안녕하세요. 열 네번째 X-Review입니다. 본 논문은 이전 김지원 연구원님이 테크관련공유에 공유해주신 내용으로 페이스북의 AI Robotics KR 페이지를 보다 우연히 작성하신 글을 보아 시간 날 때 읽어봐야지 했는데, 종강 이후 편한 마음으로 읽어본 논문입니다.
우선 본 논문을 리뷰하기 앞서 연구원분들은 URP를 통해 Camera Grabber를 경험하셨지만 Sensor에 대해서는 심도 깊이 다루지 않았다는 가정 하에 잘 알고 있을 LWIR과 비교하여 글을 작성하겠습니다. Benchmark 논문이지만 저자가 NIR을 사용한 이유에 대해 자세히 쓰여져 있더라면 좋았을 아쉬움이 있어 스스로의 고찰도 함께 담아 작성하겠습니다. 이외 최근 Object detection과 Pedestrian detection 논문을 읽다보며 드는 사견을 주로 작성하였으니 편한 마음으로 읽어주시면 좋을 것 같습니다. 그럼, 시작하겠습니다.
Introduction
도로 교통 사고로 사망하는 인구는 일년에 몇 명인지 아시나요? 135만명으로, 하루 3,700명에 달합니다. 교통 사고 사망자는 주로 보행자, 오토바이 운전자, 자전거 탑승자로 이러한 도로 위 보호가 부족한 이들을 보호하기 위한 보행자 보호 시스템인 PPS (Pedestrian Protection System)은 비전 분야에 중요한 주축으로 삼아져 오고 있습니다. Detection 분야 논문은 보통 “CNN의 성장에 힘입어”, “자율주행 자동차의 발전에 더불어”로 시작하는데, “하루 3,700명”이라는 표현이 눈을 사로잡았네요.
비전에서 보행자 탐지 (Pedestrian Detection; 이하 PD)와 (보행자 등과의) 거리 탐지 (Distance Detection; 이하 DD)는 중요하면서도 어려운 지점입니다. 위 김지원 연구원이 페이스북 페이지에 작성한 글에서 발췌한 아마존 자회사인 Zoox의 How Zoox Autonomous Vehicles ‘Perceive’ Their Surroundings 영상을 보면 차량이 빠르게 움직임에 따라 Inference가 실시간으로 변화하는 모습을 볼 수 있습니다. “Object Detection (이하 OD) 분야는 saturation (포화)되었다!”고 말하는 이들도 많지만 최근 SoTA 논문에서도 mAP는 실생활에 사용하기에는 부족해보이며 (COCO 테스트 데이터 셋에서의 SoTA mAP는 65% 수준입니다), 성능 향상을 위한 다양한 방법이 여전히 실험되고 있습니다.
하지만 PD는 OD의 한 부류로 보이면서도 풀어야하는 문제가 특정되어 있습니다. 바로 PD에서의 추론 속도 (Inference Time; FPS)이며 이는 굉장히 중요합니다. 완전 자율 주행을 위해서는 자율 주행 차량의 속도에 무관할 수 있는 수준의 추론 속도와 정확성을 모두 지녀야합니다. 사실 본 내용은 연구실의 연구원분들이 모두 알고 있음직한 내용이지만 최근 실험을 설계하며 아이디어 자체에서 정확도와 추론 속도의 Trade-off를 고려함에 있어 더욱 어려움을 느껴, 그 중요성을 다시 상기하는 중입니다. 그러면서 근래의 논문은 사용하는 OD와 PD에서 사용하는 데이터 도메인 등에 따라 성능 향상이라는 문제를 푸는 관점이 다른 것 같아 보여 PD는 OD의 한 부류가 아닌 다른 독단적인 Task로 여겨지는 것이 맞지 않을까 싶기도 합니다.
사견이 길었네요. PD는 Visble light (이하 VIS)를 활용한 데이터 셋이 많이 존재합니다. Multispectral은 PD 분야를 주로 하는 이들이 아니면 아직 생소한 개념입니다. VIS는 조도가 높은 낮에 장점을 보이지만, 조도가 낮은 밤에는 좋지 못합니다. 이는 영상을 살펴봤을 때 육안으로도 확인이 쉽지 않은 특징을 생각했을 때 당연하지만 보다 앞서 영상에서 잘 보이지 않을 수 밖에 없는 이유의 측면에서 살펴보겠습니다.
Visible light and Infrared
VIS, Visible light는 국어로 가시광선입니다. 말 그대로 육안으로 볼 수 있는 빛을 의미합니다. 알고 있는 내용이지만 놓치고 있는 부분으로, 빛이 없으면 VIS를 활용한 카메라에서도 보이지 않습니다. 가시광선의 파장은 380-750 nm 영역으로 영역에 따라 육안에 인식되는 물체의 색이 다릅니다. 우리는 무지개를 빨주노초파(남)보로 아는데, 이는 무지개가 곧 햇빛의 굴절 현상이기 떄문입니다. 즉 빛이 차단된 암실에서 물체를 본다면, 빨간색 물체라도 우리 눈은 빛이 없으므로, 물체가 빨간색 파장의 광선을 반사하지 못하여 검정색으로 보입니다.
이 또한 평소에는 관심을 가지지 않아도 들으면 당연하지하며 생각하는 내용입니다. 그렇다면 가시광선을 활용하는 카메라는 햇빛이나 조명이 물체에 반사되는 파장 영역의 광선을 흡수하는 방식과 가시광선을 방출하여 물체에 반사되는 파장을 흡수하는 방식 중 어떤 방식일까요? 이 또한 조금만 생각해보면 알 수 있는데, 전통적인 야간 촬영은 카메라 플래시라는 보조 광원 장치를 활용합니다. 그렇다면 최근 아이폰 등의 스마트폰에서 지원하는 야간 촬영은 플래시 없이도 가능한데, 이는 장시간 노출을 통해 광원을 최대한 흡수하고 몇 초간의 촬영을 통해 다중 프레임의 이미지를 합성하는 방식으로 인해 가능합니다. 즉, 어떤 방식이든 물체에 반사되는 가시 영역의 광원이 있어야만 합니다.
이를 자율주행 관점에서 살펴보면 야간 환경에서 VIS 카메라 이미지를 활용한 연구는 지양되는 것이 옳아보입니다. 이는 저조도 환경에서 VIS 카메라가 충분한 광원을 얻기 위해서는 충분한 시간이 필요하며 이는 언급한 추론 속도를 조금이라도 빠르게 하고자하는 자율주행 차량의 목적과는 궤를 달리하기 때문입니다. 물론 혹자는 자동차에서도 카메라 플래시와 같이 상향등, 하향등이 존재하므로 문제되지 않을 수 있다고 하지만, 자동차의 헤드라이트는 전방만을 비추며 빛을 방출하는 영역이 한정적이므로 그만큼 조도가 특정 영역에 집중될 수 밖에 없습니다. 또한 특정 지역에서는 도로 교통법 상 지양되며 금지되기도 합니다.
그러므로 저조도 환경을 위해 적외선 영상을 활용하는 연구는 충분히 납득될 수 있습니다. 절대 0도 이상의 모든 물체는 적외선을 방출하며 인체에 유해하지 않으므로 적외선 에너지원인 열에서 발생되는 파장을 감지하여 이를 전기 신호로 변환한 후 영상화한 영상은 VIS 영상에서 저조도 환경에서 강인성을 나타냅니다. 그러면 단순히 저조도 환경에서만 강인할까요?
