Active Learning 논문 작업에 베이스라인으로 삼은 연구에 대한 수학적 분석을 시도했다는 워크샵 논문을 리뷰해보려고 합니다.
다만 오늘의 리뷰는 다소 선택적(???) 으로 리뷰할 것 같습니다. 해당 논문은 Learning Loss 라는 Active Learning의 근본 방법론을 Human pose estimation 에 맞춰 제안한 것입니다. 그러나 제가 관심있는 것은 Human pose estimation이라기 보다는… Learning Loss라는 모델과 데이터를 어떻게 분석했는지이다 보니… 다소 Learning Loss에 초점을 맞춰서 리뷰가 진행될 것 같습니다. 바로 시작해보겠습니다.

- Paper: [CVPRW 2021] A mathematical Analysis of Learning Loss for Active Learning
- Author Video: None
- Code: None
Background (About Learning Loss)
우선 해당 리뷰를 이해하기 위해서는 Learning Loss에 대한 이해가 반드시 선행되어야 합니다. 따라서 본격 리뷰에 들어가기 앞서, 이번 파트에서는 Learning Loss (이하 LLoss) 에 대해 설명드리겠습니다. (*참고로, Learning Loss 에 대한 상세한 리뷰는 일전에 조원 연구원이 다룬 적 있으니 더 자세한 내용이 궁금하신 분을 위해 링크를 옆에 걸어두도록 하겠습니다. – 조원 연구원 LLoss 리뷰)
Active Learning 은 정말 단순하게 말하자면, label(GT) 이 없는 dataset에서 가장 성능을 올릴 수 있는 하위 데이터셋을 선택하는 모델 연구 라고 할 수 있습니다. 그렇게 선택한 하위 데이터셋의 GT는 사람(라벨러)에게 얻고나서, 그 데이터와 GT 를 가지고 학습한 모델은 성능이 좋을 것이다 라는 입장이 기저에 깔려있죠. 그러나 하위 데이터셋을 선별할 때 Label 정보 (GT)를 사용할 수 없기 때문에, 성능을 가장 높일 수 있는 데이터를 찾는 것은 사실 굉장히 어려운 문제로 전락해버립니다. 아마 이러한 이유로 Active Learning 연구가 활발히 진행되지 못하고 있는 것이 아닌가 싶습니다.
기존 연구자들은 다양한 방식으로 성능을 가장 높일 수 있는 데이터를 찾고자 하였습니다. 가령 모델이 어려워하는 데이터를 선택하는 것이 성능 향상에 큰 도움을 줄 것이라는 기준이 제안되었는데, 모델이 어려워하는 것은 곧 예측값의 신뢰도가 낮은 데이터라는 뜻이기에.. 그런 신뢰도가 낮은 데이터를 선택하는 방식으로 접근하기도 합니다. 이게 불확실성 (uncertainty) 기반의 Active Learning 연구입니다. 또 다른 시각에서는 전체 데이터셋을 커버하는 하위 데이터셋을 선별해야 성능을 올릴 수 있다고 주장합니다. 후자가 다양성 (diversity) 기반의 Active Learning 연구입니다.
이렇듯 가장 유용한 하위 데이터셋을 고르는 기준이 바로 Active Learning 의 핵심 설계 파트라고 할 수 있는데요. 제가 지금 소개하려는 연구는 유용하다는 척도로 Loss를 활용하였습니다. 우리가 모델을 학습할 때 사용하는 Loss는 예측값이 정답값과 얼마나 차이가 나는지를 의미합니다. 따라서 어떤 이미지 x에 대한 Loss가 높다면, 학습한 모델은 이미지 x에 대한 예측이 정답값과 다르다는 것을 뜻하죠. 이 때 충분히 학습이 된 모델에서도 특정 이미지에 대한 Loss가 높다면, 모델은 그 특정 이미지를 어려워한다고 해석할 수 있는 것이죠. 이러한 이유로 저자는 유용한 데이터를 선택하는 기준으로 Loss를 선택하였습니다. 즉, Loss가 높은 순서대로 하위 데이터를 선택하는 것이죠.
그런데 이에 대해 ‘그걸 어떻게 해?’ 라는 식으로 의문이 생기셨다면, 제대로 이해하고 계신 것입니다. 제가 서두에서 Active Learning 은 **label(GT) 이 없는 dataset**에서 가장 성능을 올릴 수 있는 하위 데이터셋을 선택하는 모델 연구 라고 정의를 했기 때문이죠! Loss를 구하기 위해서는 당연히 정답값이 있어야 합니다. Loss는 정답값과 모델의 예측값 사이의 차이인데, 데이터를 선택할 때에는 모델이 GT에 접근할 수 없습니다. 그렇다면 저자는 어떻게 unlabeled dataset에서 loss를 구하였을까요?
바로 Loss를 예측하는 모델 사용하였습니다. 생각보다 간단하죠? 이 네트워크를 저자는 Loss prediction module 이라고 불렀습니다. 결국 이 Loss prediction module은 어떤 이미지를 넣었을 때 해당 모델이 발생할 수 있는 target loss 예측값을 반환합니다.
