Before Review
요즘 논문 연구를 하면서 우선적으로 trouble shooting을 해야 하는 부분이 있는데 그건 바로 길이가 긴 비디오를 나름의 semantic unit으로 분할하는 작업입니다.
관련해서 Movie Scene Detection, Video Secene Segmentation 쪽 연구 동향을 살피고 있습니다. 길이가 긴 비디오를 Scene 단위로 시간 축에서 분할하는 작업입니다. 비디오의 구조적인 이해를 위해 필요한 연구라고 보시면 됩니다.
본 논문과 동일한 task를 진행하는 다른 리뷰들은 아래에 있으니 참고하시길 바랍니다.
- [2022 ACCV] Boundary aware Self Supervised Learning for Video Scene Segmentation
- [2022 CVPR] Scene Consistency Representation Learning for Video Scene Segmentation
리뷰 시작하겠습니다.
Preliminaries
한 가지 알고 가야 본 논문을 이해할 수 있어 따로 정리하도록 하겠습니다. 아래에서는 Pseudo-Boundary를 정의하는 방법에 대해서 설명하겠습니다. 참고로 아래의 방법은 [2022 ACCV] Boundary aware Self Supervised Learning for Video Scene Segmentation 에서 제안 되었습니다. 본 논문도 별다른 수정 없이 그대로 아래의 방법을 학습에 사용하고 있습니다.
Pseudo-boundary Discovery
본 논문은 Self-Supervised Learning(이하 SSL) 기반으로 Movie Scene Detection을 수행합니다. SSL 방식으로 Scene Detection을 하기 위해서는 Scene Boundary에 대한 Learning Signal이 필요합니다. 즉, Pseudo Boundary 정보가 필요합니다.
그런데 사실 pseudo boundary를 잘 찾는 것은 어렵습니다. 애초에 Scene Detection은 학습을 통해서 boundary를 찾는 과정인데 pseudo boundary는 학습을 하지도 않고 일단 학습에 사용할 boundary를 찾는 것이니 많은 제약 조건이 있겠죠.
쉽게 쉽게 가기 위해서 일단 Temporal Dimension에 대해서 고정된 window를 가정합니다. 하지만 이때 우리는 고정된 window 내에 몇 개의 boundary가 있는지 모릅니다. 사실 window 안에 없을 수도 있죠. 간단하게 생각해서 일단 window 내에서 semantic transition이 가장 크게 발생하는 부분을 고려하면 되겠네요. 실제로 그 부분이 boundary가 아닐 수 있지만 pretrain 단계에서는 꽤나 유용하게 사용할 수 있다는 의미 입니다.

위의 그림은 제안하는 방식으로 pseudo boundary를 찾았을 때의 모습입니다. 적어도 장면이 확연하게 바뀌는 부분에 대해서는 나름 잘 찾아주는 모습을 보여주고 있습니다. 사전 학습 단계에서는 저 정도의 rough한 boundary를 가지고 학습을 한 다음에 finetuning 단계에서 segmentation 능력을 좀 더 고도화를 시킨다고 보면 될 것 같습니다.
저자는 Dynamic time warping을 토대로 boundary를 찾고 있습니다. 일단 formulation을 먼저 보여 드리면 아래와 같습니다.
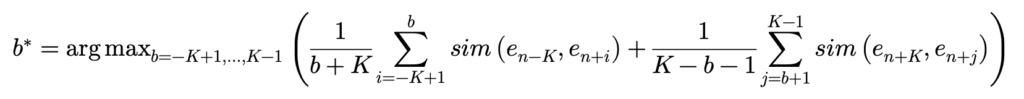
저도 처음에 수식만 보고서는 도저히 이해가 안가서 간단하게 K=5를 잡고 toy example을 만들어 보면서 이해를 해보았습니다.
