안녕하세요 ! 네 번째 x-review입니다. 바로 시작하겠습니다. ?

Introduction
nlp에서 사용되는 transformer를 computer vision에 적용한다면 image와 text 두 modality 차이로 다음의 두 가지 challenge가 존재합니다.
- scale
- language transformer에서는 processing의 기본 요소로 word token을 사용하지만, vision element들은 크기가 상당히 다를 수 있습니다. 기존의 transformer 기반 모델들은 token이 모두 고정된 크기를 가지는데 이러한 속성들은 vision에 적용하기에는 부적합합니다.
- resolution
- text 문장의 word와 비교해보면, image의 pixel 해상도가 훨씬 더 높습니다. semantic segmentation같은 경우 pixel level에서 dense한 prediction을 필요로 하는데, self-attention의 계산 복잡도가 이미지 크기의 quadratic 계산 복잡도를 가지기 때문에 high resolution image에서 transformer로 처리하기 어려울 수 있습니다.
이러한 이슈들을 극복하기 위해 hierarchical feature map구조를 가지고, 계산 복잡도가 이미지 크기의 선형적(linear)으로 비례하는 Swin Transformer를 제안하였습니다.
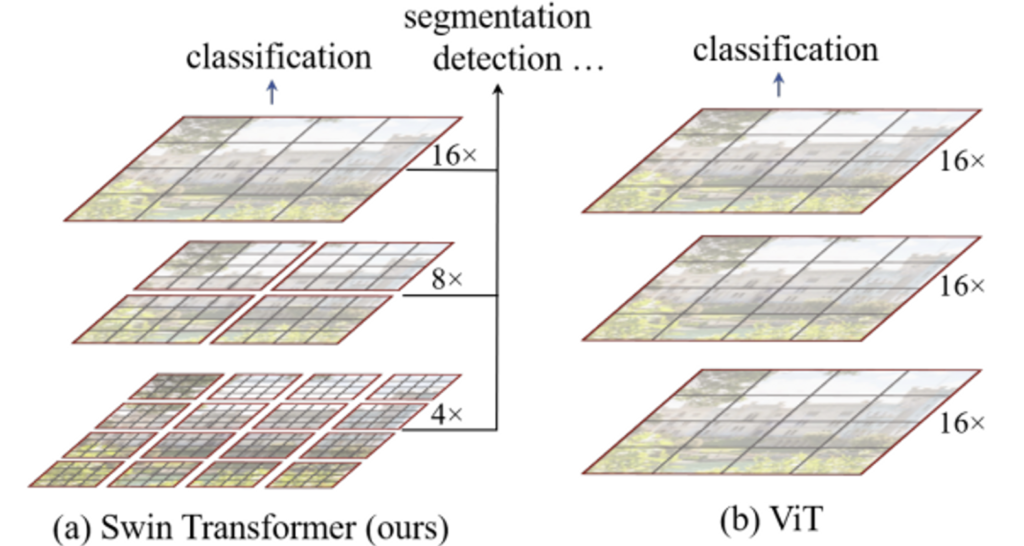
위 그림의 (a)가 Swin Transformer 구조인데, 작은 크기의 patch(회색)에서 시작해 점차 인접해있는 patch들을 merge해가며 hierachical feature map을 구성한 것을 볼 수 있습니다. 이런 계층적 구조를 통해 FPN이나 U-Net와 같이 dense prediction에 사용될 수 있죠. image내의 모든 patch 사이 self attention을 하는 것이 아닌 window(빨간색) 내에서만 계산하는데 각 window에 있는 patch의 수는 고정되어 있으므로, linear한 계산 복잡도를 가져갈 수 있겠습니다.
