제가 이번에 리뷰할 논문도 6D Pose Estimation 논문입니다.
Introduction
당시에 RGB 영상에 대한 6D Pose Estimation 분야에서 딥러닝 기법들(SSD6D, YOLO6D, AAE, PoseCNN, PVNet 등)이 좋은 성능을 보였다고 합니다. 저자들은 6D Pose Estimation의 딥러닝 연구 흐름에 대해서도 간단하게 정리하였습니다. 대부분의 방법론들은 Real-data에 대해서만 학습이 되었고, SSD6D와 AAE 방법론만 합성 렌더링 데이터로 학습이 되었다고 합니다. 또한, 대부분의 방법론들은 refinement를 하였고, 일부 방법론들(YOLO6D와 PoseCNN 등)은 refinement를 하지 않았다고 합니다. 또한, refiner는 대부분 딥러닝 기반이라 합니다.
저자들은 dense한 대응(correspondences)를 추정하는 human pose estimation 연구에 영감을 받아 새로운 3D object detector와 2D-3D의 대응을 추정하는 pose estimation(DPOD, Dense Pose Object Detector)을 제안하였다고 합니다. 이때, 많은 비용이 드는 annotation없이 대략적인 객체의 UV texture map을 이용하는 annotation-free 방식을 제안하였다고 합니다.(이에 대해서는 뒤의 method 측면에서 더 설명하도록 하겠습니다.)
**UV texture map이란?
아래의 그림과 같이 3차원 물체의 texture 정보를 2D로 표현한 것으로 이해하시면 될 것 같습니다.


저자들이 제안한 방법론은 pixel-wise의 여러 class의 객체의 ID mask를 예측하고 이미지 픽셀과 3D 모델 꼭지점의 관계를 직접적으로 제공하는 대응 맵을 예측하는 방식을 이용하였다고 합니다. 이러한 방식을 통해 많은 픽셀 단위 대응을 예측하여 기존의 방법론보다 더 잘 pose를 예측할 수 있게 되었고, 여기에 refinement를 도입하여 DPOD detector로 초기 pose를 추정한 뒤 refiner로 pose 예측을 개선할 수 있도록 하였다고 합니다. 이때, refiner는 기존의 refiner(DeepIM 등)보다 더 빠르고, 학습이 쉬우며, 합성과 real 데이터가 모두 가능하도록 하였다고 합니다.
저자들은 합성과 real 데이터 각각에서 실험을 진행하여 DPOD(dense pose detector와 refiner로 구성됨)의 성능을 확인하였고, 당시의 다른 방법론들을 능가하는 성능을 얻을 수 있었다고 합니다.
Dense한 대응점은 PnP와 RANSAC을 이용하여 정밀한 pose를 추정할 수 있게 하였고, 이후 refinement가 잘 작동할 수 있도록 하는 역할을 하였다고합니다. 또한, refinement는 1번만 적용하여도 다른 방법론들을 능가하는 성능을 보였다고 합니다.
Related Work
Deep Learning 6D Pose Detectors
딥러닝 기반의 방법론인 SSD6D , YOLO6D, BB8, iPose, AAE, PoseCNN, PVNet에 대해 간략하게 정리한 내용입니다.
우선 SSD6D는 2D Object Detector의 아이디어를 확장한 방법론으로, 다소 느리고 예측하는 pose가 근사치이므로 정확도가 떨어진다고 합니다. BB8은 3단계로 작동하며, 앞의 두 단계는 coarse-to-fine segmentation을 수행하는 것이고, 결과물은 bounding box의 point를 예측하는 3번째 네트워크의 입력으로 사용됩니다. 2D-3D 대응을 알 경우 PnP알고리즘을 통해 6D pose를 추정할 수 있으나, BB8은 단계가 많아 실행 시간이 매우 느리다는 단점이 있다고 합니다. YOLO6D는 YOLO와 BB8의 아이디어를 기반으로 제안된 방법론으로, refinement 과정 없이 효율적이고 정확한 object detection과 pose estimation을 수행하는 방법론이라 합니다. BB8과 마찬가지로 boinding box를 회귀방식으로 예측하도록 하여 직접적으로 rotation을 예측하는 방식과 다르게 모호성을 도입하지 않을 수 있다는 장점이 있다고 합니다.
