point cloud와 rgb image는 서로 상호보완적인 modality 관계가 될 수 있다. point cloud는 sparse한 특징을 가지지만 object의 정확한 location정보를 포함하고 rgb image는 dense한 color와 texture정보를 가진다. 이러한 두 modality를 fusion하는 기존의 방법론의 경우 두 modality를 각각의 model로 isolate하게 학습하고 간단하게 concatenate하는 방식의 fusion을 활용했다. 이러한 방식은 두 modality가 가지는 potential한 장점을 최대한 활용하지 못한다고 주장한다. 본 논문에서는 좀 더 두 modality를 통합적으로 활용하기 위한 Multi-Modality Task Cascade network(MTC-RCNN)을 제안한다. MTC-RCNN은 3d box proposal을 통해 2d segmentation prediction을 강화하고 이 2d segmentation prediction을 통해 다시 3d box를 refine하게된다. two stage의 3D module 사이에 2d network를 추가함으로써 3d task의 성능을 향상시킬 수 있었다고 한다. 또 3d module이 2d prediction에 overfitting되지 않게 하기위해 dual-head 2d segmentation을 제안하여 두 번째 3d module이 imperfect한 2d segmentation prediction을 학습하도록 했다. SUN RGB-D dataset에서 평가하여 좋은 결과를 얻을 수 있었다. rgb와 point cloud를 fusion하는 방법론으로 현재 baseline으로 잡고있는 tr3d 논문에 함께 reporting되어있어 읽어보았다.
Introduction
3d detection은 3차원 공간에서 object의 정확한 localization을 하는 것을 목표로 한다. 하지만 point cloud는 sparse하고 noise가 많다는 단점이 존재하기 때문에 거리가 멀거나 occlusion이 있거나 할 경우 적은 points들만 capture할 수 있게 된다. 반면 rgb image의 경우 point cloud보다 high resolution을 가지고 픽셀 단위로 dense한 color와 texture 정보를 포함하고 있다. 3d point cloud에서 적은 points들로 표현되는 object가 2d rgb image에서는 많은 pixel을 차지하여 더 풍부한 semantic feature를 추출할 수도 있을 것이다. 또 3d point cloud에서 추출한 3d structual 정보를 포함하는 feature는 depth information을 통해 rgb image의 정보를 보완할 수 있을 것이다. 따라서 3d point cloud와 2d rgb image는 서로 상호보완적인 modality관계를 가짐을 이해할 수 있다.
최근에는 rgb image와 point cloud를 fusion하는 방법론들이 많이 나오고 있다. 어떤 방법론은 pre-trained된 2d detector를 통해 region proposal을 하고 어떤 방법론은 2d features를 통해 point features를 강화하고자 한다. 또 2d network에서 얻은 semantic 정보를 fusion하거나 2d network의 모든 layer에서 feature fusion하는 경우도 있다. 하지만 기존 fusion 방법론들은 두 modality의 관계의 beneficial한 정보 중 절반정도만 활용한다. 이런 방식은 3d task에 도움이 되는 2d semantic정보만 추출하고, 더 나은 2d 정보를 추출하기 위해 3d semantic정보를 사용하는 것을 고려하지 않는다. 저자는 2d image network에 3d task prediction을 추가하여 결과적으로 개선된 2d semantic정보가 3d task prediction에 도움이 될 수 있다고 주장한다.
본 논문에서는 image와 point cloud 관계의 존재하는 상호보완적인 특징을 최대한 활용하기 위한 Multi-modality Task Cascade network for 3d object detection(MTC-RCNN)을 제안한다. 아래 Figure 1에 보이는 것처럼 key idea는 2d segmentation network를 첫 번째와 두 번째 3d detection network사이에 포함시켜 3d detection module의 성능을 향상시키고자 하였다.
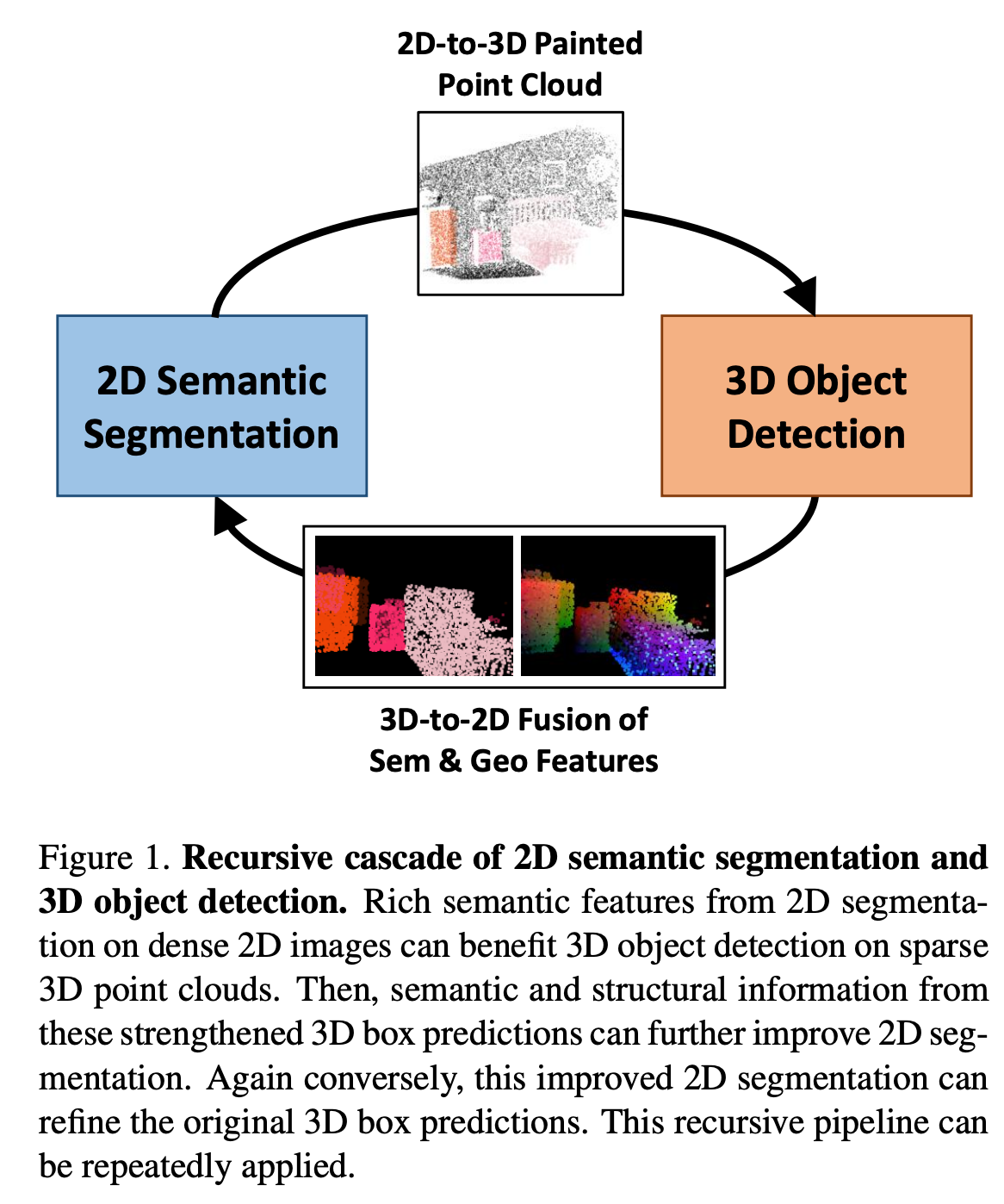
결과적으로 3d features를 2d network에서 fusion하는 것이 2d segmentation 성능과 3d box의 quality를 모두 향상시키는 효과가 있었다고 한다. 추가로 3d box annotation으로부터 2d network의 gt를 생성하기 때문에 추가적인 labeling이 필요하지 않다.
