오늘도 SSL에 관한 논문을 들고왔습니다. 지난번 논문의 연장선(?) 같은 느낌인데요. 이 논문에서도 pretext-task 없이 representation을 학습하는게 detection과 같은 Task에서 더 성능이 좋다는 논문입니다.
Introduction
이미지 기반 SSL의 기본적인 성공은 contrastive objective와 instance discrimination pretext task의 학습에 있습니다. 이러한 학습 방식을 이용하여 downstream task에서 지도학습에 준하는 성능을 달성해왔습니다. 비디오에서도 이러한 이미지 기반 SSL의 방식을 확장해서 사용을 하고 있지만, 대부분의 논문들이 공통적으로 지적하는 것과 같이 다양한 instance와 scene context로 구성된 temporal한 정보를 명시적으로 반영하지는 못합니다.
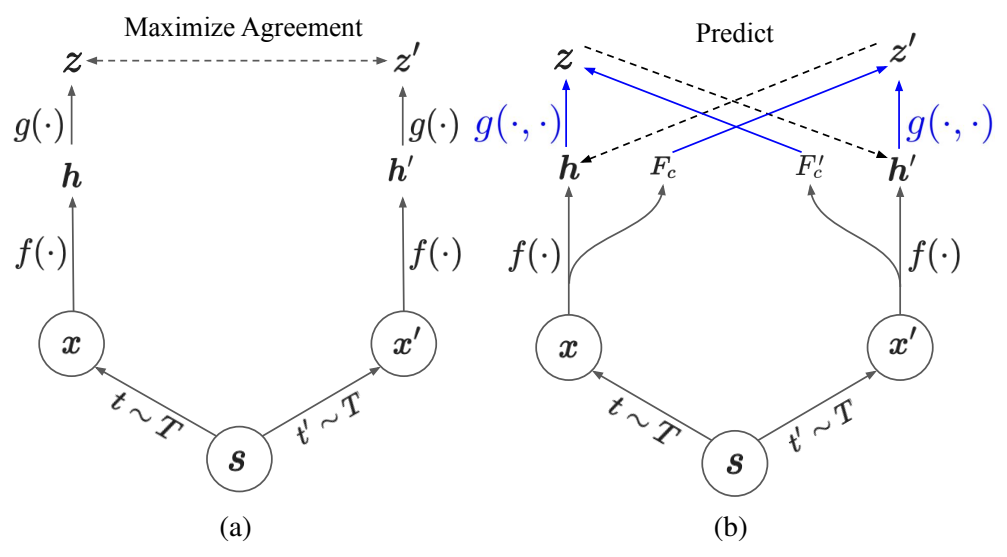
위 (a)번 그림은 일반적으로 이미지 기반 SSL에서 학습하는 구조인데요. 샘플링된 특정 이미지를 가공하여 두가지의 이미지(view)를 만들고, 두 이미지를 positive로 두고 학습을 수행합니다. 이러한 방식을 비디오에 그대로 적용하게 될 경우 이미지에 비해 덜 효율적인데요. 비디오에서는 프레임간의 변화에 따라 시각적인 특성이 변하기 때문에 그렇습니다. (같은 물체도 시간의 흐름에 따라 다르게 보이기 때문) 그래서 이러한 학습 방식을 단순하게 강제하면, 영상 끼리 공유할법한 짧은 영역의 프레임들의 표현만을 학습하는 경향성을 보일 수 있다고 합니다. 게다가 이 때 연구 흐름 기준으로 downstream task의 경우에는 pretext-task를 정의해서 학습하는 방식을 쓰고 있었지만… 실상은 contrastive learning과 같이 시각적 이해를 높히는 방향의 학습이 더 좋은 성능을 보였습니다.
