Introduction
Instance image retrieval task는 query에 나타난 특정 object를 데이터베이스에 존재하는 large/unordered 이미지에서 찾는 것을 의미합니다. 이 과정은 주로 CNN을 통해 이루어지는데요, 적은 메모리 사용과 높은 정확도를 보여주어 CNN-based 방법론이 널리 사용되었습니다. ImageNet과 같이 large annotated dataset으로 사전 학습된 네트워크들은 adaptation ability를 보여주었는데요, 특히 CNN에서 추출된 feature map(이하 activation)은 retrieval을 포함한 다양한 task에서 image discriptor로 사용되며 그 효용성을 입증하였습니다.
본 논문은 CNN을 fine tuning하여 image retrieval을 수행하였습니다. Fine tuning pretrained된 network에 추가적인 학습을 진행하여 다른 task에 보다 잘 적용 가능하도록 만드는 것입니다. 그러나 fine-tuning을 진행하기 위해서는 추가적인 annotated데이터가 필요하다는 단점이 있습니다. retrieval에서 fine-tuning 기법을 적용한 방법론으로는 NetVLAD가 있습니다. 간단히 말하자면 imagenet으로 사전 학습된 CNN backbone을 geo-tagged 이미지로 fine tuning시키되, similarity measure를 직접적으로 optimize하여 query와 matching되는 positive pair와 non-matching되는 negative pair를 활용하였습니다.
Architecture, learning, search
- generalized-pooling layer
- contrastive loss
- two-branch network
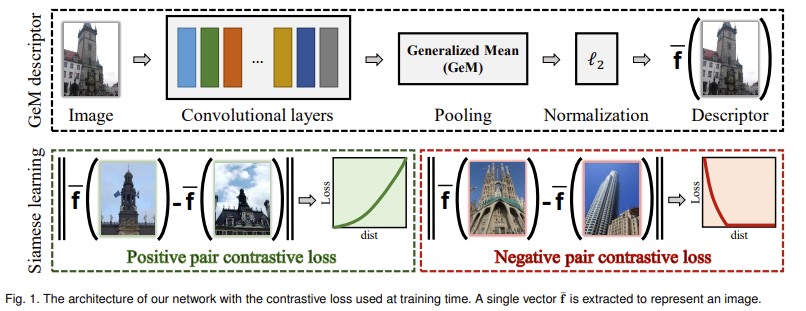
[그림 1]은 논문에서 제안하는 image retrieval의 pipeline을 나타내고 있습니다. 또한 이는 일반적인 image retrieval의 filtering에 사용되는 discriptor 추출 방식을 나타내기도 하는데요, 기존의 NetVLAD나 MAC, R-MAC과 같이 CNN에서 feature map(response)이 출력되면 하나의 벡터로 만들게 되며 이를 f(x)로 표현하였습니다.
Generalized-mean pooling and image discriptor
[그림 1] 상단의 GeM discriptor에서 저자들이 새롭게 제안하는 부분은 Generalized mean pooling 레이어로 수식으로 표현하면 아래의 수식(3)과 같습니다.
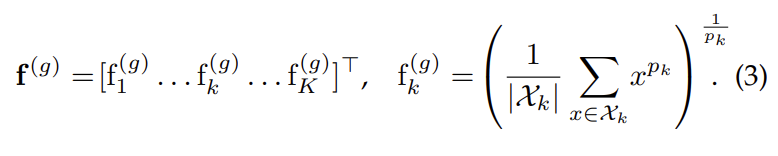
위 수식에서 X는 W \times H \times K 크기의 3D tensor, p_k는 pooling 파라미터입니다. max pooling과 average pooling은 위의 generalized mean pooling으로 나타낼 수 있는데요, p_k = 1이면 f(x)는 average pooling이, p_k → \inf 이면 max pooling이 됩니다.
