptive field를 가지게 되는 경우에는 large displacement에 대해서도 충분히 고려할 수 있기 때문에 view point가 크게 어긋나며, textureless한 상황에서도 matching을 올바르게 수행할 수 있는 것이지요.
그럼 저자가 제안하는 논문의 핵심 contribution에 대하여 한번 요약해보겠습니다.
- Keypoint detection 부분을 생략하고 Dense level에서 Descriptor Extractor 및 Matching을 수행하는 방법론을 새롭게 제안함.
- Transformer를 활용해 global receptive field를 가짐으로써 더 다양한 뷰포인트에서도 강건한 매칭을 수행할 수 있으며, Coarse-level 매칭을 기반으로 Fine-level에서의 매칭을 조정함으로써 dense-level matching의 정확성을 더욱 향상시킴.
Method
그림4는 논문의 전체 overall framework 입니다.
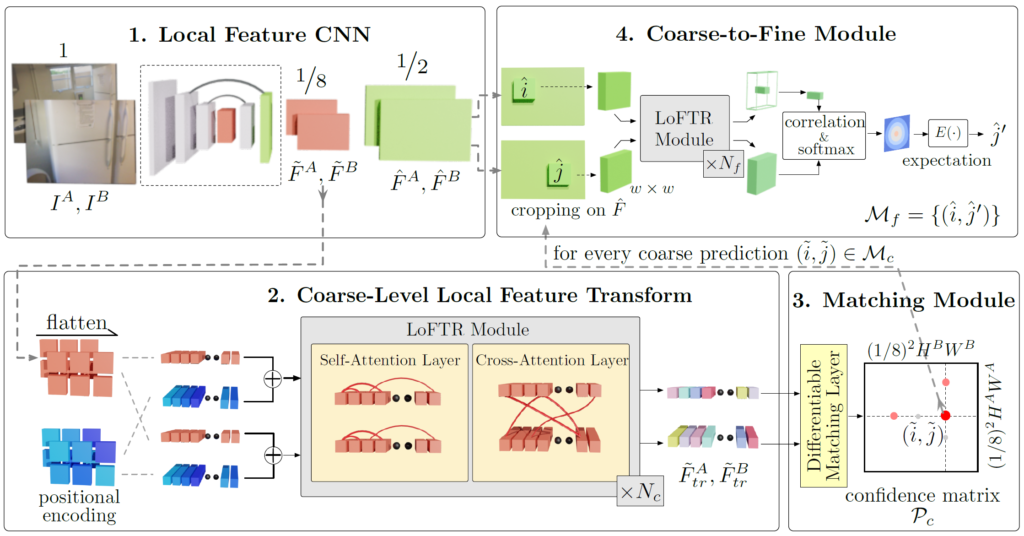
그림4를 살펴보시면 LoFTR은 1) Local Feature CNN, 2) Coarse-Level Local Feature Transformer, 3) Matching Module, 4) Coarse to Fine Module로 크게 4가지 파트로 구성됩니다.
Local Feature CNN
일단 첫번째 파트인 Local Feature CNN의 경우는 주어진 두 영상에 대해 각각 Multi-scale의 Feature Map을 추출하기 위한 단계입니다. 구조로는 CNN 기반의 FPN 구조를 가지고 있으며, 입력 영상 쌍 I^{A}, I^{B} 가 각기 들어온다고 했을 때, 원본 해상도 대비 1/8 수준의 해상도인 Coarse-level Feature map \tilde{F}^{A}, \tilde{F}^{B} 와 1/2 해상도의 Fine-level Feature \hat{F}^{A}, \hat{F}^{B} 를 추출하게 됩니다.
일단 pixel level의 dense matching을 하기 위해서는 영상 전반에 대하여 local feature들을 잘 추출해야하는 것도 있기 때문에, filter 연산을 수행하는 CNN을 활용해서 feature map을 추출했다 라고 이해하시면 될 것 같습니다.
Coarse-level Local Feature Transform
다음은 2번째 단계인 Coarse-Level Local Feature Transform에 대한 부분입니다. 일단 해당 단계의 가장 큰 목표는 Coarse-level feature map(i.e., \tilde(F)^{A}, \tilde(F)^{B} 이 matching을 수행하기 좋은 Feature map으로 재탄생하는 것입니다. 그래서 저자도 해당 단계의 이름을 Coarse-level Local Feature “Transform” 이라고 지었구요.
