제가 이번에 리뷰할 논문은 FFB6D라는 논문입니다. 6D Pose Estimation 논문으로, 2021년 CVPR oral paper라 합니다.
Abstract
본 논문은 FFB6D(Full Flow Bidirectional fusion network for 6D Pose Estimation)를 제안한 논문으로, 단일 RGBD이미지를 이용하는 방식입니다. 저자들은 RGB의 외관 정보와 Depth의 기하학적 정보가 상호보완적인 정보이지만, 이를 완전히 활용할 수 있도록 융합하는 방식에 대해서는 알려지지 않았다는 것에 인사이트를 얻었다고 합니다. 따라서 외관과 기하학적 정보를 결합하는 방법을 학습하는 FFB6D를 제안하였다고 합니다. FFB6D는 양방향 융합 모듈을 통해 representation 학습 단계에서 인코딩과 디코딩 레이어에 융합을 적용하는 방식입니다. 이를 통해 두 네트워크는 다른 네트워크의 local하고 global한 상호보완적 정보를 얻게 된다고 합니다. 또한, representation 출력 단계에서 효율적인 3D keypoint selection 알고리즘을 설계하여 pose를 추정하기 위한 keypoint를 위치를 찾는 과정을 간단하게 하였다고 합니다. 실험을 통해 여러 벤치마크에서 SOTA를 달성하였다고 합니다.
Introduction
6D Pose Estimation은 실제 활용에 있어서 굉장히 중요하지만, 센서의 노이즈, 조도 변화, occlusion등에 의해 굉장히 어려운 task입니다. 딥러닝의 발전으로 상당한 발전이 이루어지기는 하였으나, 영상만을 이용하는 것은 기하학적 정보가 줄어 어려움이 있고, 이에 depth 정보를 활용하는 여구들이 발전하게 되었습니다. 이러한 연구에서는 서로 다른 모달리티의 두 데이터의 정보를 완전히 이용하면서도 효과적으로 융합하는 방식에 대한 연구가 진행되고 있습니다.
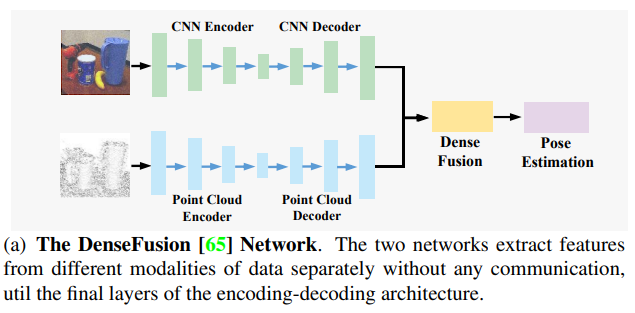
기존 연구 중 한 흐름은 RGB 이미지에서 초기 pose를 추정하고, ICP(Iterative Closest Point)알고리즘이나 multi-view hypothesis verification 방식을 이용하여 point cloud에서 pose를 개선하는 방식입니다. 이러한 방식은 시간이 오래 걸리며 end-to-end가 불가능하다는 한계가 있습니다. 또다른 흐름은 point cloud에 point cloud network(PCN)와 CNN을 적용하여 객체에 대해 crop 되어있는 이미지와 point cloud에서 각각 dense한 특징을 추출하고, 추출된 특징을 연결하여 pose 추정을 수행합니다. 최근에는 위의 그림1의 DenseFusion 방식처럼 단순 concatenation연산을 dense fusion 모듈로 대체하여 pose의 정확도를 개선하는 방법론들이 제안되었다고 합니다. 그러나 feature concatenation과 DenseFusion 모두 외관이 비슷하거나 반사하는 표면을 가진 몰체가 포함되는 시나리오에서 CNN과 PCN이 달라져 성능이 떨어지는 문제가 있다고 합니다.
