안녕하세요 ! 두번째 x-review 입니다. 팀에서 mmdetection task를 수행하며 CenterNet의 코드에서 막히는 부분이 있어 논문을 읽어보다 이렇게 x-review까지 쓰게 되었습니다.
시작하기에 앞서 본 논문은 CornerNet이라는 논문의 후속작으로 제가 CornerNet에서 필요한 부분을 언급하며 작성하였지만 부족한 부분들이 있을 수 있으니 CornerNet과 관련된 내용은 정민님과 혜원님의 리뷰를 참고해주시면 감사하겠습니다 !
그럼 리뷰 시작하겠습니다.

Introduction
Object detection의 대표적인 방법으로 anchor-based 방법론들이 있습니다. 모두가 알고 계시듯이 anchor-based는 미리 정해진 사이즈의 박스를 통해서 object detection 하는 것이죠. 그러나 anchor-based method에 대해 논문에서는 다음과 같이 지적합니다.
- GT box와의 높은 IOU를 가지는 box들을 충분히 보장하기 위해서 많은 수의 anchor box가 필요합니다.
- anchor box를 유동적으로 바꿀 수 있는 것이 아니라 정해진 size와 aspect ratio를 가집니다.
저자는 이러한 문제점들을 해결하기 위해 이전에 CornerNet이라는 방법론을 제시하였습니다. CornerNet은 두 개의 keypoint를 사용하여 object를 detection하는 방식으로 당시 one-stage detector 중 SOTA를 달성한 방법론이지만, CornerNet 역시 아쉬운 부분이 존재했습니다. object가 한 쌍의 corner로 detection이 되기 때문에 object의 어떤 전체적인 정보를 활용하는 것이 제한적입니다. 또한 한 object당 그룹화 되어야 하는 두 개의 keypoint 쌍을 제대로 알지 못하고 object의 boundary만을 민감하게 감지하는 경향이 있어 결과적으로 부정확한 bounding box를 많이 생성하게 됩니다.
CornerNet의 이러한 점들을 보완하기 위해 제시한 것이 바로 본 논문의 방법론인 CenterNet 입니다. CenterNet에서는 CornerNet에 keypoint를 하나 더 추가적으로 사용하는데, 그 keypoint는 geometric center와 가까운 center point로 생각할 수 있습니다. 해당 centerpoint를 통해 기존 한 쌍의 corner로 생성한 region에서 중심 정보를 사용할 수 있게 됩니다. 예를 들어, 만약 GT box와 높은 IOU를 가지는 bounding box라면 center keypoint 역시 GT box와 같은 class를 가질 확률이 높을 것이라는 확률적 측면으로 추가적인 정보를 사용할 수 있게되는 셈이죠. 기존의 corner로 bounding box 내부의 정보를 제대로 사용하지 못했던 CornerNet의 단점을 보완하고자 한 것 입니다. 논문에서는 두 개의 corner와 하나의 center의 정보를 최대한 풍부하게 사용할 수 있도록 두 가지 전략을 제시하였습니다. center point를 예측하는데 사용하는 center pooling과 CornerNet의 corner pooling을 보완한 cascade corner pooling으로 각각의 방법에 대해서는 뒤에서 더 자세하게 다루도록 하겠습니다.
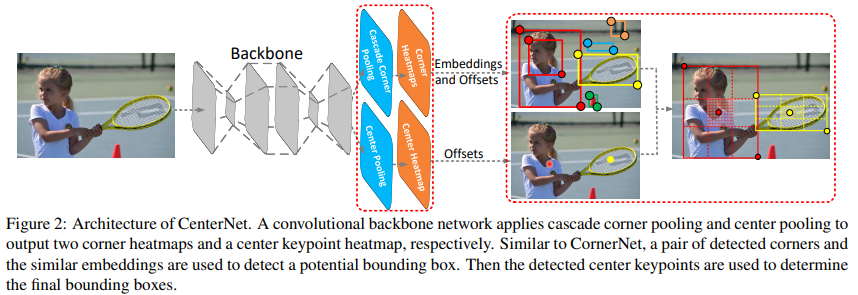
Our Approach
Baseline and Motivation
위에서도 언급했듯이 CenterNet은 CornerNet을 baseline으로 사용합니다. CornerNet은 top-left corner와 bottom-right corner 두 개의 corner point에 대해 각각 heatmap을 생성하는데, heatmap은 각 keypoint에 대한 confidence score와 location 정보를 가지고 있습니다. 다음으로 embedding과 offset을 예측하게 되는데, embedding은 두 개의 corner가 있을 때 같은 object를 가리키고 있는 corner가 맞는 것인지 확인하기 위해 사용되고 offset은 heatmap에서 input image로 복원시킬 때 corner을 input image 사이즈에 맞게 remapping 할 수 있기 위해 사용합니다.
CornerNet의 동작과정을 간략하게 생각해보면 다음과 같습니다. 우선 주어진 corner들 중에서 상위 k개의 top-left corner와 bottom-right corner을 heatmap의 confidence score을 사용해서 선택합니다. 그럼 k개씩 존재하는 top-left corner와 bottom-right corner 쌍들 중 서로 같은 object를 가리키고 있는 point가 무엇인지 선별하기 위해서 embedding vector의 거리를 계산하게 됩니다. 만약 vector의 거리가 미리 정한 threshold보다 작다면 가까운 거리에서 같은 object에 속해있는 corner라고 판단하여 일종의 bounding box를 만들 수 있습니다. 이렇게 만들어진 bounding box는 두 keypoint의 heatmap에서 기존에 가지고 있던 confidence score의 평균이 되는 값을 confidence score로 가집니다.
