Before Review
Stochastic Process라고 해서 시간이 변함에 따라 확률 변수가 어떻게 변하는 지를 모델링하는 수학적 방법이 있는데 이를 Video Representation Learning에 도입한 논문입니다.
CVPR 2023 spotlight에 해당하는 논문이지만 읽으면서 또 나름의 개선점이 보이네요. 그게 무엇인지는 방법론에 대해서 설명할 때 잠깐 얘기하도록 하겠습니다.
리뷰 시작하겠습니다.
Introduction
Fine-Grained Video Representation Learning은 다양한 video down-stream task에서 중요하게 작용합니다. 여기서 Fine-Grained Video Representation이라는 것은 프레임 단위의 Representation 까지 control 하겠다는 것을 의미합니다. 이러한 modeling을 잘 수행하기 위해서는 역시나 video의 temporal dynamics를 잘 이해하는 것이 중요하다고 강조하고 있네요.
초기의 연구는 human-generated annotation에 기반하여 temporal dynamics를 modeling 하였는데 이는 multiple-downstream task에 대해서 domain generalization을 방해합니다. 아무래도 temporal dynamics 처럼 semantic한 데이터에 대해서는 labeling 과정에서도 사람들의 주관에 따라 모호함이 발생하기 때문이겠죠.
이러한 흐름에서 최근 연구들은 Weakly Supervised Learning 혹은 Self-Supervised Learning에 주목합니다.
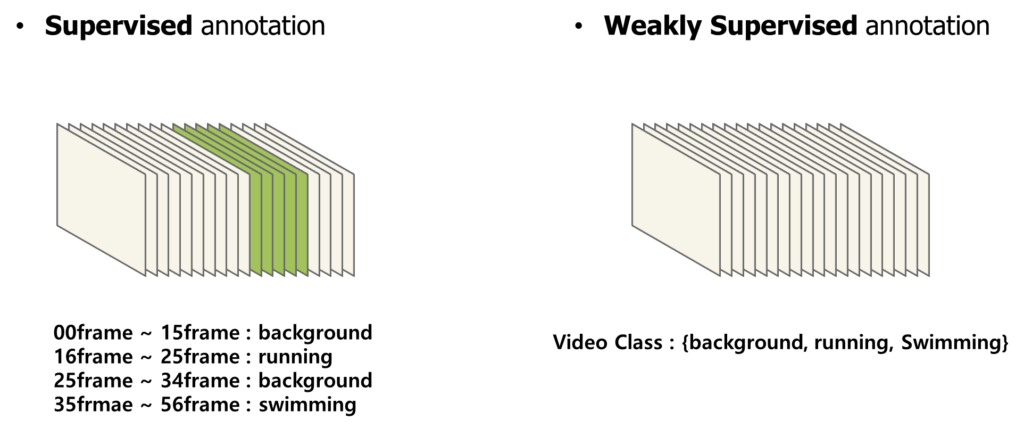
Weakly Supervised Learning은 아래 처럼 프레임 마다 Fine-Grained 레벨의 annotation이 아니라 Video 레벨의 annotation을 제공하는 것을 의미합니다.
적어도 Video 레벨의 annotation을 알고 있으면 뭔가 Video Pair (eg. Contrastive Pair)를 만들 때 유용하게 사용할 수 있겠네요.
Self-Supervised Learning은 저의 리뷰를 계속해서 보신 분이라면 알겠지만 라벨이 없는 상황에서 데이터의 패턴을 학습하는 방법론 입니다.
하지만 Weakly Supervised의 경우 Fine-Grained 보다는 덜 하지만 역시나 Video-level의 라벨을 필요로 한다는 점에서 부담이 되고, 기존의 Self-Supervised 기반의 방법 같은 경우는 View Augmentation에 의존적이라 조금 일반적이지 못하다는 한계가 있었습니다.
위의 내용은 기존 연구들을 요약하는 내용인데, 제가 이전 연구들을 읽지는 않아서 더 자세하게 설명은 어려울 것 같네요.
저자는 Weakly Supervised도 아니고 View Augmentation에 의존적인 Self-Supervised도 아닌 새로운 학습 방식을 제안합니다.

비디오는 기본적으로 Temporal Redundancy가 존재합니다. 인접한 frame들은 비슷한 정보를 가지고 있죠. 이는 FPS가 극도로 낮은 것이 아닌 이상 어느 정도 당연하게 보장되는 가정 입니다.
