Visual Place Recognition 분야의 논문을 읽어보려고 하다 Place Recognition의 베이스 논문이라고 할 수 있는 NetVLAD에 관한 이해가 우선되어야 할 것 같아 NetVLAD 논문을 읽게 되었습니다. 이 논문은 제목에서 볼 수 있듯이 Place Recognition task의 논문으로 query 이미지의 특징을 추출하고, 추출된 특징을 바탕으로 retrival을 수행하여 query 이미지의 위치를 추정하는 task입니다. NetVLAD는 CNN을 기반으로 E2E학습이 가능한 특징 기술자의 종류로, 이를 기반으로 여러 분야에서 널리 활용되고 있습니다. 그럼 본격적으로 리뷰 시작하겠습니다.
Introduction
저자들은 intro에서 여느 논문과 같이 task의 중요성을 언급합니다. Visual Place Recognition은 vision 데이터를 기반으로 물체의 위치를 추정하는 task로 컴퓨터 비전뿐 아니라 로보틱스, 자율 주행 application, 증강 현실, geo-localizing 분야에서 많은 관심을 받고 있습니다.
이러한 place recognition에는 해결해야 할 문제점이 있습니다. 하나는 조명 등 시간에 따라 모습이 달라지는 장소들을 동일한 장소로 인식할 수 있도록 하는 것이고, 다음으로는 비슷해 보이는 장소들을 구별할 정도로 풍부한 정보를 담고 있으면서도 도시 혹은 국가 전체를 표현할 수 있을 정도로 compact한 representation을 찾는 것입니다.

place recognition은 전통적으로 instance retrival 방식으로 해결하였습니다. 사전에 위치 정보를 알고 있는 이미지의 database가 존재하고 query 이미지가 들어왔을 때, query와 가장 유사한 이미지를 database에서 찾아 query 이미지의 위치를 추정하는 것입니다. 이때 각 이미지의 유사성을 비교하기 위해 SIFT와 같은 local feature를 추출하여 bag-of -visual-word, VLAD, Fisher vector 방법론을 적용하여 하나의 이미지를 single vector로 나타내었습니다.
저자들은 Image classification, scene recognition, object detection 등의 분야에서 강력한 성능을 보여준 CNN에 주목하였고 이를 place recognition에 직접적으로 적용할 수 있는 방법인 NetVLAD를 제안하였습니다.
CNN을 place recognition에 적용할 때, 다음과 같은 세 가지의 challenge들이 있었습니다.
- 어떤 CNN architecture가 Place Recogniton에 적합한가?
- 학습에 사용할 만큼의 충분한 annotated 데이터를 어떻게 확보할 것인가?
- 설계된 architecture를 어떻게 end-to-end로 학습시킬 것인가?
Method overview
image retrival기반의 place recognition은 위치 정보가 없는 query 이미지를 input으로 위치 정보가 존재하는 large image database에서 retrival을 수행하고 그 중 query와 유사도가 높은 순으로 정렬했을 때 상위에 존재하는 이미지들의 위치 정보를 query의 위치를 예측하는 데 사용합니다. image retrival을 수행할 때 query와 database의 이미지는 해당 이미지의 특징을 잘 나타내는 고정된 크기의 벡터로 변환되며 이를 수식으로 표현하면 이미지I_i의 특징 벡터 f(I_i)로 나타냅니다. 즉, image retrival은 데이터베이스에 존재하는 이미지인 {I_i}에서 f(I_i)와 f(q)가 가장 유사한 이미지를 찾는 것입니다.
기존에는 image의 특징 기술자로 SIFT와 같은 hand-engineered 방식을 사용했던 반면, 저자들이 제안하는 NetVLAD는 CNN과 함께 end-to-end로 학습 가능하다는 특징이 있습니다.
Deep architecture for place recognition
Image retrieval에서는 translation과 occlusion에 대한 강인성을 확보하기 위해 두 가지 과정을 거치는데요, 먼저 d이미지에서 local discriptor를 추출한 뒤 순서에 상관없이 pooling을 진행합니다. 여기에 추가로 scale 불변성을 확보하기 위해 여러 scale에서 local discriptor를 추출합니다.