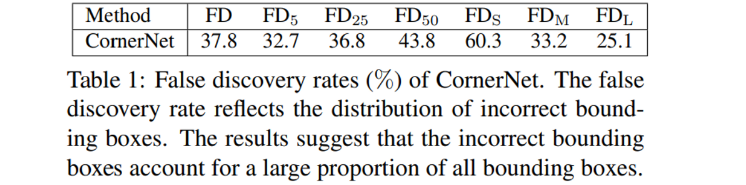
기존 CornerNet의 문제점을 강조하기 위해서 MS-COCO validation dataset에 대한 False discovry rate를 보여주고 있는데, FP의 비율이 얼마나 되는 것인지와 비슷한 의미로 봐주시면 될 것 같습니다. introduction에서 언급했던 부정확한 bounding box가 많이 발생한다는 점을 보여주고자 Table 1을 통해 정량적으로 증명하고자 했던 것 같네요. 실제로 IOU의 Threshold를 낮게 설정했을 때 조차 모든 bounding box 중에 잘못 만들어진 bounding box의 비율이 크다는 것을 보여줍니다. 예를 들어 IOU를 0.05로 설정한 경우에도 FD rate가 32.7%에 도달하게 됩니다. 결국 100개의 bounding box가 만들어졌다고 가정하면 GT Box와 IOU가 0.05도 되지 않는 bounding box가 30개 이상 존재한다는 것이죠. 이를 통해 말하고 싶은 것은 CornerNet은 박스의 boundary를 치는 것에 초점이 맞추어져 있어 정작 bounding box 안의 의미있는 정보들을 잘 사용하지 못한다는 것 입니다.
CenterNet이 아니고서라도 CornerNet을 two-stage detector 구조로 ROI Pooling을 활용하면 bounding box 내의 시각적 패턴을 사용할 수 있을 겁니다. 하지만 one-stage detector 구조인 CornerNet을 two-stage detector로 바꿔서 사용한다는건 cost가 너무 큰 일이기 때문에 computational cost를 최소화하는 효율적인 방식으로 제시하는 것이 바로 CenterNet 입니다. two-stage detector로 구조 자체를 바꾸는 것이 아니라 center point를 추가적으로 도입하여 ROI Pooling의 기능적인 장점은 그대로 구현할 수 있게 됩니다. 즉 논문에서 강조하는 것은 centerpoint 정보를 사용하고, 그 과정에서 발생하는 cost가 최소화된다는 점 입니다.
Object Detection as Keypoint Triplets
이제 부정확한 bounding box를 필터링 시키기 위해서 center keypoint를 활용하는 과정을 순서대로 살펴보자면 다음과 같습니다.
- 기존 CornerNet에서의 corner point와 동일하게 center keypoint의 heatmap을 만들고 offset을 예측합니다.
- confidence score가 높은 상위 k개의 center point를 선택합니다.
- 예측한 offset을 사용하여 선택된 center keypoint를 input image size에 맞게 remapping 합니다.
- 각각의 bounding box에 대한 중심 지역을 정의하고 정의한 중심 지역에 center keypoint가 위치해 있는지를 확인합니다.
- 만약 중심 지역에 존재한다면 bounding box를 유지하는 것이고, 존재하지 않는다면 bounding box를 제거하면 됩니다. 여기서 center keypoint를 사용하는 이유가 bounding box 내의 정보 또한 활용하기 위해서이니, center keypoint의 class label이 GT box의 class label과 동일하지 않다면 이러한 경우 역시 bounding box를 제거해주어야 합니다.
살펴본 CenterNet 동작 과정에서 “중심 지역을 정의한다”라는 말이 나오는데, 그렇다면 중심 지역이라는 것은 어떻게 정의하는 것일까요?
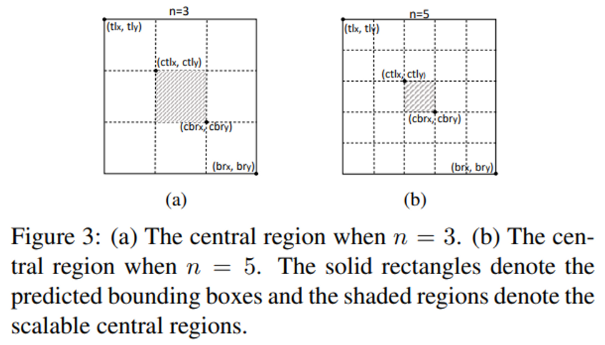
중심 지역의 크기는 detection 결과에 영향을 미칩니다. 예를 들면, 만약 중심 지역의 크기가 작다면 small object에 대한 recall 결과가 좋지 않을 것이고, 중심 지역을 크게 설정한다면 large object에 대한 pecision이 낮아진다고 저자는 얘기하고 있습니다. 이 부분이 사실 정확하게 와닿지 않지만 .. 만일 중심 지역을 작게 설정한다면 그 안에 들어갈 center point 크기 또한 작아져 detection 할 확률이 작아진다는 것이고 반대로 중심 지역이 크다면 center point의 크기가 커져 잘못된 예측을 하더라도 맞다고 판단하게 되어 precision이 낮아지는 것이 아닐까 추측해봅니다.
