본 논문에서는 3d detection task에서 LiDAR point cloud와 camera image의 multiple sensor를 사용할 때 문제와 localization, classification confidence score간 inconsistency에 대해 문제를 제기하며 end-to-end 방식의 EPNet을 제안한다. 제안하는 fusion module은 semantic image feature를 통해 point feature를 향상시키고 consistency enforcing loss를 제안하여 localization과 classification confidence 간 일관성을 더 고려한 loss를 적용하였다. KITTI와 SUNRGBD에서 평가를 진행하였고 sota를 달성할 수 있었다.
Introduction
camera image는 color나 texture와 같은 semantic 정보를 포함하고 있지만, depth 정보를 포함하고 있지 않기 때문에 3차원 검출에 어려움이 존재한다. 반면 LiDAR point의 경우에는 depth 정보와 geometric structure 정보를 포함하고 있어 3d scene을 이해하는데 더 도움이 된다. 하지만 LiDAR point는 sparse하고 입력되는 point가 unordered하다는 단점이 존재한다. 아래 Figure 1(a)는 camera image를 3d detection task에 이용했을 때 성능의 예시를 보여준다.
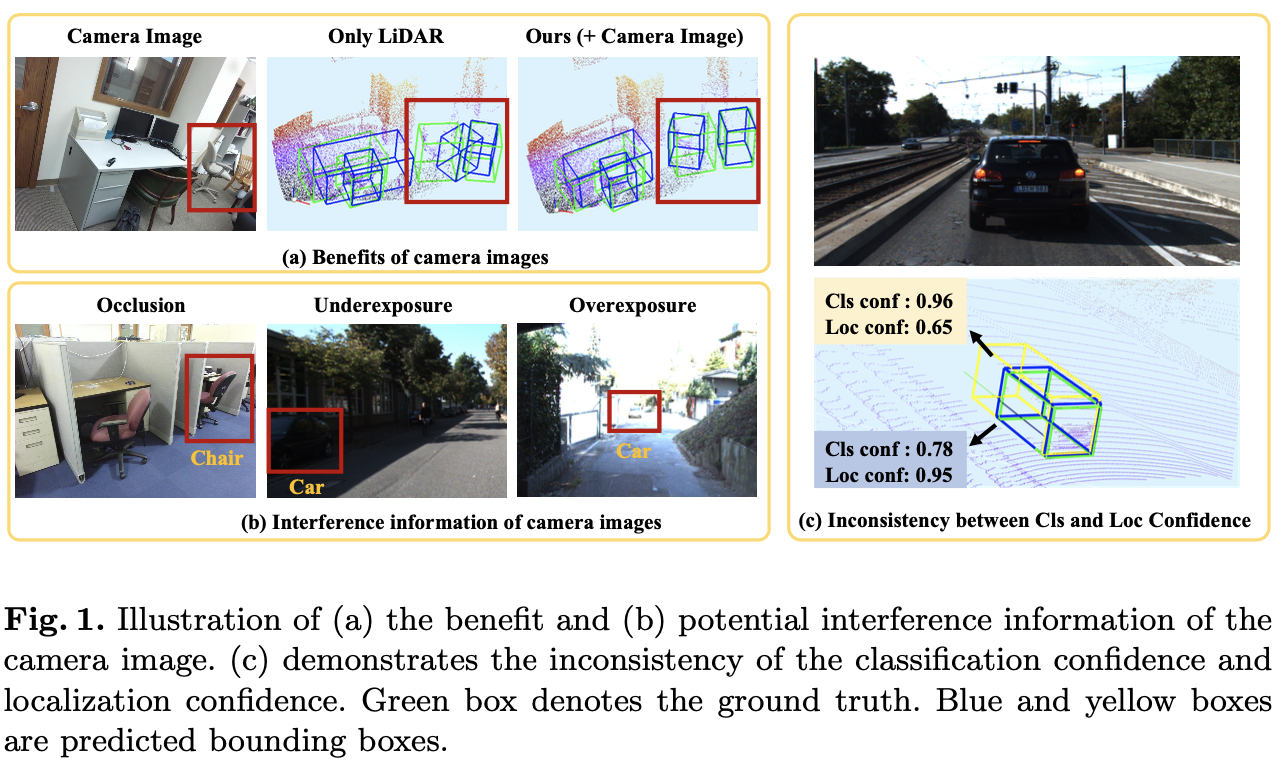
그림에서 LiDAR point로 표현되지 않은 빨간색 box로 표시된 의자의 정보가 camera image에서는 보이기 때문에 두 modality를 함께 활용할 경우 더 좋은 정확도로 검출하는 것을 확인할 수 있다. 예시로 볼 수 있듯이, color정보를 함께 사용하는 것은 정확한 검출을 위해 중요해보인다. 따라서 본 논문에서는 더 정확한 3차원 object 검출을 위해 서로 다른 sensor를 효과적으로 fusion하기 위한 module을 제안한다.