저자들은 end-to-end 학습을 위해 표준적인 image retrieval pipeline을 CNN으로 설계하였습니다. CNN에서 FC레이어를 잘라낸 후 convolution에서 생성된 feature map을 dense descriptor로써 사용하고, 추출된 descriptor를 fixed image representation으로 pooling하고 back propagation를 통해 파라미터를 학습할 수 있는 새로운 레이어를 설계하였습니다. 이때, 새롭게 제안된 pooling 레이어가 NetVLAD입니다.
NetVLAD: A generalized VLAD layer
NetVLAD를 이해하기 위해서는 먼저 VLAD를 알아야 하는데요, VLAD는 널리 사용되는 descriptor pooling 방법론으로 이미지에서 추출한 descriptor들을 하나의 벡터로 표현하는 방법론입니다. VLAD를 간단히 설명하자면, image에서 descriptor를 추출하고, 이를 clustering합니다. 그 이후에 각 descriptor와 해당 descriptor가 속한 cluster의 중심점과의 차이(residual)를 합산하여 벡터값을 도촐합니다.
N개의 D차원 descriptor {x_i}를 입력으로 하고, K개의 cluster center {c_k}가 VLAD의 파라미터로 주어지면, 출력되는 VLAD 벡터 V는 K\times D차원을 가지게 됩니다. 이를 수식으로 나타내면 [식 1]과 같습니다.
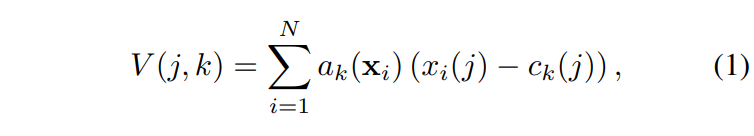
[식 1]에서 x_i(j)와 c_k(j)는 각각 i번째 descriptor와 k번째 cluster center의 j번째 차원을 의미합니다. a_k(?_i)는 descriptor ?_i와 k번째 visual word와의 관계를 나타내며, ?_k가 ?_i에 가장 가까운 cluster이면 1이고 그렇지 않으면 0이 됩니다.
여기서 저자들의 목표를 다시 한 번 언급하자면, Place Recognition을 Image retrieval 방식으로 접근하고, image retrieval pipeline을 CNN framework에서 E2E로 학습하는 것입니다. 그러나 VLAD는 a_k(x_i)에서 불연속성이 발생하여 미분이 불가능하기 때문에, a_k(x_i)를 [식2]와 같이 변경하였습니다.
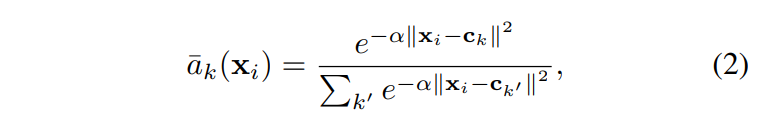
[식 2]는 cluster ?_k에 대한 descriptor ?_i의 가중치를 여러 클러스터 중심과의 근접성을 기준으로 할당하며, 0에서 1 사이의 값을 할당하되, 가장 가까운 클러스터 중심에 가장 높은 가중치가 할당됩니다. \alpha는 거리의 magnitude에 따라 응답의 decay를 제어하는 파라미터입니다. \alpha값이 증가할 수록 가장 가까운 클러스터에 대한 \bar a_k(?_i)가 1이고 그렇지 않은 경우 0이므로 원래 VLAD의 a_k와 같은 역할을 수행하도록 합니다.
[식 2]의 제곱을 확장하면 분자와 분모 사이에서 e항이 상쇄되어 [식 3]과 같이 softmax 식으로 변형되어, a_k가 0~1사이의 확률값을 나타내며, 이로 인해 soft-assignment가 발생하는 것을 알 수 있습니다.
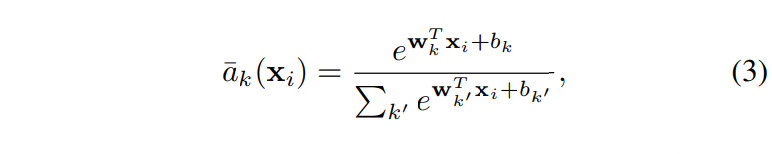
위의 식1에 식 3을 연결한 NetVLAD 레이어의 최종 형태는 [식 4]와 같습니다.
