Introduction
본격적으로 리뷰를 시작하기 전에, 해당 논문에서 다루는 task인 object detection에 대해 정리하고 가겠습니다. object detection은 주어진 이미지에서 사전에 정의된 category에 속하는 object를 찾는 것이며, 보다 구체적으로는 object는 bounding box와 그 class를 예측하는 task입니다. 논문에서는 task의 difficulty에 의해 기존의 방법론들은 architecture나 loss function이 상당한 양의 prior knowledge를 바탕으로 설계되었다고 언급합니다.
The Pix2Seq Framework
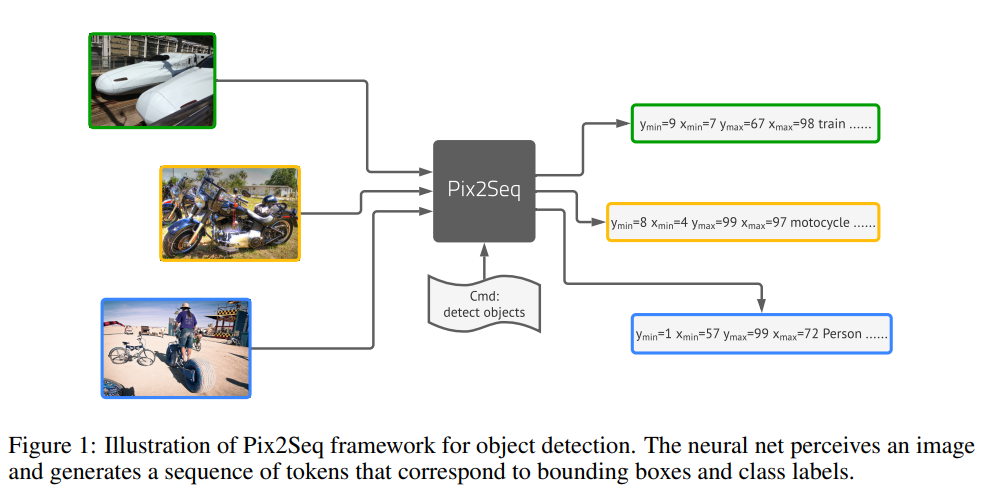
논문에서 제안하는 Pix2Seq의 프레임워크는 object detection을 language modeling task로 해결하는 것으로 [그림1]과 같이 pixel input을 입력했을 때, bbox의 정보를 담고 있는 sequence data들을 생성하는 것입니다.

위 그림은 [그림1]을 보다 직관적으로 표현한 것입니다. pixel data인 image를 input으로 마치 언어 모델이 텍스트를 생성하듯 bbox를 생성하는 모습을 볼 수 있습니다.
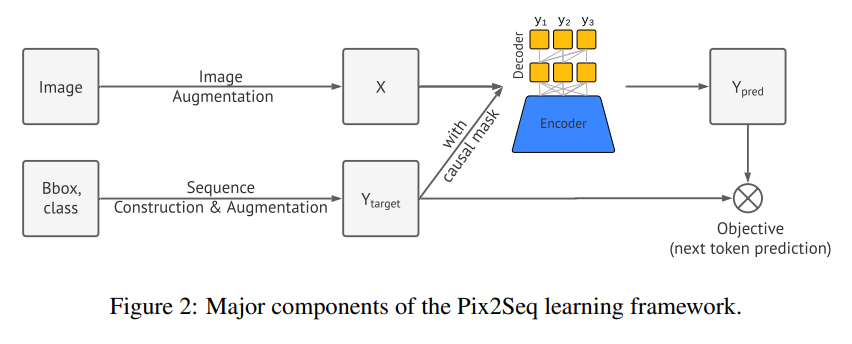
이러한 시스템을 구축하기 위해, 저자들은[그림2]와 같은 architecture를 설계하고, 다음과 같은 네 가지의 요소들을 사용하였습니다.
- Image Augmentation: 비전 task에서 흔히 training example의 증강을 위해 사용되는 기법으로, 이 논문에서는 단순 random scaling, random crop을 의미합니다.
- Sequence construction & augmentation: As object annotations for an image are usually represented as a set of bounding boxes and class labels, we convert them into a sequence of discrete tokens.
- Architecture: We use an encoder-decoder model, where the encoder perceives pixel inputs, and the decoder generates the target sequence (one token at a time).