LiDAR와 camera image의 서로 다른 표현력 때문에, 그리고 rgb image는 Figure 1(b)에서처럼 조도 변화나 occlusion에 sensitive하기 때문에 두 modality를 fusion하는 것이 쉬운 일은 아니다. 서로 다른 두 modality를 fusion하는 기존의 연구들은 서로 다른 sensor의 상호보완성을 충분히 활용하지 못하거나 information loss가 심하다고 지적한다. 본 논문에서는 image fusion module인 LI-Fusion module을 제안하여 raw input data와 camera image간 correspondence를 충분히 고려하고 image semantic features에서 중요한 부분을 adaptive하게 예측하여 useful한 image feature가 point feature의 표현력을 향상시키고 오히려 방해가 되는 image feature는 surpressed시킬 수 있다.
또한 multi-sensor fusion의 경우 classification confidence와 localization confidence 사이의 inconsistency가 부정확한 검출을 야기할 수 있다고 문제를 제기한다. Figure 1(c)를 보면 classification confidence가 0.96으로 더 높은 bounding box가 더 낮은 localization confidence를 가진다. 이렇게 classification과 Localization confidence의 inconsistent한 경향이 NMS를 거치면서 더 많이 gt와 겹치지만 낮은 classification confidence score를 가지는 bounding box를 supress하여 detection 성능을 하락시키는 요인이 될 수 있다. 기존에 이 문제를 해결하기 위해 nms score threshold를 classification, localization confidence의 곱으로 사용한 전례가 있다. 하지만 저자는 해당 방식이 두 confidence score의 consistency를 강화하기 위한 explicit한 방법은 아니라고 하며 본 논문에서 consistency enforcing loss(CE loss)를 제안한다. 이를 통해 높은 classification confidence를 가지고 gt와 많이 겹치는 bounding box를 찾을 수 있게 된다. 해당 방식은 network의 architecture를 수정하지 않는 간단한 방법이고 추가적인 learnable parameter가 필요없어 많은 시간이 소요되지 않는다는 장점이 있다.
key contribution은 아래와 같다.
1. LI-Fusion module은 semantic image feature를 통해 direct하고 effective하게 point feature를 강화.
2. CE loss(consistency enforcing loss)를 제안하여 classification confidence와 localization confidence사이의 consistency를 보장.
3. 위에서 언급한 LI-Fusion과 CE loss를 적용하여 새로운 framework인 EPNet을 제안하고 KITTI와 SUNRGBD에서 sota 달성.
Related Work
당시 3d object detection 방법론들은 monocular나 stereo방식의 camera image에 더 집중하는 경향이 있다고 한다. 하지만 camera image를 기반으로하는 방법론들은 depth 정보가 부족하기 때문에 정확한 3d bounding box를 예측하는데 어려움이 존재한다.
그리고 LiDAR based 방법론이 있는데 point cloud기반의 방법론이라고 해석하는게 더 좋을 것 같다. VoxelNet같은 경우 point cloud를 voxel grid로 나누어 voxel feature를 추출하는 방식이고 SECOND는 point cloud의 많은 연산량 문제를 해결하기 위해 sparse convolution을 적용한 모델이다. point cloud는 data특성 상 굉장히 sparse하다는 특징이 있다.