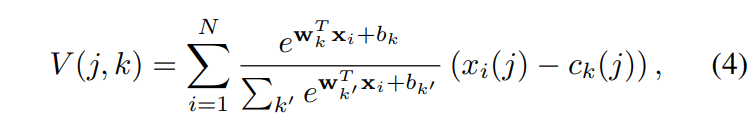
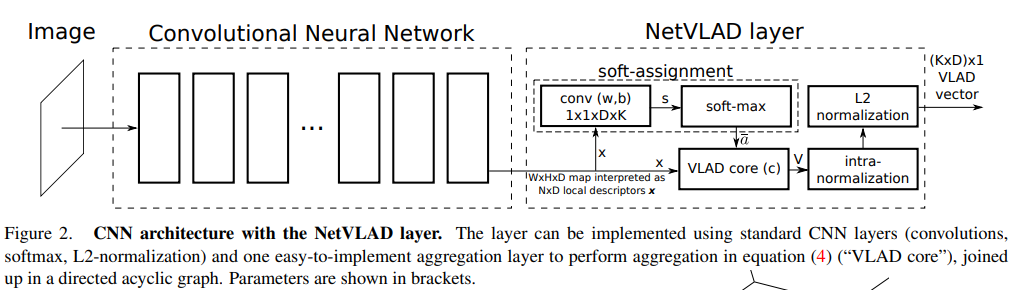
위에서 설명된 NetVLAD가 포함된 CNN architecture는 [그림2]와 같이 나타낼 수 있습니다. soft-assignment가 conv와 softmax 두 레이어로 표현된 것을 확인할 수 있습니다. Convolution을 통해 추출된 descriptor x가 NetVLAD레이어에 들어가게 되면, s_k( ?_i ) = ?^T_k?_i + b_k를 계산하고, 이를 softmax에 태우면 [식 4]동일한 형태의 계산을 진행하여 \bar a를 구할 수 있습니다.
Learning from Time Machine data
앞에서 NetVLAD라는 새로운 CNN Architecture를 설계하였다면, 이를 어떻게 end-to-end로 학습하는지 알아보겠습니다. 저자들은 NetVLAD의 학습에 있어 두 가지의 challenge가 있음을 언급하였습니다. 바로 (1)충분한 annotated data의 확보와 (2)place recognition task에 적합한 loss를 정의하는 것입니다.
Weak supervision from the Time Machine
충분한 양의 annotated data를 확보하기 위해 저자들은 Google Street View Time Machine의 이미지를 사용하였습니다. Google Street View Time Machine은 지도의 가까운 공간 위치에서 서로 다른 시간에 촬영한 여러 거리 수준의 파노라마 이미지로, place recognition을 위한 representation을 학습하기 적절한 이미지들로 구성되어 있습니다. [그림 4]에서 볼 수 있듯, 동일한 장소가 시간, 계절에 따라 달라진 모습을 담고 있어 place recognition 알고리즘이 어떤 요소에 강인하게 작용해야 하는 지를 알아내는데 유용하게 사용될 수 있습니다.

그러나 이 데이터셋은 annotation에 노이즈가 많이 포함되어 있다는 단점이 있습니다. 각 이미지에는 GPS정보가 포함되어 있어 가까운 거리를 파악하는 데는 사용할 수 있지만, 어떤 방향의 이미지를 촬영한 것인지는 별다른 정보가 제공되지 않아 GPS상으로는 동일한 이미지가 서로 다른 방향을 향하고 있는 경우가 발생합니다. 따라서 저자들은 training query q에서 GPS정보를 사용할 때 query와 지리적으로 가까운 이미지인 potential positive {p^q_i}와 지리적으로 먼 이미지인 definite negative {p^q_i}를 판단하기 위해서만 사용하였습니다.
Weakly supervised triplet ranking loss
Place recognition을 optimize할 수 있는 f_{\theta}를 학습한다는 것은 test query 이미지 q에 대해 q와 가까운 위치의 데이터베이스 이미지 I_{i*}의 순위를 다른 이미지들 I_i보다 높게 매기는 것입니다. 이를 수식으로 나타내면 d_\theta (q,I_{i*})<d_{\theta} (q,I_i)로 나타낼 수 있는데, 이는 q와 가까운 위치의 이미지 I_{i*} 사이의 euclidean distance d_{\theta}(q,I)가 q로부터 일정 거리 이상 떨어진 모든 이미지 I_i 사이의 거리보다 작은 것을 의미합니다.
