오늘은 좀 신기해보여서 가져왔는데요. ICCV 2021에서 무려 Oral 받은 논문입니다. 신기했던 부분이 object detection과 segmentation에서 흔하게 할법한 self-supervised task를 부여하는 것이 아니라, representation learning의 관점에서 수행했을 때 성능이 더 좋았다는 논문입니다. 기존의 연구 결과와 달라진 부분이라 ORAL 까지 갔던 것 같습니다.
Introduction
Retrieval 관점이 아닌 논문은 간만인데요. Visual correspondence를 학습하면 다양한 computer vision task에 적용할 수 있습니다. 이러한 correspondence는 2가지 방향(Object-level correspondence, Fine-grained correspondence)으로 학습을 진행하고, video segmentation이나 object detection 같은 down-stream task에서 사용할 수 있습니다. 대략적으로 시각적 유사도를 활용할 법한 Task에서 사용한다고 생각하면 될 것 같은데요.
당연히 이런 연구들도 지도학습 기반으로 수행이 많이 되었습니다. 하지만 공통적으로 지적하는 데이터셋의 한계와 같은 문제들로 인해 self-supervised 연구가 주목받고 있는 상황입니다. Self-supervised를 수행하기 위한 가장 쉬운 방법은 temporal한 정보를 활용해서 가상의 GT를 만들고 이를 통해 학습하는 방법이 있습니다. 실제로 효율적이고, 많은 연구들이 이러한 방식을 사용하죠.
하지만… 이 논문 저자들은 2가지 질문을 던집니다.
- Correspondence를 학습하기 위해서, self-supervised용 object tracking task를 명시적으로 디자인할 필요가 정말 있을까?
- Correspondence를 학습하기 위해서, 이미지 수준 유사성 학습만으로 되는가?
우선, image-level similarity learning(contrastive learning 기반)이 많이 발전되어, semantic한 정보를 필요로 하는 다양한 downstream task에 잘 적용되고 있습니다.
이러한 연구 흐름에 따라 논문 저자들은 한가지 가설을 세우는데요. 만약 high-level feature가 semantic한 정보나 물체의 구조를 인코딩 한다면, 유사한 물체의 correspondence를 찾는 기능이 도움이 되어야한다는 것인데요. 결론적으로는 Convolution이 visual correspondence를 학습하게 된다는 건데요.
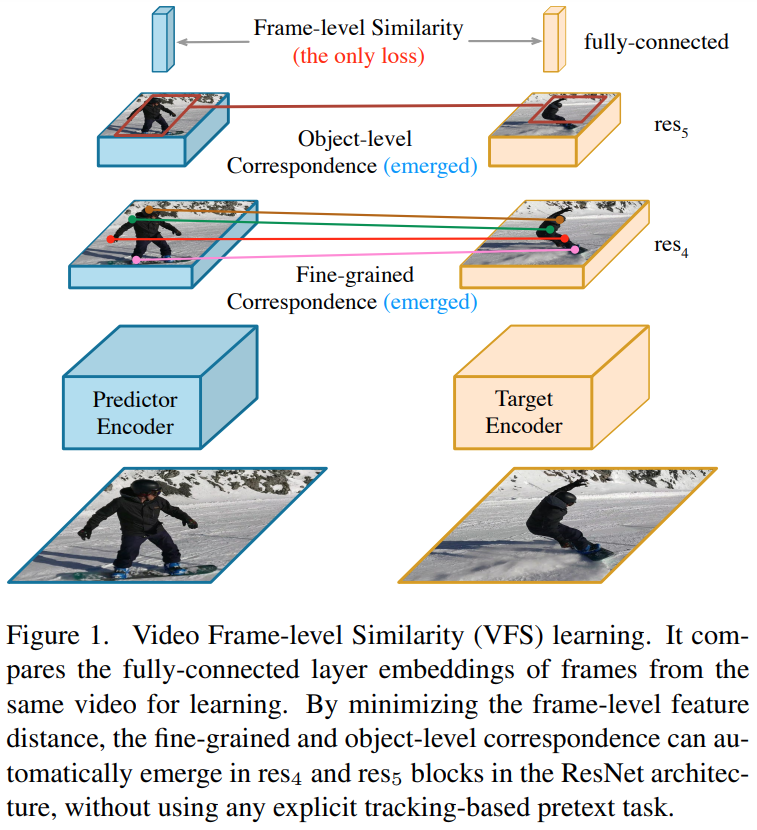
그리고 이 가설에 맞는 트래킹 기반의 pretext-task 없이 space-time correspondence를 고려할 수 있는 Video Frame-level Similarity(VFS) 학습 방식을 제안합니다. [그림 1]이 학습 방식에 대한 개략적인 내용을 담고있습니다. 학습은 영상 단위로 수행하지는 않고, 같은 영상 내의 프레임을 페어로 구성해서 입력으로 넣습니다. 그리고 이 두 프레임의 유사도를 계산하는 방식으로 모델을 학습합니다. 또 특이한점이 일반적으로 negative pair를 이용하는 contrastive learning이 많습니다. 근데 이 논문에서는 없는 상황에서도 학습을 수행했는데요. Downstream Task에서 어떤 경우에는 negative pair가 없을 때 성능이 더 잘 나오는 놀라운 결과를 확인할 수 있었습니다. 이렇게 설계한 VFS가 SOTA를 달성했고, 특이한 요소(?)들을 정리하면 아래와 같습니다.