또 camera와 LiDAR와 같이 multiple sensor를 사용하는 방식이 많이 발전되고 있다고 한다. 예를 들어 camera image로 2d proposal을 한 후 point cloud를 이용하여 3d box를 생성하는 방식이 존재한다. 하지만 이러한 방식은 2d annotation이 필요하고 detection 성능도 2d detection성능에 한정된다고 한다. 그 이상의 performance를 보이기 어렵다는 것이다. 본 논문에서 제안하는 LI-Fusion module은 LiDAR data를 direct하게 사용하고 LiDAR feature와 rgb image feature간 더 미세한 point-wise correspoindence를 고려할 수 있도록 했다.
Method
정확한 3d object detection을 하는데 multiple sensor에서 상호보완적인 정보를 추출하는 것은 중요하다. 또한 localization confidence와 classification confidence간 inconsistency를 해결할 필요도 있다고 주장하며 EPNet을 제안한다. EPNet은 two-stream의 RPN을 통해 proposal을 생성하고 refinement network를 통해 bounding box refinement를 수행한다. 학습은 end-to-end 방식으로 진행된다. LiDAR point feature와 semantic image feature를 효과적으로 fusion하기 위한 LI-Fusion module을 제안하고 consistency enforcing loss(CE Loss)를 통해 classification, localization confidence 간의 consistency를 향상시켰다.
Two-stream RPN
Two-stream RPN은 geometric stream과 image stream으로 나뉜다. 아래 Figure 2에서 보이는 것처럼 각 stream에서 point feauture와 semantic image feature를 각각 독립적으로 추출하게된다. 또 서로 다른 scale에서 LI-Fusion module을 추가하여 point feature와 상응하는 semantic image feature를 통해 feature 표현력을 높이고자 하였다.

먼저 image stream에서는 camera image를 input으로 하여 semantic image 정보를 추출하게된다. 구조는 간단하게 노란색으로 표시된 4개의 convolutional block으로 구성되며 각 convolutional block은 두 개의 3×3 convolutional layer와 batch norm layer, relu로 구성된다. 추가로 두 번째 Conv layer에서 receptive field를 넓히고 memory를 줄이기 위해 stride를 2로 설정했다고 한다. 그리고 뒤에서 빨간색으로 표시된 4개의 transposed convolution layer를 추가하여 각 conv block을 통과한 feature를 원본 image resolution으로 회복시켰다. 그리고 concat을 하여 서로 다른 receptive field를 가지는 semantic image feature map FU를 얻는다. FU도 이후에 LiDAR point feature의 표현력을 높이기 위해 사용된다.
geometric stream에서는 LiDAR point cloud를 input으로 하여 3d proposal을 생성한다. geometric stream은 4개의 set abstraction(SA)과 feature propagation(FP) layer pair로 구성되어 feature extract역할을 하게된다. Figure 2에서 SA layer와 FP layer의 출력값은 각각 Si, Pi로 표기하고 LI-Fusion module을 통해 Si와 Pi를 fusion하게 된다. point feature P4는 multi-scale image feature인 FU와 LI-Fusion을 통해 feature representation을 향상시키고, 이후에 detection head로 들어가 3d proposal을 수행하게 된다.
LI-Fusion module은 LiDAR-guided image fusion module의 줄임말로 크게 grid generator, image sampler, LI-Fusion layer로 구성되낟. 아래 Figure 3에 LI-Fusion module의 구조가 표현되어있는데 크게 두 가지 box로 나눠지는데 하나는 point-wise correspondence generation이고 오른쪽은 LiDAR-guided fusion과정으로 나눠진다.
