
안녕하세요, 로보틱스 팀 양희진 입니다. 이번에도 6D Pose Estimation 논문을 리뷰하였습니다. 매번 읽을 때마다 새롭지만 세 번째 pose estimation에 관련된 논문이기 때문에 확실히 아는 내용도 조금씩 보여 재미를 느끼는 것도 있지만 여전히 내용적으로는 어려운 분야인 것 같습니다. 이번 CDPN은 Paperwithcode에서 현재 LINEMOD 데이터셋에서 10위의 성능을 보이고 있네요. 속도와 성능을 둘 다 잡는 것에 초점을 맞추었다고 합니다. 리뷰 시작하겠습니다.
Background Knowledge
- PnP(Perspective-n-Point, reference)
3차원에서 2차원으로의 움직임을 추정하기 위한 방법입니다. n개의 3차원 공간 상의 점과 3차원 점들이 2차원 평면에 projection 되는 점의 위치가 주어집니다. PnP 알고리즘을 통해 epipolar contraint 없이 더 적은 matching pair로 더 좋은 추정 결과를 얻는 것이 PnP 알고리즘의 핵심입니다.
- Hadamard product(reference)
일반적인 행렬곱은 m \times n과 n \times p 를 가져야 행렬곱이 성립할 수 있습니다. 다른 부분은 같은 크기를 가지는 m \times n의 두 행렬의 곱을 의미합니다.
Abstract
단일 컬러 이미지에서 6D pose estimation을 하는 것은 항상 문제가 있었습니다. 최근에는 이러한 문제들을 PnP 알고리즘을 통해 해결을 하고 있습니다. 해당 논문에서는 새로운 6D pose estimation에 대한 접근법으로 CDPN(Coordinates-based Disentangled Pose Network)을 제안합니다. 여기서 말하는 disentangle을 할 경우 예측한 rotation과 translation 각각 성능의 향상과 robust한 pose estimation을 할 수 있게 해주는 것을 의미합니다. 저자는 해당 방법론이 texture-less 물체에 대해서도 잘 다룰 수 있다고 합니다. 이러한 실험들을 증명하기 위해 데이터셋으로는 6D pose estimation의 대표적인 LINEMOD, Occluded LINEMOD 데이터셋에서 진행을 하여 좋은 성능 향상폭을 증명하였고, 단일 RGB 이미지에서도 해당 방법론을 사용하여 SOTA를 달성하였다고 합니다.
1. Introduction
물체의 pose estimation은 로보틱스 분야나 VR 분야 같은 곳에서는 필수적인 요소입니다. 해당 논문에서는 단일 컬러 이미지에서 6D pose estimation를 하는 task에 초점을 좀 더 맞추었다고 합니다. abstact에서도 말씀을 드렸지만 이런 challenge는 해당 분야에서 아직도 해결이 되지 않은 문제 중 하나이므로 여기에 좀 더 가중치를 두었다 라고 해석이 됩니다. 이러한 문제를 해결하기 위해서는 texture-less한 물체와 occluded 물체를 잘 다룰 수 있어야 합니다.
일반적으로는 이런 task에 대해서 gemetric 문제를 고려하고 2차원 영상과 3차원 모델간의 특징점을 매칭하는 것으로 해결하였습니다. 하지만, 특징점을 매칭하기 위해서는 풍부한 texture가 필요하게 됩니다. 즉, texture-less 물체는 다룰 수 없는 문제가 발생합니다. 딥러닝이 발전하면서 데이터로 부터 특징을 추출하여 혜택을 볼 수 있게 되었습니다. 당시 6D pose estimation을 위한 접근법은 이미지 또는 2차원 키포인트를 PnP 알고리즘을 통해 예측하는 것입니다. 직접적인 접근법은 pose estimation의 성능 향상을 위한 3차원 정보를 주기에는 어렵습니다. 간접적인 접근법 같은 경우,
sparse한 2차원과 3차원의 관련성은 occlusion에 민감하게 작용하게 됩니다. 이런 이유로 여전히 refinement를 하는 것은 성능 향상을 위해 필요로 하게 됩니다. 앞선 접근법들을 제외하고 또 다른 새로운 방법이 있습니다. 해당 논문에서 제안하는 Coordinate-based 접근법입니다. 해당 접근법은 occlusion에 대해 매우 robust한 것이 입증되었습니다. 해당 접근법으로 물체의 좌표계를 예측하는 것은 dense한 2차원과 3차원간의 관련성을 만들어 주어 pose estimation 문제를 해결할 수 있다고 합니다. coordinate-based 방법론은 depth 정보에 의존하기 어렵고 비효율적이라고 합니다. 단일 컬러 이미지에 대한 케이스에 대해 구현이 어렵고 실시간으로 처리해야 하는 것을 만족하는 것 또한 어렵다고 합니다. PnP 알고리즘으로 간접적으로 2차원과 3차원 간의 관련성에 대한 문제를 해결했지만 각 파라미터는 각각 다른 property를 가지고 있습니다. 물체에 대한 겉모습은 rotation에 대해 많은 영향이 있는 반면에 translation의 영향은 적기 때문에 rotation과 translation은 각각 분리하여 문제를 해결해야 합니다.