그렇지 않습니다. 적외선 파장 영역은 저조도 환경 이외 안개, 비, 황사와 같은 제한적인 환경에서도 잘 작동합니다. 조도에 따른 차이는 이제 이해되었는데, 예를 들어 비가 오는 환경에서는 왜 적외선 영역이 가시광선 영역에 비해 강인성을 보일까요? 아마 이에 대해 자세히는 찾아보지 않았을 것 입니다. 흔히들 ‘비가 올 때는 비 때문에 사진이 잘 안보이니까, 안개가 끼였을 때는 사람이 잘 안보이니까’로 생각하지만 이 또한 설명한 파장 영역에서 접근해야합니다. 가시 광선의 파장은 380 – 750 nm 영역임에 비해, 적외선은 0.75 – 1000 um 영역에 해당합니다. nm은 10^-9m, um은 10^-6m임을 생각하면 적외선은 약 1000배 이상의 긴 파장을 갖습니다.
파장이 짧고 긴 것은 곧 빛의 흡수 및 굴절율과 관련이 있습니다. 장파적외선인 LWIR의 파장은 8 – 15 um으로 근적외선인 NIR의 파장 영역인 0.75 – 1.4 um에 비해 약 8-10배 수준으로 길며 대기 조건에 따라 굴절 및 흡수 현상에 덜 영향을 받습니다. 이는 굴절의 기본 원리에 의해 설명되는데 빛이 두 다른 매질, 예를 들면 공기와 물을 통과할 때 빛의 속도는 매질에 따라 변화합니다. 이 때 빛이 매질 사이의 경계를 통과할 때 발생하는 속도 변화는 굴절을 발생시킵니다.
빛의 굴절을 설명하는 스넬의 법칙에 따르면 굴절은 n_1\sin{\theta_1} = n_2\sin{\theta_2} 으로 표현되며 이 때 n_1, n_2 는 각각 첫 번째 매질과 두 번째 매질의 굴절률, \sin{\theta_1}, \sin{\theta_2}는 각각 빛의 입사각과 굴절각을 나타냅니다. 식에 따르면 빛의 파장은 굴절에 영향을 주지 않는 것으로 보입니다. 즉 빛의 파장은 동일한 매질을 통과할 때는 굴절률이 같으므로 빛은 동일한 각도로 굴절됩니다. 하지만 서로 다른 매질 사이에서 굴절이 발생할 때는, 파장이 긴 빛과 짧은 빛은 서로 다른 각도로 굴절됩니다. 일반적으로 파장이 긴 빛은 더 작은 각도로 굴절되지만 파장이 짧은 빛은 더 많은 각도로 굴절됩니다. 안개, 비, 황사와 같은 상황은 모두 대기와 다른 매질이 많이 존재하는 상황이므로 파장이 긴 영역인 LWIR 적외선이 강인성을 보일 수 밖에 없습니다.
바로 이 점이 본 논문을 읽게 된 계기였습니다. “LWIR이 NIR에 비해 다양한 한계 상황에서 강인성을 보일 것으로 예상되는데, 왜 NIR을 활용하였는가?”. 결론부터 말하자면, NIR 카메라의 화각 (FoV)과 보조 NIR 광원인 NIR lamp로 인해 높은 영상 품질을 획득할 수 있기 때문입니다. NIR lamp는 어떤 방식으로 사용되며 그렇다면 LWIR lamp는 존재하지 않는지는, 아래에서 다시 설명하겠습니다.
Introduction
다시 논문으로 돌아와 현재 PD에서 사용되는 데이터 셋은 Caltech, KAIST, CityPerson, EuroCity Persons (ECP), NightOwls 가 대표적입니다. 해당 데이터 셋들은 낮/밤, 카메라 (VIS, Infrared), 촬영 방식, 날씨 환경, 계절 등을 고려하여 설계되며 Annotation 시에는 Difficult, Occlusion, isCrowd 등을 주로 고려합니다. 아래는 대표적으로 KAIST, ECP, NightOwls와 NIRPed의 데이터 특성 및 Environment, Annotation의 특성을 담은 표입니다. 표를 살펴보면 NIRPed는 다른 세 데이터 셋과는 다르게 유일하게 Distance와 Height에 대해 Annotation되어 있습니다. 이외에도 환경 측면에서는 계절이나 날씨 등을 고려하지만 사실은 눈, 안개와 같은 제한적인 상황보다는 비오는 날만을 대상으로 하고 있습니다.
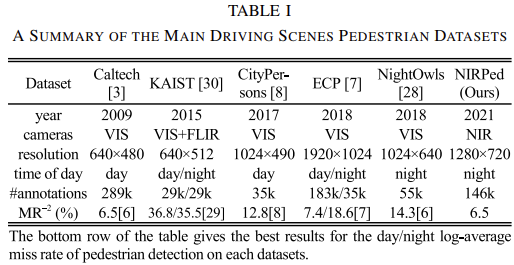
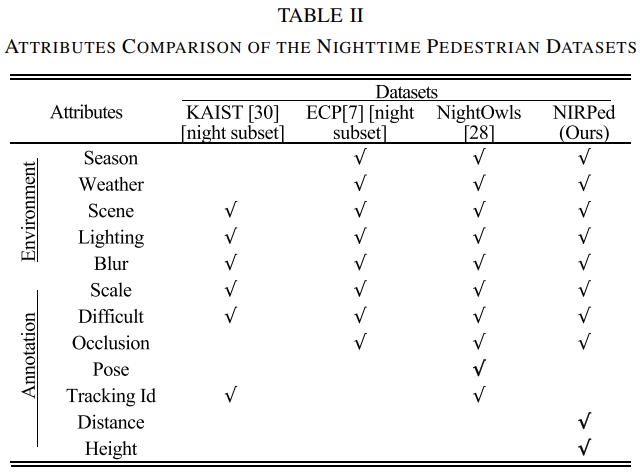
TABLE 1의 MR은 해당 데이터 셋을 사용한 논문 중 SoTA 성능을 보여주나 KAIST MR은 타 데이터 셋과의 성능과는 차이가 많이 납니다. KAIST 데이터 셋의 특성 상 멀티스펙트럴의 특성을 활용한 방법이 많아서 그런 것 같습니다. 다만 제가 봤던 몇 논문들에도 가끔 단일 모달리티에서의 성능을 비교 리포팅하는 논문들이 있었는데 다소 아쉽네요. Caltech부터 NIRPed까지 시간이 지남에 따른 카메라 스펙의 향상과 함께 resolution도 최대 1920×1024까지 높아진 모습을 볼 수 있습니다. 현 시점에서 KAIST외에도 CEuroCityPerson (ECP), NightOwls 등의 데이터 셋이 VIS 카메라를 활용한 대표적인 보행자 데이터 셋으로 사용됩니다.
저자는 이에 대해 PD의 성능 향상은 딥러닝의 발달과 함께 이루어지나 딥러닝의 특성에 따라 Large-scale의, 그리고 신뢰도 있는 데이터 셋이 필수라고 말합니다. 사견으로 이는 최근 리뷰한 논문인 UFPMP-det 에서도 언급되는 클래스 내 혼동 (intra-class confusion)이 연관성이 짙다고 생각됩니다. 본 논문에서는 이를 후에 나오는 Height 개념과 연관지어 말하는데, 다시 말하자면 사람도 어른과 아이와 같은 키 차이로 인해 클래스 내 다양성이 크다고 언급합니다. 이는 단순 Height만이 아니라 동물의 특성에 연관지어 생각하면 더욱 일리있는데, 자동차, 건물과 같은 물체는 전반적으로 형체가 비슷하며 크게 변하지 않습니다. 자동차의 디자인이 변해도 자동차가 달리는 포즈 등이 급격히 변하지는 않습니다. 하지만 동물은 몸을 움직임과 동시에 형체가 많이 변합니다. 사람도 좋은 예지만 유리병 속 고양이는 모델이 고양이라고 판단할 수 있을지도 모르게끔 말이죠. 그만큼 학습 데이터 풀에서 보지 못한 형체 등이 많이 보일 수 있다는 점에서 신뢰성 있는 데이터 셋의 방대한 양은 PD에서 더욱 필수적입니다.
