제가 이번에 리뷰할 논문도 6D Pose Estimation 논문입니다. 해당 논문은 2020 CVPR 논문으로, 제가 최근에 리뷰한 FFB6D논문이 베이스로 삼았던 논문이라 읽고 리뷰하게 되었습니다. FFB6D가 궁금하신 분은 FFB6D리뷰를 참고해주시기 바랍니다. 그러면 리뷰 시작하겠습니다.
Abstract
우선 해당 논문은 단일 RGBD 이미지에서 강인한 data-driven 6D Pose Estimation 방법론으로, 직접 pose 파라미터를 구하던 이전 방법론과 달리, keypoint 기반의 방식을 도입하여 challenge한 6D Pose Estimation을 해결하는 방법론이라합니다. 3D keypoint를 찾고 least-squares fitting 방식을 통해 6D 파라미터를 예측하는 Deep Hough voting 네트워크를 제안하였고, 깊이정보를 통해 강체의 기하학적 제약을 충분히 활용 가능하도록 한 방법론이라 합니다.
Introduction
우선 6DoF Pose Estimation 문제란 물체의 3차원 위치와 방향을 인식하는 문제로, 로봇의 grasping이나 조작, 자율 주행 및 증강현실과 같은 실제 application 관점에서 중요한 문제입니다. 6D Pose Estimation은 조도의 변화나 센서에 노이즈, occlusion이나 객체가 잘린 truncation 상황으로 인해 challenge하고, 특히 이는 실제 로봇을 조작하는 관점에서 중요한 문제입니다.
전통적인 방식은 이미지와 객체의 mesh 모델을 대응시키기 위해 hand-craft 특징을 추출하였으나, 사람이 경험적으로 디자인한 특징은 조명 변화나 심한 occlusion 상황에 제한적인 성능을 보입니다.(이러한 challenge한 상황을 모두 고려한 디자인이 어려움.)
이후 머신러닝과 딥러닝이 발전하며 DNN을 이용한 rotation과 translation을 직접 regression으로 예측하는 방식이 제안되었으나 이러한 방법론은 rotation 공간의 비선형성**으로 인해 좋지 않은 결과를 보여주었다고 합니다.
** S. Peng, Y. Liu, Q. Huang, X. Zhou, and H. Bao. Pvnet: Pixel-wise voting network for 6dof pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
최근에는 DNN을 통해 object의 2D keypoint를 추출한 뒤 PnP 알고리즘을 이용하여 6D 파라미터를 계산하는 연구가 있으며, 이러한 2-stage 방식은 안정적이지만 대부분 2D Projection을 기반으로 합니다. 그러나 이러한 projection을 활용할 경우, 투영된 공간에서는 작은 오차였으나 3D에서는 큰 오차일 수 있고, 또한 3D에서는 서로 다른 지점에 있던 keypoint가 projection되면서 겹쳐질 경우에는 이를 구분하기 어렵다는 문제가 발생할 수 있습니다. 게다가, 강체의 기하학적 정보가 projection으로 인해 사라질 수도 있다는 문제가 있습니다.

한편, 저렴한 RGBD 센서의 개발로 RGBD 데이터를 사용할 수 있게 되었고, depth 정보에 접근이 가능해져 2D 알고리즘은 3D 공간으로 확장하여 성능 향상이 가능해졌습니다. 저자들은 기존 연구의 한계를 극복하고자 depth 정보를 활용하여 2D keypoint 기반의 방법론을 알고리즘을 3D keypoint로 확장하여 기하학적 제약 정보를 활용하므로써 6D Pose Estimation 예측 정확도를 향상시키는 연구를 진행하였습니다. 조금 더 자세하게 설명을 하면, deep 3D keypoints Hough voting 네트워크를 통해 3D offset을 학습하고, 3D keypoint를 구하기 위해 voting을 수행합니다. (그림1을 통해 파이프라인 확인 가능.)
저자들은 강체의 두 포인트 사이의 거리는 유지된다는 간단한 기하학적 특성을 통해 객체 표면에서 관찰 가능한(occlusion되지 않은) 포인트가 주어졌을 때 depth 이미지에서 좌표와 방향을 얻을 수 있고, 이를 통해 선택한 keypoint의 translation offset은 고정되며 학습이 가능합니다. 또한, 포인트마다 유클리드 offset을 학습하는 것은 네트워크에게도 간단하며 최적화가 쉽다고 합니다.
