3d object detection task는 정확한 물체의 위치를 검출하는데 큰 도움이 되지만 3d data의 sparse한 특성상 어려운 task로 여겨진다. 또 object surface에서만 point cloud를 얻을 수 있기 때문에 물체의 중심 위치를 찾는데 어려움이 있다. 본 논문에서는 fully-convolutional single-shot sparse detection network인 Generative Sparse Detection Network(줄여서 GSDN)을 제안한다. 해당 모델의 주요한 구성 point는 transposed convolution과 pruning layer로 구성된 generative sparse tensor decoder로 필요한 memory는 줄이고 불필요한 object center는 제외할 수 있다는 효과를 가진다. GSDN은 하나의 fully-convolutional feed-forward pass를 통해 large scale의 input을 처리할 수 있다. 해당 모델은 3d indoor dataset에서 평가했고 당시 sota를 달성할 수 있었다. 해당 논문은 point cloud와 image fusion방법론인 tr3d-ff의 모델 구조에서 base가 되는 구조로 선택하여 좀 더 자세히 알아보기 위해 리뷰하게 되었다.
Introduction
2d image는 pixel마다 값이 있는 dense한 array형태로 존재하지만, 3D data의 경우 어떤 공간에서 points들의 집합으로 구성되거나 삼각법(triangular)을 통한 mesh로 구성된다. 이러한 data의 특성상 3d space에서 data는 작은 일부 공간만을 차지할 수 밖에 없고 따라서 3d object detection task를 수행하는데 어려움이 있다. 먼저 3차원 데이터이기 때문에 data를 처리할 때 cubic하게 complexity가 증가하게되어 많은 연산을 필요로 하게되고, 물체가 존재하는 영역의 data가 sparse하고 object surface에서 sampling된 point 정보만 가질 수 있다는 어려움이 존재한다. 기존 3d object detector들은 이러한 문제를 해결하기 위해 voxel과 같은 dense representation으로 변환하여 사용하거나 direct하게 point sets들을 mlp에 태우는 방법을 사용했다. 하지만 voxelize를 통한 volumetric feature를 사용하는 경우에는 많은 memory를 필요로 하게 되고, direct하게 point set을 처리하는 방법의 경우에는 사전에 network로 Process할 point수를 사전에 제한해주는데 이 경우 low resolution input을 large scale scene에 대해 scale up하거나 scene을 Cropping하여 small window-sliding방식을 적용하는 어려움이 존재한다고 한다. 하지만 본 논문에서는, 이를 대신하여 hierarchical sparse tensor encoder를 활용하여 3차원 cubic complexity 문제를 해결하고자 하였다. sparse representation을 활용하면서 기존의 다른 dense tensor를 input으로 한 single-shot 방법론들에 비해 빠르고 메모리 효율적인 network를 구성할 수 있었다. 또한 scene을 small window에 맞게 cropping하여 receptive field size나 point density의 손실 없이 large scale scene을 처리할 수 있었다고 한다.
또 다른 challenge한 요소로는 scan input인 sampling한 3d point는 object surface의 point인데 bounding box anchor가 나타내는 object center에 대한 정보는 없는 disjoint한 형태라고 지적한다. 대부분의 물체들은 convex한 형태이고 object center를 direct하게 예측하기는 어렵다. 본 논문에서는 generative sparse tensor decoder를 제안하여 반복적인 upsampling과정을 거쳐 최소한의 runtime으로 관련없는 정보는 버리고 anchor가 다양한 영역을 cover할 수 있도록 하였다.

정리하자만 sparse tensor를 처리하는 single-shot 3d object detection network인 Generative Sparse Detector Network인 GSDN을 제안하였다. network는 크게 feature를 추출하는 hierarchical sparse tensor encoder와 sparse input에서 object proposal을 하기 위한 generative sparse tensor decoder 두 요소로 나뉜다. 실험적으로 large-scale indoor dataset에서 sota를 달성했다.
Related Work
먼저 3d indoor object detection의 경우에는 outdoor와 다른 object placement distrubution특성으로 인해 서로 다른 방법으로 처리하는게 일반적이다. outdoor의 경우 하늘에서 새가 본 view라해서 bird’s eye view(BEV)로 처리하여 2d ground plane으로 projection하여 Detection을 수행하는게 일반적이다. 하지만 indoor의 경우에는 예를 들어 벽이나 천장에 lamp가 붙어있는 경우나 desk위에 다른 물건이 올려져있는 경우가 있다. 이러한 경우 outdoor처럼 bev로 보게되면 겹쳐서 검출하는데 어려움이 클것이다. 따라서 indoor의 경우처리하는 방법들이 다양하게 존재한다. 논문에서는 sliding-window with classification, clustering-based method, bounding-box proposal, 위의 방법들을 combination한 방법 이렇게 다양하게 존재한다고 하는데 제안하는 방법론인 GSDN의 경우는 bounding box proposal method로 input point cloud의 sparsity를 유지하면서 다양한 anchor space를 통해 large scene에서 빠르고 정확한 검출이 가능하다고 한다.
network에서 3D shape을 genrate하는 방법은 크게 continuous 3d point representation과 discrete grid representation으로 나뉘는데 GSDN은 discrete grid representation 중 sparse representation을 사용한다. sparse tensor network는 masking이나 pruning하는 것처럼 weight만 sparse matrices이고 feature map은 dense tensor인것과는 다르게, spatially sparse tensor를 input으로 하여 spatially sparse feature map을 생성한다.
Preliminaries
방법론을 소개하기에 앞서 3d representation 방식인 sparse tensor에 대해 간단히 이해해보자. 논문에서 기호에 대해, 소문자 letter(t)는 variable scalar, 대문자 letter(T)는 constants, 소문자 bold체(t)는 vector, 대문자 bold체(T)는 matrices, Euler script는 tensor, calligraphic symbol은 집합을 나타내는 기호로 표시했다.
Sparse Tensor
tensor는 고차원 데이터를 표현하는 multi-dimensional array이다. D차원의 sparse tensor는 아래와 같이 나타내며 대부분은 0의 값을 가지고 있다.