또한 주목할 점으로 위 6가지 데이터 셋 중 낮과 밤 환경을 고려한 데이터 셋은 KAIST와 ECP뿐인데 VIS 카메라를 사용한 다른 데이터 셋에서는 저조도 환경에서의 단점을 고려하였는지 또는 데이터 불균형 (시나리오 상 촬영된 환경이 아닌 이상, 보행자 수는 낮에 비해 밤에 현저히 적습니다)을 고려하였는지는 모르겠습니다만, 아쉬운 것 같습니다. 결국 위의 두 표를 통해 저자는 VIS나 혹은 간간히 LWIR을 사용한 데이터 셋이 아닌 NIR을 활용한 데이터 셋은 처음임을 말하고자 합니다. 이에 대해 왜 기존 데이터 셋들이 밤과 같은 저조도 환경에서 데이터 셋을 촬영하지 못했는지에 대해 언급하는데, 밤에 학습에 유의미한 데이터 셋을 확보하려면 VIS의 파장 영역의 특성을 활용해 Supplement, 즉 보조 광원 장치가 필요하다고 말합니다. 하지만 이러한 보조 광원 장치는 도로 위 운전자 및 보행자에 방해가 될 수 있으므로 도로 교통법 상 제한적이라고 합니다. 사실 보조 광원 장치를 이용하여 데이터 셋을 촬영했다해도 본 데이터 셋이 실용적이라고 말할 수 있을지는 회의적입니다.
OD와 PD의 최신 방법들은 많이들 알고 있을테며 앞으로 많이 리뷰할 예정이니 보다 생소한 태스크인 DD를 살펴보겠습니다. DD는 Depth Estimation과 혼동이 올 수 있으나 엄연히는 다릅니다. 촬영 시점과 대상과의 상대적 거리를 계산하는 것과 3차원 공간 속 대상의 깊이 정보를 추정하는 것은 다릅니다. 하지만 우리는 2.5D detection은 들어봤을텐데, 2.5D detection은 DD와 Depth Estimation의 중간 개념입니다. .5D는 대상과의 거리 및 이를 기반으로 깊이 정보를 추정하는 것을 목적으로 합니다.
DD는 PPS에 중요한 역할을 합니다. 또한 자율주행의 관점에서는 detection 뿐만 아니라 대상과의 거리를 추정하는 것은 굉장히 중요합니다. 그렇다면 대상과의 거리는 어떻게 측정할 수 있을까요? 다시 센서 이야기로 넘어와야겠네요. 우리는 Point cloud라는 개념에 대해 익히 알고 있습니다. Point cloud는 물체에 광학 펄스를 비춰 돌아오는 시간 (ToF, Time of Flight)을 토대로 3D 공간 상의 점을 기록하는 방식을 사용합니다. 이 때 말하는 광학 펄스란 보통 LiDAR(Ligth Detection And Ranging)을 의미하며, LiDAR는 근적외광, 가시광선, 적외선 등을 사용하여 대상물에 빛을 비추고 반사되는 광을 광센서를 통해 검출하여 거리를 측정하는 방식인 리모트 센싱 방식입니다. 보통의 물체는 빛을 반사하는 파장 영역이 존재하므로 일반적으로 정확도는 상당히 높습니다.
하지만, LiDAR는 노면이 젖은 상태, 빛을 흡수하는 물질, 빛 뭉침 및 반사가 심하게 일어나는 환경에서는 오차로 인해 정확도가 하락될 수 있습니다. 저자는 이처럼 LiDAR의 단점으로 날씨 환경에 취약함과 동시에 Small-scale이나 long-distance target에 대해 높은 오차를 보인다고 하나, 저는 날씨 환경에 취약한 부분을 제외하고선 납득되지 않았습니다. 이유는 LiDAR는 실제로 200m 이상까지 물체를 감지할 수 있으며, 오히려 근거리 물체에 대해 취약점을 보입니다. 설정된 최소 감지 거리보다 가까운 근거리 물체에 대해서는 정확도가 떨어질 수 있으며 다중 반사로 인해 광선의 경로를 정확히 탐지하지 못할 수 있기 때문입니다. 이처럼 근거리 물체는 영상 내 Small-scale이 아닌 Large-scale로 보일 것이며, 따라서 Small-scale에 대해 취약하다는 것은 옳지 않은 것처럼 와닿습니다.
사실 저자의 의도는 이것은 아니었겠죠. 저자가 하고자 하는 말을 정확히 표현하자면 최소 감지 거리 이상의 적절한 거리에서의 동일 물체가 있을 시, Large-scale에 비해 Small-scale의 물체는 광반사 표면적이 좁아 반사 신호 강도가 작으며 물체 주변의 환경에서의 다중 반사로 인하여 노이즈가 심하여 취약점을 보일 수 있다고 표현하는 것이 맞겠습니다. 또한 저자는 LiDAR가 low resolution을 가지고 있다고 하나, 이 또한 와닿지 않습니다. LiDAR가 두각을 나타내는 부분은 공간 분해능 (Spatial Resolution)으로, 적외선을 사용할 시 0.1′ 단위까지 나눌 수 있으며 이는 후처리 없이도 물체의 특징을 한 장면으로 묘사할 수 있는 수준입니다. 일반적으로 LiDAR는 RADAR나 camera에 비해 resolution이 훨씬 높은 편에 속합니다.
위의 정보를 토대로 보았을 때 사실 LiDAR는 자율 주행 차량에서 두각을 보일 수 있습니다. 하지만 LiDAR의 정보만으로 물체를 탐지하는 것은 부정확하니 카메라 등과의 Sensor Fusion을 통해 정보를 보완하여 사용하여야 하나, 대중성을 생각했을 때 LiDAR는 너무 비쌉니다. 자율주행 차량이 비싸다면 그 이유는 LiDAR 때문이다. 그것만으로도 충분한 설명이 될 수 있지 않을까 싶을 정도로, 좋은 LiDAR는 몇 천만원을 호가합니다.
전통적인 비전 기반 DD는 LiDAR를 활용한 DD에 비해 성능이 좋지 않지만, 저렴한 비용과 설명성이 높다는 장점이 있습니다. 이 때 말하는 설명성이 높다는 의미는 LiDAR로 수집한 Point cloud는 무작위로 기록되는 특성 등으로 인해 설명성이 떨어지지만 2D 영상에서는 사람이 보아도 어느 물체가 상대적으로 멀리 떨어져 있는지를 추정할 수 있습니다. 그렇기에 비전 기반 DD는 상용성 측면에서 활발히 연구가 이루어졌으며 이는 두 주축을 이루어 발달되어 왔습니다.
