이번에 가져온 논문은 ICRA2023에 게재된 논문으로, 제가 요새 눈여겨 보고 있는 Masked Image Modeling(MIM) 기반 학습 방식을 Self-supervised Monocular Depth Estimation task에 적용한 논문입니다.
제 개인적으로 MIM을 Depth task에 적용해서 논문을 써보자는 생각을 가지고 있었는데 이번 ICRA2023에 관련 논문이 떡하고 나왔어서 아쉬운 마음도 있었으나, 제가 생각했던 것보다 인상 깊은 결과를 보여주지 못해서 다행?이라는 생각이 들었네요. 해당 논문을 조금 더 자세히 들여다보고 개선해서 좋은 방법론을 만들 수 있지 않을까하여 리뷰로 가져와봤습니다.
Intro
컴퓨터비전 연구를 시작한지 4년이 다 되어가는 상황에서 한 해마다 폭발적인 관심을 받아오는 방법론들이 항상 존재하였으며, MIM은 22년 중 가장 많은 관심을 받아온 방법론 중 하나이지 않을까 싶습니다. 이러한 유행에 발맞춰 빠르게 나온 논문들의 특징을 보면 사실 그 논문의 서론 부분이 지루하다고 느껴질 때가 종종 있습니다. (오리지널 논문에서 주장하는 장점들을 장황하게 늘어놓기 때문일수도 있겠습니다.)
하지만 제가 이번에 읽은 논문의 경우에는 조금 다른 방향으로 문제를 정의하고 이를 해결하기 위해 MIM을 사용하였다는 식으로 접근합니다. 바로 MIM 기반 학습 방식이 Natural or Digital Image corruption에 강건하도록 학습시켜줄 수 있다는 것이죠.
사실 MIM 학습 방식이 입력 영상 속 잡음, 변질 등에서도 모델을 강건하게 동작할 수 있도록 장려한다는 저자의 주장이 어찌보면 당연하다고 보여질 수도 있습니다. 이는 애초에 MIM 학습 방식 자체가 영상 속 특정 영역들을 마스킹한 후 마스킹된 영역에 대해 모델이 추론하는 것이기 때문에, 마스킹을 하는 행위 자체가 영상 자체에 강력한 노이즈로 작동할 수 있기 때문이죠.
그러나 보통 MIM 기반 학습 방식을 새로 제안하거나 혹은 사용하는 논문들은 보통 MIM 학습 방식을 통해 모델의 feature representation이 더욱 향상된다는 것에 초점을 맞추어 설명을 많이 하기 때문에 오히려 Masking 하여 학습하는 방식 자체가 노이즈에 강건한 모델을 만든다 라는 것에 대해 접근하는 것이 나름 재밌게 다가왔습니다.
아무튼 논문의 서론에서 다루는 부분들이 그리 많지 않아서 저도 서론에 설명할 내용이 많지가 않네요. 요약하자면 기존의 깊이 추정 네트워크 쪽 연구들은 잘 가공된, 깔끔한 환경에서의 성능 향상을 목적으로 하지만 실제 자율주행 상황에는 날씨, 모션 블러 등으로 인한 다양한 노이즈 및 변질된 상황이 자주 연출될 수 있기에 이에 강건한 깊이 추정 모델을 만들어야 하며, 자신들은 MIM 학습 방식을 통해 영상 잡음에 강건한 모델을 만들 수 있다고 주장합니다.
그래서 한가지 더 눈여겨 볼 점은, 보통 MIM은 마스킹된 RGB image를 입력으로 넣어서 마스킹된 영역에 대하여 RGB를 Reconstruction 하거나 혹은 상황에 따라 feature token, handcrafted feature(e.g., hog) 등을 복원하여 feature representation의 성능을 높이는데 반해, 본 논문은 실제 target task에 해당하는 Depth Estimation에 곧바로 적용하는 모습입니다. 이에 대한 자세한 설명은 Method 부분에 대해서 다루도록 하죠.
Preliminary
본격적인 방법론 설명에 들어가기 앞서, Self-supervised monocular depth estimation 방법론의 학습 과정에 대해 조금 다루고 넘어가겠습니다. 사실 저랑 한대찬 연구원이 예전에 세미나와 리뷰에서 많이 다루었던 분야이기도 하였는지라 저희의 예전 리뷰들을 참고하면 더 좋겠으나 오랜만에 Self-Sup Depth Estimation 리뷰이다보니 본 리뷰에서도 설명을 하고 넘어가야겠네요.