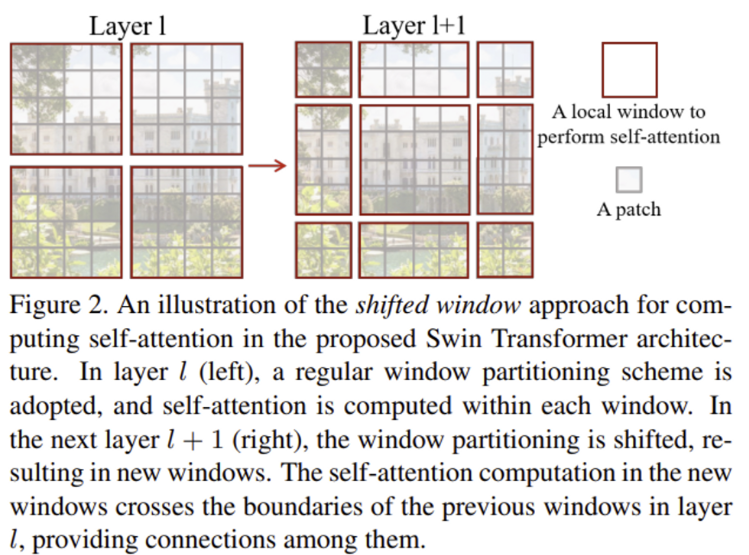
Swin transformer의 핵심이라고 볼 수 있는 shifted window입니다. 단순히 self-attention간의 window partition을 이동시키는 것인데, 자세한 내용은 아래에서 다루도록 하겠습니다.
Method
Overall Architecture
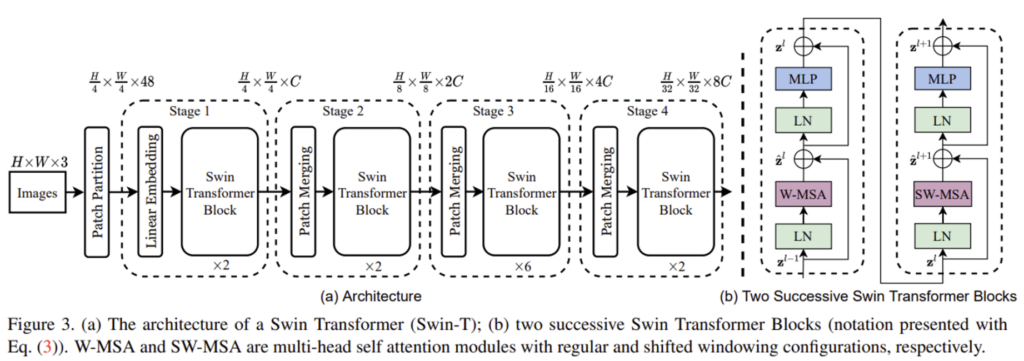
Swin transformer의 전체적인 구조입니다.
- Patch partition
- Linear Embedding
- Swin Transformer Block
- Patch Merging
크게 네 모듈로 구성되어 있는데, 동작 과정을 천천히 살펴보자면 먼저 RGB input 이미지가 들어오면 ViT처럼 non-overlapping patch들로 split 되게 됩니다(Patch Partition). 이 각각의 patch들을 “token”이라고 보게 되며 본 논문에서는 4×4의 patch size를 사용하여 patch의 feature dimension은 4x4x3(=48)이 됩니다.
- Stage 1 (x2)
- 이렇게 patch로 split한 후에 Linear layer를 거쳐 H/4 * W/4 * 48에서 H/4 * W/4 * C의 dimension으로 만들어줍니다다. (Linear Embedding) 여기서 C는 model의 크기에 따라서 달라집니다. 이후 Swin Transformer block을 통해 각 patch token에 대해 self-attention계산이 수행되게 됩니다. 이 transformer block은 token(patch)의 수를 (H/4 x W/4)로 유지합니다.