대표적으로는 pinhole-imaging-based DD, 즉 영상 내 정보만을 토대로 한 DD입니다. 2D 영상에서 대상과의 상대적 거리를 알 수 있는 방법은 사실 하나 밖에 없습니다. 바로 대상의 정보를 추정할 수 있다는 가정 아래 탐지 대상 Bounding box의 높이와 넓이를 이용하면 됩니다. 보행자를 남성 및 여성으로 구분하지는 않지만 평균 성인 키를 기준으로 미터 당 영상 내 픽셀 높이 및 넓이를 활용하면, 상대적인 거리는 어느정도 추정할 수 있습니다. 하지만 이는 현대 기술을 생각했을 때, 정확도가 많이 떨어집니다.
그보다는 inverse perspective mapping, IPM을 통한 DD를 소개해주고 싶었습니다. perspective mapping, Calibration 및 Homogeneous Coordinate를 공부해본 우리 연구원분들은 용어가 익숙할 것입니다. Calibration은 3D 공간을 2D 영상에 담을 때 생기는 왜곡을 보정하고자 카메라 파라미터를 구하는 일종이라면, IPM은 Inverse, 즉 3D->2D가 아닌 2D->3D입니다. 이 때 2D->3D라함은 실제 3D 공간보다는 Bird Eye View (BEV) 방식의 3D로 변환하는 것을 일컫습니다. 즉 3D 방식의 2D로 이미지로 표현하는 것인데, 이는 사실 아래 그림을 보면 바로 이해가 되실 것 같습니다.

IPM에 대해 조금만 깊게 살펴보겠습니다. PM, Perspectvie Mapping이란 Perspective Projection과 동일한 의미로 3D 장면을 2D image plane으로 투영하는 방식을 말합니다. Perspective Projection 이후 2D 이미지는 일종의 원근감이 있도록 생성되며 이는 당연히 동일한 크기의 물체라도 영상 내 거리에 따라 크고 작음이 다르게 보임을 의미합니다. Inverse는 Perspective Projection 과정을 역으로 진행한다는 의미로, 원근감에 의한 왜곡인 Perspective distortion을 제거하는 작업입니다. 따라서 IPM은 3D 장면에 대해 카메라의 거리에 상관없이 일관성 있게 표현하는 것을 목표로 하며, 이러한 표현 방식이 위 우측 사진의 BEV입니다.
BEV로 표현하는 이유는 BEV로 보았을 때 물체는 원근에 상관없이 동일한 크기로 표현될 수 있다는 점입니다. 이는 BEV가 모든 물체가 지면에 붙어있다는 것을 가정하기 때문에 가능합니다. 2D 이미지를 3D로 변환하기 위해서는 실제 Depth를 통해 물체의 높이 정보를 알 수 있는데, 이 정보를 모르니 모든 물체의 높이를 무시한 채 지면에 붙어있다는 가정의 BEV를 택한 것 입니다. 다음 링크를 통해 BEV로 변환하여 거리 측정을 하는 과정을 살펴보면 보다 이해가 잘 될 수 있을 것 입니다. 사실 IPM은 동차 좌표계 등을 완벽히 이해하여야만 이미지와 world 좌표 간의 관계를 이해할 수 있으나 이는 본 리뷰에서 다루기엔.. 어렵습니다.
결과적으로 pinhole-imaging-based DD는 50m 이내 물체에 대해 9.71%의 MAER을 보였으며 IPM 기반 방법은 이보다는 조금 더 높은 성능을 보입니다. 하지만 두 방법 모두 물체와의 거리가 30m만 넘어가도 MAER이 서서히 올라가더니, 멀리 있는 물체에 대해서는 좋지 못한 성능을 보입니다. 또한 두 방법 모두 일종의 통계학적이고 수학적인 방법이며 몇몇의 샘플 영상에서만 실험되어 강건성이 낮다는 특징을 보입니다.
이외에도 스테레오 카메라를 활용한 스테레오 이미지에서 시차를 활용한 Depth Estimation 등의 연구도 관련되어는 있지만, 대상과의 거리가 멀어질 수록 시차가 작기 때문에 이 또한 한계점이 분명합니다. 그러므로 저자는 2D 영상 내 Detection을 위한 정보 및 대상과의 거리 정보를 Annotation하여 PD 및 DD를 한 번에 수행하는 joint detection 방법을 벤치마킹합니다. Faster-RCNN 기반 방식이나 개인적으로 본 논문이 데이터 셋 논문임에 따라 방법론에 대해 깊게 다룰 필요는 없다는 생각이 들어 joint detection은 빠르게 보고 넘어가겠습니다. 그보다는 NIRPed의 데이터 셋 예시 사진을 보는 것이 훨씬 와닿을 것이라는 생각이 드네요.
그럼 이쯤에서, 저자가 주장하는 contribution을 정리해보겠습니다. 아래의 contribution 중 우리가 주목할 점은 NIR lamp를 활용한 부분이라고 생각됩니다. 사견으로는, 해당 보조 장치 덕분에 LWIR에 비해 우수한 품질의 영상을 획득할 수 있었을 것으로 보입니다. 이는 파장의 영역 및 해당 파장에 대응하는 온도 영역을 생각했을 때, 일반적으로 NIR은 LWIR에 비해 주관적 영상 품질이 떨어질 것이라고 예상되나 LWIR은 대상의 열을 토대로 영상을 만들기 때문에 NIR lamp와 같은 보조 장치가 없으므로, 저자는 NIR을 활용하여 영상 품질을 올린 것으로 보입니다.
- NIR + LiDAR를 통해 밤의 주행 환경에서의 데이터 셋 영상을 획득하며, PD 및 DD를 위한 Annotation을 수행
- 현재는 NIR을 활용하며 동시에 보행자와의 상대적 거리를 Annotation한 데이터 셋이 존재하지 않았다.
- NIR은 육안으로 탐지하기 힘든 보행자를 보여주며, NIR 이미지 획득 시 사용되는 NIR lamp 또한 육안으로 보이지 않기 때문에 도로 교통법에 저촉되지 않는다. 또한 밤의 도로 주행 시 주변의 빛이 뭉쳐보이는 현상, 또는 가시광선 영역으로 식별되지 않는 영역에 대해서 우수한 품질의 영상을 획득할 수 있다.
- 데이터 셋 획득시 TABLE 2에서 보이는 바와 같이 환경적 요소를 많이 고려하였으며 이외에도 데이터 불균형으로 생길 수 있는 성능 저하를 미연에 방지하고자 데이터 샘플링을 진행하였다.
- 마지막으로, Faster-RCNN 기반 PD 및 DD를 Monocular 영상에서 한 번에 수행하는 joint detection을 통해 벤치마크를 세웠다.
A. Data Collection Device

다들 KAIST 멀티스펙트럴 데이터 셋 논문을 한번쯤은 보셨을텐데, 본 논문에서 영상 수집을 위해 활용한 장비를 살펴보겠습니다. 주목할 점은 2, 3, 5번이되겠네요. 1번 Magnet, 4번 Ring, 6-7 Jigs는 각각 카메라를 고정하고, 카메라와 LiDAR의 중심이 일치하도록 고정하고, 카메라의 광학적 중심을 일치시키는 장치입니다. 2번의 NIR lamp가 본 장비의 핵심으로 보입니다. NIR lamp는 NIR 파장 영역의 광원을 방출하는데, 이는 가시광선 영역이 아니므로 육안으로 식별되지 않습니다. 이전에 몇번이나 도로 교통법을 운운하였는데 데이터 셋 취득을 위하여 밤 환경에 해당 크기 수준의 lamp에서 빛이 나온다면 이는 불법이지만, NIR lamp는 보이지 않습니다.