즉 CNN을 타고 나온 Coarse-level feature map들이 3번째 단계 Matching Module에서 matching을 잘 수행할 수 있도록 매칭에 최적화된 Feature로 변환시키겠다는 의미죠.
따라서 이 “Coarse-level Local Feature Transform” 단계에서는 Transformer 기반 모듈(i.e., LoFTR Module)을 통하여 자기 자신에 대한 Self-Attention과 두 영상 쌍에 대한 Cross Attention을 N번 반복하는 과정을 수행하게 됩니다. 어텐션 방법은 잘 아실 것이라고 판단하여 자세한 설명은 넘어가겠습니다.
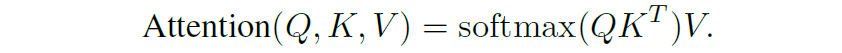
결과적으로 Self-Attention은 Query, Key Value 모두 자기 자신의 feature map을 기준으로 생성되어 위 수식 연산을 수행하는 것을 의미하며, Cross-Attention은 Query는 source image, Key와 Value는 target image를 기준으로 생성되어 위의 attention 연산을 수행한다고 보시면 될 것 같습니다.
Linear Transform
Transformer의 Self and Cross Attention 연산은 자기 자신에 대한 상관관계 뿐만 아니라 매칭을 수행할 반대편 영상에 대한 상관관계도 고려할 수 있으며, Global Receptive Field를 가진다는 점에서 CNN과 비교하여 많은 장점들을 지니고 있는 것은 사실입니다.
하지만 Global Receptive field를 가진다는 점은 곧 영상 전체에 대해서 모델의 연산이 진행된다는 것을 의미하기에 Local Receptive field를 가지는 (CNN과 같은) 연산들과 비교하여 상대적으로 더 많은 연산량이 들어갈 수 밖에 없습니다.
보다 구체적으로, Query와 Key의 길이를 N이라고 하였을 때 N개의 벡터들은 각각 D개의 차원을 가지고 있습니다. 이때 N은 영상의 Height와 Width를 flatten하여 일렬로 쭉 펼쳐놓은 것으로 사실상 N이 영상(혹은 특징맵의) spatial information으로 볼 수 있을 것입니다.
여기서 Query와 Key 간에 dot product 연산을 수행할 때, D차원끼리 연산을 수행하여 N차원을 살리는(i.e., NxD * DxN = NxN) 연산 방식을 N차원에 대한 Correlation을 계산하였다고 말합니다. 실제로 ViT가 global receptive field를 가진다는 것 역시 영상의 spatial 성분(HxW)에 해당하는 N축을 유지하는 방식으로 내적을 계산하기 때문에 영상의 전체 영역을 한번에 고려한다고 볼 수 있었기 때문이었죠.
그런데 사실 이러한 연산 방식이 NLP의 문장에서는 크게 문제되지 않았지만, 이미지 레벨에서는 얘기가 좀 달라졌습니다. 문장은 일반적으로 수십개 많아야 수백개의 단어로 구성되어있지만, 영상은 최소 수만개에서 수십만개의 픽셀들로 구성되어 있기 때문이죠.
따라서 수십만개에 해당하는 HxW에 대하여 연산을 수행한다는 것은 상당히 많은 메모리와 시간이 필요하게 될 것입니다. 물론 1단계의 CNN으로부터 원본 해상도 대비 1/8 크기의 feature map을 계산하긴 하였습니다만, 그럼에도 Query와 Key의 연산량은 5120xD * Dx5120 = 5120×5120의 크기를 가지는 값으로 나타나게 됩니다.(입력 해상도가 640×512라는 가정)
따라서 O(N^{2}) 크기의 연산량을 먹는 것이 너무 부담스러우니 저자는 이러한 연산량을 줄일 수 있는 방법에 대해서 모색하였는데요. 결론적으로는 아래 그림5와 같은 Linear Transformer 구조를 활용해서 연산량을 줄일 수 있었다고 합니다.