이렇게 2d segmentation predictions를 얻은 후, second stage 3d network(LiDAR-RCNN)를 통해 3d proposal box를 refine하게 된다. 각 3d proposal box마다 내부 points들은 2d segmentation prediction으로 projection되고 상응하는 channel-wise probability distribution은 3d box의 geometry features와 함께 추가(concat)된다. PointNet을 통해 point feature를 processing하여 3d proposal을 refine하게 된다.
또 저자는 2d network가 3d network에 비해 더 빠르게 overfitting되어 완벽한 segmentation으로 빠르게 수렴하는 경향이 있다는 것을 확인했다고 한다. 이를 완화하기 위해 training 시 더 약한 auxiliary head의 segmentation prediction을 fusion하여 두 번째 stage의 3d network가 불완전한 2d segmentation prediction을 해석하는 방법을 배울 수 있도록 제안하였다. test 시에는 auxiliary head와 main head인 DeepLabV3+ head를 함께 사용한다.
그리고 첫 번째 3d detector 전에 2d segmentation network를 추가함으로써 3d detection task에서 더 좋은 결과를 보일 수 있고 나중에 3d box를 refine하기 위한 2d segmentation prediction에서도 더 나은 proposal을 생성할 수 있다.
본 논문의 contribution은 아래와 같다.
1. 제안하는 fusion network는 rgb image와 point cloud 두 modality간 존재하는 benefical한 장점을 최대한 활용하고자 함
2. multi-modal training의 어려움에 대해 조사하고 새로운 training 방식 제안
3. SUN RGB-D 3d object detection에서 sota 달성
Related Work
irregular하고 sparse한 특징을 가지는 point cloud를 CNN을 통해 처리하는 기존의 방법들이 존재한다. VoxelNet은 3d 공간에서 일정한 grid를 가지는 voxel(volume+pixel)형태로 변환하여 3D CNN을 적용하여 feature를 추출하였다. PointNet, PointNet++의 경우에는 raw point cloud를 direct하게 입력으로 사용하였다. 최근에는 voxel-based 방식과 point-based 방식의 장점을 모두 활용하고자 두 가지 방법을 모두 사용하는 방법론들도 있다. 위의 방법론들은 RGB image를 사용하지 않았는데 본 논문에서는 geometry정보만 활용하는 모델들의 성능을 향상시키기 위해 2d image와 3d point cloud를 fusion하는 방식을 적용하였다.
초반의 rgb와 point cloud fusion method의 경우에는 2d-driven한 방법이었는데, 잘 학습된 2d detector를 사용하여 3d space를 한정하고 3d box를 찾는 방식이었다. 이 방식은 2d detector에 많이 의존하는 방식이었고 이후에 image semantic정보를 통해 3d feature를 향상시키는 방법을 사용하였다. 이 방법은 다시 여러 개의 중간단 layer에서 fusion하는지, 2d model 마지막에 fusion하는지, 2d task-level에서 fusion하는지로 나눌 수 있는데 본 논문에서 제안하는 방법은 2d task-level prediction에 가깝다고 할 수 있다. 다시만 기존의 방법론과는 다른 점이 존재하는데, 먼저 기존에는 2d model을 freeze하고 3d detector를 학습하지만 본 논문에서는 end-to-end로 학습한다. 또 2d task prediction결과를 향상시키기 위해 2d network가 3d proposal도 input으로 사용하게된다.
Method
본 논문에서 제안하는 전체적인 MTC-RCNN의 architecture는 아래 figure 2와 같다. 큰 과정으로 표현하자면 (2D)->3D->2D->3D로 표현할 수 있다. 맨 앞 2D의 round bracket이 붙은 이유는 마지막에 추가로 수행했기 때문이다.
