이번에 리뷰할 논문은 Stereo Matching 기반 방법론입니다. 근데 이제 Masked Image Modeling을 곁드린.
Intro
Stereo Matching이라는 분야는 쉽게 말하면 좌우가 나란히 있는 stereo image 쌍에 대해서 픽셀 레벨로 disparity map을 추론하는 stereo depth estimation 분야로 이해하시면 쉽습니다. 하지만 본 논문에서는 stereo matching이라는 분야로 계속해서 언급하고 있기 때문에, 해당 리뷰에서도 stereo matching이라고 부르겠습니다.
이러한 stereo matching은 아래와 같이 크게 4가지 framework으로 진행이 됩니다.
- Feature Extraction.
- Cost Volume
- Feature Matching
- Disparity Regression
이러한 4가지 파트에 대해서 각각 정확도와 효율성을 향상시키기 위한 연구들이 예전부터 꾸준히 진행되어 왔지만, 정작 unseen domain data에 대해서 준수한 성능을 보여주는 generalization 연구는 그리 많이 수행되고 있지 않다고 현 논문의 저자는 지적합니다.
그럼에도 불구하고 현재까지 unseen domain에 대한 generalization을 목적으로 둔 논문들이 존재하긴 하며, 이들의 방향성은 크게 3가지로 첫째는 unsupervised matching method, 둘째는 domain adaptation, 마지막으로는 domain generalization으로 꼽을 수 있습니다.
여기서 domain adaptation과 domain generalization에 대한 차이를 궁금해하실 수 있는데, 제가 알기로 domain adaptation은 각각 source와 target 도메인이 존재할 때, 모델이 학습 동안에 source 도메인 뿐만 아니라 target 도메인에 대해서도 접근이 가능하다는 점입니다.
반면 domain generalization은 모델이 source 도메인만을 학습할 수 있으며 target 도메인은 전혀 볼 수 없는 상황을 의미하게 됩니다. 따라서 Domain generalization이 adaptation보다 더 어려운 task로 볼 수 있으며, 실용적인 측면에서는 더 중요하고 필요한 학문이라고 제 개인적으로 생각합니다.
아무튼 이러한 기존 domain generalization 연구들에서는 종종 generalization의 성능에 가장 큰 영향을 주는 것은 network의 feature representation에 달려 있다고들 합니다. 따라서 저자 역시도 domain generalization 성능을 보장하기 위하여 feature representation을 더 향상시킬 수 있는 방법에 많은 관심과 초점을 두게 됩니다.
그리하여 본 논문에서는 원래의 target task인 stereo matching task 뿐만 아니라, 마스킹된 영역에 대해 복원을 수행하는 Masked Image Modeling(MIM)을 함께 학습을 시킴으로써(Multi-task Learning) feature representation을 향상시키고 최종적으로 모델의 generalization performance를 끌어올린다는 것이 이 논문의 핵심입니다.
모델을 어떻게 학습하는지에 대해서는 아래 method section에서 조금 더 자세히 다루겠습니다.
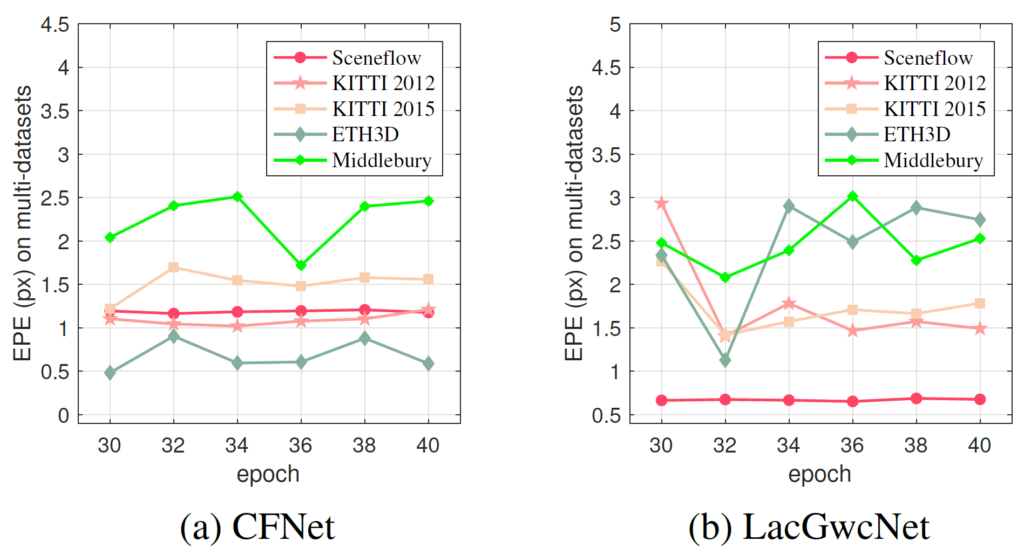
그리고 이 논문의 한가지 재밌는 점은 바로 그림1의 실험입니다. 그림1에서 나타내는 실험 결과는 기존 Domain Generalization 논문들의 경우 source domain에서 학습한 모델이 target domain으로 넘어가서 평가할 때(즉 generalization performance를 측정할 때), source domain에서 학습된 에포크의 수에 상당히 민감하다는 경향성을 나타내고 있습니다.
보다 구체적으로, source dataset으로 Sceneflow라는 데이터 셋을 활용해 모델을 학습시킨 경우, 30~40에포크 사이에 stereo matching 모델(CFNet or LacGwcNet) 성능은 다들 큰 폭의 차이 없이 비슷한 것을 볼 수 있습니다. 즉 어느정도 수렴이 되었다고 볼 수 있는 것이죠.
반면에 이렇게 학습된 모델을 KITTI2012부터 Middlebury까지 4가지 데이터 셋에 대해서 평가할 때, 특정 에포크 수(예를들어 LacGwcNet의 경우 32에포크에서 학습한 체크포인트가 Middlebury와 KITTI, ETH3D 데이터 셋에서 가장 적은 에러값을 가지고 있음.)에 상당히 좋은 성능을 보여주는 반면 또 다른 에포크에서는 상대적으로 좋지 못한 성능을 보여주고 있다는 점입니다.