또한, Occlusion에 강인하도록 설계된 방법론 중 iPose, PoseCNN, PVNet에 대한 설명과 이와 비교한 저자들의 방법론의 장점에 대한 내용입니다. iPose는 segmentation과 3D 좌표 regression, pose estimation 3단계로 작동하는 방식으로, 본 논문에서는 3D 좌표 regression이 아닌 UV map을 이용하여 잘못된 대응이 줄어들도록 하였다고 합니다. PoseCNN은 저자들의 방법론과 마찬가지로 객체 마스크를 추정하지만 그 후 객체의 중심의 translation과 rotation을 별도로 구하는 방식을 이용하는 방식이라 합니다. 또한, PVNet은 이미지의 모든 픽셀에 대한 offset을 사전에 정의된 일부 keypoint로 회귀시키는 네트워크를 설계하여 occlusion에 잘 대응할 수있도록 하였다고 합니다.
Deep Learning 6D Pose Refiners
refiner는 pose의 정확도를 높이기 위한 방법으로, SSD6D에서 사용한 refiner**와 DeepIM 방법론에서 제안된 refiner가 좋은 성능을 보였다고 합니다. 두 refiner는 유사한 개념이며 입력 이미지 패치와 예측된 상대적 transformation을 출력하도록 설계되었다고 합니다. 두 알고리즘은 모두 외부의 object detection과 pose estimation알고리즘에 의존하는 방식이라 합니다.
**Fabian Manhardt, Wadim Kehl, Nassir Navab, and Federico Tombari. Deep model-based 6d pose refinement in rgb. In Proceedings of the European Conference on Computer Vision (ECCV), 2018
Method
이제 방법론에 대해 알아보도록 하겠습니다. 먼저 데이터 준비 단계에 대해 이야기한 뒤, 사용된 아키텍쳐 및 손실 함수와 dense prediction에 대해 설명한 뒤, refiner에 대해 설명합니다.
1. Data Preparation
RGB 기반의 detector는 데이터 유형에 따라 합성과 실제 데이터 두 그룹으로 나눌 수 있다고 합니다. 먼저 합성 기반 방법론은 일반적으로 6D pose detection 데이터셋을 이용하며 object는 다른 시점에서 렌더링되어 합성 train 데이터를 생성합니다. 실제 데이터 기반의 방법론은 실제 데이터를 사용합니다. 제공된 GT pose 정보를 이용하고, 객체 마스크를 계산하여 학습 데이터의 실제 이미지에서 객체를 잘라내는 방식입니다.
이러한 두 방식은 각각의 장단이 있습니다. 실제 이미지가 충분히 객체를 다룰 수 있으면 실제 물체와 유사하기 때문에 수렴 속도가 빠르고 정확도 높은 예측이 가능하므로, 실제 이미지를 학습에 사용하는 것이 유리합니다. 그러나 실제 이미지는 빛 조건과 pose, 크기나 occlusion에 대해 검출기가 편향된다는 단점이 있어 새로운 환경에서 일반화의 어려움이 있을 수 있습니다.
pose annotation이 어려운 경우 객체의 3D 모델을 이용하여 합성 렌더링을 통해 가상의 여러 관점에서의 object를 만들어낼 수 있습니다. 그러나 합성 데이터를 이용할 경우 domain gap을 해결해야 한다는 문제가 있습니다. 학습 데이터에서 실제와 합성 데이터를 혼합할 경우 두 유형의 장점을 모두 활용할 수 있다는 장점을 있으므로, 두 방법을 모두 활용할 수 있도록 하는 방법을 고안하는 것이 필요하다고 저자들은 주장합니다. 따라서 저자들은 두 시나리오 모두에 대한 학습 데이터를 생성하는 과정에 대해 보입니다.
Synthetic Training Data Generation.