- Stage 2
- 앞에서 언급했듯이 계층적인 구조를 가지는 feature map을 생성하기 위해 layer가 깊어짐에 따라 patch를 merge하면서 token의 개수를 줄여나가게 됩니다. (Patch Merging). 인접해 있는 주위 2×2 patch들을 합쳐 하나의 큰 patch로 새롭게 만들게 되며 이 과정에서 차원이 4C로 늘어나게 되기에 linear layer를 통해 2C로 조정합니다. 이후 Swin transformer Block을 통과하며 self-attention계산을 수행합니다.
- Stage 3, 4 Stage
- 2와 마찬가지로, 이전 Stage에서 나온 output에 Patch Merging을 수행한 후 Swin Transformer Block을 태우는 식이다. 이 단계들은 VGG나 ResNet과 같은 일반적인 CNN resolution과 동일한 feature map resolution으로 hierarchical representation을 생성해냅니다.
Swin Transformer block
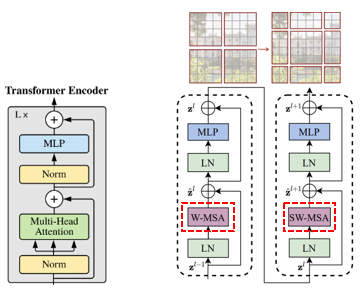
위 그림를 보면 기존 transformer block(왼쪽)과 구성은 유사하지만 한가지 차이점으로는 Swin Transformer(오른쪽)는 원래 multi-head self attention (MSA) 모듈을 shited window 모듈에 기반하여 바꾸었으며(W-MSA, SW-MSA), 각각의 MSA module을 포함한 2개의 연속적인 transformer로 하나의 swin block이 형성된 것을 볼 수 있습니다.
Shited Window based Self-Attention
기존 transformer는 global self-attention을 수행함으로써 모든 토큰 사이에 relationship이 계산되었습니다만, 이 global computation은 토큰의 수에 비례해 quadratic한 복잡도를 가지게 됩니다. 그렇기에 dense prediction이나 high-resolution 이미지를 표현해야 할 때 나오는 많은 token set으로 인해 곤란. . 하겠죠 . .
self-attention in non-overlapped
그렇기에 저자는 앞단에서 말했듯이 local window내에서 self-attention을 계산하게 되며, window는 non-overlapping(겹치지 않도록)으로 배열되어 있습니다. 각 window가 MxM개의 patch로 구성되어있다고 했을 때 global MSA 모듈과hxw의 크기의 patch 기반 window based MSA의 계산 복잡도는 아래와 같습니다.
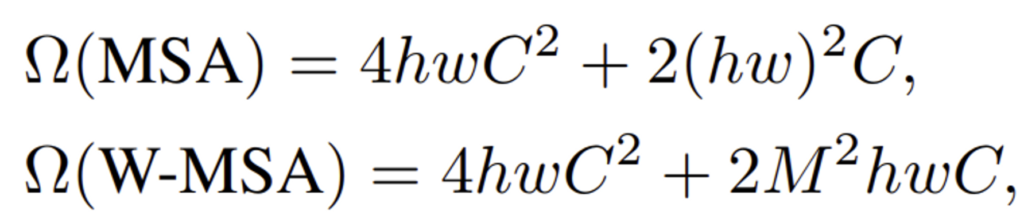
계산 복잡도를 보면 MSA는 patch 수에 따라 quadratic하고, W-MSA는 M이 고정될 때 linear합니다. hw가 큰 상황일 때 global self-attention은 계산량이 엄청나기에 적합하지 않은 반면에 window based self-attention은 계산 가능할 수 있겠네요 !
Shifted window partitioning in succesive blocks
window-based self-attention module은 각 window 내에서만 attention 연산을 수행하기 때문에 window들간의 연결이 부족하여 modeling 성능이 제한됩니다. 이를 해결하는 방법으로 기존 efficient 계산을 유지하며 consecutive Swin Transformer block에서 두 모듈을 번갈아 사용하는 shifted window partioning approach를 제안하였습니다.