이러한 Temporal Redundancy 즉, 비디오의 정보 변화는 smooth하게 발생하다는 observation을 통해 저자는 Video as Stochastic Process(이하 VSP)를 통해서 Video를 Modeling 하고자 합니다.
여기서 확률과정(Stochastic Process)은 시간 또는 공간에 따라 변화하는 Random Variable 들의 모음입니다. 간단히 말해서, 확률과정은 확률적인 방식으로 발생하는 이벤트들의 연속적인 집합이라 볼 수 있는 것이죠. 이 이벤트들은 일반적으로 시간의 흐름에 따라 발생하며, 각각은 특정한 확률분포를 따르는 값들을 가집니다. 예를 들어, 시간에 따라 변하는 주식 가격이나 날씨 패턴 등은 모두 확률과정으로 모델링될 수 있습니다.
이러한 관점으로 비디오 내부의 프레임들의 변화도 확률 과정으로 모델링을 해보겠다는 것 입니다.
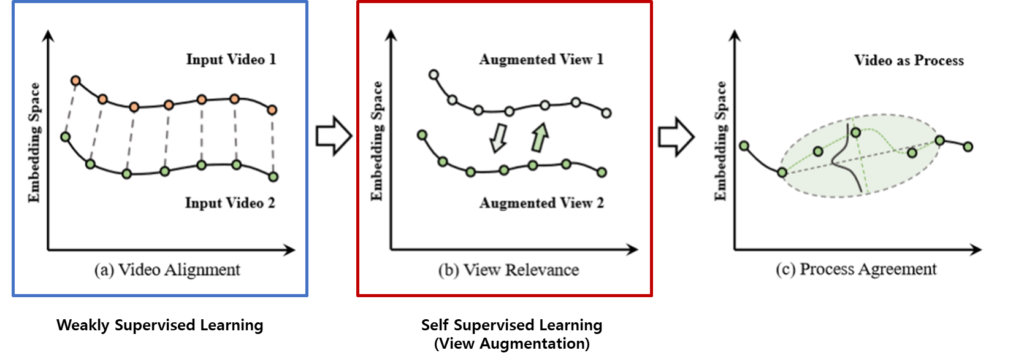
Weakly Supervised는 Video Pair annotation을 통해 동일한 action category에 해당되는 비디오 끼리 서로 view가 비슷한 부분을 찾아서 alignment 시키는 방식으로 학습을 시켰고 Self-Supervised는 Video Pair가 없으니 View Augmentation을 통해 alignment를 시켰습니다.
저자는 이러한 Label이나 Augmentation에 제약이 없는 Process-based 학습 방식을 제안합니다.
NLP에서는 stochastic process를 이용한 연구가 이미 있었지만 이를 비디오로 활용한 것은 본 논문이 처음이라는 contibution도 존재합니다.
그렇다면 이 Video as Stochastic Process (VSP) 라는 것이 무엇인지 지금부터 알아보도록 하겠습니다.
Method
Video as Stochastic Process
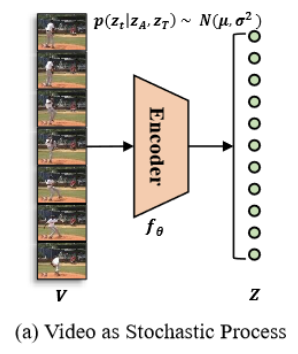
우선 VSP 가장 기본적인 가정은 Video Phase가 일관적이고 부드럽게 변해야 한다는 것 입니다. 이는 Temporal Redundancy에 의해 어느 정도 보장된다고 볼 수 있습니다.
일단 T개의 프레임들이 입력으로 들어오면 각각 embedding을 태워서 T개의 feature representation을 얻을 수 있습니다.
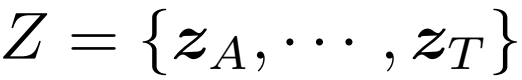
이제 이 feature들을 가지고 stochastic process를 만들 차례 입니다. 이를 위해 continous stochastic process의 Brownian bridge를 사용하였다고 하네요.
z_{A}와 z_{T}를 start point, end point로 설정합니다. 이 때 Brownian bridge의 transition density는 time-variant Gaussian distribution을 만족합니다.
