이번에 소개할 논문은 ICRA2023에 게재된 Self-supervised Depth Estimation 분야 논문입니다. 학회장에서 돌다가 보았던 논문 중 하나인데, 논문의 컨셉 자체가 나쁘지 않아서 읽고 리뷰하고자 합니다.
Intro
일단 해당 논문은 위에서도 설명드렸다시피 Self-supervised Monocular Depth Estimation 방법론에 대한 논문입니다. Self-supervised Monocular Depth Estimation이 어떻게 학습하는지에 대해서는 제 예전 Depth 리뷰 혹은 가장 최근에 작성한 리뷰글을 참고하시면 좋을 것 같습니다.
아무튼 간략하게만 소개드리면 두 카메라 사이에 외부 파라미터(Rotation & Translation) 정보와 target frame의 깊이 정보 그리고 카메라의 내부 파라미터만 있으면 target frame을 source frame으로 변환(warping)을 할 수 있으며 이러한 warped target frame과 실제 source frame 사이에 픽셀 오차를 계산함(Photometric Loss)으로써 어떠한 Depth GT 없이 모델은 학습을 할 수 있게 됩니다.
여기서 중요한 점은 Self-sup 학습 시 목적 함수로 사용되는 Photometric Loss가 사실 완벽한 목적함수가 아니라는 점입니다. 그 이유로는 학습에 사용되는 입력 데이터가 보통 비디오 프레임(t-1, t, t+1 시간대에 서로 다른 프레임을 의미), 혹은 스테레오 이미지(Left, Right Images)를 활용하게 되는데, 이러한 데이터들은 시간대 혹은 시점이 서로 다른 이미지들이기에 영상 내 동일한 대상이라고 할지라도 시각적으로 다르게 보이는 경우가 많습니다.
보다 구체적으로, 동일한 사람을 촬영했다 하더라도 시점에 따라서 대상의 밝기가 달라질수도 있고, 혹은 occlusion 등이 발생하여 보이지 않는 경우도 발생하게 될 것입니다. 이러한 경우에는 Depth Network가 완벽하게 Depth map을 추론한다 하더라도 Photometric loss 값이 크게 나올 수 밖에 없습니다.
반면에 예전에도 설명드렸다시피 Textureless한 영역에 대해서는 warped region과 실제 region 사이에 뚜렷한 특징 차이가 없기 때문에 완벽하게 warping이 되지 않더라도 photometric loss 값이 작게 계산되는 경우가 종종 발생합니다.

이해가 잘 되지 않으신 분들은 그림 1을 참고하시면 좋을 것 같습니다. 실제 Depth map과 relative pose 값이 잘 추론이 되었다면 warped source pixel(보라색 네모)는 target pixel(노란색 별)과 동일한 위치에 정합이 맞아야만 하지만, 초기 모델 학습에는 당연히 잘못된 깊이와 relative pose 값이 추론될 수 밖에 없기 때문에 그림1과 같이 보라네모와 노란 별이 정합이 맞지 않는 상황이 자주 연출됩니다.
하지만 이러한 경우에도 불구하고 둘 사이에 뚜렷한 특징 차이가 존재하지 않는, 즉 textureless한 상황이기 때문에 단순 픽셀 값의 오차를 계산하는 photometric loss는 작은 값으로 계산되는 것이죠.
아무튼 Photometric loss는 Self-supervised Monocular Depth Estimation의 핵심 목적 함수이긴 하지만, 위에서 언급한 문제들로 인하여 깊이 추정 네트워크의 성능 한계가 발생한다는 것이 해당 논문 외에도 예전부터 여럿이 언급되어 왔습니다.
따라서 본 논문에서는 이러한 Original Self-Sup 학습 방법이 아닌 새로운 학습 방법을 제안하고자 합니다. 저자가 제안하는 학습 방식의 핵심 요소는 바로 사전 학습된 FlowNet을 통해 stereo pair에서 추정한 optical flow 정보를 활용하자는 것입니다.
사실 Stereo Image에서 추론한 optical flow는 Disparity Map이랑 다를 것이 없습니다. 왜냐하면 source frame을 기준으로 target frame 내 대응되는 지점까지 가려면 몇 픽셀 움직여하는지 이동벡터를 계산하는 것이 Optical Flow의 목적이며, Stereo Image에서 Left Image와 Right Image 사이에 대응관계가 x축을 기준으로 몇 픽셀 차이나는지 시차를 의미하는 것이 Disparity Map이기 때문에 stereo image 사이의 optical flow는 disparity와 동일합니다.