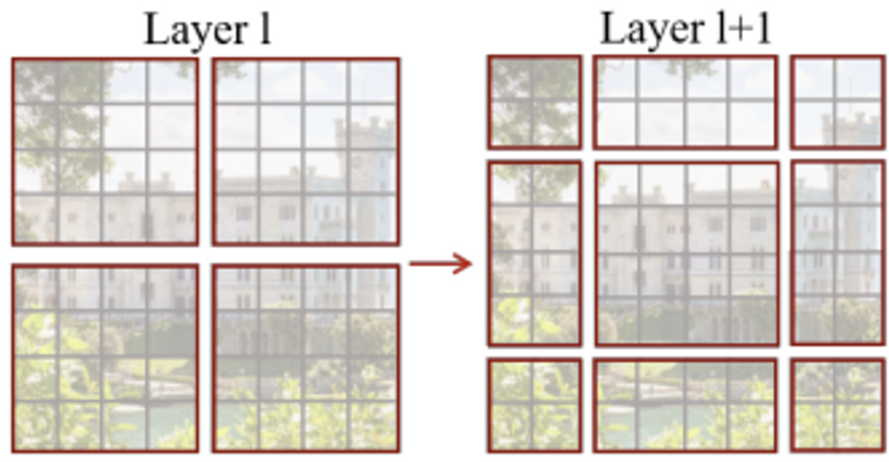
위 그림에서 첫 번째 모듈(왼쪽)은 좌상단 픽셀부터 시작해 8×8 크기의 feature map이 크기가 4×4 (M = 4)인 window 2×2로 균등하게 분할됩니다. 그 다음 모듈(오른쪽)은 window를 [M/2, M/2] pixel만큼 shift되어 크기가 조정됩니다.
연속적인 Swin Trnasformer block의 연산은 아래와 같습니다.
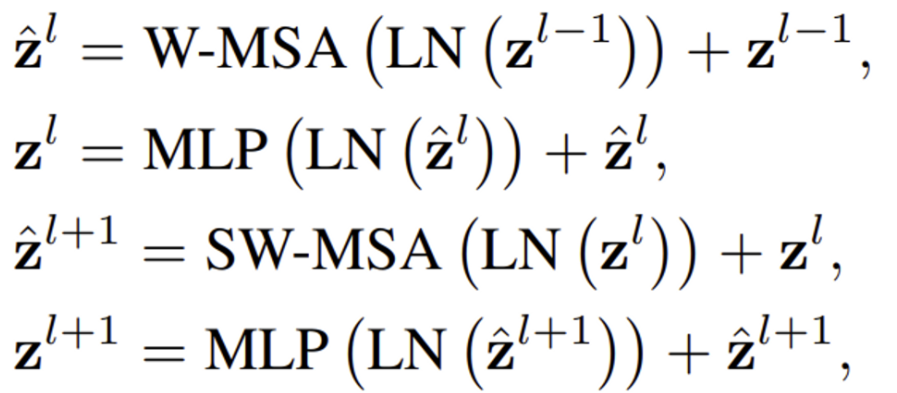
연산을 살펴보면, Window-based MSA 이후 shifted window-MSA로 진행되는 것을 볼 수 있습니다.
Efficient batch computation for shifted configuration
shifted window partitioning의 문제점이라 함은,, 아래 그림처럼 window개수가 늘어난다는 점입니다. (h/M x w/M] to [(h/M + 1) x (w/M + 1)].
