최근 Active Learning 에 대해 다시 한번 훑어보고 정리하는 시간을 가지고 있습니다. 그러면서 Active Learning 에서 비교군으로 많이 언급되는 CDAL이라 불리는 그런 논문에 대해 리뷰해보려고 합니다.
Background
많은 분들이 아시다시피, Active Learning 의 핵심 아이디어는 모델의 현재 지식을 활용하여 가장 유익한 샘플을 선택하는 것입니다. 이렇게 선택된 일부 데이터로 학습한 모델이 전체 데이터셋으로 학습한 경우와 거의 동일한 성능을 달성하기도 하면서, Active Learning 연구는 계속해서 활발하게 진행되고 있습니다.
‘가장 유익한 샘플을 선택’ 하는 것이 Active Learning 이라고 하였는데요, 가장 유익하다는 어떻게 정의할 수 있을까요? Active Learning 에서는 ‘모델에 유익하다는 것‘을 바라보는 관점이 크게 2가지 존재합니다. 바로 Uncertainty와 Diversity 입니다. 전자는 모델의 예측 결과가 얼마나 모호한지, Confidence가 얼마나 낮은 지 등을 기준으로 데이터를 선택하는 것입니다. 모델의 예측 신뢰도가 낮은(=모델의 예측이 애매하다) 것을 선택해서 라벨링을 해야 모델의 성능이 더 올라갈 것이라는 입장입니다. 그런데, 이런 불확실성 기반의 데이터 선택은 결국 선택 셋의 다양성을 확보할 수 없기도 합니다. 그래서 이에 대응하여 등장한 Diversity 기반의 연구들은 ’전체 데이터셋을 대표하는 하위 셋이 가장 유익하다’ 라고 주장합니다.
Introduction
그런데 저자는 이런 Diversity 기반의 연구 역시 ‘이미지 내의 존재하는 공간적, 의미적 맥락을 파악하는 데에는 여전히 충분하지 않다‘ 라는 점을 문제삼았습니다. Diversity는 데이터셋 전반을 파악할 수 있도록 설계되어 spatial and semantic context를 파악할 순 있겠지만, 대부분이 Feature를 기반으로 샘플을 선택하곤 합니다. 그런데 Feature는 이미지 object의 공간적 위치나 상대적인 배치에 대한 정보를 보존하지 않는 점에 집중하죠. 즉, 기존 연구들은 이미지의 local 한 특징을 파악하는 데에는 명확하지 않다고 주장합니다.
그 근거로는 CNN 기반의 모델의 경우 이미지에서 object 의 위치 또는 spatial context에 취약하다는 점을 함께 들었습니다. 이해를 위해 아래 그림을 함께 보시죠. 아래 그림에서는 CNN 기반 모델의 mis-classification을 발생하는 경우는 실제 클래스의 object 뿐만 아니라, 그 object의 근처에 나타날 수 있는 다른 클래스 때문에 발생한다는 것을 보여줍니다. 아래 그림은 Camvid 중 4개의 프레임을 보여주는데, 박스에 대한 평균 확률을 클래스 별로 나타낸 것입니다. 클래스 별 확률을 보면 (A)의 Fence, (C)의 Bicycle이 보행자 근처에 나타난 것을 확인할 수 있습니다. 저자는 이런 예시를 통해, 기존에 제안된 연구들은 이미지의 공간적, 의미적 맥락의 다양성을 전혀 커버할 수 없다는 점을 문제삼았습니다.