또한, 여러 객체가 있는 경우를 해결하기 위해 instance segmentation 모듈을 추가하여 keypoint voting과 함께 최적화하였다고 합니다. 둘을 함께 최적화함으로써 두 task모두 성능 향상이 가능하였다고 합니다. 성능 향상이 되는 이유에 대해서는 우선 의미론적 정보를 keypoint voting에 제공함으로써 point가 어디에 속하는지 식별할 수 있도록 하여 translation offset의 학습을 개선할 수 있었고, 반대로 translation offset에 포함된 크기정보를 instance segmentation 모듈에 전달함으로써, 외관이 유사하지만 크기가 다른 객체를 구별할 수 있도록 하여 instance segmentation의 성능 향상이 가능했다고 합니다.
저자들은 YCB-Video와 LineMOD 데이터셋을 이용하여 방법론에 대한 검증을 하였고, 해당 논문의 contribution을 정리하면 아래와 같다고 합니다.
- RGBD 이미지에 대한 6 Pose Estimation을 위해 instance semantic segmentation과 함께 새로운 deep 3D keypoints Hough voting 네트워크 제안
- YCB-Video와 LineMOD 벤치마크에서 SOTA 달성
- keypoint 기반 방법론에 대한 심층 분석 및 이전 방법론과의 비교를 통해 3D keypoint가 pose 추정 성능을 향상시키는 핵심 요소임을 증명하고 3D keypoint와 instance segmentation을 함께 학습하면 성능 향상이 가능함을 보임.
Proposed Method
1. Overview
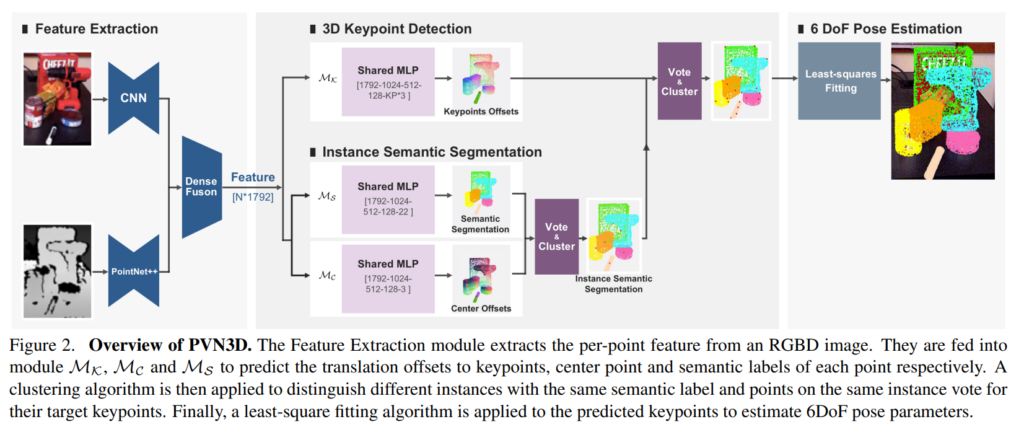
해당 논문에서는 deep 3D Hough voting 네트워크를 기반으로 하는 새로운 방법론을 제안하였고, Figure 2에서 확인할 수 있습니다. 제안된 방법론은 3D keypoint를 감지하는 모듈과 pose 파라미터 fitting 모듈이 있는 2-stage 방법론으로, RGBD를 입력으로 하는 featue extraction 모듈을 통해 외관 정보와 기하학적 정보를 융합합니다. 학습된 모듈에서 추출된 feature는 3D keypoint Detection 모듈인 \mathcal{M_K}에 입력되어 keypoint에 대한 포인트별 offset을 예측합니다. instance semantic segmentation 모듈인 \mathcal{M_S}를 통해 포인트별 semantic label을 예측하고, center voting 모듈인 \mathcal{M_C}를 통해 객체 중심에 대한 포인트별 offset을 예측합니다. 학습된 point-wise offset에 클러스터링 알고리즘을 적용하여 동일한 semantic label과 동일한 instance에 해당하는 point가 keypoint를 voting하도록 하여 서로 다른 instance를 구별하도록 합니다. 마지막으로 least-squres fitting 알고리즘이 예측된 keypoint에 적용되어 6D pose 파라미터를 추정합니다.