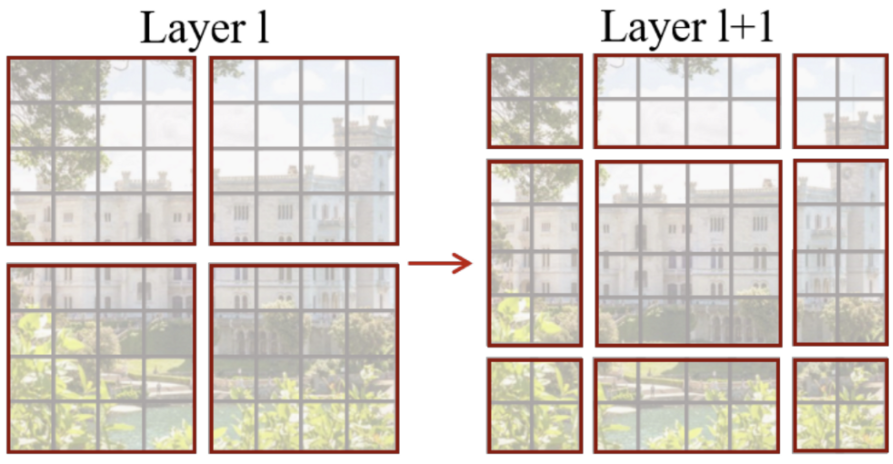
그림에서는 2×2의 window에서 3×3으로 증가한 것을 볼 수 있죠,
또, 몇개의 window는 MxM 크기보다 작아져버립니다. (4×4 크기보다 작은 가장자리의 2×2 window) 이를 나이브하게 해결한다면 단순히 MxM 크기보다 작은 window는 MxM 크기로 padding을 통해 크기를 키우고 attention계산할 때는 padding 한 부분을 masking처리함으로써 해결할 수 있겠다만 이런 방식은 연산량이 상당히 늘어나게 됩니다.
그렇기에 저자는 cyclic-shifting을 통해 보다 더 효율적인 batch computation을 하고자 하였습니다. cyclic shifting은 아래 그림과 같습니다.
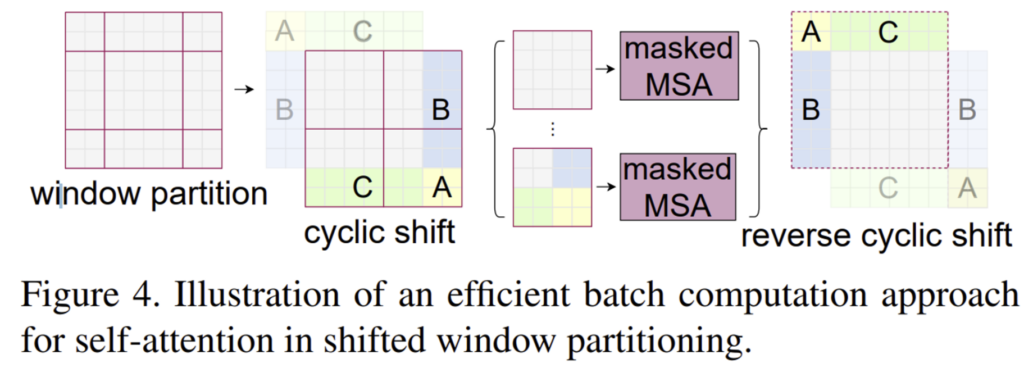
좌상단 쪽에 위치한 A, B, C 부분을 단순히 아래로 배치(좌상단을 향하여 cyclic하게 회전)하여 결국 제각각이였던 window size별로 self-attention계산을 할 필요 없게 한 것인데, shift후 batch window는 feature map에서 인접하지 않은 여러 sub-window로 구성될 수 있으므로, self-attention을 각 sub-window내로 제한하기 위하여 masking mechanism이 적용됩니다. cyclic-shift를 통해 batch window의 개수가 regular window partitioning 개수와 동일하게 유지되므로 이전에 나이브한 방법으로 언급한 패딩보다 효율적입니다.
Relative position bias
ViT에서는 각 이미지의 토큰 위치 정보를 보존하기 위해 position embedding을 더해주는 과정이 있었습니. 반면에, 위의 Swin transformer 구조를 보면 position embedding과정이 없던 것을 볼 수 있었을 것입니다. ViT와 다르게 Swin Transformer에서는 position embedding을 처음부터 더하지 않고 self-attention 과정에서 relative position bias를 더해주는 방식을 사용하였습니다.