- 더 넓은 간격으로 프레임을 뽑고, 여러개의 프레임 쌍을 구성하면 성능이 더 좋다.
- Finegrained correspondence를 학습할 때, color augmentation은 성능을 떨어뜨리지만, object-level correspondence에서는 성능이 오른다.
- Finegrained and object-level correspondences를 학습할 때, 네거티브 페어가 없는 경우가 더 성능이 좋았다.
- 더 깊은 네트워크가 더 확실한 성능 향상을 보였다.
Method
Background: Image-level similarity learning
논문에서는 이미지 기반 유사도 학습을 어떻게 수행하는지에 대해 대표적인 방식 2가지를 먼저 소개합니다. 먼저, negative sample과 함께 학습을 수행하는 contrastive learning 입니다. 특정 이미지에 여러 augmentation을 적용해 변형된 positive 이미지를 만들고, 아예 다른 이미지를 negative 이미지로 선정해서 학습하는 방식인데요. Positive 끼리는 가까워지고, negative는 멀어지도록 학습을 수행합니다.
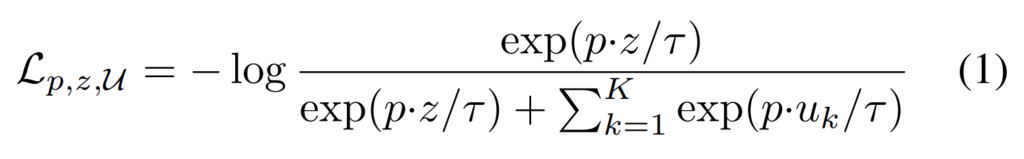
사실 많이들 이제 아실거라 간단히 설명하는건데요. [수식 1]과 같이 구성된 InfoNCE Loss가 대표적인 예시라고 볼 수 있습니다. 이 구조에서 Negative sample은 메모리 뱅크 방식으로 여러개를 한번에 사용하는데요. 이때, 단순하게 모든 feature들을 negative sample bank에 저장해두는 방식과 학습 과정에서 샘플링하는 방식으로 나뉘어집니다. 이 논문에서는 일반적으로 많이 쓰는 모멘텀 기반의 갱신 방식을 사용했다고 하네요.
또, 다른 방식으로는 negative 없이 유사도 학습을 수행하는 방식인데요. 2021년 논문임을 감안할 때, 당시에 이런 방식으로 꽤 높은 성능을 달성하고 있었던 기존 연구들이 있었다고 합니다. 이 점을 참고해서 보면 될 것 같고요.
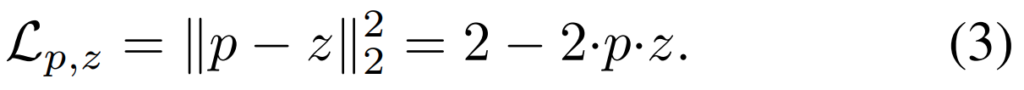
학습 자체는 [수식 3]과 같이 두 페어에 대한 cosine similarity를 계산하는 방향으로 학습을 수행할 수 있습니다. 하지만 이렇게 단순화된 학습은 feature representation 자체가 잘 학습되지 않는 방향으로 최적화가 수행될 수 있다고 합니다. 그래서 Predictor(Anchor) Encoder와 Target(Positive) Encoder의 파라미터를 공유하는 방식을 함께 쓰던가, target network의 loss는 back-prop되지 않게 하는 방식을 함께 쓴다고 합니다. 이 논문에서는 후자의 방식을 채용했습니다.