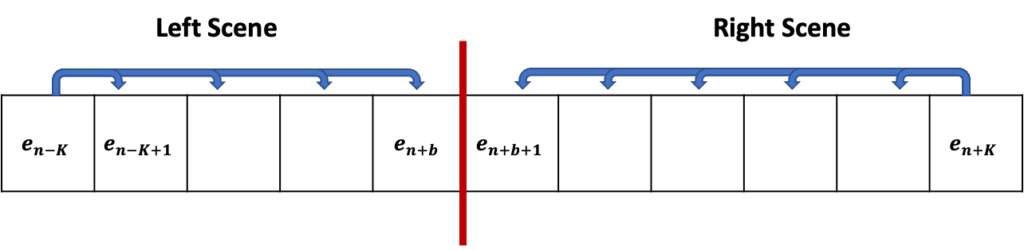
e_{n+b}와 e_{n+b+1}을 기준으로 두개의 sequence가 생성 됩니다. 수식을 보면 Left Scene 내에서 가장 왼쪽에 있는 shot인 e_{n-K}와 나머지 shot 들끼리의 유사도를 모두 더해 평균 내주고 있습니다. Right Scene 역시 마찬가지로 계산하고 있습니다.
핵심은 b의 인덱스를 조절해가면서 하나씩 boundary를 바꿔보고 그 때마다 Left Scene과 Right Scene의 유사도 평균들을 더 했을 때 최대가 되는 지점이 semantic transition이 가장 크게 발생하는 pseudo boundary라고 정의하는 것 입니다.
간단하죠. 하지만 연산 복잡도는 제가 계산했을 때 O(K^{2})으로 계산이 되는데 어차피 뭐 pseudo boundary는 학습 전에 미리 찾아놓고 돌려 놓으면 되니 크게 문제가 될 것 같진 않습니다.
이렇게 Window 마다 similarity transition이 최대로 발생하는 지점을 무조건 하나는 결정하여 pseudo boundary로 사용을 해주게 됩니다. 물론 window에 우리가 원하는 scene boundary가 없을 수도 있고, 하나보다 더 많을 수 있지만 Self-Supervised 상황에서 나름 최선의 탐색 방법을 제안하는 것 같습니다. 자세한 boundary에 대한 학습은 finetuning 과정에 맡기는 것이죠.
Introduction
컴퓨터 비전 영역에서 딥러닝을 활용한 비디오 이해 연구가 활발해지던 초기에는 비교적 짧은 영상에 대해서만 처리하였습니다. 5초~10초의 영상을 받아서 사람의 행동을 예측하거나 비디오에 해당하는 캡션을 만들거나 이렇게 진행되었습니다. 그러다 점점 평균 3분 정도의 데이터셋에서 좀 더 복잡한 머신 비전 임무를 수행하다가 요즘에는 1시간 2시간이 넘어가는 영화 데이터 셋에서의 비디오 이해 연구가 진행되고 있습니다.

위의 그림을 보면 The Godfather이라는 영화의 일부를 설명하고 있습니다. 그림 아래 캡션을 보면 각 장면이 어떤 장면인지 설명하고 있지만 굳이 이해할 필요는 없습니다.
보통 영화 데이터는 Scene의 집합으로 구성되어 각각 Scene마다 복잡한 상호 작용을 통해 형성되는 미디어 콘텐츠로 정의 됩니다. 그렇다면 우리는 Scene은 어떻게 정의가 되는 지부터 알아야 할 것 같네요.
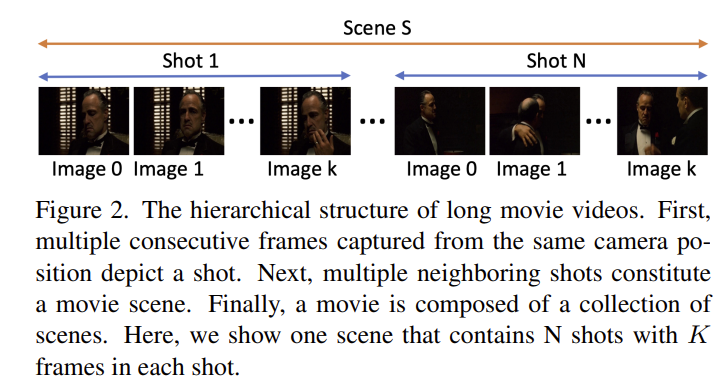
하나의 장면은 여러 shot으로 보통 정의가 됩니다. 여기서 shot은 하나의 카메라가 끊기지 않고 계속 찰영된 부분을 의미합니다. 그리고 그 하나의 shot은 여러개의 프레임으로 구성이 되는데 본 논문에서는 K개의 일정한 프레임으로 구성한다고 하네요.