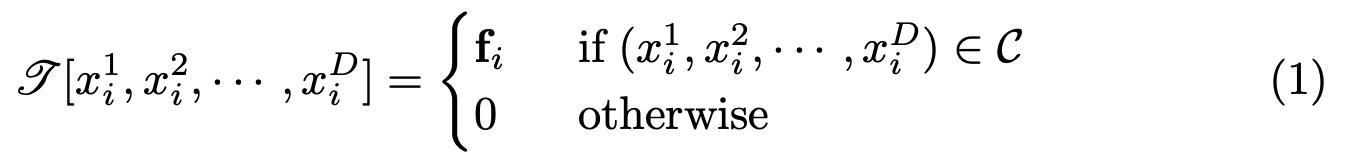
Xid는 d번째 차원의 i번째 0이 아닌 element로 fi는 해당 feature를 의미한다.
sparse convolution은 sparse한 point cloud를 처리하는데 효과적인 방식이다. 좀 더 이해를 돕기 위해 sparse convolution 연산에 대해 예전에 리뷰에서도 설명했던 것처럼 2D의 경우를 생각해서 예시를 들어보겠다.
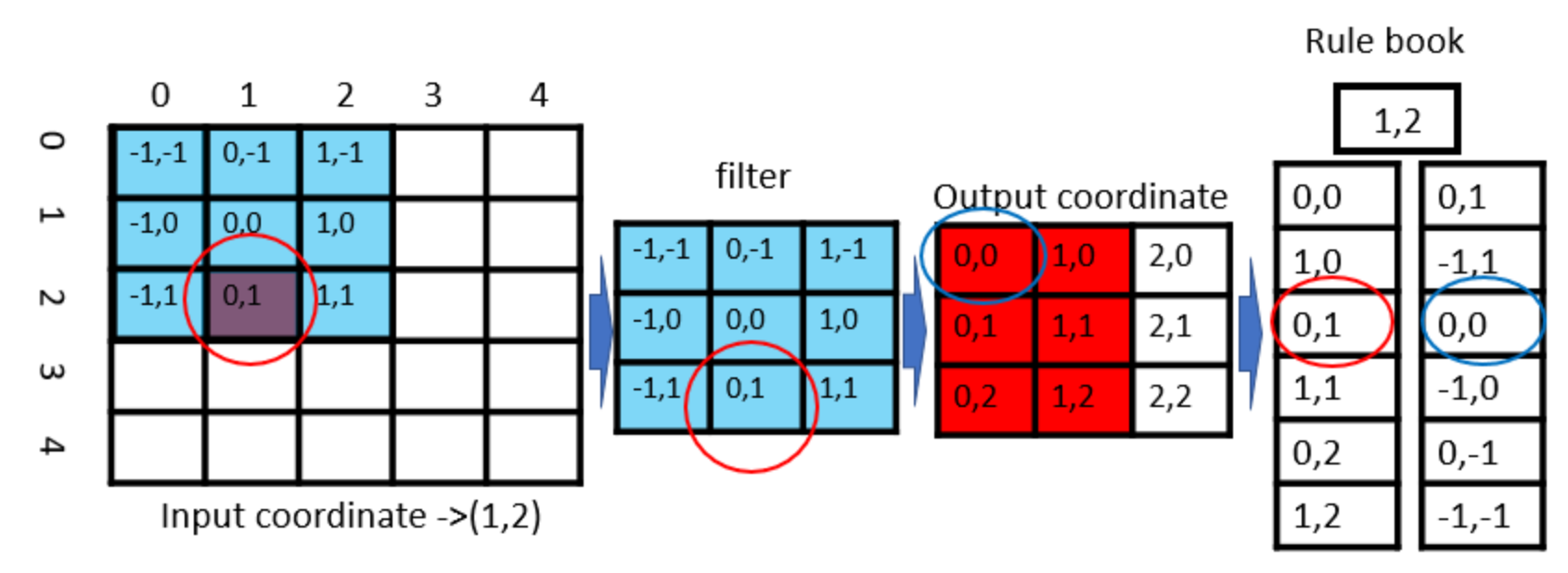
맨 왼쪽 input coordinate에서 빨간색 동그라미 부분인 (1,2)에만 어떤 정보가 존재하는 영역이고 다른 영역은 정보가 존재하지 않는 영역이다. 그림에서처럼 5×5 input에 3×3 filter를 padding없이 적용하면 3×3 output을 얻게된다. 5×5 input 중 정보가 존재하는 영역은 (1,2)하나뿐인데 전체 영역에 cnn을 적용하는 것은 많은 시간을 필요로하고 비효율적인 방식이라는 것은 직관적으로 이해가 될 것이다. 결론적으로 말하자면 sparse convolution에서는 그림 맨 오른쪽과 같이 rule book이라는 것을 생성하게 된다. rule book은 정보가 존재하는 input에 대해, filter의 어떤 부분이 output의 어떤 부분의 영향을 주는지 관계를 나타낸 것이다. 예를 들자면 input의 (1,2)는 첫 번째 cnn연산을 통해 filter의 (0,1)부분과 convolution연산을 하게되고 그 결과는 output coordinate (0,0)값에 영향을 주게 된다. 그리고 filter가 이동하여 다음에는 input의 (1,2)가 filter의 (-1,1)과 연산을 하게되고 그 결과는 output coordinate (1,0)에 영향을 주게된다. 또 옆으로 이동하면 input의 (1,2)는 filter와 연산되지 않는다. 이런 과정을 반복해서 input 영역 전체에 대해 filter와 cnn연산을 수행하게 되면 input coordinate에서 정보를 가지는 (1,2)는 (0,1),(1,0),(0,1),(1,1),(0,2),(1,2) 이렇게 6개 output coordinate에 영향을 미치게되는 것을 알 수 있고 총 6번의 계산을 통해 feature를 추출할 수 있게 되는 것이다. 이러한 sparse convolution연산을 통해 획기적으로 convolution 연산 시간을 줄일 수 있다.
Generative Sparse Detection Network
이제 논문에서 제안하는 generative sparse detection network의 구조를 알아보자. network전체에서 sparse tensor로 3d representation했고 convolution이나 batchnorm과 같은 모든 Layer가 sparse tensor연산을 위한 minkowski convolution으로 사용되었다. network는 크게 hierarchical sparse tensor encoder와 generative sparse tensor decoder 두 부분으로 나눠진다. hieerarchical sparse tensor encoder는 object의 geometr정보를 capture하기 위해 sparse tensor feature map을 생성하고 generative sparse tensor decoder는 생성된 feature map을 기반으로 object proposal을 한다. 전체 architecture는 아래 Figure 3과 같다.