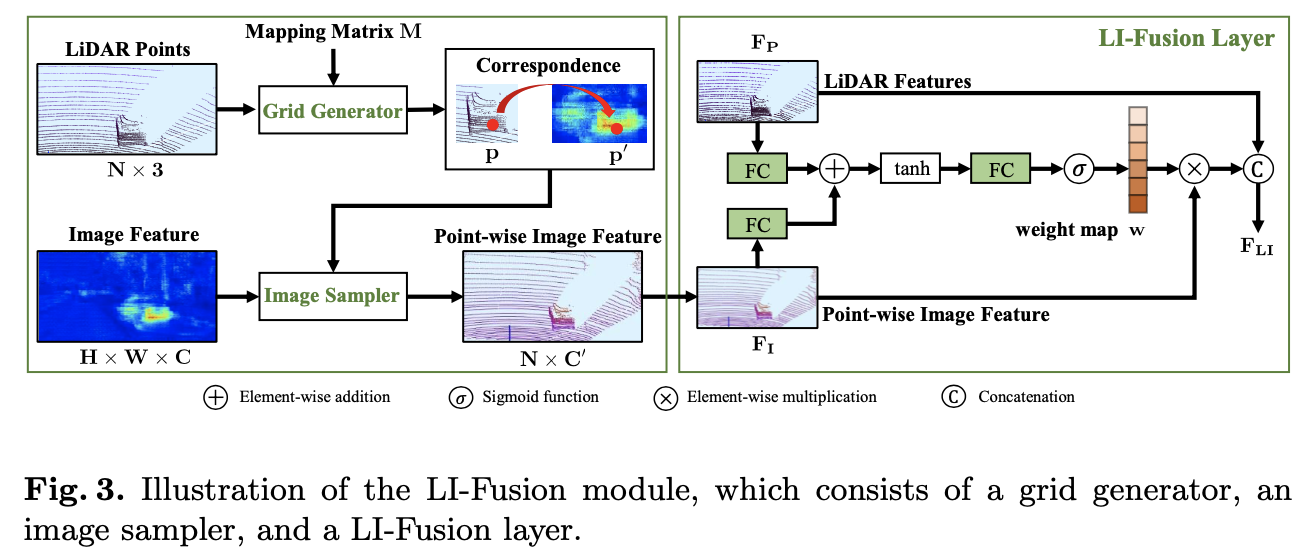
먼저 LiDAR point를 camera image에 projection하고 이렇게 mapping하는 matrix를 M으로 나타낸다. 그리고 grid generator가 LiDAR point와 mapping matrix M을 입력받아 서로 다른 resolution을 가지는 LiDAR point와 camera iamge간 point-wise correspondence를 output으로 반환한다. 좀 더 자세히 보면 point cloud의 어떤 point p(x,y,z)가 있을 때 camera image에서 상응하는 위치 p'(x’,y’)는 아래 수식과 같이 계산된다.

M은 3×4 matrix이고 p’와 p는 homogeneous coordinate로 각각 3차원, 4차원 벡터로 변환해서 사용한다. 이렇게 상응하는 관계를 파악하고 image sampler를 이용해 각 point마다 semantic feature representation을 얻는다. image sampler는 sampling position p’과 image feature map F를 입력으로 하여 point-wise image feature representation V를 각 sampling position마다 구하게된다. 그리고 sampling position이 인접한 pixel 사이에 있을 수 있다는 점을 고려하여 이 경우 bilinear interpolation을 사용한다.

V(p)는 point p와 상응하는 image feature를 의미하고 K는 bilinear interpolation function, F(N(p’))는 sampling point p’과 인접한 image feature pixel을 의미한다.
LiDAR feature와 point-wise image feature를 fusion하는 것은 어려운 일인데, camera image가 조도나 occlusion과 같은 요인에 어려움을 가지기 때문이다. 본 논문에서는 LiDAR-guided fusion layer를 통해 LiDAR feature를 이용해 point-wise image feature의 중요도를 예측하고자 했다. Figure 3에서 처럼 LiDAR feature Fp와 point-wise feature FI가 Fully connected layer를 통과하여 같은 channel을 가지는 feature map을 생성한다. 그리고 element-wise로 더해서 feature representation을 표현하고 이후 fc layer를 통과해서 하나의 channel을 가지는 weight map w로 압축된다. weight map은 sigmoid를 적용하여 0과 1사이 범위로 normalize해준다.
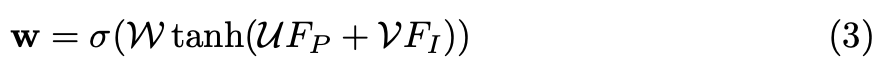
W, U, V는 LI-Fusion layer의 learnable weight이고 σ는 sigmoid function을 나타낸다. weight map w를 얻고나서 LiDAR feature FP와 semantic image feature FI를 concat하여 FLI를 생성한다.