그래서 처음에 Optical Flow를 사용한다고 들었을 때는 크게 기대가 되지는 않았습니다. 그냥 Disparity map을 Distillation하겠다는 거겠거니 하고 너무 단순한 컨셉이라고 생각하였기 때문이죠.
하지만 본 논문에서는 제법 재밌게도 단순히 DepthNet의 결과와 FlowNet의 결과값을 Distillation하는 것 뿐만 아니라 기존 Warping 개념을 접목시켜 둘 사이에 Photometric loss를 계산하는? 나름 재밌는 학습 방식을 고안합니다. 이에 대한 자세한 얘기는 바로 아래에서 다루도록 하겠습니다.
Method
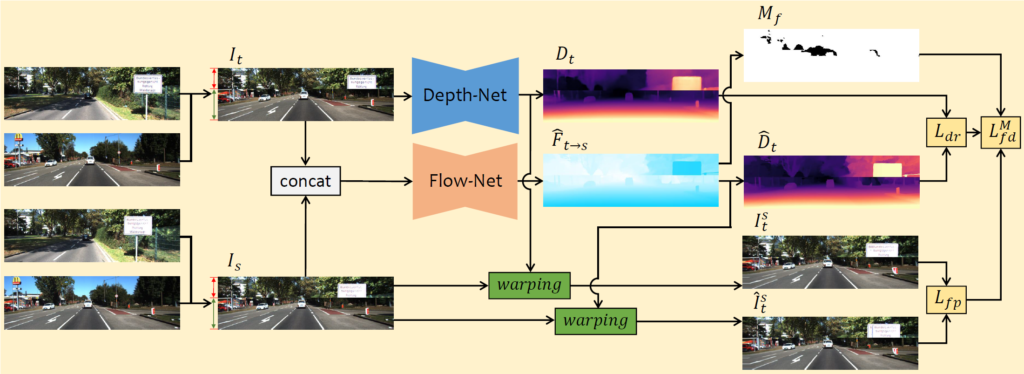
그림2는 논문의 전체 파이프라인을 나타낸 것입니다. 먼저 맨 좌측에 영상이 4개나 있는데 서로 다른 장소에서 촬영한 영상의 상단과 하단을 이어붙여서 새로운 합성 데이터를 만드는 Data augmentation 관점에서 무언가가 하나 존재하는 것 같습니다.(이것은 논문의 핵심 컨트리뷰션은 아니어서 그냥 두 영상으로 새로운 장면의 영상을 만들었구나~ 생각하시면 좋을 듯 합니다.)
아무튼 데이터 증강기법이 적용되어 Source frame( I_{s})과 Target Frame(I_{t})을 구할 수 있다면, 단일 영상을 입력으로 하는 DepthNet에는 target frame 영상만을 입력으로 하여 Depth을 추론하고, source와 target frame 쌍을 입력으로 하는 FlowNet에서는 두 영상 사이에 Disparity map을 추론합니다.
그럼 이러한 Disparity map을 내부파리미터와 외부파라미터를 활용해 Depth map으로 변환하여 DepthNet의 Depth map과 비교하는 loss를 계산할 수 있으며 추가로 각 네트워크에서 구한 추론 값들을 통해 source frame을 warping하여 두 warping image 사이에 photometric loss를 계산하는 방식으로 학습을 하게 됩니다.
Flow Distillation Loss
위에 설명에 대해서 수식적으로 조금 더 접근을 해보죠. 먼저 저자가 제안하는 Flow Distillation Loss는 다음과 같이 구성이 되어 있습니다.
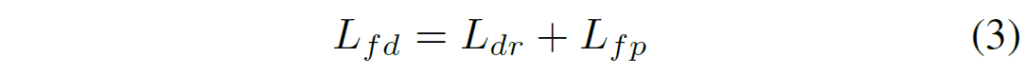
여기서 L_{dr}, L_{fp} 는 각각 Depth Regression loss와 Flow-guided Photometric loss를 의미합니다. Depth Regression loss는 아래와 같이 계산이 될 수 있습니다.