해당 논문에서는 robust하고 efficient한 pose estimation을 단일 컬러 영상에서 성능 향상에 목표를 두었다고 합니다.
contribution은 다음과 같습니다.
- 6D pose estimation을 위해 CDPN을 제안하여 물체의 회전과 이동을 효율적으로 특성화함. 물체의 pose estimation을 위해 최초로 indirect PnP-based strategy와 direct regression-based strategy를 통합하였음.
- detection error에 강인하고 특정한 detector에 민감하지 않도록 하는 pose estimation을 할 수 있게 하는 Dynamic Zoom In(DZI)을 제안함
- 실시간으로 적용을 하기 위해 회전에 대한 추정 측면에서 2-stage object-level coordinate estimation을 함께 물체가 아닌 영역에 대해서 극복하기 위해 Masked Coordinate-Confidence Loss(MCC Loss)를 제안함.
- translation의 경우, coordinate의 영향을 피하기 위해 robust하고 정확한 translation estimation을 얻기 위해 Scale-Invariant Translation Estimation(SITE)를 제안함.
- 해당 논문의 접근 방식은 매우 정확하고 확장성이 좋으며 LINEMOD 에서 SOTA를 달성하였음. 해당 모델은 충분히 빠르고(이미지당 30ms, 더 빠른 detector를 활용하면 더 단축할 수 있음) re-training 없이 다양한 detector와 함께 작동할 수 있음.
2. Related Work
저도 적으면서 이해가 잘 안되었던 direct 접근 방식과 PnP-based 접근 방식을 언급하는데 해당 내용에 대해 다루어 보겠습니다.
Direct approaches
6D camera pose estimation 및 viewpoint estimation에 대한 일부 연구에서 직접적인 접근 방식이 먼저 제안 되었고 이후 6D pose estimation 분야에서도 유사한 아이디어가 도입되었다고 합니다. 3DOF 회전 공간을 분류 가능한 viewpoint bin으로 discretize하고 SSD-based detoctor 프레임워크에 구축된 classifier를 학습시켜서 해결한 반면에 3DoF translation은 2D bounding box에서 얻었습니다. 이전에 제가 리뷰한 PoseCNN에서는 regression-based 접근법을 제안하였습니다. 6D pose parameter는 Quarternion과 distance는 입력 이미지에서 직접 regression을 수행했었습니다. 이러한 직접적인 접근 방식은 종종 pose의 세분화를 위해서 ICP(Iterative Closest Point)알고리즘을 추가로 활용하게 됩니다. 하지만 여전히 viewpoint에 대해서 ambiguity problem과 같은 까다로운 문제들을 가지고 있습니다.
PnP-based approaches
물체의 6D pose estimation을 간접적으로 해결한 접근법에 대해 알아보도록 하겠습니다. 영상에서 3차원 bounding box의 모서리 projection을 검출하는 방법을 제안하여 PnP 알고리즘을 사용하여 6D pose estimation을 해결하는 방법이 있습니다. 해당 방법도 ICP 알고리즘을 적용하면 좀 더 높은 estimation 결과를 얻을 수 있습니다. 이미지에서 객체의 keypoint를 검출하여 pose 를 해결하는 방법도 있습니다. 이러한 keypoint-based 방법 외에 간접적인 pose estimation의 또 다른 방법은 coordinate-based 접근 방식입니다. RGB-D 이미지를 기반으로 RandomForest를 사용하여 dense한 3차원과 3차원간의 대응을 예측한 다음 RANSAC 알고리즘을 통해 6D pose esitimation을 최적화하는 방법을 사용하는 방법도 제안되었습니다. 여러가지 방법론들이 있지만 저자는 회전과 이동을 별도로 처리하는 것을 제안합니다.
회전(rotation)의 경우, 기존의 coordinate-based 접근 방식에 비해 잘 설계된 local-region based 패러다임을 만들어 좀 더 정확하고 효율적으로 추정이 가능하게 된다고 합니다.
이동(translation)의 경우, 로컬 이미지 패치에서 직접 추정을 합니다. 이러한 작업을 통합한 네트워크에서 해결합니다. 이러한 과정을 통해 SOTA를 달성할 수 있었다고 합니다.