그래서 중심 지역을 적절하게 잘 정의하기 위해서 scale-aware central region 방식을 제안합니다. 윗 문단에서 언급한 성능 저하를 방지하기 위해서 large object에 대해서는 중심 지역을 작게 설정하고, small object에 대해서는 큰 중심 지역을 정의하는 방법 입니다.
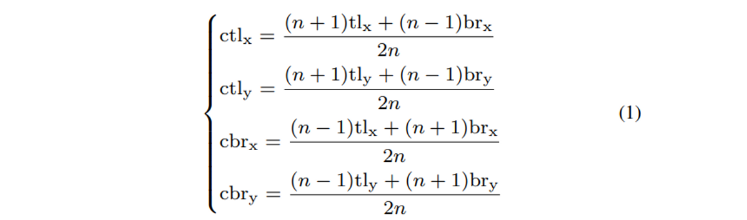
tl_x, tl_y : top-left corner의 x, y 좌표
br_x, br_y : bottom-right corner의 x, y 좌표
ctl_x, ctl_y : 중심 지역 top-left corner의 x, y 좌표
cbr_x, cbr_y : 중식 지역 bottom-right corner의 x, y 좌표
n은 중심 지역의 크기를 결정하는 홀수 정수 입니다. 논문에서는 figure3에서 볼 수 있듯이 3과 5를 사용하였습니다. bounding box를 n x n으로 나누는 것을 나타내고 n이 커질수록 중심 지역의 크기가 작아지는 것으로 보아 bounding box가 커질수록 n의 크기를 크게 설정해야 할 것 같네요. 결국 식(1)의 관계식을 만족하는 scale-aware한 중심 지역을 결정할 수 있습니다.
Enriching Center and Corner Information
저자는 추가적으로 사용하는 center point와 기존의 corner point로 얻은 정보를 좀 더 유의미하게 사용하기 위해서 2가지 방법을 제시하였습니다.
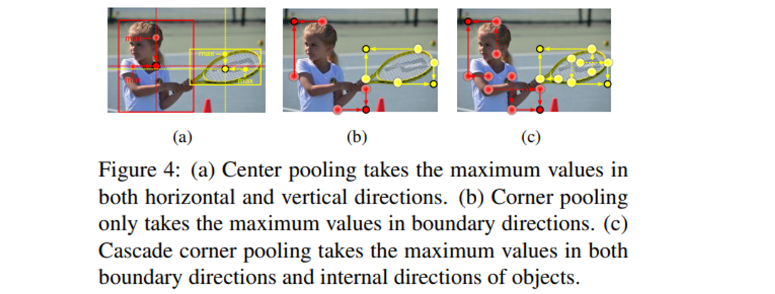
Center pooling
center point를 통해 box 내의 정보까지 활용하려는 시도는 좋았지만, 과연 center point로 얻은 정보가 항상 유의미한 것일까요 ? 사람을 detection할 때 center point로는 보통 사람의 몸 중간 부분을 가리키겠지만 사실 강력한 특징이라고 함은 사람의 머리라고 할 수 있듯이 center point의 정보가 항상 강력한 시각적 패턴을 전달할 수 있는 것은 아닙니다. 그렇기 때문에 더 풍부한 시각적 패턴을 활용한 center point를 얻고자 center pooling을 사용합니다.
center pooling은 backbone을 거쳐 생성된 feature map에서 center keypoint가 어디에 위치해 있는지 결정하기 위해서 물리적인 center에 위치한 값만을 사용하는 것이 아니라 Figure 4(a)처럼 수평과 수직 방향의 최댓값을 찾아서 더해줌으로써 좀 더 의미있는 center point를 찾고자 합니다.
Cascade corner pooling
CornerNet에서 박스 내의 정보를 사용하지 못한다는 단점이 존재한다고 반복적으로 이야기하고 있지만, 사실 CornerNet에서도 그러한 문제를 해결하기 위해서 corner pooling을 제안했었습니다. Figure 4(b)가 CornerNet에서의 corner pooling 방식을 그림으로 나타낸 것으로 corner을 결정할 때 경계선 방향으로 최댓값을 찾고 있습니다. 하지만 그림에서 직관적으로 이해할 수 있듯이 오히려 edge에 민감하게 반응한다는 단점을 더 부각시키는 방법이 아닌가 생각이 듭니다. 그래서 corner pooling을 그대로 사용하지 않고 Cascade corner pooling으로 발전시켜 사용합니다. 기존의 corner pooling이 boundary 내에서의 최댓값만을 찾았다면, cascade corner pooling은 마찬가지로 boundary에서 최댓값을 찾는 것까지는 동일합니다. 그러나 최댓값이 존재하는 경계 픽셀에서 boundary 내부 방향으로 탐색했을 때의 최댓값까지 활용한다는 점이 차이점이라고 할 수 있습니다. 결국 하나의 top-left corner을 결정짓기 위해 총 4개의 최댓값이 사용되는 것 입니다.