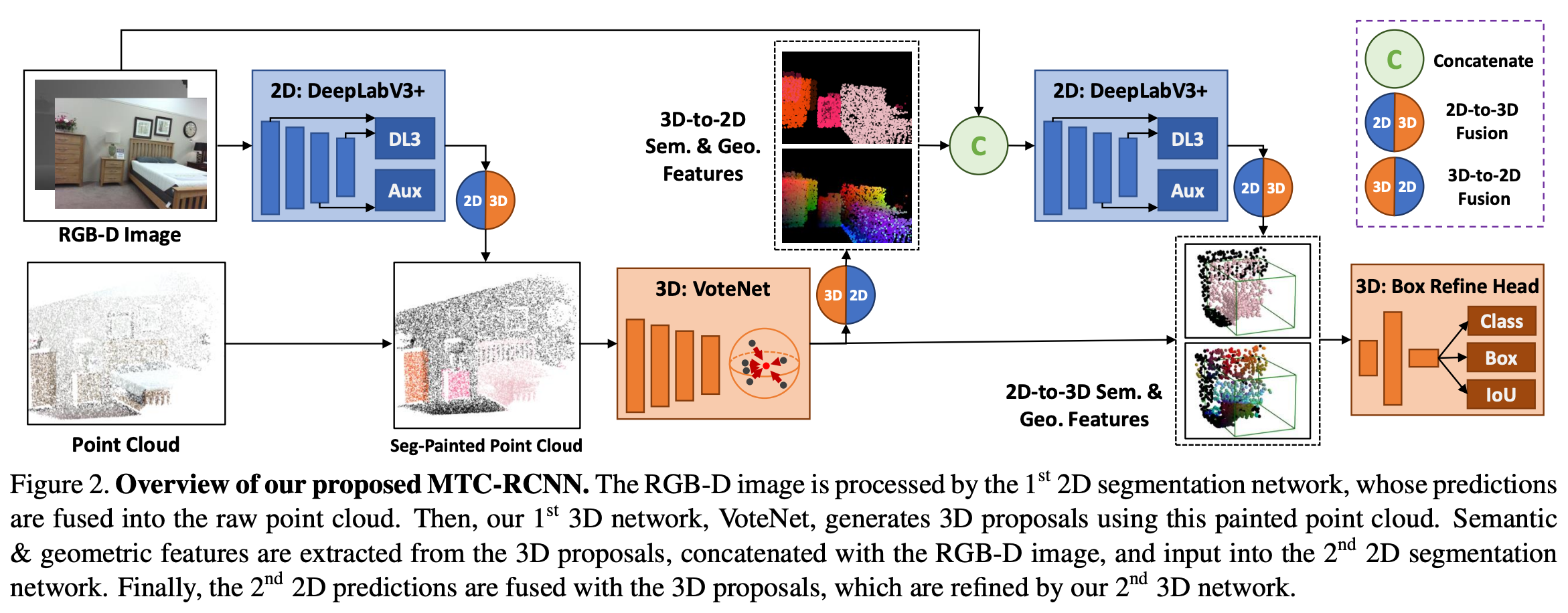
3D Proposal Generation : Deep Hough Voting(VoteNet)
본 논문에서는 3d porposal을 생성하기 위해 VoteNet을 사용했다. Figure 2의 아래 가운데 부분에 해당한다. VoteNet은 backbone으로 pointnet++을 사용하며 input point를 로부터 feature를 추출한다. 이렇게 추출된 point features는 voting을 통해 object center에 가까운 3d location을 찾게된다. 이 votes들은 위치를 기반으로 clustering되어 각 cluster마다 3d bounding box와 classification score를 예측하게 된다. VoteNet에 대해 더 자세한 내용은 기존 리뷰를 참고하면 도움이 될 것 같다.
이렇게 얻은 3d proposals는 다음 stage로 넘어가게된다.
3D-to-2D: Using 3D Proposals for 2D Semantic Segmentation
3d task를 통해 얻은 information을 가지고 2d segmentation task에서 활용하기 위해, 3d proposal로부터 geometric feature와 point-level semantic feature를 추출하여 2d semantic segmentation network의 입력으로 함께 사용하게 된다. semantic feature는 각 point/pixel이 어떤 class에 포함되는지를 알려주고 geometric feature는 object의 3d 구조에 대한 정보를 제공한다. 3D box proposal이 주어졌을 때, 먼저 box 내부 points 집합 {pi}i=1 n 에 대해 random하게 sampling한다. pi는 3d coordinate를 나타낸다(pi ∈ R3). 각 point pi마다 3d proposal에서 object class probability 분포를 통해 semantic feature si ∈ RC를 얻게 되는데 C는 class 수를 나타낸다. 그리고 geometric feature를 얻기 위해 각 points들을 proposal center에 중심을 두고 proposal의 heading 방향과 align을 맞춘 box의 canonical coordinate(정준 좌표)로 변환한다. canonical coordinate는 정확히 어떤 좌표계인지 모르겠지만, 위에 두 조건을 만족시키는 좌표계로 변환시킨다고 이해하면 될 것 같다. geometric feature gi ∈ R9 는 point의 canonical coordinate와 box의 6개 면에 대한 point offset의 두 부분으로 구성된다(3+6). 각 box마다 box 내 sampling된 points의 semantic, geometric features는 아래 수식(1)과 같다.
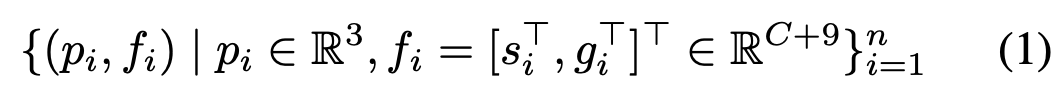
이 points들은 camera parameter를 통해 2d image로 projection되며, 상응하는 feature는 projection된 2d location에 할당된다. 그리고 HxWX(C+9)크기를 가지는 3D-to-2D feature map F3D-to-2D을 생성하게 되고 최종적으로 F3D-to-2D는 RGB-D image와 channel-wise로 concat되어 HxWx(C+13) 크기를 가지는 feature map F2D-input이 2d segmentation network의 input으로 사용된다.
2d network로는 lightweight ResNet18을 backbone으로 하는 DeepLabV3+라는 모델을 사용한다. backbone의 마지막 두 subsampling stage(C4, C5)를 제거하고 dilated convolution으로 대체하였다. DeepLabV3+ architecture는 auxiliary head가 C4에 존재하는데 이 head가 중요한 역할을 한다고 한다. 본 논문에서는 학습 시 main head대신 이 auxiliary head를 2d-to-3d fusion에 사용했는데 이유에 대해 미리 간단히 설명하면 training과 test 시 2d performance gap이 더 적었다고 한다.
2d segmentation gt의 경우 2d depth map을 3d point cloud로 확장하여 3d box 내 point들에 대해 해당 box의 class label을 부여했다고 한다.
2D-to-3D: Using 22D Segmentation for 3D Proposal Refinement
첫 번째 stage의 3d network로부터 3d proposal box들을 구했다. 이 proposals들을 refine하기 위해 두 번째 stage에서 LiDAR-RCNN으로 3d refinement를 수행한다. 더 많은 context정보를 얻기 위해 proposal box를 확대하고 이 확대된 box안에서 point sampling을 하고 바로 위에 3d-to-2d에서처럼 각 point의 geometric feature를 추출하게 된다. 그럼 위에서와 마찬가지로 각 점에 대해 9차원(3+6)의 feature vector를 얻게된다. 본 논문의 아래 실험에서 2d segmentation refinement를 하지않은 3d-3d 방법이 있는데, 이 경우에는 PointNet을 통해서 각 proposal에서 geometric point feature를 추출하게 된다.