Video Frame-level Similarity Learning
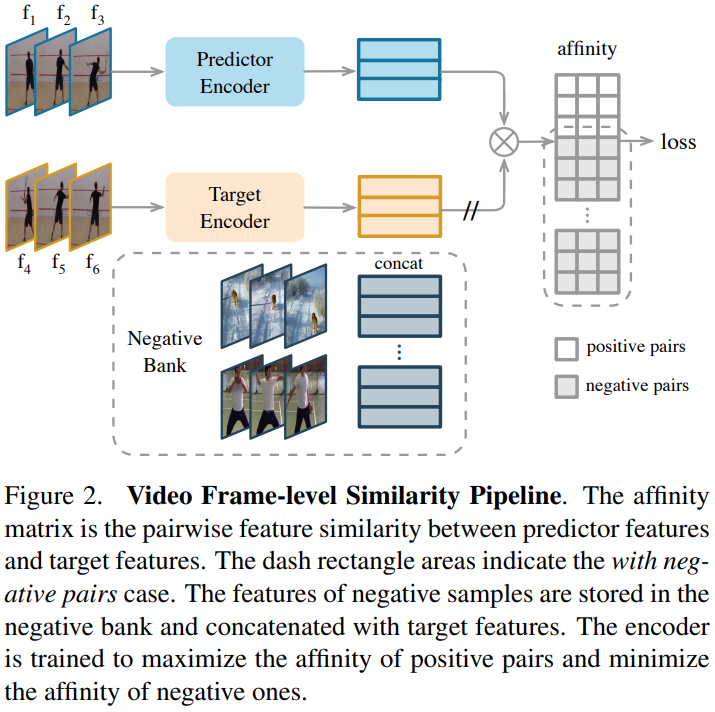
실험적인 증명 위주의 논문이라 모델 자체는 간단한데요. 구조 자체는 [그림 2]에서 확인할 수 있습니다. 길이 L의 영상에서 샘플링된 프레임 \{f_1, f_2, ...,f_L\}을 가지고 학습을 수행하는데요. Predictor Encoder와 Target Encoder에는 샘플링된 프레임 중에 랜덤으로 두 프레임을 고르고, augmentation을 적용해서 입력으로 넣어줍니다. 이때, Negative pair를 이용해 학습을 할지 말지에 따라 2가지 선택지가 존재하는데요. 만약 Negative가 있다면 [그림 2]의 similarity(Affinity) matrix를 계산할 때 Negative pair와의 유사도 값도 포함해서 Loss에 넣어주는 방식입니다. Loss 함수 자체는 Background에서 설명했던 것과 같이 두가지에 따라서 학습을 진행할 수 있습니다. 딱히 변경되는 부분은 없어서 추가로 설명하지는 않겠습니다.

L개의 프레임이 있는 비디오가 주어졌을 때, 이 비디오에서 n개의 프레임을 샘플링(\{I_1, I_2,...,I_n\}, where I_i \in [1,L]) 하는 방식에서 차이가 생길 수 있는데요. 이 때, 2개의 방식(Continuous Sampling, Distant Sampling)이 있을 수 있습니다. 이러한 샘플링 전략은 [표 1]과 [그림 3]에서 자세하게 확인할 수 있습니다.
먼저 Continuous sampling은 시작점으로부터 고정된 크기의 간격을 두고 프레임을 샘플링하는 방식입니다. 이 방식은 3D conv를 쓰는 방법론에서 흔히 쓰는 샘플링 전략으로 지역적인 특징을 학습하는데 장점이 있다고 하네요. 그리고 Distant sampling은 영상 자체를 n개의 세그먼트로 쪼갠 다음에 세그먼트 내에서 1개의 프레임을 임의로 고르는 방식입니다. 이 방식은 더 넓은 학습 커버리지를 가지면서, augmentation의 효과를 증대시킨다고 합니다.