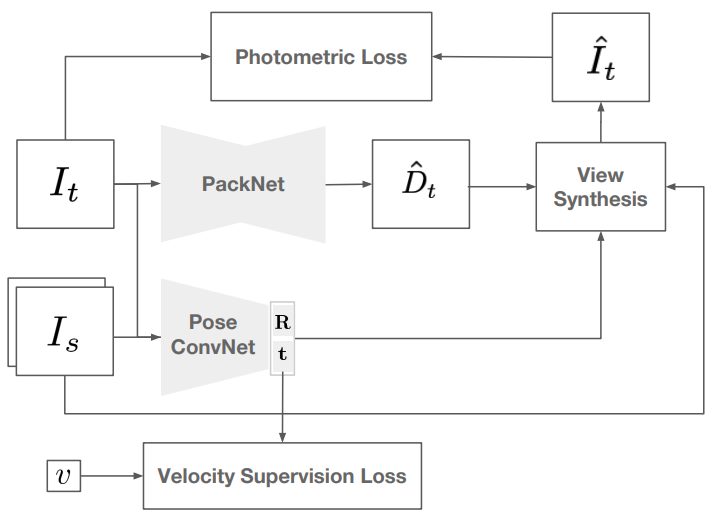
위에 그림 1은 CVPR2020에 게재된 PackNet-SFM이라고 하는 논문의 학습 framework 그림을 가져온 것입니다. PackNet-SFM이 처음 비디오 프레임 기반의 Self-supervised learning 방식을 제안한 것은 아니지만 해당 논문의 그림이 가장 직관적이어서 가져왔습니다.
일단 Self-supervised monocular depth estimation framework은 학습에 사용되는 입력은 무엇인지, 학습해야하는 네트워크는 무엇인지, loss 함수는 무엇인지를 집중적으로 보시면 됩니다.
먼저 학습에 사용되는 입력 영상으로는 하나의 target image와 2장의 source imaeg들이 존재합니다. 이 때 하나의 target image는 현재 frame을 의미하며, 2장의 source imaeg는 target frame의 시간을 t라고 하였을 때 각각 t-1, t+1의 프레임 영상을 의미합니다.
그리고 학습시켜야하는 모델은 크게 2가지로 하나는 깊이 추정 네트워크(PackNet이라고 적혀있는 부분)과 PoseConvNet이라고 하는 PoseNetwork 이렇게 2가지가 존재합니다. 당연히 깊이 추정 분야이기 때문에 Depth Network 부분은 직관적으로 학습해야하는 대상이라는 것을 알 수 있지만 PoseNetwork에 대해서는 의아해하실 수 있습니다.
PoseNetwork의 역할은 target frame과 source frame 영상 사이에 상대적인 카메라 모션을 추정하는 네트워크라고 이해하시면 됩니다. 이는 곧 self-supervised learning의 goal에 대해서 이해하시면 pose network의 필요성에 대해서 훨씬 더 잘 이해하실 수 있을 것입니다.
loss function에 대해서 살펴보면 맨 위에 Photometric loss와 아래 velocity loss가 존재합니다. 사실 velocity loss는 메인 loss가 아니고 Photometric loss가 주된 목적 함수이기 때문에 먼저 Photometric loss을 이해하는 것에 집중하시면 됩니다. Photometric loss는 영상의 오차를 계산하기 위해 SSIM loss와 L1 loss가 특정 비율로 섞여있는 오차함수입니다.
이때 계산되는 대상은 target image와 warped source image 사이에 오차를 계산하게 됩니다. 여기서 카메라 기하학에 대해 공부를 좀 해보시면 쉽게 목적 함수의 구성에 대해 이해하셨을 겁니다. 깊이 추정에서 self-supervised learning 학습 방식은 영상의 깊이 정보와 카메라 외부 파라미터 정보를 알 수 있다면 특정 frame의 영상에서 다른 시간대의 영상으로 변환(warping)을 할 수 있다는 기하학적 특성을 활용해 Lidar 정보 없이 모델을 학습시킬 수 있는 것이죠.