그럼 그 Loss prediction module은 어떻게 학습할까요? 즉, Loss prediction module의 Loss는 어떻게 구할까요? GT가 있어야 할텐데 말이죠. 이 역시 간단한데, Target Task 를 학습하면 그 때 Loss 가 발생합니다. 그럼 그 Loss를 GT로 사용합니다. 말이 반복되니 무슨 소린지 이해가 잘 안가실거 같은데요.. 아래 그림을 보시면 아주 명쾌하게 이해가 되실 겁니다. 여기서 Target은 사용자가 원하는 Task 를 의미합니다. 가령 classification, object detection 등등 태스크에는 제약이 없습니다. Loss가 있는 그 어떤 방법론이든 다 붙힐 수 있습니다.
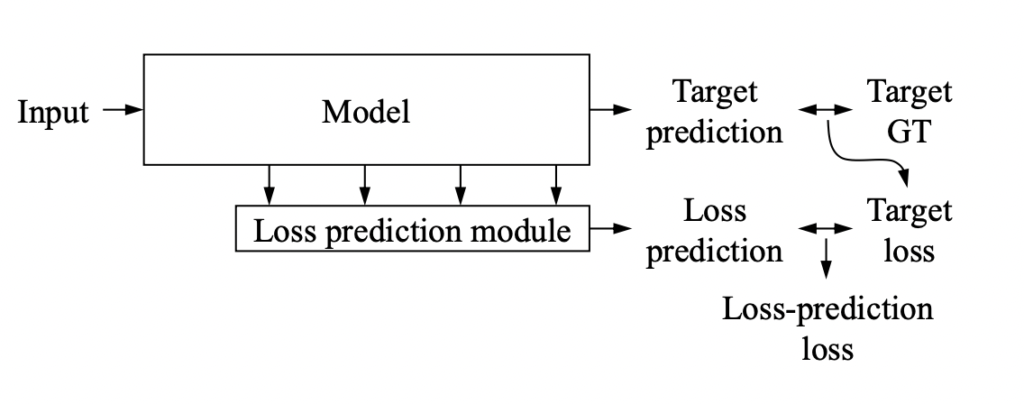
게다가 이 Loss를 예측하기 위해 설계된 네트워크는 메인이 되는 태스크의 Backbone에서 브런치를 따서 설계되기 때문에, 별도로 학습할 필요가 없습니다. 이게 무슨소리냐? 예를 들어, classification task를 수행한다고 할 때, classification을 위한 모델과 Loss를 예측하는 모델이 별도로 존재하는 게 아닙니다. 아래 이미지를 함께 보시면 이해가 좋을 것 같은데요. Target prediction이 classification에 대한 예측값이 되겠습니다. 그리고 Model은 Classification을 위한 ResNet과 같은 백본 모델이겠지요. 그 바로 밑에 붙어있는 Loss prediction module이 Loss를 예측하는 네트워크인데, ResNet 블럭마다 발생하는 feature들을 따와서 가벼운 모델을 태우고 concat하는 방식으로 설계되었습니다. 어떻게 보면 multi-task model이라고 할 수도 있겠네요. 아무튼 여기서 중요한 건, Learning Loss에서 “Loss를 예측하는 모델은 별도로 존재하는 것이 아닌데다, target task가 무엇이든 간에 상관없이 백본으로부터 연결되어 설계될 수 있다는 점”입니다.
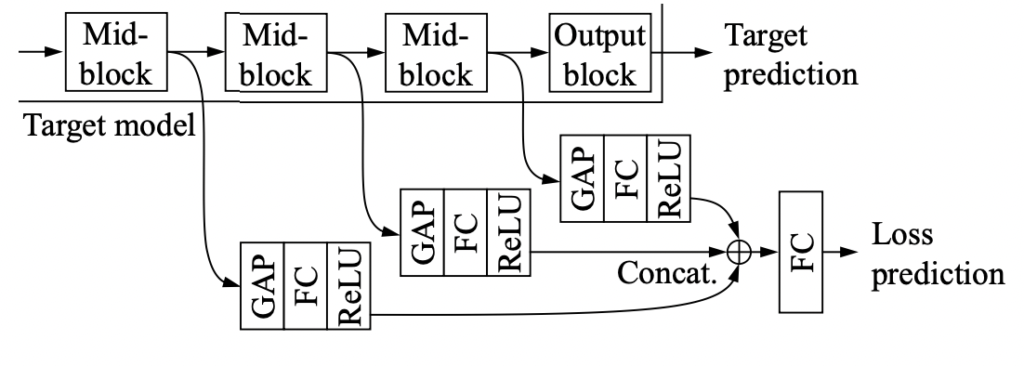
그렇다면 어떻게 모델이 구성되어 있기에 한번에 학습이 가능할까요? 아래 그림을 보시죠. 우선 target model 은 resnet으로 구성되어 있습니다. resnet의 각 블럭에서 나온 feature들을 따와서 GAP->FC->ReLU 와 같은 간단한 네트워크에 태운 뒤, CONCAT -> FC 태워서 Loss를 예측합니다. 이게 워낙 가벼운 네트워크라서 Task가 어떤 것인지 상관없이 중간 Feature를 사용한다는 점에서 아주 쉽고 간단하게 구현이 가능하며, main task와 동시에 학습이 가능한 것입니다.