Experiments
실험 결과를 보기전에 저도 잘 모르는 분야라 데이터셋 예시를 먼저 보고 넘어가겠습니다. 학습은 Kinetics로 했는데, 평가는 아래 두개의 데이터 셋에서 합니다.

DAVIS 데이터셋의 경우에는 segmentation용 데이터 셋이라고 보면 될 것 같고요.

OTB 데이터셋은 visual tracking용 데이터 셋인데. 위와 같이 사물이 있고 그 사물을 트래킹하는 연구라고 보면 될 것 같습니다.
Ablative Analysis
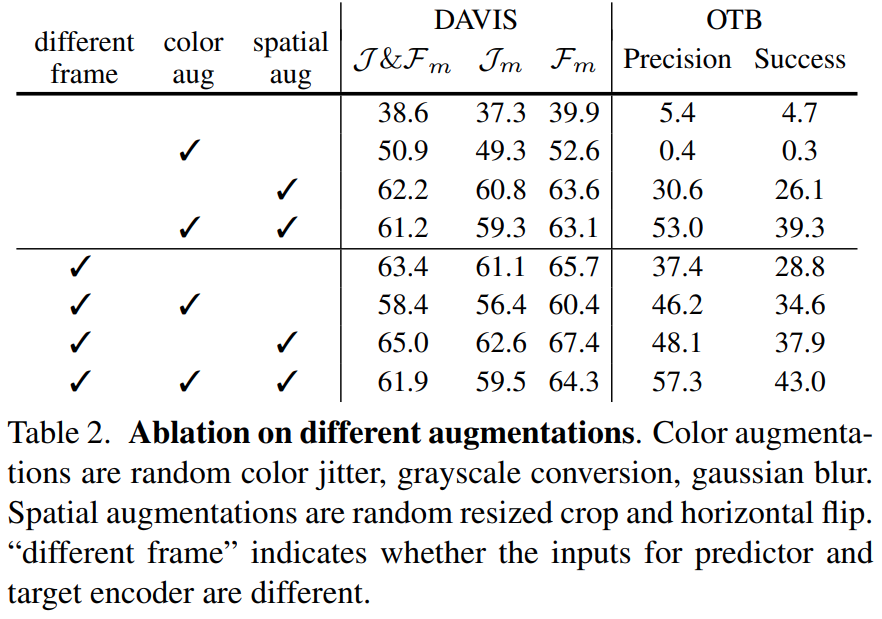
먼저 Augmentation에 종류에 따른 실험 결과입니다. Predictor 모델과 Target 모델에 같은 프레임을 입력으로 넣는 경우도 실험에 포함했는데요. “Color augmentation”의 영향력이 아예 정 반대의 결과를 내놓는 것을 볼 수 있습니다. Segmentation을 수행하는 DAVIS에서는 성능이 떨어지고, visual object tracking을 수행하는 OTB에서는 성능이 오르는 결과를 확인할 수 있었습니다. 논문 저자들도 이 부분에 대해서 VFS에서 color augmentation이 중요한 역할을 수행하고, fine-grained와 object-level correspondence에서 정 반대로 영향력을 미치는 것이라고 분석합니다.