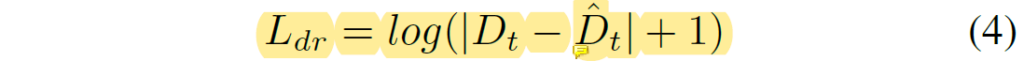
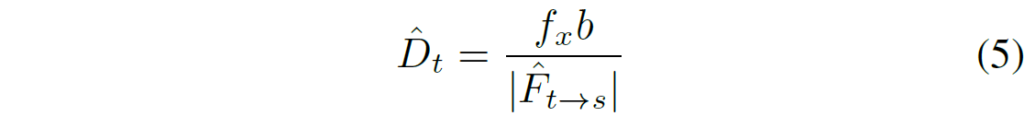
여기서 D_{t}, \hat{D}_{t} 는 각각 DepthNet의 결과 및 Pseudo Depth map을 의미하며, 이 때 \hat{D}_{t} 는 focal length와 baseline 그리고 FlowNet에서 추론된 Disparity Map을 통해 계산이 가능합니다.
즉 Depth Regression Loss는 DepthNet의 output과 pretrained FlowNet의 Pseudo GT를 서로 비교하는 loss다 라고 생각하시면 될 것 같습니다.
다음으로는 제가 생각했을 때 이 논문에서 가장 중요한 contribution으로 보이는 Flow-guided Photometric loss에 대한 설명입니다. 사실 컨셉 자체는 굉장히 쉽습니다. 바로 아래 수식과 같이 DepthNet으로 추론한 Depth 결과로 warping한 source image( I_{t}^{s} ) 그리고 FlowNet의 결과로 warping한 source image( \hat{I}_{t}^{s} ) 사이에 Photometric loss를 계산하는 것입니다.
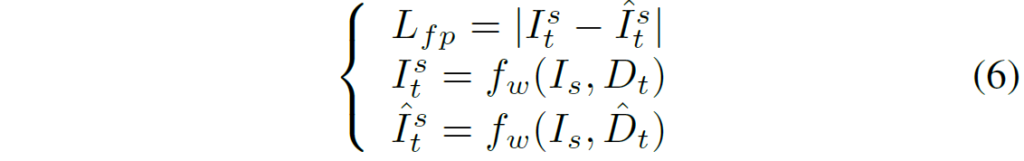
이렇게 계산하면 좋은 점이, 사실 Photometric loss의 계산 방식( 두 영상 사이에 픽셀 값 차이) 자체에는 크게 문제가 없습니다. 다만 두 영상이 촬영된 시점 및 시간대가 다른 경우에 이러한 warping을 통해 비교를 하는 계산 방식 자체가 여러 문제점을 야기했던 것이죠. (즉 완벽하게 Depth를 계산하더라도 결국 완벽한 warping을 수행할 수 없다.)
따라서 저자는 FlowNet에서 계산한 Disparity map과 DepthNet의 추론 값이 서로 동일하다면 동일한 source image에 대하여 각 네트워크의 추론 값으로 warping 시켰을 시 두 warped image 사이에 photometric loss가 0이 될 것이라는 것에 주목하였습니다.
이러한 학습 방식은 결국 동일한 warping이라는 개념을 활용한다 하더라도 시점과 시간대가 동일한 source image를 활용했기 때문에, 영상에 occlusion 혹은 시점 차이에 따른 밝기 변화로 인한 photometric loss의 문제점은 극복할 수 있을 것입니다. 다만 한가지 아쉬운 점은 결국엔 textureless한 영역에 대해서는 이 방법으로도 완벽하게 해결할 수 없다는 점이 있겠네요.