Refinement Network
refinement network전 NMS과정을 통해 high-quality의 proposal을 살리고 이것들을 refinement network로 보낸다. 각 proposal마다 bounding box 내에서 random하게 512개 points를 선택하여 feature descriptor를 생성한다. 만약 proposal이 512보다 적은 points를 가진다면 0으로 Padding한다고 한다. refinement network는 3개의 SA(set abstraction) layer로 구성되며 global descriptor를 추출하여 이후 classification이나 regression 등 downstream task를 수행하는 1×1 conv layer로 구성된 두 개의 subnetworks가 포함된다.
Consistency Enforcing Loss
보통 3d object detector들은 실제 object보다 많은 boundign box를 생성한다. 그 중에 high-quality의 box를 선택하는 것이 중요하다. NMS 과정을 통해 classification confidence에 따라 별로인 bounding box를 filtering하게된다. 하지만 이 경우 classification confidence과 localization confidence가 inconsistent한 경우 nms가 원하는대로 되지 않을 수 있다. 이러한 문제를 제기하며 저자는 consistency enforcing loss를 도입하여 high localization confidence를 가지는 box가 high classification confidence를 가져 localization과 classification confidence의 consistency를 보장하고자 한다. 아래 수식이 consistency enforcing loss를 나타낸다.
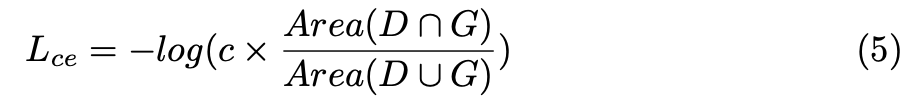
D와 G는 각각 predicted bounding box와 gt box를 나타내고 c는 D의 classification confidence를 나타낸다. 해당 loss를 최적화하기 위해 classification confidence와 IoU는 높은 값을 나타내는 방향으로 최적화 될 것이다. 이를 통해 높은 classification 확률값을 가지는 box는 NMS를 통과해도 살아남아있을 것이다.
기존 IoU loss와 제안하는 CE loss와 차이라고 하면 IoU loss는 IoU metric을 최적화하여 더 정확한 regression을 하려고 했다면, CE loss는 localization과 classification confidence의 consistency를 고려하여 NMS과정에서 더 정확한 bounding box를 살리도록 했다는 점이라고 한다.
Overall Loss Function
앞의 two-stream RPN과 refinement network를 최적화하기 위한 total loss는 아래 수식과 같다.

Lrpn과 Lrcnn은 각각 two-stream RPN과 refinement network의 목적함수이며 classification loss, regression loss, CE loss를 포함한다.
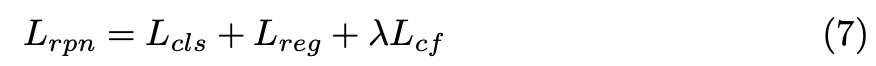
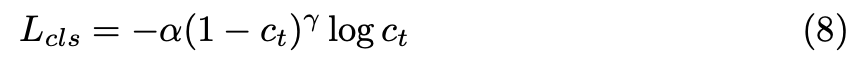
classification loss로는 focal loss를 도입하여 positive, negative sample의 balance를 맞추고자 하였다. ct는 특정 point가 gt category에 포함될 확률을 나타내며 α = 0.25, γ = 2.0이다.
각 bounding box마다 network는 Center point(x,y,z), size(l,h,w), orientation(θ)을 regression한다. bounding box의 offset에 대해서는 direct하게 gt와 offset을 smooth-l1 loss로 계산한다. bounding box의 size(l,h,w)도 smooth l1 loss로 최적화한다.
x축, z축, orientation θ의 경우에는 bin-based regression loss를 사용했다고 한다. 여기서 x,z축에 대한 경우는 어떤 값을 나타내는 것인지 정확하게 이해하지 못했다… bin-based regression loss는 각 foreground point에 대해 인접한 영역을 여러 개의 bins로 분할한다. 먼저 center point가 속하는 bin bu를 예측하고 bin 내의 residual offset ru를 regression한다.

E, S는 각각 cross entropy loss, smooth L1 loss를 나타내고 bu^와 ru^ 이렇게 hat이 붙은 것은 gt를 의미하여 각각 bin gt와 residual offset gt를 나타낸다.