저자는 이러한 점을 두고, 기존의 연구들의 경우에는 결국 각 데이터 셋에서 제공되는 GT 데이터를 통해 가장 좋은 성능을 보여주는 에포크를 체리픽해서 domain generalization의 성능을 (논문에서) 보여주었지만, 실제 domain generalization이 잘 동작해야하는 환경의 경우 새로 촬영된 환경에서의 GT 정보는 당연히 존재하지 않을 것이기 때문에 특정 에포크를 체리픽 할 수도 없으므로 이러한 에포크에 따른 성능 차이는 상당히 문제라고 주장합니다.
그리고 이러한 문제에 대해서 자신들이 제안하는 학습 방식을 이용하게 될 경우 에포크에 따른 성능의 GAP 차이가 많이 존재하지 않는다고 저자는 주장합니다.
Method
그럼 우선 본 논문의 전반적인 프레임워크에 대해서 알아보겠습니다.
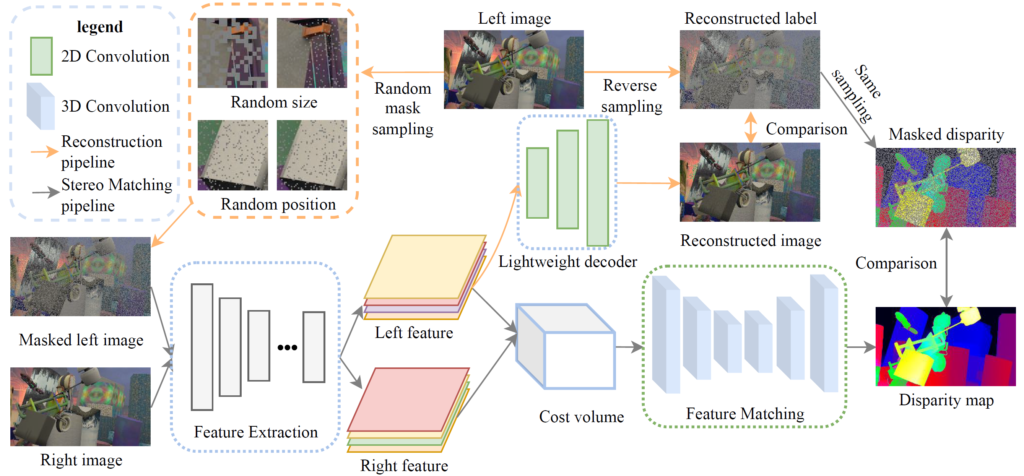
우선 본 논문에서는 합성데이터 셋(SceneFlow)을 학습으로 사용하게 되며, 구체적으로 rectified stereo image가 입력으로 들어오게 됩니다. 이때 앞서 intro에서도 설명드렸다시피 본 논문에서는 stereo matching과 더불어 Masked Image Modeling을 동시에 학습하는 multi-task learning을 통해 feature representation을 향상시키고자 하기에 left image에 대해서는 masking을 처리한 모습입니다.
여기서 저자는 Feature Extraction과 Feature Matching Module이 모델 학습에 상당히 중요한 부분들이라고 주장합니다. 그 이유는, 앞서 intro에서 Stereo Matching의 framework을 크게 4가지로 구분할 수 있다고 했으며, 그 중 Cost volume과 Disparity Map regression은 학습을 할 필요가 없거나 혹은 학습을 수행하는 layer가 상당히 shallow합니다. (Cost volume은 단순히 Left feature와 Rifht feature를 concatenation~후처리 하면 됨.)
따라서 Cost Volume을 잘 생성하기 위해 좋은 Image Feature를 추출하는 Feature Extraction 모듈, 그리고 만들어진 Cost Volume에 대하여 좋은 Feature Matching을 수행해야 하는 Matching Module이 모델의 Generalization performance를 결정하는 중요한 수단이 되는 것이지요.
아무튼 간에 Multi-task learning 중 MIM task를 수행하기 위해서 저자는 Feature Extraction 부분 뒤에 매우 Shallow한 Decoder를 추가하였습니다. 해당 Decoder는 Masking된 영역에 대해서 복원을 수행하여 실제 Left 이미지와 비교하는 목적 함수를 계산한다고 생각하시면 됩니다. 보다 자세한 내용은 바로 아래에서 다루도록 하죠.
Masked Input Image
먼저 해당 논문은 Kaiming He의 Masked Auto Encoder(MAE)에 많은 영향을 받은 것 같습니다. 논문에서도 MAE와 유사하게 마스크 픽셀은 uniform distribution에서 랜덤하게 선택하여 사용하였다고 하며, 이때 마스킹 비율과 ratio는 모두 고정하였다고 합니다.
하지만 기존 MAE와 다른점이 크게 3가지 존재하는데, low ratio와 small mask size를 사용했다는 점이며(기존 mae는 75% 마스킹 but 본 논문은 15~30%활용), 패치들의 랜덤 포지션을 활용하지 않았다고 합니다.(패치의 랜덤 포지션? 이 부분은 무엇을 의미하는지 잘 모르겠음.)
마스킹 비율을 작게 가져간 이유에 대해서 설명하면, 저자들은 모델이 마스킹된 영역을 복원할 때 주변에 이웃 픽셀들을 더 잘 활용했으면 하는 생각을 가졌다고 합니다.
이러한 주장은 기존 MAE의 철학과 상당히 반대된다고 볼 수 있는데, 기존 CNN 기반 네트워크들이 Image Inpainting을 pretext task로 적용하여 모델을 학습시켰을 때 좋은 pretrained-weight을 얻지 못한 이유에 대해서 Kaiming He는 영상의 특성 상 이웃 픽셀들이 가지는 정보가 크기 때문에 모델이 마스크 영역을 복원하는데 있어 영상 내 semantic한 정보를 이해하고 학습하기보다는 주변 이웃 픽셀들의 정보를 카피하는데 집중하여 결국 좋은 weight를 학습하지 못한다고 주장하였습니다.
하지만 본 논문의 저자는 반대로 모델이 마스킹된 영역을 복원하기 위해서 마스킹 영역 주변 이웃 픽셀들에 더 초점을 가지도록 마스킹 ratio를 작게 하였다는 말을 보고 상당히 흥미롭다고 느꼈습니다. 결국 stereo matching이라는 main task를 수행하기 위해서는 영상의 semantic한 정보도 중요할 수는 있지만 그 보다는 structure와 같은 영상의 구조적 정보들이 더 필요하다고 저자는 주장합니다.
이러한 관점에서 주변 이웃 픽셀들에 모델이 포커스를 둔다는 것은 모델이 semantic한 정보보다는 구조적인 정보에 더 초점을 가질 수 있다고 판단한 것 같은데, 이 부분에 대해서는 무엇이 더 좋은지 저도 개인적으로 궁금해서 시간이 되면 직접 실험을 해보고 싶네요.