p_k는 사용자에 의해 설정될 수도 있지만 f를 미분 가능한 형태로 변형하여 학습을 통해 설정되도록 할 수 있습니다,
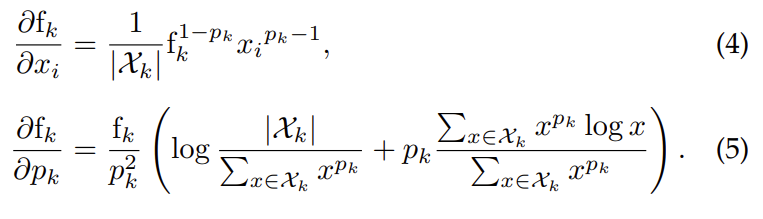
식(4, 5)를 통해 pooling이 backpropagation 과정에 포함되면 p_k는 학습을 통해 결정되고 결과적으로는 feature map의 각 W \times H 마다 서로 다른 pooling 파라미터를 사용하게 됩니다. 실험 파트에서 pooling 파라미터가 hand-tune하여 fix된 경우와 학습을 통해 설정된 경우의 실험이 있으니 나중에 다시 살펴보도록 하겠습니다.
Siamese learning and loss function
network의 학습에 사용된 loss는 contrastive loss로 두 query와 sample간의 matching 관계를 고려하였습니다. 앞서 리뷰했던 NetVLAD, R-MAC등 다른 retrieval의 training 방식을 살펴보면 [query, positive/negative]와 같이 두 이미지가 pair하게 구성되는 것을 알 수 있습니다. 여기서도 training input이 두 이미지 (i, j)로 구성되며, 이 이미지 쌍의 관계에 따라 label Y가 추가되어 최종 loss는 아래의 식(6)과 같이 사용되었습니다.
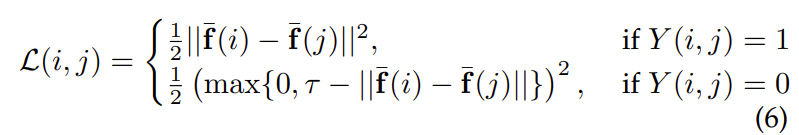
i와 j가 matching 되면, 즉, j가 i의 positive sample이면 Y(i,j)=1이 되고 그렇지 않으면 0이 됩니다.
Whitening and dimensionality reduction
앞서 설명한 과정을 다시 정리해보면 CNN으로 추출한 feature map을 GeM pooling 레이어에 통과시켜 discriptor f를 추출하였으며, 이를 GeM 벡터라고 합니다.
이렇게 추출된 GeM 벡터는 두 단계에 거쳐 post-processing을 진행합니다. 이전 방법론들은 PCA를 사용하여 discriptor의 whitening과 차원 축소를 진행하였는데요, 이 논문에서는 whitening과 rotation의 두 단계의 과정을 통해 labeled data를 leverage하고, 차원 축소를 진행하였습니다.
- whitening
whitening 단계는 intra class의 공분산 행렬 C_S가 식(7)과 같이 정의되었을 때 C_S의 제곱근의 역수에 해당하는 C_S^{-1\over 2}을 의미합니다.
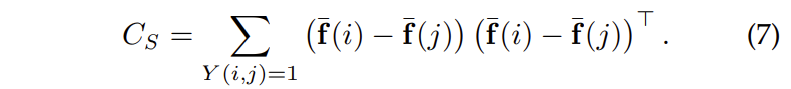
- rotation
rotation non-matching 쌍에 해당하는 interclass의 공분산 행렬인 C_D에 PCA를 적용하는 단계에 해당합니다.
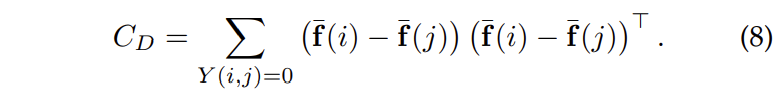
Image representation and search
학습이 종료되면 [그림 1]과 같이 query 이미지를 네트워크에 입력하여 GEM discriptor를 추출합니다. 여기서 추출된 discriptor를 scale invariant하게 만들기 위해 test시에는 추가로 multi-scale processing을 진행합니다. 기존에 사용하던 방법론과 동일하게 입력 이미지를 여러 scale로 주는 방법을 사용하였습니다. multi scale로 입력된 각각의 이미지는 각 scale에서 representation 벡터를 생성하여 최종적으로는 하나의 벡터로 통합하여 multi-scale의 representation을 생성합니다.
Image Retrieval에서는 query descriptor와 database descriptor의 Euclidean search를 진행합니다. Euclidean search란 l2-normalized 된 벡터간의 내적을 구하고 sorting 하는 것입니다.