그럼 이제 Loss prediction module의 Loss는 어떻게 정의될 지 궁금하실 것 같습니다. 여기서 중요한 건 저자가 loss를 직접 예측하는 방식으로 설계하지 않았다는 것입니다. 저자는 l_i l_j 간의 gap을 이용했다는 것입니다. 즉, pairwise loss gap을 예측하는 방식으로 설계한건데.. 왜그럴까요?
우리가 보통 모델을 학습할 때, 학습 초반의 Loss는 굉장히 큰 것을 보신 적 있을 텐데요. 그리고 학습이 진행되면서 Loss는 점차 작아집니다. Loss prediction module이 loss를 직접 예측하도록 학습을 하면, 그 값에 집중을 하는 것이 아니고 scale의 변화에 초점을 두고 학습이 된다고 합니다. 그로 인해 저자는 이미지의 pair를 구성하고 그 pair 사이의 loss 값의 gap을 예측하는 식으로 학습을 진행하였다고 합니다.
pred_loss = (pred_loss - pred_loss.flip(0))[:len(pred_loss)//2]
gt_loss = (gt_loss - gt_loss.flip(0))[:len(gt_loss)//2]
pair를 구성하는 방법은 같은 위에 있는 코드를 참고하면 더욱 이해가 편하실 것 같습니다. 한 배치 안에서 pair의 인덱스 합이 batch_size인 두 샘플이 서로 페어가 됩니다. 0번째 loss의 pair는 batch_size가 B라고 할 때, B-1번째 loss가 됩니다. 그리고 1번째는 B-2번째 loss 나머지는 동일하겠죠. Pair를 구성하는 방법 역시 알았으니 Loss를 설계하는 방식 역시 알아야 하는데요. 이는 아래 수식과 같습니다.
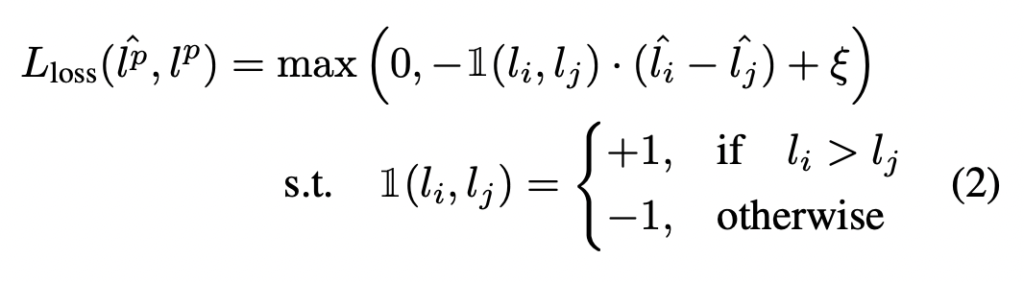
우선 실제 GT loss인 l_i, l_j가 있을 때, l_i > l_j 일 경우 pred_loss 역시 \hat{l_i} > \hat{l_j} 여야 합니다. 그래서 저자는 그런 경우가 아닌 그 반대 상황일 때 loss가 발생하도록 설계를 하였습니다. 정리하자면 margin을 사용한 Ranking loss 라고 할 수 있으며 수식 2가 지금까지 제가 설명한 내용이라고 할 수 있습니다.
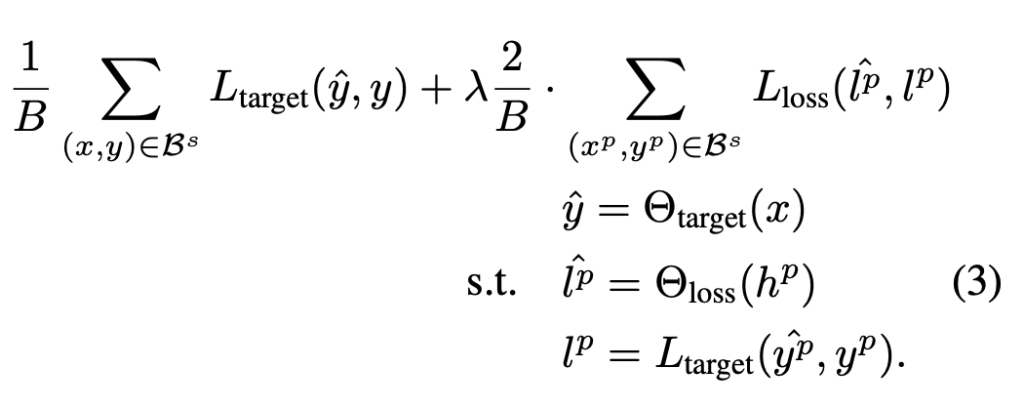
Learning Loss는 target model과 loss prediction module을 동시에 학습해야 하기 때문에, 두 개의 loss를 합쳐주는 과정이 필요합니다. 상단에 있는 수식 3이 바로 그 수식이 되겠습니다. 특별한 기법은 없이 비율을 조정해서 더해주는 연산으로 설계되었습니다.