두번째로, 너무 많은 픽셀들을 마스킹해버리게 될 경우에는 원래의 목적인 stereo matching을 수행하는데 있어 너무 어렵다고 합니다. 두 영상 사이에 공통적으로 보이는 영역들이 있어야만 매칭을 할 수 있는 것인데, 아무래도 너무 많은 영역을 마스킹해버리게 된다면 모델 관점에서 stereo matching을 수행하는데 어려움이 있고, 학습이 어려워지긴 하겠죠.
아무튼 간에 저자는 그림3과 같이 상대적으로 작은 마스킹 비율을 가지고 MIM 학습을 진행하며 실험 섹션에서도 말씀드리겠지만 최종적으로 15% 비율을 활용하게 됩니다.
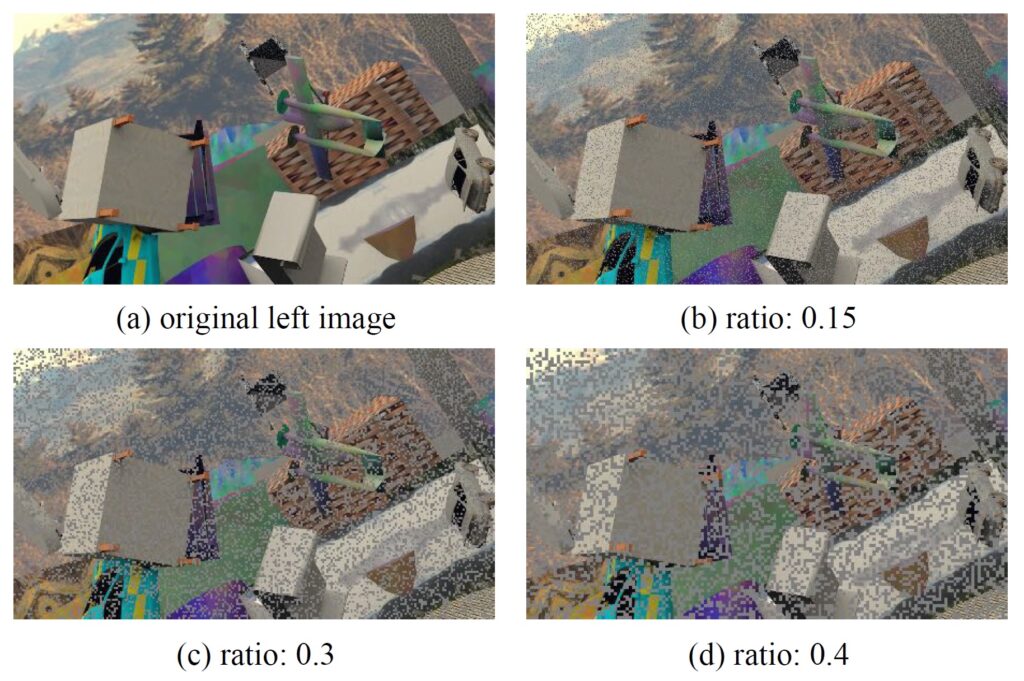
결과적으로 이렇게 마스킹 과정을 왼쪽 영상에 적용하게 된 후, 왼쪽 영상과 오른쪽 영상 각각 shared Feature Extractor를 통과시켜 Feature map을 추출합니다. 추출된 Feature map에 대하여 두 영상의 feature map은 Cost Volume을 만들거나 혹은 Left feature에 한해서 simple decoder를 타고 이미지 복원을 수행하게 됩니다.
Decoder Design
그럼 이번엔 디코더에 대해서 간략하게 소개하고 넘어가죠. 일단 Feature Extraction을 통해 타고나온 Feautre map의 크기는 원본 해상도의 1/4 수준이 됩니다. 따라서 마스킹된 영상을 복원한 후 실제 원본 영상과 비교하기 위해서는 해상도를 맞춰주는 작업이 필요로 하며, 따라서 디코더는 2개의 Upsampling 연산이 들어가 있습니다.
또한 그림2에서도 보셨다시피 디코더의 컨볼루션 레이어가 3개만 존재하는 것을 확인할 수 있는데, 실제로 2D Conv layer 3개와 각각의 Conv layer 사이에 Upsampling 연산이 포함되어 있다고 합니다.
이렇게 단순하게 디코더 모델을 설계함으로써 모델 학습 과정에서 Multi-task Learning을 수행하게 되더라도 메모리와 학습 시간을 크게 단축시킬 수 있었으며, 또한 이러한 복원 과정은 학습에서만 사용되기 때문에 실제 추론 단계에서는 아무런 부정적 영향을 끼치지 않는다고 합니다.(뭐 이건 MIM 학습 방식이라면 다들 가지는 이점이죠^^..)
Loss Function
목적 함수에 대해서도 다뤄보죠. 목적 함수는 사실 너무도 간단한 것이 Multi-task Learning으로 Stereo Matching과 MIM을 수행하기에 이 두 테스크에 대한 loss가 끝입니다.
즉 기존 Stereo Matching 논문들이 활용하는 loss framework를 그대로 활용하였으며, MIM 역시 MAE 논문을 기반으로 하여 Noramlized RGB Target에 대하여 마스킹이 된 영역에 한해서만 Mean Squared Error(MSE) loss를 계산하였다고 합니다. 수식으로 표현하면 아래와 같습니다.
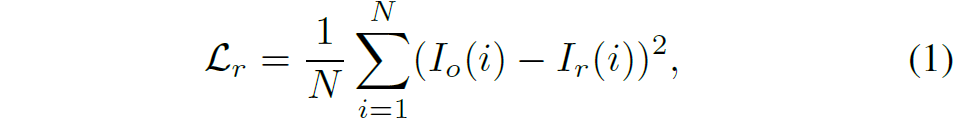
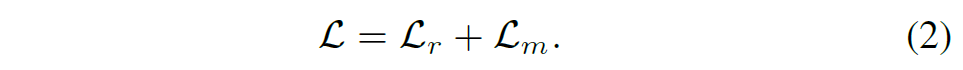
Algorithm applicability and advantage
MIM 논문 특성상 Method 부분에서 다루는 내용이 참으로 애매하긴 합니다ㅎㅎ.. 본 논문에서도 이러한 점을 인식했는지 Method 방법론에서 본인들이 제안하는 학습 프레임워크의 활용성 및 이점에 대해서 한번 더 언급하는 섹션이 존재하네요.