3. Method
3.1. Framework
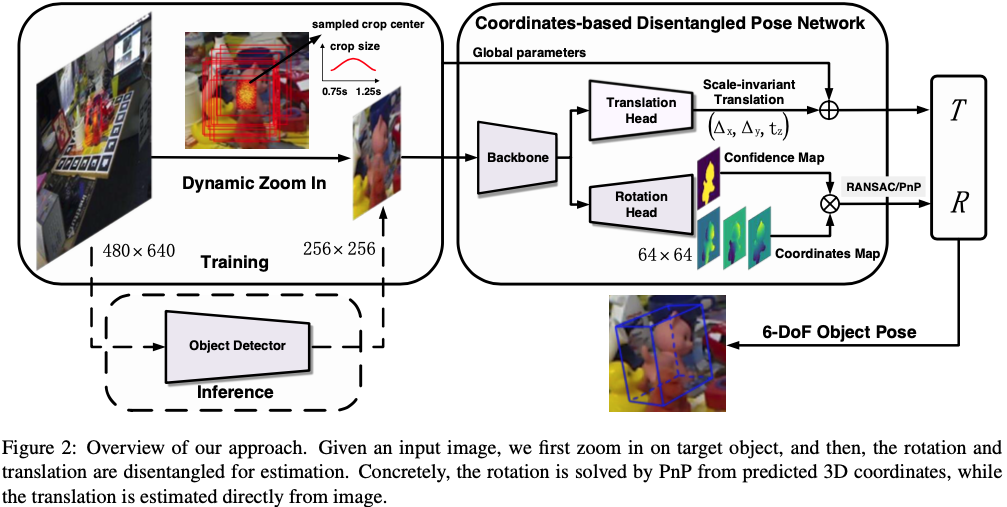
coordinate-based 접근 방식을 선택하여 occlusion과 clutter에 대해서 강인함을 보이는 dense한 대응에 대해 회전을 추정합니다. 2차원-3차원에 대한 대응을 만들기 위해서는 정확한 물체의 영역을 추출해야 합니다. 해당 과정을 위해서 semantic segmentation 네트워크를 학습시키는 방법도 있지만 해당 방법은 이미지 내에 물체가 multi-class에 해당하는 경우 이를 처리하는 데에 불편하다고 합니다. Mask RCNN과 같은 instance segmentation은 이를 처리할 수 있지만, 2-stage detector이기 때문에 실시간으로 처리하는 것은 어렵습니다.
하지만, 위 방법과 다르게 저자는 2단계의 파이프라인을 선택하여 사용합니다.
- 빠르고 lightweight를 가지는 detector(예를 들면 tiny YOLOv3)를 사용하여 coarse detection을 수행한다.
- 고정된 크기의 segmentation을 구현하여 객체의 픽셀을 추출한다.
detection의 경우, 제안된 Dynamic Zoom in(DZI)으로 인한 detection error를 pose estimation 프레임워크가 상당 부분 허용될 수 있게 설계되어있으므로 빠르지만 정확도가 낮은 detector로도 충분하다고 합니다.
segmentation의 경우, coordinates regression에 붙이면 프레임워크를 보다 충분히 가볍고 빠르게 만들 수 있습니다. 기존의 segmentation-based 접근 방식과 비교했을 때, 위와 같은 2단계의 파이프라인은 다양한 상황에서 정확한 객체 영역을 효율적으로 추출할 수 있게 됩니다.
translation의 경우, 좀 더 robust하고 정확한 추정을 위해 2차원-3차원 대응 대신 이미지에서 예측하여 예측된 3차원 coordinates의 scale error로 인한 영향을 피합니다. 전체 이미지에서 translation을 regression하는 것 대신에 detection된 객체 영역에서 translation을 추정하는 Scale-Invariant Translation Estimation(SITE)를 제안하여 회전과 이동에 대해 disentangled process가 Coordinate-based Disentangled Pose Network(CDPN)로 통합됩니다.
3.2. Dynamic Zoom In(DZI)
앞서 프레임워크에서 언급된 DZI에 대해 알아보겠습니다.
이미지 내에 있는 물체의 크기는 카메라까지의 거리에 따라 임의로 변경될 수 있으므로 coordinate regression의 난이도가 크게 증가하는 문제가 발생하게 됩니다. 또한 이미지 내에 물체가 작은 경우 네트워크를 통해 useful한 특징을 추출하기 어려운 문제도 있습니다. 해당 문제를 해결하기 위해 detection된 물체를 고정된 크기로 확대(zoom in)하게 됩니다. 반면에 unified pose network는 모든 detector에 대해서 강인해야하므로 detection error인 \epsilon을 고려해야 합니다. 하지만 특정 detector에 대해 Pose network를 직접 학습하는 것도 좋지만 network는 detector와 밀접한 관련이 있습니다. 이런 문제를 해결하기 위해 Dynamic Zoom In(DZI)를 제안합니다.
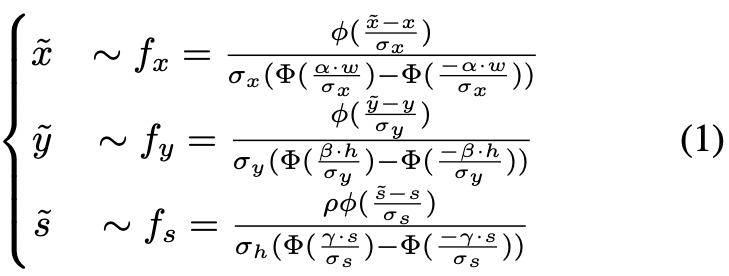
식(1)을 살펴보면 (x, y)와 (h, w)는 각각 물체의 중심과 GT의 크기를 의미하고 s는 \max(h, w), \phi는 정규분포(standard normal distribution)를 의미합니다. \Phi는 누적 분포 함수(cumulative distribution function, CDF)를 의미합니다. \alpha ,\beta, \gamma, \rho 는 샘플링 할 때 범위를 제한하는 coefficient 역할입니다. \sigma_{x}, \sigma_{y}, \sigma_{z}는 분포 모양을 제어하는데에 사용됩니다.