아래 예시 그림에서 NIR lamp의 유무에 따른 영상을 보여주는데, 이 점이 끌렸습니다. LWIR에서는 객체가 방출 및 반사하는 열을 탐지하지만 이는 곧 보행자의 형상이 뚜렷하지 않을 때도 있었는데, NIR lamp에서 방출하는 supplemental light는 이를 극복할 수 있는 장점을 보입니다. 실제로 NIR lamp가 없다면 50m 이상의 물체는 식별되지 않습니다.

아래는 NIR 카메라 및 LiDAR의 사양입니다. Grabber에 관심이 있다면 혹은 영상 처리에 관심이 있으셨다면 해당 내용만으로도 얻을 수 있는 점이 몇몇 있습니다. 먼저, NIR 카메라의 사양입니다.
- NIR camera: CMOS sensor, 830 – 870 nm spectral, 1280 x 720 pixel resolution, 33ms fixed exposure time, 30 x 19′ (HFoV x VFoV), 12mm folcal length lens.
- NIR lamp: 848 – 852 nm emission spectral, 160 m illumination distnace, 30′ illumination angle (which well matches the camera’s FoV)
- Velodyne small 3D LiDAR VLP-16: 903 nm emitting wavelength, 16 labser beam, 360 x 30 (HFoV x VFoV), 16 vertically arragned laser beam (with 2′ vertical resolution), 5-20 Hz operation frequency correspoding to 0.4′-0.1′ horizontal resolution, 300,00 data points / seconds. 100m range and 2cm distance precision.
우선 NIR 카메라의 사양을 확인하면, NIR 파장 영역의 CMOS 센서를 활용하며 해상도 또한 괜찮습니다. 또한 Exposure time (Shttuer speed)를 33ms로 고정하는데, 이는 NTSC 표준인 29.97Hz (실제 흑백 영상은 30Hz입니다)를 충족합니다. 본 연구실에서 작성한 R2T2 논문을 살펴보면 Initalize, Processing 등을 위하여 Shutter speed를 15 ms로 고정하는데 이와는 상반됩니다. 또한 NIR camera는 NUC mode 또한 존재하지 않겠네요. FoV가 생각보다 좁은 모습을 보이는데, FoV와 Focal length를 고려했을 때 이는 탐지 가능 거리를 늘리고자함이지 않을까 싶습니다.
NIR lamp는 당연히도 NIR 파장 영역을 방출하는데, 주목할 점으로는 30’의 각도로 160m까지 넓게 퍼져나갑니다. 이 때 각도가 NIR 카메라의 HFoV와 동일하므로 영상 내 모든 지점은 곧 NIR lamp를 흡수 및 반사했음을 내포합니다.
마지막으로 Point cloud를 획득하여 거리를 측정하기 위한 3D LiDAR 제품을 살펴보면, HFoV가 360′, 즉 전방위를 측정할 수 있다는 점이 역시 LiDAR의 장점을 여실히 보이는 것 같습니다. 또한 해당 제품은 NIR 영역 내인 900 nm 대 파장을 방출하여 물체를 검출하며, 이외에도 operation frequency를 5-20 Hz로 설정하여 위에서 언급한 0.4′-0.1′ 수준으로 공간 분해능 단위를 나눌 수 있으며 초당 300,00 포인트를 획득할 수 있음은 실로 대단합니다. 물론, 100m까지 그리고 2cm 오차 범위 내로 거리를 측정할 수 있음은 LiDAR의 주 장점을 여실히 보여줍니다.
B. Data Collection and Target Distance Obtaining
본 장은 이미 언급한 데이터 셋 취득 시 고려한 상황 및 Annotation 시 고려한 상황을 담고 있으므로, 빠르게 보고 넘어가겠습니다. 영상 취득 시 각 요소는 PD 성능에도 지대한 영향을 줍니다. 낮과 밤의 조도 차이가 대표적일 수 있겠지만 이외에도 계절에 따라 변하는 context 정보, 날씨에 따라 변하는 영상 화질, 외에도 인구 밀집 수준 등이 영향을 미칠 수 있습니다. 최근의 데이터 셋 논문은 인공지능 모델의 성능에 영향을 줄 수 있는 요소들을 고려함과 동시에 해당 요소들을 담은 데이터 셋의 불균형 문제를 고려하는 추세인 것 같습니다.
본 데이터 셋은 2018년부터 2021년까지 3년 간에 걸쳐 다양한 환경을 고려했습니다. 특히 앞서 말한 데이터의 균형을 맞추고자 하는 노력에 심혈을 기울였다는 생각이 드는데 3년 간 촬영했음에도 142K (142,000 장) 수준의 데이터와 423k 수준의 point cloud 파일을 수집한 것으로 보아, 자주 볼 수 없는 환경에서 촬영한 데이터를 기준으로 샘플링 한 것으로도 보입니다. 동시에 NIR lamp를 활용한다고 하였는데 해당 lamp에서 방출되는 광원이 표지판, 건물 등에 반사되어 원치 않은 결과를 얻거나 혹은 Exposure time을 고정해도 장시간 노출되었을 때 생길 수 있는 영상 차이, 흐림 (Blur) 등의 문제가 있었으며 이들 중 고려하기 가장 어려웠던 점은 실제 주행 환경이다보니 일정한 속도로 달릴 수 없는 한계로 인한 움직임으로 인한 영상 내 흐림이 있습니다. 아래 이미지를 통해 확인하시면 좋습니다.

또한 LiDAR는 초당 300,000 개의 Point cloud 데이터를 획득한다고 하였는데, LiDAR 뿐만 아니라 camera도 Exposure time이 33ms인 것을 고려하면 약 30FPS, 초당 30 장의 영상을 획득합니다. 그렇다면 데이터의 양이 너무 방대하며 실제적으로는 비슷한 Viewpoint만이 반복되어 유의미한 영상이라기엔 아쉬움이 있으니 이를 극복하고자 데이터의 양 자체를 줄이는 것이 필요한데, 우선적으로 저자는 LiDAR의 operation frequency를 10Hz 미만으로 설정하였습니다. 본 LiDAR의 성능이 최대 20 Hz까지 가능했던 것과 비교하면 방대한 양의 Point Cloud를 획득하는 것에 부담을 느낌과 동시에 한 장면에 대해 카메라로 획득한 2D 영상과 LiDAR로 획득한 3D Point cloud의 시점이 일치하는 것이 이상적이므로 이를 위하여 조정한 것으로 보입니다.
실제 다음 절에서는 2D 영상과 3D Point cloud를 퓨전하는 방법에 대해 언급하는데, 이는 방법 자체는 굉장히 간단하지만 기술적으로 볼 때는 좋은 것 같아 미리 소개하고자 합니다. 방법은 2D 영상과 3D Point cloud를 획득한 시점을 각각 이미지 확장자 파일과 Pickle 파일로 저장하여 둘을 매핑하는 방법으로, 말 그대로 2D 영상 내 객체에 3D 정보를 통해 거리를 Annotation한다고 보시면 됩니다. 말처럼 이는 간단한 방법이나 사실 쉽지 않습니다. 우선 이는 카메라 및 LiDAR의 사양을 확인했을 때 FoV가 다르기 때문에 매핑이 쉽지 않습니다. 그러므로 3D 정보를 동일 시점의 2D 영상 앞뒤 몇 프레임에 매핑했을 때 최적으로 보이는 영상을 선택해야하는 작업이 필요합니다. 또한 2D 영상과 3D Point cloud를 동시에 저장한다고는 하나, 획득하는 양 자체가 많이 차이나기 때문에 이를 위해 3D Point cloud를 UDP 기반 Socket protocol을 통해 실시간으로 전송하는 것이 필요합니다. 이는 카메라 Grabber 시 데이터 전송 속도 및 효율을 생각하여 GigE Interface를 활용했으며 속도 및 안정성을 위해 C++ 기반으로 작성한 것과 비슷한 이유라고 생각하면 이해에 도움이 되겠습니다.