그래서 결과적으로 당시 연구에서는 SOTA를 달성하였는데, 사실 Active Learnig 특성 상 뭐가 SOTA다 말할 수는 없어서… 애매한 부분이 없지않아 있습니다. 그러나 최근에 나오는 연구들에도 항상 벤치마크로 사용됨에도 불구 비등한 성적을 내는 것으로 보아 제법 효과가 있다는 것을 논문 상으로도 경험적으로도 알 수 잇었죠 (이것이 저희가 베이스라인으로 선정한 이유이기도 합니다)
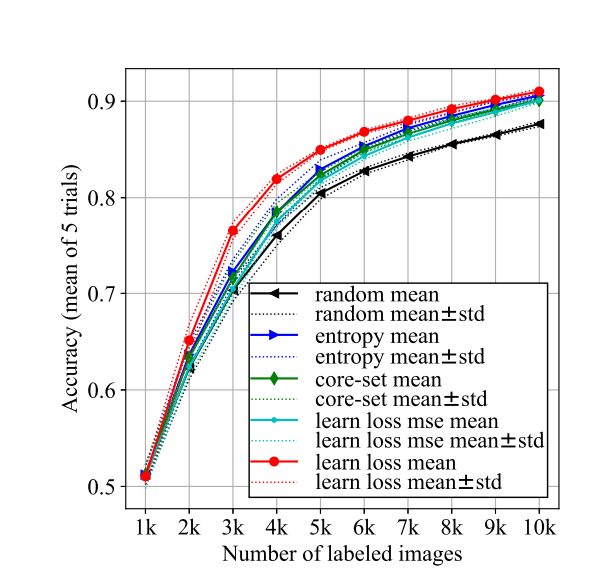
제가 리뷰에서 계속 주장한 바와 같이 Learning Loss는 Task에 대한 의존도가 굉장히 떨어집니다. Classification에도, Object Detection에도, 그리고 Human pose estimation에도 상관없이 Loss만 있다면 뭐든지 적용이 가능하죠! 그래서 Learning Loss에서도 본 모델의 확장성과 일반성을 보여주기 위해 앞서 언급한 태스크에 대하여 모델 학습 및 평가를 진행한 결과를 보이기도 하였습니다.
마지막으로 본격 리뷰에 들어가기 전에, Active Learning 학습 순서에 맞춰서 Learning Loss를 정리해보도록 하겠습니다.
- 데이터의 유익함 판단에 사용될 초기 Labeled Dataset을 랜덤하게 선택한다
- Labeled Dataset을 사용하여 Main Model과 함께 Loss prediction module을 학습한다
- 학습하면서 발생하는 Main Model의 예측값과 GT 사이의 loss는
- Loss prediction module의 GT이므로 이를 통해 Loss prediction module 역시 학습된다
- 학습이 완료되면 Unlableled dataset 을 Loss prediction module에 태운다
- Loss가 높은 순서대로 B개의 label을 얻어서 Labeled dataset에 추가한다
- 정해진 횟수만큼 2-4번이 반복된다
자, 험난했네요. 이제 Learning Loss에 대해서는 충분히 이해하셨을 것이라 생각이드네요.. 이제서야 진짜 리뷰가 시작됩니다. 사실 아래 부분은 오히려 간단해요! Learning Loss를 어떻게 분석하였는지에 대해 집중해서 리뷰할 거거든요..ㅋㅋ
Introduction
결론부터 말씀드리자면, 해당 논문은 Learning Loss를 Human Pose Estimation에 맞춘 Learning Loss++를 제안하였습니다. 사실 Learning Loss라는 네트워크는 Classification에 초점을 두고 설계한 방법이다보니, 이런 Downstream task에 최적화된 방법은 아닐 수 있습니다. 그래서 저자는 기존 Human pose estimation의 특성과 함께 이를 왜 발전시켜야하는지를 먼저 어필합니다.
우선 대부분의 human pose model의 경우 2D-heatmap을 regression하는 방식으로 관절(joint)의 위치를 추정하기 때문에, 결과값을 확률적으로 해석하는 learning loss (classification)과는 다르다고 합니다. 그렇기 때문에 AL이 적용된 Human pose estimation이 어려운 과제라고 하였구요. 뿐만아니라 Leanring loss에서의 loss는 직관적으로 설계되어 있고, loss prediction module에서 공간적 정보를 손실한다는 것이 저자가 생각하는 기존 모델의 한계라고 합니다. (저자도 Learning Loss는 이런 다운스트림 태스크에 최적화된 method가 아니기에, 이 부분에 대해서는 당연하다는 듯 글을 작성하긴 하였습니다. )
저자는 loss에 대한 gradients를 중심으로 모델의 분석을 제시하였습니다.
Gradient Analysis
우선 \theta는 loss prediction module에서 두번째 레이어의 출력이라고 정의합니다. 이 정의에 의거해서\theta에 대한 예측 Loss는 \hat{l} = \theta_i^Tw 라고 정의할 수 있습니다. 당연히 w는 가중치를 나타내겠죠.