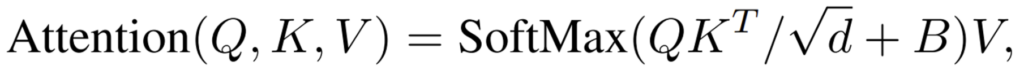
- d : query / key dimension
- Q, K, V ∈ \mathbb{R}^{M^2 * d}
위 식은 일반적인 attention score를 구하는 식인데, 여기에서 +B 부분이 relative position bias에 해당합니다. M개의 patch가 하나의 window를 구성하기 때문에 각 축에서 relative position은 [-M + 1, M -1]의 범위 안에 존재합니다. 따라서 작은 크기를 가지는 bias matrix를 \widehat{B} ∈ \mathbb{R}^{(2M-1) * (2M-1)}에 속하는 B로 파라미터화 할 수 있습니다.
기존 sin, cos 주기로 구한 절대좌표를 사용하는 것보다 상대좌표를 더해주는 것이 더 좋은 방법이라고 하네요 !
Architecture Variants
본 논문에서는 아래와 같이 4개의 version의 model을 소개하였습니다.
- Swin-T: C = 96, layer numbers = {2,2,6,2}
- Swin-S: C = 96, layer numbers = {2,2,18,2}
- Swin-B: C = 128, layer numbers = {2,2,18,2}
- Swin-L : C = 192, layer numbers = {2,2,18,2}
Sinw-B는 ViT-B/DeiT-B와 같은 계산 복잡도와 model size를 갖도록 설계하였으며, 모델 크기가 각각 0.25배, 0.5배, 2배인 Swin-T, Swin-S, Swin-L을 소개하였습니다. C는 첫 번째 stage에서 hidden layer 개수와 같습니다.
Experiments
다음은 ImageNet image Classification, COCO object detection, ADE20k semantic segmentation에 대한 실험들입니다.
Image Classification on ImageNet-1K, ImageNet-22K pretraining
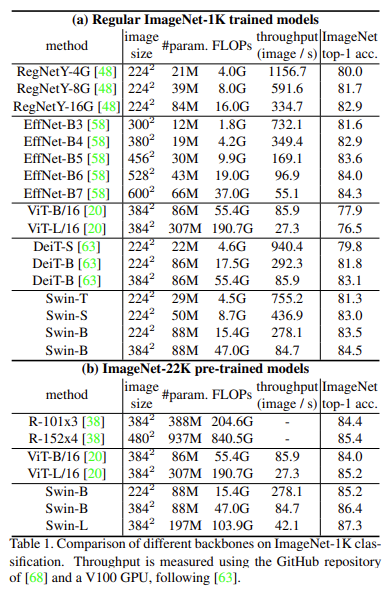
ImageNet-1K, 22K에서의 Image Classification 결과입니다. (a)에서 transformer 방법론인 ViT-B, DeiT-B와 Swin-B을 비교해보자면 셋 다 파라미터 수는 비슷하지만 속도 면에서 Swin이 조금 더 좋은 것을 볼 수 있으며, 당시 CNN 기반 모델 중 SOTA model이었던 EfficientNet과 비슷한 성능을 보였습니다. 또 (b)를 보면 22K로 pretrain했을 때가 처음부터 1K로 train한 것에 비해 1.8~1.9%정도 성능 향상이 이뤄졌네요. .