보다 구체적으로는 target frame 영상에 대한 Depth 정보를 계산하고 target frame와 source frame 사이에 상대적인 외부 카메라 행렬을 계산하였다면 target frame에서 source frame으로, 혹은 source frame을 target frame으로 변환을 할 수 있습니다. 따라서 모델 학습 과정 중에 깊이 추정 네트워크 뿐만 아니라 두 영상 사이에 상대적인 카메라 변환 관계를 계산하는 pose network도 함께 학습을 수행하는 것이며, 두 네트워크의 추론 값이 잘 맞을 수록 더 완벽한 warping이 가능하기에 두 frame 사이에 photometric loss(영상의 차이)가 0에 가깝게 될 것입니다.
물론 이러한 학습 방식은 여러가지 단점이 존재합니다. 애초에 이러한 기하학적 가정이 통하기 위해서는 카메라만 움직이고 그 외에 모든 대상은 정적으로 촬영되어야 한다는 제약조건이 존재하며(하지만 보통 자율주행 환경에서는 그런 가정이 많이들 깨지죠) 두 프레임 사이에 occlusion으로 인하여 완벽하게 warping하더라도 loss가 0이 되지 않을 가능성도 있습니다.
그리고 가장 중요한 점은 영상 정보만으로 모델을 학습하였기 때문에 깊이 추정 네트워크가 추론하는 Depth map의 scale 값이 모호해진다는 문제가 존재합니다. 즉 pixel level에서의 상대적인 깊이 추정만 수행할 뿐 실제 해당 정보들을 따로 후처리 해주지 않는 이상 meter 단위로 표현할 수 없다는 의미입니다. 그 문제를 해결하기 위해 PackNet sfm에서는 velocity loss라는 것을 적용하여 scale 모호성을 해결해주려고 하였습니다만 지금 제가 다루고 있는 내용들은 본 논문의 리뷰와는 크게 관계가 없으므로 이정도만 다루고 넘어가겠습니다.
아무튼 요약하자면, Depth estimation 분야에서 비디오 프레임으로 Self-supervised Learning을 수행하기 위해서는 Depth Network 뿐만 아니라 Pose Network도 함께 존재하며 모델 학습에 사용되는 입력들은 총 3장(t-1, t, t+1 frame image)가 있고 Photometric loss를 main으로 학습한다…정도로 볼 수 있습니다. 이러한 개념을 숙지하신 채로 본 논문에서 어떤 방식으로 MIM 기법을 적용하여 모델을 학습하는지 이해하면 될 것 같네요.
Method
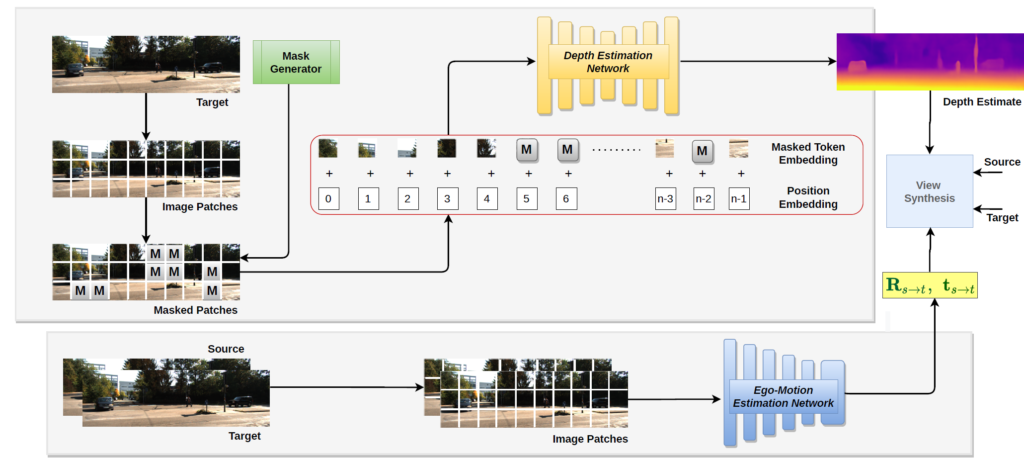
일단 그림2를 살펴보시면 모델이 제안하는 방법론의 흐름에 대해서 알 수 있습니다. 제가 위에서 설명드린 Depth Estimation 분야의 Self-sup learning 방식과 MIM 학습 방식의 흐름에 대해서 잘 알고 계시다면 본 논문의 방법론 자체는 매우 쉽게 받아들이실 수 있습니다.