다음으로는 Annotation 입니다. MATLAB GUI Tool을 사용하였으며 환경은 계절 (cold or hot), 날씨 (clear or rainy), city (changsha or shaoyang), 도시 (urban, university, campus of suburban)으로 구분지어져 있습니다. 개인적으로 city는 왜 분류했는지 의문점이 드네요. 도시로 구분지을 수 있었을텐데, 불필요하단 생각이 듭니다. 클래스는 Pedestrian, cyclist, motocyclist로 구분하였으며 눈여겨 볼 점은 우리가 익히 아닌 bounding box (BB) 이외에도 occlusion을 고려하여 실제 영상에서 보이는 부분만을 박스 친 visible BB를 Annotation 했습니다. 해당 visible BB는 추후 다시 사용되는 개념으로 지금은 BB와 비율을 계산하여 occlusion rate를 계산하여 difficult를 정한다고 생각하면 좋습니다. 이외 KAIST 데이터 셋의 isCrowd와 같은 인구가 밀집된 경우, people로 Annotation한 점과 사람이 자동차 내에 있는 경우 혹은 근처 프레임을 통해서만 식별되는 경우는 모두 ignore로 처리하였습니다. 본 Annotation 지침은 특별하진 않지만 visible BB와 날씨를 고려한 점은 볼만한 것 같습니다. 하지만 아쉬운 점은 여전히 rainy, 비오는 상황만이 아닌 더욱 제한적인 환경은 고려하지 않았다는 점이네요.
그렇다면 14만장의 영상 중 실제 사람의 비율과 이외 타 데이터 셋과의 장점은 어떤 것이 있을까요? 우선 NIRPed는 총 236,000 수의 사람과 관련된 (pedestrian, cyclist 등) 객체 중 pedestrian, cyclist, motorcyclist는 각각 140,000, 7,000, 33,000만 명이 분포해있습니다. 이는 KAIST나 ECP night 데이터 셋에 비해 4-5배 이상의 객체를 포함하며 NightOwls는 이미지 수는 NIRPed에 비해 많지만 그 중 88% 이상이 배경 (Background)에 해당하기 때문에 본 데이터 셋은 장점이 부각됩니다. 또한 NIR camera와 LiDAR의 FoV로 인해 더 먼 지역을 넓게 담을 수 있어 PD와 DD의 성능을 향상할 수 있다는 장점이 있습니다.
이외에도 전 데이터 셋을 train, validation, test를 4:3:3의 비율로 나눌 때도 데이터 셋 내 보행자의 거리를 균형적으로 분배하고자 노력했습니다. 이는 아래 표를 통해 드러나며, Near (20m 미만), Medium (20m – 60m), Far (60 – 80m)의 세 분류로 나누었으며 주목할 점으로는 80m 수준의 먼 보행자도 확인할 수 있다는 점 입니다. 이 또한 본 LiDAR가 최대 200m 이상까지 검증할 수 있어 가능했습니다.


우리는 KAIST 데이터 셋에서 Reasonable과 UnReasonable을 분류하였는데 이 때 실제 자율 주행 차량 운용 측면에서 UnReasonable은 실제 측정하기에는 불충분한 정보 등으로 인해 고려하지 않는 보행자에 해당합니다. KAIST는 Reasonable 보행자를 55px (23m) 이상을 구분합니다. 딥러닝 모델 측면에서 55px 미만의 보행자를 탐지하지 않는 것은 아니지만, 공용 평가 측도는 55px 이상의 보행자만을 따져 리포트합니다. ECP와 NightOwls는 각각 40px (63m), occlustion 40% 미만, 50px (50m), dfficult 및 truncated 제외임에 비해 NIRPed는 80m 미만, occlusion 35% 미만, difficult로 포함되지 않은 보행자를 Reasonable로 분류합니다. 이는 곧 NIR camera가 넓은 지역을 볼 수 있으며, LiDAR가 80m 이상 거리의 보행자까지 감지할 수 있기에 가능한 일입니다. 실제 80m 보행자가 몇 px로 Annotation된지는 말하지 않지만 아마 80m 수준이면 실제 COCO small object에 속하는 32px 보다 훨씬 작은 수준에 포함된다고 보입니다. (본 논문에서는 60m가 30 px이라고 리포트되어 있습니다.)
위의 TABLE 2를 다시 보면 distance 이외에도 height가 Annotation되어 있습니다. 제가 본 논문을 읽다 이해에 어려운 부분이였는데, 저자는 미래 자율 주행 운용을 위한 컴퓨터가 부착된 차량 (Ego-vehicle)이 보행자와의 충돌을 피하기 위해서는 distance 및 height가 중요하다고 말합니다. 이에 height라는 Annotation을 추가하였다고는 하나 이것이 bounding box의 height와 무엇이 다른지에 대해선 나와있지 않습니다. 아래 Fig 5와 Fig 6은 카메라 거리와 height의 차이, 그리고 보행자의 height를 short, normal, tall로 나누어 비율을 관찰하고 있습니다. 또한 저자는 보행자의 픽셀 높이와 거리를 엮어 생각했는데, 예를 들어 near, medium, far은 곧 픽셀 높이에서 200, 69, 50에 해당합니다.
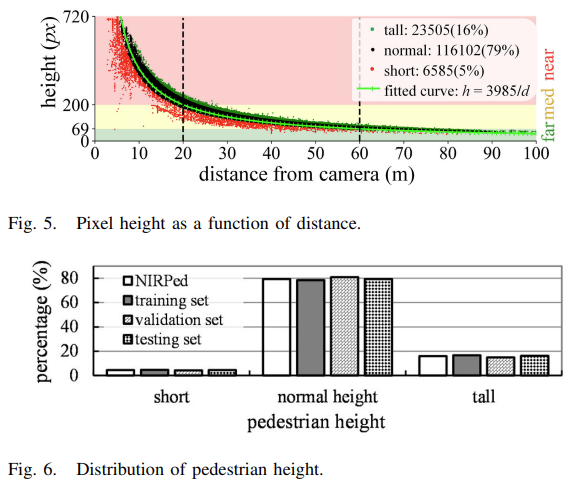
결과적으로 본 논문에서 말하는 height는 small, medium, large를 균형 있게 구분하기 위함인지 다른 이유인지는 나와있지 않지만, 짐작건데 height는 결국 픽셀 높이가 다를 때, 예를 들어 먼 거리 혹은 가까운 거리, 또는 어른과 어린이가 이미지 내 보여질 수 있는 표현력에 차이가 있을 수 있기 때문에 height를 따로 Annotation하여 균형 있게끔 분류하고자 했음을 의미한다고 보여집니다.
이제 데이터 셋에 관한 이야기는 끝이 났습니다. 사실 데이터 셋 논문은 예시 이미지 몇 장만으로도 이해될 수 있는 부분이 많지만 NIR을 사용한 이유에 대한 고찰 등을 짐작하기 위해서는 사실 추가적인 공부가 많이 필요했습니다. 이제는 joint detection, 즉 2D 이미지 내 detection 정보와 3D distance 정보를 한 번에 학습하는 방법에 대해 알아보겠습니다. 이미 언급한 듯 본 리뷰는 사실 데이터 셋과 센서를 중점적으로 다루고자 했기 때문에 본 내용은 짧게만 짚고 넘어가겠습니다.