Object Detection on COCO
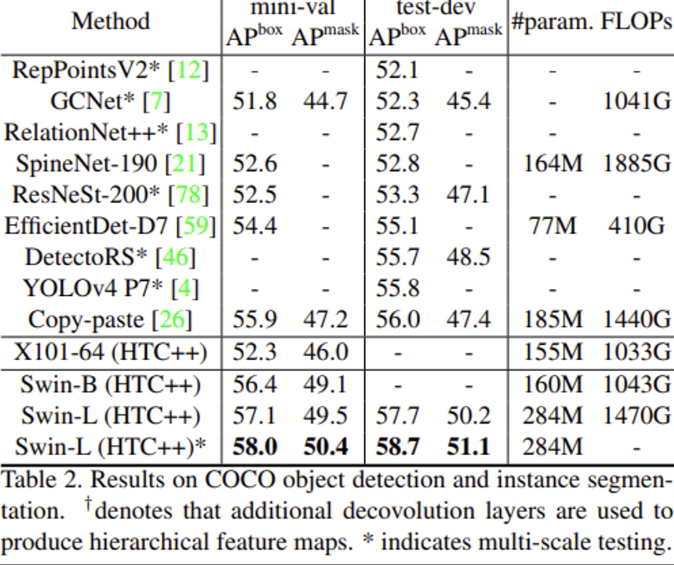
Semantic Segmentation on ADE20K
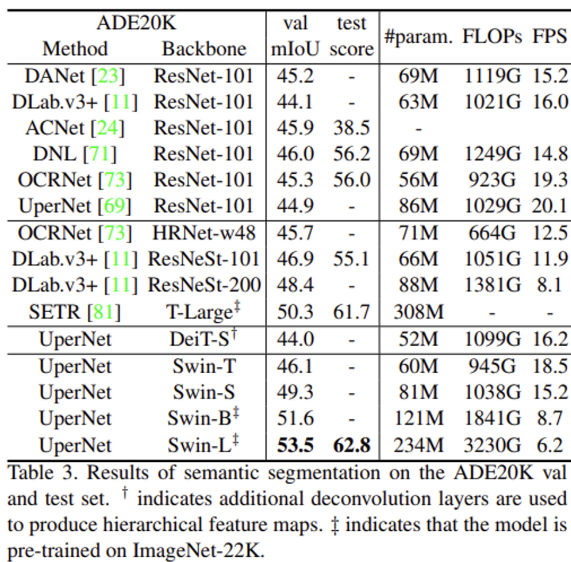
Object Detection, Segmentation task에서 백본으로 사용했을 때의 성능은 거의 다 SOTA를 달성했습니다.
Ablation Study
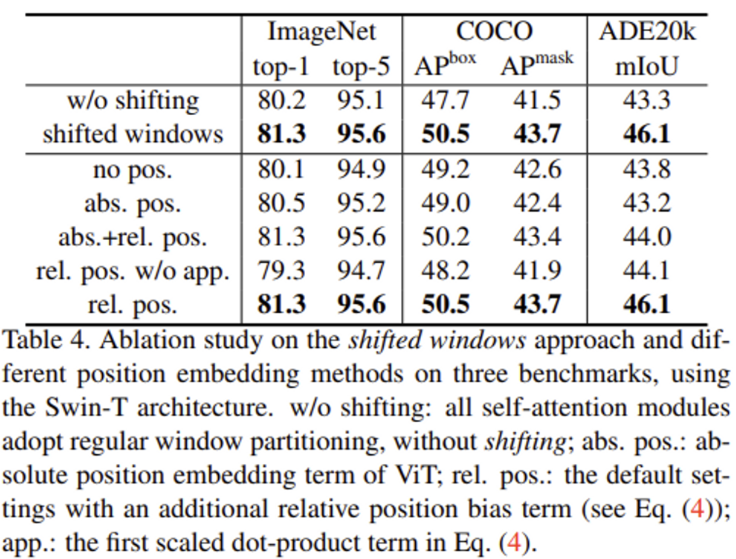
Shifted windows&Relaticve Position bias
ImageNet, COCO, ADE20K에 대해 shifted window에 관한 ablation study 결과입니다. 보다시피 모든 task에서 shifted window를 사용한 것이 성능이 더 높은 것을 확인할 수 있네요.