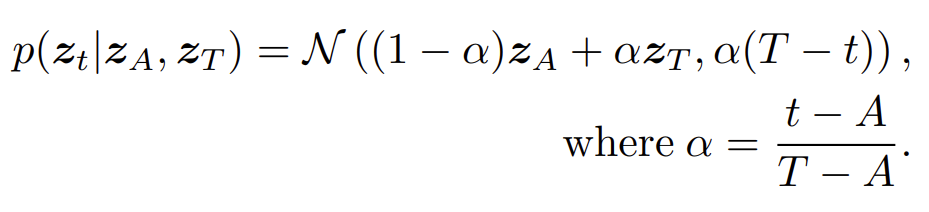
z_{t}는 임의의 point를 의미 합니다. 위의 가우시안 분포의 통계치를 살펴보면
- Mean : (1-\alpha)z_{A}+\alpha z_{T}
Start point와 End point의 선형 결합으로 이루어져 있습니다. z_{t}가 start 부근 근처에 존재하면 z_{A}와 비슷해야 할 것이고 반대로 end 부근 근처에 존재하면 z_{T}와 비슷할 수 있도록 설계한 것 입니다.
- Variance : \alpha(T-t)
분산은 z_{t}가 process에 가운데에 있을 때 가장 uncertainty가 높을 수 있도록 설계한 것 입니다.
Brownian Bridge Construction
Brownian Bridge를 이용한 학습은 triplet pair를 필요로 합니다. Start Point, End Point, Length 이렇게 세 가지의 정보를 필요로 합니다. 저자는 Self-Supervised, Weakly Supervised, Fully Supervised 모든 상황에서 어떻게 하면 Bridge를 구성할 수 있는지 아래와 같이 정의 합니다.
Raw Videos
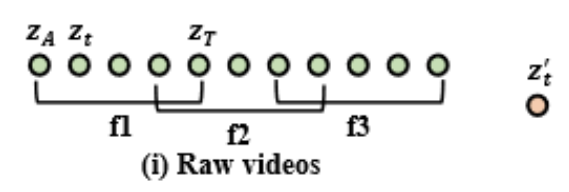
자 일단 라벨이 없는 상황에서는 사실 naive하게 진행합니다. Temporal Redundancy는 구간이 길어지면 보장을 할 수 없으니 어느 정도 짧은 간격을 두고 process sampling을 합니다. 이 때 temporal continuity를 위해 어느 정도 overlap을 허용한다고 하네요. 이렇게 별다른 label 없이 학습한 setting을 VSP라 정의하겠습니다.
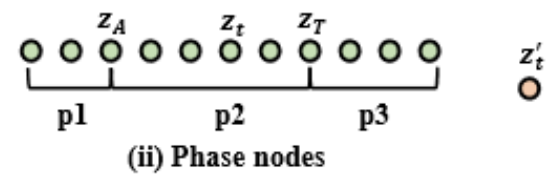
Phase nodes
이 분야에서 Phase node annotaiton은 start와 end point에 대한 구간만 정의되고 각 구간이 어떤 action category인지는 모르는 상황이라 보시면 됩니다. 그럼 이 구간에 대한 annotation이 있으니 bridge를 구성하기는 쉽겠네요. 그냥 phase 하나가 bridge가 되는 것이라 보면 됩니다. 이 annotation을 활용해서 학습한 setting을 VSP-P라 정의하겠습니다.
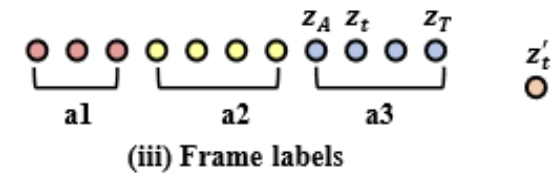
Frame labels
마지막으로 Fine-Grained level의 supervision을 활용 했을 때의 상황입니다. 각 phase에 대한 구간 정보와 더불어 각 phase가 어떤 category에 해당되는지 까지 알고 있으니 bridge를 구축하고 contastive pair를 구성할 때 hard pair를 만들기 더 용이한 상황이라 보시면 됩니다. 이 annotation을 활용해서 학습한 setting을 VSP-F라 정의하겠습니다.
자 이제 각 annotation 상황 별로 bridge contruction에 대한 정의는 끝났으니 이를 활용하여 learning signal을 어떻게 정의할 것인지 살펴보도록 하겠습니다.
Process Contrastive Training
우선 적으로 contrastive loss를 정의하기 전에 z_{t}와 Brownian bridge 안에 target point 간 distance를 정의하도록 하겠습니다.