Training and Inference
Training
본 논문의 Loss는 CornerNet의 Loss를 그대로 사용하고 있습니다. 그래서 간략하게 각각의 Loss가 어떤 역할로 사용되는지 정도로만 알아보고자 합니다.
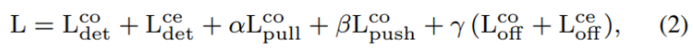
L_{det}^{co}와 L_{det}^{ce}는 corner와 center keypoint의 heatmap을 예측하는 Loss로 Focal Loss를 사용합니다. L_{pull}^{co}는 corner point에 대한 pull loss로 embedding에 사용하는 loss 입니다. 같은 object에 속하는 embedding vector의 거리를 최소화하기 위해 사용됩니다. L_{push}^{co}는 마찬가지로 corner의 embedding에 사용하는 Loss인데 pull loss와 반대로 다른 object에 속하는 embedding vector의 거리를 최대화 합니다. L_{off}^{co}와 L_{off}^{ce}는 각각 corner와 center keypoint의 offset을 예측하기 위해 단순히 L1 Loss를 이용합니다.
Inference
Inference에서는 soft-nms를 사용하여 불필요한 bounding box를 제거해줍니다. 논문에서는 confidence score에 따라 상위 100개의 bounding box를 선택하여 사용한다고 합니다.
Experiments
MS-COCO Dataset로 실험을 진행하였습니다.
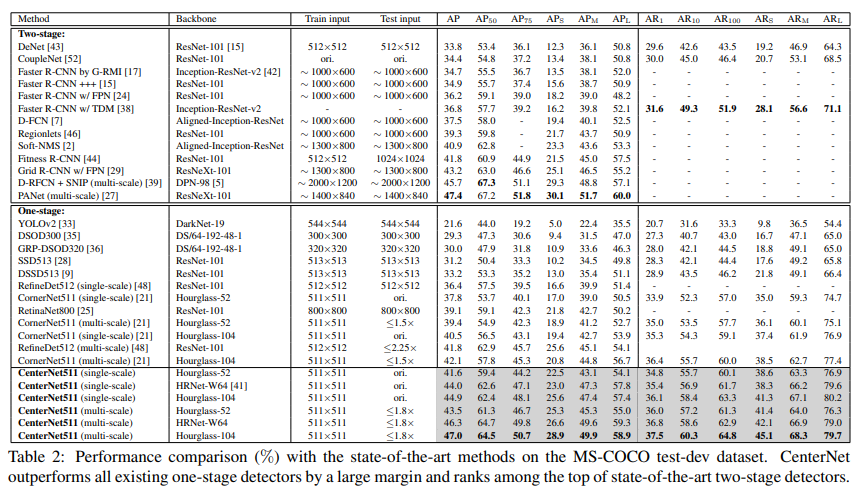
의미있게 본 부분은 small object에 대한 성능 향상으로, CenterNet511-52의 경우 small object의 AP가 single-scale에서 5.5%, multi-scale에서 6.4% CornerNet 대비 향상한 것을 볼 수 있습니다. 저자는 이러한 성능 향상에 대해 small bounding box의 중심 지역을 scale-aware하게 지정하였기 때문이라고 이야기합니다.
Incorrect Bounding Box Reduction
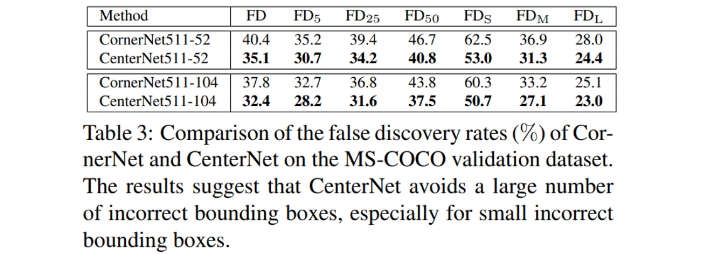
해당 Table 3은 CornerNet과 비교하여 CenterNet에서 설정하는 scale-aware한 중심 지역이 부정확한 bounding box를 줄이는데 효과적인지 보여주고 있습니다. CornerNet에 비해 FD rate가 줄어든 것을 확인할 수 있습니다.
Inference Speed
또 하나 저자는 CornerNet은 cost가 최소화되는 방향으로 CornerNet의 단점을 보완한 method라고 강조 했었습니다. 그래서 NVIDIA Tesla P100 GPU라는 동일환 환경에서 inference time을 측정해본 결과,
CornerNet511-104 : 300ms per image
CenterNet511-104 : 340ms per image
CornerNet이 오히려 inference time이 빠르다는 결과가 나왔다고 합니다. 대신 backbone을 바꿔서 CenterNet511-52로 측정해보면 270ms inference time이 나와 CenterNet511-104보다 더 빠르고 정확해졌다고 하지만 .. 동일한 backbone을 사용하지 않은 두 개의 모델을 비교하는 것이 의미있는 것인지 의문이 들긴 합니다.
Ablation Study
논문에서 새롭게 제안한 central region, center pooling, cascade corner pooling에 대해 각각 성능 향상에 얼마나 영향을 주는지에 대한 실험 결과 입니다.