이러한 상황에서 논문 저자는 Contextualized Spatio-Temporal Contrastive Learning(ConST-CL)을 제안하는데요. 이 방법론이 위의 (b)번 그림에 해당합니다. 이 방식은 Global contrastive objective를 통해 spatio-temporal 일관성을 강제하는 학습 방식의 단점을 우회하면서, spatio-temporal한 특성을 배우는 방식입니다. (강제하는 방식의 예시가 딱히 없는데 아마도 global feature를 따로 만들어서 학습하는 방식들이거나, 비디오를 표현하는 feature를 이용해서 학습하는 방식들을 말하는 것 같네요) 이를 우회하기 위해서 기존의 방식과 다르게 projection function g(\cdot, \cdot)을 이용해서 instance feature만을 다루는 것이 아니라 context feature도 고려할 수 있도록 함수를 설계했다고 하네요.
(instance feature는 원본 view로 부터 추출된 feature이고, context feature는 타겟 view에서 추출되는건데 변형된 이미지로부터 공통적인 특징을 학습하면 semantic한 정보를 추가적으로 배워서 이렇게 표현하는 것 같습니다.)
이렇게 학습을 하면서도 global(이 논문에서는 holistic이라고 쓰네요) representation과 local representation의 불균형에서 기인하는 문제를 해결하기 위해서, 모델이 두 정보를 함께 배울 수 있는 2개의 브랜치 모듈을 디자인했다고 합니다.
그래서 Contribution을 정리하면…
- fine-grained spatio-temporal 표현력 학습을 위한 영역 기반 contrastive learning 프레임워크 제안
- video feature의 지역적인 특징을 고려하면서도 의미론적으로 일관된 학습이 가능한 contextualized region prediction task 제안
- holistic(global) & local 표현력 학습을 조화롭게 수행하는 간단한 네트워크 설계
- Downstream task에서의 좋은 성능
이라고 하네요~.
Method
(아래에 있는 [그림 2]를 먼저 보시고 읽는 것을 추천드립니다)
Region-Based Contrastive Learning in Videos
백본은 R3D라는 3D Resnet을 이용하고, 백본 f(\cdot)에 의해 추출되는 비디오 \{x,x'\}에 해당하는 video-level representations은 \{z,z'\} \in \R^c와 같이 표기합니다. 이 feature들로 학습하는 video-level global contastive loss를 L_g라고 표현합니다. 이렇게 단순하게 학습을 하게 되면 global feature들의 유사도는 높아지겠지만, dense prediction task(localizaton이나 object detection)에서 중요한 local feature들에 대한 학습이 잘 안됩니다. 그래서… spation-temporal 도메인에 확장해서 학습하는 방식을 사용합니다. 추출된 Feature 맵에 대해서 \{F,F'\} \in \R^{T \times H \times W \times C}라고 표현할 때, feature 내의 복셀을 h_i \in F / h_j^{'} \in F'로 표현합니다.
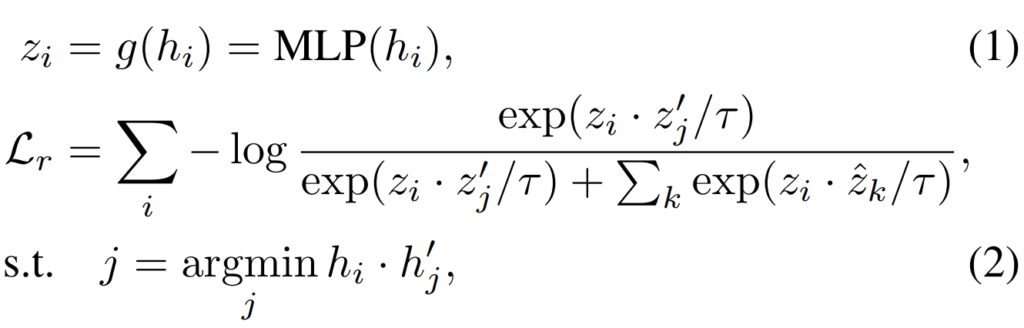
[수식 1]은 해당 모델에서 projection을 수행하는 과정이라고 보면 되고요. [수식 2]는 복셀 단위의 InfoNCE Loss(\hat{z}는 negative)입니다. 즉, 이 모델에서는 전체 이미지를 가지고 contrastive learning을 수행하는 것이 아니라, 이미지의 특정 부분인 복셀단위로 학습을 수행합니다. 뒤에서 나올 [그림 2]를 보면 이해가 쉬운데요. 이미지 내에서 특정 영역 단위 학습을 수행한다고 보면 됩니다. (그림에서는 마치 사물이 위치한 곳에서 샘플링을 하는 것 같지만, 실제로는 랜덤입니다.) 따라서 수식의 \{i,j,k\}는 모두 그리드 좌표를 의미하게 됩니다.