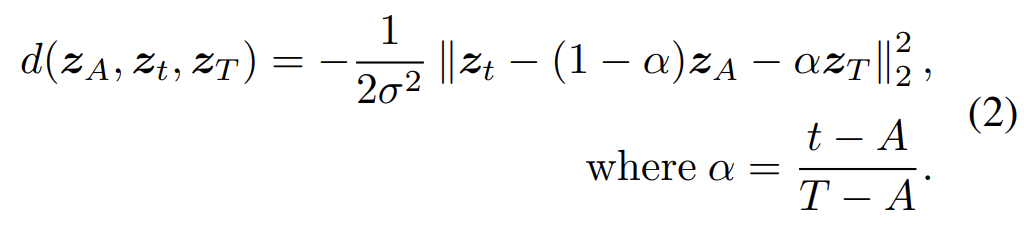
target으로 하는 point는 z_{A}와 z_{T}로 부터 만들어지는 Gaussian Distribution이라 볼 수 있습니다. 이해가 조금 어렵다면 그냥 stochastic process 상황에서 사용하는 거리지표를 썼나 보구나 하고 넘어가셔도 무방합니다.
그 다음으로 contrastive learning을 위해 positive, negative pair를 만들어야할 차례 입니다.
Positive sample은 같은 brownian process에 있는 sample들을 의미합니다. Negative의 경우 다른 brownian process에 있는 sample 들을 의미합니다.
Pair를 만들어줬다면 우리가 잘 알고 있는 Contrastive Loss를 통해서 학습을 진행할 수 있습니다.
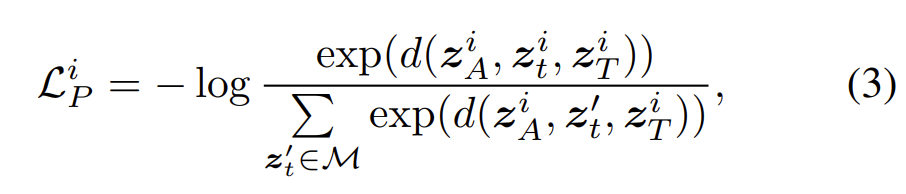
제가 이전까지 리뷰 했던 논문들과 다른 점은 Contrastive Pair를 정의할 때 stochastic process 에 기반한 Pair를 정의했다는 점이라 볼 수 있습니다.
아까 위에서 설명했던 Frame labels를 활용하면 Contrastive Pair를 훨씬 더 정교하게 만들 수 있습니다. 각 bridge 별로 서로 같은 category인지 아닌지 알 수 있기 때문에 Hard Positive, Hard Negative를 annotation을 통해서 만들 수 있는 것이죠.
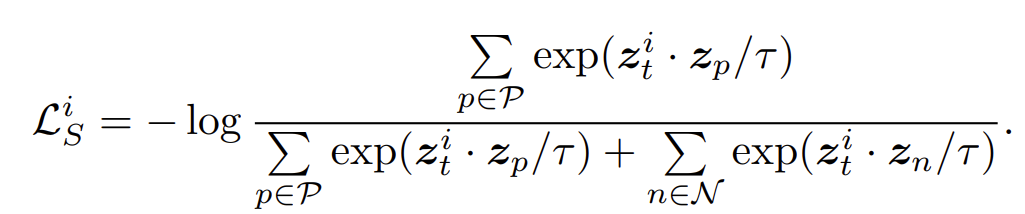
그래서 명시적으로 positive pair, negative pair를 구분하여 계산할 수 있습니다.
VSP, VSP-P의 경우 L_{P} 만을 활용하여 학습을 진행하고 VSP-F의 경우 L_{P}와 L_{S}를 같이 활용하여 학습을 진행할 수 있습니다.