3D 모델이 주어질 경우 해당 object를 모두 커버할 수 있도록 렌더링을 해야 합니다. 객체의 위쪽 반구에서 pose를 샘플링하며, 카메라의 시야 방향을 기준으로 ±30 degree까지 평면 내에서 회전합니다. 그 후 각 카메라 위치에서 객체가 검정 배경으로 렌더링 되고 RGB와 depth 채널이 저장됩니다.
depth map을 mask로 사용하여 각 렌더링에 대해 타이트한 bounding box를 정의합니다. 이 bounding box 위치로 이미지를 잘라내어 RGB 패치와 배경에서 분리된 mask, 카메라 위치를 저장합니다.
Real Training Data Generation.
pose annotation이 사용 가능한 데이터를 학습과 test 데이터로 나누고, 이때 BB8과 YOLO6D에서 정의된 프로토콜을 따라 15%는 학습에, 85%는 평가에 사용합니다. pose사이의 상대적 방향이 특정 threshold보다 크도록 설정하며, 선택된 pose들이 객체의 모든 방향을 커버할 수 있도록 합니다. detector를 학습하기 위해 제공된 mask를 사용하여 원래의 이미지에서 객체를 잘라낸 후 online-augmentation 단계를 통해 저장됩니다. in-plane 회전을 추가하여 새로운 pose를 인공적으로 시뮬레이션합니다.
1.1 Correspondence Mapping
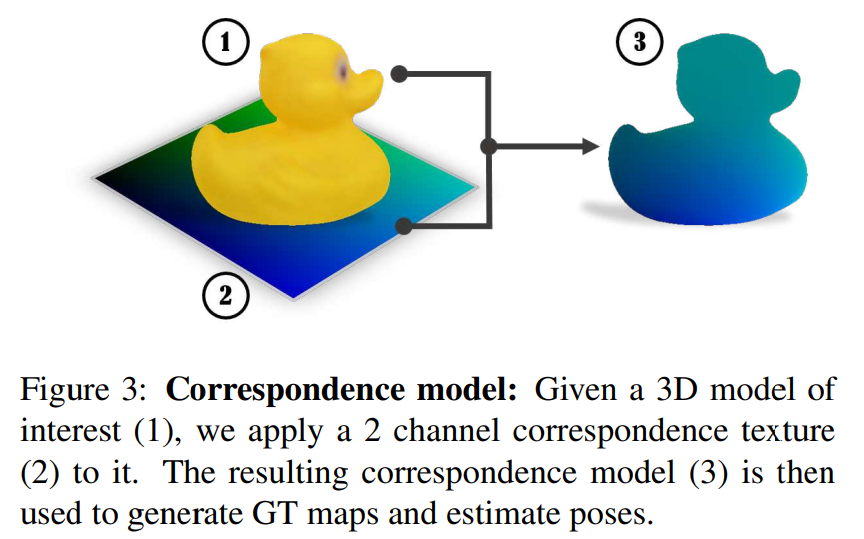
dense한 2D-3D 대응을 학습할 수 있도록 하기 위해 각 데이터 셋의 모델은 correspondence map(위의 Figure 3 참고)으로 texture를 표현합니다. correspondence map은 2채널 이미지로 0~255의 범위의 값을 가지고 있습니다. object는 단순한 구형이나 원통형 투여을 이용하여 질감을 형성합니다. 이렇게 object에 texture를 입힘으로써, 픽셀의 색상이 주어질 경우 모델 표면에서의 위치를 즉시 추정할 수 있으므로 읽기 쉬운 2D-3D 대응을 제공한다고 합니다. 편의를 위해 correspondence map으로 텍스쳐를 입힌 모델을 correspondence model이라 하고 학습 데이터와 동일한 pose의 correspondence model을 렌더링하고 각 RGB 패치에 대한 대응 패치를 저장한다고 합니다.