- Objective/loss function: The model is trained to maximize the log likelihood of tokens conditioned on the image and the preceding tokens (with a softmax cross-entropy loss).
Sequence Construction from Object Descriptors
PascalVOC, COCO, OpenImage같은 여러 object detection 데이터셋에는 당연히 이미지 데이터와 해당 이미지에 대응되는 annotation이 존재합니다. 당연히 이 annotation들에는 bbox의 위치에 관한 정보와 class의 정보가 있으며, Pix2Seq는 이를 discrete token들의 sequence로 표현하였습니다.
class label은 categorical 한 값이므로 자연스럽게 discrete token으로 표현이 가능합니다. 그러나 bounding box는 localization에 의해 도출되는 위치 값이므로 discrete token으로 나타낼 수 없습니다. bounding box는 좌상단과 우하단의 두 코너 점, 혹은 중심점과 박스의 높이,너비로 표현되는데 이를 discrete token화 하기 위해 논문에서는 코너의 x, y 좌표를 구성하는 continuous한 수를 discretize하였습니다. 보다 구체적으로 설명하자면 하나의 object를 5개의 discrete token sequence, 즉, [y_min, x_min, y_max, x_max,c]으로 표현합니다. 이때 continuous number로 이루어진 x와 y는 1과 n_bins 사이의 정수로 quantized 되고 c는 class index를 의미합니다.
좌표값과 클래스 각각을 하나의 단어로써 취급하는 방식을 사용하였으므로, 모델의 vocabulary size는 n_bins + class 수와 같습니다. 저자들은 이러한 방식의 장점으로 적은 수의 단어를 사용하여 높은 precision을 달성할 수 있음을 언급하였습니다. 예를 들어 일반적으로 단어 번역을 위한 언어 모델이 32K 이상의 vocabulary size를 가지는 반면, input image가 600 \times 600인 이미지에서는 n_bins가 600일 때 모든 bbox의 좌표를 오차 없이 표현할 수 있고, 이에 사용되는 단어의 수는 600 + c 만큼만 필요하니 비교적 간단하게 모델링이 가능합니다.
각 object를 short discrete sequence로 표현하였다면, 다음으로는 한 이미지에 존재하는 object들을 serialize하여 단일 sequence를 생성해야 합니다. nlp에서는 단어와 단어, 문장과 문장 사이의 순서가 중요하게 적용됩니다. 그러나 object detection에서 각각의 object에 대한 정보를 sequence데이터로 표현하고 나면, 하나의 이미지에 존재하는 object끼리는 그 순서가 중요하지 않습니다. 따라서 저자들은 단알 sequence로 합칠 때 무작위의 순서로 진행하였습니다. 이외에도 ording의 영향을 알아보기 위해 영역이 넗은 순으로 정렬하는 Area ording, 거리순으로 정렬하는 dist2ori등을 사용하였으며 추후 실험 부분에서 다른 ording method를 사용한 ablation이 있으니 여기서는 일단 넘어가도록 하겠습니다.
object들로 sequence를 생성하였다면 한 가지 문제점이 더 남아있게 됩니다. 바로 각 이미지에 존재하는 object의 개수다 달라 셍성된 sequence의 길이가 달라진다는 것입니다. 이에 저자들은 마지막에 EOS 토큰을 추가하여 서로 다른 길이의 sequence를 사용할 수 있도록 하였습니다. [그림 4]는 sequence construction의 예시로 오른쪽 이미지의 세 object를 tokenize한 것을 나타낸 것입니다.

Architecture, Objective and Inference
모델의 구조는 단순 encoder-decoder로 구성되어 있습니다. encoder는 픽셀, 즉 이미지를 인식하는 CNN backbone을, decoder로는 language model에 널리 사용되는 transformer decoder를 사용하였습니다. 이때 decoder는 인코딩된 이미지에 따라 한 번에 하나의 token을 생성합니다.
Objective
Pix2Seq는 언어 모델과 유사하게 이미지와 이전 token 값을 입력으로 새로운 token을 예측하도록 학습이 진행됩니다. 식으로 표현하자면 아래의 목적 함수를 최대화 하는 방향으로 학습이 진행되는 것이죠.