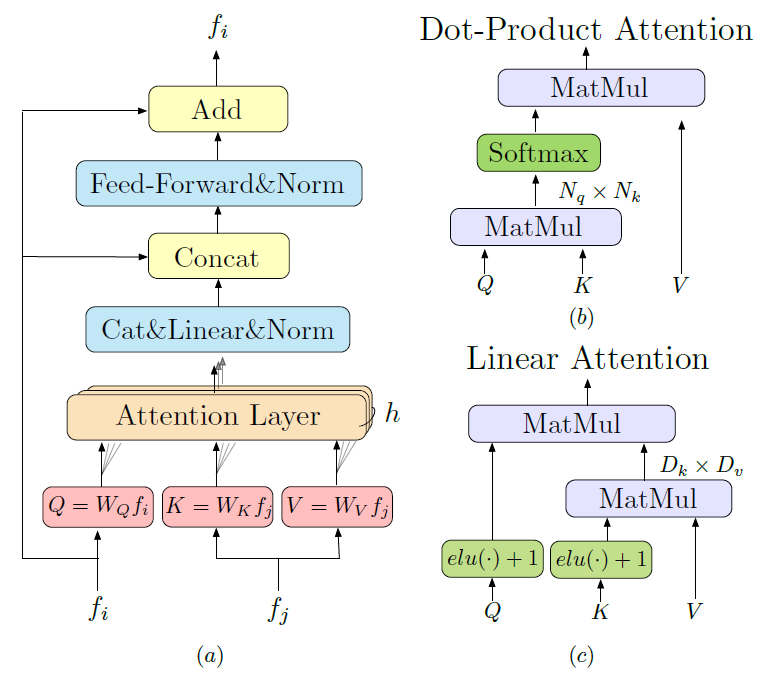
그림5-(c)를 보시면 Query와 Key에 대해서 각각 elu activation function과 +1을 처리해주는 모습입니다. 그 이후에 기존 방식처럼 Query와 Key 간에 내적 연산이 아닌 Key와 Value에 대해서 내적 연산을 먼저 수행하는 모습입니다?
갑작스러운 이러한 연산에 저는 당황을 했지만.. 게다가 NxD * DxN의 연산이 아닌 DxN * NxD 연산을 통해 최종적으로 DxD의 채널축에 대한 상관관계를 계산하는 모습에 한번 더 당황을 했지만? 아무튼 Key와 Value의 D차원을 살리는 내적 연산을 통하여 DxD의 크기를 만들고 이를 Query와 한번 더 행렬곱을 해줌으로써 NxD의 결과물을 내었다고 합니다.
사실 논문에서도 새롭게 제안하는 방식은 아니고, “Transformers are RNN”이라는 20년도 ICML 논문에서 나왔던 방식을 그대로 활용하였다고 했기에 실제 Linear Transformer의 Linear Attention 과정이 어떠한 기대효과를 낼 수 있는가에 대해서 구체적으로 나와있지는 않습니다.
다만 저자는 보통 D보다 N이 더 크기 때문에, NxN 간에 연산보다는 DxD 간에 연산을 통하여 O(N^{2}) 크기의 연산을 O(N) 수준까지 낮출 수 있었다고 합니다. 무언가 석연치 않지만 D 차원을 살리는 방향으로 내적을 하는 것이 N 보다는 더 적게 연산이 들기 때문에 연산량을 줄이고자 이런식으로 진행하였구나 정도로 이해하고 넘어가면 좋을 듯 합니다.
아무튼 이러한 Linear Attention 연산이 포함된 Transformer module은 각각 Self-Attention 그리고 두 영상 간에 Cross-Attention으로 구성이 되어 있으며, N번 반복을 수행하게 됩니다.
Establishing Coarselevel Matches
이렇게 Coarse-level에 대하여 matching을 수행할 수 있도록 Feature map들이 잘 변환이 되었다면, 이러한 2단계의 출력 값들을 가지고 matching을 수행하게 됩니다.
매칭을 하는 방법으로는 이전 방법론들이 제안하였던 optimal transport(OT) 방법론과 dual-softmax operator 연산이 있다고 합니다. 이 두 가지 방식에 대해 저자는 모두 실험을 해본 것 같은데, dual-softmax operator가 더 빈번하게 활용이 되고 중요하다고 저는 알고 있어서 dual-softmax 방식으로 매칭하는 방법에 대해서만 집중적으로 다뤄보겠습니다.