먼저 알고리즘의 활용성 측면에 대해서 다루면 결국 앞서 stereo matching task의 4가지 framework(Feature extraction, Cost volume, Feature Matching, Disparity Regression)에 대하여 현재까지 대부분의 연구들이 다 이러한 흐름을 따른다고 합니다.
따라서 본 논문에서 제안하는 Multi-task Learning은 다른 Stereo Matching 논문들에게 적용하기가 상당히 쉽다는 점을 어필합니다. 단순히 decoder 하나 추가해서 reconstruction loss를 추가하면 끝이긴 하니깐요.
또한 알고리즘적 이점으로는 Domain Adaptation 분야와 다르게 (본 논문에서 제안하는) MIM Reconstruction 방식의 학습은 Target 도메인의 데이터 셋을 학습 때 전혀 고려하지 않아도 되며, domain generalization 분야와의 비교에서 역시 해당 분야 논문들은 test 단계에서 추가적인 framework이 붙어야하는 대신에 (본 논문의 경우) Reconstruction framework은 전혀 붙을 필요가 없기에 훨씬 더 효율적이고 단순하다고 주장합니다.
Experiments
Datasets & Evaluation Metrics
그럼 이제 실험 섹션에 대해서 알아보겠습니다. 먼저 해당 논문에서 사용한 데이터 셋은 앞서 그림1에서도 보셨다시피 총 5가지 입니다. 학습에 사용되는 Source Domain Dataset은 Sceneflow라는 합성 데이터 셋이며, 그 외에 평가용으로 활용되는 target domain dataset은 KITTI 2012&2015(KT-12, KT-15), ETH3D(ET), 그리고 Middlebury(MB) 데이터 셋입니다.당연히 해당 논문의 task는 domain generalization이기 때문에 이러한 target domain에 대해서 어떠한 fine-tuning 과정을 거치지 않았다는 점을 염두해주시면 좋겠습니다.
평가 메트릭으로는 크게 End-point-error(EPE)와 percentage of error pixels(t-px error)이 존재하는데, 이 t-px error는 쉽게 말해서 모델이 실제 정답과 비교했을 때 픽셀 에러 오차가 t 보다 더 큰 영역들이 얼마나 있는지에 대한 에러 퍼센테이지를 계산한다고 생각하면 되고, 결국 둘다 에러를 의미하는 것이기 때문에 값이 낮을수록 좋다고 이해하시면 좋겠습니다.
Masking Ratio
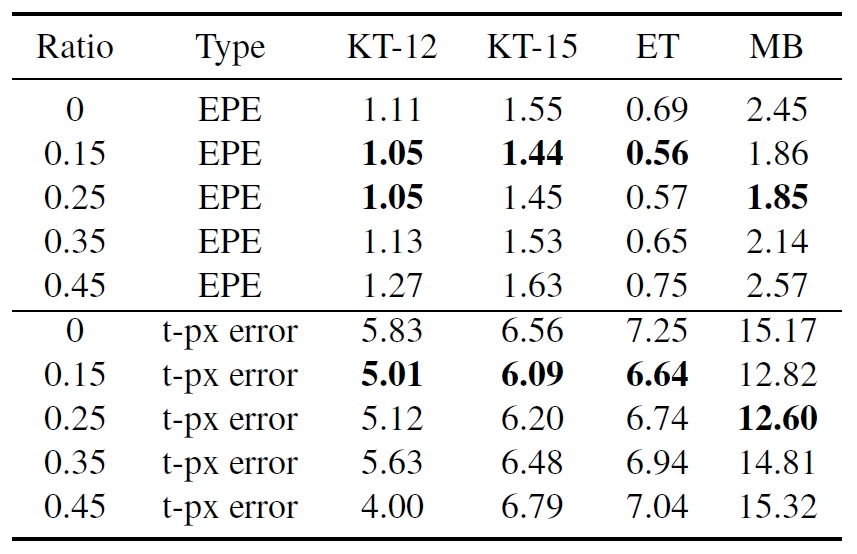
그럼 masking ratio에 대한 ablation study부터 살펴보시죠. 전반적으로 보면 EPE도 그렇고, t-px error도 그렇고 작은 크기의 masking ratio 값을 가져야 좋은 generalization performance를 보여주는 것을 확인하실 수 있습니다.
저자는 이러한 경향성을 바탕으로, 마스킹 ratio가 너무 높은 경우에는 모델이 reconstruction을 수행하는 것 자체도 너무 어렵기도 하며 동시에 stereo matching을 수행하는 과정 자체도 너무 하드해져서 두 task 모두 학습이 어렵다는 단점이 있기에 성능이 하락한다고 설명합니다. 제 개인적으로는 stereo matching 단계에서는 성능이 떨어지는 것이 이해는 되지만 reconstruction 과정이 너무 어렵다는 저자의 주장은 사실 잘 모르겠네요. 아무래도 평가 기준은 Stereo matching task와 관련된 것이고 reconstruction 결과에 대해서는 정량, 정성적으로 보여주지 않고 있기에.. 아무튼 그렇습니다.
Convergence process
앞서 intro에서 domain generalization 성능이 source dataset에서 학습된 에포크의 수마다 편차가 상당히 크다는 점을 figure 1을 통해서 설명드렸습니다.