2. Learning Algorithm
3D keypoint Detection 모듈\mathcal{M_K}은 keypoint에 대한 offset을 예측하도록, segmentation 모듈\mathcal{M_S}와 center voting 모듈\mathcal{M_C}은 인스턴스 수준의 분할을 하도록 학습하며, 세 모듈을 함께 학습하는 방식은 multi-task learning으로 앞서 이야기하였 듯, 서로의 성능을 향상시키도록 서로 도움을 줍니다. 각 모듈을 학습하기 위한 loss 및 세부 사항은 다음과 같습니다.
3D Keypoint Detection Module
Figure 2와 같이 feature로부터 각 객체의 3D keypoint를 검출합니다. \mathcal{M_K}는 visible(이미지에서 확인 가능한) point에서 target keypoint 까지의 유클리드 offset을 예측하며, visible point는 예측된 offset과 함께 target keypoint를 voting하는 데 사용됩니다. voting으로 결정된 point는 클러스터링을 통해 모아져 voted keypoint로 선택됩니다.
visible seed point의 집합인 \{ p_i \}^N_{i=1}와 동일한 객체 인스턴스 I에 속하는 selected keypoint 집합인 \{ kp_j \}^M_{j=1}가 주어졌을 때, p_i=[x_i;f_i]로 x_i는 3D 좌표, f_i는 추출된 feature를 나타내고, kp_j = [y_j]로 y_j는 keypoin의 3D 좌표를 나타냅니다. \mathcal{M_K}는 각 seed point의 feature를 받아 seed point들에 대한 translation offset인 \{ of^j_i \} ^M_{j=1}를 생성합니다. 이때 of^j_i는 i번째 point의 j번째 keypoint까지의 translation offset을 나타냅니다. voted keypoint는 vkp^j_i = x_i +of^j_i 로 나타낼 수 있으며, offset을 학습하기 위해 L1 loss를 적용하여 학습을 할 수 있습니다.
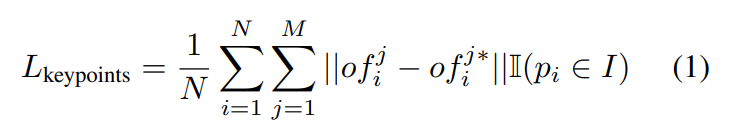
이때, of^{j*}_i는 GT offset을 나타내고 M은 selected target keypoint의 수, N은 seed point의 수를 나타내며, \mathbb{I}는 I 인스턴스에 해당하면 1, 아니면 0이 됩니다.
Instance Semantic Segmentation Module
여러 객체가 있는 경우를 해결하기 위해 기존 연구는 detection을 활용하거나 semantic segmentation을 먼저 적용한 뒤, 단일 객체만 포함되도록 RoI를 구하여 문제를 단순화 하는 방법을 활용하였다. 저자들은 segmentation 모델이 다른 객체를 구별하기 위해 global하고 local한 feature를 추출하도록 하면 keypoint를 찾는 데 도움이 되고, keypoint에 대한 offset을 예측하도록 하면 외관정보는 유사하짐나 서로 다른 크기를 가지는 객체를 구별하는 데 도움이 되므로 이 두 task를 함께 학습하고 최적화 할 경우 keypoint에 대한 offset을 예측하는 task와 instance segmentation의 성능이 모두 향상될 것이라 생각하여 multi-task learning 방식을 적용하였습니다.
- point별 feature가 주어졌을 때, instance segmentation 모듈인 \mathcal{M_S}는 point별 semantic label을 예측하고 이는 Focal loss를 적용합니다.(아래의 식2) 이때 \alpha는 balance 파라미터고 \gamma는 focusing 파라미터, c_i는 GT class를 one-hot-encoding하였을 때 i번째 class에 해당하는 포인트에 대한 예측 신뢰도를 나타냅니다.
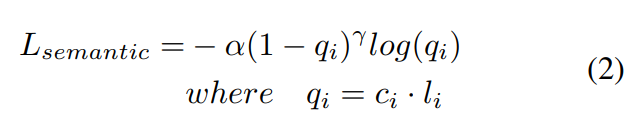
- center voting module인 \mathcal{M_C}는 서로 다른 instance를 구분하기 위해 서로 다른 객체의 center를 투표하도록 하며, CenterNet에서 영감을 받아 2D center를 3차원으로 확장하였다고 합니다. 2D center point과 다르게 3D center point는 일부 view-point에서는 occlusion되지 않으므로 중심점을 object의 특수한 keypoint로 볼 수 있으므로 \mathcal{M_C}는 3D keypoint detection 모듈인 \mathcal{M_K}와 유사하게 학습을 진행합니다. L1 loss를 이용하여 학습하며 아래의 식3이 이에 해당합니다. 이때, △x_i는 중심 객체에 대한 offset을 나타내고 *가 있으면 GT offset을 의미합니다.