최근에는 대부분 CNN global image discriptor를 average query expansion과 결합하여 사용하고 있고, 거의 starndard한 방향으로 굳어져서 저자들도 공정한 비교를 위해 이를 사용하였다고 합니다.
Experiments
Pooling methods
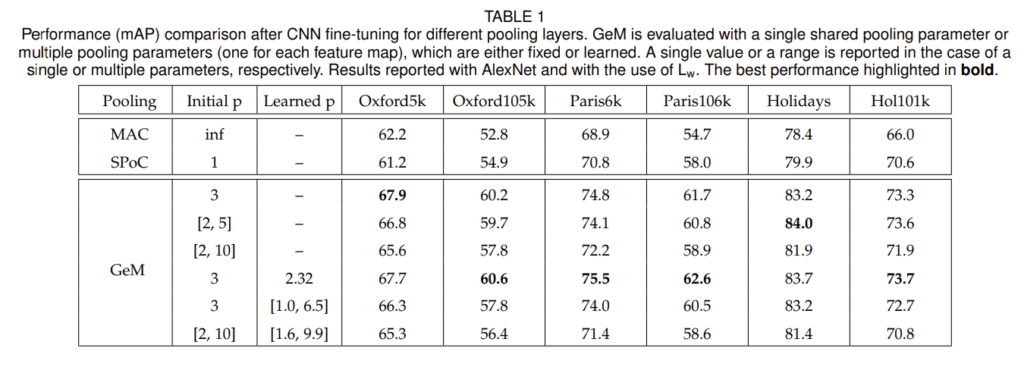
[표1]은 pooling layer에 따른 retrieval 성능으로 전반적인 task에서 기존 방법론에 비해 GeM레이어가 높은 성능을 달성한 것을 확인할 수 있습니다. 특히 GeM은 pooling 파라미터 p에 따른 실험 결과를 리포팅하였는데, 크게 파라미터의 고정 유무와 siamese network간의 share 여부를 비교하여 실험을 진행하였습니다. 결과에서 learned p가 존재하지 않는 실험은 고정된 initial p 값을 사용하여 pooling을 진행한 것이고, p값이 두 개 존재하는 실험은 siamese network에서 각각 추출된 두 feature map에 별개의 p값을 사용한 것입니다. [표1]을 다시 살펴보자면, shared 파라미터를 사용하는 것이 multiple 파라미터를 사용한 경우보다 높은 성능을 보이는 것을 확인 할 수 있습니다. 이는 별개의 파라미터를 사용함으로 인해 보다 복잡한 cost 함수를 사용하기 때문입니다.
다음으로는 shared parameter를 사용하는 경우, 학습을 통해 p를 결정하는 것과 고정값을 사용하는 것은 거의 비슷한 성능을 보입니다. 따하서 저자들은 뒤의 실험들에 single+shared+learned 파라미터를 사용하였습니다.
Learned projections
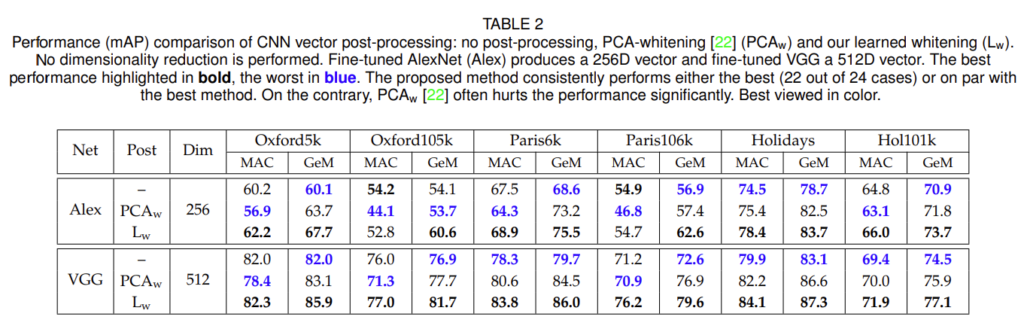
[표2]는 PCA-whitening의 우뮤에 따른 성능으로 각각 non-whitening, PCA-whitening, learned PCA-whitening을 비교하였습니다. 보시면 모든 벤치마크에서 GeM+Learned PCA를 사용한 것이 가장 좋은 결과를 보이는 것을 확인할 수 있습니다.