앞서 언급한 바와 같이 Google Street View Time Machine data에서는 (q, {p^q_i}, {n^q_j})와 같은 형대의 train dataset을 얻을 수 있는데, potential positive set {p^q_i}에는 query와 일치하는 positive 이미지가 하나 이상 포함되어 있지만 그 이미지가 어떤 이미지인지는 알 수 없습니다.
저자들은 이러한 ambiguity 해결하기 위해 각 training tuple(q, {p^q_i}, {n^q_j})의 {p^q_i}에서 q와 가장 가까운 potential positive 이미지를 나타내는 p^q_{i*}를 [식 5]와 같이 나타내었습니다.
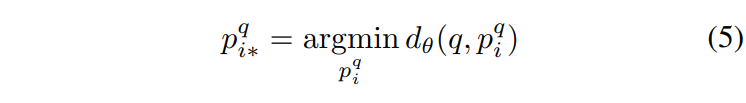
그런 다음 [식 6]같이 q와 p^q_{i*} 사이의 거리 d_{\theta}(q,p^q_{i*})가 q와 모든 negative image n^q_j 사이의 거리 d_{\theta}(q,n^q_j)보다 작도록 이미지 표현 f_{\theta}를 학습하면 됩니다.
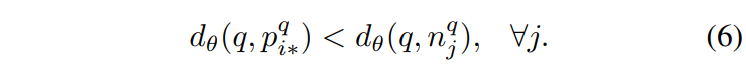
위의 내용을 바탕으로 저자들은 weakly supervised ranking loss L_{\theta}를 [식 7]과 같이 정의하였습니다.
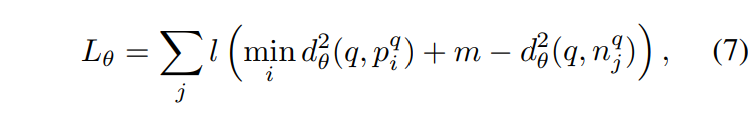
여기서 l은 l(x) = max(x, 0)이고 m은 margin을 나타내는 상수값을 의미합니다.
[식 7]을 살펴보면 각 negative에 대해 q와 negative 사이의 거리가 q와 positive사이의 거리 + margin보다 크면 l값은 0입니다. 반대로 q와 negative사이의 거리가 더 작다면 l 값은 양수값을 갖게 됩니다. 이를 통해 positive 이미지와 q사이의 거리가 다른 모든 negative보다 작아지는 방향으로 학습이 진행됩니다.
Experiments
실험에는 Pittsburgh, Tokyo 24/7 데이터셋을 사용하였으며, evaluation metric으로는 Recall을 사용하였습니다.
네트워크의 convolution레이어에는 사전 학습된 AlexNet, VGG26, Places205를 사용하였으며, pooling레이어에는 Max pooling, VLAD로 비교군을 설정하였다고 합니다.

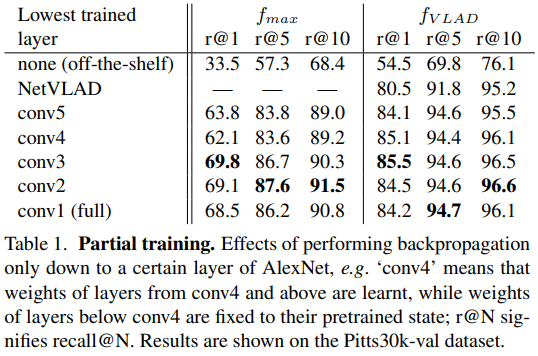
[표 1]은 Network의 layer를 부분적으로 학습했을 때의 결과를 비교한 것으로 각각 recall이 1, 5, 10일 때의 결과를 리포팅하였습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
본문에서 ‘a_k가 0~1사이의 확률값을 나타내며, 이로 인해 soft-assignment가 발생하는 것을 알 수 있습니다.’라고 말씀해주셨는데 여기서 soft-assignment가 정확히 어떤 것인지 알 수 있을까요 ? ?
