안녕하세요. 백지오입니다.
여섯 번째 X-Review는 Temporal Action Detection 논문인 Boundary-Matching Network를 준비하였습니다.
이 논문은 저희 팀 기초 교육 과정에 읽은 논문인데, Action Detection 분야에서도 특히 Proposal Generation에 집중하여 성능을 개선하는 접근 방식과, 방법의 효과를 입증하기 위한 실험이 인상적이어서 가져와봤습니다.
시작에 앞서, Temporal Action Detection에 대해 간단히 설명 드리겠습니다.
Image에서 객체를 분류하는 task와 이 객체의 위치까지 파악하는 object detection task가 있는 것처럼, Video 분야에서도 어떠한 액션을 분류하는 task와 액션이 존재하는 시간대까지 파악하는 action detection task가 있습니다.
이해를 돕기 위해 이 논문의 정성적 결과 그림을 조금 먼저 가져와 보겠습니다. Object Detection에서 물체가 있는 위치의 bounding box를 예측하는 것처럼, Action Detection에서는 영상에서 액션이 있는 구간을 예측합니다.
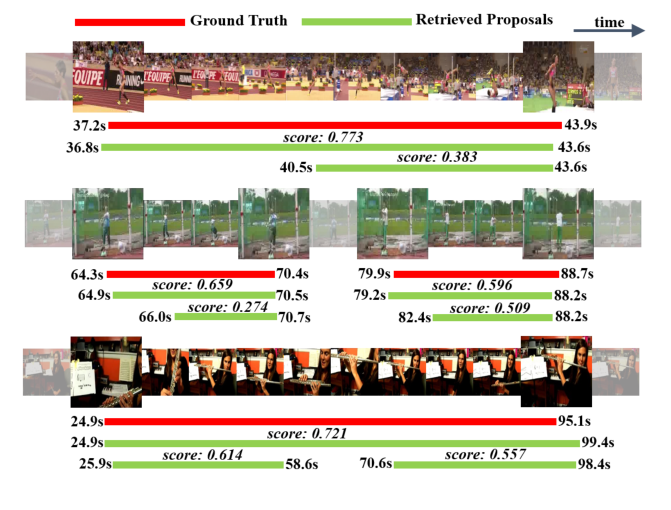
이러한 Action Detection에도 Object Detection의 2-stage Detector들과 유사하게 클래스와 무관하게 액션이 있는 것으로 보이는 영역을 찾는 proposal generation을 먼저 수행하고, 제안된 영역들이 어떤 클래스에 속하는지(혹은 background인지) 분류하는 2-stage 방법이 흔히 사용됩니다.
저자들은 이때 액션을 분류하는 성능은 상당히 좋아졌으나, 영상에서 액션이 포함된 영역에 대한 좋은 proposal을 생성하는 부분이 아직 많이 미흡하여 Action Detection의 성과가 좋지 않으며, 좋은 proposal을 만듦으로써 자연스럽게 성능을 개선할 수 있으리라 보고 Proposal Generation을 개선하고자 합니다. 저자들이 제시하는 좋은 proposal generation의 조건은 다음과 같습니다.
- 실제로 액션이 발생한 영역을 정확하게 탐지할 수 있는 유연한 길이와 정확한 경계의 temporal proposal 생성
- proposal에 대한 적절하고 신뢰할 만한 confidence score 생성
기존의 방법론들은 흔히 “top-down” 방식의 proposal 생성을 수행했는데, 고정된 크기의 sliding window 형식으로 영상을 몇 개의 영역으로 나누고, 이들 각각에 대해 동시에 confidence score를 계산하였습니다. 저자들은 이러한 방식이 액션의 위치를 유연하고 정확하게 잡아내지 못한다고 지적합니다.
한편, 이 논문에 영향을 준 Boundary-Sensitive Network (BSN)에서는 “bottom-up” 방식의 proposal 생성을 적용했습니다. 이는 시간적 경계(temporal boundary)를 정의하고 이를 조합하여 proposal을 생성하는 방법입니다. 사전에 존재하는 sliding window의 길이에 맞추어 proposal이 생성되는 것이 아니라, 어떤 액션의 시작점과 끝점을 찾고, 이들을 합쳐 proposal을 생성하므로 앞선 방법에 비해 더욱 다양한 길이의 정교한 proposal을 생성할 수 있습니다.