Experiments
본 논문에서는 outdoor dataset인 KITTI와 indoor dataset인 SUNRGBD에서 평가를 수행했다. 각 데이터셋에 대해 간단히 살펴보면 KITTI는 outdoor autonomous driving scene으로 7,481장의 training frame, 7,518장의 test frame을 포함한다. 그리고 object size, occlusion, truncation 등에 따라 easy, moderate, hard 이렇게 3가지 Level로 나뉘어져있다.

SUN RGBD의 경우 indoor dataset으로 10,335장의 이미지로 구성되며 5,285장이 train, 5,050장이 test이미지이다. 700개 categories에 대해 annotation되어있지만 standard test protocol에 따라 많은 object가 포함되어있는 10개의 class에 대해 평가를 진행한다.

Metric은 average precision(AP)를 사용했다.
setting에 대해서도 간단히 살펴보자면 LiDAR point cloud의 range는 camera coordinate 기준으로 X(right)[-40,40], Y(down) -1,3], Z(forward)[0,70.4] meter이고 θ는 [-∏,∏]이다.

geometric stream input으로 16,384 points를 sampling해서 사용했고 image resolution은 1280×384이다. NMS threshold는 0.8로 했고 64개의 positive candidate box를 얻어 refinement를 수행했다. two-stream RPN과 refinement network는 end-to-end로 학습되며 50 epoch동안 학습했다. augmentation으로는 random rotate, random flip, random scale을 사용했다.
결과부터 보면 먼저 아래 Table 5는 KITTI에서 결과이다.
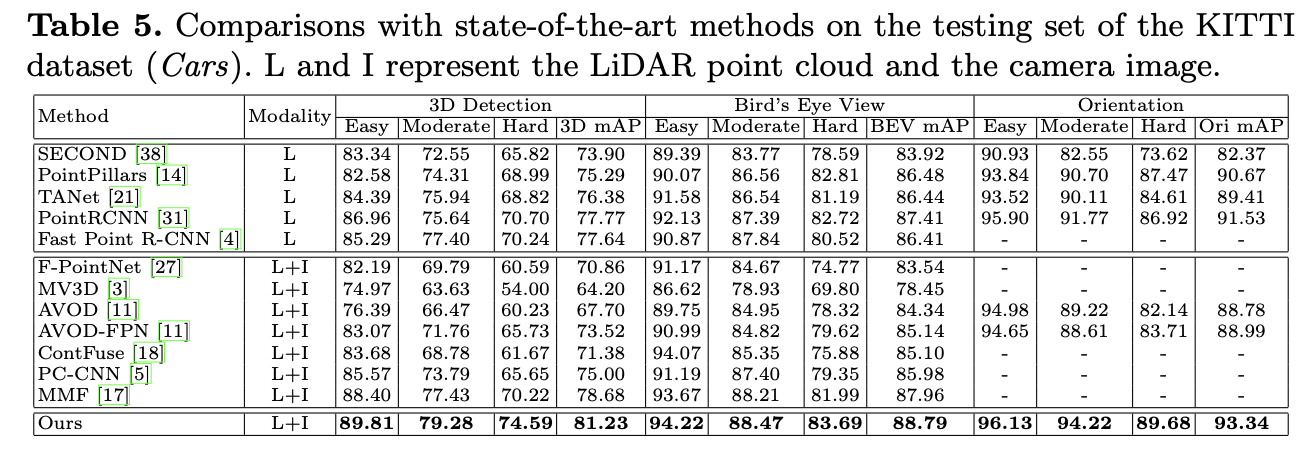
LiDAR point cloud만 사용한 방법론들과 Image를 fusion한 방법론을 비교해보면 전반적으로 fusion하지 않은 point cloud만 사용한 방법론이 더 좋은 성능을 보이는 경향이 있는데 image를 fusion하는 다양한 연구가 진행되며 점차 fusion 방법론들이 좋은 성능을 보이고 있다. 기존 sota대비 2.55% 더 좋은 성능을 보이고 있다.

그리고 SUNRGBD에서의 결과를 보면 역시 가장 좋은 성능을 보이고 있다.