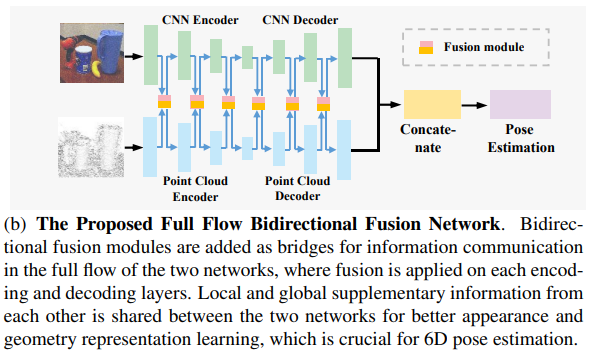
저자들이 제안하는 FFB6D(full flow bidirectional fusion network)는 그림2와같이 encoder&decoder에서 레이어를 융합하는 네트워크로, 저자들이 핵심으로 생각하는 RGB 외관정보와 point cloud의 기하학적 정보를 추출하는 과정에서 서로 상호 보완적으로 작용할 수 있도록 디자인하였다고 합니다. 상호 보완적으로 작동하는 방식에 대해 설명하자면, RGB에서는 외관이 유사한 경우 각 객체의 고유한 representation을 학습하기 어렵지만, depth 정보를 학습하는 PCN에서는 각 객체에 대한 구분이 가능하고, 반대로 물체가 반사되는 경우 point cloud의 depth 정보가 누락될 수 있으나, 외관 정보를 학습하는 CNN으로부터 정보를 얻을 수 있다고 합니다. 이러한 이유로 encoding-decoding 단계에서 분리된 특징 추출기를 이용해야하며, fusion 방식을 통해 두 정보를 적절히 융합해야 한다고 합니다.
pose 추정은 학습된 외형과 기하학적 표현을 이용하며, 3D keypoint 기반의 6D pose 추정 방식인 PVN3D**가 제안한 파이프라인을 따른다고 합니다. 아래의 그림3이 PVN3D의 파이프라인에 대한 그림으로, RGB와 Depth로부터 특징을 추출한 뒤, keypoint를 찾아 voting을 이용하여 6D pose를 추정하는 방식입니다. (더 자세한 내용은 형준님이 작성하셨던 리뷰를 참고해주세요.) 그러나 PVN3D는 3D keypoint를 선택하기 위해 keypoint 사이의 거리만 고려하므로 일부 선택된 keypiont는 textureless한 영역에 생길 수 있어 위치를 찾기 어려울 수 있다고 합니다.(textureless->특징 정보가 적음) 저자들은 객체의 texture 정보와 기하학적 정보를 모두 고려하여 3D keypoint를 자동으로 선택할 수 있는 SIFT-FPS 알고리즘을 제안하였습니다. 이를 통해 특징이 많은 keypoint를 더 쉽게 찾을 수 있고, pose의 정확도도 올릴 수 있었다 합니다.
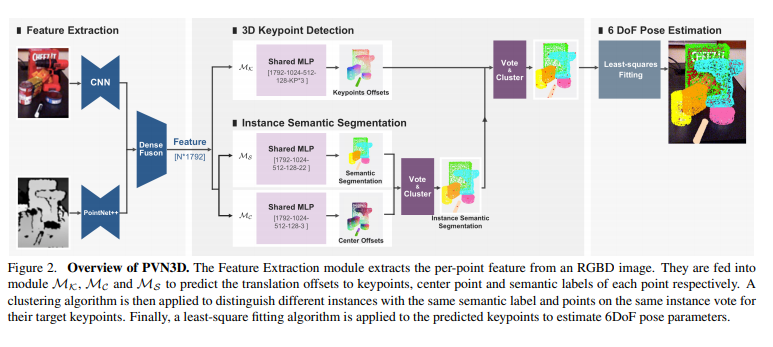
**Yisheng He, Wei Sun, Haibin Huang, Jianran Liu, Haoqiang Fan, and Jian Sun. Pvn3d: A deep point-wise 3d keypoints voting network for 6dof pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages
저자들의 방법론은 6D pose estimation에서 유명한 벤치마크인 YCB-Video, LineMOD, Occlusion LineMOD에서 실험을 진행하였고, 실험 결과 시간이 많이 드는 post-refinement과정 없이도 SOTA를 달성했다고 합니다.
본 논문의 Contribution을 정리하면
- 단일 RGBD이미지로부터 representation을 학습하기 위한 새로운 네트워크를 제안하였고, 3D object detection과 같은 다른 task에 일반화 가능
- object의 texture와 기하학적 정보를 활용하는 간단하고 효율적인 3D keypoint selection 알고리즘 제안
- YCB-Video, LineMOD, Occlusion LineMOD에서 SOTA 달성
Related Work
Pose Estimation with RGB-D Data
전통적인 방법은 수동 코딩된 템플릿이나 RGBD의 다른 목적으로 최적화된 RGBD 데이터의 feature를 이용하여 대응 그룹화와 hypothesis verification을 수행하였다고 합니다. 최근의 데이터기반 방식은 RGB 이미지에서 초기 pose를 예측하고, ICP와 같은 알고리즘을 이용하여 pose의 예측을 고도화 하는 방식을 이용합니다. 그러나 이러한 방식은 시간이 오래걸리고, end-to-end로 최적화 할 수 없다고 합니다.