그럼 이제 L_loss는 다음과 같이 정의내릴 수 있을 것 같습니다.
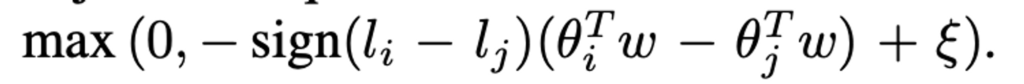
이에 따라 gradient 는 아래와 같이 정의할 수 있을 것 같습니다.
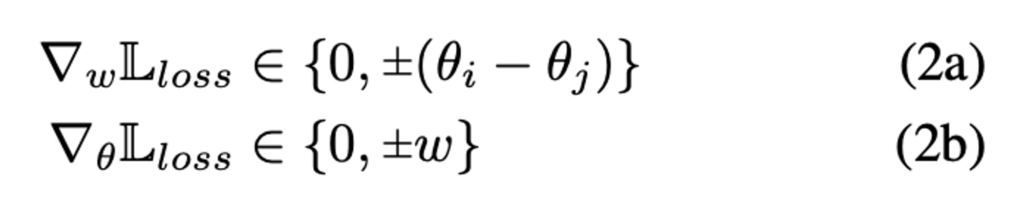
식 2(a)를 보면 가중치는 중간 피처들 사이에서 가장 변별력이 높은 요소를 강조하도록 정렬되어 있습니다. \theta를 n 차원 공간에서 벡터로 취급하고 \theta_i, \theta_j가 한 구성 요소에 대해서만 다른 경우, 가중치 벡터 w는 특정 구성 요소를 따라 증폭된다고 합니다.
방금 말한 그라디언트의 차별적인 속성에 대해서는 아래 그림을 함께 보시죠.
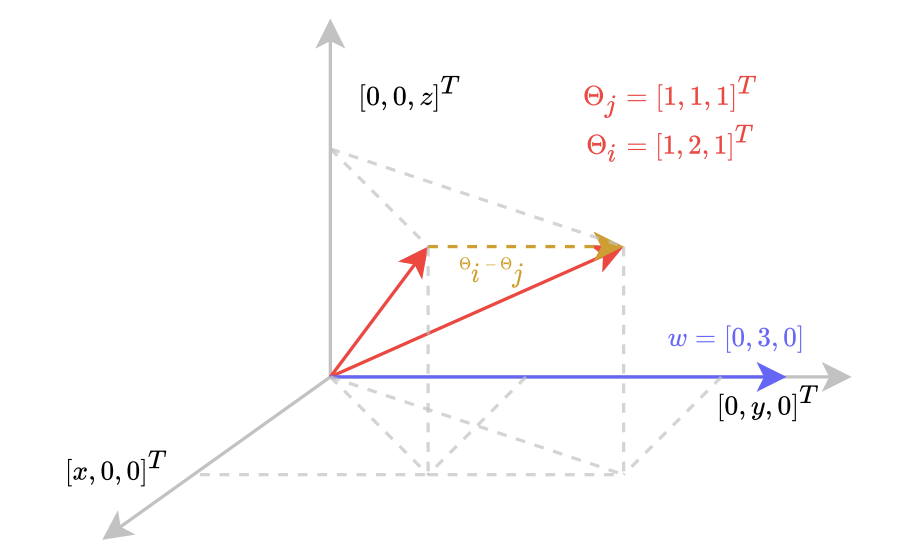
3차원 벡터 공간에서 \theta_i = [1, 2, 1]^T, \theta_j = [1, 1, 1]^T, w = [0, 3, 0]이 있습니다. (이 때, LLoss 와 동일하게마진으로는 1을 사용합니다) 실제 loss l_i, l_j 에 따라 loss는 두 가지 경우로 나누어지는데, 이는 LLoss 수식 (2)과 같이 [1] l_i > l_j [2] l_i < l_j 인 경우로 나뉘게 됩니다. 우선 [1]에 따라 L_{loss}에 \theta_i, \theta_j, w를 대입하면: L_{loss} = max(0, -1*(6-3)+1) = 0 이 됩니다.
이는 직관적으로 해석하자면 \theta를 w를 따라 projection 하는 것에 해당합니다. 현재의 w는 이미 판별 성분을 따라 정렬되어 있기 때문에 이 경우 Loss가 발생하지 않게됩니다,
그러나 [2] l_i < l_j 인 상황을 살펴보면 약간 달라지는데요. 우선 수식에 대입을 해보면 L_{loss} = max(0, 1*(6-3)+1) = 4 가 되어 Loss가 발생하게 됩니다. Eq (2a)에 따라 ∇_wL_{loss} = [0, 1, 0]^T를 구할 수 있으며, Gradient Descent가 이 방향 ∇_wL_{loss} 에 역으로 작용되게 됩니다. 이 단계를 통해 가중치 벡터가 방향을 바꾸고 궁극적으로 Loss를 최소화하는 방향으로 조절될 수 있게 된 것이죠.