저자들은 이러한 BSN에서 세 가지 문제를 정의하고 개선한 bottom-up 방식의 proposal generation 방법인 Boundary-Matching (BM) 방식을 제안합니다. 저자들이 제시한 BSN의 문제점은 다음과 같습니다.
- 생성된 proposal들에 대한 confidence evaluation이 각각 실행되어 비효율적이다.
- BSN이 생성한 proposal feature는 시간적인 맥락을 파악하기에 충분히 좋지 않다.
- BSN은 여러 단계로 구성되는데, 통합된 프레임워크가 아니라 비효율적이다.
저자들은 앞서 언급한 단점들을 해결한 BNM을 제안하며, 이를 적용하여 대표적인 Action Detection 데이터셋인 THUMOS-14와 ActivityNet-1.3에서 SOTA를 달성하였습니다.
Approach
논문에서 상당히 복잡한 annotation이 많이 등장해서, 블로그에 자세한 설명을 작성하고 여기서는 최대한 쉽게 설명해보겠습니다. 자세한 내용이 궁굼하신 분은 여기를 참고해주세요!

먼저, 영상에서 특성을 추출해줍니다. 논문 자체가 proposal generation에 집중한 것이기 때문에, 새로운 방법을 사용하지 않고 기존 action detection 방법에서 흔히 사용하는 3D 합성곱 혹은 2-stream 방법(RGB + Optical Flow)을 사용합니다. 영상에서 $\sigma$ 간격으로 특성을 추출하여 feature sequence $F$로 만들어줍니다.
추출된 feature sequence를 Base Module에 입력하는데, 이때 가변적인 길이를 가진 feature sequence를 길이 $l_\omega$ 길이의 observation window로 분할해줍니다. 이때, 길이가 긴 액션도 포함될 수 있도록 $l_\omega$를 충분히 길게 설정해줍니다. 이렇게 변환된 feature sequence를 Teporal Evaluation Module과 Proposal Evaluation Module에 각각 입력해줍니다.
Temporal Evaluation Module (TEM)
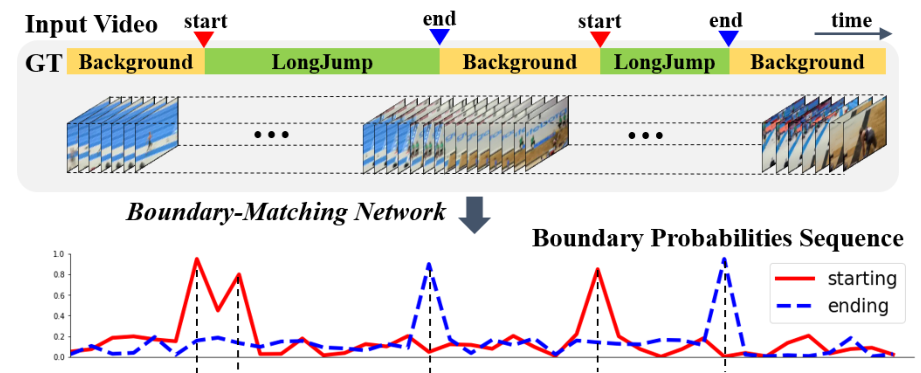
TEM은 영상의 각 영역이 어떤 액션의 시작 경계(Starting Boundary) 혹은 끝 경계(Ending Boundary)일 확률을 예측합니다. 이때 확률이 높은 시작 경계와 끝 경계의 매칭을 통해 proposal이 생성되는 것 입니다.