1.2 Online Data Generation and Augmentation
Detection and Pose Estimation
data preparation의 마지막 단계는 online-data generation 단계로 학습에 사용할 수 있는 전체 RGB 이미지를 제공하는 과정입니다. 생성된 패치는 여러 개체가 포함된 학습 이미지를 생성하는 MS COO 데이터의 이미지 위에 렌더링 된다고 합니다.(아래의 그림처럼 이미지 위에 객체들을 붙인 것) 이를 통해 detector가 다양한 배경에 대해 학습할 수 있도록 하며, 배경이 아닌, 변하지 않는 객체의 특징을 네트워크가 학습할 수 있도록 한다고 합니다. 또한 밝기/채도/대비를 무작위로 변경하고 노이즈를 추가하는 등의 augmentation을 적용하였다고 합니다. 또한, 이에 대응되는 ID mask와 correspondence patches를 검정 배경 위에 렌더링하여 생성합니다. ID mask는 오브젝트에 속한 픽셀에 class id 번호를 할당하는 방식으로 구성됩니다.

Pose Refinement
현재 pose와 예측된 pose에 있는 물체를 포함하는 이미지 쌍이 입력으로 제공됩니다. 이때 합성 데이터인 경우와 실제 데이터인 경우 차이가 생기는데, 합성 데이터일 경우 현재 포즈에서 임의의 배경에 object를 넣어 이미지를 생성하며, 이때 무작위로 광원을 추가합니다. 실제 데이터는 실제 이미지를 이용하며, 두 데이터는 모두 무작위로 augmentation이 진행됩니다. 그 다음 detector에서 예측된 포즈를 시뮬레이션 한 뒤 refinement를 수행하게 됩니다.
Dense Object Detection Pipeline
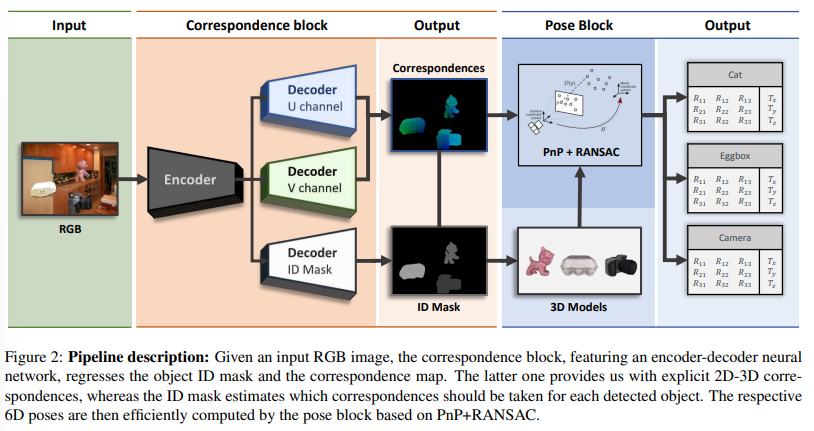
추론 과정은 두 block(Correspondence block & Pose Block)으로 나뉘어집니다.
Correspondence Block
RGB 이미지에서 ID mask와 dense 2D-3D correspondence map의 regression을 수행하는 encoder-decoder 구조로 3개의 decoder가 있습니다. encoder는 ResNet과 유사한 아키텍처를 기반으로 하고 decoder는 bilinear interpolation과 CNN으로 원래의 크기까지 upsampling하는 구조를 이용합니다.
ID Mask 헤드의 경우 object의 수 + 1(배경)만큼 채널을 가집니다. 두개의 correspondence head도 대응 맵의 고유 색상 수(앞서 0~256의 값을 갖는다고 하였으므로, 256)만큼의 채널을 가지고, 각 채널은 채널 번호에 해당하는 클래스에 대한 확률값을 저장합니다. regression을 통해 각 픽셀이 최대 추정 확률을 가지는 클래스를 단일 체널 이미지로 저장하여 correspondence 이미지를 생성합니다. 직접 regression을 통해 좌표를 구하는 것 보다 이산화된 color class classification 문제로 공식화하는 것이 더 좋은 결과를 보인다는 것이 입증되어 output의 품질을 향상시킬 수 있었다고 합니다.(3차원의 continuous한 공간을 2차원의 discrete한 공간으로 줄일 수 있기 때문이다.) loss함수는 아래와 같이 정의가 되며,
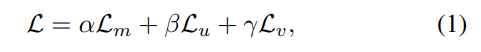
\mathcal{L}_m은 mask loss로 weighted cross-entropy함수, \mathcal{L}_u, \mathcal{L}_v는 U와 V 채널의 corrrespondence 이미지의 퀄리티를 담당하는 loss함수로 cross-entropy loss, \alpha, \beta, \gamma는 가중치 factor로 여기선 모두 1로 설정하였다고 합니다.