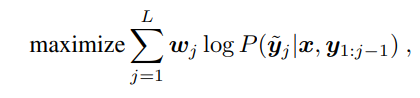
x가 주어진 이미지라면, y는 input sequence, y~는 x에 관한 target sequence를 의미합니다. x와 1~j-1번째 y~이 주어졌을 때, 그 다음 output이 y가 되도록 학습이 진행됩니다. w_j는 사전에 할당된 j번째 토큰에 대한 가중치 값이며, 저자들은 모든 j에 대해 w_j 를 1로 설정하였다고 합니다.
Sequence augmentation to integrate task priors
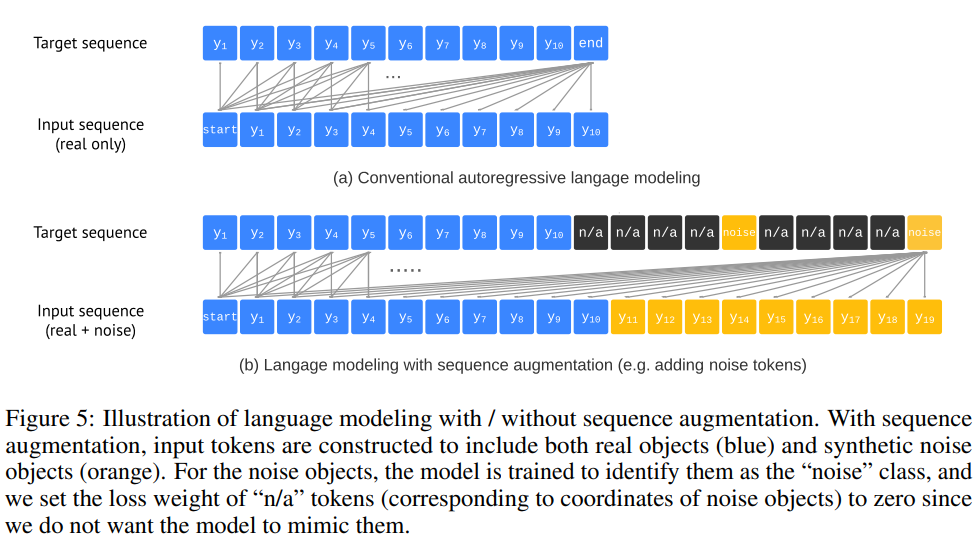
EOS토큰을 사용하면 모델이 문장(sequence, 즉, object)의 생성을 끝내는 지점을 나타낼 수 있습니다. 그러나 실제로는 모델이 이미지의 모든 object를 생성하기 전에 EOS 토큰을 생성하여 detection을 중단시키는 현상이 발생하였다고 합니다. 이러한 현상은 생성되는 box의 개수 자체를 크게 감소시켜 recall에 치명적인 영향을 끼치게 됩니다. 때문에 저자들은 recall높이기 위해 likelihood를 임의로 낮춰 EOS 토큰의 sampling을 지연시키는 방식을 사용하였으나 noisy하고 반복적인 prediction이 도출되었다고 합니다.
저자들은 sequence augmentation기법을 도입하여 이러한 문제를 해결하는 데 성공하였습니다.
Experiments
실험 부분에서 특이한 점이 있는데 저자들이 MS-COCO2017 데이터셋의 결과만을 리포팅하였습니다. 다른 데이터셋에 대한 실험 결과가 있었다면 보다 객관적인 평가가 가능했을 것 같습니다.
모델의 Baseline구조는 ResNet backbone에 transformer encoder, decoder를 사용하였습니다.