방법을 하나씩 추가할 때 마다 성능 하락 없이 모든 부분에서 성능이 향상되고 있습니다. 다만 center point라는 새로운 keypoint를 적용한 것이 논문의 contribution인데 central region과 cascade corner pooling를 단독으로 적용했을 때의 성능만 기재되어있고 center pooling을 단독으로 사용한 성능은 공개하지 않은 점이 아쉬운 것 같습니다.
좋은 리뷰 감사합니다.
cornernet에 추가로 center point를 예측하여 좀 더 정확한 object 검출을 시도했네요. 설명을 잘해주셔서 술술 잘 읽히는 리뷰였습니다:) 마지막 ablation study에서 center point를 적용한것이 본 논문의 keypoint이며 center pooling을 단독으로 사용한 성능을 공개하지 않아 아쉽다고 하셨는데, 제가 이해하기로는 이미 center point를 구한 후에 central region을 적용하여 해당되는 영역안에 keypoint가 존재하는지 확인하는 것 같아서 center point를 적용하는 것과 center pooling을 단독으로 적용하는 것과는 큰 연관이 없는 것 같은데 제가 이해한게 맞나요? 그리고 추가적으로 occlusion이 심한 경우 예측한 object center가 어떤 corner 쌍에 속하는지 어떻게 판단할 수 있는지에 대한 내용도 논문에서 다루고 있나요?
감사합니다.
안녕하세요 ! 댓글 감사합니다.
center pooling은 center point의 값을 정할 때 수평과 수직 방향으로 최댓값을 구하여 더해주는 방식으로 제가 마지막 ablation study에서 cascade corner pooling을 나머지 방법을 적용하지 않고 단독으로 적용한것처럼 center pooling 또한 수평과 수직 방향의 최댓값을 더해주지 않는 center point 그 자체의 값으로만 학습된 성능이 표시되어 있지 않아 아쉬웠던 점으로 이야기한 것이었습니다 !
음 occlusion 상황에서의 corner와 center 검출에 대해서는 생각해보지 않았는데 충분히 다루어볼만하다고 생각이 듭니다. 하지만 아쉽게도 본 논문에서는 해당 내용을 다루고 있지는 않습니다.
안녕하세요, 좋은 리뷰 감사합니다.
밴치마킹을 위해 논문을 읽으신 걸로 아는데, 덕분에 잘 읽었습니다.
중심 지역의 크기에 대한 설명을 해주셨습니다. 해당 부분에 대해서 제가 이해를 잘 못해서 질문을 남깁니다.
중심 지역의 크기가 작으면 small object에 대한 recall이 낮다고 하셨는데 그럼 large object에 대한 recall은 어떤가요? 마찬가지로 중심 지역의 크기가 큰 경우 small object에 대한 precision은 어떤지도 궁금합니다.
감사합니다.
안녕하세요 ! 댓글 감사합니다.
사실 small object와 large object에서의 recall과 precision 관계는 small object-recall, large object-precision로만 한줄 서술되어 있는 것이라 본문에서도 이 부분은 제 생각이 많이 들어가 있습니다. 그래서 정확하진 않지만 희진님의 질문에도 제 생각을 이야기해보자면 .. small object에 대해 작은 중심 지역이 만들어져 center point 크기가 작아진다면 detection에 대한 정확도가 떨어져 precision 역시 낮아질거라 생각하지만 반대로 large object의 경우 center point가 커진다면 잘못된 예측이더라도 detection 할 확률이 커지기 때문에 recall은 오히려 높아질 수도 있지 않을까 생각해보았습니다 .. ㅎㅎ
안녕하세요 ! 좋은 리뷰 감사합니다.
기존 anchor based method에 반하여 centerNet은 anchor box를 단 한개만 사용하므로 NMS과정이 필요 없는것으로 이해를 했습니다. 그렇다면 많은 anchor box를 사용하는 기존 anchor based method에 것에 비해 CenterNet의 inference time이 더 빠를 것 같은데 이에 대한 언급은 논문에서 없었는지 궁금합니다.
또 CornerNet의 문제점을 강조하기 위한 MS-COCO validation dataset에 대한 False discovery rate를 보여주는 table1을 보면 samll object에 대해서는 높은 FD rate를 보이는데 특히 small object에 대해 부정확한 bouding box가 많이 발생하는 이유가 기존 CornerNet의 문제점과 관련있는지 궁금하네요.
안녕하세요 ! 댓글 감사합니다.
다른 anchor base method와의 inference time의 비교에 대한 언급은 논문에서 없었습니다만, 윤서님이 말씀하신 것처럼 더 빠를 수도 있다고 생각이 들기도 하지만 한편으로는 본문에서 언급한 것처럼 CenterNet의 inference에서도 soft-nms를 사용하고 있기 때문에 눈에 띄는 inference time의 차이가 있을지는 저도 궁금하네요 !
CornerNet에서 어떤 문제점을 이야기하면서 small object에 대한 높은 FD rate가 발생한다는 이야기는 없지만 experiment 부분에서 small bounding box의 중심 지역을 scale-aware하게 지정하였기 때문에 small object의 성능 향상이 두드러진다고 이야기한 것을 보아 center point가 도입되고 scale-aware하게 중심 지역을 설정한 것이 small object에서 좋은 영향을 끼친 것이 아닐까 생각합니다.