point cloud의 birdeye-view(위에서 내려다본 형태) 이미지에서 RGB 이미지의 외관정보를 추가하는 작업을 할 수 있었다고 합니다. 그러나 이러한 방식은 RGB 표현을 학습하기 위한 기하학적 정보는 무시하고 위에서 내려다 본 point cloud이미지는 물체의 pitch roll 정보를 무시하며 2D CNN도 기하학 정보에 잘 포착하지 못했다고 합니다.
CNN과 Point Cloud네트워크를 분리하여 각 특징을 추출한 다음 pose를 추정하기 위해 두 정보를 융합하는 방식은 더욱 효과적일 수 있으나, 각각 추출된 특징을 추출하는 과정에서로 정보를 공유할 수 없어 학습되는 representation에 한계가 있다고 합니다. 저자들은 이러한 한계를 극복하기 위해 양방향 융합 모듈을 통해 두 네트워크의 정보를 주고받을 수 있도록 하였다고 합니다.
** Roll-Pitch-Yaw

Proposed Method
RGBD 이미지가 주어졌을 때 6D Pose Estimation은 물체를 좌표계에서 카메라 좌표계로 변환하는 변환 행렬을 예측하는 것을 목표로 합니다. 변환행렬은 회전과 이동행렬로 구성됩니다.
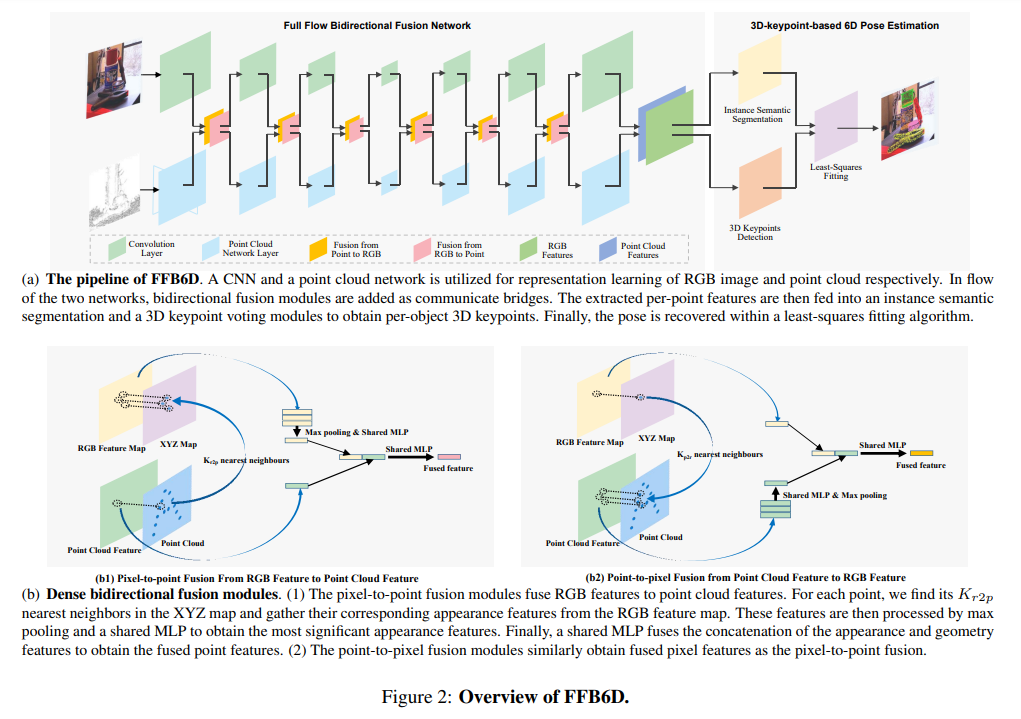
1. Overview
저자들은 그림4의 (a)와 같이 full flow bidirectional fusion network를 제안하였습니다. 객체별 3D keypoint localization을 위해 point 단위의 RGBD feature를 추출합니다. RGB에서 외관 특징을 추출하고 Depth에서 기하학적 특징을 추출하는 과정에 각 layer의 정보를 교환하는 역할을 하는 point-to-pixel과 pixel-to-point 융합 모듈이 추가됩니다. 이를 통해 두 네트워크는 서로의 정보를 활용하여 자체 representation을 더 잘 학습할 수 있습니다. 그 후, point별 특징을 instance segmentation과 3D keypoint selection 모듈에 입력하여 장면에서 object별 3D keypoint를 얻습니다. 이후 least-squre fitting 알고리즘(오차의 제곱이 최소가 되도록 하는 알고리즘)을 이용하여 pose 파라미터를 추정합니다.