이렇게 Shot이 구성되고 연속적인 Shot이 모여서 하나의 Scene을 만들어냅니다. 그리고 Shot 모여서 만들어내는 스토리가 변할 때 Scene이 바뀐다고 합니다.
즉, Scene은 영화를 구성하는 하나의 Story Unit이라 볼 수 있겠네요.
이렇게 영화 비디오 처럼 길이가 2시간 정도로 긴 데이터에서 굉장히 의미론적 해석을 요구하는 Scene을 자동으로 구분하는 것은 굉장히 어려운 작업 입니다. 단순히 Visual Clue에만 반응하여 Scene을 구분하는 것이 아니라 Scene 자체의 의미론적 정보까지 이해해서 구분해야 하기 때문 입니다.
이러한 상황에서 저자는 기존의 방법들이 Convolution 연산에 기반하기 때문에 Long-Range Temporal Context를 이해하지 못하여 Scene Understanding 능력이 떨어진다고 보고 있습니다.
성공적인 movie scene detection을 수행하기 위해서는 short-range에 해당하는 visual clue도 잘 봐야 하지만 long-range에 해당하는 정보를 잘 reasoning 해야 한다고 주장합니다.
여기서 long-rage context를 modeling 하기 위해 저자는 transformer를 사용합니다. 하지만 transformer를 그냥 사용하면 self-attention의 quadratic 복잡도로 인해 조금 문제가 있죠. 이를 해결하기 위해 저자는 S4A block을 제안합니다.
S4A block의 전체적인 목적은 transformer를 지탱하는 self-attention 연산의 복잡도를 낮추면서 long-rage context를 모델링하는 것 입니다.
그런데 사실 읽고 나니 novelty가 조금 아쉬운 부분이 있는… 그런 연구였습니다. 무튼 이제 저자가 제안한 S4A block이 무엇인지 같이 살펴보도록 하겠습니다.
Technical Approach
Problem Overview
몇 가지 notation 들을 좀 정리하도록 하겠습니다.
일단 비디오 V는 automatically-detected shot으로 나뉜다고 합니다. 여기서 사용하는 MovieNet이라고 하는 데이터가 shot 단위로 제공이 되는데 그래서 저자도 shot을 구분할 때는 별다른 처리를 하지 않아서 automatically-detected shot이라 표기를 한 것 같습니다.
- V=\{ s_{1},\ldots ,s_{i},\ldots s_{T}\}
그 다음 하나의 shot은 uniform 하게 frame이 sampling 되어 있습니다.
- s_{i}=\{ f_{1},\ldots ,f_{i},\ldots f_{K}\}
Scene Detection이라는 Task는 결국 임의의 shot s_{i}가 scene boundary 인지 아닌지 예측하는 문제라고 보시면 됩니다.
The TranS4mer Model
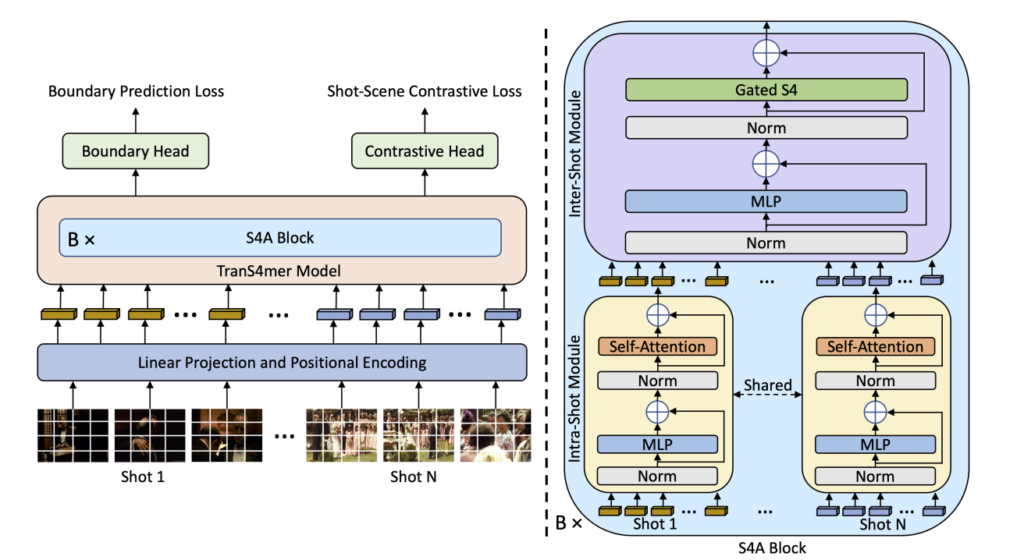
이전 방법론들의 전체적인 구조를 같게 하기 위해서 N=2m+1의 window를 가지고 예측을 수행한다고 합니다. 즉, 하나의 shot에 대해서 예측을 수행할 때 양 옆으로 N=2m+1개의 shot을 참조한다고 보시면 됩니다.