타겟 물체의 위치 C_{x, y}, 크기 s = \max(h, w) 가 존재하는 이미지가 주어졌을 때, 식(1)에서 정의된 정규 분포에서 위치 \tilde C_{x, y} 와 크기 \tilde{S} 를 샘플링합니다. 샘플링의 범위는 객체의 height h, width w 및 coefficient인 \alpha ,\beta, \gamma, \rho에 따라 달라집니다. 이후 샘플링된 \tilde C_{x, y}과 \tilde{S}를 사용하여 객체를 추출하고 필요에 따라 padding을 통해 가로와 세로의 aspect ratio를 변경하지 않고 고정된 크기로 크기를 조정해줍니다.
DZI의 장점을 4가지에 대해서 저자는 얘기합니다.
- detection error인 \epsilon에 대한 pose estimation 모델을 robust하게 만들어줍니다.
- 학습 과정과 독립적인 detector에 대한 시스템의 확장성이 좀 더 좋아지고 평가 과정에는 single-stage detector를 사용하여 해당 시스템을 좀 더 빠르게 수행할 수 있게 됩니다.
- 더 많은 학습 샘플들을 제공하여 pose estimation의 성능을 향상시켜줍니다.
- 고정된 크기의 출력으로 RANSAC 알고리즘을 사용한 네트워크의 추론 및 PnP 계산에 소요되는 시간을 일정하게 유지해주는 효과도 있다고 합니다.
3.3. Continuous Coordinates Regression
Coordinates-Confidence Map
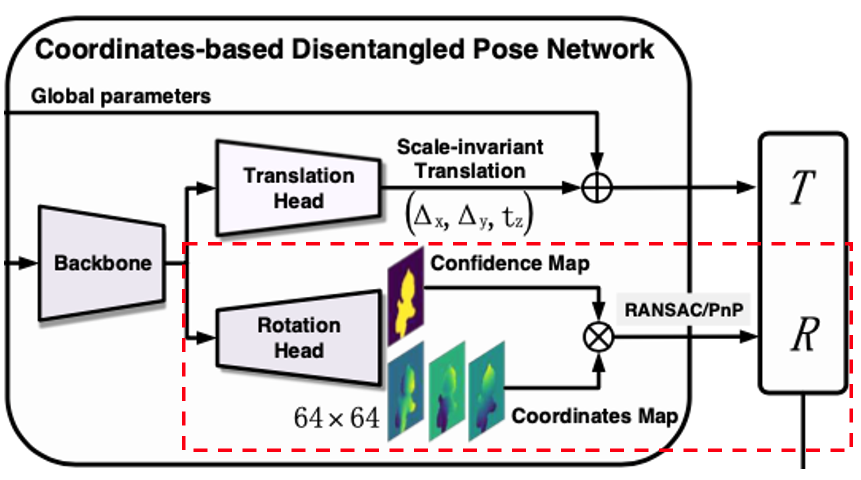
이미지 패치를 추출하고 중심 픽셀의 좌표를 예측하는 것과 달리 해당 논문에서 제안하는 방법은 모든 객체 픽셀의 3차원 좌표를 한 번에 예측하여 높은 효율성을 달성하는 것입니다. 추가적으로 네트워크에서는 각 픽셀에 대한 신뢰도값을 예측하여 픽셀이 객체에 속하는지 여부를 나타내게 됩니다. 추가적인 네트워크의 branch를 사용하는 거 대신에 두 과정의 출력 크기가 동일하고 값이 정확한 위치 대응을 갖는 사실에 기반하여 해당 과정을 coordinate regression로 merge 합니다. 그런 다음에 convolution과 deconvolution layer로 구성된 rotation head를 도입하여 feature를 처리하면서 scale up 하고 3개의 채널을 갖는 coordinate map M_{\\coor}와 1채널(단일 채널)을 가지는 confidence score map의 M_{\\conf} 을 포함한 총 4채널을 구성하는 Coordinates-Confidence Map (H \times W \times 4)로 변환합니다. 이때 M_{\\coor}에서 각 픽셀은 3차원 좌표를 encoding하고 각 채널은 객체의 좌표축을 나타내게 됩니다.
Masked Coordinates-Confidence Loss
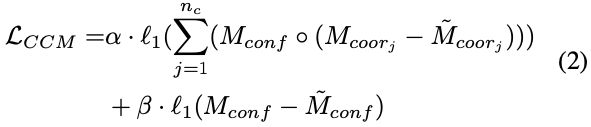
다들 아시다시피 배경에 대한 GT의 좌표는 알 수 없습니다. 그래서 당시 대부분의 접근법에는 배경에 특별한 값을 assign하는 방법을 사용했는데 이러한 방법은 regression 대신에 classification을 통해서 좌표를 예측하기 때문에 이러한 접근 방식에 효과적입니다. 해당 논문에서 수행하는 접근 방식은 연속되는 좌표를 직접적으로 regression하기 때문에 네트워크가 coordinate map의 객체에 대한 boundary에서 sharp한 edge를 예측하도록 강요하게 됩니다. 이러한 방법은 학습이 어렵고 잘못된 좌표를 도출하는 경향이 있게 됩니다. 이러한 문제를 해결하기 위해 저자는 Masked Coordinates-Confidence Loss(MCC Loss)를 제안합니다. 해당 loss function은 coordinate map의 경우는 foreground 영역에 대한 loss만 계산하고 confidence map은 모든 영역에 대한 loss 을 적용하게 합니다. 이렇게 하는 방법은 object가 아닌 영역에 대한 영향을 피하고 네트워크가 보다 정확한 좌표를 제공할 수 있도록 하기 때문이라고 합니다. 이때 학습시에는 L1 loss 를 사용했다고 합니다.
loss function에 나오는 n_{c}는 coordinate의 채널 수를 의미하므로 3이 됩니다. M^i_{*<em>}과 \tilde M^i_{*</em>} 는 각각 GT map과 predict map을 의미합니다. \circ는 Hadamard product라고 합니다.