2. Full Flow Bidirectional Fusion Network
정합된 RGBD 이미지가 주어졌을 때, 카메라의 intrinsic matrix를 이용하여 depth 이미지를 point cloud로 올립니다. 이후 RGB 이미지와 point cloud에서 각각의 특징을 추출하기 위해 CNN과 PCN을 적용합니다. 이때 두 정보에 양방향 통신을 위해 point-to-pixel, pixel-to-point fusion 모듈이 추가되어 서로의 local 및 global 정보를 활용하여 representation을 학습할 수 있게 됩니다.
Pixel-to-point fusion from image features to point cloud featuers
CNN에서 추출한 외관 정보를 PCN(point cloud network)에 공유하는 모듈로, 가장 간단한 방법은 RGB feature map에서 global feature를 생성하여 이를 각 point cloud feature map에 연결하는 방식입니다. 그러나 픽셀의 대부분이 배경이며, 여러 object가 있기 때문에 RGB feature로부터 global한 feature를 생성할 경우 많은 detail한 정보가 사라지고, pose 추정에도 안좋은 영향을 줄 수 있습니다. 따라서 point-to-pixel 모듈을 도입하였다고 합니다. 이때 주어진 RGBD 이미지는 align이 맞추어져 있으므로 pixel과 point를 연결할 수 있습니다.
point-to-pixel 과정은 3D Point에 대응되는 pixel의 depth를 카메라의 intrinsic matrix를 이용하여 3D point로 올리고 XYZ map을 얻습니다. 그림4의(b) 왼쪽의 그림이 이에 해당하며, 각 point feature는 XYZ map에서 3D point의 주변 point인 K_{r2p}를 찾아 대응되는 RGB의 feature map에서 외관 정보를 모아 인접한 외관의 특징을 통합하고 shared MLP를 이용하여 point cloud의 feature와 동일한 채널 크기로 압축합니다.
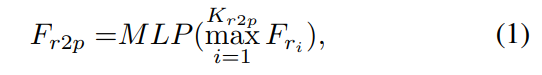
- F_{r_i} : RGB feature에서의 i번째 근접 픽셀
- F_{r2p}: 통합된 외관 feature
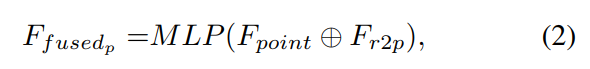
point feature인 F_{point}와 F_{r2p}를 concate(⊕)하여 함께 shared MLP를 통과시켜 융합된 point feature를 얻습니다.
이러한 방식을 이용하여 feature를 융합하며, 한가지 더 고려해야할 점은 encoder가 깊어질 수록 높이와 너비가 작아지는 것입니다. 각 pixel의 해당 3D 좌표를 찾기 위해 XYZ map을 유지해야 하고, 가장 간단한 해결 방안은 원본의 크기와 동일해지도록 kernel을 적용하여 XYZ의 평균을 계산하여 새로운 XYZ 좌표를 생성하는 것이지만, 이는 전경과 배경 사이의 경계에서 depth가 크게 변하는 문제로 인해 노이즈가 많이 추가될 수 있다고 합니다. 따라서 nearest interpolation 알고리즘을 이용하는 것이 평균을 이용하는 것 보다 더 나은 방식이라 합니다.
Point-to-pixel fusion from point cloud features to image features
point-to-pixel 모듈은 위의 pixel-to-point 모듈과 마찬가지로 작동하며, 그림4의 (b) 오른쪽에서 네트워크를 확인하실 수 있씁니다. 마찬가지로 global한 특징을 각 픽셀에 연결하는 방식이 아닌, dense하게 특징을 융합하는 방식을 이용합니다. XYZ 좌표가 있는 각 픽셀의 특징에 대해 point cloud에서 가장 가까운 K_{p2r} point를 찾아 해당 point의 feature를 수집합니다. point의 feature를 RGB feature의 채널과 동일하게 압축한 뒤 max pooling을 이용하여 통합하고 통합된 point feature를 RGB feature에 연결하여 shared MLP로 융합된 feature를 생성해냅니다.