- V_{i}=\{ s_{i-m},\ldots ,s_{i},\ldots s_{i+m}\}
즉, 2m+1의 인접한 shot들이 s_{i}에 대한 long-range contextual cue를 제공한다고 보시면 됩니다.
ViT를 기본적으로 사용하기 때문에 P개의 패치를 가지며, D차원의 latent dimension을 가지는 형태로 데이터가 변환 됩니다.
- V_{i}\in R^{N\times K\times P\times D}
Intra-Shot Module
Intra-Shot Module은 그냥 ViT 그대로 생각하시면 됩니다. Token Sequence를 입력으로 넣어서 Self-Attention이 적용된 output을 만들어내는 것이죠.
여기서 저자는 Self-Attention의 Computation Cost가 크다 보니, 이를 해결하기 위해 window에 있는 모든 shot에 대해서 서로 attention을 하는 것이 아니라 shot 마다 따로 attention 하는 방식을 제안합니다.
이렇게 되면 연산 복잡도가 O(N^{2}K^{2}P^{2}) 이 되는 것이 아니라 O(NK^{2}P^{2}) 로 줄일 수 있다고 합니다. 즉 일단 Self-Attention 자체는 shot 마다 따로 하여서 short range modeling을 위해 진행한다고 보시면 됩니다.
ViT 구조에 대해서 알고 있다면 바로 이해하실 수 있을 것 같네요.
Inter-Shot Module
다음으로 제가 생각하기에는 좀 중요한 부분인데 논문에는 설명이 너무 짧게 나와 있네요. 일단 각각의 Shot에 대해서 Self-Attention을 거치고 나온 Output들을 한꺼번에 처리해주는 부분 입니다.
저자는 길이가 긴 Movie Dataset을 이해하기 위해서는 long-range context가 중요하다고 했고 이를 해결하기 위해 Gated S4 layer를 활용하여 처리해주고 있습니다.
Self-Attention이 적용되고 나온 output들을 다시 reshape 해주면 아래와 같이 정리할 수 있습니다.
- V^{\prime }_{i}=\{ z_{1},\ldots ,z_{L^{\prime }}\} ,where z_{i}\in R^{D} , L'=N\times K\times P
다음으로는 두 번의 Residual Connection을 통해서 Inter-Shot Module이 진행됩니다.
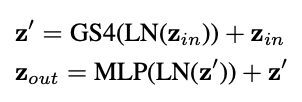
여기서 Gated S4 layer는 [ICLR 2023] Long Range Language Modeling via Gated State Spaces 에서 제안된 방법인데 자세한 설명은 나와있지 않고 저자는 그냥 idea를 빌려왔다는 식으로 설명하고 그냥 사용만 하고 있는 모습입니다.
사실 이게 제안된 방법론의 전부라…. CVPR에 억셉되기에는 novelty가 많이 떨어지는 논문이었습니다. 리뷰 퀄이 낮아진건가.. 요즘 논문 읽으면서 만족했던 적이 별로 없던 것 같습니다.
Training and Loss Function
제가 preliminaries에서 얘기한 pseudo boundary를 통해서 일단 shot에 대한 pseudo boundary learning signal을 만들고 이를 가지고 binary classification loss를 사용합니다.