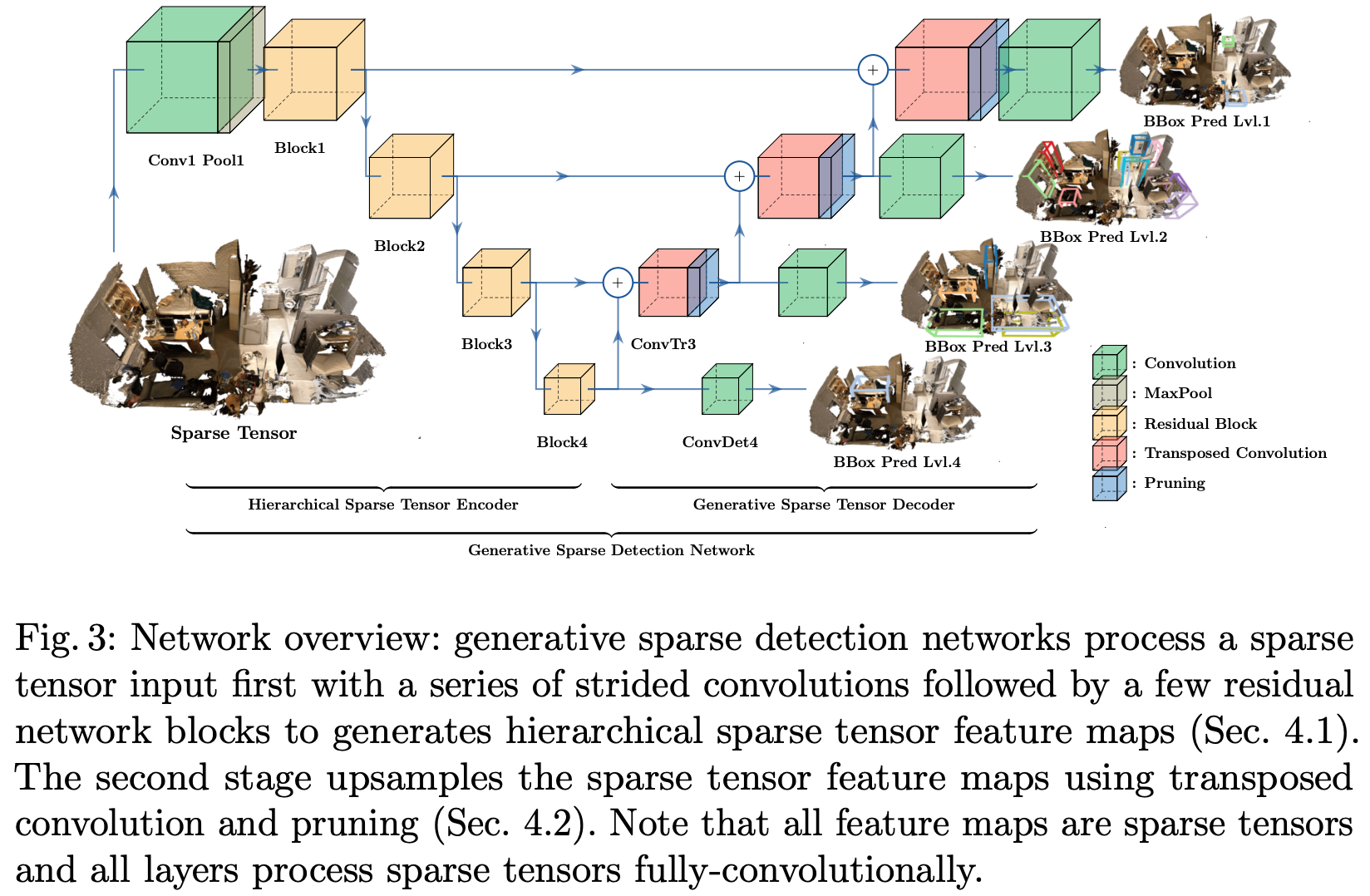
Hierarchical Sparse Tensor Encoder
Figure 3에 왼쪽부분에 해당하는 Hierarchical sparse tensor encoder는 backbone으로 residual network를 사용했다. 뒤에서 실험할 때 Resnet34를 사용했다고 한다. network는 space의 resolution을 줄이고 receptive field size를 증가시키기 위해 strided convolution을 사용한 residual block으로 구성하였다. network는 Input으로 high resolution의 sparse tensor를 입력으로 하여 downsampling과 residual blocks fl(·;Wl) for l ∈ [1, …, L]을 통해 hierarchical feature map을 생성하게 된다. encoder의 과정은 아래와 같이 수식으로 나타낼 수 있다.
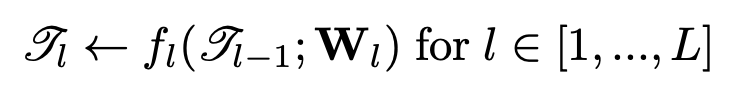
이렇게 얻은 hierarchical sparse tensor feature maps는 뒤에 Generative sparse tensor decoder를 통과하게 된다.
Generative Sparse Tensor Decoder
Figure 3의 오른쪽 부분인 generative sparse tensor decoder는 transposed convolutions를 이용해 hierarchical sparse tensor feature maps에서 bounding box anchor를 찾는 역할을 한다. 여기서 transposed convolution은 흔히 아는 upconvolution, deconvolution과 동일하다. input sparse tensor가 transposed convolution을 통과하고 output sparse tensor를 생성했을 때, 모든 voxel에서 object bounding box anchor를 생성하지는 않기 때문에 연산량을 고려하여 이러한 Voxel은 제거를 해줘야하는데 이 과정이 sparsity pruning이다. transposed convolution뒤에 sparsity pruning과정을 추가하여 반복하면서 space의 resolution을 증가시키고 메모리 연산량을 줄일 수 있도록 한다. 이 과정에서 hierarchical sparse tensor feature map과 upsample한 sparse tensor 간 skip connection을 통해 input의 Fine detail정보를 보존해준다.