Proposal Evaluation Module
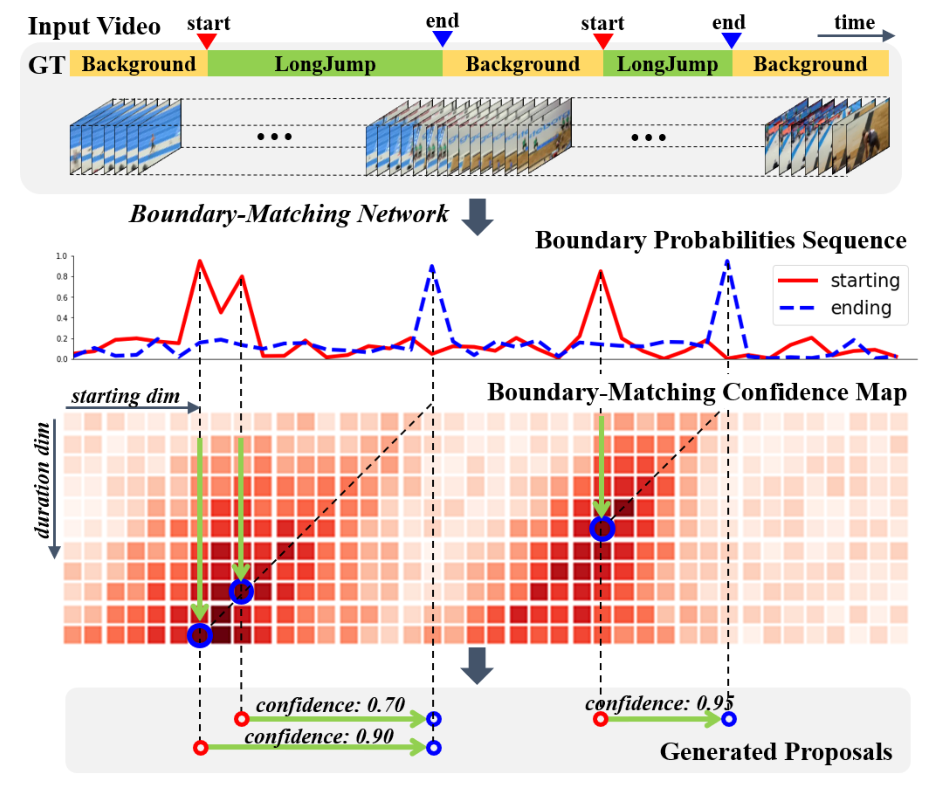
PEM은 위 그림에 나타난 것과 같은 Boundary-Matching confidence map을 생성합니다. BM confidence map은 어떤 시작 경계(가로 축)로부터 어떤 길이(세로 축)만큼의 영역이 액션인지에 대한 confidence를 생성합니다.
앞서 BSN의 단점으로 생성된 proposal들에 대한 confidence를 각각 계산하는 방식의 비효율성을 지적하였는데, BMN은 위와 같이 모든 시작 지점과 길이에 대응하는 confidence를 위와 같이 map 형식으로 한번에 계산하여 이러한 단점을 개선하였습니다.
그림에 나타난 것처럼 TEM이 생성한 boundary 확률과 PEM이 생성한 BM confidence map을 함께 활용하면 쉽게 proposal과 confidence를 생성할 수 있습니다.
Boundary Matching Layer
PEM은 Boundary Matching Layer(BM Layer)와 몇 개의 합성곱 계층으로 구성되는데요. 이때 조금 특이한 역할을 수행하는 BM Layer를 살펴보겠습니다.
앞서 특성 추출과 base module을 거쳐 feature sequence $S_F \in \mathbb{R}^{C\times T}$를 얻었습니다. $C$는 단순히 한 시점의 feature의 길이로 생각하시면 되고, $T$는 영상의 시간 축에 해당하는 길이입니다. PEM은 영상의 전체 영역을 균등하게 나누어, 각 영역에서 여러 가지 길이에 대응하는 proposal들의 confidence를 구하여 BM confidence map을 만들었죠.
예를 들어, $T=100$ 즉, 길이가 100인 영상이 입력되었을 때, PEM이 $N=20$개의 지점에서 시작하는 proposal들에 대한 confidence를 평가하고자 한다면, 영상의 0에서 시작하는 proposal들에 대한 score, 5에서 시작하는 proposal들에 대한 score, 10에서 시작하는 score 등을 생성하여야 할 것입니다.