2D-to-3D fusion을 위해 저자는 3d box를 refinement하기 위해 2d network에서 2d segmentation prediction을 사용하여 더 많은 semantic feature 정보를 포함하려고 했다. 위의 문단에서 설명한 두 번째 stage의 3d framework를 확장해서, 각 proposal에 대해 sampling된 points들을 camera parameter를 사용하여 2d segmentation prediction에 projection한다. 2d로 projection한 지점의 channel-wise class 분포가 9차원 geometric feature에 추가되어 각 point마다 9+C(class)차원의 feature를 가지게 된다. 이 feature가 앞에서 말한 pointnet을 통해 전달되는 것이다.
training 시 auxiliary head의 2d prediction 결과를 fusion한다. 위에서 학습 시 main head대신 auxiliary head를 fusion에 사용했다고 하고 간단히 언급했는데, training과 test 사이에 2d 성능 gap이 auxiliary head에서 더 작았기 때문이라고 했다. 만약 학습 시 main head를 fusion하게 되면 proposal 주변 point의 segmentation이 너무 잘 되어서 refinement를 하는 것의 영향이 적다고 한다. 따라서 학습 시 auxiliary head를 fusion하고 test시에는 두 head를 모두 사용하여 model이 불완전한 2d predictioin에 적응되어 학습되도록 한다.
Early 2D-to3D Fusion: PointPainting
지금까지 흐름을 한 번 보자면 처음에 3d proposal 단계, fusion 2d segmentation network, 3d refinement module 순서의 파이프라인을 설명했다. 뭔가 architecture 그림을 보고 처음에 rgbd input을 2d network로 처리하는 내용이 먼저 나오지 않아 당황했는데, 추가적으로 적용한 것이라 뒤에서 설명한 것 같다. 본 논문에서 설명하기로 지금까지 설명한 파이프라인대로 반드시 3d detection으로 시작하는 순서로 할 필요는 없다고 하면서 PointPainting이라는 방법과 마찬가지로 첫 번째 3d proposal을 생성하기 전에 2d segmentation network를 추가할 수 있다고 한다. point cloud가 VoteNet에 입력되기 전에 각 points는 2d segmentation predictions로 projection되고 각 point에 상응하는 2d projection의 probability distribution이 할당되게 된다.
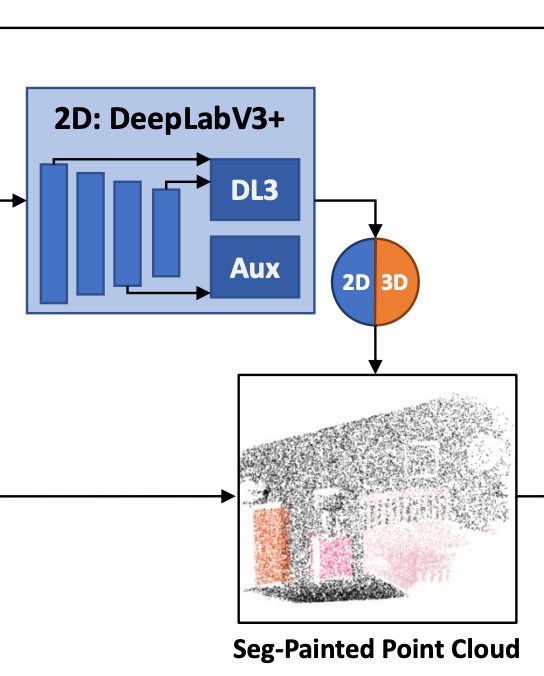
이렇게 painted된 point cloud는 3(x,y,z)+C(class)의 dimension을 가지며 VoteNet의 입력으로 전달된다. 그리고 VoteNet을 통과해 3d proposal을 생성하여 이전 pipeline을 따라가게된다.
이러한 pointpainting가 framework에 효과적인 이유를 3가지로 제시하고 있다. 먼저 초기에 proposal generation을 하면서 직접적으로 그 다음 3d detection의 quality를 높일 수 있다. 그리고 더 좋은 quality의 초기 Proposal을 하면서 뒤에 두 번째 stage에서 3d refinement도 향상시킬 수 있다. 그리고 마지막으로 아래 Figure 3과 같이 전체 pipeline을 재귀적으로 적용할 수 있다고 한다.
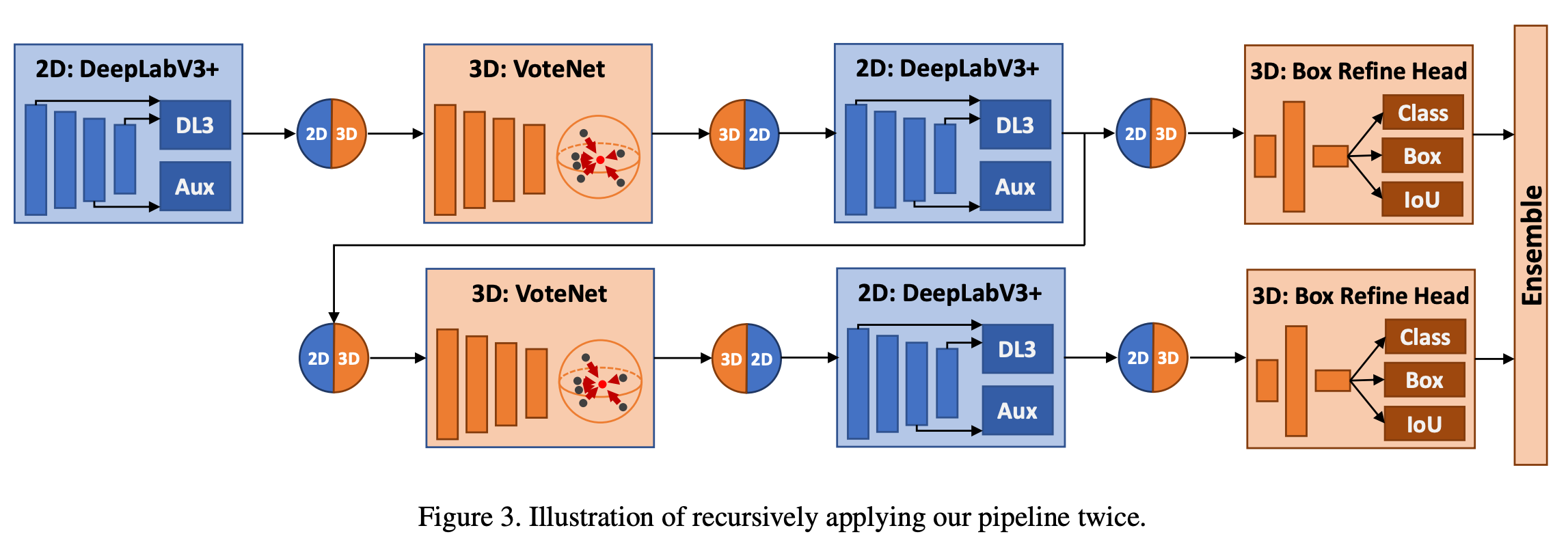
그림을 보면 2d segmentation으로부터 pipeline을 시작해서 3d proposal을 생성하기 위한 단계로 fusion된다. 이렇게 proposal하는 방식을 사용하여 fusion하는 2d network는 3d proposal을 refine하기 위해 더 나은 2d prediction을 할 수 있게된다. 이 과정을 반복하면서 refine된 3d box를 함께 사용할 수 있고 결과적으로 이러한 재귀적인 pipeline방식을 통해 3d box prediction의 성능이 향상된다는 것을 증명했다.