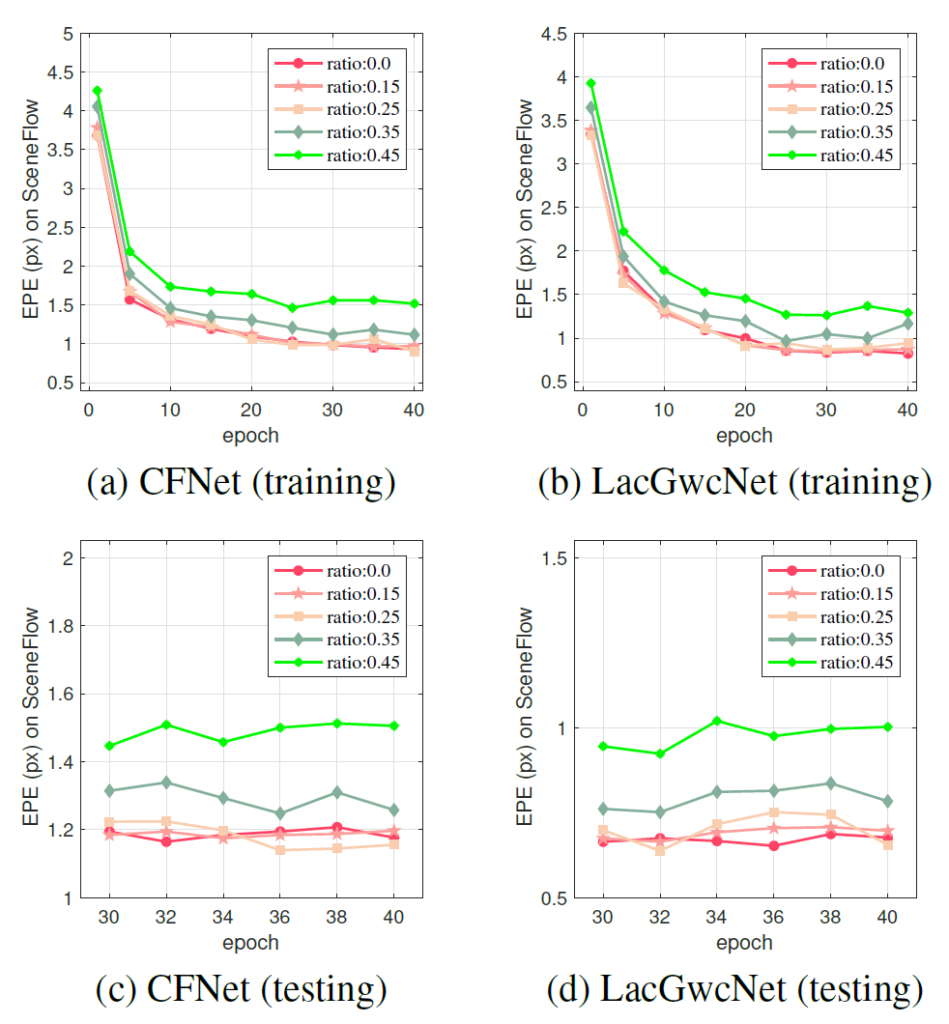
그림 4는 그림1의 실험을 보다 더 자세히 나타낸 결과로, MIM task를 학습하는지 안하는지 그 여부에 따른 학습 및 평가 과정에서의 에포크 성능 차이를 나타낸 그림입니다.
그림 4에 대한 결과를 요약하면 첫째로, source domain에서 train과 test에 대한 결과가 상당히 안정적이라는 점이며, 둘쨰로는 베이스라인(no MIM)과 비교하여 제안하는 방법론은 low mask ratio에서 수렴 과정이 크게 변화하지 않았다는 점이며 셋째로 high mask ratio는 학습 과정과 matching accuracy에 상당히 부정적인 영향을 미친다는 점 입니다.
결국 stereo matching이라는 분야는 로컬 정보에 상당히 민감하기 때문에 이러한 결과가 나왔다고 저자는 주장하며, 이러한 마스크 비율은 모델이 두 feature map의 correlation을 계산하고 학습하는데 있어서 상당히 중요한 역할을 수행한다고 합니다.(당연한거 아닌가..?)
Run Time
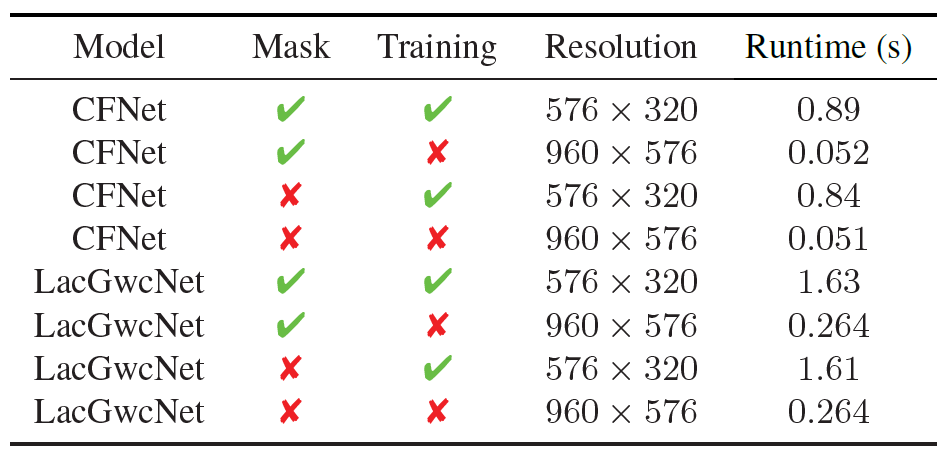
다음은 학습 및 평가 단계에서의 Run Time을 나타낸 결과입니다. 마스킹을 적용했을 때와 이를 통해 MIM task를 학습시킬 때 각각 베이스라인 대비 runtime이 얼만큼 증가하였는지를 나타낸 것으로, 마스킹을 적용하는 행위 자체는 속도에 거의 영향을 주지 않으며, reconsturction을 수행하는 단계에서도 베이스라인 대비 학습 시 런타임이 크게 증가하지 않는다는 것을 어필하고 싶은 것 같습니다.
음 근데 Training 이라는 항목이 MIM을 학습하는 과정을 추가한 것으로 보이는데 이때는 해상도를 576×320으로 상대적으로 낮은 단계를 표기했네요. 만약 960×576 사이즈가 될 경우에는 더 큰 run-time 속도를 가질 것 같은데 왜 이런식으로 테이블을 구성했는지 잘 모르겠습니다.
Training Epochs and generalization performance
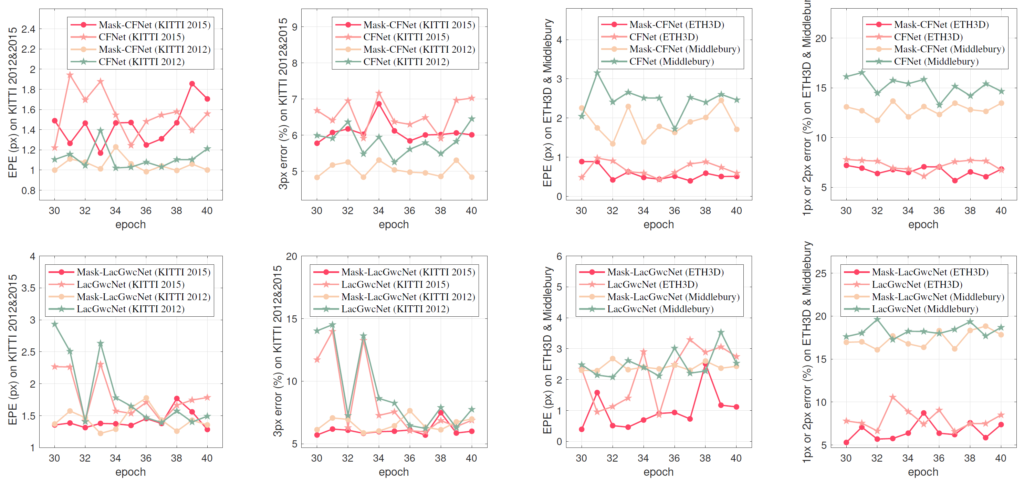
다음은 epoch에 따른 generalization performance 편차에 대한 실험 결과입니다. 그림4는 source domain에서 에포크에 따른 성능 편차를 확인한 것이라면, 지금 그림5의 경우에는 target domain에서의 성능 편차를 나타낸 것입니다.