그런데, 만약 $T$가 $N$으로 깔끔하게 나누어지지 않는다면, 예를 들어 $T=100$인데 $N=3$이라 33.33부터 시작하는 proposal을 평가해야 한다면, 33번째 feature를 사용해야 할지 34번째 feature를 사용해야 할지 애매할 것입니다.
그래서 BM Layer는, $C\times T$ 크기의 $S_F$에 $T\times N$ 크기의 sampling mask weight를 점곱하여 $S_F$를 $C\times N$크기로 변환해줍니다. 이때 sampling mask weight는 아래 식에 의하여 생성되는데요.
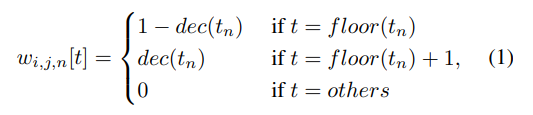
이해하기 쉽게 생성된 sampling mask weight의 그림을 보겠습니다.
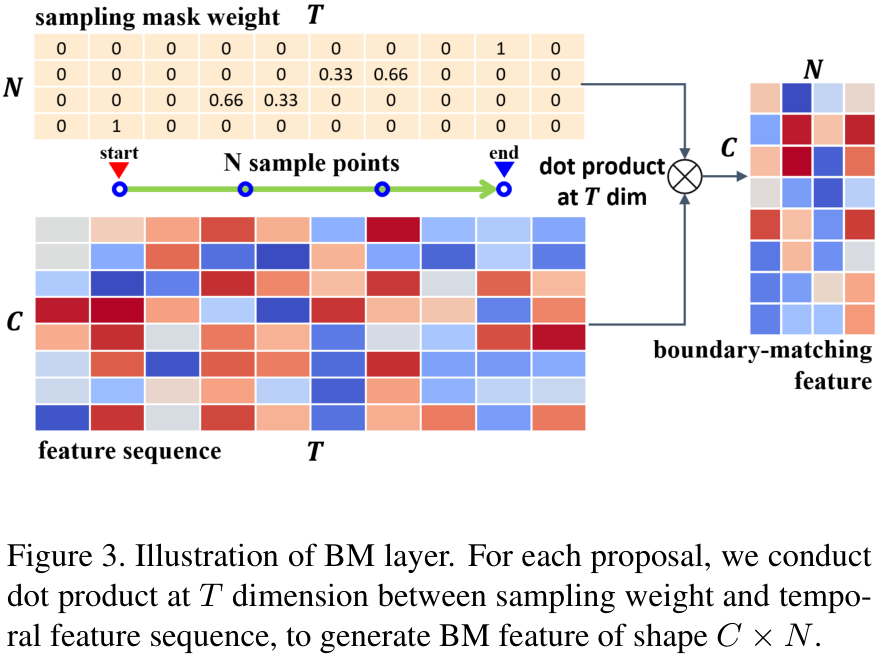
그림 상단의 가중치 행렬을 보면, 0.66, 0.33과 같이 적절하게 feature를 합쳐 새로운 BM feature를 만드는 것을 확인할 수 있습니다.
BMN 학습
BMN은 앞서 언급한 세 모듈을 포함하여 모델 전체를 end-to-end로 학습합니다. 당연히 각 모듈을 학습하는데 사용되는 손실 함수도 통합되어 있는데요. 하나씩 살펴보겠습니다.
$$ L_{TEM} = L_{bl}(P_S, G_S) + L_{bl}(P_E, G_E)$$
먼저 TEM은 실제 액션의 시작 지점과 끝 지점을 나타내는 $G_S, G_E$와 예측된 $P_S, P_E$간의 binary logistic regression loss를 손실함수로 사용합니다. 정확히 $G_S, G_E$와 일치하는 $P$에 대해서만 loss를 적용하는 셈인데, $G_S, G_E$의 주변부도 고려하는 loss를 사용하면 어떨까하는 생각이 문득 드네요.
$$L_{PEM} = L_C(M_{CC}, G_C) + \lambda \cdot L_R(M_{CR}, G_C)$$
PEM은 BM Confidence map을 생성하는데, 앞서 설명하지는 않았지만 사실 두 가지 방식으로 두 개의 map $M_{CC}, M_{CR}$을 생성합니다. $M_{CC}$는 이진 분류 손실로 학습되며, $M_{CR}$은 회귀 손실 함수로 학습이 됩니다.
$$ L = L_{TEM} + \lambda L_{PEM}$$
최종 손실 함수는 두 모듈의 손실함수의 합에 L2 규제를 적용하여 완성됩니다.