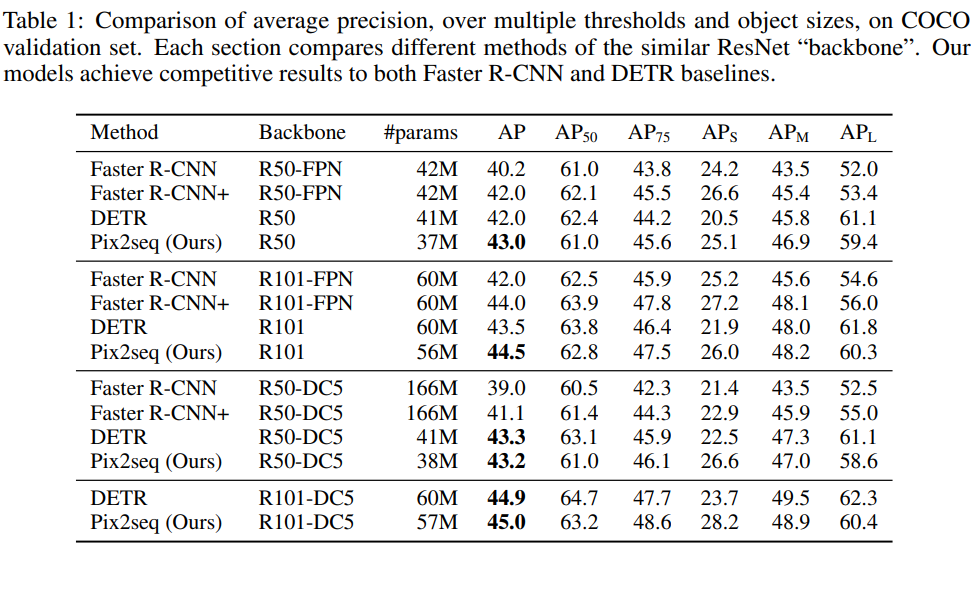
[표1]은 ResNet을 Backbone으로 하는 다른 모델들과의 성능 비교 결과입니다. 전반적으로 Pix2seq모델이 좋은 성능을 보여주고 있으며 특히 small object에서는 R-cnn에 비해 4-5AP가량 좋은 성능을 보이는 것을 확인할 수 있습니다.
Ablation on Sequence Construction
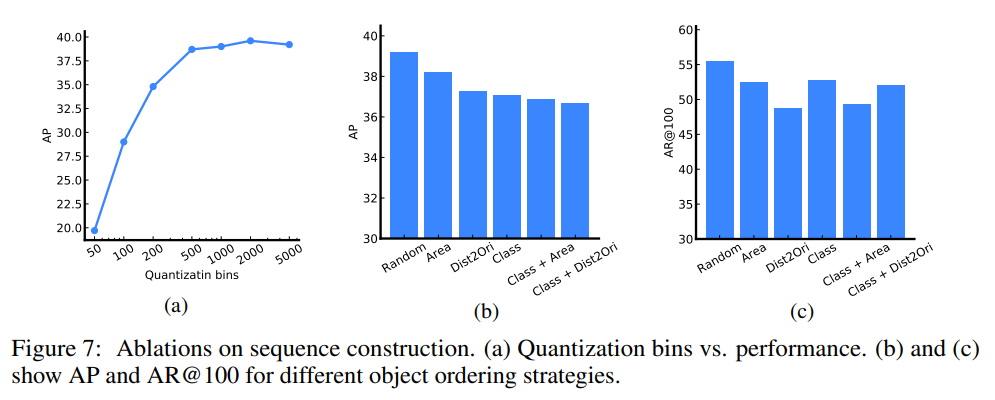
[그림 7(a)]는 bbox로 Sequence Construction을 진행할 때, n_bin의 크기에 따른 AP를 나타낸 그래프입니다. Quantization bin은 앞서 언급했던 sequence [y_min, x_min, y_max, x_max,c]에서 box의 좌표인 y_min, x_min, y_max, x_max를 나타내는 표현의 범위라고 생각할 수 있는데, 600정도까지는 AP가 가파르게 증가하다가 그 이후로는 어느 정도 일정해지는 모습을 보입니다. 이는 학습에 사용된 이미지가 640*640으로 픽셀 수 만큼의 양자화를 진행하면 그 이상의 정밀도에서 발생하는 것과 큰 차이가 나지 않음을 의미합니다.
[그림 7]의 (b),(c)는 object의 순서에 따른 AP와 top100-AR입니다. training sequence construction에서 object를 무작위 배열(random), bbox의 면적(Area), box의 좌상단과 image 원점까지의 거리(Dist2Ori), class 이름순(Class) 등의 ordering method를 사용했을 때 Precision과 Recall 모두 Random의 성능이 가장 높은 것을 볼 수 있습니다. 논문에서 저자들은 지정된 ordering method를 사용하면 object를 생성 시 앞부분에서 놓친 object를 뒷부분에서 다시 생성할 가능성이 낮지만, random으로 학습하면 나중에 찾을 수 있기 때문이라고 하였습니다.

끝으로 정성적 결과를 보여드리면서 리뷰 마치도록 하겠습니다.