Pose Block
pose block은 pose를 예측하는 부분으로, 추정된 ID mask가 주어졌을 때, 이미지에서 어떤 객체가 탐지되었는지 2D 위치를 알 수 있으며, correspondence map은 2D 점을 실제 3D 모델의 좌표로 매핑한 뒤 카메라의 대응과 고유 파라미터가 주어졌을 때 PnP알고리즘을 이용하여 6D pose를 추정합니다. 각 모델에 대한 대규모 correspondence를 얻기 때문에(dense함) RANSAC은 PnP와 함께 outlier에 강인하게 작동하도록 합니다.
Deep model-based Pose Refinement
제안된 refiner는 기존의 refiner 방법론과 유사하게 ImageNet에서 사전학습된 백본 네트워크를 사용합니다. ResNet 기반 아키텍처를 이용하였으며, loss 함수는 L1 norm을 가지는 ADD 측정값을 이용합니다.
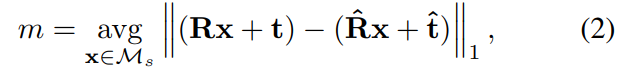
식(2)는 Pose와 예측 Pose에서 오브젝트 사이의 정점 간 거리르 나타내며 R,t는 rotation과 translation, \mathcal{M}_s는 CAD모델에서 샘플링 된 포인트의 집합을 나타냅니다. 포인트는 반복될 때 마다 다시 샘플링되며, 효율성과 메모리를 고려하여 샘플링되는 점의 수는 1만개로 제한하였다고합니다.
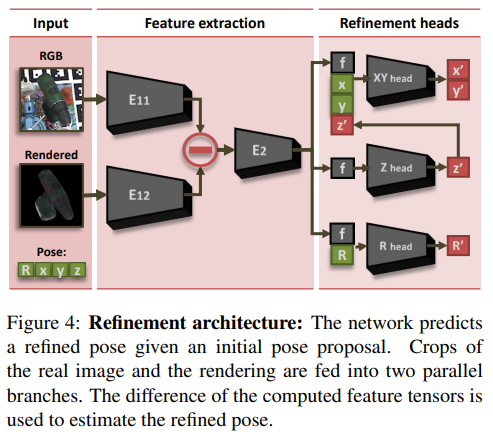
위의 Figure 4는 refinement 구조를 보여줍니다. ImageNet에서 사전학습 된 네트워크의 장점을 활용하기 위해 두개의 입력이 따로 들어가며, 각 브랜치에서 입력 이미지의 특징과 예측된 pose의 물체 렌더링의 특징을 추출하여 E2에 함께 입력으로 넣어 특징 벡터 f를 생성합니다. 이후 refinement head엣어 3개의 개별 출력 헤드를 통해 X,Y 방향에 대한 regression, Z 방향에 대한 regression, Rotation에 대한 regression을 수행합니다.
이때 Rotation은 쿼터니안 형태의 4개의 값을 예측합니다. 이때, xy와 z에 대한 예측은 초기의 pose값을 함께 입력으로 사용함으로써 안정적이고 빠르게 학습할 수 있다고합니다.
Evaluation
Datasets
LineMOD와 OCCLUSION데이터셋을 이용합니다.
- LineMOD: 13 sequence로 구성되며 clutter한 환경에서 하나의 object에 대한 GT Pose를 포함함.
- OCCLUSSION: LineMOD의 확장으로 occlussion에 대한 평가를 수행하기 좋은 데이터. 하나의 sequence로 구성되며LineMOD의 모든 object에 대한 pose가 제공됨.