BMN 추론
추론 단계에서는 boundary probability sequence $G_S, G_E$와 BM confidence map $M_{CC}, M_{CR}$을 이용해 proposal을 생성합니다.
먼저, $G_S, G_E$에서 confidence가 임계값 이상인 위치들을 찾고, 이들을 매칭하여 proposal들을 생성합니다. 그 다음 각 boundary probability와 두 개의 confidence map에서 얻은 score들을 아래 식을 통하여 융합합니다.
$$ p_f = p^s_{t_s} \cdot p^e_{t_e} \cdot \sqrt{p_{cc} \cdot p_{cr}}$$
$p^s, p^e$는 boundary의 확률이고, $p_{cc}, p_{cr}$은 confidence score입니다.
마지막으로, Soft NMS를 이용해 중복된 proposal들을 제거해줍니다.
실험
저자들은 Action Detection에서 흔히 사용되는 THUMOS-14와 ActivityNet-1.3에서 실험을 진행하였습니다. Temporal Action Proposal Generation의 성능을 평가하기 위해, 저자들은 여러 IoU 임계값에 따른 Average Recall (AR)을 평가하였으며, 평균 proposal 갯수(AN) 대비 AR (AR@AN), AR vs. AN 커브(AUC)도 지표로 사용하였습니다.
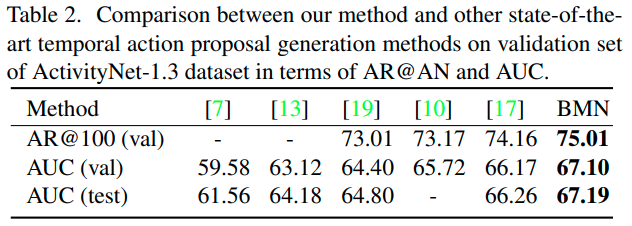
먼저 ActivityNet에서의 비교를 보면, 기존 SOTA 방법론들 대비 성능이 향상되었으며, 특히 [17]로 나타난 BSN에 비해 약 1% 정도의 유의미한 성능 향상이 있었습니다.
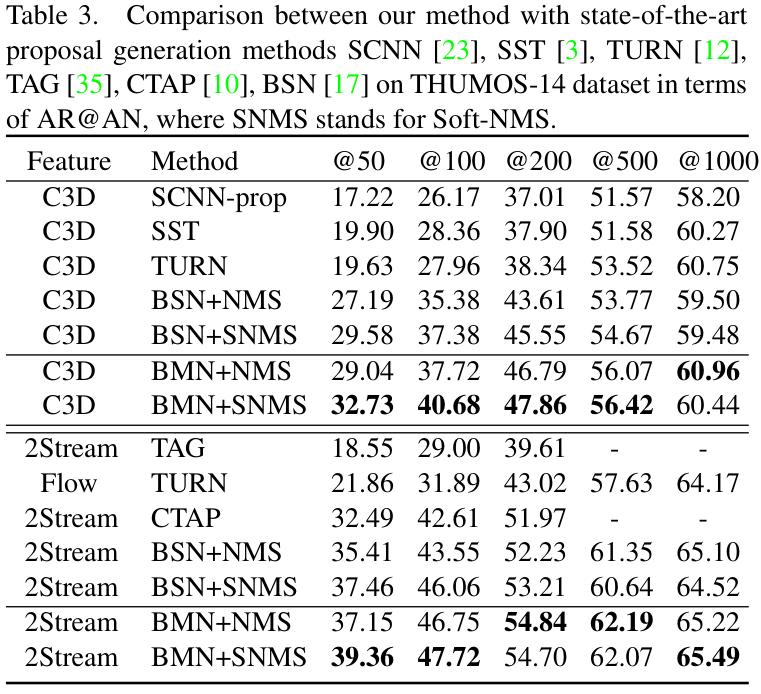
THUMOS-14 데이터셋에서의 비교 결과도 살펴보면, 기존 방법론들 대비 거의 모든 AR@AN 설정에서 성능이 앞섰으며, 특히 Soft NMS를 적용하면 성능 향상이 더 커졌습니다. 저자들은 3D 합성곱 기반 특성과 2Stream(RGB+Optical Flow) 기반 특성을 각각 활용하여 성능을 비교하였는데, 어떤 특성을 사용해도 BMN은 기존 방법 대비 좋은 성능을 보여 저자들이 제안한 Proposal Generation이 유효함을 보였습니다.