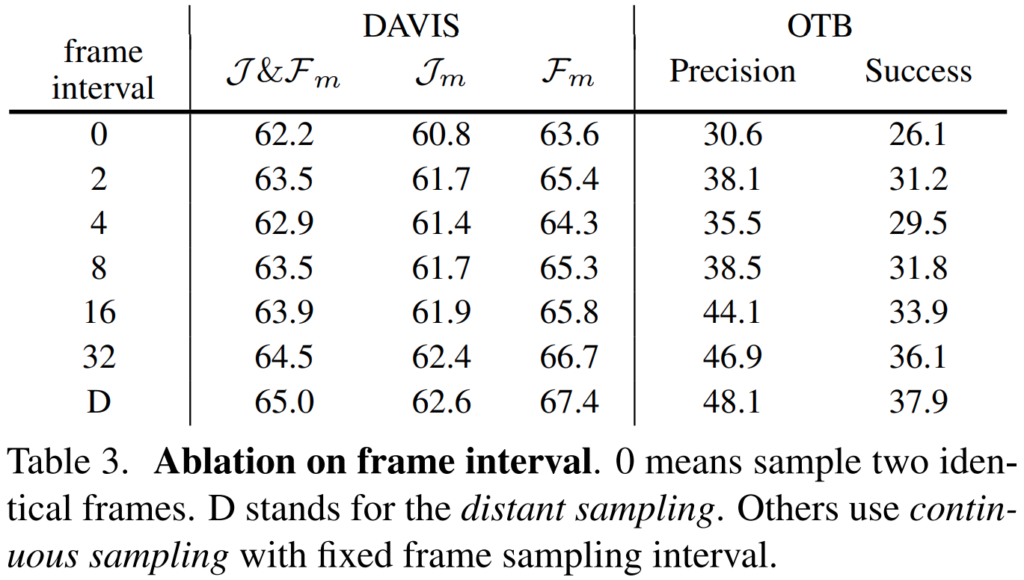
다음 실험은 프레임 샘플링 간격에 따른 성능입니다. [그림 3]에서 보여주는 두가지 방식에 대한 ablation결과인데요. 공통적으로는 distant sampling이 더 높은 성능을 보입니다. 사실 이러한 부분에 대해서는 다양한 연구가 비디오에서 Temporal한 정보를 활용하는 것이 좋다는 것을 입증하고 있는데요. 이 부분도 유사한 관점에서 생각해볼 수 있습니다. Distant sampling의 경우에는 영상을 더 넓은 커버리지를 가지도록 학습하기 때문에, Temporal한 정보를 더 활용한다고 생각해볼 수 있습니다.
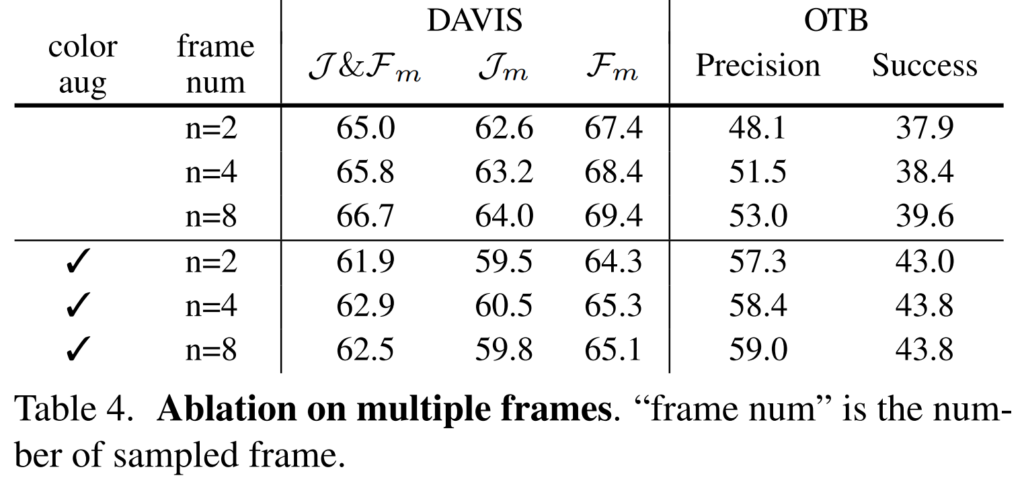
학습이 페어 단위로 수행되는데요. 이 페어에서 몇개의 프레임으로 구성할건지에 대한 실험 결과입니다. 더 많은 프레임을 한 페어에 구성해서 학습을 수행하면 성능이 더 좋다는 결과인데요. 제가 생각했을 때는 이 실험은 배치 크기가 클때의 장점과 동일한 장점을 가지기 때문에 이런 결과가 나오는 것 같습니다.