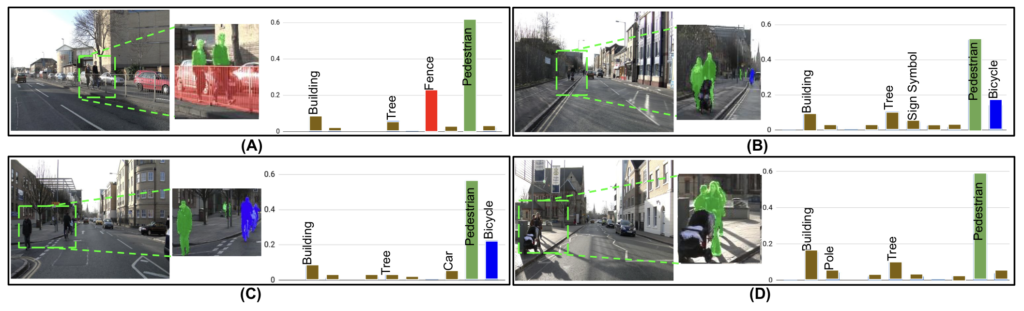
정리하자면, object 근처에 어떤 것이 있는 지도 굉장히 중요한 요소이기 때문에 ‘공간적 맥락을 파악해서 하위 데이터셋을 선택할 때 가급적 다양한 물체가 포함된 이미지를 선택하는 것이 중요하다‘ 라는 주장을 하고 있습니다. 예시로 설명하자면, Uncertainty 기반의 연구 중 Entropy 가 ‘유익한’ 데이터의 기준이라고 해봅시다. 이럴 경우 모델은 4개의 프레임 중 3개를 선택한다고 했을 때, Entropy 가 높은 B, C, D를 선택할 것입니다. 그러나 공간적 맥락을 파악한다면, A, C, D를 선택할 수 있을 것입니다. 왜냐? Bicycle이 아닌 Fence라는 객체가 있는 또 다른 클래스가 있는 데이터를 선택함으로써 다양성을 유지하자는 것이 저자의 주장이기 때문이죠.
그렇다면 이제 본 논문의 제목에도 등장한 ‘Contextual Diversity’의 중요성을 이해하셨을 것이라 생각됩니다. 그럼 이제 저자는 contextual diversity를 어떻게 정의하였고, 모델에 이걸 반영하기 위해 어떤 방법론을 제안하였는지 설명드리겠습니다.
Active Frame Selection
본격적인 설명에 앞서 본 논문의 요약을 먼저 소개해보도록 하겠습니다.
- 데이터셋에 존재하는 다양한 object class의 공간적, 의미적 맥락의 다양성을 파악하기 위해, 새로운 정보 이론적 거리 측정인 맥락적 다양성(CD, Contextual Diversity)를 제안하였습니다.
- 앞서 정의한 CD를 Core-set과 함께 사용하여 SOTA를 달성했고, RL 프레임 워크에서 CD를 보상 기능으로 사용함으로써 추가의 성능 개선을 가져올 수 있었다고 합니다.
Core-set은 뭐고, 왜 갑자기 RL이 등장한 건지.. 싶으실 것 같습니다. 저자는 Uncertainty 와 Diversity를 동시에 고려한 Active Learning 을 제안하고자 하였는데, 이를 위해 데이터의 공간적, 의미론적 맥락을 기반으로 모델 예측의 불확실성을 샘플 간의 다양성과 통합한 프레임 워크를 제안한 것이죠. Intro에서 살펴본 공간적 맥락을 정의한 것이 CD고 이를 기존 연구들과 결합했더니 엄청난 성능 개선을 가져왔다라고 앞선 요약을 정리할 수 있을 것 같습니다. 나머지 디테일은 아래 리뷰에서 함께 설명드리겠습니다.