Transposed Convolution and Sparsity Pruning
여기서는 hierarchical feature map에서 sparse tensor가 anchor를 생성하는데의 지원을 확장하기 위해 transposed convolution의 kernel size를 2보다 크게 설정하여 upsampling해준다. transposed convolution을 수식으로 표현하면 아래 수식(2)와 같다. C는 supp(sparse tensor)로 표현하는데 transposed convolution을 거친 feature로 이해하면 될 것같다.
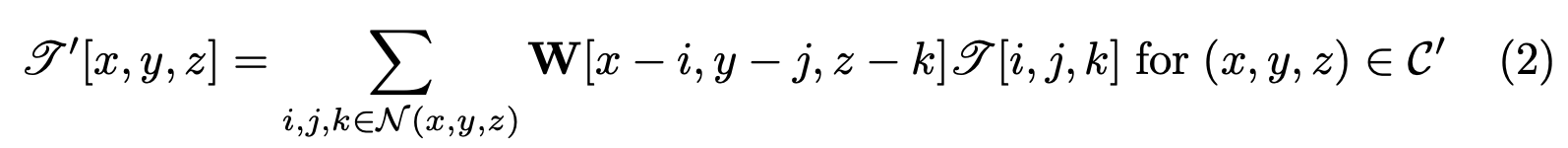
- C’ = C⊗[−K, …, K]3
- N (x, y, z) = {(i, j, k)||x−i| ≤ K, |y−j| ≤ K, |z−k| < K,(i, j, k) ∈ C}
- W : 3D convolution kernel weights
- 2K + 1 : convolution kernel size
이렇게 transposed convolution을 통과한 sparse points들은 더 넓은 영역을 포함하게 되어 Figure 4처럼 다양한 영역을 포함할 수 있다.
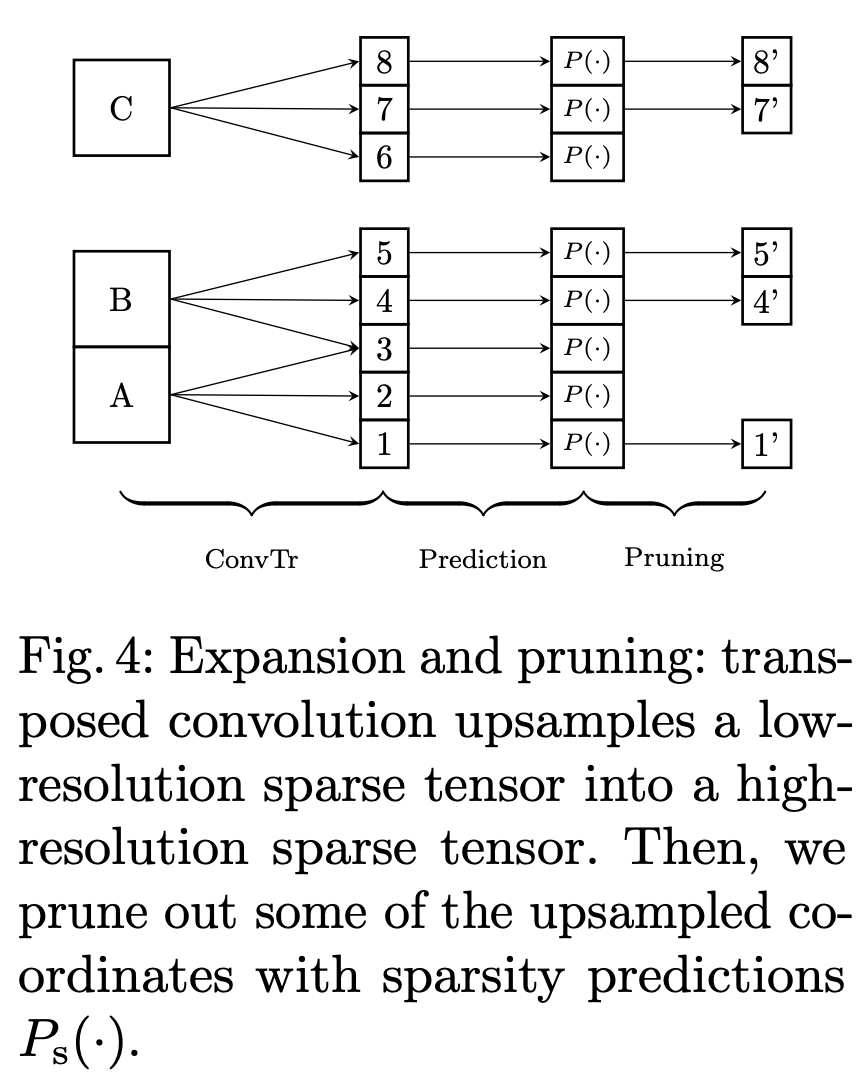
그리고 모든 coordinates들에서 object bounding box anchor를 포함하지는 않으므로 bounding box anchor를 가질 확률이 적은 voxel은 제거를 해주는 pruning과정을 거치게된다. 주어진 feature의 각 voxel Ps()에서 sparsity pruning confidence threshold τ보다 작은 voxel들은 제거를 해준다.
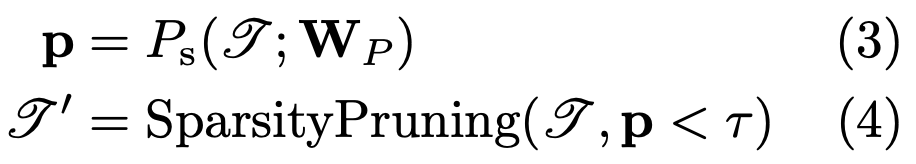
Skip connection and Sparse Tensor Addition
generative과정을 거친 upsample된 sparse tensor feature map은 더 넓은 영역의 context 정보를 얻을 수 있지만, input의 fine detail정보를 잃어버릴 수 있다. 이러한 fine detail정보를 회복하기 위해 skip connection을 추가하여 encoder로부터 feature map의 정보를 추가하게된다. upsample된 feature map과 low level feature map모두 sparse tensor이기 때문에 sparse tensor addition으로 더해준다.