일단 학습에 사용되는 이미지는 총 3장이라고 했었죠. t-1과 t+1 시간대의 영상을 의미하는 source frame들과 t 시간대의 영상을 의미하는 target frame이 있다고 하였을 때 본 논문은 Depth Estimation network에 입력으로 사용되는 target frame 영상에 대해서만 masking을 적용합니다.
반면에 target frame과 source frame 영상을 함께 입력으로 하는 Pose network(논문에서는 Ego-motion network라고 하는 것)에서는 입력 영상에 대해 어떠한 마스킹 처리를 적용하지 않습니다. 그리고 각각 깊이 맵과 상대적인 카메라 정보를 추론하였다면 이를 통해서 source frame을 target frame으로 변환시켜서 두 영상 사이에 Photometric loss를 계산하게 됩니다.
사실 논문에서 제안하는 방법론은 이게 끝입니다. 학습하는 과정이 너무 간단해서 딱히 드릴 말씀이 없네요. 일단 일반적인 MIM 학습 방식과 본 논문에서 MIM을 적용한 방식의 차별점에 대해서 조금 더 정리를 하고 바로 실험 섹션으로 넘어가야할 것 같습니다.
제안하는 MIMDepth가 기존의 MIM 방법론과 비교하였을 때 큰? 차별점은 다음과 같습니다.
- Masked Image에 대해 모델이 추론하는 결과는 RGB 영상이 아닌 Depth map을 추론합니다. 일반적으로 MIM은 Down Stream task 학습에 사용하기 전 모델의 좋은 weight을 구하기 위한 pre-training 기법으로써 masked rgb imaeg를 입력으로 하여 마스킹된 영역 대응되는 RGB 영상을 복원하는 방식으로 모델을 학습시킵니다.
하지만 본 논문의 목표는 변질된 영상에 대해서도 강건하게 깊이 추론이 가능한 깊이 추정 네트워크를 학습시키는 것이기 때문에 일반적인 MIM 방식처럼 마스킹된 RGB 영상을 복원하는 방식으로 사전 학습 후 Depth Estimation에 대해 fine-tuning하게 될 경우 모델은 image corrpution에 강건한 특성은 잊어버린 채 깊이 추정에만 포커싱을 두고 학습이 된다고 주장합니다.
즉 저자는 입력 영상에 대해 마스킹이 존재한 상황에서 깊이 추정을 수행해야 imaeg corrpution에 강인한 방향으로 네트워크를 학습시킬 수 있기에 마스킹된 영상에 대해서 곧바로 Depth를 Prediction하는 방향으로 학습을 수행하게 됩니다. - 이러한 관점에서, MIMDepth의 경우에는 Masking Ratio의 비율이 25% 수준으로, 75% 수준의 마스킹 비율을 활용하는 기존의 MIM 방법론들과 비교하여 Masking Ratio의 비율이 상당히 낮습니다. 아무래도 RGB 영상을 입력으로 넣고 RGB 영상을 복원하는 AutoEncoder 형식의 학습 방식은 입력과 출력 사이에 도메인 차이가 전혀 없기 때문에 상당히 쉬운 task에 속하게 됩니다.
따라서 마스킹 비율을 크게 높여서 모델이 학습하고자 하는 문제의 난이도를 크게 높여야 모델이 조금 더 의미론적인 부분들을 잘 학습할 수 있는 것이죠.
반면에 MIMDepth의 경우에는 영상 도메인을 입력으로 하여 Detph 도메인으로 변환을 하는 과정이기 때문에 풀고자 하는 문제가 상대적으로 상당히 어려운 축에 속합니다. 이러한 관점에서 영상의 마스킹 영역을 크게 높여버리게 될 경우 풀고자 하는 문제가 너무 어렵기 때문에 모델이 전혀 학습하지 못하고 성능이 크게 감소하는 것이 아닐까 생각이 듭니다. - 그리고 MIMDepth의 경우에는 마스킹된 영역에 대해서만 loss를 계산하는 기존 MIM 방법론과 달리 마스킹이 되지 않는 영역에 대해서도 loss 계산을 합니다. 이는 2번과도 유사하게 연계되는 것으로 영상 내에서 마스킹이 된 영역의 비율이 25% 수준으로 매우 낮기 때문에 기존의 MIM 방법들처럼 마스킹이 된 영역에 대해서만 loss를 계산하면 영상 속 loss가 계산되는 영역이 매우 적어 모델 학습에 부정적인 영향을 끼치게 됩니다.