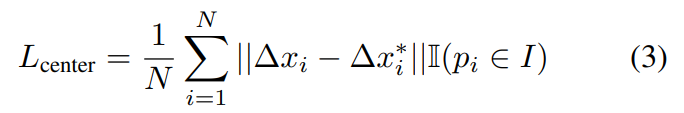
Multi-task loss
\mathcal{M_K}, \mathcal{M_S},\mathcal{M_C} 모듈을 함께 공동으로 학습하기 위해 아래의 식 (4)와 같이 loss를 합쳐 학습하며, \lambda_1,\lambda_2,\lambda_3은 각 task에 대한 가중치입니다.
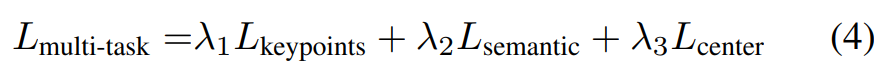
3. Training and Implementation
Feature 추출에는 이미지에 대해서는 ImageNet에서 사전학습된 ResNet34와 PSPNet을 이용하였고, depth 정보에 대해서는 PointNet++을 이용하였다고 합니다. 또한, \lambda_1,\lambda_2,\lambda_3=1로 설정하였다고 합니다.
keypoint selection은 PVNet에서 설명했듯이, 박스에 대한 8개의 모서리를 선택할 경우 객체와 떨어진 점을 keypoint로 활용하게 된다는 문제가 있어 객체 표면에서의 FPS 알고리즘을 적용하여 M개의 Mesh의 keypoint를 선택하였다고 합니다.
Least-Squares Fitting은 카메라 좌교계에서의 M개의 keypoint인 \{ kp_j \}^M_{j=1}와 그에 대응되는 object 좌표계에서의 \{ kp'_j \}^M_{j=1}가 주어졌을 때, 최적의 pose를 추정하기 위한 알고리즘을 적용하며, pose 파라미터 (R,t)를 계산합니다. 아래의 식을 통해 오차가 최소화되도록 R과 t를 구합니다.
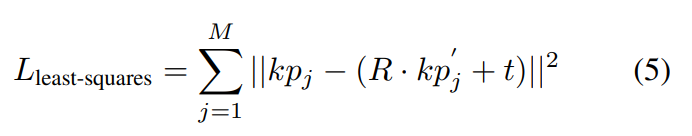
Experiments
Dataset
- YCB-Video
- 21개의 다양한 모양과 texture를 가진 YCB 객체의 장면을 캡쳐한 92개의 RGBD 비디오를 포함
- 비디오에 segmentation 주석과 6D Pose 주석을 달았음
- train set: 학습용 비디오 80개 & 8만개의 합성 영상
- test set: 12개의 비디오
- LineMOD