Ablation Study
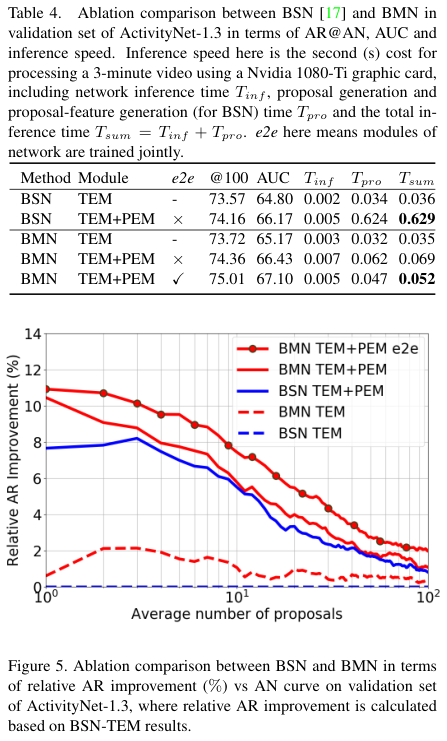
저자들은 BMN의 각 모듈들의 효과를 확인하기 위해, BSN과 BMN, BMN의 각 모듈 적용 여부에 따른 성능 및 속도를 비교해보습니다. BSN과 BMN의 구조가 유사하여, BSN과 BMN에 TEM만을 적용하였을 때는 비슷한 성능을 보였는데, PEM을 적용한 결과 두 모델 모두 성능이 크게 증가하여 PEM이 proposal 생성에 중추적인 역할을 함을 확인할 수 있었습니다. 각 proposal에 대한 confidence를 따로 계산하는 BSN에 비하여, BMN은 모든 proposal에 대한 score를 한번에 계산하여 추론 속도가 훨씬 빨랐고, BMN은 또한 모든 모듈을 함께 학습할 수 있어, 성능과 학습 속도면에서도 우수했습니다. 저자들이 주장한 BSN의 단점인 비효율성과 충분하지 못한 성능이 개선되었음을 보였네요.
일반화 성능

BMN이 학습 과정에서 본 적 없는 액션에 대하여도 proposal을 잘 생성하는지 확인하기 위해, ActivityNet에서 서로 겹치지 않는 “Sports, Exercise, and Recreation”과 “Socializing, Relaxing, and Leisure” subset을 분리하여 각각 seen과 unseen 카테고리로 분류하였습니다. 그 다음 모델을 seen 데이터에서만 학습시킨 것과 unseen 데이터까지 포함하여 학습시킨 다음 unseen 카테고리에 대한 proposal 성능을 확인하였는데, 성능 감소가 미미하여 BMN이 액션 proposal을 처음보는 액션에 대해서도 잘 수행함을 볼 수 있습니다.