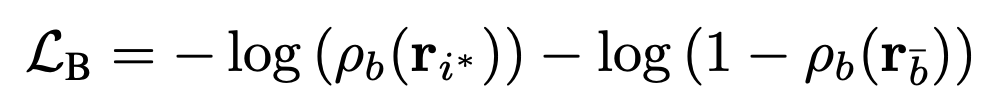
여기서 r_{i^{*}}는 pseudo boundary에 해당하는 shot 입니다. cross entropy loss를 통해서 해당 shot에 대해서는 boundary일 확률이 1에 가까워지도록 학습이 되는 것이고 boundary에 해당되지 않는 shot은 boundary일 확률이 0에 가까워지도록 학습이 됩니다.
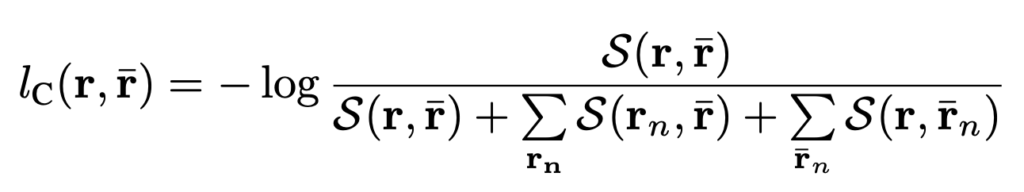
다음은 Scene Contrastive Loss 입니다. 우선 shot에 대한 representation은 ViT의 CLS token을 활용했다고 합니다. 그리고 Scene에 대한 representation은 그냥 shot representation을 평균 낸 것을 활용한다고 합니다.
사실 이 부분에 대한 Loss도 [2022 ACCV] Boundary aware Self Supervised Learning for Video Scene Segmentation 에서 제안된 SSM Loss를 그대로 사용하고 있습니다.
이 논문의 Contribution은 어디에 있는 걸까요..?
Experiments
Main Results on the MovieNet Dataset
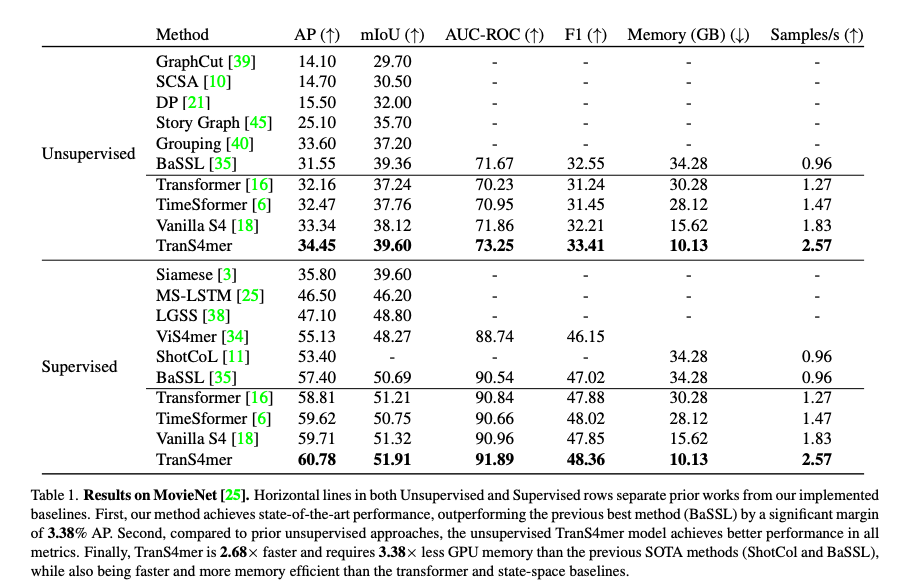
Comparison to the State-of-the-Art
우선 Benchmarking 입니다. Unsupervised, Supervised 모든 지표에서 가장 좋은 성능을 보여주고 있습니다. 뭐 딱히 얘기할만한게 없네요. 그래도 저자가 많은 부분을 참고한 BaSSL에 비해서는 더 높은 성능을 보여주고 있습니다.
Comparison with Transformer and State-space Baseline
Transformer 구조에서 다양한 베이스라인을 구축하여 비교하고 있습니다. Long-Range Context를 위해 Gated S4 Layer를 사용하였는데 그 부분을 다른 방법론들로 대체하여 실험을 진행한 것이라 보면 됩니다.
결론적으로는 Gated S4 Layer를 활용하는 TranS4mer가 가장 높은 성능을 보여주고 있습니다.
성능을 제일 높게 달성한 것은 좋은데 결국 모든 framework에서 저자가 새롭게 제안하는 것은 단 하나도 없다는 것이 아쉽네요.