그리고 애초에 task 자체는 입력 영상에 대하여 픽셀 레벨 수준의 촘촘한 깊이를 추정하는 것이 가장 큰 목표이기 때문에 마스킹이 되지 않은 영역에 대해서도 올바르게 loss를 계산해야 모델이 깊이 추론을 더 잘할 수 있겠죠. 반면에 기존 MIM은 방법론들은 입력 영상에 대해서 출력이 입력 영상과 동일하게 나오도록 하는 것이기 때문에 마스킹이 안된 영역에 대해 loss를 계산해봤자 x 넣어서 x를 만들어내는 매우 간단한 문제로 귀결되기에 학습에 사용할 필요가 없습니다.
이 정도로 본 논문의 학습 과정을 정리할 수 있겠네요.
Experiments
그럼 마지막으로 실험 섹션에 대해서 다루고 리뷰 마치도록 하겠습니다. 먼저 본 논문에서는 반복적으로 말씀드리다시피, 다양한 변질 환경에서도 깊이 추정을 강건하게 수행하는 것이 목표이기 때문에 이와 관련된 실험 세팅들에 대해 간략히 말씀드리겠습니다.
기본적인 실험 환경으로는 KITTI Dataset을 활용하여 학습 및 평가를 진행하였으며, 학습 모델로는 CNN의 대표격 모델인 Monodepth2 방법론과, 3D Conv layer를 가지는 PackNet-SFM, 그리고 Transformer 기반 방법론인 MT-SfMLearner를 활용하여 실험을 진행합니다.
아무래도 깊이 추정 방법론은 영상을 warping하여 학습을 수행하기 때문에 pytorch의 grid sampling이라는 기법을 활용하게 되는데 해당 기법을 적용하게 되면 seed를 고정했다 하더라도 랜덤성이 발생하게 됩니다. 그래서 본 논문의 실험 결과에서는 3번의 반복적인 학습을 통해 RMSE 평균 값을 정량적 성능으로 리포팅합니다.
Natural Corruption에 대한 강건성: 먼저 Natural Corruption에 대한 정량적 성능부터 살펴보시죠. 저자는 Natural Corruption에 대한 정의로 gaussian noise, motion blur, weather, digital corruption으로 구분지었으며, 이에 대한 정량적 성능은 그림3 제일 좌측에서 확인이 가능합니다.
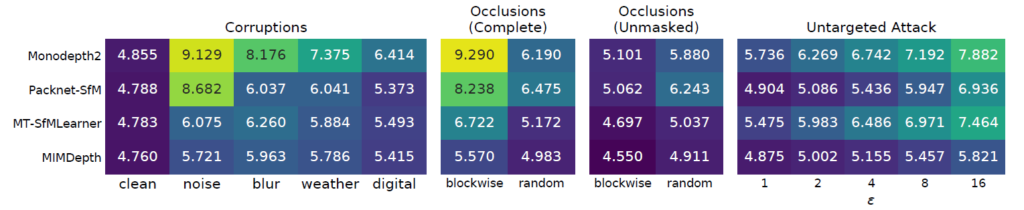
일단 그림-3 좌측 그림 중에서도 제일 좌측의 Clean은 아무런 noise를 넣지 않았을 때 상황으로, 이 경우에는 MIM Depth가 가장 성능은 좋지만 사실 성능의 차이가 소수점 0.02 수준이라 매우 미미합니다. 하지만 gaussian noise와 motion blur 등의 환경에서는 MIM Depth의 성능이 타 방법론과 비교하여 상대적으로 더 큰 폭의 향상이 존재합니다. 하지만 digital에 대해서는 또 packnet-sfm보다 좋지 못한 결과를 보여줌으로써 아쉬운 경향을 보입니다.