그래서 결국 저자는 그라디언트의 접근 방법으로 기존 LLoss에서 설계한 Loss 함수의 특성을 파악할 수 있었습니다. \theta_i - \theta_j (기울기의 판별 속성)은 바로 예측 Loss를 설명하는 방식으로 w를 정렬하도록 강제하는 것이죠. 이를 통해 저자는 즉, 가장 변별력이 높은 구성요소 \theta_i - \theta_j를 따라 가중치 벡터 w를 정렬하도록 강제된다라는 말이 될 것 같습니다.
이 외에도 저자가 Introduction에 언급한 loss prediction에서의 공간적 정보 손실 문제는.. 아마 Global Average Pooling을 적용해서 그런 것 같고, 이를 위해 Convolution 네트워크로 설계했다 라는 말 외에도 Loss는 KL-divergence를 변경하였다 등등 다양한 해결방식을 제안하였습니다. 다만, 이에 대해서는 디테일하게 다루진 않으려고 합니다. 제가 집중한 포인트는 그라디언트로의 접근과 데이터 시각화를 통한 데이터 분석 이었기 때문이죠.
아래는 저자가 제안하는 다운 스트림 태스크에서의 correlation을 리포팅한 것입니다. 결국 LossNet이 얼마나 loss를 잘 맞췄고 연관관계가 있는지에 초점을 두고 잘 해결해나간 것을 정성적으로 확인할 수 있었습니다.
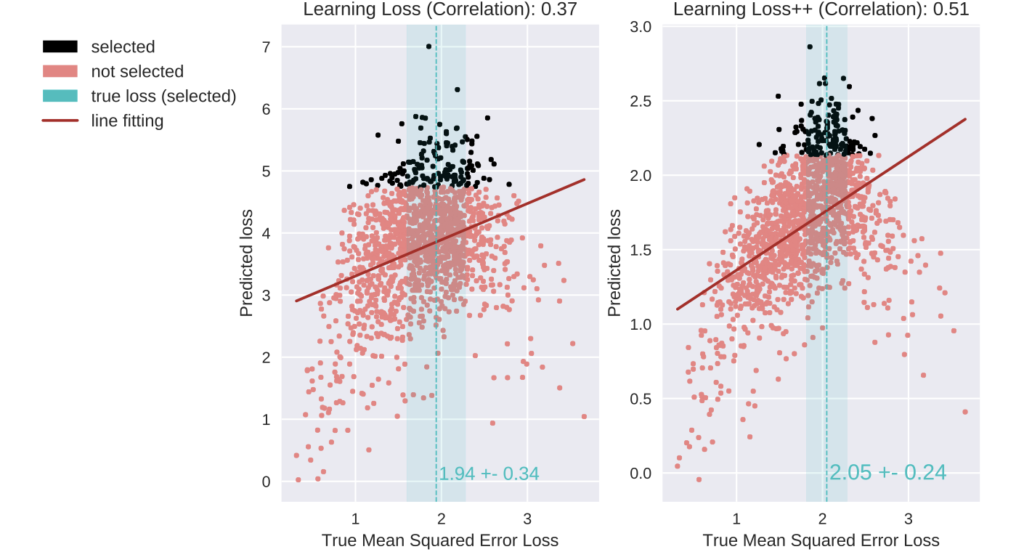
최근 Learning Loss에 대해 어떤 식으로 모델을 분석하는 것이 좋을까, 어떻게 접근하는 것이 좋을까라는 점에 어려움을 느껴 한 번 힌트를 얻고자 읽게 되었는데요. 접근의 시작점은 비슷하다고 할 수 있으나, 이를 풀어나가는 입장에서는 약간 차이가 있었습니다. 판별적 특성을 가진다라 제법 유의미한 인사이트 였습니다. 제가 해결하고자 하는 문제에 직접적으로 사용할 순 없겠지만 말이죠. 이상 리뷰 마치겠습니다.
안녕하세요, 홍주영 연구원님, 좋은 리뷰 감사합니다.
Learning Loss를 접한 것은 처음인데, 자세하게 설명되어 있어서 이해하는데 큰 도움이 됐습니다. 사담으로 core ML과 그다지 큰 연관이 없어 보이는 벤츠 인도 지부 연구자들이 낸 논문이라는게 눈이 가네요.
내용이 낯설어서 정리를 하며 읽어 보았습니다. Learning Loss를 이해하는데 집중했습니다.
1. Active Learning은 unlabeled dataset에서 모델의 성능 향상에 기여도가 클 것이라 예상되는 subset을 선택하는 모델에 대한 연구입니다. 이 때 GT(label)정보를 이용할 수 없기에 데이터 선별은 굉장히 어려운 작업이 됩니다.
2. 기존 연구자들은 성능 향상에 크게 도움이 될 것이라 기대되는 데이터를 얻기 위해 다양한 방식을 고안했습니다. uncertainty 및 diversity 기반 Active learning은 그 중 하나입니다. 이 중 uncertainty 기반 방법은 모델이 예측을 어려워하는 데이터가 성능 향상에 기여할 것이라 보는 방법입니다.