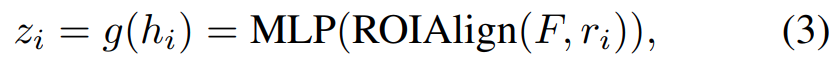
이 좌표에 접근하는 방식은 Faster-RCNN의 ROIAlign을 사용해서 feature를 가져옵니다. 수식으로는 [수식 3]과 같이 구성되어 있고, 좌표 자체는 r = \{t, x_{min}, y_{min}, x_{max}, y_{max}\}입니다.
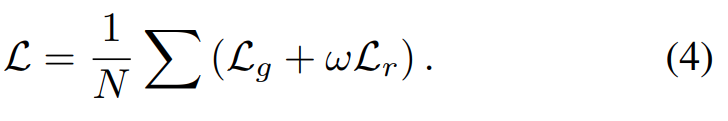
그래서 전체 Loss는 [수식 4]와 같이 구성되는데요. L_g가 뭔지 안나와서… 아마도 infoNCE 같기는 하지만, 두 Loss를 더해서 최종 Loss로 사용합니다.
Contextualized Spatio-Temporal Contrastive Learning (ConST-CL)
앞에서 설명한 “Region-Based Contrastive Learning in Videos”는 큰 단점이 있습니다. 이 학습 방식은 비디오의 특성상 프레임에 따라서 instance의 모양이 바뀌지만, 이러한 것을 고려하지 않고 항상 유사해지도록 학습한다는 것입니다. 그래서 이 논문 저자들은 Contextulaized Spatio-Temporal Contrastrive Learning(ConST-CL)를 제안합니다. 이 모델의 핵심은 source view의 이미지로 target view를 복원하는 학습 방식이 핵심인데요. 아무것도 없으면 복원을 못하겠죠? 그래서 target view의 context feature들을 이용해서 복원을 시킵니다.
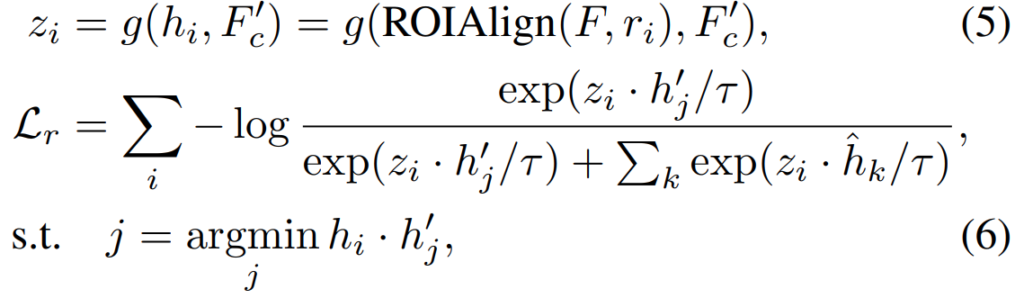
수식으로는 위의 두 수식인데요. “Region-Based Contrastive Learning in Videos”와 유사한 형식이지만 크게 보면 [수식 5]에서 입력이 두가지가 되었습니다. 이는 이 모듈이 복원 관점에서 작동해야하기 때문에 그러한데요. ROIAlign(F,r_i)는 source view의 특정 박스를 의미하고, F_c^{'}는 이제 target view의 context feature를 뜻합니다.