Occlusion에 대한 강건성: 다음으로는 occlusion 상황에 대한 강건성 여부에 대해 알아보겠습니다. 저자는 occlusion 상황을 가정하기 위해 단순히 test image에 masking을 수행한 후 이에 대한 RMSE를 계산하였습니다. 저자는 MIM 학습 기법에서 활용하는 마스킹 처리 방식인 blockwise와 random 각각 2가지 마스킹 처리 방식에 대한 정량적 결과를 그림3 중앙에 배치합니다.(참고로 마스킹 비율은 학습 때와 동일하게 25% 비율입니다.)
Occlusion에 대하여 실험 결과가 2가지인데 먼저 Complete는 영상 전체에 대한 정량적 지표를 의미한 것이며, Ummasked는 마스킹이 안된 영역 부분만 평가한 결과를 의미합니다. 확실히 occlusion 상황에 대해서는 제안하는 논문의 성능이 가장 좋은 결과를 보여줍니다.
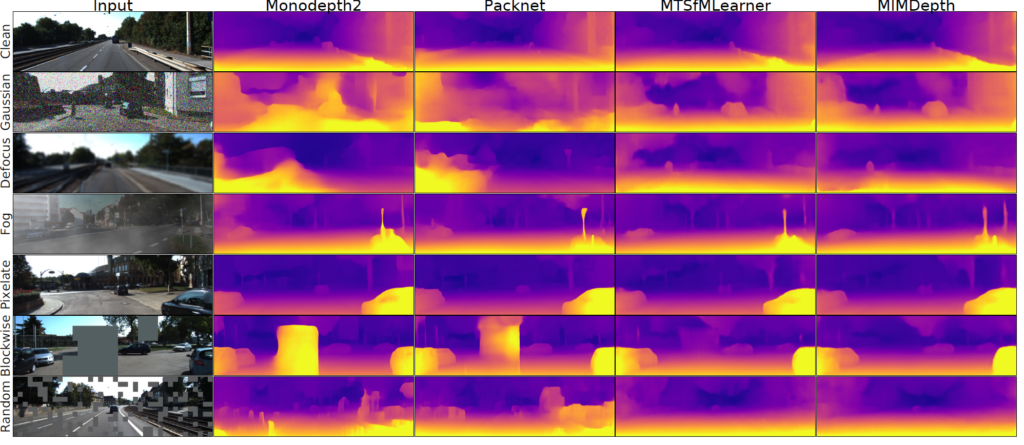
다만 blockwise와 random masking 비율에 따라 성능의 폭이 좀 커지는데 이는 random masking의 경우 밑에 정성적 그림에서도 보시면 아시겠지만 영상 전반에 걸쳐 국소적으로 나타나는 반면에, blockwise masking의 경우에는 영상 일부에 전역적으로 마스킹이 되는 것을 확인할 수 있습니다. 이러한 차이에 따라 성능 차이도 크게 발생하는 것으로 보입니다.
하지만 사실 이 실험 결과가 좋다고 해서 막 흥미롭고 대단하다는 생각은 조금 덜 드는 것이 결국 MIMDepth의 경우에는 학습 때 이러한 마스킹된 영상을 입력으로 받아서 학습을 쭉 수행했기 때문에.. 당연히 타 방법론들과 대비하여 좋은 성능을 보일 수 밖에 없게 됩니다. 그리고 저자는 마스킹된 영역에 대해 영상 전체에 대한 픽셀 평균 값으로 대체하여서 최대한 blackout 상황이 아닌 실제 occlusion 상황처럼 만들려고는 했으나 결국엔 이 또한 완벽한 occlusion 환경이 아니라는 점에서 아쉽게 느껴집니다(물론 실제로 occlusion 환경 자체를 만들기는 어렵긴 하지만요..)
그 다음으로는 adversarial attack에 대한 실험을 진행하는데, 해당 부분에 대해서는 제가 관련 개념이 부족해서 아무리 읽어도 실험 방식 및 의도를 잘 모르겠더군요. 추후에 관련 자료를 읽으면서 내용을 보충해야할 것 같습니다.
