INTRO

본 논문은 Domain adaptation 문제를 효율적으로 해결하기 위해 Active Learning 을 적용한 논문이다. Domain adaptation이란 어떤 테스크 A에 대해서 특정 도메인으로 학습된 모델을 같은 테스크를 갖는 다른 도메인의 문제를 해결하도록 학습하는 방법론으로, 기존에 모델이 작동하는 도메인을 소스 도메인(Source domain, S), 이동하고자 하는 도메인을 타겟 도메인(Target domain, T)라고 한다.
S에서 T로 모델의 작동환경을 이동하기 위해 T 도메인에 속하는 unlabeled data, 즉 비가공 데이터 중 어떤 데이터를 이용해야 할 지를 Active Learning 방법론을 통해 선별한 분야가 Active Domain Adaptation(ADA)이다. 여기서 도메인이란 하나의 속성을 취하는 집합을 의미하며 Figure1의 2열(실사), 3열, 4열(추상화된 그림), 5열은 각각 도메인이 다르다고 볼 수 있다.
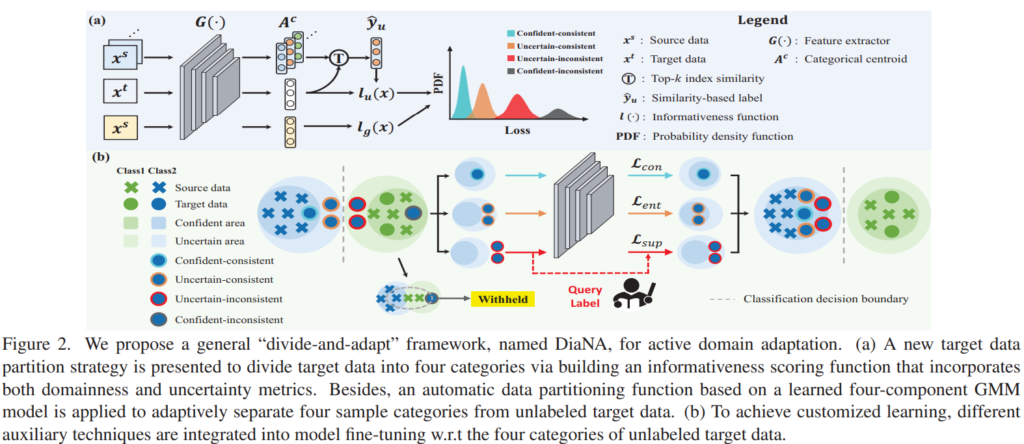
본 논문은 target domain을 포함하는 unlabeled datapool을 figure1의 분류처럼 4 타입(confidence-consistenct, uncertain-consistent, uncertain-inconsistent, confident-inconsistent)으로 나누어 각 타입을 learning stage에 차등적으로 활용한다. 제안하는 프레임워크 “divide-and-adapt(DiaNA)”는 제안하는 접근법을 통해 Domain Adaptation 문제에 다양화된 해법을 제공하였다.
METHOD
Problem formulation.
S: labeled된 기존 소스 도메인
U: unlabeled 상태(미가공)인 Target domain 데이터
T: Active Learning을 통한 데이터 가치평가로 인해 선별되어(iteratively queried) 라벨링(가공)되는 고가치 데이터
Active Learning process를 통해 U 에서 예산(B)만큼 T를 선별하여 가공해 S에 포함시킨다.