또, 아래 부분은 position embedding approach간의 차이를 보여줍니다. shifted window결과와 동일하게 모든 task에서 relative position bias를 사용한 경우가 가장 성능이 좋습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
ViT와 다르게 Swin Transformer에서 position embedding을 처음부터 하는 것이 아니라 self-attention 과정에서 relative position bias를 더해주는
방식을 사용한다고 말씀해주셨는데, 그렇다면 처음에 embedding이 되지 않은 채로 patch 형태로 split되어 self attention이 되는것인가요 ?
그렇다면 입력 이미지의 전체 position에 대해서는 고려되지 않은 채로 split된 patch 내에서의 position만 고려된 embedding이 되어 온전히 입력 이미지의 position이 고려된 것이라고 생각하지 않는데, 이에 대해 어떻게 생각하시는지 궁금합니다 !
댓글 감사합니다.
본문에도 적어뒀듯이 relative position은 [-M+1, M-1]의 범위 안에 존재합니다. 여기서 M이란 patch의 개수인데, 만약 patch 개수가 16개인 경우에는 각 축에서 [-15, 15]의 범위를 가지게 되겠죠. 즉 patch 내의 position을 더해준 것이 아닌, 이미지를 split한 patch들간의 상대좌표를 더해준 것이기에 온전히 입력 이미지의 position을 고려한다고 볼 수 있겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
결국 swin transformer는 일정한 개수의 patch로 이루어진 window를 사용하고, patch merging을 통해 하나의 patch가 보는 영역을 넓히는 방식으로 linear한 complexity를 확보한 것으로 이해하였습니다.
그 중에서도 인접 window와의 연결을 위한 shift windowing이 핵심적이라고 설명해 주셨는데, 해당 부분의 cyclic shifting부분에 궁금한 점이 있습니다. MSA수행 시 단순히 A, B, C를 masking하여 self-attention을 수행하는 것으로 이해하였는데요, 그렇다면 shift windowing에서는 ABC영역을 고려하지 않는 건가요? 이 과정이 이해가 잘 안가서… 추가적인 설명을 부탁드리고 싶습니다…
실험 파트의 object detection 결과에서 AP box는 우리가 알고 있는 bounding box에 대한 Average Precision인 것 같은데 AP^mask는 어떤 값을 의미하는지, AP^box와의 차이는 무엇인지 궁금합니다.
마지막으로는 ablation study의 abs+rel은 vit처럼 절대 좌표로 positional embedding을 수행한 뒤에 상대 좌표도 함께 더해준 것인가요? abs+rel 보다 rel만 사용한 것이 더 좋은 성능을 보인 것이 흥미롭네요 ㅎㅎ
댓글 감사합니다.
1. 본문의 그림을 보면, 좌상단에 위치한 A, B, C를 cyclic하게 회전심으로써 윈도우 사이즈를 제각각으로 할 필요 없이 4×4만으로 각각의 self-attention을 구할 수 있게 되었습니다. 하지만 A, B, C는 실제로는 떨어져 있는 값들이므로, ABC를 포함하여 self-attention 하는 것은 의미가 없습니다. 그렇기에 A, B, C 부분에 mask를 씌워서 self-attention을 수행하는 것인데요, 예를 들어 B가 포함되어있는 저 window 부분을 계산할 때 왼쪽 부분을 계산할 때에는 B 부분을 masking 처리해 계산을 안하게 되겠고, B 부분을 계산하게 될 때는 왼쪽 회색단에 mask를 씌워 계산을 안하도록 한다고 보면 될 것 같습니다.
2. 실험 파트의 APbox는 object detection의 AP이며, APmask는 instance segmentation에서의 AP입니다.
3. 넵. relative position bias에 관한 ablation study에서 abs+rel은 positional embedding을 수행한 뒤 relative position bias를 더해준 것이 맞습니다 !