Training Losses
3D proposal generation의 경우 첫 번째 stage의 3d network를 의미하는 것인데 VoteNet의 loss를 그대로 사용하였다.
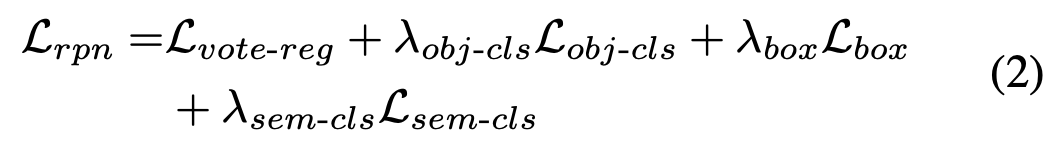
각 loss term은 순서대로 voting loss, objectness classification loss, box estimatin loss, multi-class semantic classification loss를 의미한다. loss 가중치도 votenet과 동일한 값을 사용했다.
2D segmentation segmentation의 경우 위에서 설명했던 것처럼 또 그림에 나타나있는 것처럼 두 개의 head를 가지는데, DeepLabV3+ head와 auxiliary head이다. 2d segmentation loss는 아래와 같고 직관적으로 이해할 수 있다.
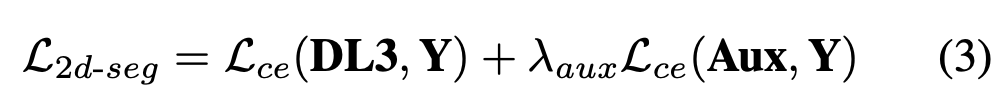
DL3과 Aux는 각각 head에서 segmentation prediction을 의미하고 Y는 2d segmentation map의 gt이다. Lce는 mulit-class cross entropy loss이다.
두 번째 stage의 3D Box refinement의 경우 3d refinement loss가 적용되고 크게 box refinement loss, multi-class semantic classification loss, IoU prediction loss 3가지 part로 나뉘어진다.

그 중 box refinement loss인 Lbox-refine은 아래와 같다.

∆r는 3d proposal box와 해당 box와 matching되는 gt box와의 잔차를 의미하고 위에 hat이 붙은 ∆r^은 이 잔차에 대한 prediction이다.
multi-class semantic classification loss인 Lsem-cls는 proposal의 class예측과 gt box의 class간 multi-class cross entropy loss이고 Liou는 high quality의 bounding box를 예측하기 위한 confidence loss이다.
결과적으로 전체 loss는 아래와 같다.
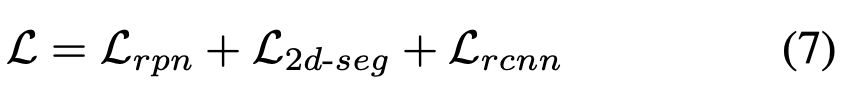
Experiments
데이터셋은 single-view의 indoor dataset인 SUN RGB-D dataset에서 평가를 진행했다. SUN RGB-D는 10,335장의 rgb-d image를 포함하며 5,285장을 training에 나머지 5,050장을 test에 사용하였다. 기존 논문들에서 평가한 방식으로 총 10개의 prevalent한 object class(bed, table, sofa, chair, toilet, desk, dresser, night stand, bookshelf, bathtub)에 대해서 평가를 진행했고 point cloud는 2d depth map에서 camera parameter를 통해 생성했다.
2d segmentation network인 DeepLabV3+ model은 ImageNet에서 pre-trained된 ResNet18 backbone을 사용한 모델로 사용했다. 학습은 총 240epoch동안 했고 각 view마다 20,000개의 point를 sampling했다.
기존 방법론들이 여러 번 train하고 best result를 reporting했는데, fair comparision을 위해 기존과 동일한 evaluation protocol을 따라 5번 학습해서 각 학습마다 5번씩 평가를 진행, 총 25번의 평가 결과 중 가장 좋은 성능과 평균 성능을 reporting하였다. 아래 Table 1이기존 방법론들과 비교 결과를 보여준다.