Figure2를 통해 간단하게 프로세스를 소개하면 GMM 모델을 통해 unlabeled data를 4 Type:confident-consistent (CC), uncertain-consistent (UC), uncertain-inconsistent (UI), confident-inconsistent (CI)으로 분류하여 모델 학습에 적절히 사용한다. 모델의 학습을 위해서는 3가지 loss가 사용되는데, 모델의 정확한 확률분포 예측을 장려하기 위해 GT를 사용하는 superivsed loss와 self-supervised learning 분야에서 주로 사용하는 consistency loss, 예측에 대한 entropy를 낮추어 안정적인 예측을 할 수 있는 모델로 학습하기 위한 entropy loss로 구성된다. 제안하는 방법론은 가장 확신도가 높고 안전하다고 판단되는 데이터인 CC는 unlabeled 상태에서 학습에 이용하도록 consisteny loss에 활용하며, 예측에 대한 일관성은 있지만 확신도는 낮은(편향되어 학습했지만 노이즈는 아닌) UC 데이터는 예측된 확률분포의 entropy를 줄이기 위한 entropy loss를, 확신도도 낮고 일관성도 없는, 모델이 거의 처음본다고 판단되는 데이터에 대해서는 고가치 데이터로 선정하여 라벨링을 진행하고 supervised loss에 활용한다. 위와 같은 방식으로 unlabeled pool에서 적절한 target data를 선정하여 domian adpatation을 위한 학습을 할 수 있으며 labeleing 할 target domain의 데이터를 최소화 할 수 있다.
Informativeness Scoreing Mechanism.
기존 ADA 접근법들은 보통 uncertainty와 domainness를 기준으로 Target data 중 고가치 데이터를 선별하였다. 제안하는 논문은 기존 접근법들을 더욱 개선하기 위해 1) labeled samples을 활용하여 unlabeled data의 카테고리를 추정하여 사용하며, 2) uncertainty와 domainness를 하나의 메트릭스인 informationness로 측정하여 사용한다.
- Categorical centroids
categorical centroids는 제안하는 논문이 위의 1)의 방법론이다. 논문에서는 feature들이 임베딩 된 latent space 상의 category prototype을 찾기 위해 labeled samples를 활용하여 그 평균값을 사용한다. 아래 수식1에서 G(x)가 feature extractor이며 x가 입력 이미지, l함수는 지시함수로 class c에 대한 category prototype을 찾기 위한 필터링 함수이다. (조건에 맞으면, y가 c와 같으면 1/ 아니면 0)
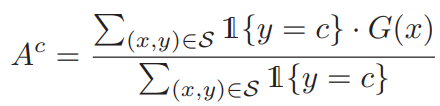
- Similarity-based data label
unlabeled data에 대해서 유사도 기반으로 label을 생성하기 위해 위의 방식으로 만든 categorical prototype을 이용했다. 유사도 계산을 위해 latent space 상의 magnitude기반으로 정렬한 feature를 이용했다. magnitude로 정렬한 임베딩 feature G(x)의 label을 할당하기 위해 수식2를 활용했다. topk(G(x))는 정렬한 list에서 G(x)와 가장 가까운 k개를 의미하 c클래스에 속하는 feature 중 Ac에 가장 가까운 feature k개를 Topk(Ac)라 하며 IoU는 두 인자의 index list간의 겹치는 정도를 의미한다. 가장 많이 겹치는 class c가 x의 label이 된다.
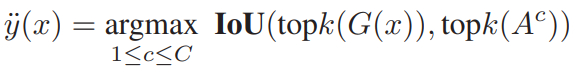
- Informativeness function
데이터 선별을 위해 본 논문은 uncertainty와 domainness를 포함한 새로운 지표 informativeness를 제안하였다. 제안하는 informativeness function(InfoF)는 아래 수식3과 같다. l은 앞선 수식1과 같은 지시함수이며 위의 방식으로 unlabeled data에 할당한 data label을 활용한다. P(x)는 x에 대해 클래스 c로 예측한 확률분포 예측(probabilistic prediction)값이다. unlabeled data sample에 대한 predicted class와 similarity-based label에 따라 2가지 타입으로 크게 나눌 수 있는데 이는 다음과 같다: consistenct 와 inconsistent 또한 prdiction score에 따라 (thresholding을 통해) 두 가지로 나눌 수 있다: confident samplies 와 uncertain samples. 이를 조합하여 본 논문은 target domin에 속하는 unlabeled data를 (앞서 소개한)4가지 타입으로 나눌 수 있다: confident-consistent (CC), uncertain-consistent (UC), uncertain-inconsistent (UI), confident-inconsistent (CI).