다시 본론으로 돌아오겠습니다. Pseudo-Label 즉 모델의 예측값을 임의의 GT로 활용하는 것은 semi-/self-supervised learning 연구에서 많이 활용하는 방법입니다. 그러나 예측의 불확실성을 고려하지 않고 무작정 사용할 경우, 과적합 혹은 편향 등이 발생할 수 있습니다. 그럼에도 불구하고 이런 모델의 예측값에는 유용한 정보가 포함되어 있기 때문에 적절히 사용하는 것인데요. 본 논문의 핵심 키워드인 ‘문맥적 다양성(CD, Contextual Diversity)’ 는 바로 이 수도 라벨에서 시작되었습니다. CD의 핵심은 모델의 mixture of softmax posterior probabilities of pseudo-labeled samples를 정량화 하는 것입니다. 왜냐? 이 혼합 분포가 바로 이미지에 존재하는 공간적, 의미론적 맥락을 파악할 수 있기 때문이죠. 따라서 저자는 CD에 의거하여 Unlabled pool에서 샘플들을 선택하고, 두 가지 strategy에 따라 AL을 제안하였습니다. 첫번째는 Core-set이라는 DIversity 기반의 대표적인 AL방법론에서 영감을 얻은 CDAL-CS이고, 두번째는 강화학습 프레임워크를 사용한 CDAL-RL 입니다. 아래 그림이 바로 저자가 제안하는 Contextual Diversity for Active Learning (이하 CDAL)의 파이프라인입니다. 전체적인 그림에 대해 설명드리기 위해 본격적인 리뷰에 앞서 다소 이해하기 어렵게 서술한 것 같습니다. 자세한 파트에 대해서는 아래에 설명드리도록 하겠습니다.
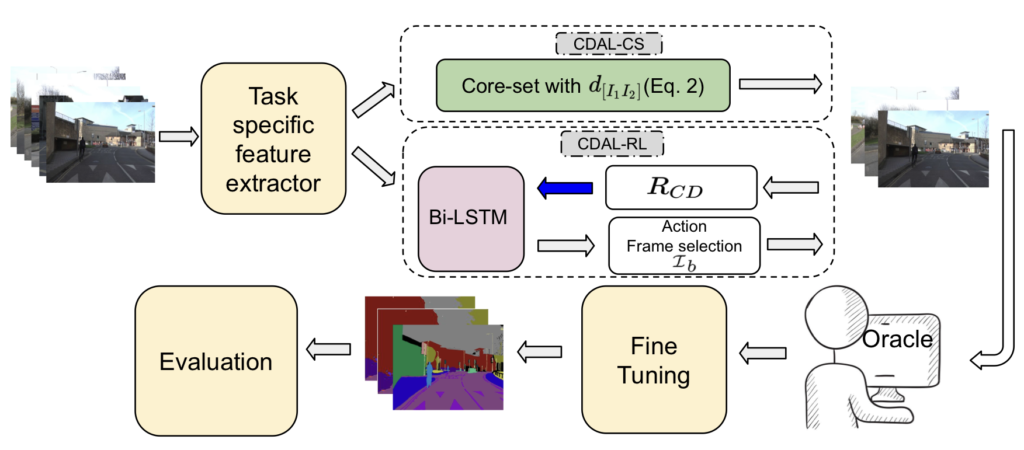
Contextual Diversity
해당 파트에서는 Intro에서 공간적으로 가까이 있는 클래스를 고려해야한다고 계속 강조했던 CD에 대한 정의를 설명합니다. CNN이 공간적 맥락을 파악할 수 있도록 넓은 receptive field를 가진 건 분명하지만, 공간적으로 가까이 있는 클래스 사이 간섭은 예측값을 더욱 모호하게 만들게 됩니다. 따라서 저자는 이러한 class-specific confusion을 정의하여 예측값의 ambiguous를 정량화하고자 하였습니다.
그전에 Notation에 대해 먼저 정리하겠습니다. C = {1, …, n_C}가 클래스를 의미하고, 입력 이미지 \mathsf{I} 내의 영역 r이 주어졌을 때, 모델 \theta가 예측한 softmax 확률 벡터를 Pr(\hat{y}|\mathsf{I};\theta) 라고하고 이걸 편의상 P_r 이라고 표기합니다. 이런 영역은 태스크에 따라 픽셀일수도, 바운딩 박스일수도, 전체 이미지 일 수 있겠죠 (각각 segmentation, detection, classification 이겠네요) 그리고 영역 r에 대한 수도라벨은 \hat{y_r} = argmax_{j∈C}P_r[j] 로 정의되며, P_r[j]는 벡터의 j번째를 의미합니다. I = ∪_{c∈C}\mathcal{I}^c는 Unlabeled 를, \mathcal{I}_c는 클래스 c로 분류된 region이 하나 이상 있는 이미지의 집합입니다. 또한 모델이 클래스 c에 속한다고 생각하는 모든 region의 집합을 R_\mathcal{I}^c=∪_{\mathsf{I}∈I_c}R_l^c이라고합니다.