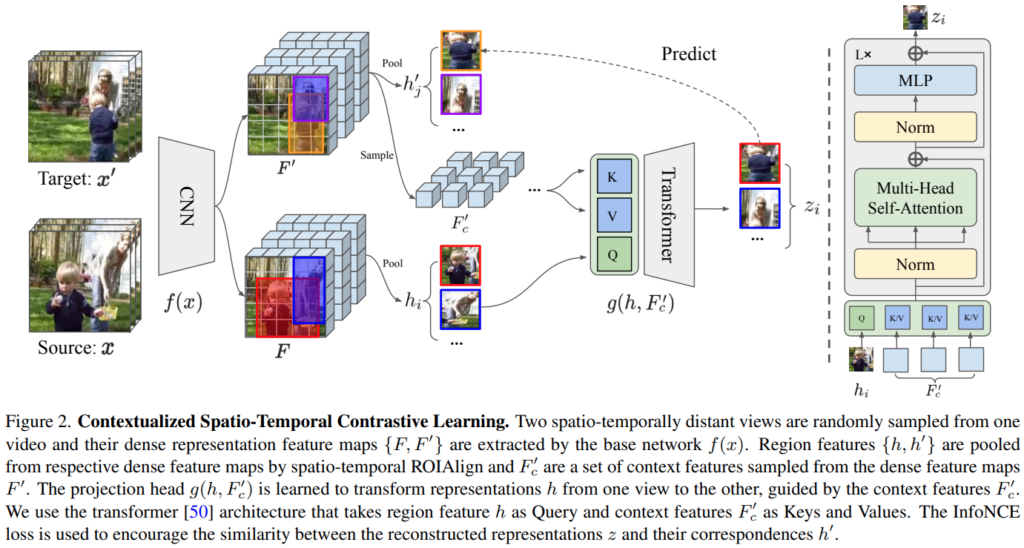
논문 배치상 이 그림이 조금 더 일찍 나와야할 것 같은데, 너무 뒤에 나오네요. 아무튼 [그림 2]가 전반적인 학습 과정에 대한 그림입니다. Context feature에 대한 설명을 이어서 하자면, 이 feature가 트랜스포머 디코더의 Key, Value로써 활용됩니다. Context feature 자체는 특정 영역을 가져오는건 아니고, F'에서 임의의 간격을 두고 subsampling 한 feature라고 보면 됩니다. 디코더의 Q에는 source view의 feature가 들어가기 때문에, target의 정보를 바탕으로 새로운 프레임을 복원해낸다고 보면 됩니다.
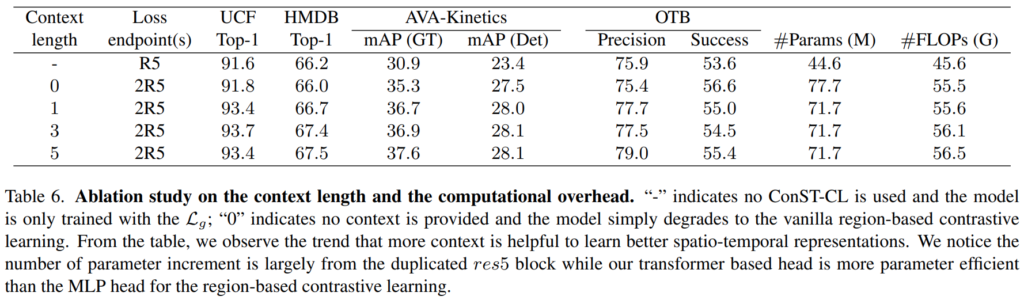
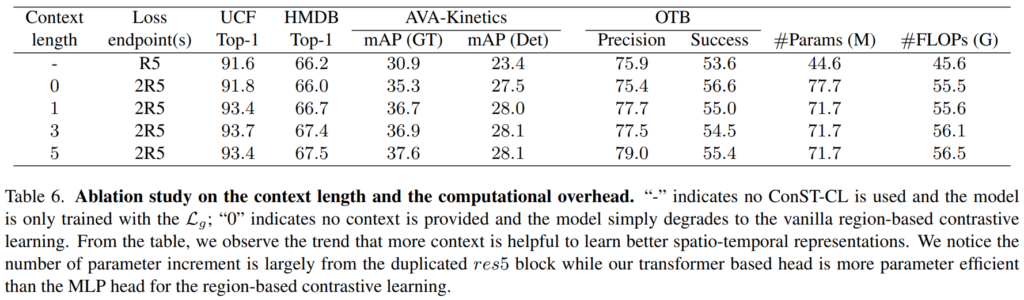
이 Context feautre는 context length에 따라 뽑히는데요. 적당한 간격을 두고 뽑아야 좋은 성능을 보이는 것을 알 수 있습니다.