안녕하세요 리뷰 잘 읽었습니다.
CornerNet 논문에 대한 의구심도 들었는데 CenterNet이라니 저자는 Anchor-Free based Detection 중에서도 독특한 방법을 추구하는 듯 보입니다. 우선 리뷰를 읽다 충분히 이해되지 않은 부분에 대한 보충 설명을 부탁드립니다.
1. CornerNet의 한계점으로 “object가 한 쌍의 corner로 detection이 되기 때문에 object의 어떤 전체적인 정보를 활용하는 것이 제한적입니다. 또한 한 object당 그룹화 되어야 하는 두 개의 keypoint 쌍을 제대로 알지 못하고 object의 boundary만을 민감하게 감지하는 경향이 있어 결과적으로 부정확한 bounding box를 많이 생성하게 됩니다.”라고 말씀해주셨습니다.
이 때, object의 어떤 전체적인 정보를 활용하는 것에 제한적이라는 의미를 어떻게 이해하면 좋을까요? Corner 들의 쌍으로 Detection 되는 것이 Bounding box를 부정확하게 많이 생성하게 된다는 것을 말씀해주셨는데, Object의 전체적인 정보를 활용한다면 보다 정확한 Bounding box를 생성할 수 있나요? 스스로는 CornerNet이 Detection 중 Object에 대한 Classification의 성능 저하를 초래할 수 있겠구나하며 읽었는데, Object의 전체적인 정보를 어떻게 활용하는 것이 부정확한 Bounding box를 생성한다는 의미에서 와닿지 않습니다. 예시를 들어 설명해주시면 더욱 감사하겠습니다.
또한, Object의 Boundary만을 민감하게 감지하는 경향이 부정확한 Bounding box를 생성하나요? 흔히 알려진 Square-shape Bounding box라면 Object의 Boundary를 통해 Bounding box를 생성하는 것이 더욱 정확한 Bounding box를 생성할 것이라고 생각이 드는데, 왜 그런지 의문점이 듭니다.
예를 들어, 물체의 Contour에 집중하는 방식으로 학습한다면 Classification 성능이 낮아질 수 있으나, Contour-based method로 Bounding box 성능은 괜찮을 것 같은데, 그 이유는 무엇인가요? 또한, 부정확한 Bounding box를 만들다한들, NMS 등을 통해 Bounding box를 제거하면 그만이지 않나요? (물론 Inference time, Memory Consuming 등을 고려하면 반박할 수 있지만, DETR에서는 이미지 내 Object는 평균 7개인데 Query를 100개씩 던져놓기도 했어서, 부정확한 Bounding box로 초래될 수 있는 결과에 대해 말씀해주시면 더욱 감사하겠습니다.)
2. 다음으로는 CornerNet에 대한 질문입니다. 건화님이 작성해주신 몇 줄의 파이프라인을 읽었을 때 전체적인 청사진이 그려져 논문 한편을 금방 읽은 느낌이였습니다. 다만 CornerNet에서 두 Corner Point가 동일 Object를 칭하는지 알고자 Embedding vector의 거리를 계산한다고 했는데, 우선적으로 Embedding vector의 의의와 Embedding vector는 어떻게 구해지나요? 단순 2D Offset Vector 사이 유클리디안 거리를 GT Bounding box의 대각선 길이를 Threshold로 두는지, 아니면 다른 방법인지 궁금합니다.
왜냐하면, 단순 Threshold 이하일 때 동일 Object를 칭한다면 Object가 많을 때, 또한 단순히 Object가 많은 것이 아닌 동일 Object의 Overlap이 심하다면, 어떻게 극복할 수 있는지에 대해 의문점이 듭니다. 그렇다면, 해당 Embedding Vector를 구한 다음, 동일 Object에 해당되는 Pair를 찾고자 일종의 Bipartite Matching 과정이 있나요 아니라면 Backpropagation 과정이 존재하나요?
3. CornerNet Baseline 중, “실제로 IOU의 Threshold를 낮게 설정했을 때 조차 모든 bounding box 중에 잘못 만들어진 bounding box의 비율이 크다는 것을 보여줍니다. 예를 들어 IOU를 0.05로 설정한 경우에도 FD rate가 32.7%에 도달하게 됩니다. 결국 100개의 bounding box가 만들어졌다고 가정하면 GT Box와 IOU가 0.05도 되지 않는 bounding box가 30개 이상 존재한다는 것이죠.”라고 말씀해주셨습니다.
해당 부분이 이해되지 않는데, 지금의 제가 이해를 잘못하고 있는 것일까요? 보통 IoU>=0.05라함은 GT와의 IoU가 0.05 이상이면 True Bounding box로 판단한다는 의미로 아는데, 그렇다면 IoU가 낮을 수록 FD는 낮아지는 것이 자명하지 않나요? 현재 실험에서 FD_5, FD_25, FD_50은 0.05, 0.25, 0.5로 정한 IoU에 대해 GT와의 Bounding box를 비교하여 FD로 정한 수치로 해석되지 않나요?
해당 부분은 제가 이해를 잘못하고 있는 점인지, 혹은 해당 테이블에서 사용된 IoU Rate가 다른 의미로 해석되는지 의문점이 듭니다. 아마도 논문에서 해당 내용이 나왔을터인지라 제가 오해하고 있나 생각이 드는데, 이번 기회에 되짚어주시면 감사하겠습니다.