Building 2D-3D Correspondences
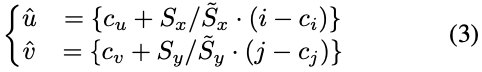
특정 threshold를 설정하여 confidence map로부터 객체의 픽셀을 추출할 수 있습니다. 하지만, RGB 이미지의 객체 크기는 일반적으로 Zoom in으로 인해 coordinate map의 객체 크기와 다른 문제가 생깁니다. 이러한 문제를 해결하기 위해 2D-3D에 대한 대응을 구축하기 위해 coordinate map의 픽셀을 precision의 손실이 발생하지 않도록 RGB 이미지에 매핑을 합니다. (3)식을 살펴보면 RGB 이미지에서 객체의 중심과 크기를 (c_u, c_v) 및 (\tilde S_x, \tilde S_y)로 지정하고 coordinate map에서는 (c_i, c_j) 및 (S_x, S_y)로 지정합니다. 이렇게 지정된 coordinate map의 픽셀 (i, j)에 대해 RGB 이미지의 해당 픽셀 (\hat u, \hat v)으로 표현할 수 있습니다. {}괄호가 쳐져 있는 것을 볼 수 있는데, 이는 반올림 연산을 수행하지 않도록 하기 위함이라고 합니다. 이렇게 rotation은 RANSAC을 사용한 PnP의 correspondences에서 쉽게 해결할 수 있다고 합니다.
3.4. Analysis on Translation

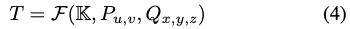
픽셀 P_{u, v}와 해당 좌표를 의미하는 Q_{x, y, z}를 모두 네트워크로부터 추정하며 이러한 과정은 PnP를 통해 해결된 translation에 영향을 끼치게 됩니다. 3차원 좌표를 의미하는 Q_{x, y, z}와 scle factor error를 의미하는 \delta_{\\scale}은 depth component인 T_z에 매우 큰 영향이 있음을 그림3(b)에서 확인할 수 있습니다. 물체마다 다른 \delta_{\\scale}이 다르면 translation의 성능이 불균형해지는 것을 실험을 통해 증명했다고 합니다. 식(4)의 \mathbb K는 camera intrinsic parameter, \mathcal F는 PnP 알고리즘, I는 input image를 의미하고 \mathcal G_w는 네트워크를 의미하는데 w라는 파라미터를 설정하는 것으로 보입니다만 w에 대한 파라미터의 설명이 나와있지 않아 의미를 알 수가 없네요.

식(5)를 의미는 좀 더 robust하고 정확한 translation estimation을 위해 이미지에서 translation T를 직접 학습하여 Q_{x, y, z}의 \delta_{\\scale}의 영향을 피하는 방법을 제안하게 됩니다. 이미지에서 T를 추정하는 것은 물체의 위치와 크기가 카메라까지의 방향과 거리를 직접적으로 구할 수 있다는 것을 생각해보면 매우 합리적인 방법입니다. 이러한 방법은 여러 접근 방식에서 제안되었었는데요. 예를 들어 이미지에서 R(rotation)과 T(translation)을 동시에 학습하기 위해 sementic segmentation network를 학습하는 것을 생각해보면 ADD에 대해서는 성능이 좋았는데, 5cm 5^\circ에서는 성능이 좋지 않습니다. 아래 테이블 1에서 해당 결과를 확인할 수 있습니다.

이러한 결과는 직접 regression하는 T가 정확한 T를 제공할 수 있는지에 대한 검증을 하게 됩니다. 이러한 결과를 통해 다양한 strategy를 단일 모델로 하는 R은 coordinate에서 간접적으로 추정하고 T는 직접적으로 regression하는 CDPN(Coordinates-based Disentangled Pose Network)으로 통합합니다. 이러한 접근 방식은 R과 T 둘 다 좀 더 정확하고 robust하고 정확한 estimation을 달성하게 됩니다. 저자는 최초로 이렇게 통합하여 pose esitmation을 추정하는 것이라고 주장합니다.