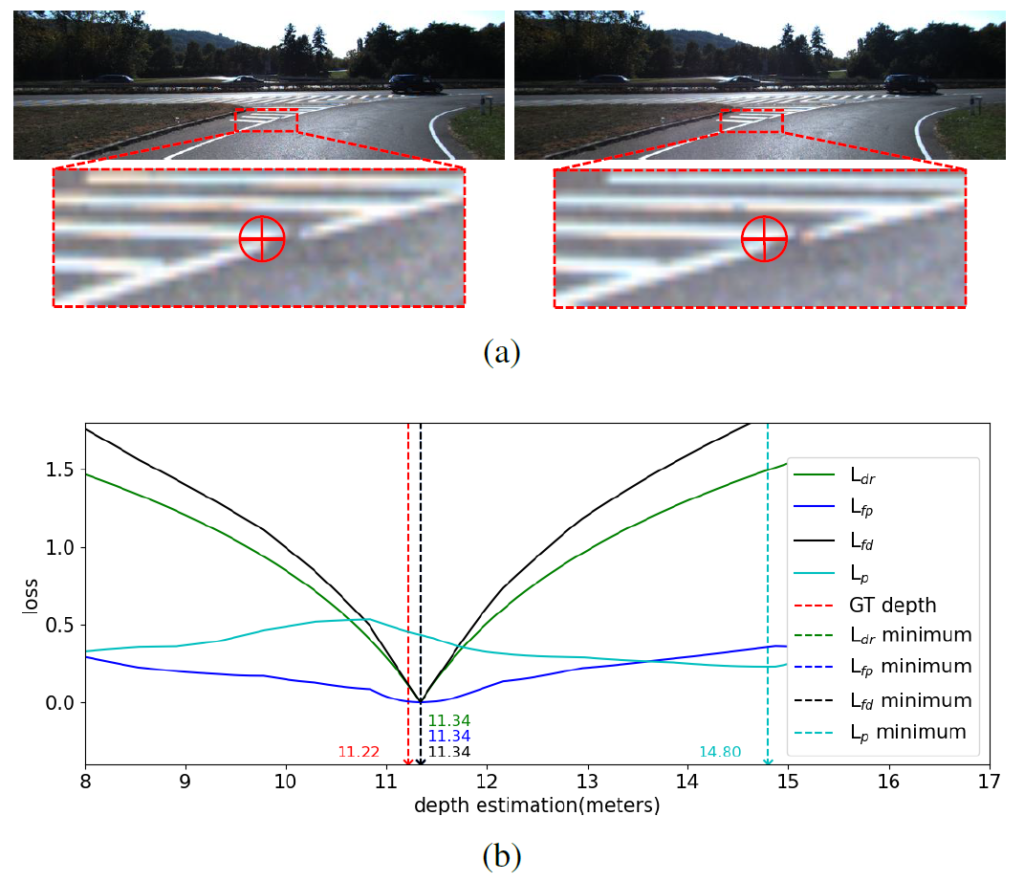
아무튼 저자는 그림3의 b를 통해 자신들이 제안하는 loss가 기존 photometric loss보다 더 좋다라는 것을 주장합니다. 사실 이 그림3-b를 어떻게 해석해야하는지, 어떻게 구했는지 등이 논문의 설명만으로는 부족해서 완벽하게 이해하지는 못했습니다만, 일단 제가 이해한 내용을 바탕으로 설명드리면 그림3-a에서 볼 수 있듯이 두 스테레오 영상 사이에 대응 픽셀들로부터 Depth Estimation과 Loss의 상대적 관계를 b 그래프로 나타낸 것이라고 합니다.
여기서 GT Depth는 11.22m에 해당하게 되는데 loss가 가장 최소가 되는 Depth의 지점이 Flow-guided Photometric loss, Depth Regression loss, Flow Distillation loss 모두 11.34미터로 실제 GT 11.22m와 상당히 근접한다는 점을 저자는 주장하고 있는 듯 합니다.
반면에 기존 Photometric loss의 경우에는 실제 정답 GT와 가까운 11.22m 부근에서는 오히려 loss 값이 상당히 큰 편에 속하고 14.80m일 때 가장 작은 loss 값으로 수렴하게 됩니다. 즉 Photometric loss가 가장 작아진다 하더라도 이것이 항상 올바른 Depth와 귀결되는 것이 아니라는 것이죠.
아무튼 저자는 이처럼 자신들이 제안하는 loss function들이 가장 최소가 되는 지점이 실제 GT Depth와도 유사하다는 점을 들면서 본인들이 제안하는 학습 방식을 사용하면 모델이 정확한 깊이 추정을 학습할 수 있다고 주장합니다.
Prior Flow based Mask
다음은 Optical Flow 분야에서 많이 활용하는 Flow based Mask 방식에 대한 설명입니다. 사실 해당 기법은 기존 Optical Flow 분야에서 사용하고 있는 occlusion 제거 방식을 그대로 차용한 것 같은데, 저자는 Depth 분야에서 해당 기법을 적용한 것에 대해 contribution이 있다는 식으로 주장을 합니다.