4. CenterNet에서 Center Keypoint를 정의하고 해당 정보를 통해 Bounding box를 생성하는 과정을 잘 설명해주셔서 이해에 도움이 되었습니다. 의문점으로 Top-k Center Keypoint에 대해 중심 지역에 포함되면 Bounding box를, 중심 지역에 포함되지 않으면 무시한다 (Bounding box를 버린다)고하는데, Class 정보에 대해서는 저자가 말한 “CornerNet은 Object 내의 정보를 이용하지 못한다”는 것이 이해됩니다만, Center KeyPoint는 단순히 Corner Keypoint Pair들로 만든 Bounding box를 살리느냐, 버리느냐만을 결정하나요? 그렇다면 저자가 말하는 부정확한 Bounding box를 제거하기 위한 하나의 수단으로써 Center Keypoint를 활용하는 것에 불과하나요?
머리로는 이해되지만, 사실 해당 구문이 CornerNet에서 False Bounding box가 이미 많은데, 해당 Bounding box가 단순히 부정확하게 많이 쳐져서 발생한 것인지, 혹은 CornerNet 자체의 한계점이 명확히 존재하기 때문인지 궁금하네요.
물론 이 점에 대해서는 건화님의 고찰을 듣고 싶습니다. 저는 CornerNet의 리뷰를 읽었을 때도 스스로 납득되지 않는 점이 많았기에, 저자의 이러한 고찰이 단순히 + alpha를 통해 성능을 개선하는 Contribution에 그친 느낌을 받았습니다.
+ 중심 지역의 크기와 Small object, Large object에 대한 성능에 대한 고찰을 써주셨는데, 이에 대해서는 제 고찰을 말씀드리고 의논하는 것이 좋을 것으로 보입니다. 현재 CenterNet의 Center Keypoint는 역할이 “불필요한 Bounding box를 제거하기 위한 수단”으로 보입니다. Small obejct는 Object의 크기가 작음에 Corner Keypoint Pair도 근접하게 위치한 반면 Center Keypoint 또한 Corner와 근접하게 국소적으로 위치할 것으로 보입니다. Object scale만 고려했을 때, Object도 작은데 중심지역 또한 작다면 그만큼 정확하게 Center Keypoint가 위치하지 않았다면, 모든 Bounding box들이 버려질 것 입니다.
이는 예시로 Bounding box 내 Object의 Classification Score (Confidence Score)이 1일 때만 Foreground로 취급한다로 볼 수 있습니다. Center Keypoint 또한 학습 대상이므로 오차가 존재하는데, 그 오차를 고려하지 않고 중심 지역을 너무 국소적으로 설정한다면, 실상 Small object에 대한 Bounding box가 모두 버려질 것으로 보입니다. 그 반대로 Large Scale Object에 대해서는 반대로 생각하면 되지 않을까 싶습니다.
논문에 대한 사견 및 고찰이 담겨져 있어 논문을 읽기에 훨씬 수월하고 좋았습니다.
5. Center Pooling, 그 의의가 굉장히 좋은 것 같습니다. 그렇다면 의문점으로 Center 지점은 이전에 설정한 중심 지역과 어떤 연관성이 있나요? Center Keypoint가 정말 Object의 중심이 아닌, Semantic information을 담은 위치로 보내는 것에 대해서는 일리가 있다고 생각됩니다만, 그렇다면 사전에 정한 중심 지역도 학습 파라미터로 설정하여 조정을 하나요? Figure를 봤을 때 중심 지역은 정말 Object의 중심으로 보이고, Center Pooling을 통한 Center Keypoint는 물체의 중심이 아닐 확률이 더 높아보이는데, 그렇다면 해당 Bounding box들이 버려지는 것 아닌가요?
또한 학습을 한다한들, 동일 Object에 대해서도 핵심이 되는 Keypoint가 모두 다를 것인데, 이러한 점도 고려하는지 궁금합니다.
정말 흥미롭게 읽은 논문 리뷰입니다. 감사합니다.
안녕하세요 ! 댓글 감사합니다 . .
1. 우선 object의 전체적인 정보를 활용하지 못하여 부정확한 bounding box를 만든다는 말의 의미를 논문의 말을 빌려 좀 더 설명해보자면 다음과 같습니다. CornerNet 뿐만 아니라 keypoint based method는 keypoint가 만들어진 후 crop된 region의 시각적인 패턴을 잘 사용하지 못한다는 단점이 존재해왔다고 합니다. 우선 detection을 해야하니까 두 개의 corner을 만들긴 하였는데 object의 특징이 전혀 존재하지 않는 부분에 corner을 만들어 bounding box를 대체하려다보니 정작 object의 feature가 존재하는 cropped region의 정보는 활용하지 못한다는 의미에서 부정확한 bounding box가 많이 생성된다고 이야기한 것이 아닐까 생각합니다.
