소개
최근 Self-supervised Learning(SSL) 분야는 다양한 비전분야의 응용문제(downstream vision tasks)에서 좋은 퍼포먼스를 보이고 있다. 현재 SSL분야는 크게 두 가지 접근법으로 발전하고 있다: Instance Discrimination(ID), Masked Image Modeling(MIM). ID는 보통 이미지간의 관계를 이용한 SSL 학습법으로 동일 이미지에 대해 다른 augmentation을 적용하여 생성한 multi view 이미지를 이용해, 같은 이미지로부터 생성된 두 이미지의 임베딩 공간상의 거리를 가깝게, 다른 이미지로부터 생성된 이미지의 임베딩 특징량(feature)와의 거리는 멀도록 거리를 이용해 학습하는 방법론이다. 반면 MIM의 경우 이미지 내 정보를 학습하는데 유용한 방법론이며, 일부가 가려진 이미지(masked images)를 원본 이미지로 재건(reconstructs)하는 과정을 통해 모델을 학습하는 방법론이다. Contrastive Learning, Asymmetric Networks, Feature Decorrelation으로 대표되는 ID 방법론의 경우 이미지 간의 관계(inter image relationship)를 잘 학습하는 반면 이미지 내부의 정보에 대한 표현력인 spatial sensitiveity는 부족하다. 반면 Masked Auto Encoder(MAE)로 대표되는 MIM 방법론의 경우 이미지 내 정보(Intra image)에 대한 표현력은 좋으나 이미지 간의 관계를 고려하지 않기 때문에 semantic alignment에 약점이 있다.
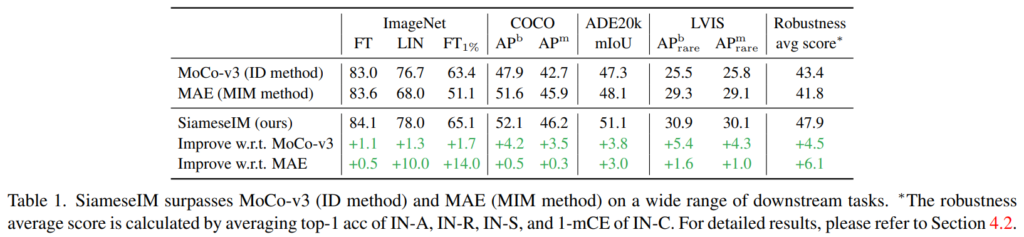
본 논문에서는 semantic alignment와 spatial sensitivity를 모두 갖출 수 있는 방법론으로 Siamese Image Modeling(SiamesIM)을 제안한다. semantic alignment를 위해 multi view이미지를 프레임워크의 학습에 사용하며 spatial senectivity의 향상을 위해 MIM에서 영감을 받은 이미지 reconstruct방식을 도입하였다. 그 결과 Table 1에서 확인할 수 있듯이 다양한 벤치마크에 대해 대표적인 ID 방법론인 MoCo-v3와 대표적인 MIM 방법론인 MAE보다 우수한 성능을 보였다. 또한 few-shot, long-tail 시나리오에서도 우수하게 작동한다고 하니, 학습 메커니즘을 어서 알아보자.
방법론
[프레임워크의 구성]
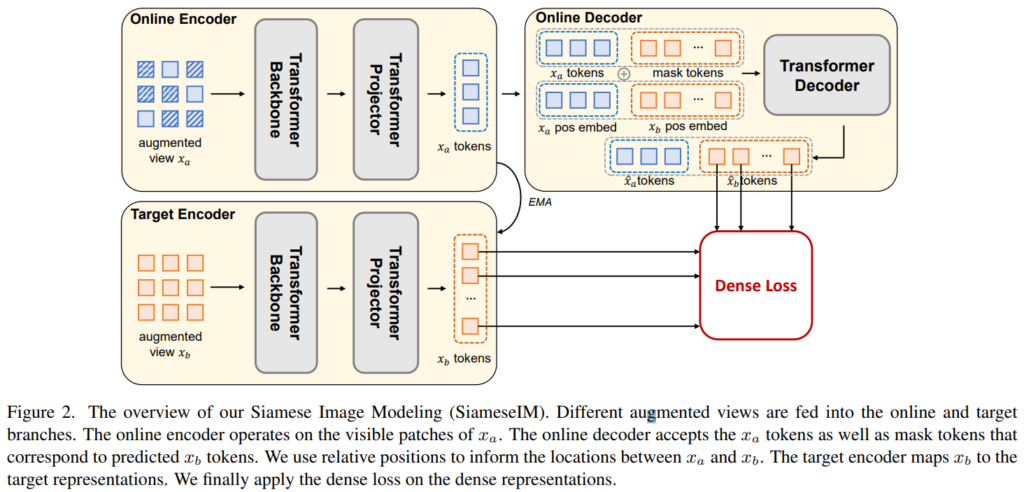
SimasesIM의 전체적인 구조는 Figure2와 같다. Siamese라는 이름처럼 두 개의 브랜치(Online branch, Target branch)로 구성된다. 이는 multi view를 이용하는 SSL 방법론에서 많이 사용되는 구조이다. Online branch는 Online encoder와 Online Decoder로 구성되어있고, Target branch는 Momentum encoder(Encoder network의 파라미터를 Exponential Moving Average, 이하 EMA 방식으로 업데이트하는 구조를 의미한다. 보통 Teacher model의 학습을 통해 Student model을 업데이트 할 때 사용하는 방법론이다.)로 구성된다. 또한 Encoder는 그림에서 확인할 수 있듯이 Backbone과 Projector로 구성되는데, 학습 시에 모든 구조를 활용하지만 Pre-training 과정이 끝나면 Downstream evaluation을 위해서는 online encoder의 Backbone만을 사용한다.