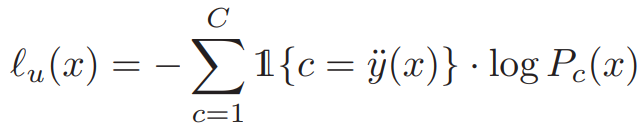
- Informative Sampling Function

CC, UC, UI, CI의 분류를 예측하는 모델을 학습하기 위해 Gaussian mixture model (GMM) 을 이용하였으며 학습에는 labeled sample을 이용하였다. 예측을 위한 입력값은 위의 수식 3과 같으며, 차이점은 labeled data를 이용했으므로 데이터 x에 대한 Similarity-based data label(y..)이 아닌 실제 label인 y를 사용했다. 이를 입력으로 하여 학습한 GMM 모델의 output인 P(l)을 통해 수식5와 같은 방식으로 분류했다. 이때 1이 CC, 2가 UC, 3이 UO, 4가 CI가 된다.
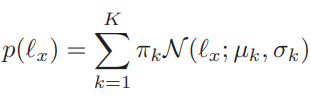
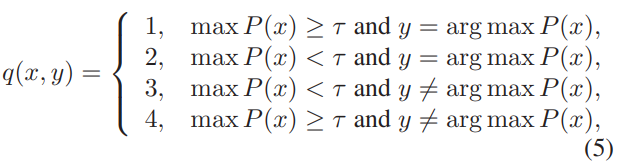
training objectives
모델 학습을 위한 최종 목적함수는 supervised loss와 consistency regularization, entropy loss 로 구성된다. supervised loss(L_sup)는 예측 확률분포를 학습하는 일반적인 classification task를 위한 loss와 같다. consistency regularization은 similarity label을 기반으로 autoaugmentation[2]을 통해 augmentation 된 값이 기존 x를 통해 예측했던 similarity label값과 같도록 유도하며 이는 기존 self-supervised learning에서 주로 사용했던 loss와 유사한 역할을 한다. 마지막으로 entropy loss는 최종 예측된 확률분포의 entropy를 최소화하여 one-hot 벡터와 같이 확신도 높은 예측을 유도하기 위한 loss로 사용되었다. 각 목적함수는 가중치 합을 통해 최종 목적함수에 반영된다.
