제가 이번에 리뷰할 논문도 6D Pose Estimation 논문으로, 현재까지 760회의 인용수를 기록하고있습니다. 그러면 리뷰를 시작하겠습니다.
본 논문도 RGB-D로부터 6D Pose를 추정하기 위해 서로 다른 두 데이터를 완전히 활용하기 위한 연구입니다. 저자들은 DenseFusion이라는 구조를 제안하여 두 데이터를 개별적으로 처리하고, dense fusion network를 이용하여 픽셀 수준의 dense한 feature embedding을 추출하고 이를 통해 pose를 추정합니다. 또한, 반복적인 refinement 과정을 end-to-end로 통합하여 pose 추정 정확도를 개선하면서 실시간에 가까운 inference가 가능하도록 하였다고 합니다. 시험은 YCB-Video와 LineMOD에 대하여 진행하였고, SOTA를 달성하였다고 합니다.
Intro
6D Pose Estimation을 위해서는 객체의 다양한 모양과 질감에 대해 처리할 수 있어야 하며, occlusion과 센서 노이즈, 조명 변화에도 강인해야 합니다. 저렴한 RGB-D 센서가 등장하여 조도가 낮은 경우에도 RGB 보다 강인하게 textual-less한 객체의 pose를 추정이 가능해졌으나, 기존 방식은 pose 추정의 정확도와 속도 두가지를 모두 다 만족하기 어려웠다고 합니다.
우선 고전적인 방식은 RGB-D에서 특징을 추출한 뒤 correspondence grouping과 hypothesis verification을 통해 pose를 추정하는 방식으로, 이는 hand-craft 기반의 특징과 고정된 matching 방식에 의존하므로 occlusion과 조도 변화 시 성능이 하락하였다고 합니다.
또한 시각 인지의 발달로 인해 PoseCNN과 같이 RGB-D 입력으로부터 pose를 추정하기 위한 deep neural network를 이용하는 data-driven 방식이 등장하였고, 이러한 방법들은 3D 정보를 완전 활용하기 위해서는 PoseCNN의 ICP(Iterative Closest Point)와 같이 후처리 과정(refinement)이 필요합니다. 이러한 refinement 과정은 별도로 최적화를 해야하며, 실시간성을 저해하게 됩니다.
Frustrum PointNet과 같이 RGB-D 데이터의 상호보완적 특성을 활용하기 위해 제안된 end-to-end의 모델은 주행 장면에서는 잘 작동하며, 실시간성을 확보하였으나, 로봇을 조작하는 경우에 흔히 발생하는 occlusion에는 여전히 잘 작동하지 않았다고 합니다.
저자들은 end-to-end 방식의 6-DoF pose 추정 방식을 제안하였습니다. 방법론의 핵심은 이미지를 crop하여 global feature나 2D bounding box를 계산하던 이전의 방식과는 다르게 픽셀수준에서 RGB와 piont cloud를 embedding하고 융합하였다는 것입니다. 픽셀 수준의 융합을 통해 local한 외관 정보와 geometry 정보를 명시적으로 추론할 수 있으며, 심한 occlusion 상황을 처리할 수 있었다고 합니다. 또한, pose refinement 과정을 end-to-end 학습 방식에 통합할 수 있도록 하였고, 이를 통해 실시간성을 유지하면서 모델의 성능을 향상시킬 수 있었다고 합니다. 저자들은 YCB-Video와 LineMOD 벤치마크에서 SOTA를 달성하였으며 PoseCNN에 ICP(refinement 과정)를 적용하는 경우보다 3.5% 정확도가 향상되면서도 추론 시간은 200배 이상 빠르다는 것을 보여주었고, 매우 복잡한 상황에서 강인하게 작동하는 것도 보였다고 합니다.
해당 논문의 contribution을 정리하면
- RGB-D로부터 color와 depth 정보를 결합하는 방식 제시
- 신경망 구조 안에 반복적인 refinement 과정을 통함하여 이전 연구들이 후처리 ICP 과정에 의존하던 것을 제거
Model
challenge한 조건(심한 occlusion, 열악한 조명 등)에서 물체의 6D Pose를 추정하는 것은 color 정보와 depth 정보를 모두 이용해야 가능하지만, 이 두 데이터는 서로 다른 space에 존재합니다. 따라서 서로 다른 두 데이터에서 특징을 추출하여 적절하게 융합하는 것이 매우 중요하며, 이를 위해 (1) 각 데이터의 고유한 구조를 유지하면서 color와 depth 정보를 처리하는 네트워크 구조와 (2) intrinsic 매핑을 통해 color-depth 정보를 융합하는 dense pixel-wise fusion 네트워크를 제안합니다. 또한, 미분 가능한 iterative refinement 모듈을 제안하여 pose 추정을 개선합니다. 제안된 refinement 모듈은 메인 아키텍쳐와 함께 학습가능하며 inference 시간의 아주 일부만 차지한다고 합니다.