먼저 attention 연산이 처리된 두 coarse level feature map \tilde{F}^{A}_{tr}, \tilde{F}^{B}_{tr} 에 대하여 socre matrix S를 다음과 같이 계산할 수 있습니다.
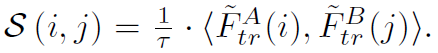
문제는 저 화살괄호(<>)의 연산 의미를 논문에서 설명을 안해주는 바람에.. 정확하지는 않을 수 있으나 제가 알기로는 != 연산으로써 사용될 수 있다고 하더군요? 즉 A feature map의 i값과 B feature map의 j값이 서로 같은지 다른지 여부에 따라서 값이 정해지는? 그런 score matrix라고 볼 수 있을 것 같습니다.(t 값에 따라서 soft하게 변환이 되는건지…? 그 여부가 확실치 않습니다.)
아무튼 이런식으로 S 행렬을 계산하게 되면 다음으로 soft nearest neighbor matching의 확률 값을 획득하기 위해서 i축과 j축에 연달아서 softmax 연산을 취한 후 이렇게 취득된 2개의 output 값을 픽셀 레벨로 곱하는 방식을 활용합니다.
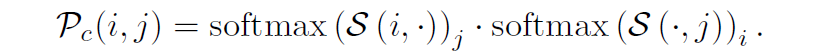
위 수식을 통해 confidence matrix P를 계산하였다면, 실제로 매칭된 결과를 선택하는 selection 과정을 거쳐야만 최종적으로 매칭 결과가 확정이 됩니다. 이 방식은 단순하게 일정 threshold( \theta_{c})보다 더 높은 confidence score를 가지는 매칭 값들을 선정하는 과정과 mutual nearest neighbors 기법을 통해 매칭된 결과 중의 outlier 들을 제거하는 방식을 활용해서 최종 매칭 결과물들을 산정하였다고 합니다.
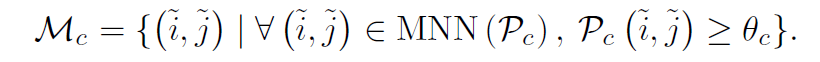
Coarse-to-Fine Module
지금까지의 과정을 통해서 Coarse Level에서의 matching 결과는 올바르게 잘 수행을 했습니다. 하지만 이 논문의 핵심은 local & fine level에서의 dense matching을 수행하는 것이기 때문에 Coarse level에서 matching한 결과를 Fine-level에서 재조정 및 최종 매칭하도록 구성이 되어있습니다.
방식은 굉장히 간단한데, coarse-level에서 matching한 결과물 (\tilde{i}, \tilde{j} )들을 실제 fine-level feature map의 location (\hat{j}, \hat{j})으로 위치시키는 것입니다.
그 이후로 해당 위치를 중심으로 wxw 크기의 filter를 설정함으로써 해당 wxw 크기의 영역을 local feature로 보고 Fine-level matching을 수행하도록 하는 것이지요. 즉 요약하면 Coarse level 단계에서 계산된 matching location을 center point로 두고, 해당 지점 기준 w x w 크기의 영역을 local feature로 재구성하여 Fine-level matching에 활용한다는 것입니다.
아무튼 마찬가지로 Fine-level에서 feature matching을 다시 잘 수행할 수 있도록 Self & Cross Linear Attention으로 구성된 LoFTR Module을 N번 반복해서 태워 matching에 최적화된 feature map으로 변환을 시킵니다.(즉 step2와 동일한 과정을 fine level에서 진행한다고 보시면 됩니다.)
이렇게 변환된 Fine-level feature map을 \hat{F}^{A}_{tr}, \hat{F}^{B}_{tr} 라고 할 때, \hat{F}^{A}_{tr}(i) 와 \hat{F}^{B}_{tr} 의 전체 벡터들간에 matching distribution을 계산함으로써 i와 매칭되는 최적의 position j를 찾는 방향으로 매칭이 수행됩니다.
Loss Function
LoFTR 방법론은 두 뷰포인트의 Camera Pose 정보와 Depth map을 통해 두 매칭쌍에 대한 confidence matrix의 GT를 생성하여 GT confidence matrix와 모델이 추론한 confidence matrix 간에 지도학습 방식으로 학습이 진행됩니다.