Region Generation
“Region-Based Contrastive Learning in Videos”에서 입력으로 들어가는 박스가 랜덤이라고 설명했는데요. 학습에 사용하는 Kinetics-400 데이터 셋에 박스 정보가 없어서 그렇지, 실제로 있다면? 활용해볼 수 있다고 생각할 수 있는 부분입니다. 그래서 논문 저자들도 3가지 방향으로 이 방식을 고민해봤다고 하는데요. 최종적으로 사용한 random boxes와 boxes from low-level image cues, boxed from detectors입니다. 디텍터를 쓰는 방법은 다들 아실 것 같고, low-level image cue에서 박스를 치는 방식은 저도 몰랐는데 고전적으로 사용하는 기계학습 방법론이 있네요. 학습 기반이랑 아닌 것 정도로 나누어서 고민을 해본 것 같습니다.
실제로 실험 결과도 바로 이어서 보면, 사실 이 박스 정보가 정확한지 유무는 사실 학습에 크게 영향을 미치지 않는 요소이기 때문에, 최종적으로는 Random으로 결정했다고 합니다.
Balancing Global and Local Losses
기존의 방식들이 구분력 있는 local feature가 global representation으로 추출될 수 있음을 증명해왔고, 이 방식을 잘 생각해보면 global & local representation에 제약조건을 잘 걸면… 상호 보완적으로 학습이 수행될 수 있다는 결론에 도달하는데요.
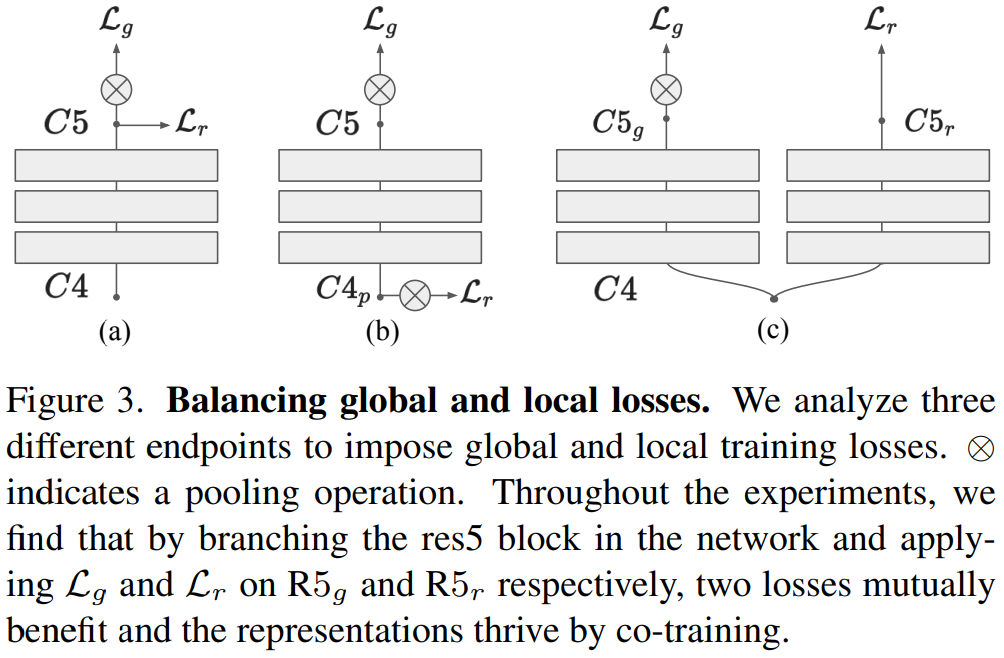
이 논문에서는 이러한 발견을 적용하기 위해서 백본으로 사용하는 ResNet3D-50 구조를 수정합니다. C5의 끝부분에 local loss를 추가하는 방식이 이 방식인데요. Average pooling이 수행되기 전에 loss를 계산하는 것이 핵심입니다. 이 방식은 [그림 3]의 (c)의 형태로 수정이 되었는데요. 보면 알겠지만 마지막 res5 블록을 복제해서 한쪽은 global loss를 계산하고, 한쪽은 local loss를 계산하는 것을 볼 수 있습니다.