일단 이 마스크의 역할에 대해서 소개드리면 Target frame에서 Source frame으로의 변환을 가능케하는 flow map이 일정 range를 벗어나게 되면 그 값들을 제거해버리는? 마스크라고 생각하시면 됩니다.
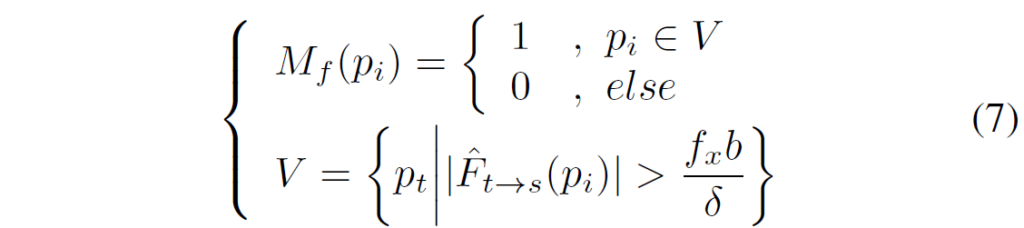
논문에서는 델타 값을 80으로 둠으로써 FlowNet으로 추정된 결과값이 Disparity가 80을 초과하는 영역들에 대해서 제거해버리는 마스크를 위 수식을 통해 생성합니다.

위에 그림의 b는 기존 monodepth2의 auto masking 기법을 통해 계산된 마스크를 의미하며 c는 Flow based mask를 의미합니다. 기존 autuomasking 전략은 하늘과 같이 Depth가 무한이 되는 영역에 대해서 제대로 마스킹을 해주지 못하는 반면에 Flow based masking은 거리가 상당히 큰 영역에 대해서 잘 처리를 해둔 모습입니다.(실제 하늘 말고도 저 멀리있는 집도 제거된 모습이네요.)
이러한 마스킹을 적용해준다면 모델 학습에 당연히 유용할 것 같습니다만, 본인들이 제안한 것이 아닌 기존 다른 분야에 있는 기법을 그대로 차용했기 때문에 조금 아쉽기는 합니다. 하지만 다른 분야에서 좋은 결과를 보여주었다는 점에서 조금의 contribution은 인정해주어야 할 것 같습니다.
Experiments
그럼 실험 섹션 다루고 리뷰 마치도록 하겠습니다.
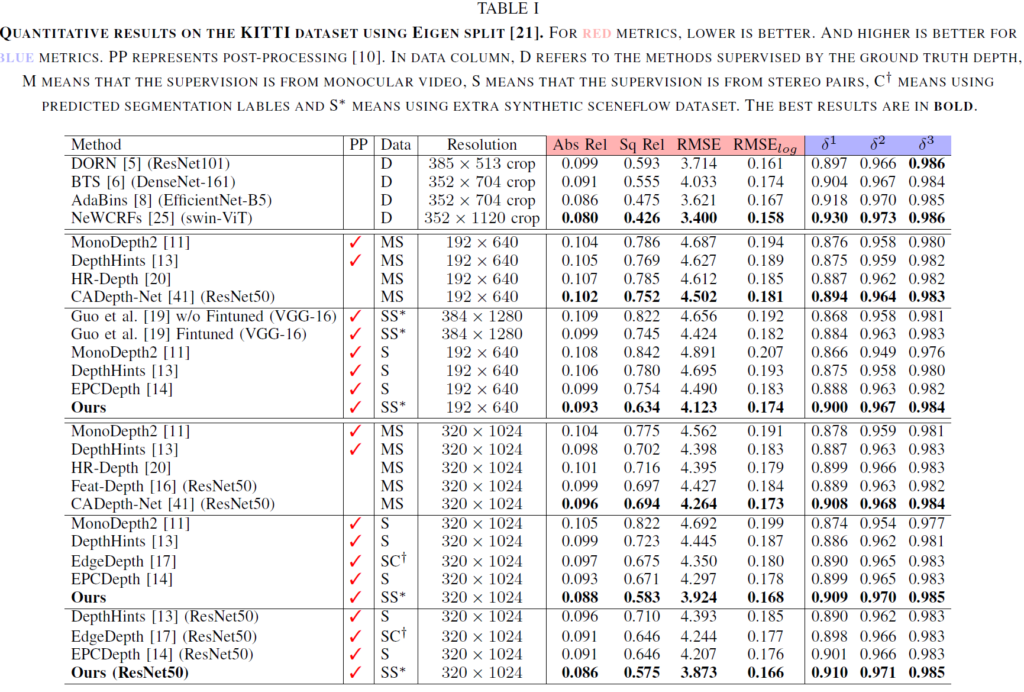
위에 캡션에서도 볼 수 있다시피 D는 supervised learning, M은 Monocular Video, S는 Stereo pair를 활용한 결과, S*은 Scenflow Dataset으로 사전학습된 FlowNet을 활용한 결과입니다. 그리고 C는 Segmentation Label을 활용한 것이라고 하네요.