Multi-scale Bounding Box Anchor Prediction
sparsity pruning을 통과한 모든 voxels들은 이제 bounding box anchor를 가지고 있을 것이다. voxel하나의 k개의 anchor box가 있다라고 하면 network는 object anchor likelihood score 1개, anchor box offet 6개(x,y,z,w,h.l), semantic class score c 이렇게 해서 총 (c+7)*k 의 output을 도출한다. 여기서 왜 z축 기준 회전인 rotation정보는 추정하지 않는지 의문이 들 수 있는데, 3d object detection에서 모두 rotation정보를 추정하는 것은 아니다. 크게 AABB(axis-align bounding box)와 OBB(oriented bounding box)로 나뉘는데 데이터셋에 따라 rotation이 없이 한 방향으로 annotation된 AABB의 경우 rotation 정보를 고려하지 않아도 된다.
이렇게 network가 bounding box parameter를 추정하는데 object는 다양한 크기를 가질 수 있다. 따라서 다양한 aspect ratio를 고려하여 anchor box를 생성한다. aspect ratio seed ar에 대해 아래와 같은 경우를 고려하여 총 k=13개의 anchor를 사용한다.
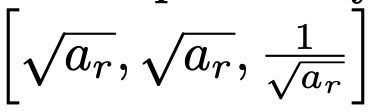
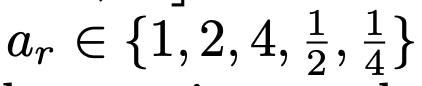
그리고 더 다양한 scale의 object를 포착하기위해 SSD모델처럼 decoder의 여러 stage에서 anchor를 예측하게 된다. anchor size는 이전 level의 2배로 증가시켰다고 한다.
GSDN의 전체적인 algorithm은 아래와 같다.

Losses
gsdn은 sparsity prediction, anchor prediction, semantic class, bounding box regression 이렇게 4가지 종류의 output을 예측한다. 원래 sparsity prediction과 anchor prediction은 binary classification loss를 적용하려고 했지만 많은 voxel에서 positive anchor를 많이 가지지 않기 때문에 positive anchor와 negative anchor가 imbalance하다는 문제가 존재한다. 따라서 저자는 balanced cross entropy loss를 제안한다.

P = {i|yi = 1}, N = {i|yi = 0}은 각각 positive, negative label을 의미한다. negative와 positive의 비율을 고려한 loss이다. anchor가 positive로 분류되는 기준은 어떤 voxel의 anchor가 gt box와 3d iou 0.35이상일 때이며 3d iou가 0.2보다 작은 경우 negative로 분류한다. 0.2와 0.35사이의 iou를 가지는 경우는 고려하지 않았다고 한다.
Lclass는 positive anchor에 대해 semantic class prediction과 gt bounding box class와 cross entropy loss를 사용했고 bounding box center와 offset regression은 Huber loss를 사용했다고 한다. huber loss는 L1 loss와 l2 loss의 장점을 살리고 단점을 보완하기 위해 제안되었다고 한다. 모든 지점에서 미분이 가능하며 outlier에 robust하다고 한다.
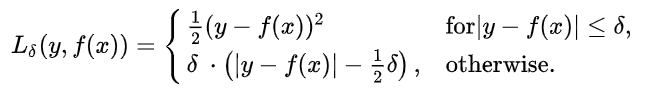
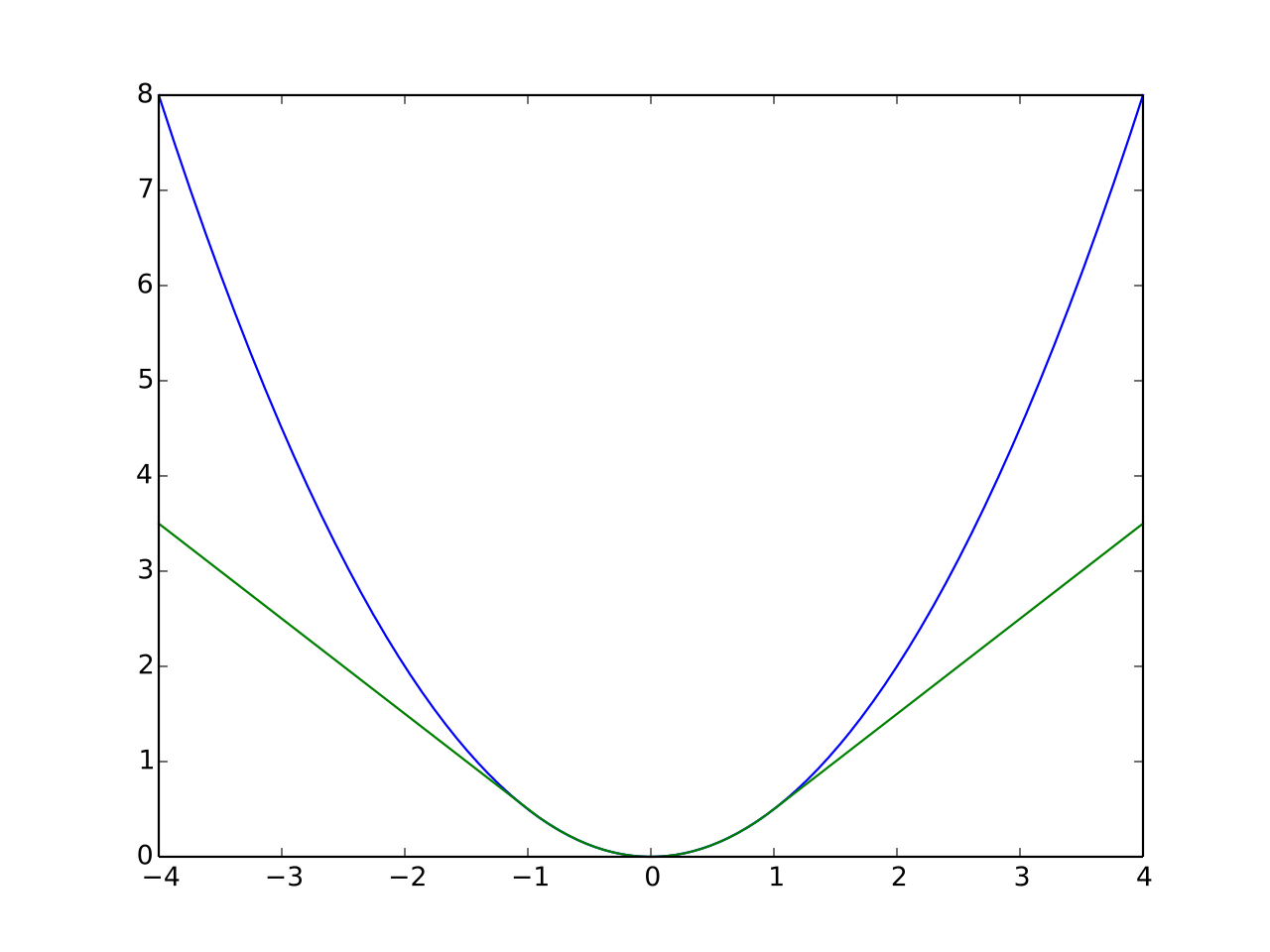
파란색이 l2 loss이고 초록색이 huber loss이다. -1,1사이에서는 l2 loss와 유사하고 다른 부분에서는 l1 loss와 유사한 형태를 보인다.