저자의 주장을 따르면 Masked Image Modeling으로 학습하지 않은 baseline 방법론들은 에포크별로 성능 편차가 크게 나타나고 있는 반면(star), MIM을 함께 학습한 모델들의 경우에는(circle) 에포크별 성능 편차가 크게 줄어들었다고 합니다.
일단 KITTI 2015 및 2012 데이터 셋의 LacGwcNet의 경우에는 저자가 주장하는 경향성이 크게 보이는 것 같습니다만, 그 외에 다른 데이터 셋들에 한해서는 솔직히 잘 모르겠습니다. 그림으로 봤을 때는 그렇게 드라마틱한 변화를 보여주진 못하는 것 같고 결국 MIM으로 학습한 모델들도 에포크에 따른 편차가 제법 있어보인다는 느낌이 강하게 드네요.
저자들도 이를 의식했는지 에포크에 따른 데이터의 편차를 정량적 수치로 볼 수 있게끔 평균과 분산을 다음과 같이 계산하여 나타내었습니다.
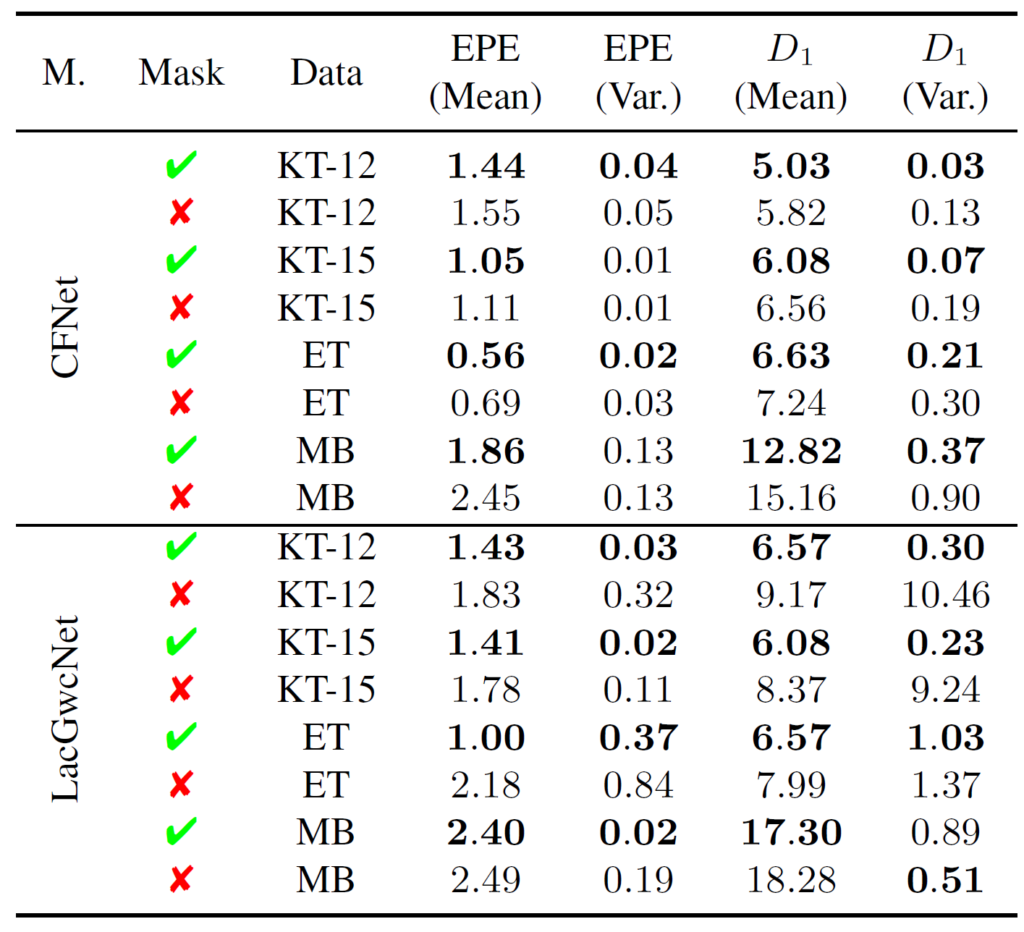
위에 표를 살펴보시면 Mask를 적용한 경우 평균적으로 EPE와 D1의 값이 더 작은 것을 볼 수 있네요. 그리고 variance에 한해서도 더 적은 값을 가지는 것을 확인하실 수 있습니다.(CFNet의 EPE 평가 지표를 제외하구 말이죠.)
Comparisons with generalization method
해당 파트에서는 다른 stereo matching methods와의 비교를 해보는 시간을 가질 것입니다.