정량적 실험
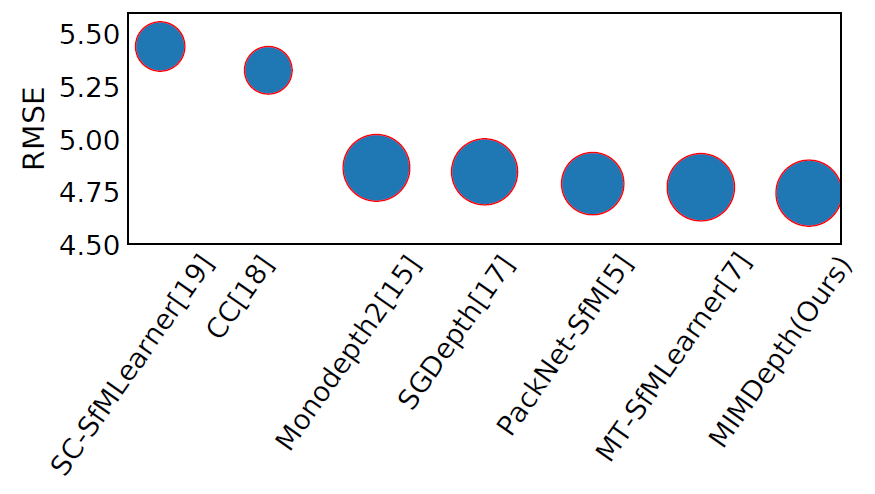
다음은 일반적인 clean 상황에서 타 방법론과 MIMDepth 간에 정량적 성능을 비교한 결과입니다. 사실 제가 생각했을 때 본 논문의 가장 큰 약점이라고 생각되는 부분이 clean 상황에서 MIMDepth의 성능 향상이 매우 적다는 것인데 그래서인지 정량적 실험 결과도 표 형식으로 안보여주고 저렇게 plot해서 애매하게 보이도록 하더군요.(상당히 당황..)
아무튼간에 저자는 y축은 RMSE에 대한 성능, scatter의 너비는 delta accuracy(값이 클수록 좋음)에 대한 것을 나타냈다고 하는데, 저런식으로 보여주면 솔직히 타 방법론과 비교해서 본 논문의 성능이 얼만큼 좋은지 어떻게 알까요.. 일단 자기들이 좋다고는 하는데 그래봤자 RMSE 소수점 0.02 정도 꼴로 매우 미미할 것이며 Depth 분야에서는 Abs_rel과 같은 다른 평가지표들도 있는데 해당 지표를 보이지 않는 것으로 보아 성능이 더 낮은 것으로 판단됩니다. 그리고 Delta에 대한 지표 역시 scatter의 너비로 표현했는데 너비가 다 똑같아 보여서 누가 더 좋다고 하기도 애매하네요.
Ablation study
다음은 ablation study에 대한 결과입니다.
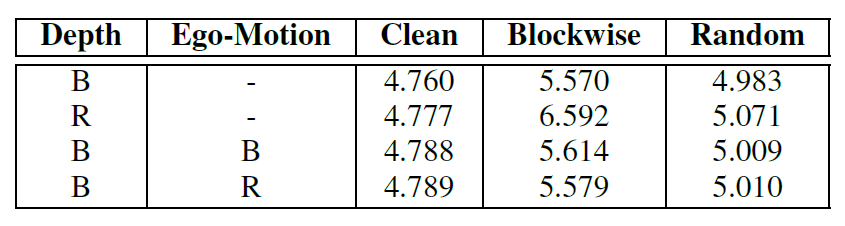
위에 표는 Depth Network와 Ego-motion Network에 대해 각각 Block-wise masking, random-masking을 어떻게 처리하는지에 대한 결과를 나타낸 것입니다. 결론부터 말씀드리면 Depth network에 대해서만 Block-wise masking을 하는 것이 가장 좋았다고 합니다. Clean에서는 사실 성능 차이가 그리 크지는 않지만 Blockwise와 같은 occlusion 환경에서 block-wise로 학습한 모델이 정량적 성능이 더 높기에 이를 채택한 것 같습니다.(사실 당연한 결과겠지요)
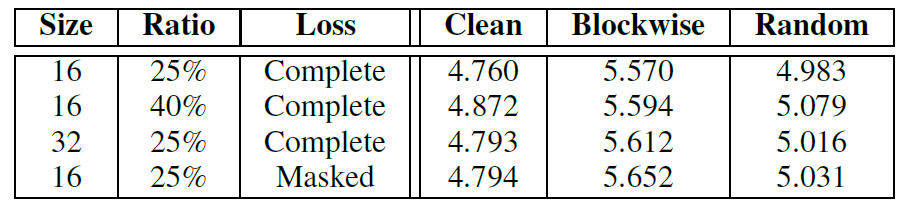
다음은 mask ratio, size, 학습 때 loss를 계산하는 영역등에 대한 ablation study 결과입니다. 가장 먼저 ratio를 살펴보면 40% 비율보다는 25% 정도의 비율로 학습을 하는 것이 가장 성능이 좋았으며, Size에 대한 실험에서는 32보다 16으로 수행하는 것이 조금 더 좋은 성능을 보여줍니다.