Evaluation Metrics
ADD score를 평가지표로 사용하였으며, ADD는 예측된 pose와 GT pose에 대한 모델의 point사이의 average Euclidean distance로 정의되며, 대칭적이지 않은 객체는 아래의 식(3), 대칭적인 객체는 아래의 식(4)로 측정합니다.
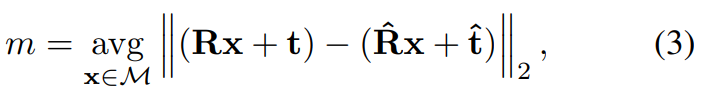
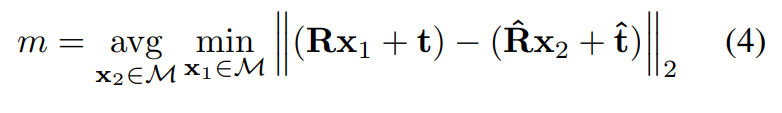
Single Object Pose Estimation
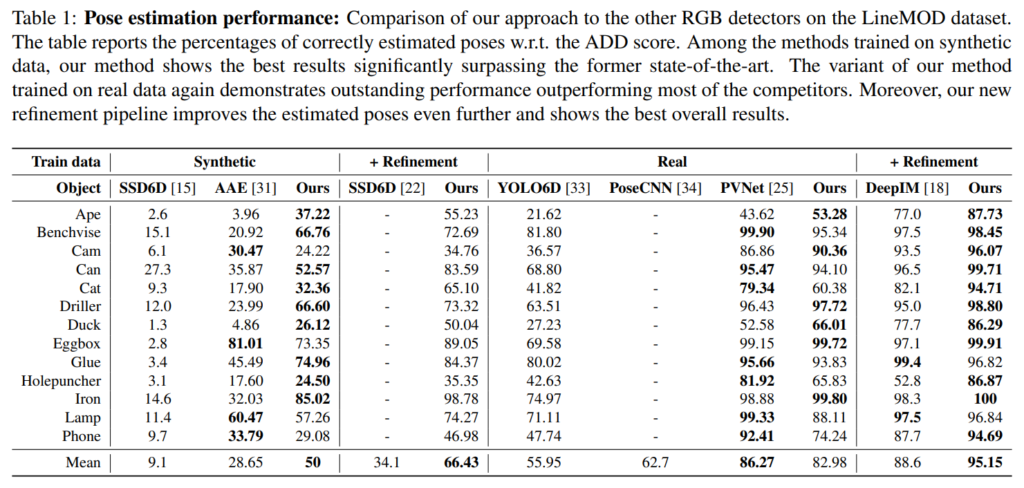
LineMOD에 대한 Pose 추정 결과는 Table1에 나와있습니다. 실제 데이터와 합성 데이터로 합습한 경우의 성능을 별도로 비교하였으며, refinement를 수행한 경우도 함께 리포팅 되어있습니다.
- 합성 데이터로 학습 + refinement를 수행하지 않은 경우
- 대부분 object에 대한 다른 방식과 비교했을 때 대체로 좋은 성능을 보였습니다. 평균을 보았을 때, 기존의 방식인 AAE의 성능보다 저자들이 제안한 방식의 성능이 크게 향상된 것을 확인할 수 있습니다.
- Ape와 Duck에서 이러한 경향이 두드러지게 나타납니다.(이에 대한 이유를 분석한 내용은 나와있지 않아서 아쉽습니다..)
- 합성 데이터로 학습 + refinement
- refinement를 수행한 SSD6D와 비교했을 때 약 2배정도 성능이 향상되었습니다.(평균값을 기준으로 함)
- 실제 데이터로 학습 + refinement를 수행하지 않은 경우
- Pose CNN이나 YOLO6D보다 성능이 뛰어나고, PVNet과는 유사한 성능을 보입니다. (PVNet의 성능이 더 좋음)
- 실제 데이터로 학습 + refinement
- refinement를 수행할 경우 정확도가 향상되어 성능이 95.15%까지 달성하였다고 합니다.