또한 실험 파트 Table1에 r@1, r@5, r@10라고 표기되어 있는 성능 지표가 다소 생소하여 .. 어떻게 정의되어 평가되는 것인지 보충 설명해주시면 감사하겠습니다.
마지막으로 weakly supervised triplet ranking loss 파트에서 margin이라는 상수값 m이 사용되는 이유가 무엇인가요 ? ? positive 이미지와 q 사이의 거리가 다른 negative 보다 작아지는 방향으로 학습이 진행되기 위해서라면 q와 negative 사이의 거리와 q와 positive 사이의 거리를 비교하는 것으로 충분하지 않을까 생각이 드는데 여기서 +margin이 된 거리와의 비교를 하는 이유가 궁금합니다 !
댓글 감사합니다.
soft-assignment란 본문에 언급된 그대로 softmax를 통해 0~1사이의 확률값으로 나타내는 것을 의미합니다. VLAD는 cluster k와 x의 관계에 따라 a_k값이 0 또는 1로 할당되는데 이를 hard-assignment라고 하며, NetVLAD의 경우 이와 대조적으로 0~1사이의 값을 할당하며 이를 논문에서는 soft-assignment라고 합니다.
image retrieval task에서 자주 사용되는 평가 지표로 recall값을 의미하는데요, recall@N은 N장의 이미지를 찾았을 때 n장의 이미지 중 True인 이미지의 비율을 의미합니다. 이 논문에서는 query의 gt position과 25m 이내의 이미지를 correctly localized된 이미지라고 하였습니다.
margin의 사용 이유는 논문에서 직접적으로 언급된 바는 없습니다. 그러나 저자들이 loss를 설계할 때 triplet loss를 기반으로 설계하였기 때문에 이를 기반으로 설명드리자면 negative를 anchor에서 멀어지도록 학습할 때 margin을 더해 보다 negative를 더 멀어지는 방향으로 학습시키기 위해서라고 생각합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
본문인 NetVLAD와는 조금 거리가 있는 질문일 수 있지만 , ,
image retrieval 과정 중, image에서 local descriptor를 추출한 뒤 순서에 상관없이 pooling을 진행하는 것이 translation과 occlusion에 대한 강인성을 확보하는 것이라고 하셨는데,, 잘 와닿지 않습니다. 추가 설명을 부탁드려도 괜찮을까요 ?
감사합니다 ! !
이미지에서 discriptor를 추출한 다음 pooling을 통해 하나의 벡터로 만들게 되면 이 벡터는 이미지를 대표하는 벡터를 나타내게 되는데요, 이때 discriptor의 순서가 pooling 결과값에 영향을 주게 된다면 같은 이미지에서 translation, occlusion등 일부 변화가 발생했을 때 pooling 결과값이 매우 크게 차이날 수 있습니다. 예를 들어 이미지 A와 A에 translation+occlusion이 적용된 A’, 다른 구역의 이미지 B가 있을 때, A와 A’가 A와 B보다 비슷한 결과를 내도록 하는 것이라고 이해하였습니다.
안녕하세요, 좋은 리뷰 감사합니다.
‘VLAD는 a_k(x_i)에서 불연속성이 발생하여 미분이 불가능하기 때문에, a_k(x_i)를 [식2]와 같이 변경하였습니다.’ 라고 설명을 해주셨는데 식(1)에 대해 식(2)로 개선한 것으로 이해하고 있습니다. 2가지 질문이 있습니다.
1. 식(1)의 a_k(x_i)를 식(2)로 approximation을 시킨건가요?
2. 식(1)의 a_k(x_i)이 불연속성이 이 어느 부분에서 존재한다 거나, 식에 대한 그래프 개형이 어떻게 생겼는지에 대해서 궁금합니다.
감사합니다.
넵 맞습니다. 식(1)의 a_k는 논문에서 다음과 같이 정의되었습니다.
“a_k(x_i) denotes the membership of the descriptor x_ito k-th visual word, i.e. it is 1 if cluster c_k is the closest cluster to descriptor x_i and 0 otherwise.”