- 13개의 object가 포함된 데이터셋
- texture less한 물건, clutter한 장면, 조도 변화가 있어 복잡한 데이터 셋.
Metrics
- ADD(-S)
- ADD는 예측된 pose와 GT pose로 변환된 object point 쌍 사이의 평균 거리
- 대칭 및 비대칭 객체를 고려하여 평가하는 방식으로, 6D Pose Estimation에서 일반적으로 사용하는 평가지표
- 대칭 객체는 ADD-S로 평가하며, PoseCNN에 따라 ADD-S 곡선 아래 면적(AUC)을 리포팅 함.( AUC의 threshold= 0.1m)
- 로봇 조작에 대한 최소한의 허용 오차를 측정하기 위해 2cm 미만의 ADD-S 비율 리포팅
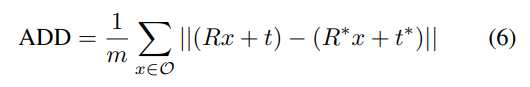
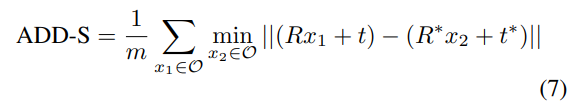
1. Evaluation on YCB-Video & LineMOD Dataset
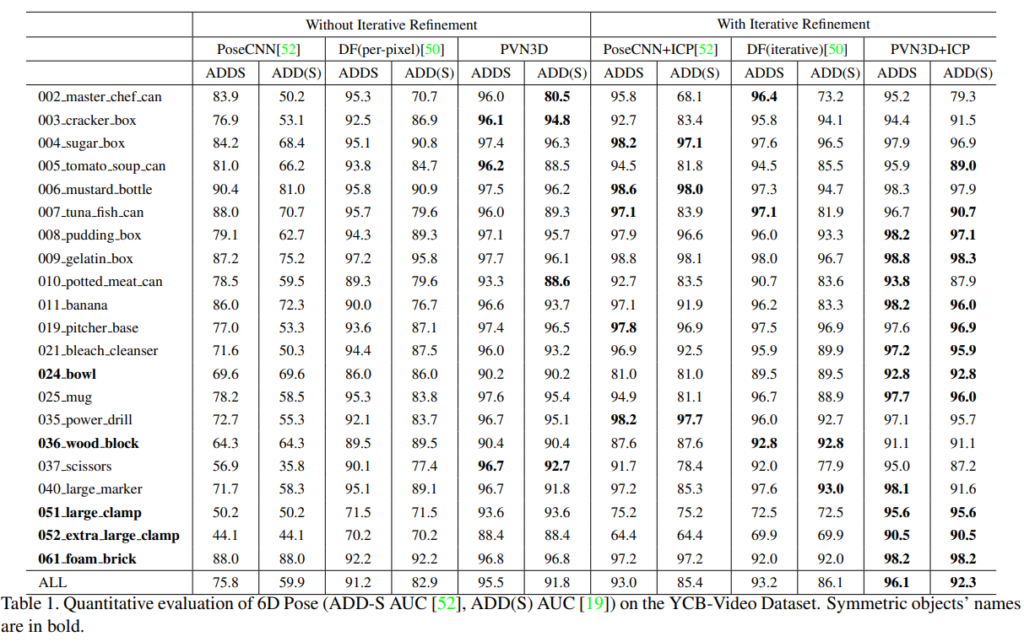
Table1은 YCB-Video에 대한 평가 결과로, 다른 단일 이미지에 대한 방법론과 비교하였을 때, refinement를 거치지 않은 PVN3D가 다른 기존 ㅂ낭법론들과 비교했을 때 최고의 성능을 나타내었고, refinement인 ICP를 적용할 경우에는 PoseCNN+ICP에 비해 +6.4%, DF(iterative)에 비해서는 + 5.7% 의 성능을 얻을 수 있었습니다.
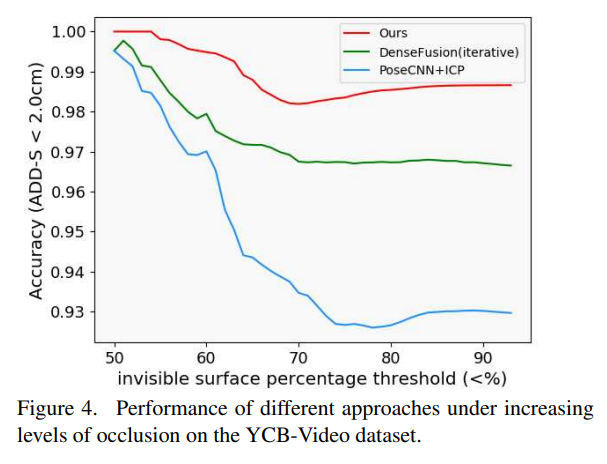
또한, Figure4르 통해 PVN3D가 다른 방법론들과 비교했을 때, occlusion이 심해져도 성능 하락이 적음을 확인할 수 있고 occlusion에 강인하다는 것을 보였습니다.
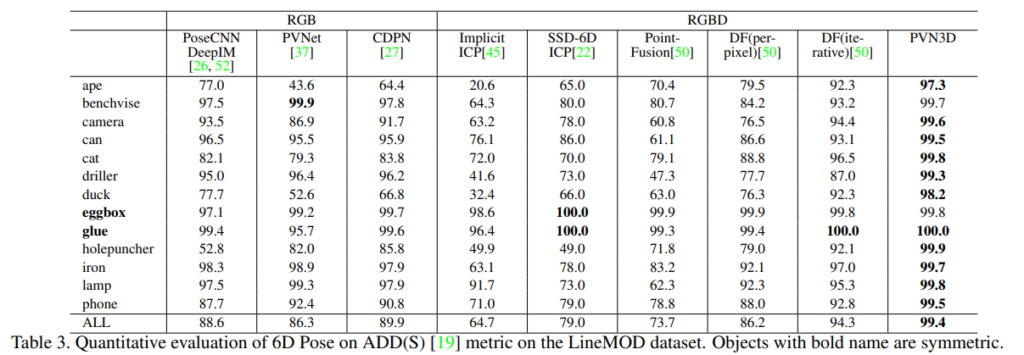
LineMOD에 대한 성능은 Table3을 통해 확인할 수 있으며 대부분의 객체에 대한 pose 추정 결과 PVN3D가 가장 좋은 결과를 보이을 확인하 수 있습니다.