이제 Unlabeled pool \mathcal{I}에 대해 주어진 모델 \theta에 대한 클래스 c에 대한 클래스 별 confusion은 다음과 같은 분포로 정의할 수 있습니다.
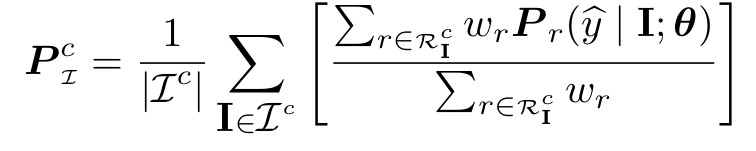
모델이 완벽하다면 P^c_\mathcal{I}는 원핫 인코딩된 벡터이지만, 충분하게 훈련되지 않은 모델의 경우 P^c_\mathcal{I}는 클래스 c와 다른 모든 클래스 사이의 confusion을 나타내는 엔트로피가 높아질 수 있습니다. 앞서 저자는 줄곧 CNN 기반의 분류기에서 불확실성은 이미지의 공간적 의미적 컨텍스트로부터 비롯된다고 하였는데요, 그림 1을 예시로 설명드리겠습니다. 보행자 클래스에 가장 높은 확률로 예측하겠지만, Fence나 bicycle에도 충분히 높은 확률을 가질 수 있겠죠(region에 두 object가 있으니까요). 이런 경우 P^c_\mathcal{I}[j]는 j={Fence, bicycle}에 높은 값을 가져, 레이블이 Unlabeled Pool \mathcal{I}에서 클래스 간 confusion 가능성을 반영합니다. 학습이 계속될수록 모델의 성능이 증가하면 결국 확률 질량이 j=c에 집중되어 P^c_\mathcal{I}의 전체 엔트로피는 감소하게됩니다.
Contextual Diversity를 확보하기 위해서는, 이미지가 나머지 하위 집합과 다른 종류의 confusion을 포착해야 합니다. 이를 위해 저자는 주어진 이미지쌍 I_1, I_2에 대해 symmetric KL-divergence을 사용하였습니다. 따라서 정의된 pairwise contextual diversity에 의한 클래스별 confusion 사이에 대한 차이는 다음 수식과 같이 정의 하였습니다.
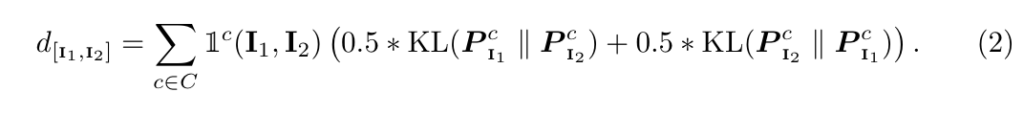
여기서 \mathbb{1}은 I_1, I_2가 모두 \mathcal{I}^c 에 속할 때만 1이고 나머지는 0이라는 의미입니다. 이는 두 이미지 모두 클래스 c로 수도 라벨이 지정된 영역이 하나 이상 있는 경우, 즉 두 이미지 모두에 클래스 c에 대한 신뢰할 수 있을만한 confusion 값이 잇을 경우에만! 클래스 별 confusion gap을 고려할 수 있도록 설계된 수식입니다. 모든 클래스에 걸쳐 누적된 이 confusion gap은 두 이미지 간 pairwise contextual diversity에 대한 값이 됩니다. 이렇게 pairwise 거리를 사용하여 샘플 선택을 위한 AL방법론인 Core-set에 적용할 수 있게되며, 이를 통해 다양한 컨텐스트 다양성을 계산할 수 있게됩니다.