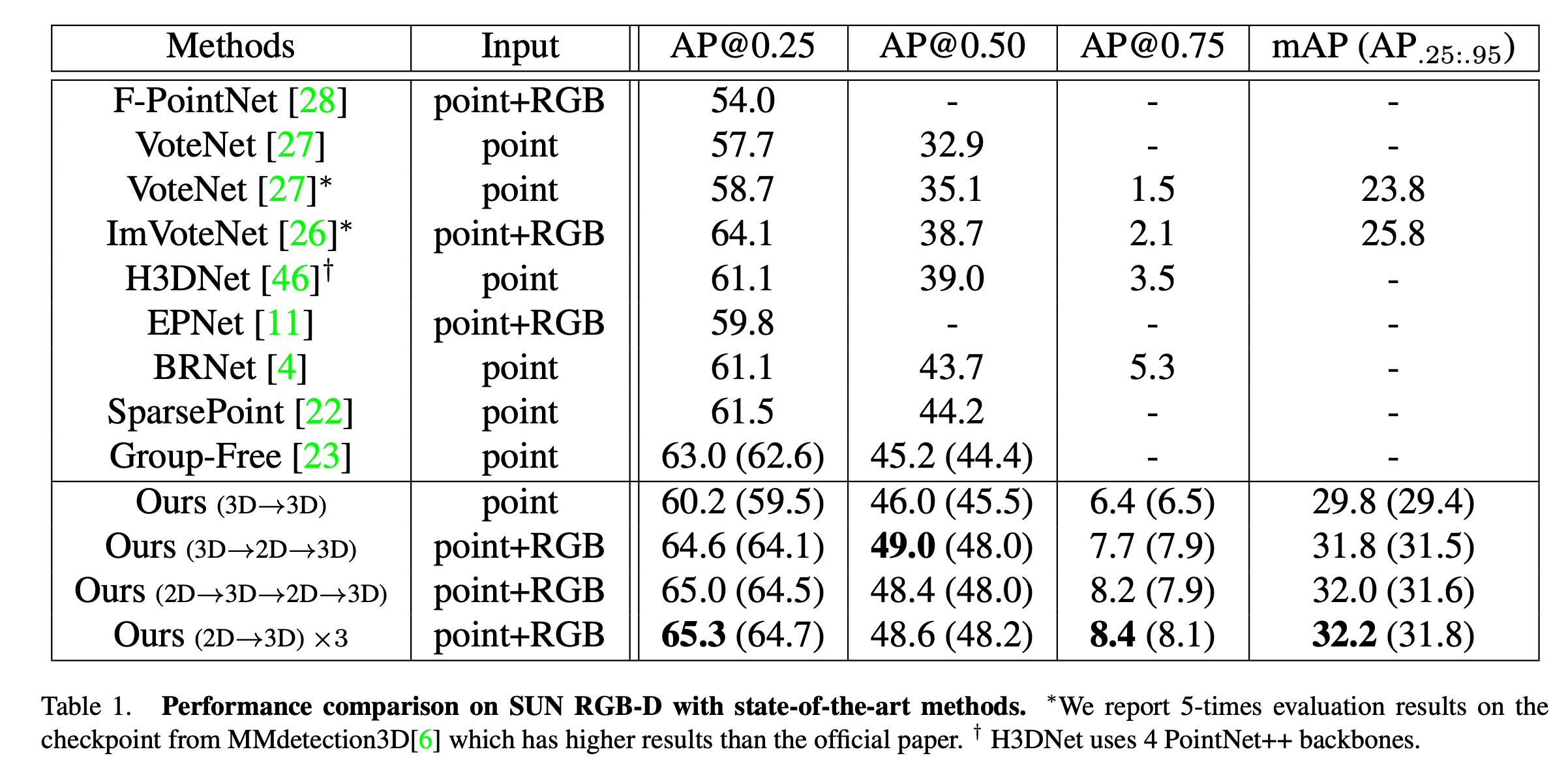
기존 VoteNet에 3d refinement module을 추가한 것을 baseline으로 설정했고 가로선 바로 아래 모델에 해당한다. baseline 모델에 2d segmentation model을 3d module 사이에 추가했을 때 최대 4.4%의 성능 향상을 보이고 다른 기존 방법론들보다 높은 성능을 보였다.
아래 Figure 4는 전체적인 pipeline에서 task마다 결과를 보여준다.
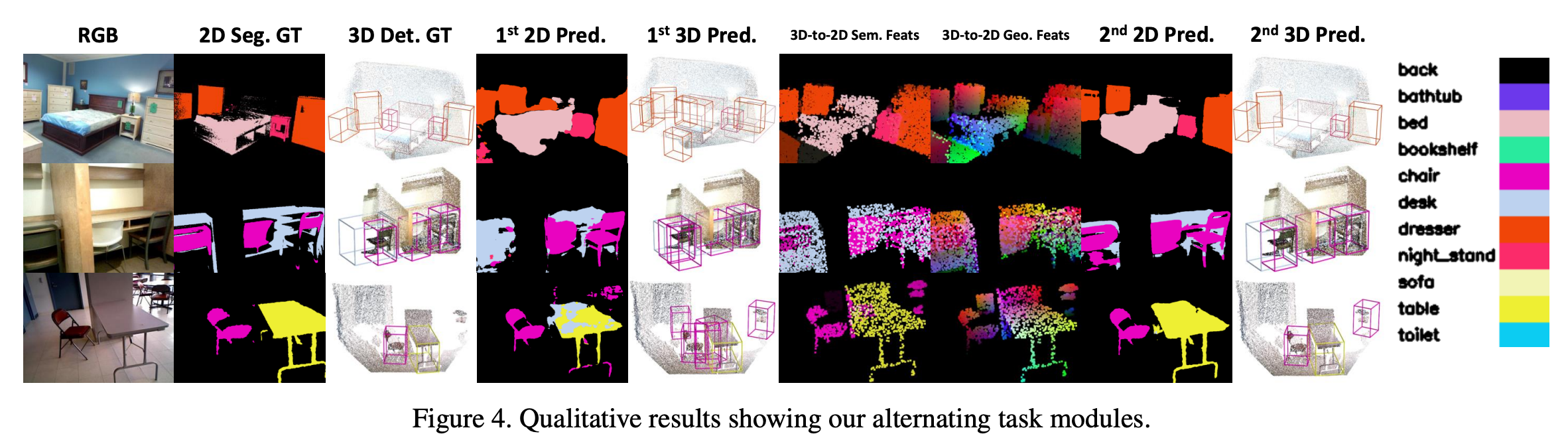
첫 번째 2D Pred에서보면 완벽하지 못하게 예측한 것을 확인할 수 있다. 예를 들어 두 번째 row에서 맨 왼쪽의 의자를 찾지 못하고 그냥 desk로 segmentation 해버렸다. 그리고 3D-to-2D feature를 통해 더 많은 정보를 포함한 후에는 의자를 정확하게 segment한 것을 확인할 수 있다. 이에 따라 MTC-RCNN이 2d image와 3d point cloud간 장점을 효과적으로 활용하여 정확한 검출을 할 수 있었음을 알 수 있다.