Action Detection 성능
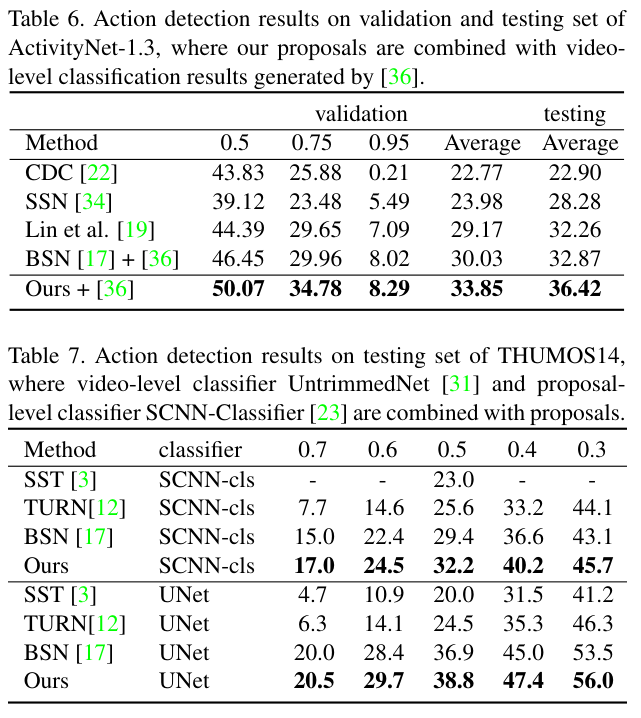
마지막으로, 이렇게 좋은 proposal이 Action Detection에 유의미한 성능 개선을 주는지 확인하기 위해 BMN 모델을 실제로 Action Detection에 적용하여 성능을 측정한 결과, 기존 모델들에 proposal generator를 BMN으로 바꾸니 성능이 향상되었습니다. 표 6에서는 BMN을 Proposal 기반 detection 모델에 적용한 결과 성능이 향상됨을 확인할 수 있으며, 표 7을 보면 video-level classifier인 UntrimmedNet에 적용하여도 성능 향상이 확인됨을 볼 수 있습니다.
결론
이 논문에서는 Action Detection의 성능을 향상시키기 위해 Temporal Proposal Generation에 집중하여, 더 정확하고 빠르게 proposal을 생성하고자 하였습니다. 이를 위해 기존의 sliding window나 anchor 방식이 아닌, 영상의 각 영역이 temporal boundary일 확률을 파악하고, 확률이 높은 boundary 간의 matching을 수행하여 proposal을 생성하였으며, proposal의 confidence를 BM confidence map을 통해 한번에 계산하여 좋은 proposal과 confidence score를 생성하였습니다.
Action Detection에서 Proposal Generation이라는 subtask에 집중하고, 이를 개선하며 실험에서도 별도의 지표로 성능 개선을 확인한 것이 인상적이었으며, 단순히 어떤 데이터셋에서 SOTA를 달성한 것만을 보이지 않고 classification 모델의 구조나 사용하는 특성 추출의 방식(C3D, 2stream)을 바꿔가며 실험한 것이 믿을만 하다는 인상을 주었습니다. 특히 일반화 성능까지 확인한 것이 굉장히 꼼꼼하다는 생각이 듭니다.
오늘 리뷰는 여기까지입니다.
다들 1학기 고생많으셨고, 좋은 주말 보내시기 바랍니다. ?
안녕하세요, 백지오 연구원님. 좋은 리뷰 감사합니다.
비디오 쪽 리뷰를 보는 건 처음이라 낮설었는데, 새로운 용어들과 익숙해지기 위해 노력하며 읽어보았습니다. 비디오의 액션을 검출하고 분류까지 하는 Action detection task가 신기했습니다.
논문의 contribution은 다음과 같이 정리될 수 있을 것 같습니다.