3.5. Scale-invariant Translation Estimation(SITE)
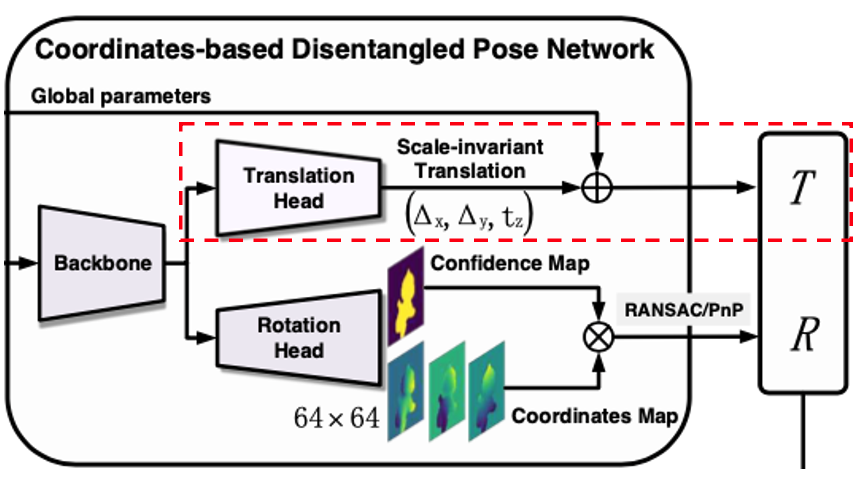
이미지에서 직접 T를 regression하는 당시의 접근법은 주로 이미지 전체에 대해서 수행합니다. 이러한 접근법은 매우 비효율적이라고 저자는 비판을 합니다. detection된 물체에 대해서 직접 T를 추정하는 것이 더 효율적이지만 해당 방법에는 문제가 따르게 된다고 합니다. 제목과 같이 Scale에 invariant하지 않는 문제를 의미하는 것 같습니다. 이러한 문제를 해결하기 위해 저자는 SITE(Scale-invariant Translation Estimation)라는 방법론을 제안하여 로컬 이미지 패치를 기반으로 매우 정확하고 효율적인 T를 추정합니다.
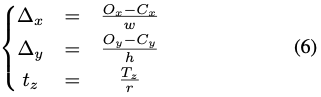
먼저, 샘플링된 로컬 패치 이미지의 정보인 T_G를 계산합니다. 이때 T_G는 위치 C_{x, y}, 크기 (h, w)를 둘 다 포함합니다. 그런 다음 backbone에 추가적인 translation head를 도입하여 scale-invariant한 T_S = (\Delta_x, \Delta_y, t_z)를 예측합니다. \Delta_x, \Delta_y는 bounding box 중심에서 물체의 중심까지의 offset을 의미합니다. absolute offset을 regression하는 것 대신에, 일정한(즉, scale-invariant)한 상대적인 offset을 예측하도록 학습합니다. 이때 t_z는 zoomed depth를 의미합니다. 해당 과정은 식(6)으로 나타낼 수 있게 됩니다.
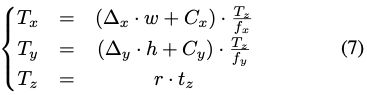
식(7)은 최종적으로 translation T=(T_x, T_y, T_z)는 T_S와 T_G를 결합하여 결과를 나타내는 것을 볼 수 있습니다. 이때 (O_x, O_y)와 (C_x, C_y)는 원본 이미지에서 물체의 중심과 패치의 중심을 투영한 값을 의미합니다. (h, w)는 원본 이미지에서 샘플링된 물체의 크기를 의미합니다. r은 앞서 설명한 DZI(Dynamic Zoom In)의 크기 조정 비율입니다.
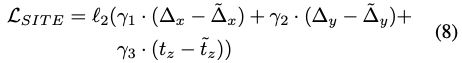
앞선 내용을 바탕으로 식(8)은 translation head net의 loss function을 나타냅니다. 여기서 *, \tilde *는 각각 실측값(GT)과 예측값을 의미합니다. (논문에서는 예측값과 실측값으로 나와있는데 잘못 작성된 것 같습니다.) bounding box의 중심이 객체의 중심과 일치하지 않는 경우, occlusion 상황에 대해 처리할 수 있도록 loss function을 설계했다고 합니다.
4. Data Preparation
Dataset
해당 논문에서 진행한 실험은 LINEMOD, Occluded-LINEMOD에서 진행을 하였다고 합니다.
Synthetic Training Data
LINEMOD 데이터셋은 한 클래스당 약 200개 정도의 학습 이미지를 제공하는데, 이 정도 양은 딥러닝 학습에 비교적 적은 양입니다. 그래서 학습 세트에 pose distribution에 따라 각 클래스에 대해 1000개의 이미지에 대해 무작위로 렌더링을 진행했다고 합니다.
5. Experiments
5.1. Metrics
평가 지표로는 여러가지가 사용되었는데 6D pose estimation에서 대표적으로 사용되는 2D proj, 5cm 5^\circ, ADD가 되었습니다. 역시나 symmetric object에 다루기 위해 ADD-S를 사용하였다고 합니다.