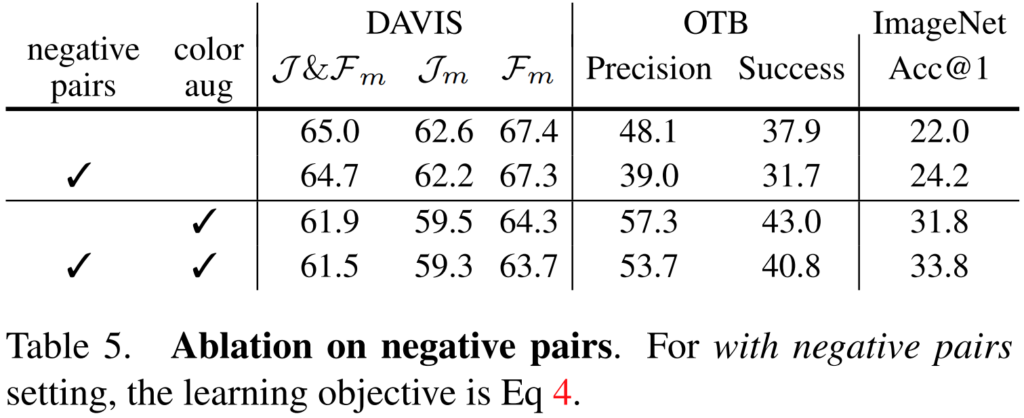
다음은 네거티브 페어의 존재 유무에 따른 실험 결과입니다. 이 실험이 사실 제일 충격적인 결과였는데요. 오히려 Negative pair가 있는 경우에 downstream task에서 성능이 떨어지는 결과를 보여주었습니다. 그럼 왜 이렇게 성능이 떨어질까요? Negative 페어가 있는 이유는 instance discrimination을 학습하기 위해 있습니다. 이 목적을 달성하기 위해 오히려 downstream task에서 필요한 cross instance discrimination을 위한 intra-instance invariance를 저해한다는 것인데요. 이에 대한 증명을 하기 위해 ImageNet에 대한 분류 정확도를 함께 보게 되면 오히려 성능이 오르는 것을 볼 수 있습니다. 즉, 실제로 이런류의 task에서는 오히려 negative 페어가 없는 것이 더 좋은 학습 결과를 이끈다는 것이죠.
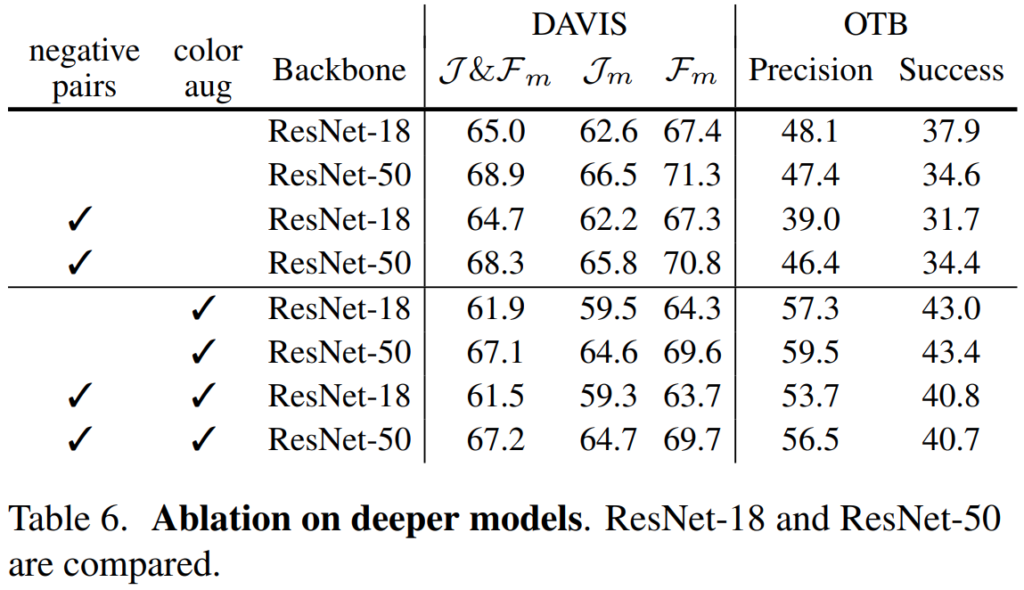
[표 6]은 더 깊은 모델이 더 좋은 성능을 가진다는 실험 결과인데요. 일반적으로 많이 알려진 부분이라… 자세한 설명은 넘어가겠습니다.