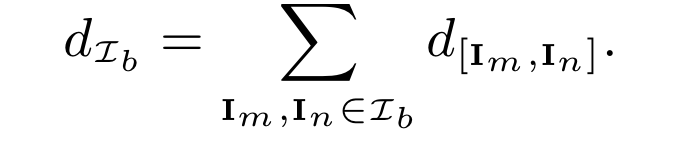
Frame Selection Strategy
결국 저자는 새로운 AL 모델을 제안한 것이 아니라, 기존 연구에 더해서 저자가 제안하는 CD까지 고려하면 모델의 성능이 더욱 높아질 것이라고 제안한 것입니다. 그러므로 어떤 데이터가 유용한 지 선택하는 방법까지 제안하기 보다는, 기존에 있던 연구들에 저자의 CD를 추가함으로써 아이디어를 검증하였습니다.
아이디어 검증에 사용된 연구는 두 가지인데요. Diversity 기반의 대표적인 방법론인 core-set 과 강화학습에 저자의 CD를 붙인 성능을 확인하였습니다. Core-set에 저자의 CD를 붙힌 것을 CDAL-CS라 하고, 강화학습에 CD를 적용한 것을 CDAL-RL 이라고 하였습니다.
Coreset은 feature space 사이에서 유클리드 거리에 의해 핵심이 되는 샘플들(core-set)을 선택하는 다양성 기반의 AL 방법론입니다. 저자는 Coreset에 CD를 적용한 CDAL-CS를 제안하였는데요. Core-set을 CD 와 함께 사용하기 위해 유클리드 거리를 pairwise contextual diversity인 수식 2로 대체하였습니다.
CDAL-RL은 강화학습을 사용한 것으로 보상함수의 일부로 CD를 사용하며, Bi-LSTM 기반의 policy network를 사용하여 학습하였다고 합니다. 이 때 보상 함수는 3가지로 구성되는데 R_{cd}, R_{vr}, R_{sr}이 있습니다. R_{cd}는 저자가 정의한 수식으로 선택한 이미지셋 I_b에 대해서 계산된 문맥적 다양성을 의미합니다.
다음으로 R_{vr}은 시각적 표현인 visual representation을 의미하는데요. 이 보상을 통해 이미지의 feature representation을 사용하여 Unlabeled Pool 전체 셋에 대한 시각적 대표성을 통합하고자 하였습니다. 이미지 I_i∈\mathcal{I}, I_j∈/mathcal{I}_b의 feature representation을 각각 \mathbf{x}_i, \mathbf{x}_j라고 할 때 R_{vr}는 아래와 같이 정의될 수 있습니다. 이 보상은 피처 공간 전체에 분산된 이미지를 선택하도록 즉 다양한 샘플을 선택하도록 유도합니다.
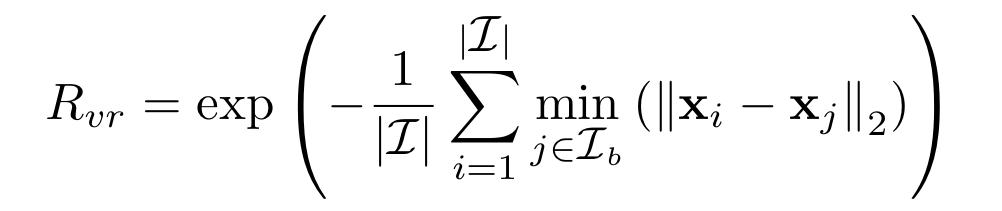
R_{sr}는 semantic representation으로 선택한 이미지 하위 집합이 모든 클래스에서 균형을 이룰 수 있게 정의된 것이라고 합니다. 이는 시맨틱 segmentation에만 사용됩니다.