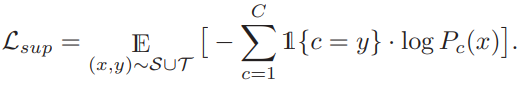

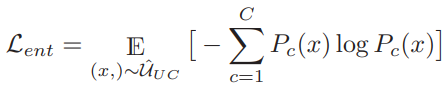
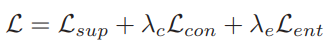
EXPERIMENTS
- Main Results
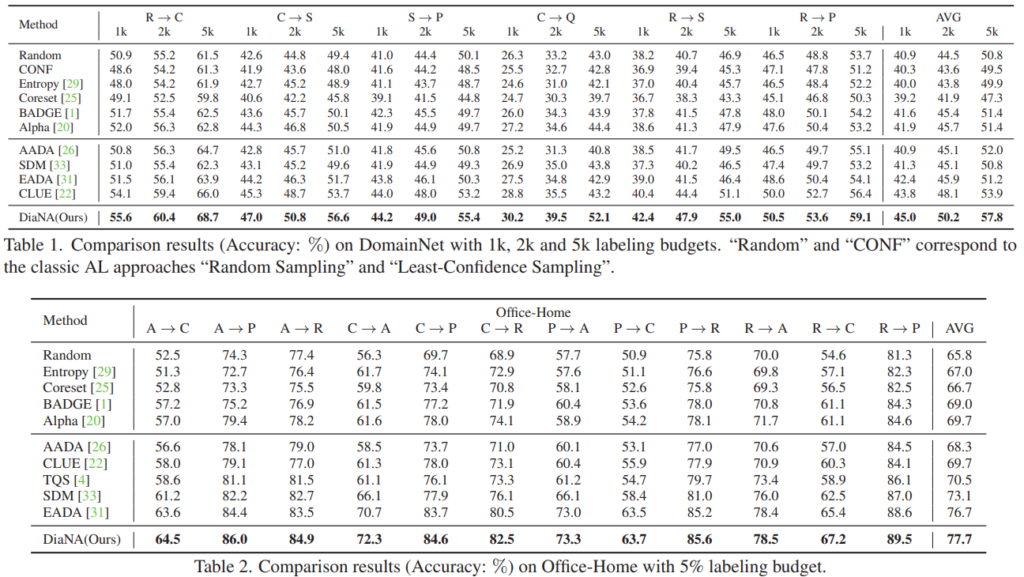
위의 Table 1, 2는 DA 분야에서 주로 사용되는 데이터셋(DomainNet, Office-Home)에 대한 SoTA 모델과의 비교 성능이다. 제안하는 방법론이 기존 방법론에 비해 우수한 성능을 보임을 위 벤치마크를 통해 증명하였다.
- Ablation study
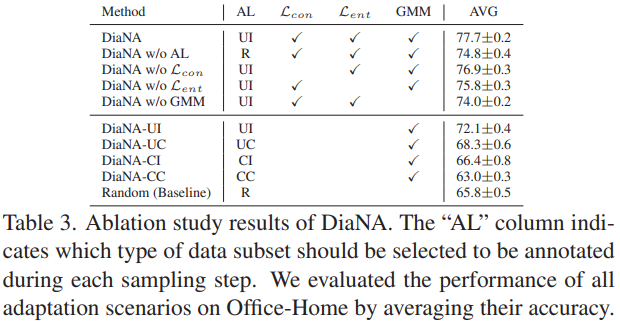
DiaNA의 각 요소들의 효과를 증명하기 위한 ablation study는 위와 같다. 표에서 확인할 수 있듯이 제안하는 모든 요소(Sampling 전략의 사용 유무, 목적함수의 구성, GMM을 통한 4가지 분포분류 사용 유무)가 모델의 정확도를 개선하는데 기여하였다. 또한 unlabeled data 의 4가지 분류 중 하나만을 사용하였을 때 보다 모두 사용하였을 때 성능의 개선되었음을 알 수 있다. (sampling 전략:UI, R, UC, CC에서 R은 렌덤을 의미한다)
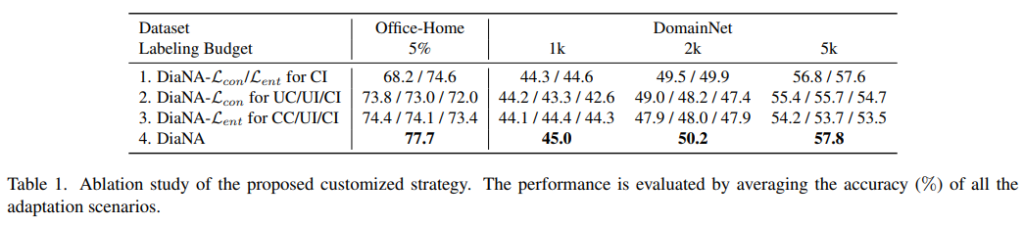
또한 UC/UI/CI/CC 에 대한 학습 사용 전략의 ablation study를 진행하였으며 DA Task에서 어떤 unlabeled data를 고가치데이터로 판별해야하는지 인사이트를 주었다. 위 실험에서는 (당연하게도)모두 사용하는것이 가장 좋으며 confident-consistent (CC)가 포함되면 꽤 좋은성능을 보임을 확인할 수 있다.