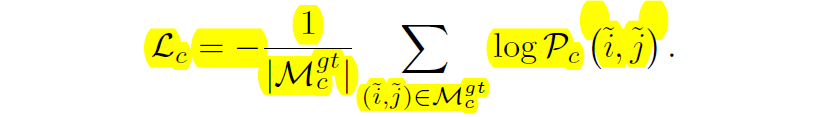
즉 위에 수식처럼 dual softmax를 처리해서 계산한 P matrix에 대해 GT 값에 대한 negative log-likelihood를 최소화하는 방향으로 모델이 학습이 되는 것이지요.
Fine level에서도 loss 값이 계산이 되는데 Fine-level에서는 단순히 query i position을 실제 GT pose와 Depth 정보를 토대로 target j로 변환했을 때의 위치와 모델이 matching한 j의 결과에 대해서 l2 distance를 계산하는 방식으로 학습이 수행됩니다.
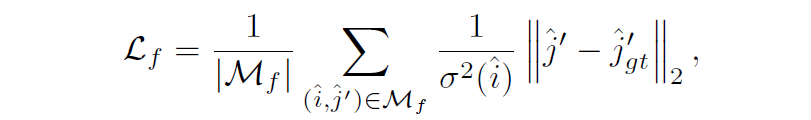
Experiments
그럼 이제 실험 섹션을 다루고 리뷰를 마무리 짓겠습니다.
일단 평가 방식은 Homography Estimation 방식과 두 영상 쌍 사이에 Relative Pose Estimation을 평가하는 방식 2가지로 이루어졌다고 볼 수 있습니다. Homography Estimation 방식은 모델이 추론한 matching pair들을 RANSAC을 통해서 Homography를 추정하고 이렇게 추정된 Homography가 영상에 적용되었을 때의 영상의 각 corner point 값과, 실제 GT Homogrpahy를 영상에 적용했을 때의 영상의 각 corner point들 간에 차이를 계산한 것이지요.
이때도 계산 값을 단순히 RMSE와 같이 regression한 것은 아니고 3픽셀, 5픽셀, 10픽셀 기준으로 해당 기준 이내로 들어온 결과값이 몇개가 있는지에 대해 True False 이진 분류 형식으로 평가를 하였으며 따라서 cumulative curve(AUC)를 계산할 수 있었다고 합니다.
Relative Pose Estimation의 경우에도 camera pose의 각도 오차가 5도 10도 20도에 따라서 임계치를 설정함으로써 AUC 곡선을 계산할 수 있었다고 합니다.
Homography Estimation 실험에 사용한 데이터 셋으로는 HPatches, 그리고 Relative Pose Estimation 실험으로는 ScanNet, MegaDepth가 존재하는데 각각의 데이터 셋에 대한 설명은 추후에 정리해보도록 하겠습니다.
그리고 저자가 비교 방법론으로 사용한 것은 detector based local feature methods (e.g., R2D2, D2Net, DISK)와 detector-based local feature matcher 방법론(i.e., Superglu with Superpoints) 그리고 LoFTR와 마찬가지로 detector free 방법론들인 Sparse-NCNet, DRC-Net을 비교 방법론으로 선정하였다고 합니다.
Quantitative Results
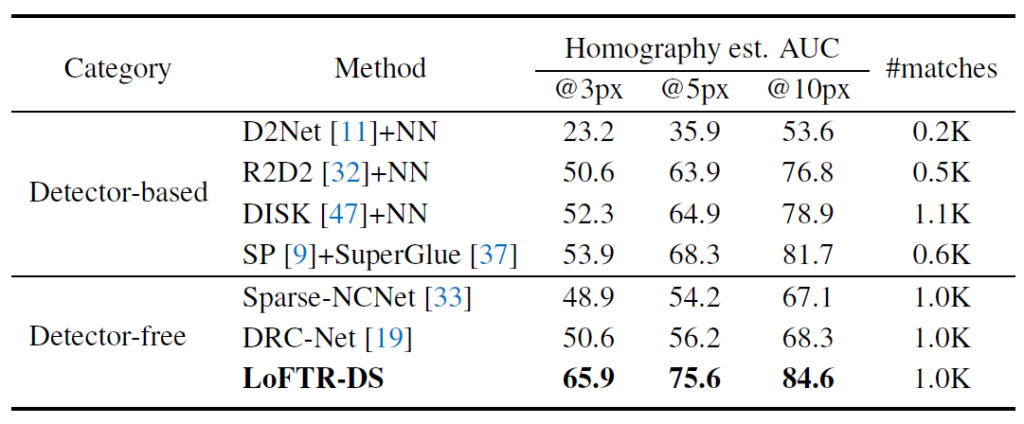
먼저 HPatches 데이터 셋에서의 성능 평가 결과입니다. 보시면 LoFTR이 Detector-based 뿐만 아니라 Detector Free 방법론도 모두 압도적으로 이겨버리는 모습입니다. (와 이정도로 성능 차이가 나는 것이면 논문 쓸 맛 진짜 났겠다..)