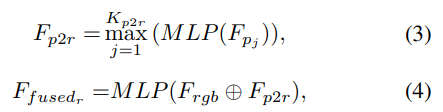
- F_{p_j} : j번째 근접 point feature
- F_{p2r}: 통합된 point feature
Dense RGBD feature embedding
위의 제안된 full flow fusion network를 통해 CNN브랜치에서 dense한 외관 embedding을, PCN 브랜치에서는 dense한 기하학적 특징을 얻을 수 있습니다. 그 후 각 점을 이미지 평면에 투영시켜 두 feature 사이의 대응을 찾습니다. 이 대응 관계에 따라 외관과 기하학적 특징쌍을 얻고 이를 연결하여 추출된 dense한 RGBD feature를 얻을 수 있습니다. 이렇게 얻은 feature는 instance segmentation과 3D keypoint selection에 입력으로 들어가게 됩니다.
3. 3D Keypoint-based 6D Pose Estimation
해당 과정은 3D keypoint를 이용하여 물체의 pose를 추정하는 PVN3D 연구를 기반으로 하였습니다. 저자들은 PVN3D의 keypoint 공식을 이용하면서도 3D keypoint 선택 알고리즘을 개선시켜 물체의 texture 정보와 기하학적 정보를 충분히 활용하여 pose를 예측할 수 있도록 하였습니다. 장면에서 object별로 선택된 keypoint를 감지한 후 least-squres fitting알고리즘을 이용하여 pose 파라미터를 예측합니다.
Per-object 3D keypoint detection
앞선 과정을 통해 dense한 RGBD의 embedding feature를 얻었고, PVN을 따라 인스턴스 별로 객체를 구분하는 instance semantic segmentation 모듈과 3D keypoint를 찾는 keypoint voting 모듈을 통해 객체별 3D keypoint를 구합니다. n instance semantic segmentation은 point마다 클래스를 예측하는 semantic segmentation 모듈과 객체 중심에 대한 piont 별 offset을 학습하여 인스턴스를 구분하는 center point voting 모듈로 구성됩니다. 각 인스턴스에 대한 keypoint voting 모듈은 MeanShift clustering 방식을 이용하여 3D keypoin에 투표하는 selected keypoint에 대한 offset을 학습한다고 합니다.
Keypoint selection
기존의 연구들은 가장 먼 점을 샘플링하는 FPS 알고리즘을 이용하였습니다. 그러나 이러한 방식은 유클리드 거리만을 고려하기 때문에 texture가 없는 영역이 선택될 경우 감지를 하기 어렵고 Pose의 정확도가 떨어집니다. object의 texture와 기하학적 정보를 최대한 활용하기 위해 간단하지만 효과적으로 3D keypoint를 선택할 수 있는 SIFT-FPS 알고리즘을 제안하였다고 합니다.
SIFT 알고리즘을 이용하여 texture 이미지에서 2D Keypoint를 감지한 뒤 이를 3D로 변환하고 FPS 알고리즘을 적용하여 상위 N개의 keypoint를 선택하는 방식이라 합니다. 이처럼 texture 정보를 고려하는 과정을 추가함으로써 기존의 keypoint selection 과정의 문제점을 해결하고자 하였습니다.ㄷ
Experiments
Benchmark Datasets
- YCB-Video
- 21개의 선별된 YCB 객체의 장면을 캡쳐한 92개의 RGBD 비디오를 포함
- 합성 영상을 이용하여 train set 구성
- depth영상의 구멍을 hole completion 알고리즘을 이용하여 채움
- LINEMOD
- 13개의 object가 포함된 데이터셋
- texture less한 물건, clutter한 장면, 조도 변화가 있어 복잡한 데이터 셋임.
- Occlusion LINEMOD
- 한 장면에 여러 annotation된 object들이 있음
- 객체들이 많이 occluded 되어있어 challenge함
Evaluation Metrics
평균 distance metrics인 ADD(-S)를 이용하여 평가를 진행합니다. ADD는 예측된 pose와 GT pose로 변환된 object point 쌍 사이의 평균 거리를 구하며, 아래의 식으로 구할 수 있습니다. 이때 대칭적인 물체는 AAD-S를 이용하여 평가를 진행합니다.(도넛과같이 회전해도 큰 차이가 없는 객체애 대한 고려를 위해)
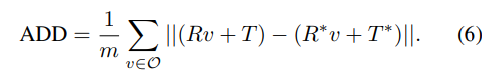
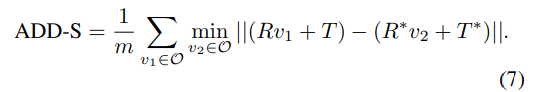
YCB-Video에서는 이전 연구를 따라 accuracy-threshold 곡선의 아래 여역을 계산하여 평가를 진행합니다. (ADD-S와 ADD(S) AUC) LineMOD는 물체의 직경의 10% 미만의 distance 정확도를 리포팅합니다.