[프로세스]
학습 시에는 동일한 이미지를 통해 생성한 두 multi view이미지, xa와 xb를 각 브랜치에 입력으로 한다. Online branch의 입력이 xa라 할 때, Online encoder는 xa를 latent representation으로 임베딩하며 Online decoder는 이를 이용해 xb의 latent representation을 예측한다. 이때 xa와 xb간의 관계성을 임베딩한 벡터를 decoder의 입력으로 받는다. Target branch는 xb를 입력으로 하며 Online encoder의 파라미터를 닮아가도록 학습하는 EMA 기법을 통해 파라미터가 업데이트된다. Online encoder를 통해 xb의 latent representation 을 생성하며 Online decoder로 예측한 xb의 latent representation과 Target encoder로 생성한 실제 xb의 latent represntation이 유사해지도록 목적함수를 구성하여 학습이 진행된다.
또한 multi view image 생성을 위해 color augmentation을 포함한 spatial augmenation을 이용하였으며 online branch의 입력에는 masked augmentation 또한 적용하였다. 또한 뒤의 ablation study에서 제안하는 augmentation의 유효성을 입증하였다.
[Multi view간의 Position embeding 방법]
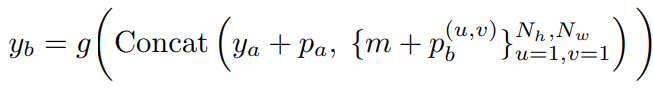

xa로 부터 xb의 latent representation을 예측하기 위하여 online decoder는 xa의 latent representation 뿐 만 아니라 xa와 xb의 position 정보를 입력으로 받는다. 수식1에서 확인할 수 있듯이 Online decoder, g는 ya의 latent representation과 그 position 정보인 pa, 그리고 mask token에 대한 latent representation과 이에 xb의 position 정보를 더한 값들을 이어 붙인 벡터를 입력으로 한다. 이는 Figure2의 Online decoder 그림과 같이 보면 더 명확하게 이해가능 하다. latent representation은 이미지를 encoder에 입력하여 얻을 수 있는 출력값이라면 position 정보는 어떻게 구성될까? 이는 [46]에서 제안한 positional encoding 방법을 따랐다고 한다.
어떤 이미지 x로 부터 두가지 view인 xa와 xb를 만들었을때, 이 위치를 표현하는 방식이며, 두 view를 생성하는 방법이 의존적인것은 아니다. xa의 positional embeding 표현을 기준으로 xb의 positional embeding을 생성하므로서 두 벡터의 관계를 효과적으로 나타낸 것이 특징이며 수식은 아래와 같다.