게다가 저자는 이러한 성능 차이가 나는 배경에 대해서 엄격한 matching confidence threshold 값의 설정에 있다고 하는데, 말그대로 threshold 값을 크게 높였을 때 타 방법론들은 매칭의 결과값들이 확 낮아지는 모습이지만 본인들이 제안하는 방법론은 매칭 스코어가 상당히 높은 쌍들이 많이 존재한다는 의미로 해석할 수 있습니다.
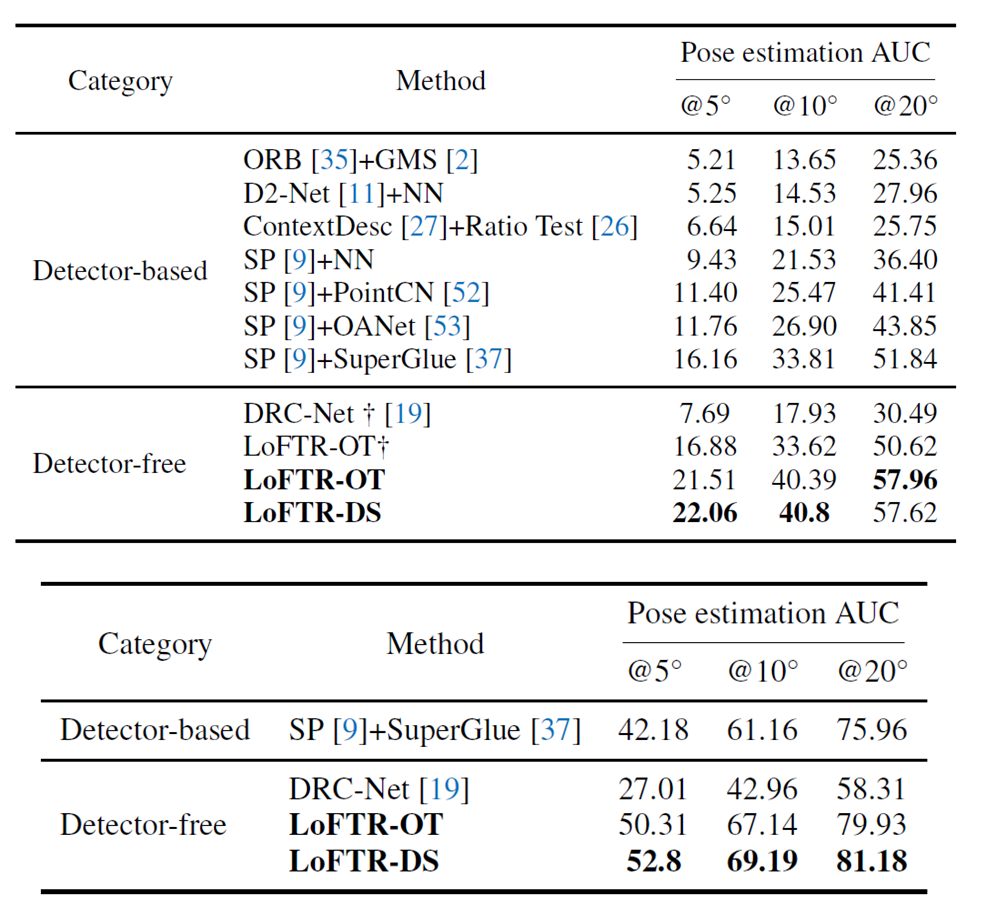
다음은 Relative pose estimation과 관련된 실험입니다. 위의 테이블은 ScanNet, 아래 테이블은 MegaDepth Dataset에서의 정량적 결과를 의미합니다. LoFTR-OT와 DS는 각각 매칭하는 방법의 차이로 DS는 Dual-Softmax라고 보시면 됩니다.