그리고 masking된 영역에 대한 loss 계산 보다는 영상 내 전체 영역에 대하여 photometric loss를 계산하는 것이 Clean, Blockwise, Random 상황에서 가장 좋은 정량적 지표를 달성했다고 합니다. 근데 성능의 향상이 다 RMSE 0.1 미만 수준이라서 이거 참.. 아쉽네요.
결론
사실 이 논문을 보면서 처음 서론은 흥미로웠지만, 실험 세팅에 대해서는 상당히 아쉽고 별로라고 생각되는 부분이 많았습니다. KITTI Dataset뿐만 아니라 DDAD, M3D 등등 다양한 Depth Estimation 셋에서 일반화적인 성능을 보여주면 좋았을텐데 그런 실험들도 없었으며, 방법론 자체도 너무 단순합니다.(물론 MIM 기법 자체가 다 그렇긴 하지만.. 적어도 실험의 양이 부족했으면 본인들의 contribution을 더 넣었으면 좋았을텐데 그것도 아니고, 실험이 많은 것도 아닌 참으로 애매합니다.)
게다가 마지막으로 성능의 향상 폭이 너무나도 미미하였기 때문에, 한번 더 아쉬움이 느껴지는 논문이었습니다. 저자들도 그것을 의식했는지 table로 성능을 보여주는 것이 아니라 scatter 형식으로 성능을 보여주는 것이 참으로 씁쓸하네요.
그럼에도 불구하고 해당 논문이 ICRA에 붙을 수 있었던 이유는, MIM 기반 방식을 처음 Self-SUP Depth Estimation에 적용하기도 하였으며, 게다가 이러한 학습 방식이 다양한 robustness 상황에 강건하게 동작할 수 있다라는 가능성을 보여주었기에 그 부분이 리뷰어들에게 매력적으로 다가오지 않았는가 싶습니다.
저자의 주장대로 현재 Self-Sup Depth Estimation 분야는 Clean 환경에 대해서 성능 쪼이기에 너무 혈안이 되어있긴 하거든요. 저도 이쪽 분야에 대해 논문을 쓰면서 성능 향상에 목 매달린 적이 있었기도 했구요. 그래도 이 논문이 아쉬운 것은 한두가지가 아니니 해당 논문을 참고해서 추가 연구를 더 해볼만할 것 같습니다.
리뷰 잘 읽었습니다.
우선, 본 논문의 내용과는 직접적으로 관련이 없긴 한데 packnet 에서 velocity loss를 통해 scale 의 모호성을 어떤 식으로 해결하였는지 간략하게 설명해 주실 수 있나요? 제가 해당 부분에 대해 정확하게 잘 알지 못하는데, 제대로 알아보고 싶어서 이렇게 여쭤봅니다!
그리고, 본 논문에서 저자의 언급도 그렇고 본 리뷰 마지막에서도 그렇고 clean한 환경이 아닌 특정 노이즈가 있는 환경에 대해서 초점을 잡은거 같긴 한데 이는 무엇을 통해서 해결을 했다고 보면 될까요? input image에 masking을 씌우는 행위를 noise 부여로 보고 이를 통해 noise가 존재하는 상황에서 더 강건하게 모델이 학습되었다고 보면 되는것인가요 ??
마지막으로 별로 중요한 말은 아닌데 리뷰에서 언급하신 것 처럼 contribution이 확실히 타 논문대비 부족하다고 느껴지긴 하네요..최초라는 타이틀이 중요하긴 한가 봅니다. .ㅎㅎ