Evaluation on Three Benchmark Datasets
YCB-Video
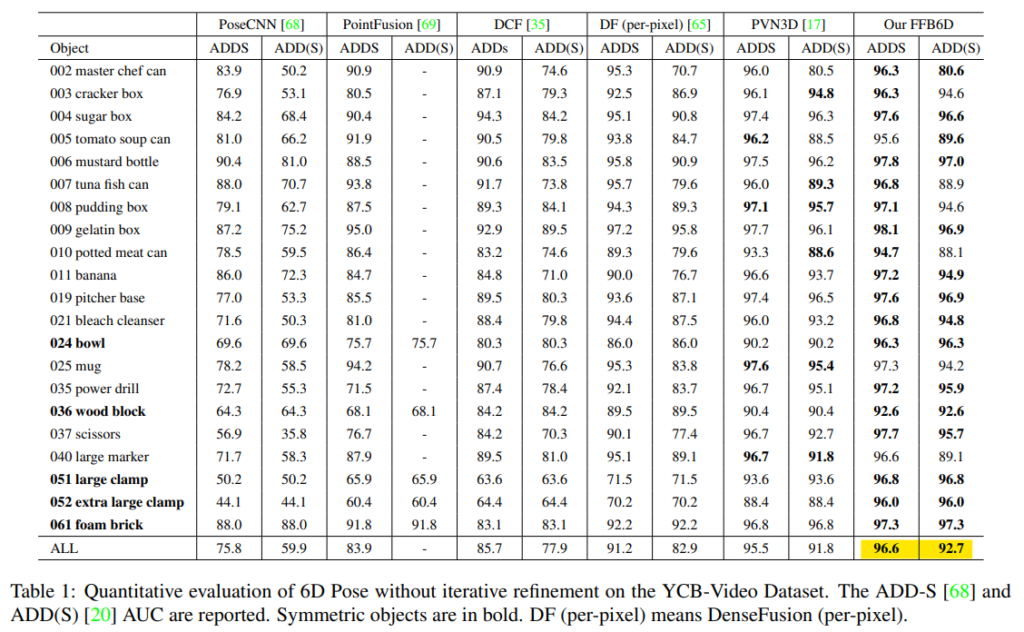
위의 Table1은 YCB-Video에서 평가결과이다. FFB6D는 기존 방법론의 SOTA 성능보다 ADD-S에서 1.1%, ADD(S)에서 0.9% 더 좋은 성능을 보였다.
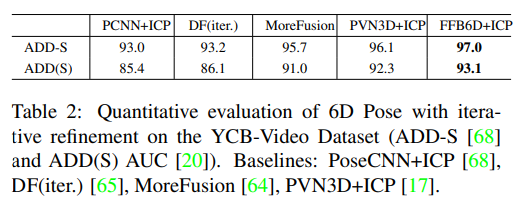
또한, 추가적인 refinement를 통해 정확도를 더욱 높일 수 있으며, ADD-S에서 refinement가 없어도(Table1) 다른 방법론에 refinement를 적용한 것 보다 좋은 성능을 보이는 것을 확인할 수 있습니다.
Robustness towards occlusion.