1. Architecture Overview
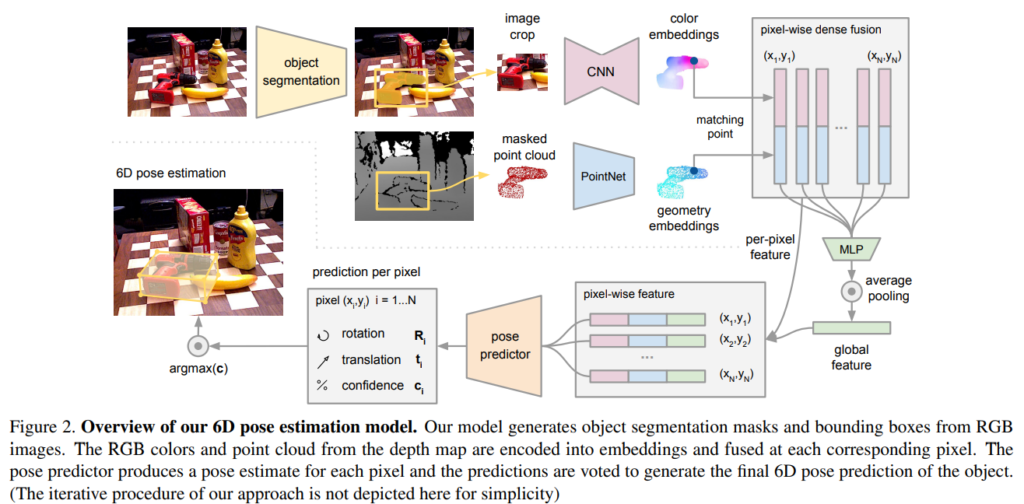
위의 그림이 본 논문의 아키텍쳐로, 크게 두 단계로 이루어졌다고 합니다. 우선 color 이미지로부터 semantic segmentation을 수행하는 과정을 거친 뒤, segmentation 된 object에 대해 masked point cloud(3D Point cloud로 변환)와 해당 영역만 잘린 이미지 패치를 입력으로 하는 두번째 과정을 거치게 됩니다.
두번째 과정은 segmentation 결과를 처리하여 6D Pose를 추정하는 단계로, 이 과정도 4가지로 구성됩니다.
- crop된 이미지의 각 픽셀을 color feature embedding에 매핑하는 fully convolutional 네트워크
- masked point cloud의 각 point를 처리하여 geometry feature embedding하는 Point Net 기반의 네트워크
- 두 정보를 융합하여 6D Pose를 출력하는 pixel-wise fusion network
- 함께 학습 가능한 iterative refinement 과정
2. Semantic Segmentation
저자들이 사용한 semantic segmentation은 기존에 PoseCNN에서 사용한 네트워크를 그대로 사용하였다고 합니다. 이는 encoder-decoder 기반의 구조로, 출력은 N+1 채널(각 class에 대한 이진 마스크)입니다.
3. Dense Feature Extraction
color와 depth 정보는 서로 다른 space에 존재합니다. 따라서 저자들은 데이터의 고유한 구조를 유지할 수 있는 embedding space에서 color와 depth의 특징을 추출하기 위해 각 데이터를 별도로 처리합니다.
Dense 3D point cloud feature embedding
기존 방법론은 depth를 또하나의 채널로 생각하고 CNN을 거쳤지만, 이러한 방식은 depth 채널의 3D 구조를 무시하는 방식이므로, 카메라의 intrinsic 파라미터를 이용하여 3D point cloud로 변화시킨 뒤 3D Point cloud에 사용되는 PointNet과 유사한 구조를 이용하여 기하학적 정보를 추출하였다고 합니다. P개의 point cloud를 d_{geo}의 feature space로 매핑하였다고 합니다.
Dense color image feature embedding
color embedding 네트워크는 3D point와 2D 이미지 사이의 dense한 대응관계를 형성하기 위한 픽셀 단위의 feature를 추출하는 것을 목표로 합니다. encoder-decoder 구조의 CNN 네트워크는 이미지를 H ⨉ W ⨉ d_{rgb} embedding space로 매핑하였고, embedding feature의 각 픽셀은 해당 위치엥서 입력 이미지의 외관 정보를 나타내는 d_{rgb}차원 벡터라고 합니다.