Experiments
Comparison with State-of-the-Art Methods
Phase Classification and Frame Retrieval
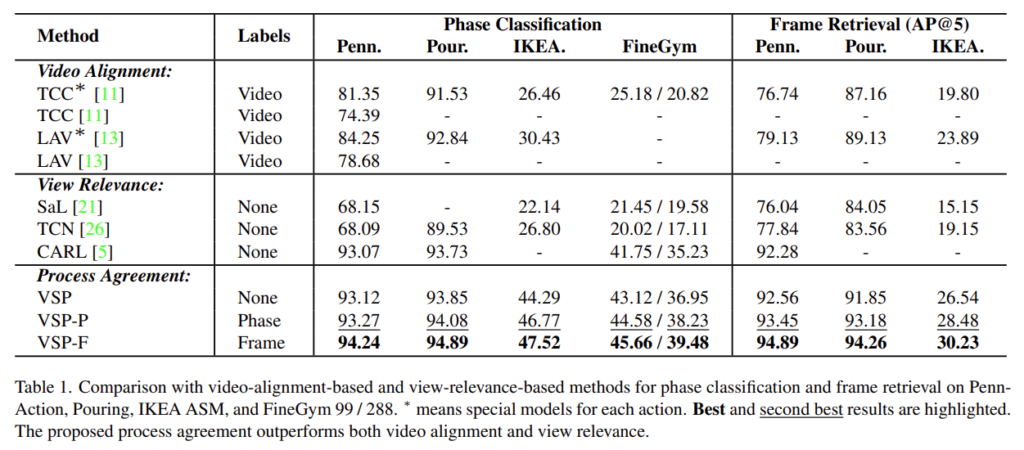
Phase Classification과 Frame Retrieval이라는 task에 대한 benchmarking 입니다. Video Alignment 방식, View Relevance 방식은 기존의 연구 방식이라 보면 되고 Process Agreement가 이번에 저자가 새롭게 제안한 학습 방식이라 보면 됩니다.
CARL이라는 연구와 중점적으로 비교해서 보시면 됩니다. CARL(2022, CVPR) 과 VSP를 비교하면 일단 다 가장 높은 성능을 보여주고 있습니다.
여기서 주목해야 하는 부분은 IKEA나 FineGym같이 어려운 데이터 셋에 대해서 기존 CARL에 비해 인상적인 폭으로 성능을 뛰어넘고 있습니다. Penn이나 Pour와 같이 쉬운 데이터 셋에 대해서는 어느정도 saturation이 되어 성능 폭이 많이 차이나지 않지만 데이터 셋이 어려워지면 본 방법론의 효과가 더욱 극명하게 드러나고 있네요.
VSP-P나 VSP-F는 당연히 더 많은 label을 활용 했기 때문에 성능이 더 높네요.
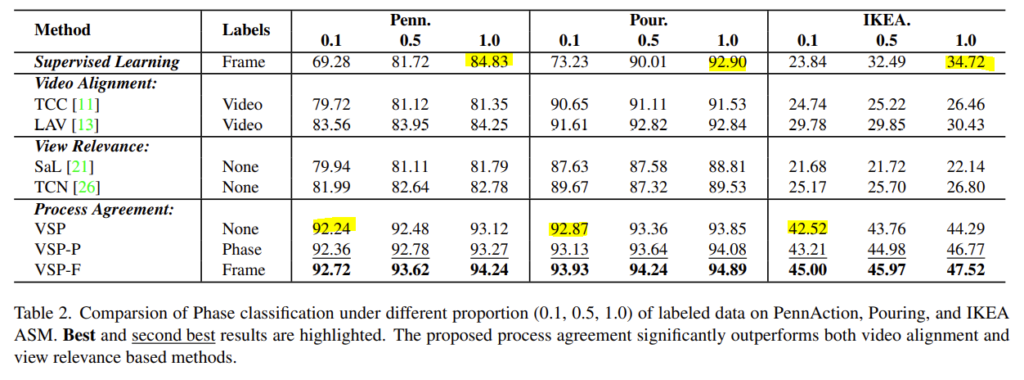
다음으로는 Phase Classification을 토대로 학습에 사용한 label data의 비율을 바꿔가면서 진행한 실험 입니다. 인상적인 것은 VSP가 10% label을 활용했을 때의 성능이 100% Supervised Learning 보다 성능이 높다는 것 입니다.