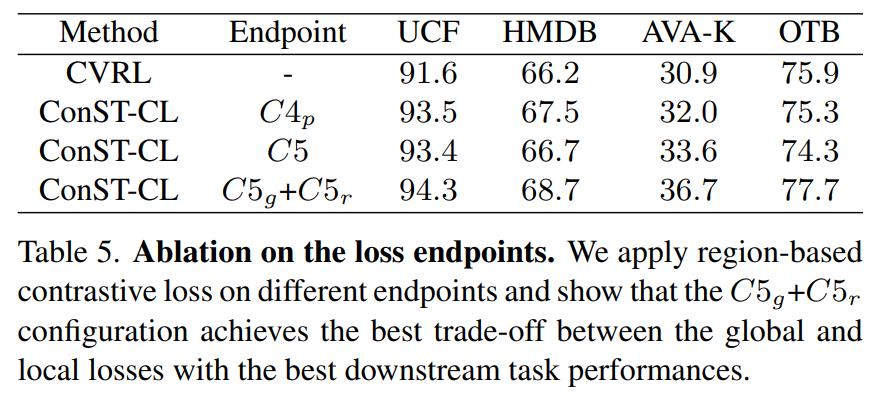
실제로 이 조합에 대한 실험 결과가 [표 5]에 위치하는데요. 모델의 레이어 추가로 인하여 약간의 코스트 증가가 있긴 하지만, 기본적으로 AVA-K와 OTB와 같은 downstream task에서 성능이 꽤 오르는 것을 볼 수 있습니다.
Experiments
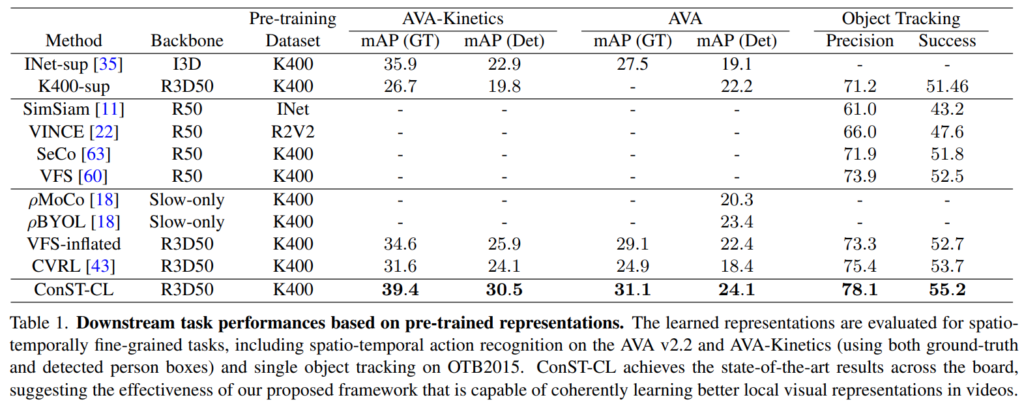
[표 1]은 이제 사전학습 표현력에 대한 성능 비교인데요. AVA로 시작되는 데이터 셋들은 object detection(사람 찾는거긴 한데…)쪽 TASK라고 보시면 됩니다. 이게 비교군 성능이 비어있는 이유는 원래 분류 성능만 측정하는 애들이 많아서 그런 것 같네요. 동일 백본 사용하는 비교군들 중에서도 가장 성능이 좋은 것을 볼 수 있습니다.