A. Joint Detection Model Architecture
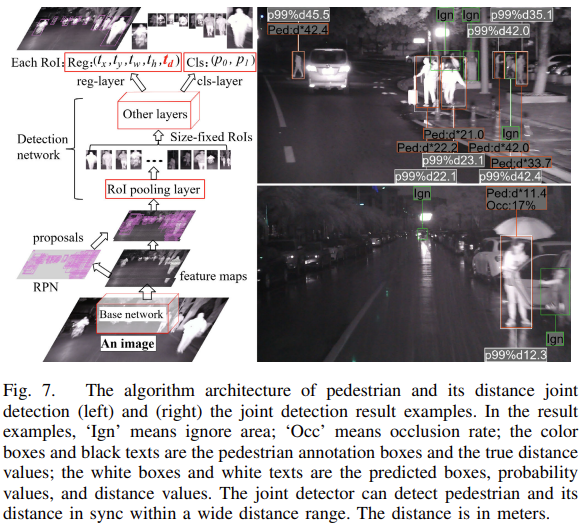
저자는 Faseter-RCNN을 사용합니다. 본 리뷰에서는 Faster-RCNN에 대해서는 집중적으로 다루지 않을 것이며 Joiunt detection을 수행한 부분만 살펴보겠습니다. 이는 아래 Fig 7을 보면 알 수 있는데 기본적으로 구조는 Faster-RCNN을 통한 PD를 수행하다, Detection Network에서 distance 정보를 결합하여 Regression 시 BBox offset 외에 distance를 추가적으로 삽입하는 것이 끝입니다. 벤치마크 논문이 보통에 그러하듯 큰 실험적 성능을 보이기보다는 베이스적인 방법론을 보이는 것이므로 이에 대해 큰 리뷰를 하고자는 하지 않았습니다.
위에서 visible BB를 활용할 것이라고 말씀드렸는데, 이는 학습 몇 평가 시 IoU를 계산하는 부분에 있어 GT-Predicted BBox외 GT visible BB – Predicted BBox를 모두 계산하여 둘 다 임계점을 넘었을 때만 두는 방식을 사용합니다. 이는 곧 2-Stage detection에서의 단점 중 하나인 너무 많이 생성되는 Bounding box의 NMS를 효과적으로 수행할 수 있음을 의미하기도 합니다. (본 내용은 사실 둘 모두 넘는 경우 이외의 경우에 대해서도 Positive / Negative sample로 구분하여 경우에 따라 Positive / Negative를 판단할 때도 있지만, 지금 그 부분은 큰 효용성이 없다고 보여져 해당 내용은 배제했습니다.)
distance term이 추가됨에 따라 Loss또한 달라집니다. Loss의 Classification Loss는 동일하나 Regression Loss에서 distance term이 추가됩니다. 이는 수식으로만 빠르게 넘어가겠습니다. 아래 수식은 일반적인 detection의 Loss (Classification + Regression)의 Regression Term을 추가한 것에 불과합니다.
L = \frac{1}{N_{cls}} \sum_i L_{cls} (p^i, u^i) + \frac{1}{N_{reg}} \sum_i c_iL_{reg}(t^i, v^i)L_{cls}(p^i, u^i) = - \sum_{k=0.1} (- \log^{u^i_k}_{p^i_k} + \log^{1 - u^i_k}_{1 - p^i_k})L_{reg}(t^i, v^i) = \sum_{j \in x, y, w, h, d} R(t^i_j - v^i_j)아래의 distance regression offset에 대한 term만 살펴보겠습니다. 수식에서 d_m 은 전체 보행자의 평균 높이입니다. d^* , d 는 각각 GT와 predict distance를 의미합니다. log term만봐도 수식이 쉽게 이해되실 수 있을 것이라고 생각듭니다. 이 때 GT의 height가 크다면 Loss 함수 미분 시 값이 커지므로 backpropagation 시 영향을 많이 줄 것입니다. 그러므로 본 Loss의 목적은 근거리 (Height가 큰) 보행자에 대한 DD 성능을 높임에 있습니다.
v^i_d = - \log (d^* / d_m) \\ t^i_d = -\log(d / d_m)
Experiments
마지막으로 실험입니다. 사실 실험은 Distance에 대한 MR, NIRPed에서 본 모델을 적용했을 때의 MR, distance와 height가 MAER에 미치는 영향을 살펴보겠습니다. 이 때 MAER은 DD 평가 측도이며 아래 식으로 계산됩니다. GT와 Predict distance 사이 차를 통해 계산됩니다.
MAER = \frac{1}{N} \sum \left [|d - d^*| / d^*) \cdot 100\% \right]그럼, 본 논문의 실험 표를 보며 리뷰를 마무리하겠습니다.
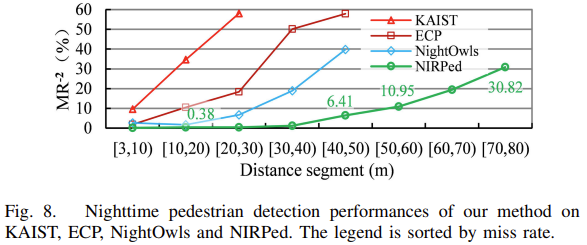
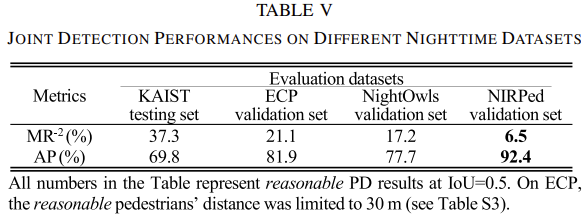

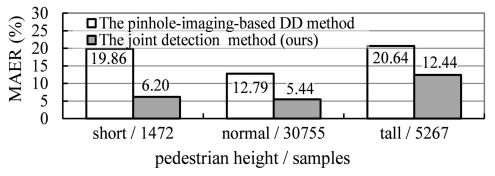
표를 한번에 들고 왔습니다. 그 이유는 몇 번 말했지만 데이터 셋 취득 과정이 중요한 논문으로 그 방법론은 중요치 않다고 생각되었기 때문입니다. 실험을 보면 순서대로distance가 늘어남에 따라 MR이 증가하는 것은 당연하지만, 본 논문에서는 타 데이터 셋에 비해 훨씬 먼 거리를 탐지할 수 있었으며 6.5% 수준의 낮은 MR, 그리고 전통적인 DD 방법 중 하나인 pinhole-imaging-based DD에 비해 좋은 성능, 그리고 pedestrian height를 봤을 때 모든 측도에서 성능 개선이 이루어짐을 보입니다.
사실 본 논문은 중간고사 이후 편한 마음으로 보고자 한 논문이나, Grabber에 관심이 깊은 저는 NIR을 사용한 저자의 고찰에 대해 궁금했지만 사적으로 추론하며 읽을 수 밖에 없어 아쉬웠습니다. 그럼 리뷰 마치겠습니다.