Multiple Object Pose Estimation
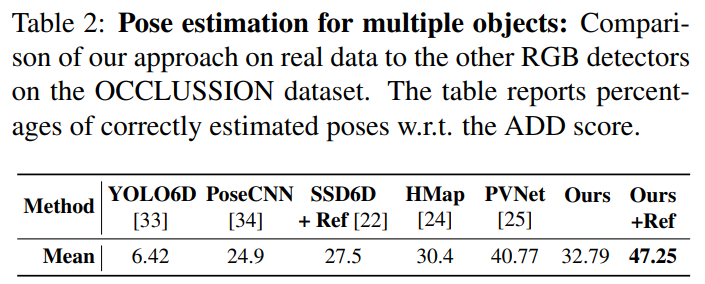
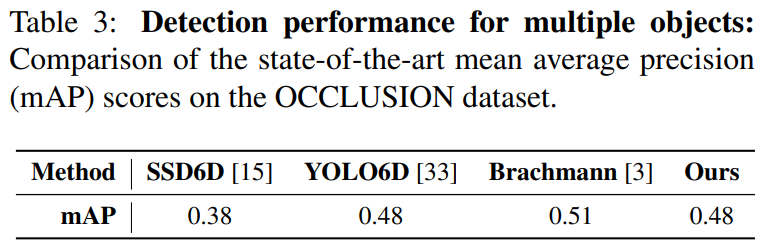
감지해야 할 객체 수가 증가하고 occlusion이 심각한 경우가 존재하는 경우에 대한 평가를 OCCLUSION 데이터셋으로 평가한 결과입니다. 객체 검출 정확도는 mAP로 리포팅하였으며(표3), 표2에서 ADD score를 확인하실 수 있습니다. 다른 검출기에 비해 경챙력 있는 성능을 달성하였으며, 여기에 refinement를 적용할 경우 가장 좋은 성능을 보이는 것을 확인할 수 있습니다.
실험 결과 해당 방법론이 잘 작동함을 여러 케이스로 보였고, 데이터의 준비 과정에 대한 자세한 설명이 있어서 이해를 하는 데 도움이 되었습니다. Refinement의 경우 초기에 예측한 pose를 사용할 경우와 사용하지 않았을 경우의 성능이 어떻게 변할 지 확인을 할 수 있었으면 좋을 것 같습니다.
좋은 리뷰 감사합니다.
제가 이번주 리뷰했던 논문에서도 data randomization을 이야기하며 학습할 때 가상데이터와 실제데이터를 함께 학습하여 다양한 환경에서 강인하게 작동하도록 한다는 점이 비슷해서 신기하네요ㅎ
간단하게 질문드리자면 위에서 pose estimation real data를 BB8과 YOLO6D에서 정의된 프로토콜을 따라 15%는 학습에, 85%는 평가에 사용한다고 하셨는데 fine-tunning을 하는 것이라 학습데이터에 적은 비율을 할당한 것인가요?
우선 BB8과 YOLO6D의 논문을 확인해보았는데, YOLO6D는 BB8의 방식을 따랐다고 되어있고, BB8의 경우 이유를 언급하고 있지 않아 정확하게 설명드리기 어려울 것 같습니다. 다만 기존의 연구의 방법론의 test 프로토콜을 따라한 것으로 보입니다. 논문에서는 두 방법론을 이야기하였으나, PVNet도 동일한 train/test 셋을 이용하였다고 합니다. 결론적으로 해당 비율은 6D pose estimation에서 많이 사용되는 데이터 구성 방식인 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다. 제 책상 데이터셋을 보니 반갑네요…^^
Ape와 Duck에 대해서 분석이 나와있지 않아 조금 아쉽네요.. 승현 연구원님께서는 이 부분에 대해서 개인적으로 분석해보신다면 어떻게 생각하시나요?
해당 논문의 실험 결과만을 가지고 원인을 분석하기는 어려울 것 같습니다.