즉, a_k는 0과 1의 값만을 도출하는 binary function으로 불연속함수이며, 이로 인해 미분이 불가능함을 의미합니다.
안녕하세요 좋은 리뷰 감사합니다.
혹시 저자들이 학습을 위해 구축한 데이터셋이 Weak-supervision인 이유가 무엇인가요? 그리고 해당 데이터셋이 Weak-supervision이라면, Fully-supervised 기반으로 학습하는 다른 방법론들이 존재하나요? 그렇다면 그들이 사용하는 데이터셋에는 어떠한 annotation이 추가로 존재하는 것인지도 궁금합니다.
댓글 감사합니다.
실제 촬영한 데이터셋이 아닌 google streetview에서 크롤링한 데이터셋이다보니 제공되는 정보가 image와 GPS정보로 한정되어 있기 때문에 weak-supervision으로 구성하지 않았을까…생각합니다. 다른 VPR 데이터셋은 RGB+GPS와 함께 IMU나 Lidar 정보를 포함하고 있는 것 같습니다만… VPR논문을 처음 읽어본 것이라 관련 연구는 잘 모르겠습니다.
좋은 리뷰 감사합니다.
본 논문의 intro에 따르면 NetVLAD 방식이 조도 및 시간 변화에 따라 달라지는 장소의 모습에도 동일한 장소로 인식할 수 있고, 비슷한 장소도 구별할 수 있을 정도로 풍부한 정보를 담는, compact한 representation을 구하기 위한 방법론이라 합니다. 그렇다면, 실험의 어떤 부분을 통해 이를 확인할 수 있는 지 설명해주실 수 있을까요?? 이러한 주장을 튓받침할만한 실험 결과가 어떤 것인지 궁금합니다.
댓글 감사합니다.
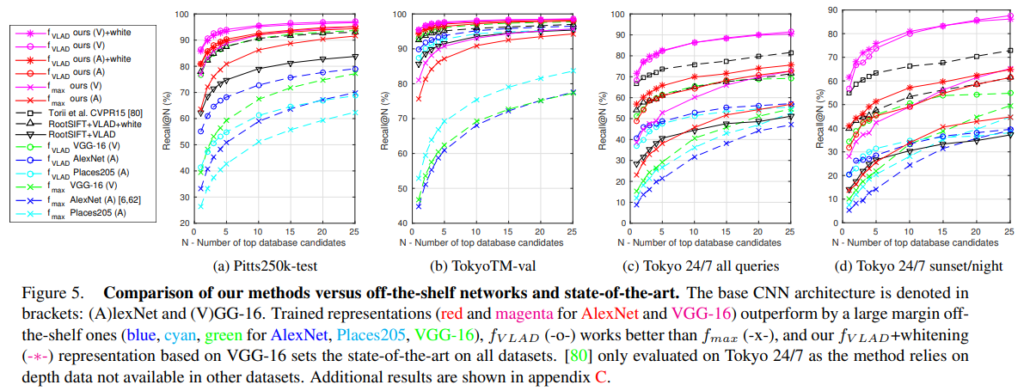
해당 결과는 논문의 NetVLAD방식과 기존의 off-the-shelf CNN 방법론들과의 차이에서 확인할 수 있습니다. [그림 5]의 (a) Pitts250k-test를 보시면 f_VLAD ours(A)가 AlexNet과 NetVLAD를 사용한 성능을 나타내고, f_VLAD AlexNet(A)가 기존 VLAD를 사용한 것을 나타냅니다. 이때 recall@1이 기존 방법론은 55.0%, NetVLAD는 81.0%의 성능을 달성하여 큰 성능 향상을 이룬 것을 확인할 수 있습니다. 또한 (c), (d)는 Tokyo 24/7로 test한 결과를 나타낸 것으로 해당 데이터셋은 낮/밤(+저녁)시간대에 촬영하여 조명 변화를 담고 있는데, (c)의 경우 모든 시간대를 포함한 경우, (d)는 밤 시간대의 recognition성능을 보입니다. 보시면 두 경우 모두 NetVLAD의 성능 향상이 이루어졌으므로 저자들이 주장했던 ‘rich하며 compact한 representation을 추출하는 방법론임을 입증하였다고 생각합니다.