최종 loss는 아래와 같다.
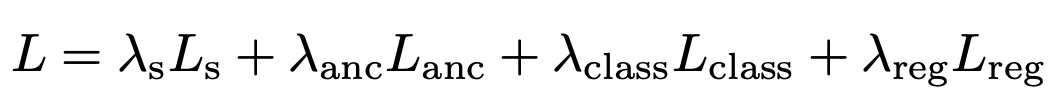
- λs = 1, λanc = 1, λclass = 1, λreg = 0.1
Prediction post-processing
학습하고 나서 3d iou가 0.35를 넘는 anchor box가 많이 생성될 것이다. 겹치는 box들에 대해 nms를 적용해주고 filtering을 해준다. 그리고 최종 Prediction을 미세조정하기 위해 yolov2(9000)에서처럼 제거된 모든 bounding box의 score를 가중 평균하여 합한다고 한다.
Experiments
scannet, s3dis(stanford large-scale 3d indoor spaces) 총 2개의 indoor dataset에서 평가를 수행하고 large-scale scene에서 좋은 결과를 보이는지 검증하기 위해 Gibson environment에서도 평가를 했다고 한다.
scannet의 경우 1500개의 indoor scene을 포함하며 18개의 class에 대해 평가를 했다. annotation은 rotation정보가 없는 axis align bounding box로 되어있다.
S3DIS(stanford large-scale 3d indoor spaces)는 6개 건물의 272개 room을 3d scan한 데이터로 floor, ceiling, 5개의 furniture class를 포함해서 총 7개 class를 포함한다고 한다. encoder backbone으로는 Resnet34를 사용했고 voxel size는 5cm, sparsity pruning confidencesms 0.3, 3d nms threshold는 0.2로 설정했다.
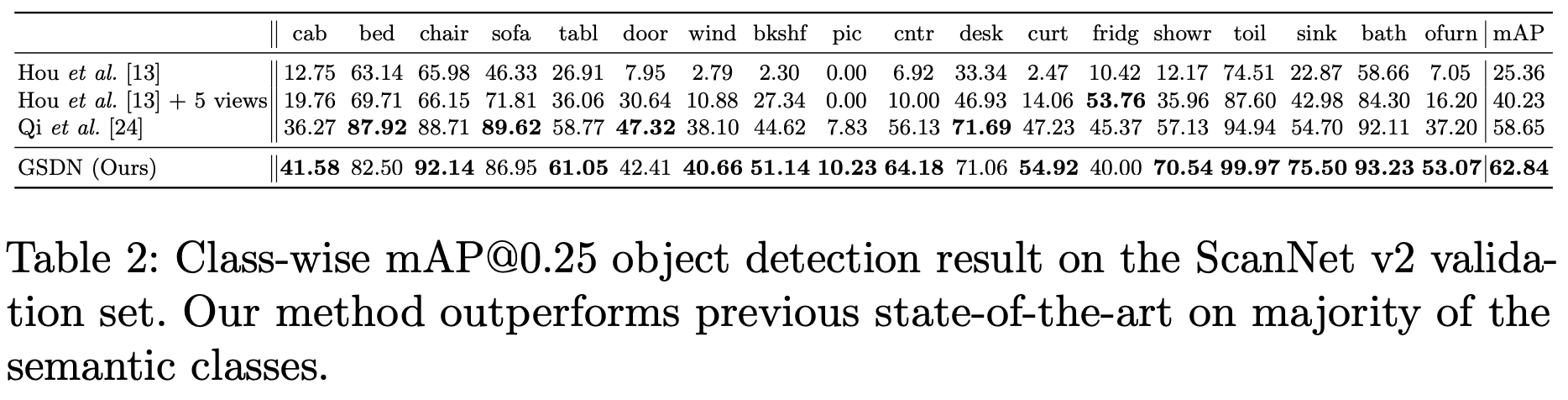
아래 Table 1을 보면 scannet 데이터셋에서 기존 다른 방법론들과 GSDN과의 성능 차이를 한 번에 볼 수 있다. single shot detector이지만 다른 방법론에 비해 4%정도 좋은 성능을 보이고 있다.

아래는 각 class별 ap를 나타낸 표이다. single shot인 경우와 그렇지 않은 경우 모두와 비교했을 때에도 대부분의 class에서 가장 좋은 정확도를 보인다.