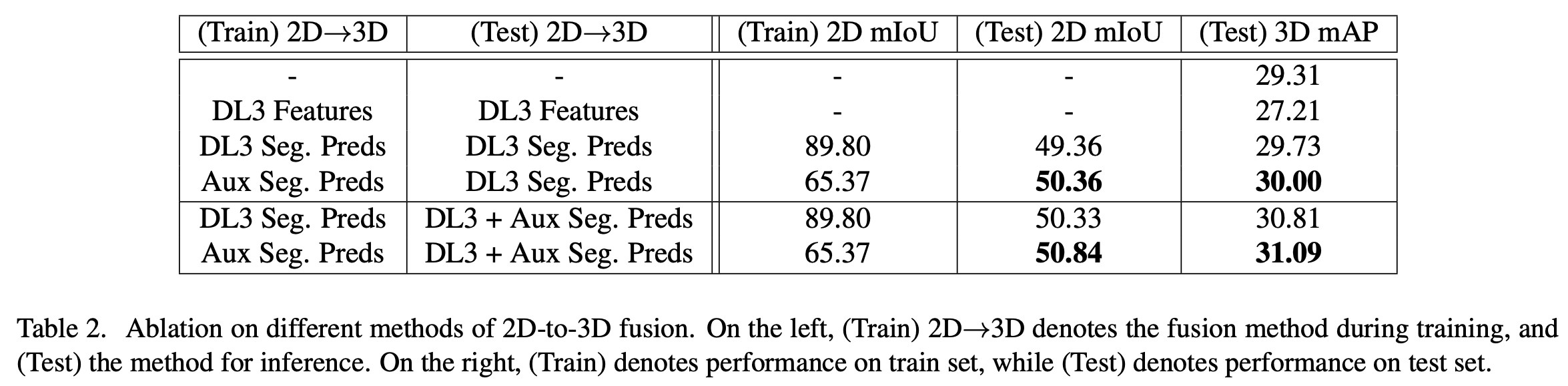
아래는 ablation study이다. Table 2의 경우 2D-to-3D fusion에 대한 ablation study로 DeepLabV3+의 feature를 단순히 concat한 2번째 row 방식은 첫 번째 row의 baseline보다 오히려 낮은 결과를 보인다. 그리고 2d segmentation prediction을 추가하여 fusion한 경우 baseline보다 좋은 성능을 보인다. 하지만 이 경우 train과 test 사이에 mIoU gap(89.8, 49.36)이 큰 것을 알 수 있다. 이렇게 gap이 큰 경우 3d refinement의 성능이 좋지 않기 때문에 아래 4번째 row에서는 auxiliary head의 weak한 prediction을 통해 학습하여 gap을 줄였다(65.37, 50.36). 가로선 아래 두 row는 inference 시 main head와 auxiliary head를 ensembling한 prediction으로 auxiliary head로 학습하는 것이 더 좋은 성능을 보이고 있다.
아래 Table 3은 two stage에 관한 ablation으로 우선 longer training은 기존 votenet의 경우 180epoch동안 학습했는데 240epoch으로 학습했을 떄 더 좋은 성능이 나온 것을 보여주는 것이다. 그리고 두 번째 stage로 3d refinement module을 추가했을 때 24.55에서 29.31로 큰 폭의 성능 향상이 있는 것을 확인할 수 있다.

Table 5에서는 3D-to-2D fusion이 성능이 큰 폭으로 상승하는데 도움을 주었다는 것을 보여준다. 2d segmentation 성능이 향상됨에 따라 이를 활용하는 3d proposal의 성능도 좋아졌다.
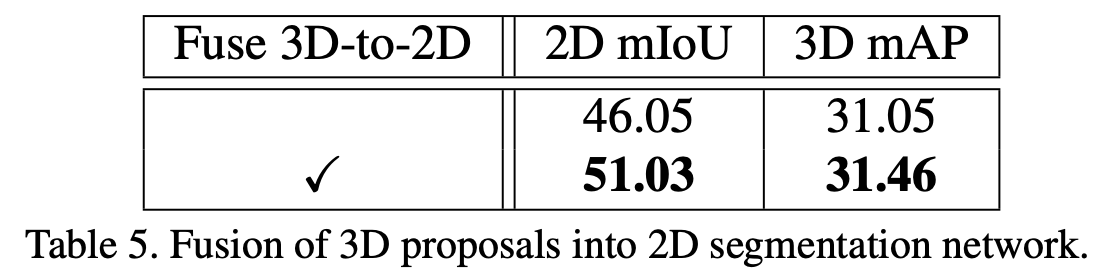
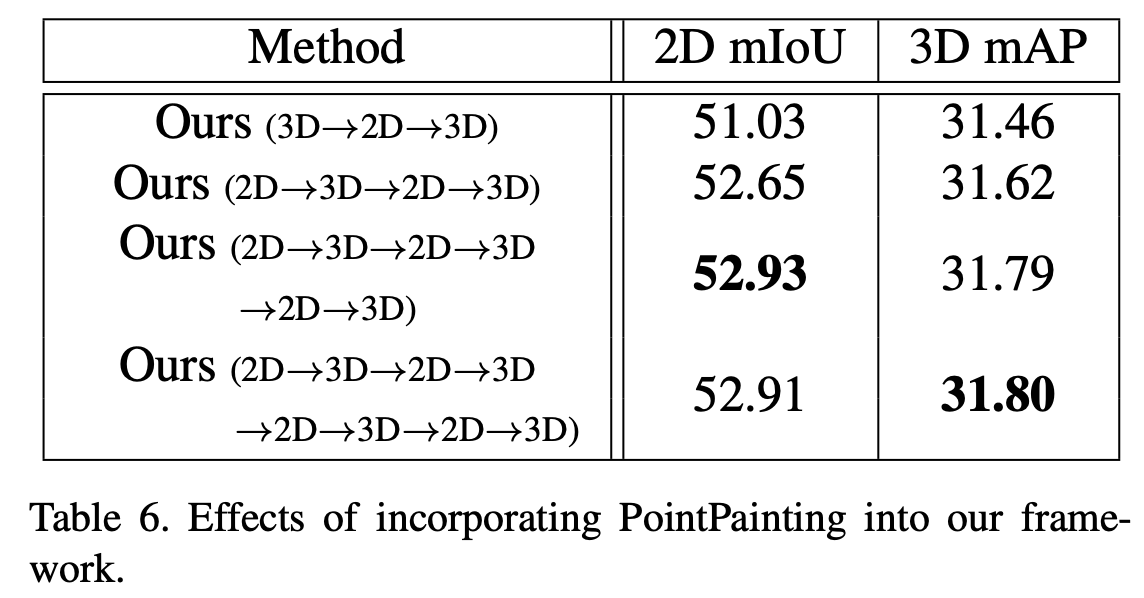
Table 6에서는 2D network를 맨 처음 3D proposal generation을 하기 전에 추가하는 것에 대한 성능이다. 첫 번째 행과 두 번쨰 행을 비교했을 때 의미있는 성능 향상이 일어난 것을 확인할 수 있고, 추가로 재귀적으로 반복했을 때 추가로 성능이 향상되는 것을 알 수 있다.