5.2. Experiments on LINEMOD dataset
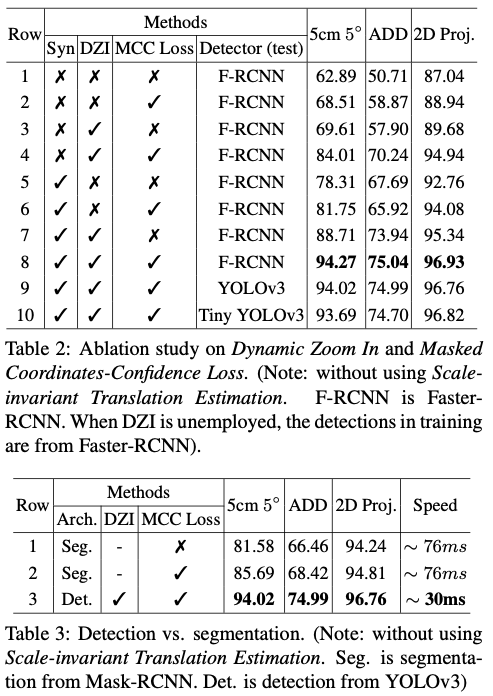
LINEMOD에서의 실험결과를 나타내는 표입니다. 속도가 어느정도로 차이가 나는지 궁금했는데 마침 표3을 보시면 detection과 segmetation을 비교하는 표가 있는데 해당 표에서는 성능과 속도 측면을 비교합니다. segmentation-based baseline을 만들기 위해 물체의 segmentation mask를 제공하기 위해 Mask-RCNN을 학습시켰다고 합니다. 그런 다음 방금 전의 mask를 사용하여 훈련 중에 물체를 확대하고 평가 중에 2D-3D에 대한 대응을 구축하기 위해 confidence map으로도 사용합니다. detection-based 프레임워크인 DZI로 학습을 하면 segmentation-based 프레임워크보다 정확도와 속도가 둘다 빠른 결과를 볼 수 있습니다.
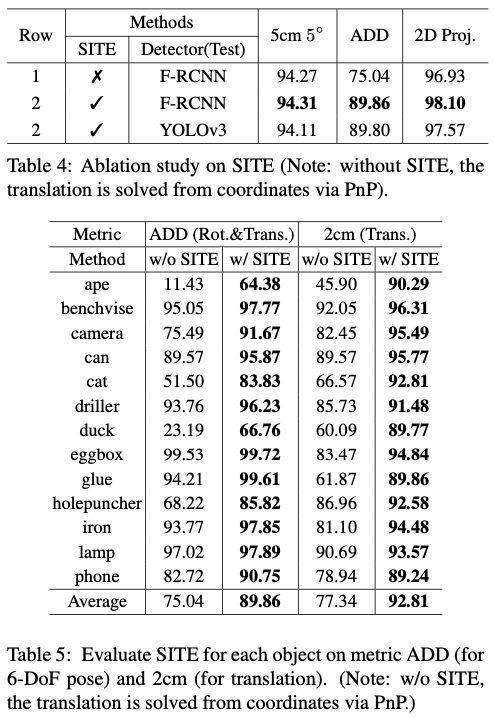
Ablation study로 SITE를 적용하여 표5에서 상당한 성능 향상을 보여주는 것을 볼 수 있습니다.
6. Conclusion
이번 논문에서는 rotation과 translation을 분리하여 coordinate-based 6D pose estimation을 하는 방법을 제안합니다. 좀 더 robust하고 정확하면서 효율적인 pose estimation을 하기 위해 DZI, MCC Loss, SITE을 제안했습니다. 해당 방법은 texture-less 물체이거나 occlusion된 물체에도 다룰 수 있으면서 LINEMOD에서 대표적으로 사용되는 평가 지표에 대해서 SOTA를 달성한 것도 보았습니다. 향후에는 카메라 Locaization과 같은 다른 관련 영역에도 이러한 접근 방식을 적용할 수 있을 것으로 기대합니다.
안녕하세요. 좋은 리뷰 감사합니다.
6D pose estimation을 위한 접근법을 직접적인 접근법, 간접적인 접근법으로 나누어서 이 둘의 한계에 대해서 정리해주셨는데 사실 직접적인 접근법, 간접적인 접근법이 무엇인지 잘 와닿지 않아서 이해하기가 힘든데 예시를 들어주실 수 있을까요?
안녕하세요, 주연님 리뷰 읽어주셔서 감사합니다.
6D pose estimation을 하려면 일반적으로 direct method와 indirect method를 사용하게 됩니다.
Direct method는 이미지에서 딥러닝 신경망을 통해 pixel-wise의 정보를 추출하여 6D pose estimation을 수행하는 방법을 얘기합니다. 예를 들어 앞서 리뷰한 PoseCNN에서 6D pose estimation을 수행하기 위해 2D 이미지와 3D 모델을 사용하는 방법을 얘기할 수 있고 해당 모델을 통하여 객체의 2차원 특징과 3D 모델을 일치시키는 방식으로 pose estimation을 수행합니다.
Indirect method는 이미지에서 특징점을 추출하고 해당 추출된 특징점으로 매칭 알고리즘을 이용하여 6D pose estimation을 수행하는 방법입니다. PnP알고리즘이 대표적인 예시가 될 수 있습니다. 카메라로부터 얻은 2D 이미지상의 특징점과 해당 특징점들에 대응하는 3D 모델 상의 특징점을 사용하여 pose estimation을 수행합니다. 해당 과정을 수행하기 위해서는 우선적으로 카메라의 intrinsic matrix와 같은 파라미터 값들이 필요하게 됩니다.
감사합니다.
좋은 리뷰 감사합니다.