4. Pixel-wise Dense Fusion
이미지와 3D Point cloud로 부터 얻은 dense한 feature를 융합하는 과정으로 단순한 방식은 분할된 객체 영역의 global feature를 생성하는 방식은 occlusion 과 부정확한 segmentation 결과로 인해 다른 객체나 배경 정보가 포함되어 성능이 저하될 수 있으므로, 새로운 픽셀단위의 dense fusion 네트워크를 제안하였다고 합니다.
Pixel-wise dense fusion
저자들은 global fusion 대신 픽셀단위의 local fusion 방식을 통해 물체의 보이는 영역을 기반으로 pose를 예측하도록 하여 global fusion 방식의 문제인 occlusion 영역과 잘못된 segmentation 결과로 인한 노이즈 영향을 최소화 할 수 있다고 합니다.
dense fusion 과정은 다음과 같습니다.
- 먼저 geometric한 정보를 카메라의 intrinsic 파라미터를 이용하여 이미지 평면에 투영하여 이미지의 feature와 연결합니다.
- 연결된 feature 쌍은 concat하여 이후 네트워크의 입력으로 들어가 고정된 크기의 global feature 벡터를 생성합니다.
- 이후 global feature만을 이용하지 않고, dense하게 융합된 각 피처에 global feature를 융합하여 각 feature마다 하나의 pose를 예측하도록 네트워크를 학습시킵니다. (즉, global feature를 구할 때 사용했던 color feature와 depth feature에 global feature를 추가하여 각 feature set마다 pose를 추정하는 것입니다.)
Per-pixel self-supervised confidence
각 특징마자 pose를 추정한 뒤, 최상의 pose를 예측하기 위해 self-supervised 접근법을 이용하였다고 합니다. 이를 위해 네트워크가 pose 뿐만 아니라 score c_i도 예측하도록 하였고, 이를 objective 함수에 추가하여 학습을 진행하였다고 합니다. 이에 대한 설명은 바로 다음 섹션에서 설명합니다.
5. 6D Object Pose Estimation
Pose 추정 오차함수는 GT와 예측된 pose를 3D 모델로 변환시켜 동일한 점들 사이의 거리로 정의합니다.(기존 연구들과 동일) 그러나 여기에 앞서 이야기했던, per dense-pixel의 오차를 최소화 하기 위해 아래와 같이 loss가 정의된다고 합니다.
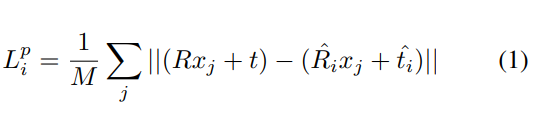
- x_{j}: 3D point로부터 랜덤하게 선택된 M개의 point 중 j 번째 point
- p=[R|t]: GT pose
- \hat{p}_i=[\hat{R}_i | \hat{t}_i]: i번째 dense-pixel로부터 예측된 pose
오차함수 중 파란색 부분이 기존 오차함수와 다르게 각 feature마다 pose를 예측하는 방식을 고려하도록 설계된 부분입니다. 또한, 위의 식(1)은 비대칭 객체에 대한 loss함수이며, 대칭적인 물체의 경우 아래의 식(2)를 이용하여 가장 가까운 점 사이의 거리를 최소화 하도록 함수를 정의합니다.
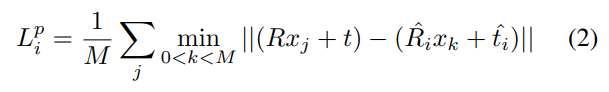
예측된 모든 dense-pixel pose에 대한 최적화를 진행합니다.
L = {1 \over N} \sum_{i}{L^P_i}이때 네트워크가 dense-pixel loss에 confidence를 가중치로 부여하고, 신뢰도 정규화 항을 추가하여 최종적 오차함수는 아래와 같이 정의됩니다.
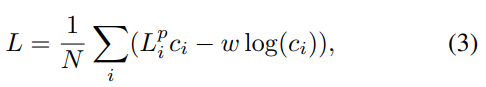
- w: balancing 하이퍼파라미터
- 신뢰도가 낮으면 pose 추정에 대한 loss가 줄어들지만, 두번째 항에서 높은 페널티가 발생하도록 설계되었습니다.