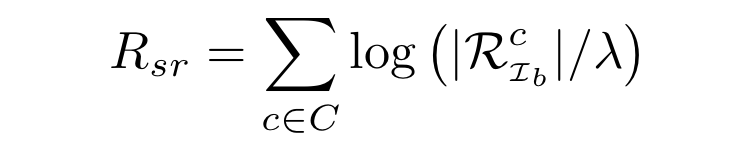
이제 최종적으로 총보상은 R = αR_{cd} +(1-α)(R_{vr} +R_{sr})로 정의하고, 이를 LSTM 기반 policy network를 학습하는 데에 사용하였습니다. 여기서
Results and Comparisons
아무래도 object 주변의 공간적 다양성에 집중한 논문이다 보니, 그동안 AL에서 메인 실험으로 내세운 Classification보다는 segmentation>detection>classification 순으로 성능을 리포팅하였습니다. 성능 비교에는 흔히 비교에 많이 사용되는 VAAL, Coreset, QBC, MC-Dropout을 사용하였습니다.
Semantic Segmentation
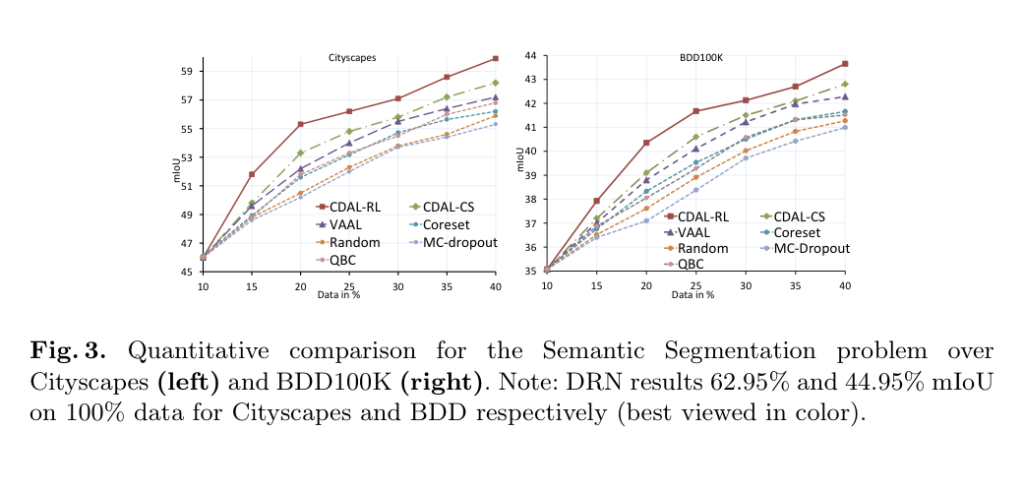
Cityscapes와 BDD100K 데이터셋에 대한 결과입니다. 최근 방법론인 VAAL과 프로토콜도 백본도 동일하게 설정하였으며 이와 비교했을 때 월등히 좋은 성능을 나타냈습니다. 추가되는 데이터는 각각 150과 400으로 VAAL과 동일하게 설정하였다고 합니다. CD를 사용한 두가지 방법론 CDAL-RL, CDAL-CS 모두 기존 방법론 대비 월등히 좋은 성능을 보이며, 이를 통해 저자가 제안하는 CD가 효과적임을 알 수 있었습니다. 특히 segmentation이 이런 공간 컨텍스트의 영향을 가장 많이 받았습니다. 이를 통해 CD가 공간적 의미론적 contextual을 효과적으로 포착하는 동시에 가장 많은 정보를 제공하는 샘플을 선택하는 데에 효과적임을 알 수 있었습니다.