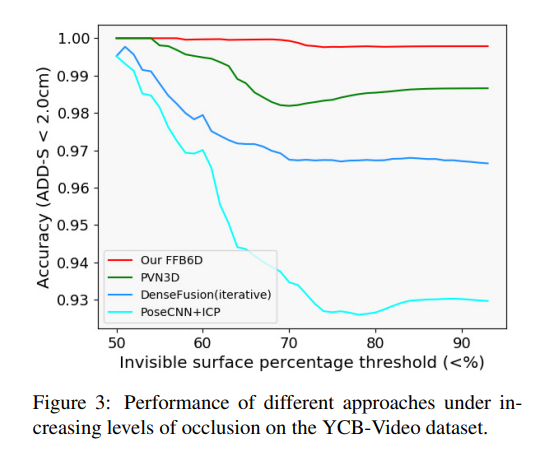
그림5는 YCB-Video 데이터에서 occlusion 정도에 따른 ADD-S 정확도가2cm 미만인 경우를 그래프로 시각화 한 결과입니다. occlusion이 증가할수록 기존 방법론들은 성능이 저하되지만, 저자들이 제안한 FFB6D는 성능 저하가 거의 발생하지 않습니다. 이는 양방향 fusion 방식이 외관 정보와 기하학적 정보를 최대한 활용하여 많은 영역이 가려진 경우에도 keypoint를 찾을 수 있도록 한 것이라고 저자들은 주장합니다.(occlusion이 심해도 두 정보를 상호보완적으로 활용하여 객체를 잘 구분할 수 있었다는 것으로 이해하였습니다. 일부 영역만 보일 경우, 가리고있는 물체와 하나로 생각할 수 잇으나, depth나 외관정보를 적절히 활용하여 이를 구분할 수 있었다고 생각하면 될 것 같습니다.)
Evaluation on the LineMOD dataset & Occlusion LineMOD dataset.

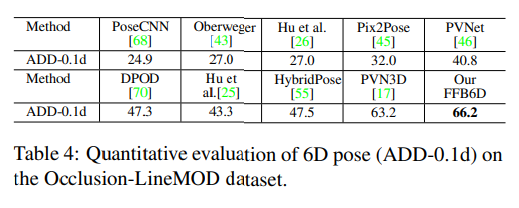
table 3과 table4는 LineMOD와 Occlusion LineMOD에 대한 실험 결과입니다. 두 데이터셋에서 모두 SOTA를 달성하였으며, Occlusion LineMOD에 대한 결과를 통해 저자들이 제안한 방식이 occlusion에서 잘 작동함을 다시한번 보였습니다.
Ablation Study
Effect of full flow bidirectional fusion
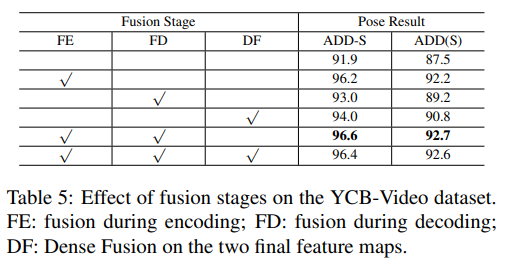
Table5는 저자들이 제안한 full flow bidirectional fusion이 도움이 되는 지 검증하기 위해 융합단계에 대한 ablation 실험을 진행한 결과입니다. 융합을 하지 않은 첫번째 행에 대한 결과와 비교했을 때, encoding과 decoding, 최종 feature map에 fusion 모듈을 추가할 경우(순서대로 2,3,4행의 결과) 모두 성능이 향상되는 것을 확인할 수 있습니다. 그중 encoder에 추가한 경우 성능이 크게 향상되었습니다. 또한, encoding과 decoding에 모두 적용할 경우에 가장 좋은 성능을 보였고, 모두 적용한 경우의 성능이 큰 차이가 없는 이유는 encoding과 decoding과정에서 정보를 모두 융합하였기 때문에 DenseFusion이 추가되어도 성능에 이득이 없다고 분석하였습니다.
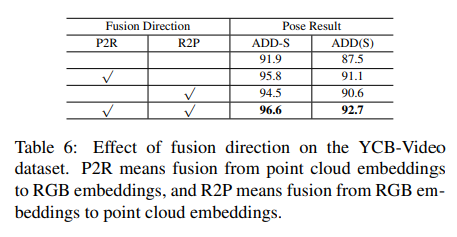
또한 bidirection의 효과를 확인하기 위한 ablation study를 진행하였고, 각각의 방향으로 융합을 진행하는 것도 성능 향상에 큰 도움이 되며, 둘 다 적용할 경우 가장 좋은 성능을 보임을 확인하였습니다.
Effect of 3D keypoints selection algorithm
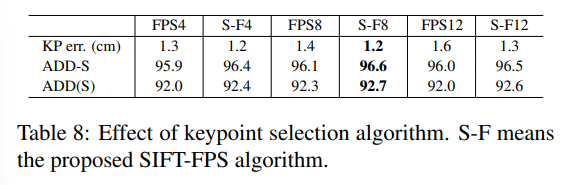
texture 정보를 고려하여(SIFT를 이용) keypoint를 선택하는 SIFT-FPS 알고리즘에 대한 실험 결과입니다. 숫자는 keypiont의 개수를 의미하며, 결과를 종합하였을 때, SIFT-FPS 알고리즘으로 8개의 keypoint를 선택하는 것이 가장 좋은 성능을 보였습니다.