- 신뢰도가 가장 높은 pose 예측값을 최종 출력으로 사용합니다.
6. Iterative Refinement
기존 방법론들이 많이 사용하던 ICP(iterative closest point) 알고리즘은 refinement에 효과적이지만, real-time으로 작동하는 것을 어렵게 하는 경우가 많다고 합니다.(아무래도 최적의 값을 찾기 위해 반복적으로 이를 수행하므로 시간이 오래 걸립니다.) 또 다른 refinement 방식은 실시간 렌더링이 가능한 엔진과 object 모델을 이용하는 방식이 있으며, 본 논문에서는 추가적인 렌더링 기술 없이, 최종 pose를 개선할 수 있는 네트워크 기반의 iterative refinement 모듈을 제안합니다.
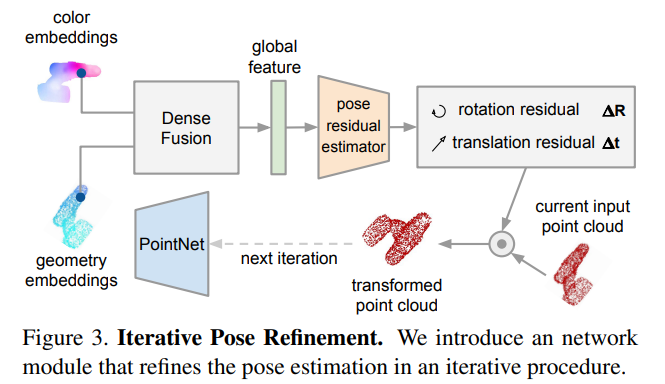
해당 네트워크는 반복적으로 자체의 pose 추정 오차를 수정할 수 있도록 하는 것을 목표로 하며, 새로운 pose를 예측하는 것이 아니므로, 이전의 예측 pose를 다음 네트워크의 입력에 포함합니다. 저자들의 핵심 아이디어는 이전 pose를 대상 물체의 표준 프레임으로 간주하고 입력된 point cloud를 이 추정의 표준 프레임으로 변환하는 것입니다. 즉, 예측된 pose로 변환된 point cloud를 네트워크에 입력으로 넣어 잔여 pose(이전에 예측된 pose에서 얼만큼을 더 변환해야 하는지)를 예측하도록 하는 것입니다. 이 과정을 반복하여 refinement를 수행하며, K번 반복후 각 반복당 최종 pose 추정치를 아래의 식을 통해 얻습니다.
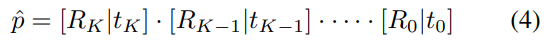
또한, end-to-end라고는 하였지만, 앞의 pose 추정 단계가 어느정도 수렴한 후에야 해당 과정을 함께 학습할 수 있었다고 합니다.
Experiments
저자들은 실험을 통해 (1) dense fusion network가 global fusion 방식과 비교하였을 때 어떤지, (2) dense fusion이 occlusion과 segmentation 오류에 얼마나 강한지, (3) 반복적인 refinement 모듈이 pose를 개선할 수 있는 지, (4) 저자들이 제안한 방식이 실제 활용 측면에서 효율적인지를 확인하고자 한다고 합니다.
(1)~(3)은 6D Pose Estimation 데이터셋인 YCB-Video와 LineMOD로 평가를 하고, (4)는 실제 로봇 플랫폼에서 로봇의 작업 성능을 평가하였다고 합니다.
Dataset
- YCB-Video
- 21개의 다양한 모양과 texture를 가진 YCB 객체의 장면을 캡쳐한 92개의 RGBD 비디오를 포함
- 비디오에 segmentation 주석과 6D Pose 주석을 달았음
- train set: 학습용 비디오 80개 & 8만개의 합성 영상
- test set: 12개의 비디오
- LineMOD
- 13개의 object가 포함된 데이터셋
- texture less한 물건, clutter한 장면, 조도 변화가 있어 복잡한 데이터 셋.