Comparison with the state of the art
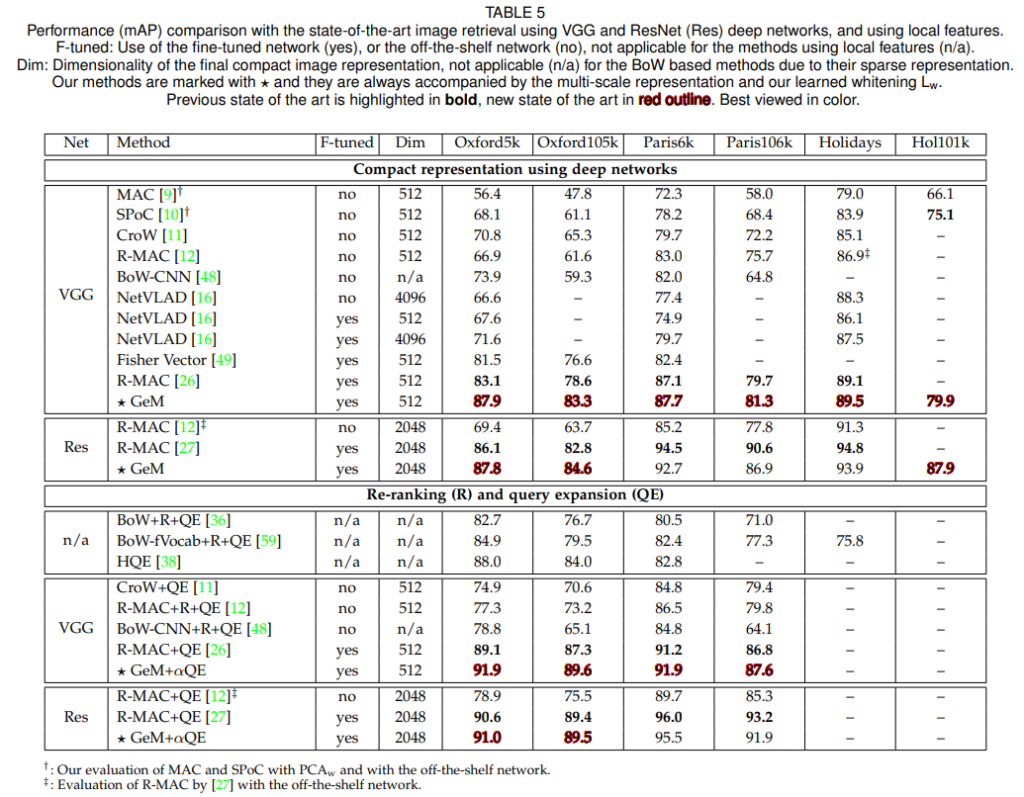
마지막으로 sota와의 결과 비교를 끝으로 리뷰 마치겠습니다.
안녕하세요 혜원님!
‘이렇게 추출된 GeM 벡터는 두 단계에 거쳐 post-processing을 진행합니다. 이전 방법론들은 PCA를 사용하여 discriptor의 whitening과 차원 축소를 진행하였는데요, 이 논문에서는 whitening과 rotation의 두 단계의 과정을 통해 labeled data를 leverage하고, 차원 축소를 진행하였습니다.’
1. 이 부분에서 ‘whitening’이 무엇인지 궁금합니다.
2. GeM 벡터의 차원을 축소하는 과정이 왜 진행되는지 궁금합니다!
안녕하세요 정의철 연구원님! 댓글 감사합니다.
1. whitening이란?
해당 블로그 글을 참고하시면 좋을 것 같은데요, 입력 벡터를 평균을 0, 표준 편차를 1로 만들어주는 정규화의 한 방법이라고 생각하시면 될 것 같습니다.
2. 차원 축소를 해주는 이유?
이 논문의 task가 image retrieval이기 때문에, 이미지의 detail한 정보보다는 이미지의 전체적인 정보들을 비교하고자 하는 것입니다. PCA를 통해 차원 축소를 진행하면 GeM벡터값을 해당 벡터의 특징이 잘 나타나는 축으로 projection하게 됩니다. 즉, 고차원의 데이터를 저차원으로 바꿔주면서 공간적 detail 정보는 소실되지만 translation에 강인하면서도 적은 연산량을 가지게 되는 것이죠.