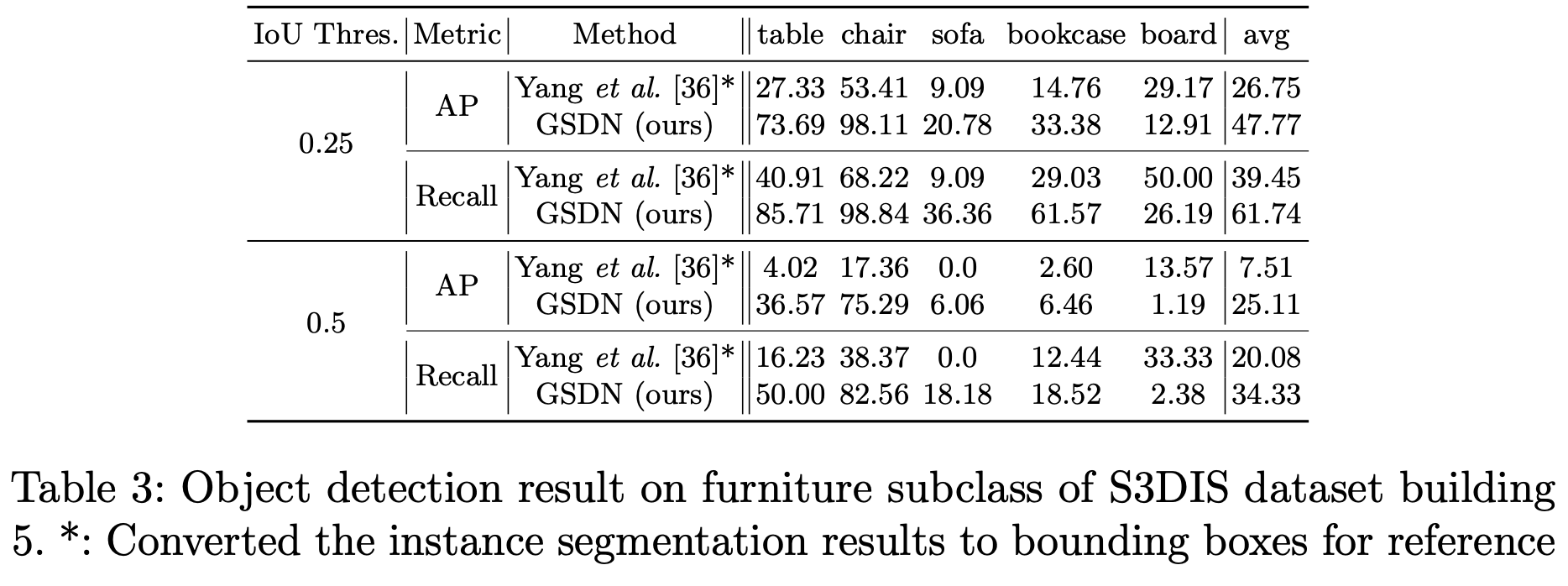
아래는 S3DIS 데이터셋에서의 평과 결과이다. Yang et al.[36]은 기존 방법론으로 scene을 crop하여 receptive field를 제한하고 속도가 느리다고 한다. 반면 gsdn은 전체 large scale의 scene을 input으로 한다. 결과적으로 정확도와 recall에서 모두 큰 성능 차이를 보여준다.
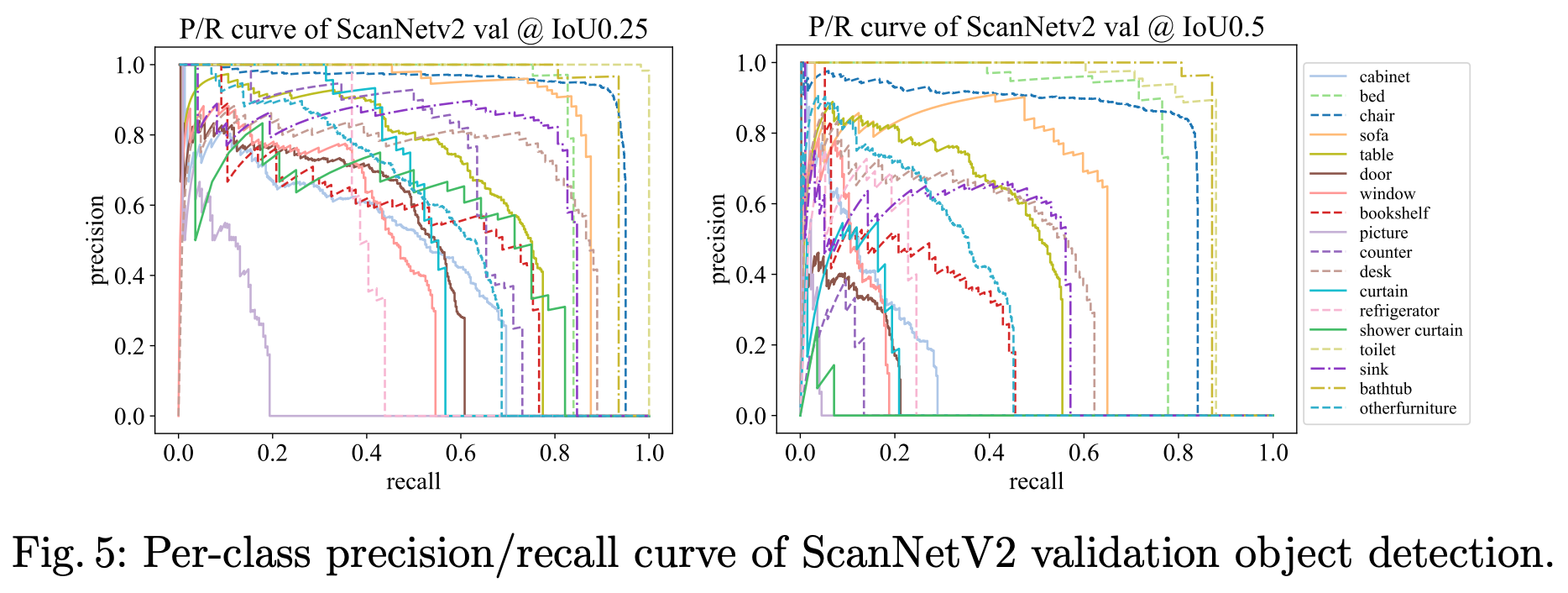
아래는 scannet dataset에서의 class-wise precision-recall curve를 시각화한 것이다. 몇몇 class의 경우 pr곡선이 급격이 꺾이는 것을 확인할 수 있는데 다양한 aspect ratio를 가지는 anchor가 생성될 때에도 한계가 존재하는 것으로 보인다.
아래 Figure 6은 scannet에서 평가한 결과를 시각화 한 것이다. 전체적으로 얇은 구조의 물체를 검출하는데 어려움을 가지는 것 같고 더 extreme한 anchor가 필요하거나 anchor free방식도 고려해보면 좋을 것 같다.