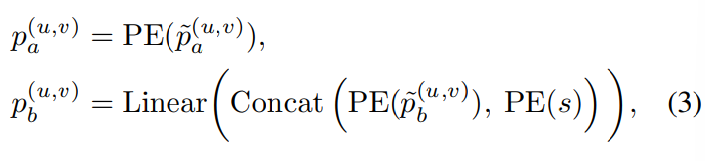
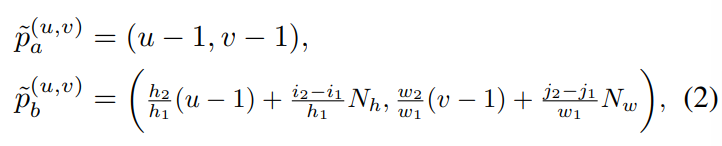
u와 v는 각각 hight와 width 차원에 대한 위치 index라고 하는데, 즉, Figure3의 xa의 모서리 좌표중 하나를 의미한다. 다만 u와 v값에 -1을 취해 이미지 내부의 점을 이용한 것에 대한 추가 설명은 없어 본 리뷰에서는 해당 내용을 포함하지 못했다. 간단히 이해하자면 Figure3에서 처럼 xa의 한 모서리 점을 원점(0,0)으로 하고 xa에 (u-1, v-1)과 대응하는 xb 상의 점을 해당 좌표계를 이용해 pb로 표현한 것으로 이해하면 좋겠다.
[Loss 함수]
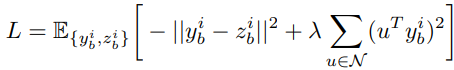
SimasesIM의 학습을 위한 Loss 함수는 위의 같다. yb는 online branch로 생성한 예측값이며 zb는 타겟브랜치로 생성한 positive sample에 대한 representation이다. 또한 수식4의 시그마의 변수로 있는 N은 target branch로 생성한 negative sample들에 대한 representation 집합이다. UniGrad[43]라는 방법론에서 고안한 loss함수이며 InfoNCE loss와 유사하게 작동한다. 즉, yb가 다른 negative sample들보다 positive sample의 임베딩값인 zb와 가장 유사해지도록 loss가 구성되었다. 이때 i는 각 이미지의 인덱스를 의미한다.
실험
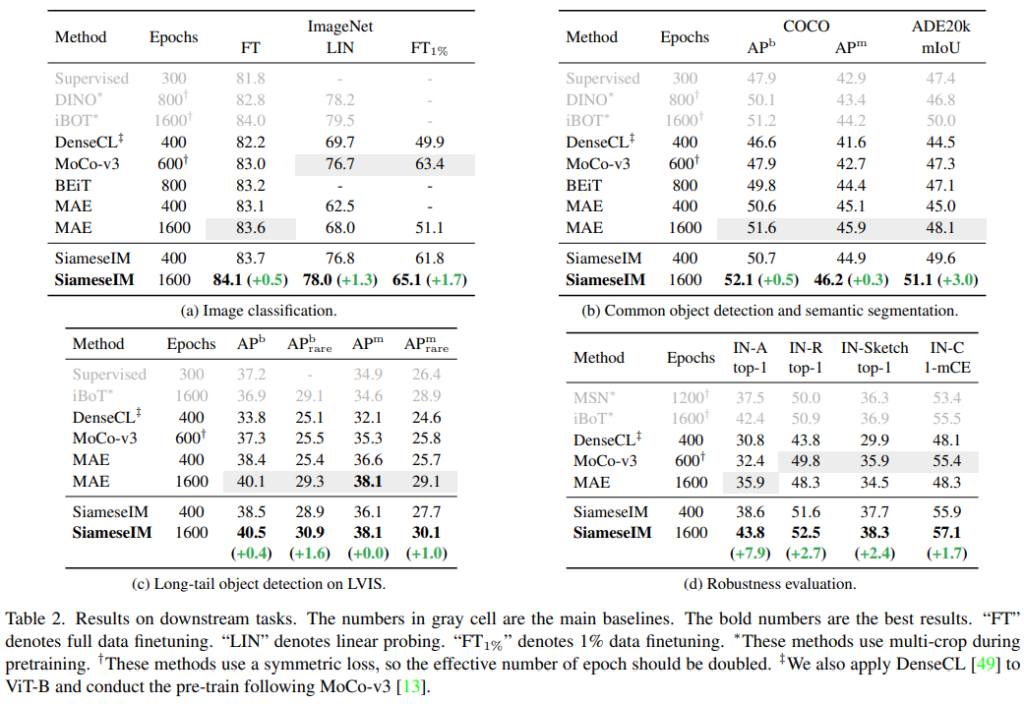
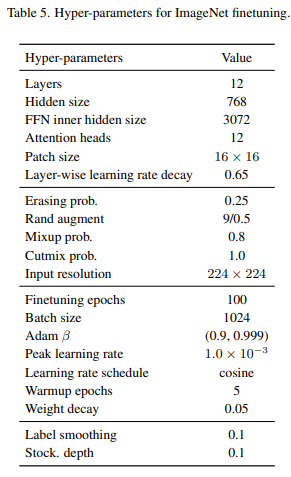
먼저 Main Results로 Image classification, Object detection, Semantic Segmentation, Long-tail version Object detection(hard case)와 같은 다양한 테스크에 대한 실험결과를 Table2에서 제공하여 제안하는 방법론의 우수성과 강인함을 보였다. 실험은 앞서 말한것처럼 전체 프레임워크를 통해 MoCo-v3와 같은 세팅을 이용해 ImageNet 데이터셋으로 pre-training 한 이후 Online encoder의 Backbone network만을 이용하여 fine-tuning 한 결과이다. full data를 이용한 fine tuning 결과 뿐 만 아니라 1% 데이터만 이용한 few-shot learnig setting에 대한 실험도 제공한다. fine tuning을 위한 세팅은 MAE와 같으며 자세한 Task networks에 대한 구성이 아래 예시와 같이 appendix에 공개되어 있다.