핑크색 색상이 칠해져 있는 컬럼들은 값이 낮을수록 좋은 평가 메트릭이며, 보라색?은 값이 높을수록 좋은 메트릭입니다. 일단 보시다시피 저자가 제안하는 방법론이 동일한 입력 해상도 관점에서 가장 좋은 모습들을 보여주고 있습니다만, 사실 이러한 결과는 당연할 수 밖에 없다고 생각이 들긴 합니다.
가장 좋은 비교 대상들이 EPCDepth 정도인 것 같은데, EPCDepth는 Stereo image만을 활용하지만, 저자는 Pretrained FlowNet을 활용하고 있기에 추가적인 데이터 및 정보들이 활용이 됩니다. 따라서 Stereo Data만을 활용한 방법들보다는 월등이 좋을 것이라고 생각하고 있으며 그나마 재밌는 점은 EdgeDepth라는 방법론이 Pretrained Segmentation Network를 활용한다는 점인데 Segmentation보다 FlowNet을 활용하는 것이 깊이 추정에 더 좋은 성능을 보여준다는 점?이겠네요. 물론 그것도 어찌보면 당연한 결과일 것 같습니다. Segmentation보단 Optical Flow가 Depth Estimation과 더 유사한 task이기 때문이겠죠.
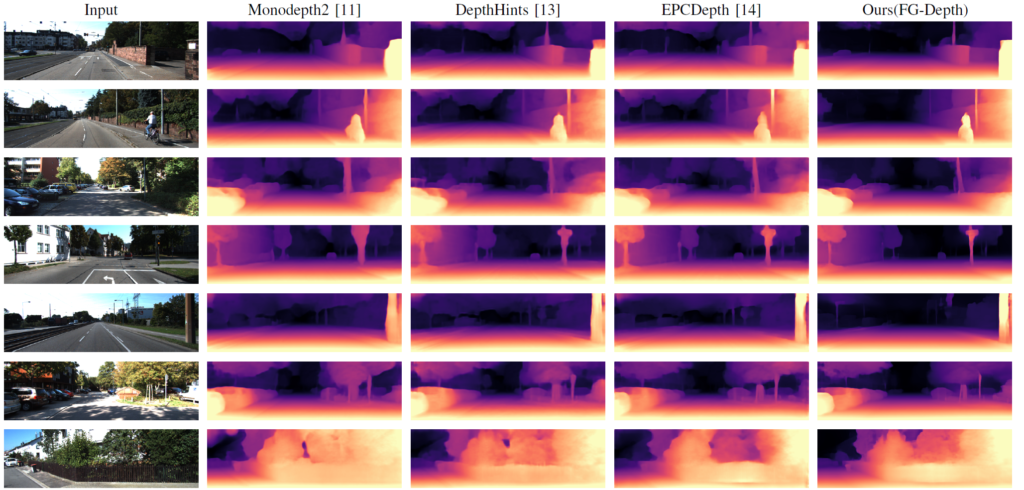
다음은 정성적 결과입니다. 사실 정성적 결과에서는 특출나게 저자가 제안하는 방법론이 더 예쁘다라는 인상을 받기는 어렵습니다. 그래도 한가지 재밌는 점은 다른 방법론들은 하늘에 해당하는 부분에 미세하게 깊이를 추론하는 반면에 저자가 제안하는 방법론은 Flow based Mask 덕분인지 하늘 혹은 상당히 멀리 있는 대상에 대해서는 일절 깊이를 추정하지 않는 모습입니다. 그래서 깊이 감에 대해 더 잘 표현이 되는 느낌이 들긴 합니다.