결과적으로 Dual Softmax 방식이 OT 방식보다 항상 더 좋은 성능을 보여주고 있으며 타 방법론과의 비교 결과에서도 월등히 좋은 모습을 보여주고 있습니다.
Ablation Study
다음은 Ablation Study 결과입니다.

저자들은 Ablation 실험을 재밌게 설정하였는데, 베이스라인 방법이 뚜렷하게 없다보니 자신들이 제안하는 LoFTR 방법론을 Full이라고 하였을 때, Full을 기준으로 하나씩 제거하는 방향의 ablation을 수행합니다.
즉 첫번째 행의 실험은 LoFTR의 가장 핵심인 Transformer 기반의 LoFTR Module을 컨볼루션으로 대체하게 될 경우를 의미하며, 이때 성능이 크게 드랍하는 것을 볼 수 있습니다. 이는 곧 Transformer 기반의 Global Receptive field 및 Cross Attention이 얼마나 matching task에서 중요한지 볼 수 있습니다.
2번째로는 Coarse resolution과 fine-resolution을 기존 1/8, 1/2 대신 1/16, 1/4로 바꾸었을 때 결과를 의미하는데, 더 작은 해상도에서 matching을 수행하게 되면 pose estimation 성능이 크게 감소하는 것을 볼 수 있습니다. 물론 런타임 속도는 훨씬 빨라지긴 하겠습니다만(104ms 정도 소요된다 합니다.) 성능의 드랍이 너무 커서 불합격 판정을 받은 것 같습니다.
3번째 행은 Transformer에서 positional encoding을 DETR 방법론이 그랬던 것처럼 각 layer별로 적용을 해보는 방식을 의미한 것 같은데, 그 경우에도 성능에 그리 긍정적인 모습을 보이지 못했다고 합니다. 제가 리뷰에다가는 디테일하게 다루지는 않았지만, 실제 그림4에서 보듯이 positional encoding은 LoFTR Module의 입력 전에 단 한번만 사용이 됩니다.
마지막으로 LoFTR 모듈의 반복 횟수를 기존 Coarse level 4, Fine level 1에서 각각 2배 키운 8개와 2개로 설정할 경우 5도 이내에서의 AUC 성능은 조금 더 향상했지만 그 외에는 성능이 오히려 떨어졌으며 성능의 편차도 그리 크지 않아서 효율성을 위해 더 적은 반복 횟수를 선택했다고 합니다.
Qualitative Results
다음은 정량적 결과입니다.

확실히 indoor와 같이 texture less한 상황(2번째 행) 혹은 view point의 변화가 너무 심한 경우(1행)에서는 superpoint의 keypoint 자체가 온전히 잘 뽑히지 않아서 superglue라는 좋은 매칭 결과를 사용하더라도 매칭 결과물 자체가 없는 모습입니다.
물론 outdoor에서는 특징으로 잡을 요소들이 실내보다 상대적으로 더 많고 뚜렷하기 때문에 superpoint+superglue도 좋은 매칭 결과를 보여주는 듯 보입니다만 LoFTR의 경우에는 실내와 실외 다양한 상황에서 좋은 매칭 결과물을 보여주고 있습니다.
특히 3번째 행의 야외 환경에서 superpoint + superglue의 경우 matching 정확도는 100% 이지만 매칭 쌍의 개수가 296개인 반면에 LoFTR의 경우 915개 중에 900개의 매칭을 올바르게 성공하여 확률대비 매칭 정확도가 우수하다고 볼 수 있습니다.
결론
시기적절하게 Transformer 모듈을 잘 활용했으며 그 결과 Homography Estimation과 Pose Estimation 벤치마킹에서 월등한 성능을 낸 좋은 논문이라고 생각합니다. Attention 연산이 흔하게 사용되고 있는 요새에는 그렇게 참신하다! 라는 생각이 덜 들수도 있겠으나 21년도 당시에 이런 흐름을 제안했다는 것은 상당히 고평가 될 부분이라고 생각이 드네요.