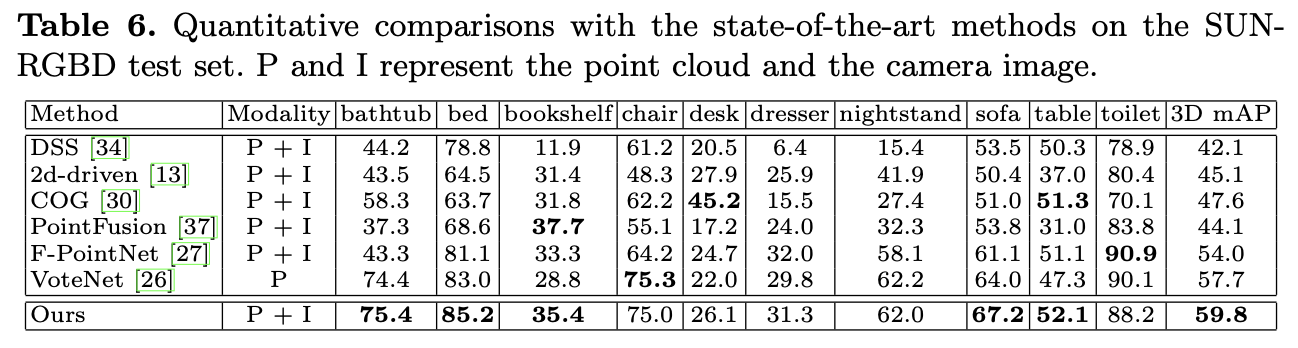
PointFusion, F-PointNet을 multi-sensor를 사용한 base model로 잡았는데 두 방법론은 모두 2d bounding box를 camera image에서 2d detector를 통해 생성하고 3d box를 예측하는 방식이다. F-PointNet의 경우 LiDAR point를 3d box를 생성하는데만 활용하고, PointFusion은 global image feature와 point feature를 단순 concat하여 fusion한다고 한다. 하지만 본 논문에서 제안하는 EPNet은 point feature와 image feature간 correspondence를 명시적으로 고려하여 표현력을 높이는 방식을 통해 더 좋은 quality의 예측이 가능하다고 한다.

LI-Fusion module과 CE Loss에 대한 ablation study에 대해서도 몇 가지 살펴보자면 아래 Table 1에서 1,2행을 비교했을 때 LI-Fusion module을 추가했을 때 1.73% 정확도가 향상한 것으로 보아 해당 fusion방식이 효과적이라는 것을 알 수 있다. 또 CE loss를 적용했을 때를 비교하기 위해 1,3행을 보면 3.93%의 정확도 향상을 보여 확실히 CE loss에서 classification confidence와 localization confidence의 consistency를 고려한 방식이 성능 향상에 큰 도움이 된 것으로 보인다. 둘 다 적용했을 때는 5.06%나 정확도 향상을 이룬 것을 알 수 있다. 아 참고로 ablation은 KITTI dataset에 대해 수행했다.
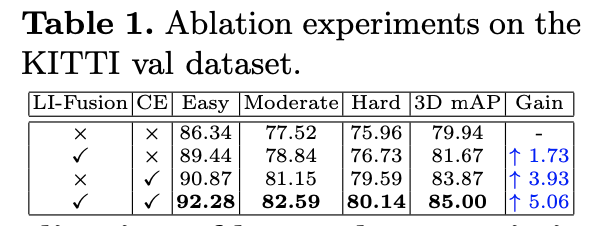
또 Table 2의 fusion하는 방식에 대해 보면 SC는 simple concatenation으로 단순히 concat하는 fusion방식을 적용했을 때 성능 하락을 보인다. SS는 single scale fusion으로 two-stream RPN과 비슷한 architecture를 가져가는데 마지막 LI-Fusion module을 제외하고 모두 제거했다는 점이다. 이 경우 약간의 성능향상이 보였고 Figure 2에서 처럼 LI-Fusion module을 적용하여 feature의 표현력을 높였을 때 1.73%의 정확도 향상을 보인다.