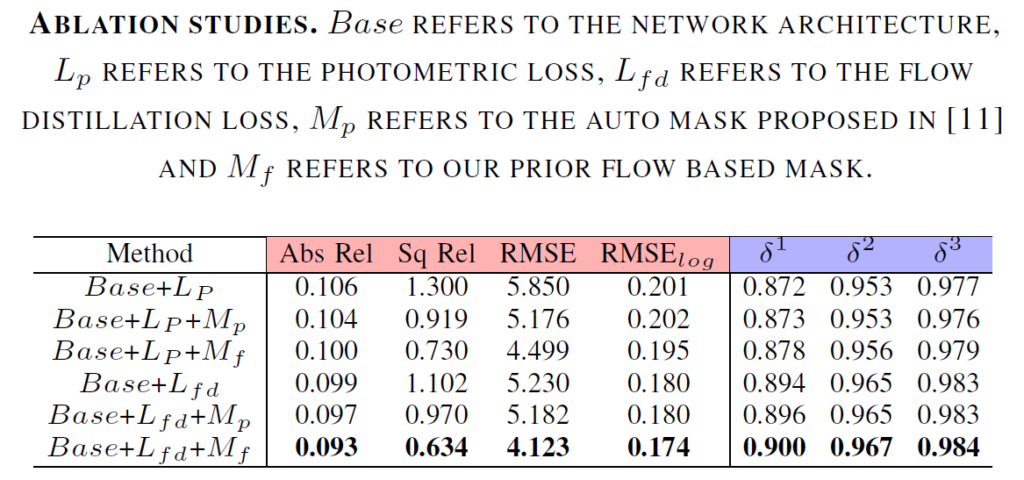
위에는 baseline을 기준으로 저자가 제안하는 loss function 및 flow based masking 활용에 대한 성능 향상을 본 것입니다. 보시다시피 기존의 automasking을 통해 계산된 M_{p} 역시 모델 학습에 중요한 효과를 보여주고 있는 것이 맞습니다.
하지만 기존 마스킹 전략을 Flow-based Masking으로 대체하게 될 경우( M_{fp}) 얻을 수 있는 성능 이점이 상당히 커지는 것을 확인할 수 있습니다.(2-3행) 그리고 저자가 제안하는 FLow-Distillation Loss를 활용하게 되면 상당히 큰 성능 향상을 또 볼 수 있었네요.
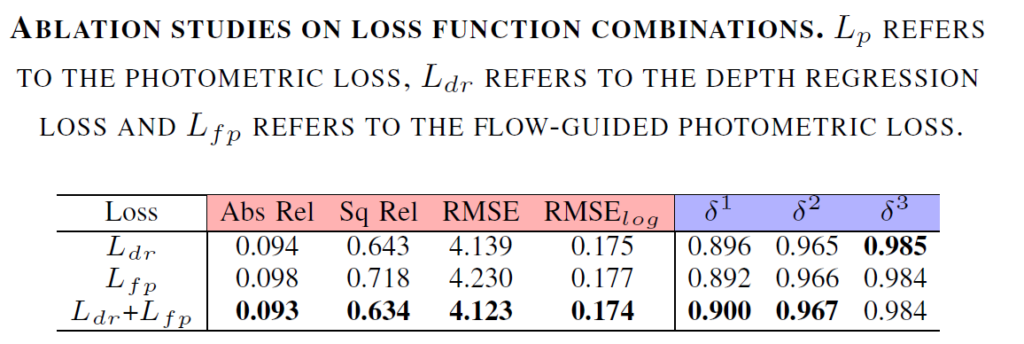
다음은 Flow Distillation Loss 내부에 Depth Regression Loss와 Flow based Photometric loss의 Ablation Study에 대한 결과입니다. 확실히 Depth Regression loss가 Flow-based Photometric loss보다 더 직접적인 영향을 미쳤기 때문에 성능 향상에 더 큰 영향을 끼치는 것 같습니다. 하지만 둘을 동시에 사용했을 때 모든 메트릭에서 성능 향상(비록 미미하긴 하지만..)이 있었다는 점에서 flow based photometric loss도 가치는 있다고 생각합니다.
결론
Contribtuion이 엄청 대단하다고 생각이 들지는 않았지만, 저자가 해당 논문에서 보여준 실험 결과들은 Photometric loss에 대한 단점을 어떻게 해결해야할지 고민하던 저에게 많은 도움이 된 것 같습니다. 그리고 Flow-based Photometric loss 계산 방식은 나름대로 신선하기도 했었네요.