2. Ablation Study
Comparisons to Directly Regressing Pose

입력으로부터 pose를 바로 예측하는 방법론과 3D keypoint를 이용하는 방법론의 성능을 비교하기 위한 실험결과는 Table 4에서 확인할 수 있습니다. RT는 직접 회귀로 구하는 방식, KP는 keypoint를 이용하는 방식을 나타내며, keypoint를 이용할 경우가 좋은 성능을 보임을 확인할 수 있습니다.
Comparisons to 2D Keypoints
또한, 2D와 3D Keypiont의 영향을 Table 4를 통해 확인할 수 있으며, ours(2D KP)와 ours(3D KP)를 비교했을 때, 상당한 성능 향상(13.7%)이 있음을 확인할 수 있습니다.
Effect of Multi-task learning
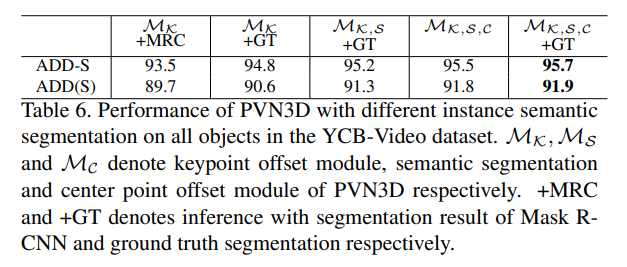
Multi-task learning의 효과는 위의 Table 6을 통해 확인할 수 있습니다. 모든 모듈을 함께 학습하였을 때 Pose 추정에서 최대 성능을 얻을 수 있었습니다.
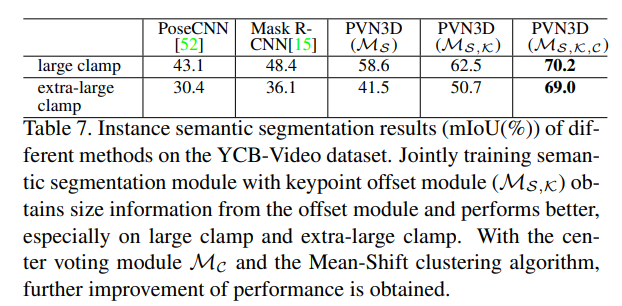
Table 7을 통해서는 keypoint와 center offset 학습이 instance semantic segmentation의 성능을 얼마나 향상시킬 수 있었는 지 확인할 수 있습니다. 모든 모듈이 함께 학습 된 경우에 모두 최대의 성능을 보였습니다.
이러한 실험을 통해 multi-task learning을 통해 서로의 성능을 향상시킬 수 있음을 확인하였습니다.
이상으로 리뷰 마치도록 하겠습니다.
좋은 리뷰 감사합니다.
translation과 같은 요소는 제가 알기로 물체마다 scale이 다르면 translation의 성능에 대한 불균형이 생기는 것으로 알고 있습니다.
제가 최근에 리뷰한 CDPN에서는 앞서 얘기한 translation은 scale에 대해 민감하므로 이런 문제를 해결하기 위해 제안된 SITE(Scale-Invariant Translation Estimation)과 같은 방법을 GDR-Net에서도 사용하였습니다. 해당 논문에서는 Deep 3D keypoints Hough voting을 통해 translation offset을 고정할 수 있는 기하학적 특성을 고려하여 학습이 가능 했기 때문에 해당 방법론을 통해 scale-invariant한 역할을 했다고 이해해도 될까요?
감사합니다.
논문에 명시적으로 scale invariant한 역할을 하기 위해 Deep 3D Hough voting 네트워크를 설계하였다는 내용은 없지만, 단순한 기하학적 특성(강체의 두 point는 거리가 유지된다는 것)을 활용하여 keypoint에 대한 포인트들의 offset이 유지된다는 점에서 말씀하신대로 scale-invariant한 역할을 한 것으로 보입니다.