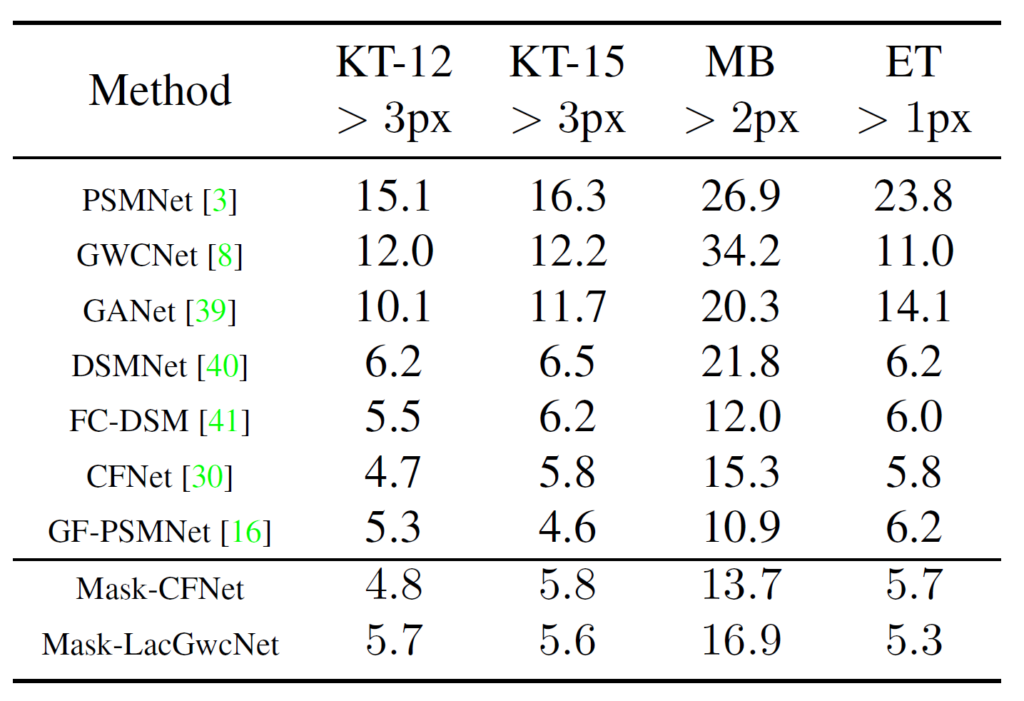
위에 표에 나와있는 다양한 모델들은 모두 Scene-Flow 데이터 셋으로 학습한 후 어떠한 fine-tuning 없이 4가지의 real data에서 평가만을 한 결과를 의미합니다. 이렇게 수치적은 측면으로만 놓고 보면 사실 논문에서 제안하는 방식이 과연 뛰어난가?라는 생각이 들긴 합니다. 예를 들어 CFNet과 Mask-CFNet이 KITTI에 대해서는 비슷하거나 기존 CF-Net이 더 좋은 결과를 보여주고 있거든요.
즉 압도적인 Generalization performance를 보여주지 않자 저자는 이에 대해서 또 epoch에 따른 성능 차이를 언급합니다. 즉 지금 위에 표 결과는 저 방법론들이 가장 좋은 성능을 보여주는 epoch일 때의 결과를 나타낸 것이지만, epoch에 따른 성능 차이를 비교한다면 자신들이 제안하는 성능이 더 좋다라는 것을 말이죠.
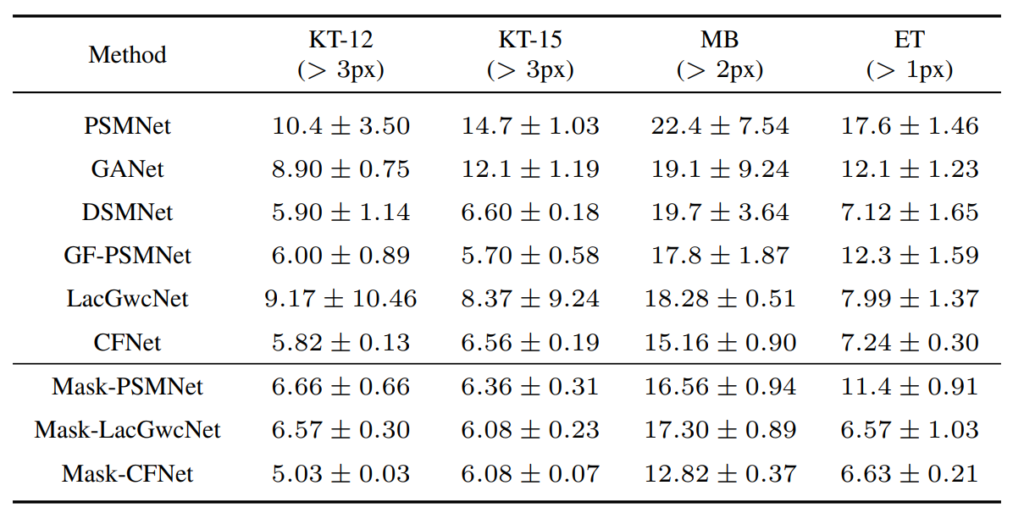
실제로 위에 표는 본 논문 supplemental material에서 가져온 것으로 CFNet과 LacGwcNet의 평균 값보다 Mask를 적용하였을 때의 평균 성능이 더 좋은 것을 확인할 수 있었습니다. 게다가 LacGwcNet의 경우에는 KITTI 데이터 셋에서 에포크에 따른 편차가 상당히 크게 나타나있네요.
게다가 더 재밌는 점은 PSMNet을 mask를 적용했을 때와 안했을 때의 성능 향상 폭도 상당히 크다는 점입니다. 기존 PSM net이 KITTI에서 10.4 +- 3.5의 T-px error를 가지고 있는 반면, Masking을 적용하여 학습시킬 경우 6.66으로 상대적으로 상당히 작은 에러 값을 지니고 있다는 것이죠.
Discussion
다음은 논문에서 얘기하는 Limitation에 대한 내용입니다. 저자는 Domain Generalization에 대해서 생각보다 재밌는 그리고 불편한 문제점을 하나 제기하는데, 바로 현재의 Domain Generalization 성능을 평가하는 환경 자체가 과연 올바른 환경인가?에 대한 의문을 이야기합니다.
이것이 무슨 말이냐면, SceneFlow 데이터 셋으로 학습하여 실제 Domain Generalization performance를 추정하기 위한 unseen dataset으로 활용되는 4가지 데이터 셋(KITTI 12&15, Middle Bury, ETH 3D)은 다들 source domain과 비슷한 오브젝트를 포함하고 있다는 말입니다.
보다 구체적으로, 보행자, 도로와 같은 길거리 장면 등은 source domain에서의 drving dataset(subset of scene flow)과 환경이 유사하기 때문에 정말로 domain generalization의 의미를 다시 생각해봐야하지 않을까라고 주장합니다. 물론 domain generalization의 의미를 color distribution, illumination 등등의 작은 개념들로 따지면 이러한 실험 환경도 충분히 유의미하지만, 보다 더 큰 의미로 보면 지금의 실험 환경이 가지는 한계가 명확하다는 점이죠.