- UDA/SSDA/SFDA와의 비교
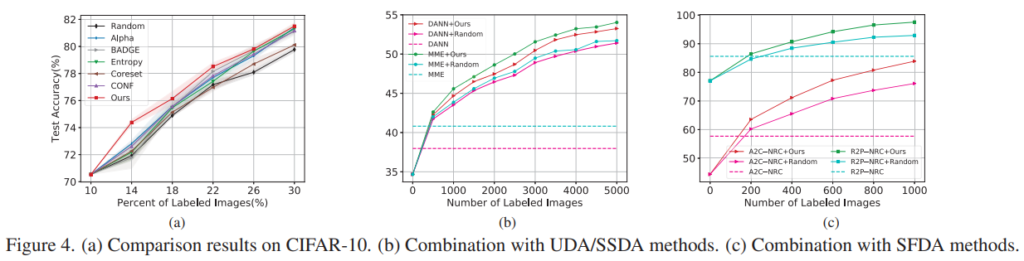
본 논문에서는 Active Learning 전략의 이점을 보이기 위해 CIFAR10에 대한 AL 적용실험(a)과 기존 DA 분야의 아키텍쳐인 UDA/SSDA/SFDA에 제안하는 AL sampling 전략을 접목하여 이루어낸 성능 개선 효과 (b), (c)를 리포팅하였다. (a)는 CIFAR10이라는 단일 도메인 데이터셋을 이용하여 Domain Gap 이 매우 적거나(실제적으로는) 없지만(이론적으로는), 비교한 방법론(다만 최신방법론은 아님)들에 비해서는 높은 성능을 보임을 리포팅했다. Domain Gap의 효과를 동일 데이터셋 내에서 극대화하기 위해 fewer labeling budget setting(매 iteration마다 추가되는 데이터셋 양이 매우 작음)을 사용하였다. AL 방법론 자체의 이점에 대해서는 확인하기 어려우나, DA 분야에 적용하였을때 개선의 효과가 있음을 알 수 있다.
안녕하세요. 황유진 연구원님. 리뷰 잘 읽었습니다.
그럼 이 TASK에서 모델은 원본 데이터로 지도학습된 모델을 이용하는건가요?
실험중에서 pretrained 모델이 아니라, 원본 모델에서부터 active learning을 이용해 학습을 수행한 결과는 없나요?
데이터의 가치판단을 위한 평가 모델은 labeled data를 통해 지도학습방식으로 학습됩니다.
원본 모델이 의미하는 바를 정확히 이해하지는 못했으나, 데이터 가치판단을 시도하는 도메인에 속하는 소량의 labeled data 로 지도학습 방식으로 학습한 모델을 통해 active learning에서 데이터 선별을 진행하는것이 일반적 입니다.
안녕하세요 황유진 연구원님 좋은리뷰 감사합니다.
Domain Adaptation with Active Learning 이 바로 저희가 다크데이터 과제에서 궁극적으로 나아가야할 방향이지 않을까라는 생각이 항상 기저에 깔려있어, 흥미롭게 읽었던 것 같습니다.
인상깊었던건 테이블 3에서의 UI 성능인데요. UI가 제일 높은 성능을 보인다는 소식이 어쩌면 기쁜 소식이 아닌가 싶습니다. 실험을 하면서 어려운 데이터를 고르는게 좋은 기준이 맞을까? 하는 의구심이 있었거든요 (물론 태스크가 달라서 확답하긴 어렵지만요..)
그런데 갑자기 궁금한 게 … 저자는 왜 하필 Gaussian mixture model (GMM) 을 사용한걸까요? 기존 연구에서 해당 모델을 사용한 AL 이 있었을까요?
기존 연구중에 GMM을 사용하는 방법론을 소개하는 논문을 리뷰해 본 적이 없네요?
다만 GMM을 이용한 이유에 대해서는 labeled data를 다양한 카테고리로 나눌때 이분법적인 분류를 이용하기 보다 분포기반으로 분류하도록 하여 이분법적으로 분류 시 발생할 수 있는 위험을 줄이기 위한것으로 저는 이해했습니다. 감사합니다