내용적으로 이해하기에 난이도가 높은 것 같네요…
우선 직접적인 접근법과 간접적인 접근법 모두 3d CAD model을 사용하는 것인가요? 그리고 dynamic zoomin(DZI)는 2d coordinate에 대해 수행하고 나중에 2d->3d로 mapping하는 과정이 맞게 이해한 것일까요? zoom in을 할 경우 z정보(depth)가 달라질 수 있을 것 같아서 질문드립니다ㅎ
안녕하세요, 도경님 리뷰 읽어주셔서 감사합니다.
‘우선 직접적인 접근법과 간접적인 접근법 모두 3d CAD model을 사용하는 것인가요?’
→ 네, 둘 다 사용합니다.
‘dynamic zoomin(DZI)는 2d coordinate에 대해 수행하고 나중에 2d->3d로 mapping하는 과정이 맞게 이해한 것일까요? zoom in을 할 경우 z정보(depth)가 달라질 수 있을 것 같아서 질문드립니다ㅎ’
→ 과정에 대해서는 도경님이 이해하신 것이 맞습니다. depth 정보에 대해서 이야기 해보자면, 해당 DZI을 수행하는 이유는 이미지 내에 물체가 작은 경우 해당 물체를 좀 더 잘 검출할 수 있도록 해당 과정을 수행하는 것입니다. 즉, 입력 값이 (x, y, w, h)인 정보를 이용하여 ouput이 bounding box의 offset이므로 box를 잘 치기 위한 수단 중 하나이므로 해당 과정에서는 depth 정보는 필요로 하지 않습니다.
감사합니다.
좋은 리뷰 감사합니다.
해당 논문을 정리해보면 rotation과 translation이 물체의 외관 정보에 영향을 미치는 정도가 다르기 때문에
이 두가지를 나누어(disentangle 하여) 해결해야 하며, 이를 위해 CDPN이라는 네트워크를 제안한 것이 핵심이라 생각됩니다.
Dynamic Zoom In은 detection에 의한 에러의 영향을 줄이기 위해 GT 박스에 랜덤하게 변화를 주는 것으로 이해하면 될까요?? 만약 그렇다면, 부정확한 GT를 주는 것이 detection 모델을 학습시키는 것이 목적이 아니라 pose를 학습하는 것이므로 괜찮다는 의미인지 궁금합니다.
또한, 고정된 크기의 segmentation을 구현하여 객체의 픽셀을 추출한다고 하셨는데, 고정된 크기의 segmentation이 어떤것을 의미하는 지 설명해주실 수 있을까요??
Ablation 파트는 translation에 대한 예측값을 구할 때, 간접적으로 구하는 방법(식 4)과 직접적으로 구하는 방법(식 5)를 비교하여 직접적으로 translation을 구하는 것이 좋다는 것을 보인 것으로 이해하였는데, 실험 결과중에서 어떤 것이 이에 해당하는지 잘 파악이 되지 않습니다. 혹시 실험 결과중 어떤 것을 비교해야 하는 지 다시 설명해주실 수 있나요??
안녕하세요, 승현님 리뷰 읽어주셔서 감사합니다.
‘Dynamic Zoom In은 detection에 의한 에러의 영향을 줄이기 위해 GT 박스에 랜덤하게 변화를 주는 것으로 이해하면 될까요?? 만약 그렇다면, 부정확한 GT를 주는 것이 detection 모델을 학습시키는 것이 목적이 아니라 pose를 학습하는 것이므로 괜찮다는 의미인지 궁금합니다.’
→ 먼저 DZI는 랜덤하게 변화를 주는 것이 아니라 샘플링을 하기 위해 object의 height, width 그리고 coefficient에 의존한다고 논문에 나와있습니다. 해당 coefficient는 샘플링의 range를 제한하는 파라미터로 보입니다. 물체를 좀 더 잘 검출하기 위한 수단 중 하나라고 생각하시면 될 것 같습니다.
‘또한, 고정된 크기의 segmentation을 구현하여 객체의 픽셀을 추출한다고 하셨는데, 고정된 크기의 segmentation이 어떤것을 의미하는 지 설명해주실 수 있을까요??’
→ Section 3.3. Continuous Coordinates Regression에서 다루는 내용으로 고정된 크기를 가지도록 구성한 Coordinate-Confidence Map(H x W x 4)를 의미합니다.
‘Ablation 파트는 translation에 대한 예측값을 구할 때, 간접적으로 구하는 방법(식 4)과 직접적으로 구하는 방법(식 5)를 비교하여 직접적으로 translation을 구하는 것이 좋다는 것을 보인 것으로 이해하였는데, 실험 결과중에서 어떤 것이 이에 해당하는지 잘 파악이 되지 않습니다. 혹시 실험 결과중 어떤 것을 비교해야 하는 지 다시 설명해주실 수 있나요??’
→ fig3(b)를 보시면 T_z의 정확도가 T_x, T_y에 비해 낮은 것을 확인할 수 있는데 이는 스케일에 대해 에 scale factor error가 물체마다 존재하기 때문에 unbalance한 성능을 보이게 됩니다. scale factor error를 피하기 위해 식(5)를 사용했다고 생각합니다.
답변이 도움되셨으면 합니다.
감사합니다.