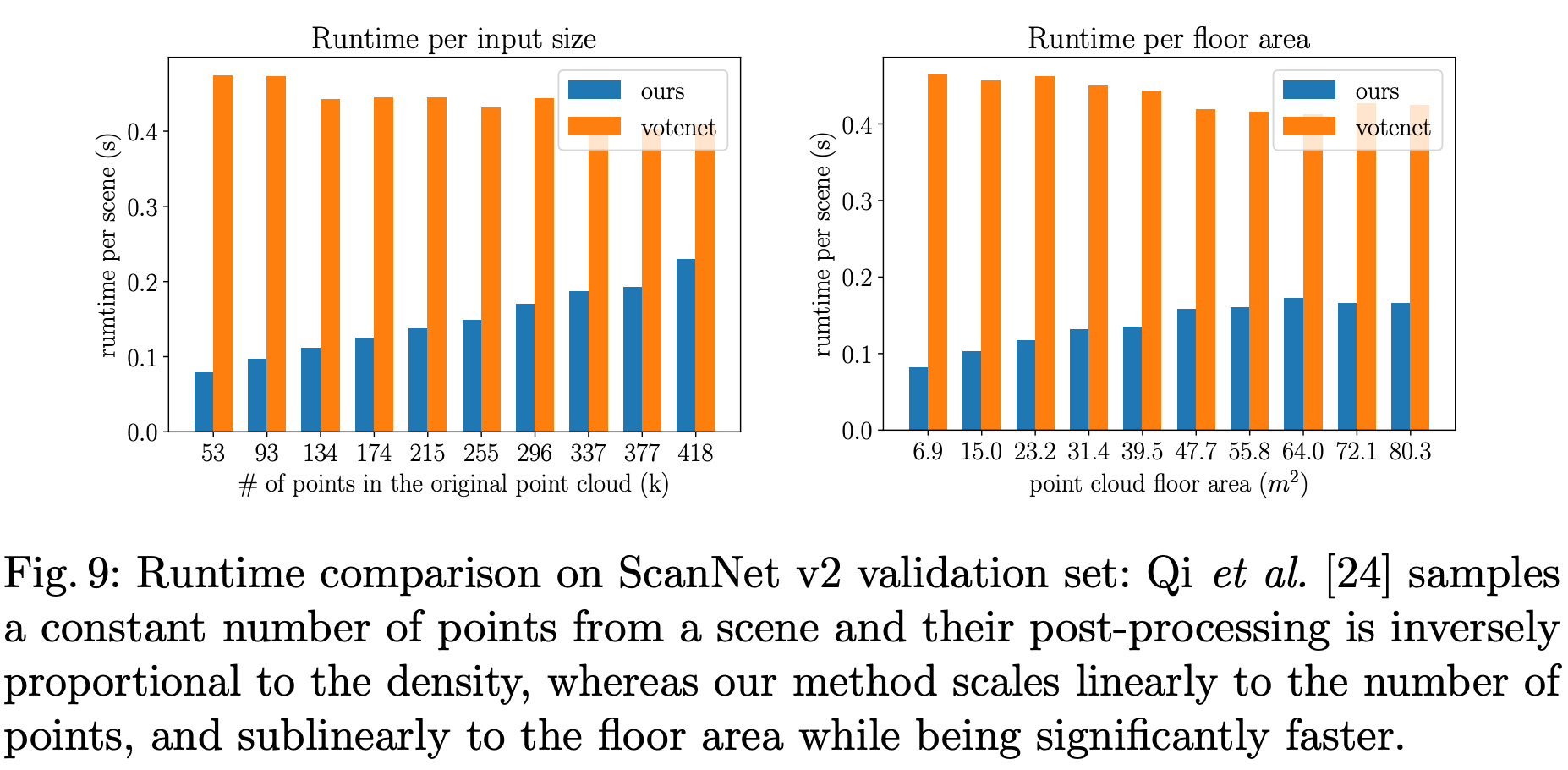
다음은 runtime에 대한 분석이다. network의 feed forward과정과 nms과정을 포함한 runtime이다. Ours인 gsdn은 평균적으로 0.12초가 걸린다고 한다. votenet의 경우에는 0.45초가 걸린다고 한다. 사실 여기서 의문이 드는 건 runtime을 왜 single shot 방법론과 비교하지 않고 votenet과 비교한지 잘 모르겠다. gsdn의 경우 point 수가 늘어남에 따라 linear하게 runtime이 증가한다. 하지만 votenet의 경우 input point cloud 크기의 관계없이 일정한 수의 point를 subsampling하다보니 높은 runtime이 유지되는 것을 알 수 있다.
마지막으로 large scale scene을 가지는 S3DIS dataset과 Gibson environment에서도 general하게 작동한다는 것을 보인다.


Conclusion
본 논문에서는 single-shot fully convolutional 3d object detection 모델인 GSDN을 제안했다. GSDN은 sparse tensor를 이용하였고 sparsity를 유지하면서 sparse tensor decoder를 통해 object center를 proposal한다. large-scale point cloud를 효율적으로 processing하고 3d indoor dataset에서 sota를 달성할 수 있었다. 저자는 마지막에 image detection을 추가로 활용하여 성능을 향상시킬 수 있는 방법에 대해 추후 연구하겠다고 하며 마친다.
좋은 리뷰 감사합니다.
리뷰의 앞부분에서 해당 논문의 장점이 불필요한 object center를 줄일 수 있다고 하셨는데, 불필요한 object center란 Generative Sparse Tensor Decoder에서 제거하는 voxel을 의미하시는 것인가요?? 해당 과정은 즉, 배경영역의 정보를 줄이는 것으로 이해하면 되나요??
또한, class-wise precision-recall curve 그래프를 보면 클래스에 따라 경향이 달라지는 것 같은데, 한계가 존재하는 경우에 해당하는 클래스들의 특징이 무엇인지 분석이 있는지도 궁금합니다.
댓글 감사합니다.
불필요한 object center를 제외한다는 것이 fig 4에 나타난 것처럼 generative sparse tensor decoder에서 transposed convolution을 거쳐 upsampling된, 더 넓어진 영역에서 voxel마다 bounding box anchor를 가질 확률이 적은 voxel을 제거한다는 뜻으로 말씀하신 내용과 같습니다.
정량적, 정성적 평가를 함께 고려해보았을 때 picture, window와 같은 얇은 물체들에 대한 검출이 어려운 것으로 보입니다.