비슷한 맥락으로 object의 Boundary만을 민감하게 감지한다는 말도 설명할 수 있을 것 같은데요, 이 부분은 저의 개인적인 생각이긴 합니다만 CornerNet의 경우에 bounding box를 대체할 corner 두 개의 점을 만드는 것에 초점이 맞춰진 것일 수도 있겠다는 생각을 해보았습니다. 그리고 제가 생각했을 때 저자들이 object의 boundary만을 민감하게 감지하는 경향이 있다고 이야기한 것은 두 개의 corner 포인트를 따라 만들어지는 가상의 box의 형태를 민감하게 감지한다는 말이 아닐까요? 실제 CornerNet에서 corner pooling을 할 때에도 두 개의 corner point에서 수평과 수직 방향으로 max value를 더해주는 것을 볼 수 있는데, 어떻게 보면 corner에서 수평, 수직 방향을 연속적으로 이었을 때 anchor-based의 bounding box와 같은 형태를 만들 수 있는 것처럼 정말 anchor box를 corner point 두 개로 대체하는 것에 초점을 맞추는 경향이 있는 것 같습니다. 그래서 정작 중요한 object의 정보는 후순위로 넘어가게 되어 부정확한 bounding box가 많이 생성되는 것이라고 이해하였습니다.
2. Embedding vector의 의의라고 함은 상인님이 말씀하신 것 처럼 선택된 top k개의 top-left corner와 bottom-right corner 중에 같은 object를 가리키고 있는 corner pair들을 grouping 하기 위해 구해지는 거리라고 할 수 있습니다. 특이한 점 중 하나는 구해지는 값 자체는 아무 의미없는 값이 되고 embedding의 차이만이 유의미한 값이 됩니다. embedding의 차이를 구하여 가장 작은 값을 가지는 두 point가 한 쌍의 corner point가 되는 것입니다. 구하는 방식이라고 함은 top-left corner의 embedding 값과 bottom-right corner의 embedding 값, 그리고 평균값의 차이를 이용하여 계산됩니다. 해당 embedding 방식은 사실 CornerNet에서 처음 제시한 방식은 아니고 “Associative Embedding: End-to-End Learning for Joint Detection and Grouping”의 방식을 사용하였다고 하니 참고하시면 좋을 것 같습니다. “왜냐하면, 단순 Threshold 이하일 때 동일 Object를 칭한다면 Object가 많을 때, 또한 단순히 Object가 많은 것이 아닌 동일 Object의 Overlap이 심하다면, 어떻게 극복할 수 있는지에 대해 의문점이 듭니다.” 이 부분은 도경님의 질문과 비슷하게 occlusion에 대한 질문인 것 같은데 위에서도 답변 드렸듯이 이에 대한 부분은 후속 연구에서 다루고 있는지를 찾아보아야 할 것 같습니다 . .
3. 저도 이 False Discovery rates가 정확하게 이해가 되지 않아 FP로 이해하시면 될 것 같다고 말씀을 드렸었는데요, 논문에서 제가 본문에 적어놓은 것 이상의 해당 Table1에 대한 설명이 서술되어 있지 않아 제가 이해한 방향으로 이야기해보자면, “IOU≥ 0.05인 경우에도 FD rate가 32%가 넘는 다는 것은 결국 100개의 bounding box가 만들어졌을 때 incorrect bounding box가 30개 이상 존재한다”라는 말을 좀 더 직관적으로 이해하시면 편할 것 같습니다. 내가 IOU를 0.05까지 낮추어 최대한 많은 bounding box를 correct bounding box로 취급하려 했지만 그럼에도 불구하고 IOU가 0.05도 되지 않는 낮은 IOU를 가지는 bounding box가 여전히 30% 이상을 차지하고 있기 때문에 이를 False Discovery라고 정의하고 FD Rate를 통해서 incorrect bounding box가 많이 발생한다는 것을 증명하고자 했다고 이해하였습니다.
4. 음 제가 질문을 제대로 이해하였는지는 모르겠지만 center keypoint의 class label이 GT의 class label과 다르다면 해당 bounding box를 버린다고 이야기 한 것은 CenterNet에서는 center point를 만든 후 center pooling을 통해 box 내의 정보를 활용하고자 하는 것인데 class label 자체가 다르다면 박스 내의 정보를 활용하는 것이 무의미해지기 때문에 GT label과 다른 경우에 1차적으로 필터링해주는 과정이라고 생각해주시면 될 것 같습니다.
5. center point와 중심 지역의 관계는 최소한 중심 지역 안에 center point가 위치해 있어야 center point로 인정하고 사용하게 됩니다. 중심 지역을 벗어난 위치에 center point가 있을 경우 해당 bounding box는 사용하지 않고 제거되는 것 입니다. 그리고 center pooling에서 center keypoint의 수평, 수직 방향으로의 최댓값을 더하여준다는 것은 박스 내의 sementic information이 담겨져 있는 위치로 center keypoint의 물리적인 위치를 옮긴다기보다는, 최댓값을 가지는 픽셀값을 더해줌으로써 center keypoint의 정보를 더해준다고 이해하였습니다. center pooling을 거친다고 해서 실제 물리적인 center point의 위치가 sementic한 정보가 담긴 곳으로 이동하지는 않습니다. 말씀해주신 것처럼 동일 object에 대해서도 핵심이 되는keypoint가 모두 다를 것이므로 오히려 물리적인 center을 정하고 두 방향으로 sementic한 정보를 찾아 더해주는 것이 맞지 않을까 싶습니다.