Ablation Study
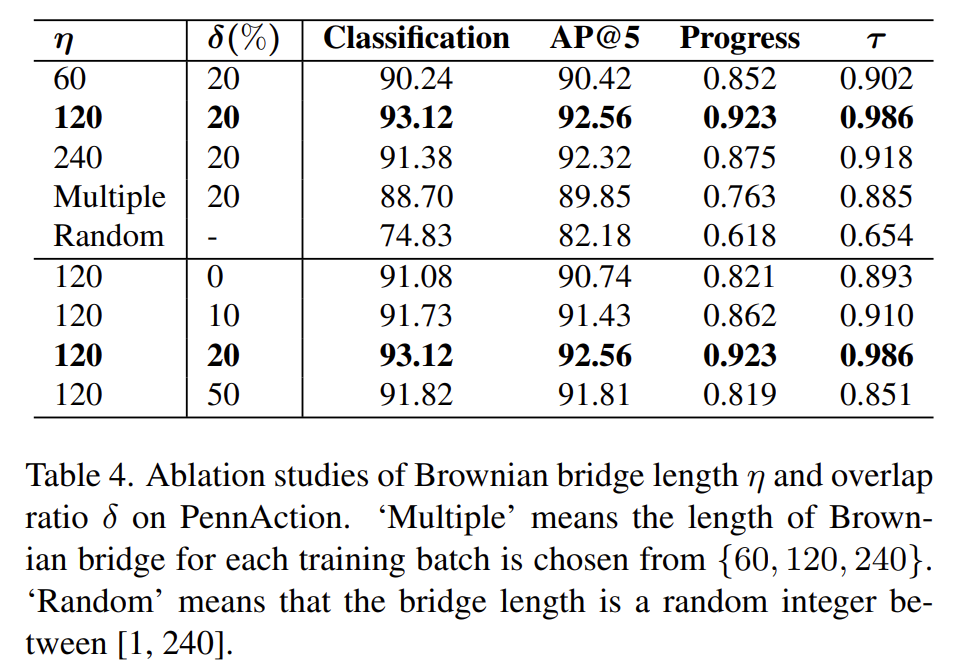
개인적으로는 stochastic process를 컨셉으로 잡았으니 다양한 process 방법에 대한 ablation이 있었으면 좋았을 텐데 그러한 부분이 없던 것은 조금 아쉽네요.
bridge 길이에 대한 ablation 하나만 보면 되는데 결론적으로는 너무 짧거나 너무 길면 성능이 떨어지는 모습을 볼 수 있습니다. 근데 이 부분에 대해서 조금 성능 변화가 크게 발생해서 이러한 bridge 길이에 대해 민감한 부분은 조금 아쉽네요.
Generalization Verification
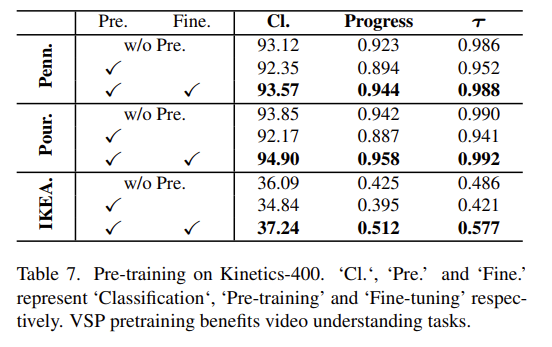
Kinetics로 사전 학습한 다음에 성능을 보여주고 있습니다. 참고로 위의 모든 실험들은 pretrain과 downstream data가 모두 같습니다. 이러한 상황에서 저자가 제안하는 VSP는 large-scale의 unlabled data 에서도 좋은 representation을 얻을 수 있음을 보여주는 실험 입니다.
Conclusion
논문의 근본적인 아이디어는 [ICLR 2022 Oral] Language modeling via sthochastic process 에서 가져왔네요. 확실히 NLP와 비디오는 context를 잘 모델링 해야 한다는 점에서 비슷한 면이 있는 것 같습니다.
깃허브에 들어가보니 코드가 공개 예정이던데 어서 빨리 코드와 체크포인트가 공개되었으면 좋겠네요.
이상으로 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
확률과정이라는 개념이 낯설어 어렵지만, 동영상을 brownian bridge라고 하는 확률과정의 형태(?)를 이용하여 설명할 수 있는데, 같은 brownian bridge에 속한 것들을 positive, 그렇지 않은 것들을 negative로 하여 contrastive learning을 수행한다는 것으로 이해하였습니다.
이 brownian bridge가 어떤 것인지, 영상이 같은 process에 속해있다는 것이 어떤 의미인지 간단하게 알려주실 수 있을까요?
감사합니다!
Brownian Bridge : https://en.wikipedia.org/wiki/Brownian_bridge
Brownian Bridge는 브라운 운동(무작위로 움직이는 입자나 입자군의 운동을 설명하는 확률과정)을 특정한 시간 간격 내에서 관찰하는 것을 의미합니다.
이때 같은 프로세스라는 것은 동일한 시간 간격 내(논문으로 따지면 동일한 start와 end 내에 있는 것)에 있는 것을 의미하겠죠.
저도 얕게만 알고 리뷰를 작성한터라 더 자세한 답변을 드리기는 어렵네요.