Conclusion
본 논문에서는 재귀적으로 3d detection과 2d segmentation prediction을 사용하여 각 task를 최대한 활용하는 방법인 MTC-RCNN을 제시하였다. 3d box proposal로부터 semantic, geometric feature를 추출해서 fusion하여 2d segmentation network에 활용하여 더 나은 2d segmentation prediction을 생성하고 이것이 이후 3d proposal을 refine하는데 사용된다. 또 전체 pipeline이 재귀적으로 반복하며 더 좋은 성능을 낼 수 있었다. 해당 모델은 SUN RGBD에서 당시 sota를 달성했다. 하나 아쉬운 점은 inference speed에 대한 reporting이 없다는 것인데 real-time에 적용하기는 어려울 것 같다. 어쨋든 두 Modality의 정보를 mutual하게 도움되도록 사용하기 위해 segmentation과 3d proposal을 재귀적으로 사용했다는 것이 흥미로웠다.
안녕하세요. 좋은 리뷰 감사합니다. 방법론이 재귀할 수 있는 모델이라는 것이 흥미롭고 실제로 재귀할 수록 성능이 올라 흥미로운 논문이었던 것 같습니다. Figure 3를 보면 어떻게 재귀적으로 작동하는지 볼 수 있는데 도경 연구원님 설명으로는 계속해서 refine된 feature를 사용할 수 있기 때문에 재귀적으로 작동하는 것이 좋다고 하셨습니다. 그런데 Figure 3에서는 화살표가 box refine head 전에 화살표가 그려져서 재귀하는데 실제로를 box refine head를 여러번 사용하는 건가요?
댓글 감사합니다.
3d proposal을 하고 2d prediction하는 과정을 반복하며 각 head에서 예측한 결과를 ensemble한다고 합니다. 여러 번 재귀적으로 사용하면 말씀하신대로 여러 head의 결과를 함께 사용할 것이고 Figure 2의 경우 2d->3d->2d->3d의 pipeline을 한 번 반복하여 하나의 head에서 box refinement 결과를 사용하겠네요!
안녕하세요 김도경 연구원님 좋은 리뷰 감사합니다.
baseline모델이 votenet에 3d refinement모델을 추가한 것이라고 설명해 주셨는데, 표1의 3d->3d방법의 경우 PointNet을 추가한 방법, 그리고 아래 2d가 포함된 방법들은 rgbd의 segmentation결과를 추가로 이용하는 방법론이라고 이해하였습니다.
[표6]이 2d,3d를 재귀적으로 반복했을 때의 성능을 리포팅한 것이라고 하셨는데, 이 성능들은 [그림3]과 같이 2d->3d를 수행할 때마다 생성되는 3d box refine head를 ensemble한 결과를 나타내는 건가요?
intro에서 3d box의 annotation으로부터 2d의 network의 gt를 생성한다는 언급이 있어 2d segmentation모델의 gt는 모든 픽셀에 class가 할당되어 있는 것으로 알고 있는데 3d도 point 마다 class가 붙어있는지 혹은 bbox의 3d좌표값을 segmentation gt로 변환하는 과정이 포함되는지 의문이 들었습니다.
마지막으로는 논문 자체와는 조금 거리가 있는 질문일 수도 있지만 [그림6]의 첫 번째와 마지막 그림을 보면 실제 존재하는 object임에도 gt박스가 없는 경우가 있으며 오히려 detect결과가 object를 더 잘 나타내는 것 처럼 보이는데 이러한 경우가 일반적인 경우인지도 궁금합니다.
댓글 감사합니다.
1. 2d->3d를 수행할 때마다 생성되는 3d box refine head를 ensemble한 결과가 맞습니다. Figure 3이 Table 6의 세번째 row에 해당하는 pipeline이겠네요
2. 2d gt 생성의 경우, 우선 2d depth map을 camera parameter를 이용해 3d point cloud로 확장하고 어떤 point가 3d box 내부에 포함될 경우 해당 3d box label을 할당합니다. point가 box내부에 포함되어있지 않다면 background로 labeling했다고 합니다.
3. 저도 해당 그림을 보고 gt보다 더 잘 찾았다고 생각했는데요, 사실 gt의 경우 sparse하여 3d structure가 육안으로도 명확하지 않은 경우는 annotation을 하지 않은 것 같습니다.(제 생각입니다) 하지만 논문에서 rgb의 semantic 정보를 충분히 사용하여 annotation되어있지 않은 object까지 검출한 것으로 보입니다. 최근 다른 논문을 확인해보면 예를들어 fcaf3d같은 경우에도 gt에 없는 물체도 찾은 시각화 자료가 있었습니다.
좋은 리뷰 감사합니다.
마침 제가 읽은 논문도 rgb와 depth의 상호 보완적으로 특징을 추출하기 위한 fusion 방식이라 더 흥미롭게 읽었습니다.
리뷰를 읽으며 2D 이미지에 대한 segmentation을 수행하지는 않는지 궁금했는데, 마지막에 설명이 되네요..ㅎㅎseg-painted point cloud는 결국 class 정보를 주는 것인데, 처음에 설명하신 3D Proposal Generation 과정은 클래스 정보가 포함되 point cloud 정보이지만 VoteNet과 동일한 방식으로 이루어지는 것인가요?? VoteNet의 입력에는 class 정보가 포함되지 않았던 것 같아서 이는 어떻게 처리 되는지 궁금합니다.
댓글 감사합니다.
저도 rgb와 depth를 어떻게 효율적으로 fusion하면 좋을지 고민을 많이 하게 되네요..ㅎ
votenet의 경우 pointnet++을 backbone으로 사용하는데 input point cloud(x,y,z)로부터 pointnet++을 통과시켜 임의의 n개의 seed point를 추출하게 됩니다. 이떄 각 seed는 (x,y,z + C)의 크기를 가지게되고 C는 feature들인데 여기에 class 정보가 포함되지 않을까 싶습니다.