좋은 리뷰 감사합니다
처음 관련된 내용부터 자세히 설명해주셔서 재미있게 읽었네요:)
처음에 LWIR대신 NIR을 활용한 이유에 대해 NIR에서 강인성을 증명하면 다른 파장의 센서에서는 더 강인하게 작동하기 때문일 것이라고 생각했는데 조금 다른 이유였네요..ㅎ 또 NIR lamp를 사용했을 때 더 특징들이 두드러지는 것이 추후 이상상황에서 적용해볼만 하겠다는 생각이 들었습니다
질문 간단히 드리면 처음에 Depth Detection 설명에서 depth estimation과 다르다고 하셨는데, 촬영 시점과 대상과의 상대적 거리를 계산하는 것이 3차원 공간 속 depth를 추정하는 것과 어떻게 다른 건가요..? 설명을 보고도 어떤 차이가 있는 것인지 명확히 이해가 되지 않아 질문드립니다.
그리고 2d와 3d를 fusion하는 방법으로 획득한 시점 기준 주변 프레임 중 최적으로 mapping되는 영상을 선택한다고 하는데, 3d정보를 2d와 mappoing할 때 이러한 fusion방식에서 misalignment문제는 따로 해결하지 않고 단순히 여러 프레임 중 최적의 mapping된 프레임을 사용한 것인가요?
말씀하신대로 NIR을 사용한 이유에 대한 설명이 부족한 점이 아쉽네요.. 자세히 작성해주셔서 재미있게 읽었습니다. 감사합니다!
네 안녕하세요. Grabber 중, Sensor에 대한 설명을 곁들여 흥미가 떨어질 수 있었으나 끝까지 읽어주셔 감사합니다.
실제로 NIR lamp가 Foggy, Snow와 같은 이상 상황에서 강인할지는 두고봐야할 것 같습니다. 말씀드렸듯이 파장의 측면에서는 LWIR이 강인할 것으로 예상되나, NIR lamp의 도움을 곁들인다면.. 모르겠네요ㅎㅎ
우선 질문에 대해 Depth Detection이 아닌 Distance Detection과 Depth Estimation이긴 합니다만, 둘 차이를 말씀드리자면 Distance Detection은 2D 영상에서 대상과의 거리를 탐지하는 방법입니다. 이 때의 기준은 하나의 객체이며, 객체의 Pose등과 상관없이 Sensor (Camera, LiDAR, …)와 객체의 거리를 탐지합니다. 영상에서 거리 탐지를 위해 거리라는 정보를 학습하도록 합니다. 이와 반대로 Depth Estimation은 영상 내 픽셀 별로 카메라와의 상대적인 깊이를 추정합니다. 이 떄 픽셀 별이라는 것이 3차원 공간 속이라고 생각할 수 있는데, 이는 대상의 Pose 등에 의해 달라질 수 있기 때문입니다. 또한 Depth estimation은 보통 Stereo 영상에서 수행됩니다. 물론 Mono 영상에서도 수행되긴 하지만 성능이 낮으며, Distance Detection은 Mono, Stereo와 상관 없이 실제 거리 정보를 학습합니다.
두 번째 질문으로는 2D와 3D의 영상을 Fusion하는 방법에 대해 말씀해주셨습니다. 제 고찰에서 Misalignment 문제는 크게 신경쓰지 않아도 됩니다. 이 또한 위의 답변에 엮어 말할 수 있겠는데, 객체 Bounding box와의 거리를 측정하면 되며 논문에서 2D + 3D Fusion이라고 표현은 했지만 사실 현 태스크의 목적은 2D를 기반으로 하므로 2D 영상에 촬영 시점이 동일한 (또는 편차로 인하여 앞뒤 몇 프레임의 차이가 있을 수 있으므로) 3D 데이터를 입혀 비슷해보이는 영상에서 객체의 거리 정보만을 추출하면 되기 때문입니다.
말씀해주신 것과 같이 NIR의 장점에 대해 더 고찰이 있었으면 좋겠으나, 아직 LWIR도 상용화되진 않았기에 KAIST Multispectral 논문과 같이 새로운 방향성을 제시한 정도로 알아두면 좋을 것 같습니다. 물론 논문을 읽다보니 든 생각으로, 이상 상황을 고려한, 날씨 상황을 고려한, 낮 / 밤을 고려한 등의 다양한 상황에서 LWIR 데이터 셋 논문을 다시 작성해도 그 자체만으로도 충분히 contribution으로 삼을 수 있을 것으로 보입니다. 또한, 본 논문은 생각보다 데이터 셋의 수준이 괜찮음에도 불구하고 스스로의 고찰을 통한 해석이 많은 만큼… 글쓰는 방법이 아쉬웠던 것 같습니다.
논문 읽어주셔서 감사합니다.
안녕하세요 좋은리뷰 감사합니다
가시광선이 아닌 적외선 영상을 사용해야하는 이유에 대해 자세하게 설명해주셔서 감사합니다. 적외선 영상을 사용하지 않고자하는 분파의 주장도 궁금하네요.
본 논문의 loss가 height 큰 보행자에 대한 가중치가 비교적 크게 설계되었다고 하셨는데, 확실하지는 않으나 키가 큰 보행자라고 이해했습니다. 이렇게 설계하거나 데이터셋을 해당 기준(키?)으로 나눈 설계의 이유가 있을까요?
감사합니다
네 안녕하세요. 리뷰 읽어주셔서 감사합니다.
그쵸.. 제가 적외선 영역을 사용하지 않는 분파라면, 다음과 같은 한계점을 시사할 것 같습니다. 적외선 영상의 상용성에 대한 의문점: 밤에 강인하지만 오히려 낮에는 VIS 카메라로 촬영한 영상보다 영상 품질이 떨어진다면, 돈 들여 설치할빠에야 돈 더 주고 조금 더 비싼 LiDAR 써버리면 되지 않나?, 영상에 대한 설명성: 가시광선 영역의 영상으로 최근 중국 CCTV 에서는 사람의 인상착의 (상의 색, 바지 색 등등)까지 탐지한다고 하는데, 적외선 영상은 사람의 형체가 보일 뿐에 그치지 않나? 자율주행차량이라고 발전의 속도를 생각해봤을 때 그 한계점을 굳이 들고 가야하나? 영상의 활용성에 대한 의문점: 두 영상을 입력으로 받는다면 추론 속도도 느려질 것이고 그렇다고 한 영상만 쓰기에는 조도가 애매하거나 긴급히 변하는 상황이라면? 자율 주행 차량이 순발력있게 처리할 수 있는 수준일까?
등등의 다양한 의견이 분분할 수 있을 것 같네요.
질문에 대해 키가 큰 보행자, 이 문장이 논문에 그대로 쓰여진대로입니다. 다만 저는 이 부분에 대해 공감하지 못해 height가 큰 보행자라고만 설명해두었는데 키가 크다는 것보다는 아마 저자가 의도하고자한 바는, LiDAR가 신기하게도 설정된 최소 감지 거리 근방의 근거리 물체에 대해 정확도가 낮은 측면을 고려하여 해당 객체에 대한 Distance Detection 성능을 높이면 -> 전체 성능을 높일 수 있을 것이다. (마치 Object detection에서 Large 사이즈의 객체는 100%에 가까운 Precision을 보여주니, Small-Medium에 집중하여 리포트 성능을 높이고자 하는 실험)는 전제하에 설계한 것으로 보입니다. 이를 위해 저자는 Height라는 Annotation을 추가하였지만, 제 생각에는.. Bounding box의 Height와 큰 차이점을 모르겠습니다. 해당 Height가 Bounding box에서 추출한 정보보다는 LiDAR에서 추출한 정보 (조금이라도 더 정확한 정보를 위하여)인 것 같습니다만, 저자가 한-두 문단 공들여 써놓은 것 치고는 큰 공감을 하지는 않았습니다. Trivial solution으로 느껴졌습니다ㅎㅎ
읽어주셔서 감사합니다.