Scene Detection on Other Datasets
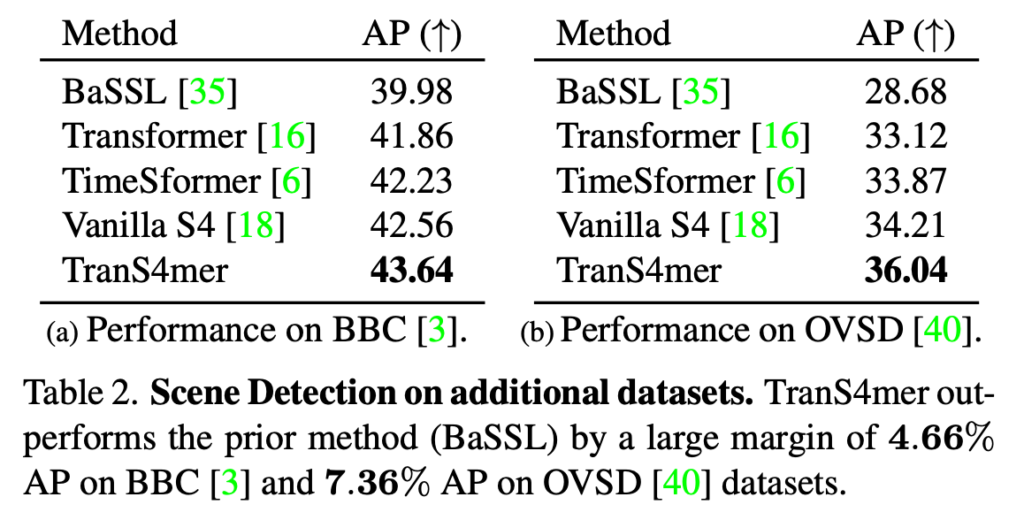
MovieNet이 아닌 다른 데이터 셋에서의 Scene Detection 실험 입니다.
BaSSL과 중점적으로 비교를 하고 있네요. 연구가 아직 그렇게 활발하게 이루어지는 분야는 아니라 비교군이 하나 밖에 없는 것은 조금 아쉽네요. BBC, OVSD라는 데이터 셋에서는 좀 더 차이가 명확하게 드러나고 있습니다.
Long-Range Video Classification
비디오의 길이가 긴 Video Classification 실험 입니다.
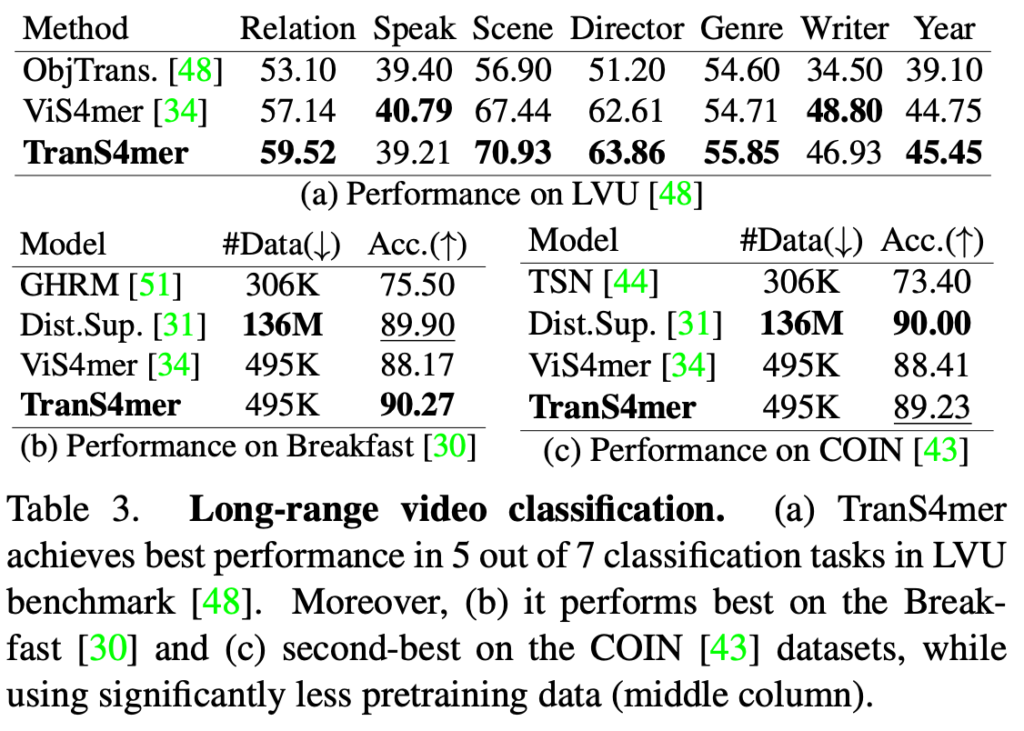
애매하게 모든 부분에서 SOTA 인 것도 아니고 왔다리 갔다리 하네요.