Comparison with State-Of-The-Art
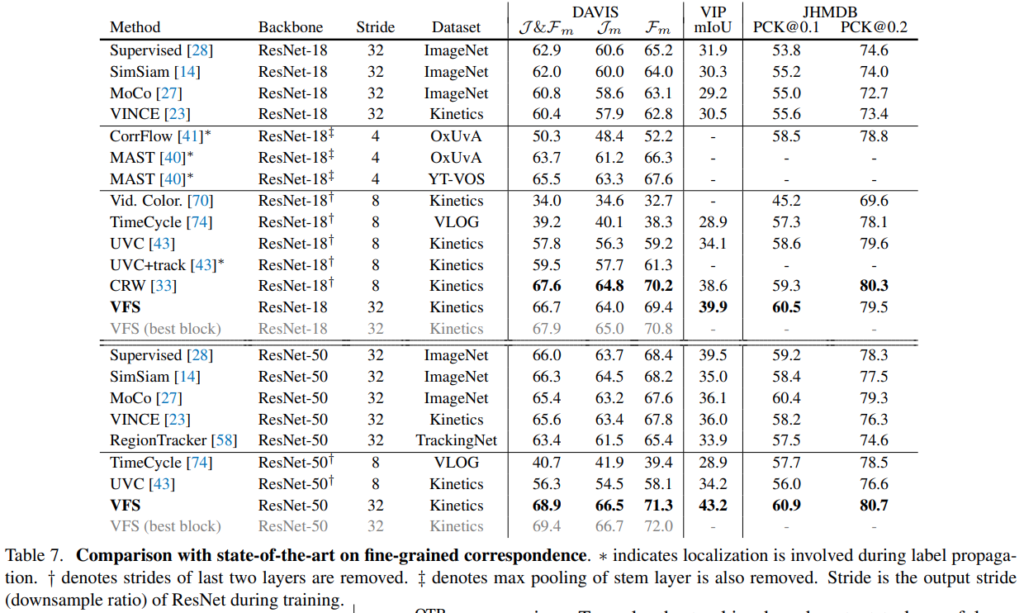
Fing-grained corresspondence(Segmentation)에서의 실험 결과가 조금 애매하긴 한데, Resnet50에서는 높은 성능을 보여줍니다. 문제는 CRW 성능이 살짝 문제가 있는 것 같습니다. 읽어보니 Resnet50으로 포팅하는 과정에서 랜덤보다 성능이 낮게 나오는 원복 이슈가 있었다는 것 같은데, 그래서 성능이 문제가 있다고 보는 것 같습니다. 이러한 점을 감안하고 성능을 보면… 충분히 높은 것 같습니다.
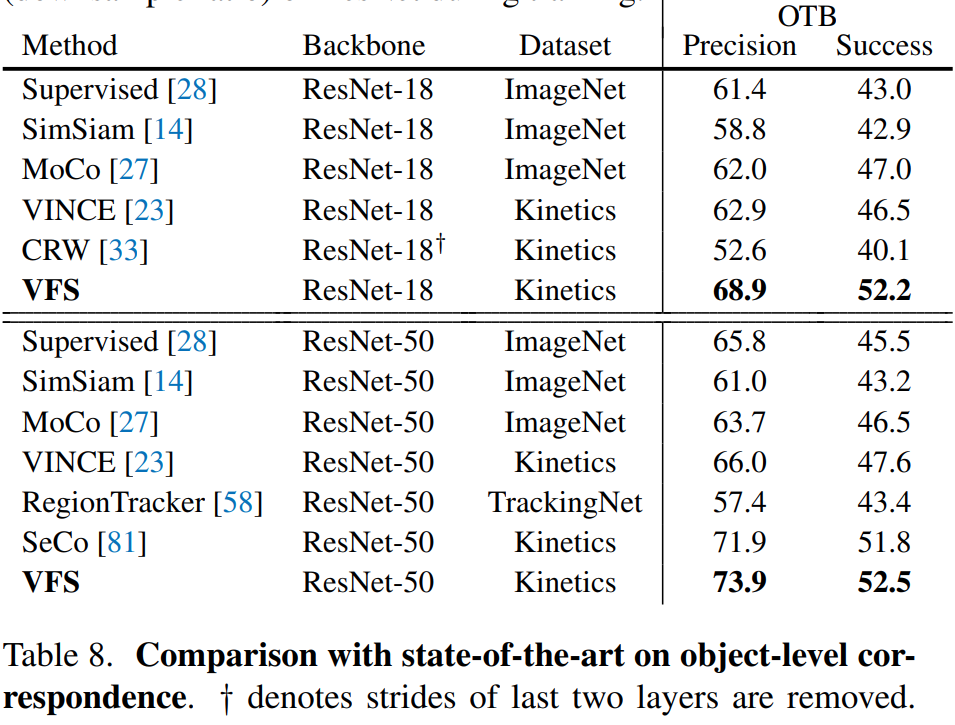
Object-level correspondence(Tracking) 실험 결과는 확실합니다. 확실한 성능 향상이 있었음을 보입니다.