3. 본 논문에서 기반이 되는 연구(Learning Loss?)는 유용한 데이터의 판별 척도로 Loss를 활용합니다. Loss는 GT와 prediction 값의 차이로, Loss값이 크다면 모델이 예측을 어려워한다고 해석할 수 있습니다. 따라서 Loss가 높은 순서대로 하위 데이터를 선택합니다.
4. 하지만 Active Learning에서 대상으로 하는 data pool은 unlabeled이기 때문에 GT를 이용하는 Loss를 구할 수 없습니다. 이에 Loss prediction module에서는 ‘Loss를 예측’하는 모델을 사용합니다. 이 모듈에서는 어떤 이미지를 모델에 넣었을 때 target loss 예측값을 반환합니다.
5. Loss prediction module이 학습하는 방법은, 다시 말해 Loss prediction module의 Loss를 구하는 방법은 Target Task 학습 시 출력되는 Loss를 GT로 사용하는 것입니다.
6. Loss prediction module은 main task model (Image Recognition을 위한 ResNet이라던지)의 Backbone을 이용하기 때문에 별도로 학습할 필요가 없습니다. Learning Loss에서 Loss prediction module은 별도로 따로 존재하는게 아니라 main task model과 붙어 있으며, target task가 무엇이든(classification이든 regression이든) 상관 없이 backbone에서 연결되어 설계될 수 있습니다. 가볍고 간단한 네트워크라서 main task와 동시에 학습이 가능합니다.
7. Loss prediction module의 Loss는 직접 예측되는 방식으로 설계되지 않고, l_i, l_j간 gap(->pairwise gap. 여기서 l_i, l_j가 무엇을 뜻하는건지 잘 모르겠습니다.. )을 예측하는 방식으로 설계됐습니다. 이는 Loss prediction module이 loss를 직접 예측하도록 학습시키면, 그 값 자체에 집중하지 않고 scale변화에 중점을 두고 학습하기 때문입니다(학습 초반의 Loss는 굉장히 컸다가 학습이 진행되면서 Loss가 작아집니다)
8. Learning Loss는 target model과 loss prediction module을 동시에 학습하기에 두 loss를 합쳐주는 과정이 필요합니다. 추가적으로, Active learning은 그 특성상 무엇이 SOTA라고 말하기 힘들다고 합니다.
9 : Learning Loss는 Loss만 있다면 그 어떤 Task에도 적용 하능합니다. 따라서 확장성/일반성이 매우 큽니다.
10 : Active Learning의 Learning Loss 진행 과정은 다음과 같습니다 : 먼저, 초기 labeled dataset을 무작위로 선정하고 -> Labeled Dataset을 학습하며 Main model과 Loss prediction module을 학습하고 (이 때 발생하는 GT – Pred = Loss는 Loss prediction module의 GT이므로 이를 통해 Loss prediction module을 학습시킴) -> 학습 완료 이후 이번엔 Unlabeled dataset을 Loss prediction module에 태워서 -> Loss가 높은 데이터 순서대로 annotation 우선순위 할당
11 : 해당 논문은 Human Pose Estimation이라는 task를 위해 Learning Loss를 계량하는데, Learning Loss 네트워크는 Classification에 초점을 두고 설계한 방법이기 때문에 다양한 Downstream task에 최적화시키기 쉽지 않습니다.
읽으면서 생긴 질문으로는 다음과 같습니다.
1. pairewise gap의 l_i, l_j가 구체적으로 무엇을 의미하는 것인가요?
2. Active learning이 그 특성상 무엇이 SOTA라고 말하기 힘들다고 하셨는데, 이 부분이 정확히 무엇을 의미하는건지 와닿지 않습니다. 혹시 이유를 말씀해 주실 수 있을까요?
추가적으로, Gradient Analysis 부분의 이미지가 잘 업로드가 되지 않은 것 같습니다.. 확인해 주시면 감사하겠습니다 !
안녕하세요 허재연 연구원님 요약 잘 읽었습니다.
1. 그 부분의 경우 제가 코드블럭으로 참고한 pair를 구성하는 방법에 대해 참고해주시면 이해가 좋을 것 같습니다.
pred_loss = (pred_loss – pred_loss.flip(0))[:len(pred_loss)//2]
위와 같이 구성되어 있는데, batch_size가 b라고 가정해봅시다.
그럼 해당 코드는 순차적으로 얘기하면 idx_0 – idx_(b-1) || idx_1 – idx_(b-2) || idx_2 – idx_(b-3) || idx_3 – idx_(b-4) …. b//2 개만큼 구성이 되겠죠. l_i, l_j는 각각 전자, 후자를 의미합니다.
2. 왜냐하면 동일하게 CIFAR-Train 데이터셋을 사용한다 하더라도, 랜덤하게 K개의 초기 Labeled dataset을 선택해서 모델을 학습하기 때문에, 논문에 리포팅되는 성능은 각 논문마다 다를 수 밖에 없습니다. 누구는 CIFAR-10 중 subset-A로 학습한 성능을 리포팅하고, 누구는 subset-B로 학습한 성능을 그외 등등… 결국 학습 데이터셋이 다른데 누가 더 성능이 좋다 라고 비교하거나 SOTA를 구하는 것은 큰 의미가 없는데다, 초기 라벨셋을 어떻게 선정하는지에 따라서 각 방법론들의 성능도 많이 차이가 나는 것을 확인할 수 있었기 때문입니다.