실험이 전체적으로 아쉬운 것이 그냥 실험 했고 성능 이렇게 나왔더라 식으로 서술이 끝나서 진짜 굉장히 기분이 안좋았습니다. 왜 이런 논문이 억셉이 됐는지…
사실 실험이 Ablation 까지 있는데 그냥 hyperparamter 실험 정도라 의미가 하나도 없는 것들인 것 같아서 리뷰에는 넣지 않도록 하겠습니다.
정말로 Gated S4 Layer가 Long-Range Context를 Modeling 하는 지도 저는 잘 모르겠습니다. 관련하여 이를 증명하는 실험도 나와있지 않고 사실 [ICML 2022] Time Is MattEr : Temporal Self-supervision for Video transformers 연구에서는 ViT가 오히려 temporal context를 잘 잡지 못한다는 내용이 이미 증명되어 있는데 본 논문의 주장들은 너무 근거가 없는 것 같네요.
Conclusion
요새 읽은 CVPR 2023 페이퍼들을 보면 별로 만족할만한 논문을 못 본 것 같습니다. 저희팀에서 냈던 VVS가 CVPR에 떨어져서 그런지 이런 논문들을 보면 정말 참을 수가 없네요…!!!
요즘 비전쪽 논문 보면 여기 저기 좋은 것들 가져다가 붙여서 우리가 SOTA다 이런 논문이거나 아니면 데이터랑 GPU 때려 박은 논문 밖에 못 본것 같은데 솔직히 좀 아쉬운 심정 입니다.
깊은 고찰과 참신한 아이디어가 돋보이는 페이퍼가 별로 없는 것 같습니다. 비전 쪽 연구가 이런 실정이니 다음 리뷰는 간만에 ML 논문 리뷰해서 좀 환기해보도록 하겠습니다.
리뷰 읽어주셔서 감사합니다.
안녕하세요. 임근택 연구원님. 리뷰 잘 읽었습니다.
리뷰 읽는 저도 이게 어째서… CVPR…? 이라는 생각이 드네요.
1. notation 중에서 m이 혹시 프레임인가요? 아니면 따로 하이퍼 파라미터로 있는 값인가요?
2. 이러한 구조면 논문 저자 주장대로라면 temporal한 정보를 보면서 pseudo boundary가 점점 정교해질텐데 왜 학습 도중에 갱신하지 않는걸까요? 부정확한 pseudo boundary로 학습하면 성능이 더 떨어질텐데… 어차피 GPU 때려박고 학습돌릴거면 충분히 할 수 있을 것 같은데 왜 안하는걸까요?
2.1. 여기 TASK도 읽다보니 상당히 애매한것 같습니다. 예시로 가져온 대부 Scene 라벨링을 보면 정말 이게 구분이 가능할지 좀 의구심이 드네요. 기준이 상당히 애매해보입니다. Semantic한 정보를 봐야한다고는 하지만 상당히 아직은 어려워보이는데 임근택 연구원님은 어떻게 생각하시나요?
1. 네 프레임은 맞지만 shot 내부에 있는 keyframe 입니다. 이는 데이터셋에서 이미 제공되는 부분이라 그냥 프레임이라 봐도 무방합니다.
2. 학습 도중에 갱신 되는게 맞습니다. 제가 잘못썼네요. .Representation이 중간 중간 업데이트 되면서 유사도가 달리지기 때문에 pseudo boundary가 업데이트 됩니다.
2.1. 저도 어려울 것 같다고 생각합니다.