Metrics
- ADD(-S)
- ADD는 예측된 pose와 GT pose로 변환된 object point 쌍 사이의 평균 거리
- 대칭 및 비대칭 객체를 고려하여 평가하는 방식으로, 6D Pose Estimation에서 일반적으로 사용하는 평가지표
- 대칭 객체는 ADD-S로 평가하며, PoseCNN에 따라 ADD-S 곡선 아래 면적(AUC)을 리포팅 함.( AUC의 threshold= 0.1m)
- 로봇 조작에 대한 최소한의 허용 오차를 측정하기 위해 2cm 미만의 ADD-S 비율 리포팅
Evaluation on YCB-Video Dataset
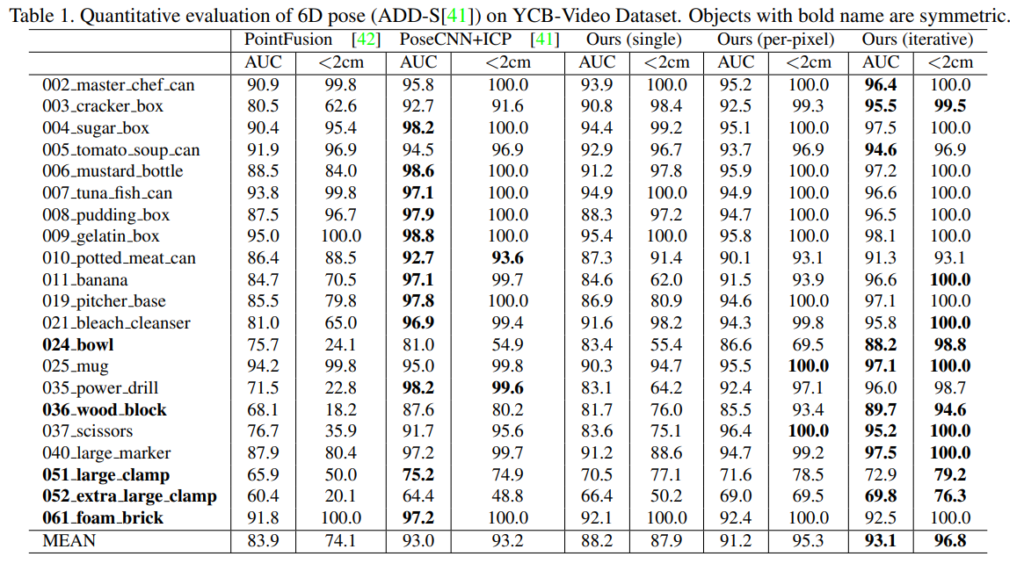
Table 1은 YCB-Video에서의 21개 객체에 대한 평가 결과로, 다른 방법론들과 비교했을 때 저자들이 제안한 방식(+refinement)이 가장 좋은 성능을 나타냈다고 합니다. AUC에서는 미세한 성능 향상이 나타나지만, <2cm에서는 PoseCNN+ICP 방식보다 3.5% 더 좋은 성능을 보였습니다.
Effect of dense fusion
(1)에 대한 실험 결과로, 저자들이 제안한 dense fusion 결과(Ours(single)과 Ours(per-pixel))가 PointFusion과 비교했을 때 상당히 크게 성능이 향상되었습니다. 이를 통해 dense fusion 방식의 global fusion 방식(PointFusion)보다 좋다는 것을 보였습니다.
Effect of iterative refinement
(3)에 대한 실험 결과로, Ours의 iterative와 나머지를 비교하면 iterative refinement의 효과를 확인할 수 있습니다. 특히 방향이 모호한 texture-less하고 대칭적인 객체에서 성능이 두드러지게 향상되었습니다. (bowl (29%), banana (6%), extra large clamp (6%))
Robustness towards occlusion
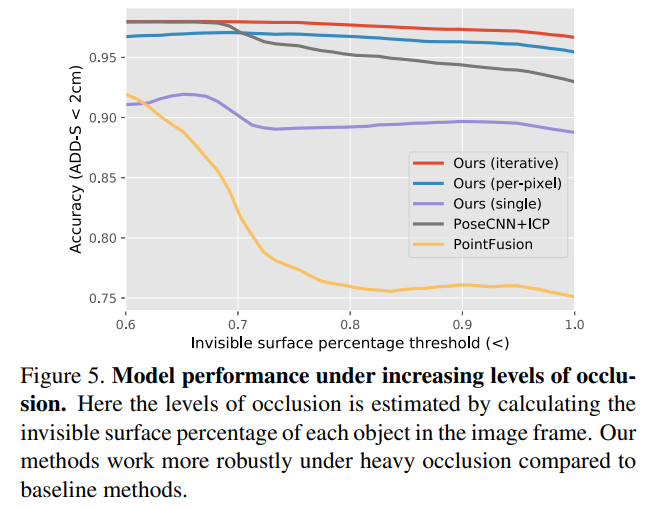
Figure 5는 (2)에 대한 실험 결과로, 저자들이 주장한 dense fusion 방식의 장점인 occlusion과 segmentation 오류에도 강인함을 정량적으로 확인하고자 각 object의 보이는 영역의 비율을 계산한 뒤, occlusion 정도에 따라 어떻게 변하는 지 확인한 결과입니다. 저자들이 제안한 방식이 invisible 영역이 증가함에도 성능이 크게 저하되지 않는 것을 호 ㅏㄱ인할 수 있습니다.