우리에게 익숙한 2-stage object detection task처럼, action detection task는 1. class와 무관하게 액션이 있는 것으로 보이는 영역을 찾는 proposal generation과, 2. 제안된 영역들이 어떤 클래스에 속하는지(아니면 background인지) 판별하는 단계로 나뉩니다. 이 때 Action classification 성능은 좋아졌지만, 아직 proposal generation 단계가 미흡하여 Action Detection의 성과가 좋지 못하며, 이 단계를 보완해서 성능을 높일 수 있을 것으로 기대됩니다. 저자가 제시하는 좋은 proposal generation은 1. 유연한 길이와 정확한 경계의 temporal proposal을 생성하고, 2. proposal에 대한 적절한 confidence score를 생성하는 것이고, 기존 방법론들은 ‘Top-down 방식’으로 고정된 크기의 sliding window로 동영상을 영역으로 나누고 각각에 confidence score를 계산했습니다. 저자들은 이러한 방식이 Action의 위치를 유연하고 정확하게 잡아니지 못한다고 지적했으며, 이 논문에 영향을 준 Boundary-Sensitive Network(BSN)에서는 “bottom-up” 방식의 proposal 생성을 적용하는데, 이는 시간적 경계(temporal boundary)를 정의하고 이를 조합하여 proposal을 생성하는 방법입니다. 저자들은 이러한 BSN에서 문제점을 정의하고 bottom-up 방식을 개선해서 Boundary-Matching(BM) 방법을 제안합니다. BMN은 모든 시작 지점과 길이에 대응하는 confidence를 map형식으로 한번에 계산하여 proposal에 대한 confidence를 각각 계산하는 방식의 비효율성을 개선하였습니다.
Experiment 부분을 보다 궁금증이 생겼는데, Table3에서 THUMOS-14 데이터셋 그래프에서 Feature가 뜻하는 것이 무엇인지 잘 모르겠습니다. 맨처음에 데이터셋인가 싶었는데 그것도 아닌 것 같고, 방법론은 옆에 Method라고 따로 써져 있네요. 이에 대해 알려주실 수 있을까요?
감사합니다
안녕하세요. 허재연 연구원님.
꼼꼼히 읽어주셔서 감사합니다.
Table 3.의 Feature는 가로, 세로, 채널, 시간의 4차원 데이터인 영상에서 feature를 추출하는 방법을 의미합니다. C3D는 3D 합성곱을 의미하며 2Stream은 RGB 이미지와 Optical Flow라고 하는 일종의 2D handcrafted feature를 사용하여 2D 합성곱으로 feature를 추출하는 방식입니다.
3D CNN은 영상의 가로, 세로, 시간 모든 요소를 고려할 수 있지만 연산량이 많은 단점이 있고, 2Stream은 시간에 따른 픽셀의 변화를 이미지와 유사한 Optical Flow 형식으로 변환하여 2D CNN으로 처리함으로써 연산량을 줄인 방식입니다.
다만 이러한 차이는 영상에서 feature를 뽑아내는 방식의 차이이기 떄문에, Table 3.는 저자들이 제안한 proposal generation 방식이 feature extraction 방식에 관계없이 어떤 방식에서든 효과가 좋았다는 것으로 볼 수 있을 것 같습니다.
감사합니다.
좋은 리뷰 감사합니다.
Loss에 들어가는 입력을 보면 뭔가 행렬 행태의 map이 들어가는 것 같은데 label은 구간 정보(2초~5초)로 들어가는 것으로 알고 있습니다.
이렇게 예측과 정답간의 구조적인 차이가 있는데 실제로 label이 어떻게 변환되어 Loss가 계산되는지 궁금하네요.
안녕하세요. 임근택 연구원님.
말씀하신 것처럼 action detection task에서 label은 어떤 액션의 클래스와 해당 액션의 구간 정보 (시작 시간과 끝시간 혹은 시작 시간과 길이)로 주어집니다.
한편 BMN에서 PEM이 생성하는 BM confidence map은 어떤 시작 시작 시간부터 특정한 길이의 action이 있을 확률을 갖고 있는 행렬이죠.
이러한 행렬을 생성하도록 PEM을 학습시키기 위해, 주어진 라벨을 활용해 Confidence Map과 같은 크기의 BM Label Map을 생성하는 과정을 거치고, 이를 이용해 학습을 진행합니다. Label Map은 ts에 시작하여 te에 끝나는 어떤 proposal에 대하여, 이 proposal과 실제 action의 IOU를 구하여 생성됩니다.
예를 들어, 어떤 GT action이 0~5초에 존재할 때, Label map의 (3, 3), 즉 3초에 시작하여 3초간 진행되는 proposal에 대한 label값은 1/3이며, (1, 4)는 4/5가 되겠습니다.
좋은 질문 덕분에 Label Map의 생성과정에 대해 더욱 깊게 생각해 볼 수 있었습니다.
감사합니다! ?