Conclusion
고민할 부분이 상당히 많았던 논문 같습니다. Negative pair가 성능을 떨어뜨리는 부분 같은 경우에도 학습할 때, 분류 문제를 푸는게 아니라면 고민해볼 수 있는 부분 인 것 같다는 생각도 들었습니다. 더 의심하는 자세를… 가지면서 실험을 해야하지 않을까 싶네요.
안녕하세요 이광진 연구원님 좋은 리뷰 감사합니다.
이해가 안되는 건 직접 물어보면서 답변을 들을 수 있으니 도움이 많이 되네요 ^^
마치 self-supervised learning 중 BYOL 처럼 Positive pair 만을 가지고 비디오에서의 태스크를 수행한 것 같네요. (비교 실험에 MoCo도 있는데 이건 없는건 좀 아쉽네여 ㅎ)
궁금한 게 하나 있는데 프레임을 뽑을 때, Distant sampling 즉 널찍널찍하게 뽑는게 왜 더 성능 향상에 도움이 되는 건지 궁금한데 알려주실 수 있나요?
이게 그림을 보면 쉬운데… 그림이 안올라가는 상태라 설명이 좀 복잡하네요. 요약해서 설명하면 비디오는 인접한 프레임들끼리 유사도가 높죠? 그래서 anchor-positive로 가까운 프레임을 뽑게되면 애시당초 유사도가 높은 프레임들이 선택되어 학습을 수행하기 됩니다. 모델이 배울 것이 없는거죠. 이러한 맥락에서 적당히 넓은 간격으로 뽑으면 비교적 차이가 나는 프레임들이 뽑히게 되기 때문에 성능 향상에 도움이 됩니다.
좋은 리뷰 감사합니다.
궁금한 것은 Positive Pair만 가지고 학습하는 Loss를 수식3에서 설명해주신 것 같은데 단순환된 학습이 정확히 무엇을 의미하는 것인가요? Loss 수식이 간단하기 때문이가요? 아니면 Gradient 관점에서 뭔가 다른 이유가 있나요?
그리고 이러한 문제를 해결하기 위해 target network의 loss는 back-prop되지 않게 하는 방식을 사용한다고 햇는데 어떻게 이러한 방법이 단순화된 학습 방식을 해결할 수 있는지 궁금합니다.
첫번째 질문은 저자들은 negative가 있어야하는 infoNCE 방식의 방법론에 비해서 구조가 단순해서 그렇게 표현한 것 같네요.
두번째 질문은 이미지 기반 self-supervised 방법론에서 많이들 쓰는 방식을 채용한 것 같습니다. Target(Positive) 이미지에 대해서도 모델을 학습하게 되면 overfitting되는 문제가 있어서 그렇게 하는 것 같다고 추정중입니다.
안녕하세요 좋은 리뷰 감사합니다.
좋은 표현력을 학습하기 위해 predictor와 target encoder의 가중치를 공유하며 학습하는 방식과 target의 gradient를 끊는 방식 중 후자를 선택했다고 적혀있었습니다.
그런데 파라미터의 학습 관점에서, predictor와 target encoder가 동시에 좋은 표현력을 학습해가며 서로 다른 image에 대해 유사한 표현력을 가질 수 있도록 최적화가 진행되면 더욱 좋을 것 같다는 생각이 들었습니다.
target의 gradient를 끊은 뒤 predictor만 파라미터를 갱신하게 되면, 학습하지 않은 target encoder와 유사한 표현력을 갖게 되는데, 이것이 유의미할 수 있는 이유에 대해 질문 드리고 싶습니다.
두 모델이 weight를 공유하고 있기 때문에, 그 부분에서는 문제가 없습니다. 오히려 augmentation된 이미지를 학습을 안하는 것에서 더 자연스러운 분포를 학습하는 방향 같기도 하고요. 자세한 내용은 이미지 기반 self-supervised 에서 쓰는 방식이니까 그쪽 참고해도 좋을 것 같네요.