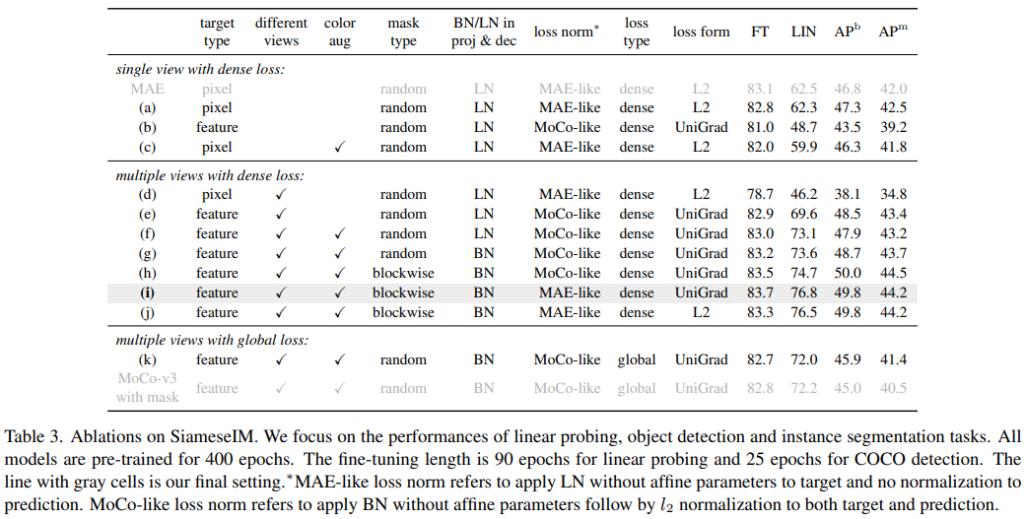
다음으로 Table3의 Ablation Study를 통해 다양한 분석을 제공했는데, color, make, multi view augmentation의 사용에서부터 normalization methods, loss function 등 다양한 요소에 대하여 실험해, 제안하는 구성의 효과를 보였다. 먼저 color augmentation의 경우 기존 MIM 접근법에서는 효과가 좋지 않아 사용하지 않았는데 분석결과 ID에서 사용하는 Multi view를 활용한 학습에서 효과가 있는것으로 확인되어 제안하는 SiameseIM은 color augmentation도 multi view 이미지 생성 시 도입하였다. 또한 Mask augmentation을 위한 mask type 등을 실험을 통해 가장 SiameseIM 세팅과 적합하도록 구성하였다.
참고
[43] Exploring the equivalence of siamese self-supervised learning via a unified gradient framework
[46] Repre: Improving self-supervised vision transformer with reconstructive pretraining
좋은 리뷰 감사합니다.
영상 내 특징 학습 능력이 좋지만 구분 능력이 상대적으로 부족한 MAE와 기존 방법을 융합한 SSL 기법인 것까지는 이해했습니다.
근데 이를 수행하기 위해 Multi view간의 Position embeding 부분이 중요해 보이는데… 어떻게 하는 건지 이해가 안되는 것도 문제인데 이렇게 복잡하게 하는 이유도 이해하기 힘들어서 추가적인 설명 부탁드릴까요?
spatial augmentation 때문인가요?
positional embeding 시 view에 대한 파라미터가 서로 의존적인 정보를 갖도록 하기 위해 Figure3의 파란색 view를 나타내는 파라미터를 이용해 주황색 view에 대해 표현한 수식입니다. self-learning에서는 종종 공유하는 정보에 대한 모델 예측의 강인성을 높이기 위한 설계를 진행하는데, 이러한 학습을 위해 위와 같은 positional embedding 방식을 제안한 것으로 이해했습니다. 감사합니다.