CE loss에 대한 분석도 보면 Figure 5(a)에서 CE loss를 적용했을 때 1.28%의 정확도가 향상된 것을 보아 classification, localization confidence의 consistency가 성능 향상에 긍정적인 영향을 준 것을 이해할 수 있다. (b)에서 R은 얼마나 많은 positive candidates가 유지되었는지에 대한 R의 ratio로 consistency를 평가했다.
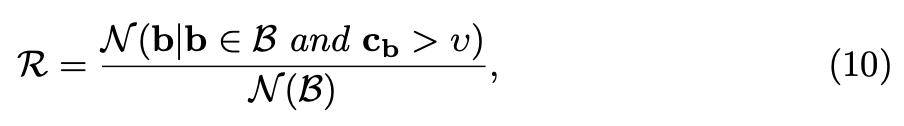
B는 positive candidate box set을 의미하고 cb는 box b의 classification confidence를 나타내며 v는 small classification confidence를 filtering하기 위한 threshold이다. N은 box 수를 의미한다. B에 있는 상자들은 대응하는 gt box와 threshold(0.7)보다 큰 iou를 가지고 있다. 그래프에서 가로축은 v값으로 minimum threshold[0.1,0.9]인데 그림에서 잘못 표기한 것같다. 아무튼 아래 그림에서 볼 수 있듯이 CE loss로 학습된 모델은 다양한 classification confidence threshold 설정값에서 iou loss로 학습된 모델보다 더 나은 consistency를 보인다.
그림 5(b)에 나타난 바와 같이, CE 손실로 훈련된 모델은 분류 신뢰 임계값의 모든 다른 설정에서 IoU 손실로 훈련된 모델보다 더 나은 일관성을 보여줍니다.
Conclusion
본 논문에서는 새로운 3d object detector인 EPNet을 소개한다. EPNet은 two stream RPN과 refinement network로 구성되낟. two-stream RPN은 LiDAR point cloud와 camera image처럼 서로 다른 센서 간 feature를 효과적으로 fusion하기 위해 LI-Fusion module을 추가하여 구성하였다. 또한 classification confidence와 localization confidence간 inconsistency 문제를 issue rising하며 CE loss를 통해 두 confidence간 consistency를 보장할 수 있도록 했다. 실험을 통해 LI-Fusion module과 CE loss의 효율성을 입증하였고 outdoor환경 데이터셋인 KITTI와 Indoor 데이터셋인 SUN RGBD에서 sota를 달성할 수 있었다. 저자는 마지막에 앞으로 image feature를 enhance할 수 있는 방법에 대해 찾아보겠다고 하며 논문을 마친다.
좋은 리뷰 감사합니다.
정리하자면 이미지와 depth 정보를 효율적으로 융합하기 위해 LI-Fusion 모듈을 제안하며, Consistency Enforcing loss로 classification과 localization confidence간의 consistency를 향상시켰고,
LI-Fusion의 경우 여러 scale에서 수행되며, LiDAR 정보를 이용하여 point-wise image feature의 중요도를 예측한다고 하셨는데, depth와 color영상이 각각의 장단점이 있듯이, 거꾸로 image 정보를 이용하여 3D point feature의 중요도를 예측하는 방식은 아예 고려하지 않은 것인지 궁금합니다. 제안된 LI-Fusion의 그림을 보았을 때 point-wise image feature는 상당히 sparse해 보여서 이러한 궁금증이 생겼습니다.
댓글 감사합니다.
fusion하는 방법에는 여러 방법이 존재합니다. 3d point cloud를 2d image feature정보를 개선하기 위한 fusion, 2d image feature를 point feature로 개선하기 위한 fusion, 두 모달리티 모두 재귀적으로 서로 향상된 feature 표현력을 가지도록 하는 방법 등이 있는데 본 논문에서 제안하는 방법론은 semantic image feature정보를 활용하여 3d point cloud의 표현력을 높이는 방식을 사용했습니다. LI-Fusion 그림에서 sparse하게 보이는 것은 3d point cloud data의 본질적인 특성으로 본 논문에서는 앞에서 말한 것처럼 image feature를 point cloud의 표현력을 높이기 위해 사용되었으므로 raw point cloud와 같은 sparse함을 보인다고 할 수 있겠습니다.