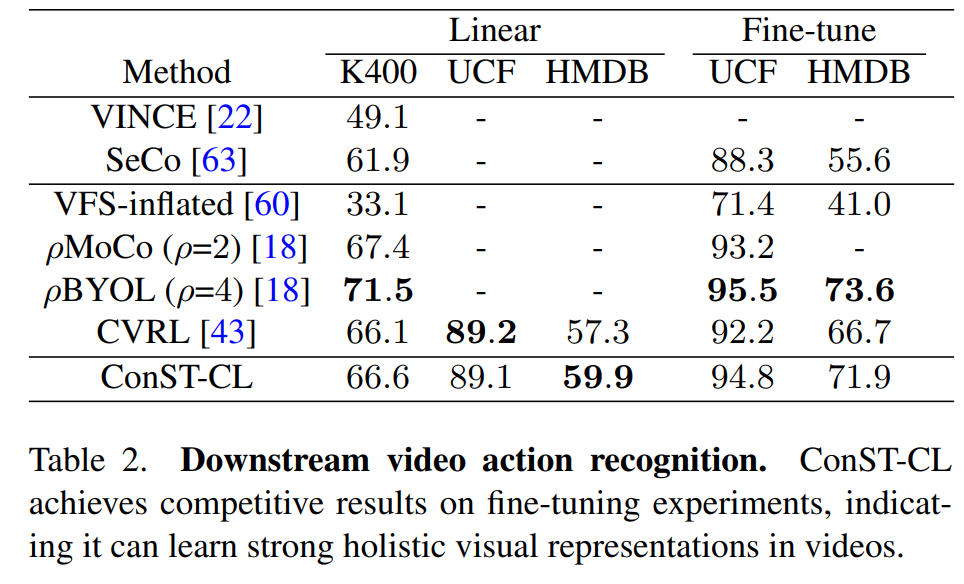
분류 문제에서도 가장 좋은 성능 까지는 아니고, 준수한 성능을 보이는데요. 이 부분에 대해서는 중요한 사실 하나가 포함되어 있습니다. 다른 방법론과 달리 ConST-CL은 fine-tuning을 안합니다. 그래서 성능 차이가 좀 떨어져 보이는데요. 그럼에도 불구하고 이렇게 좋은 성능이 global & local feature에 제약을 주는 Y자 형태의 모델 수정이 유효했음을 입증합니다.
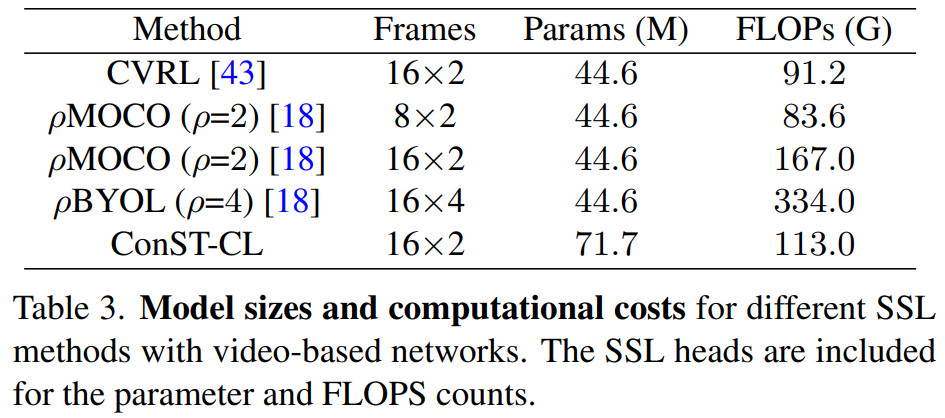
또한, 모델 입력 프레임 갯수와 크기에 대해서도 비교를 하는데요. 모델을 수정했고, 트랜스포머를 쓰기 때문에 파라미터 자체는 클 수 밖에 없지만, 연산량 측면에서는 오히려 더 적다는 점을 강조합니다.
Conclusion
논문에서는 이제 좀 더 fine-grained 표현을 학습하기 위한 self-supervision signal이 빠져있고, ViT 구조를 그냥 쓰는게 최선의 형태는 아니라고 한계까지 명확하게 언급하는 논문 오랫만에 잘 봤습니다. 필요한 ablation은 이번에는 중간중간 넣어서 실험 부분이 짧게 느껴지는데 중요한 부분은 다 소개해드렸으니 리뷰 마치겠습니다.