Time Efficiency
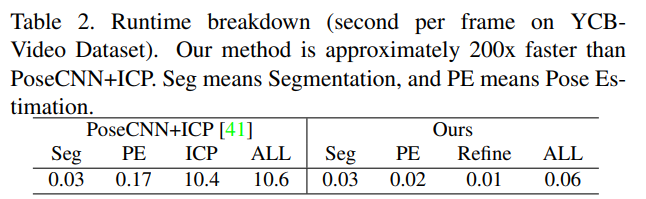
Table2는 시간의 효율을 확인하기 위해 PoseCNN+ICP 방식과 비교한 결과로, 저자들이 제안한 방법론이 2배 이상 빠르고, 특히 ICP(refinement 과정)에서 크게 효율이 좋아진 것을 확인할 수 있습니다.

Figure 4는 정성적 결과를 나타낸 것으로, 가장 왼쪽 상황의 크래커 상자는 앞의 bowl로 인한 occlusion에 의해 PointFusion에서는 강인하지 못하였으나, PoseCNN과 Ours에서는 잘 예측이 되었습니다. 또한, 그림에는 표시되지 않았으나, 가운데 케이스는 segmentation이 잘 이루어지지 않은 경우로, Ours에서만 클램프(집게같은 공구)가 잘 예측된 것을 확인할 수 있습니다.
Evaluation on LineMOD

저자들의 알고리즘이 기존 방법론에 refinement를 적용한 것 보다 좋은 성능을 보였으며, iterative를 통해 refinement를 수행할 경우 가장 좋은 결과를 보임을 확인할 수 있습니다.
Robotic Grasping Experiment

마지막으로 (4)를 확인하기 위한 실험으로, 위의 그림과 같이 테잉블에 YCB 물체를 배치한 뒤 로봇에 Pose를 추정하도록 하여 물체를 잡도록 한 결과를 분석한 파트로, 각 객체마다 12번씩, 총 60번의 그립을 시도하도록 하였다고 합니다. 73%의 확률로 물체를 잡는 데 성공하였다고 합니다.(다른 모델로 비교를 진행하지는 않았습니다.) 이를 통해 저자들은 본 논문에서 제안한 방법론이 학습 데이터와 다른 배경임에도 불구하고 domain adaptation을 수행하지 않고도 로봇에 적용 가능함을 보였다고 합니다.
본 논문은 이해를 하기 좋게 작성되어다고 생각합니다. 특히, 실험파트를 통해 어떤것을 보일지 명시해주어 실험을 이해하는 데 도움이 많이 되었습니다. 이상 리뷰를 마치겠습니다.
좋은 리뷰 감사합니다.
몇 가지 질문이 있습니다.
1. 픽셀 수준의 매칭이 핵심적인 아이디어 같은데 CNN과 pointNet으로부터 임베딩되는 특징의 H, W가 어떻게 되는지 궁금합니다.
2. Loss에서 dense-pixel에 대한 포즈 오차를 구하는데 GT와 예측 정보 포인트 간 매칭을 어떻게 시킨건가요?
감사합니다.
1. CNN으로부터 임베딩 되는 특징은 H x W x d_{rgb}이고, pointNet으로부터 임베딩되는 특징은 P x d_{geo} 라고 나와있습니다. 제가 이해하기로는 이미지를 기준으로 모든 픽셀과 매칭을 하는 것이 아니라, point cloud를 카메라 파라미터를 이용하여 2D로 투영시킨 뒤, 각 포인트에 대응되는 위치에 있는 이미지를 이용하는 방식으로 진행하였습니다.
2. GT는 객체 전체에 대한 pose 정보이고, 예측된 pose는 3D point 중 랜덤하게 선택된 포인트로부터 구한 Pose 정보입니다. 따라서, 랜덤하게 선택된 M개의 포인트들이 모두 각각의 pose를 예측하고 이 예측된 pose와 객체에 대한 pose의 오차를 이용하는 loss입니다. (즉, 포인트마다 GT가 달라지지 않습니다.)