이에 대해 더 구체적으로, 논문에서는 자신들이 제안한 학습 방식으로 학습된 모델의 진정한 Domain Generalization performance를 계산하기 위해서, 위성 사진과 일상의 사진 등을 평가해보았습니다. 그 결과는 아래 그림과 같은데, 한눈에 보더라도 disparity map 계산이 실패한 것으로 보이죠.

저자는 이러한 관점에서, 진정한 의미의 domain generalization으로 다가가기 위해서는 실험 환경을 변경해야하지 않을까 라는 조심스러운 의문을 제기한 채로 논문을 마무리 짓습니다.
결론
사실 방법론적인 측면, 그리고 실험에서 떠드는 결과들의 내용들을 보면 진부하고 참신하다는 생각이 전혀 들지 않는 방법론이었습니다. 그래서 2023 CVPR 논문이 맞나?라는 생각이 종종 들기도 했었죠. 하지만 이 논문이 CVPR에 붙을 수 있었던 이유에 대해서 그 누구도 건들지 않았던(오히려 숨기려고 했던) domain generalization 분야의 문제점들(에포크에 따른 generalization performance 차이, 실험 환경 등)을 언급하고 이를 해결하려고 노력했다는 점에서 리뷰어들의 환심을 사지 않았을까 생각합니다.
그런 점에서 나름 재밌게 읽어보았다는 생각도 들었으며, 본 논문에서 related work 등도 잘 정리를 해놓았기 때문에 stereom matching 관련에서 공부를 시작하기 좋은 논문이 아닐까 라는 생각이 들었습니다.
안녕하세요. 신정민 연구원님.
좋은 리뷰 감사합니다.
리뷰에서 말씀하신 것처럼, 논문에서 제시하는 문제가 굉장히 인상깊은 것 같습니다.
일상 사진의 경우 disparity를 전혀 못 잡는게 충격적이네요…
그런데 애초에 딥러닝 기반의 stereo matching에 이 정도로 어려움이 있다면 딥러닝 기반이 아닌 기존의 stereo matching 방법을 쓰는 것이 낫지 않나 하는 생각이 드는데 혹시 그렇게 하지 않는 기존 방법의 문제나 딥러닝 기반 방법의 장점이 있을까요?
감사합니다.
리뷰 감사합니다.
음 어떻게 보면 기존의 전통적인 stereo matching 방법을 사용하는 것이 해당 논문에서 밝힌 일상 사진에서 어느정도 준수한 성능을 보여줄수도 있을 것 같다는 생각에는 동의합니다.(아무래도 규칙 기반 방법론이기 때문에 어떠한 데이터가 오더라도 완전히 실패하는 경우는 없겠죠.)
하지만 확실한 건 딥러닝 기반 방법론은 학습된 데이터와 비슷한 도메인에서 상당히 좋은 성능을 보여준다는 점입니다. 실제로 전통적인 스테레오 매칭 기법으로 SGM 정도가 있을텐데 해당 방법들은 추론 속도도 느리고, 생성된 disparity map 자체가 매우 거칠며(연속적이고 부드럽지 못함), textureless한 영역에서 특히 심한 오차를 보여줍니다.
물론 딥러닝 기반도 textureless한 영역에 대해서 좋은 추론을 하기에는 어렵긴하지만 supervised learning을 하게 될 경우에는 해당 부분들이 어느정도 극복이 가능하며 그외에 부드럽고 정확한 결과 및 빠른 추론속도가 가능하기에 딥러닝 기반 방법론들을 어떻게든 일반화 성능을 끌어올려서 사용하려고 하는게 아닐까 싶네요.
안녕하세요.
좋은 리뷰 감사합니다.
기존 MAE는 이웃 픽셀들이 가지는 정보가 커서 이들을 카피하는데 집중하느라 semantic한 정보를 학습하지 못하기에 masking ratio을 크게 가져간 반면, 본 논문에서는 stereo matching을 수행하기 위해 structure 정보에 초점을 맞춰 이웃 픽셀들에 초점을 가지도록 ratio를 작게 가져간 부분이 흥미로웠습니다. 이와 같은 이유로 mask size도 줄인 것인가요 ?
masking ratio에 관한 ablation study를 보면 대게 ratio를 낮게 했을 때 error가 더 적은 것을 볼 수 있지만, 0.45기준 t-px error가 ratio가 0.15일 때 5.01인 것에 비해 1이나 낮네요 . . 혹시 0.45보다 ratio를 더 크게 했을 때의 결과는 없었는지 궁금합니다.
또, End Point error metric이 실질적으로 의미하는 것이 무엇인지요 .. 어떻게 계산되는지 알 수 있을까요 ?
감사합니다 !
질문 감사합니다.
질문에 대한 답변은 다음과 같습니다.
Q1. 이와 같은 이유로 mask size도 줄인 것인가요 ?
A1. 네 맞습니다.
Q2. 혹시 0.45보다 ratio를 더 크게 했을 때의 결과는 없었는지 궁금합니다.
A2. 네 없습니다.
Q3. End Point error metric이 실질적으로 의미하는 것이 무엇인지요
A3. https://stackoverflow.com/questions/49699739/what-is-endpoint-error-between-optical-flows 링크 설명 참고부탁드립니다.
감사합니다.
안녕하세요. 신정민 연구원님. 리뷰 잘 읽었습니다.
리뷰에서도 언급하셨는데 왜 성능이 좋은지 잘 모르겠네요. 편차가 작아졌다고 크게 주장하는데, 그래프랑 표를 봐도 그렇게 큰 발견인지 잘 모르겠습니다. 정민님이 작성하신 MAE 리뷰를 몇개 좀 봤었는데요. 이 경우에는 마스킹되는 픽셀 영역이 가우시안 노이즈 같이 적용되고 있는데 이 크기를 더 키우는 실험은 없나요? 이것과 마스킹 비율에 따라서 평균&편차의 차이가 더 좁아지는 등의 설명은 없는지 궁금합니다. 감사합니다.
논문에서 마스킹 비율에 따른 평균,편차 비교 실험은 없습니다.
다만 논문에서 마스킹 비율에 따른 단일 에포크 성능 리포팅이 있으며
그 중에서 가장 최선의 성능을 내는 마스크 비율일 때의 에포크 별 평균, 분산을 나타낸것이기에 어느정도 유추가 가능할 것을 판단됩니다.
그리고 저도 리뷰에서 남겼듯이… 성능이 엄청 드라마틱하다… 라고 할 수는 없겠으나 그래도 generalization 관점에서는 잘 풀어냈다고 생각합니다.