다만 개인적으로 textureless데이터에 texture를 입힘으로써 성능이 향상되었다거나 이런 분석이 있었으면 좋을 것 같습니다.(참고로 해당 클래스에서의 성능 향상이 제가 생각한 원인이 맞는지에 대한 분석은 없었으므로 이건 어떤 분석을 원했는지로만 참고해주시 바랍니다…)
안녕하세요 이승현 연구원님 좋은 리뷰 감사합니다.
제가 잘 모르는 부분에 대해 간단한 질문을 드리자면..혹시 refiner 이라는 과정에 대해 설명해주실 수 있나요..?
다음으로 evaluation metric에서 대칭성에 따라 수식이 다른데, 왜 대칭성을 고려해야하는지도 궁금합니다. 태주님이 세미나에서 대부분의 물체가 대칭적인 구조를 가진다고 하셨는데, 평가지표에서 이를 고려해야하는 부분이 궁금해져서요. 감사합니다.
refiner 과정은 예측된 Pose 예측을 더 정확하게 하기 위한 단계로, 여기서는 Figure 4가 해당 과정입니다. 그림을 기반으로 설명을 드리자면, 앞선 Dense Object Detection 과정을 통해 각 객체들에 대한 R-T pose값이 예측이 됩니다. 이 예측값의 정확도를 높이기 위한 방법론으로, 각 객체에 대해 Crop한 이미지와, 앞선 예측으로 구한 Pose 에 해당하는 랜더링 이미지를 준비합니다.(반구를 기준으로 위의 다양한 뷰 포인트에서 촬영된 객체의 이미지가 검정 배경에 나타나있음) 랜더링 된 이미지와 실제 RGB 영상을 이용하여 pose를 추정하게 됩니다. 어떻게 보면 예측된 Pose와 RGB 영상의 일치정도를 비교하여 poes 정확도를 높이는 과정으로 생각하시면 좋을 것 같습니다.
또한, 대칭적인 구조를 가지는 물체를 고려해야하는 이유에 대해 질문하셨는데, 극도로 대칭적인, 도넛을 예로 생각해보겠습니다. 도넛을 회전시켰을 때 어디로 얼만큼 회전했는지 알 수 없습니다. 즉 영상을 통해 예측하는 것이 사실상 불가능한 경우로(사람도 어디로 얼만큼 돌렸는 지 알 수 없음) 이러한 경우에 대해 별도로 오차를 고려해야 하므로 평가지표에서 이를 구분하여 평가를 하는 것입니다.
안녕하세요, 좋은 리뷰 감사합니다.
6D Pose Estimation에 대한 관련된 논문들은 볼 때 마다 새롭게 느껴지네요.
“refinement는 1번만 적용하여도 다른 방법론들을 능가하는 성능을 보였다고 합니다.” 라고 설명을 해주셨는데, PnP+RANSAC 알고리즘을 통해 refinement를 진행하는 것으로 이해를 했는데 PnP와 RANSAC 알고리즘도 소위 말하는 ICP(Iterative Closest Point)로 즉, 반복적인 과정으로 refinement를 하는 과정이라고 이해하고 있는데 어떻게 생각하시는지 이승현 연구원님의 생각이 궁금합니다.
감사합니다.
우선 refinement 과정은 PnP+RANSAC이 아닌, ResNet 기반의 모델을 이용하여 수행합니다. 따라서 본 논문에서의미한 refinement는 해당 네트워크를 통해 pose 정보를 다시 추출하는 과정을 1번 반복한 것으로 이해하시면 될 것 같습니다..
안녕하세요 좋은 리뷰 감사합니다.
occlution데이터셋으로 진행한 실험에서 ours는 synthetic과 real중 어떤 데이터셋으로 학습을 진행한 결과인지 궁금합니다.
우선 Table 2에 캡션에는 real data라고 되어있고, 평가 메트릭은 다르지만 동일한 OCCLUSION에 대한 결과를 리포팅한 Table 3에 대해서는 별다른 언급이 없으므로 OCCLUSION에 대한 실험 결과는 real에서 진행한 것으로 보입니다.