안녕하세요 홍주영 연구원님 리뷰 잘 읽었습니다.
LPN 모듈을 사용하는 Active learning에서는 왜 pretrained된 모델을 쓰지 않나요? 모델의 초기화 방법론에 따라 초기 Loss가 너무 들쭉날쭉 할 것 같은데, 이에 따른 랜덤성이 극대화될 것 같습니다.
그리고 중간에 Loss 이미지좀 고쳐주세요 감사합니다.
지적하신 부분, 초기화 방법론에 따른 성능의 들쭉날쭉 (??) 차이가 있는 건 확실히 맞습니다.
어떻게 초기화를 할 지에 따라서 성능 차이가 있던 것은 기존 많은 연구들에서도 리포팅하고 있는 사실이니까요. 그러나 이건 아주 적은 데이터셋으로 학습을 시작한다는 Active Learning 의 특성 때문이지 않을까 싶은데요. 뿐만아니라 아직 연구의 성숙도가 진행되지 않아 그러지 않을까 싶습니다. 기존 연구에서는 다루지 않다보니 저도 명확하게 이유가 이렇다고 말씀드리긴 어렵네요
그리고 이미지 바로 수정했습니다 ^^ 지적 감사합니다 ^^
안녕하세요 홍주영 연구원님 리뷰 잘 읽었습니다.
gradient analysis 수식에서 i와 j의 의미하는 바를 추가적으로 소개해주시면 감사할 것 같습니다.
감사합니다
그 부분의 경우, LLoss에서 정의된 i, j와 동일합니다. LLoss 중 Loss prediction module 에서는 하나의 batch 내에서 두 개의 샘플로 구성된 pair를 만들게 되는건 아실겁니다. Batch size가 B라고 했을 때, 0번째 <-> B-1번째, 1번째 <-> B-2번째 …. B//2 개의 pair가 구성되고 그 사이의 loss값의 차이를 가지고 loss gap을 예측하는 것이 LPM 모듈인데요. 여기서 i, j는 각각 앞에 있는 것 뒤에있는 것을 의미합니다. 즉, pair를 구성하는 각 샘플을 의미하는 인덱스로 이해하시면 됩니다.
안녕하세요 좋은 리뷰 감사합니다.
리뷰를 읽으며 active learning task에 대한 의문이 생겼습니다.
1. 초기에 라벨링하는 데이터셋에 따라서도 성능 차이가 크다면, 실제 기업에서 취득한 데이터셋의 효율적인 annotation을 위해 active learning을 적용하는 경우 학계에서 벤치마킹한 데이터셋이 아니고 완전히 새로운 도메인의 데이터셋이기 때문에 SOTA 방법론들이 좋은 성능을 보장할 수 없게 되는 것인가요?
2. 그리고 active learning 중간 단계인 20, 40, 60 등등의 %만 라벨링되어있는 상황을 생각해보았을 때, 기업 입장에서 현재 active learning 방법론이 유효하게, 목적에 맞게 적용되고 있는지를 확인해보려면 결국 100%의 라벨을 얻어야만 하는 것인지도 궁금합니다.
1. 아직까지 Active Learning이… Domain Adaptation의 영역까지 커버할만큼 성숙된 분야는 아닙니다. 그렇기 때문에, 김현우 연구원의 말씀대로 “완전히 새로운 도메인 데이터셋에서 SOTA 방법론만큼 성능이 보장”할 수 없을 것 같습니다. 또 그런 이유로 CIFAR-10, CIFAR-100 과 같은 쉬운 데이터셋으로 실험을 보이고 있는 상황입니다.
뿐만아니라, 현재 Active Learning 은 방법론마다 “초기에 라벨링하는 데이터셋에 따라서도 성능 차이가 크”게 발생하는 상황입니다. 같은 CIFAR-10에 포함되는 데이터라고 해도 선택한 하위 데이터셋의 크기와 구성 이미지들에 따라 성능이 천차만별입니다. 그렇기 때문에 분명 A라는 논문에서 자신의 방법론이 SOTA라고 주장할지언정 B라는 논문에서 다른 하위데이터셋으로 Active Learning을 수행햇을 때 전혀 다른 성능이 리포팅되는 상황이라.. 명확하게 SOTA라고 말할 수 있는 방법론도 없는 상황입니다.
이런 이유들로 아직 Active Learning 이 응용을 위해 나아가야 할 길은 멀지 않나.. 개인적으로 생각해봅니다.
2. 그렇다고는 할 수 있겠으나.. 1번에서의 답변과 비슷한 이유로 아직까지 기업의 응용 단에서 Active Learning을 쌩(??)으로 가져다 쓸 수 있을지는 의문입니다.. 기업 입장에서 서비스를 돌릴 땐 안전하게 100% 의 데이터셋을 라벨링 하지 않을까요 …ㅎ허허