Model parameters and time efficiency
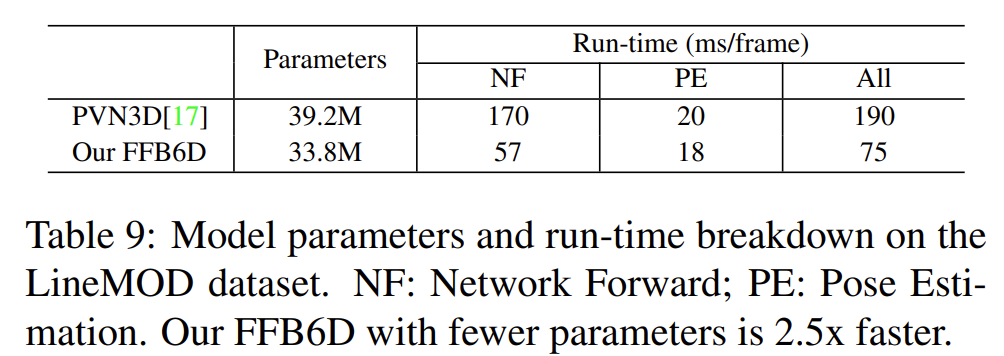
위의 Table 9는 파라미터와 시간에 대한 결과로, 저자들이 제안한 방법론은, 저자들이 베이스라인으로 삼았던 PVN3D와 비교하였을 때 약 2.5배 속도가 빨라진 것을 확인할 수 있습니다.
양방향 정보 공유를 위해 제안한 FFB6D 네트워크가 두 정보를 결합하는 방식이 참신하다고 생각됩니다.(단순 concate이아닌 XYZ map이라는 것을 활용한다는 점에서..) 그리고 실험을 풍부하게 하여 자신들의 결과를 입증한 논문인 것 같습니다.
안녕하세요, 좋은 리뷰 감사합니다.
간단한 질문이 있습니다. shared MLP는 기존 MLP랑 역할이 다른 건가요? 다르다면 해당 역할이 궁금합니다.
감사합니다.
안녕하세요 희진연구원님.
shared MLP는 가중치를 공유하는 MLP를 의미합니다. 여기서는 동일한 가중치로 point들에 대한 연산을 수행한다는 점에서 이렇게 표현한 것 같습니다.
감사합니다.
좋은 리뷰 감사합니다.
제가 이번에 읽은 fusion논문에서도 단순히 concat하는 fusion방식을 지적하며 명시적인 fusion방식은 제안하는데 아이디어가 비슷하네요.
혹시 6d pose estimation쪽에서는 model의 inference speed에 대해서는 아직 크게 고려하지 않나요?
감사합니다.
안녕하세요. inference speed에 대한 실험 결과가 있으나 제가 추가하지 않았습니다.
우선 6D Pose Estimation도 로봇에 활용하려는 연구이다보니, inference time에 대한 고려가 있습니다. 또한 리뷰에서 본 논문은 언급했듯이 시간이 많이 드는 후처리 과정이 없어도 정확도 높은 예측이 가능한 방법론을 제안하였습니다. 이 부분은 제가 리뷰에 실험을 추가해두었습니다.
안녕하세요 승현 연구원님,
좋은 리뷰 감사합니다.
설명이 자세해서 이해하는 데 도움이 됐습니다.
단순히 RGB map의 features와 point cloud features map의 features를 concat하는 건 퓨전의 효과를 충분히 내지 못하고 오히려 성능 하락으로 이어질 수 있다고 이해를 하였는데요 그 이유에 대해서 조금 이해가 완전히 되지 않았는데 그 부분을 조금 더 설명해주실 수 있을까요?
감사합니다.
안녕하세요. 질문 감사합니다.
우선 RGB와 Depth 정보가 상호보완적이라는 것을 이해하셨을까요? 서로 상호보완적인 특성을 활용하기 위해 2차원 Depth map이 아니라 3차원 point cloud로 만들어 사용합니다. 이러한 저자들의 관점이 융합과정에도 이어집니다. pixel-to-point와 point-to-pixel 과정을 통해 3차원 point와 2차원 픽셀에 대응되는 특징을 융합하게됩니다.