Object Detection
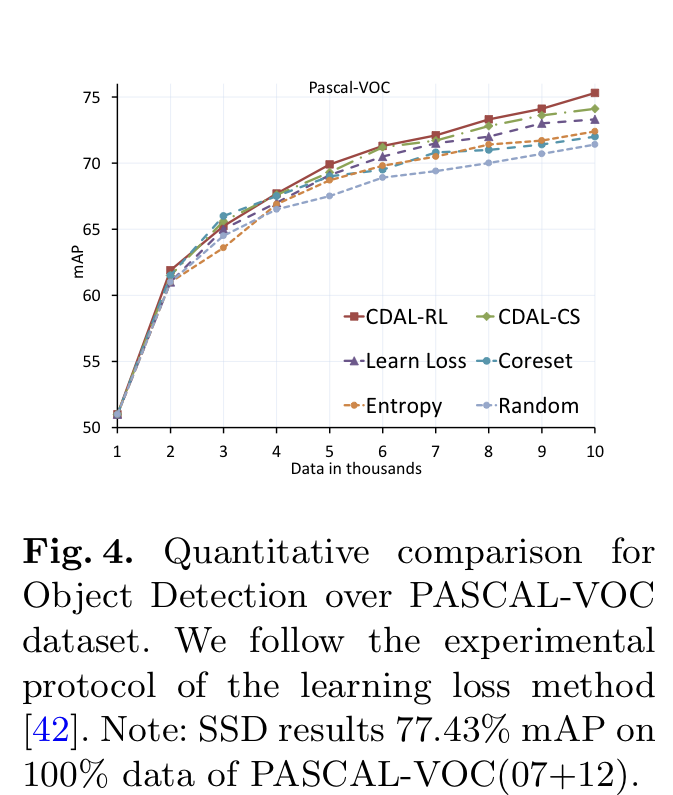
Detection은 learning loss의 프로토콜을 따랐습니다. 여기서 의문은 learning loss에 대해서는 왜 semantic segmentation에서 사용하지 않았으냐 궁금하실 것 같은데요. Learning loss에서는 segmentation에 대한 성능 평가를 진행하기 않았기 때문이 아닌가 싶습니다. 아래 그림이 바로 PascalVOC에 대한 결과입니다. 기존 SOTA인 Learning loss와 비교하였을 대 훨씬 더 높은 성능을 달성하였으며, CD 가 다른 태스크에서도 효과적임을 확인하였습니다.
Classification
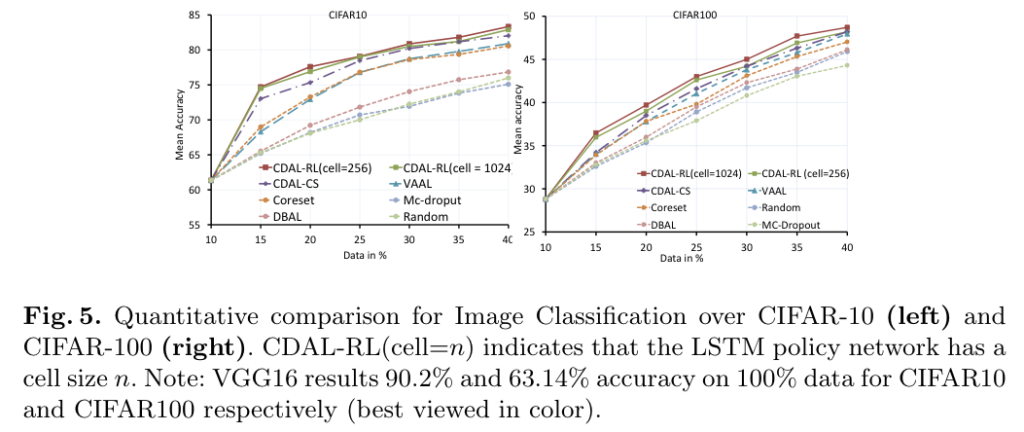
마지막으로 이미지 분류에 대한 성능입니다. 저자는 클래스 수가 많아졌을 대에도 CD의 강점을 보여주기 위해 CIFAR-10, 100에 대한 성능평가를 제안하였습니다. 아래 그림 5가 바로 그 결과인데요. 두 데이터셋 모두 CDAL이 기존 SOTA인 VAAL을 뛰어넘는 것을 알 수 있었습니다. 특히 CIFAR-10에서는 VAAL보다 5000개 적은 샘플로 약 81%의 정확도를 달성하였고, CIFAR-100에서는 2500개 적은 샘플로 47.95%의 정확도를 달서하였습니다.
Analysis and Ablation Study
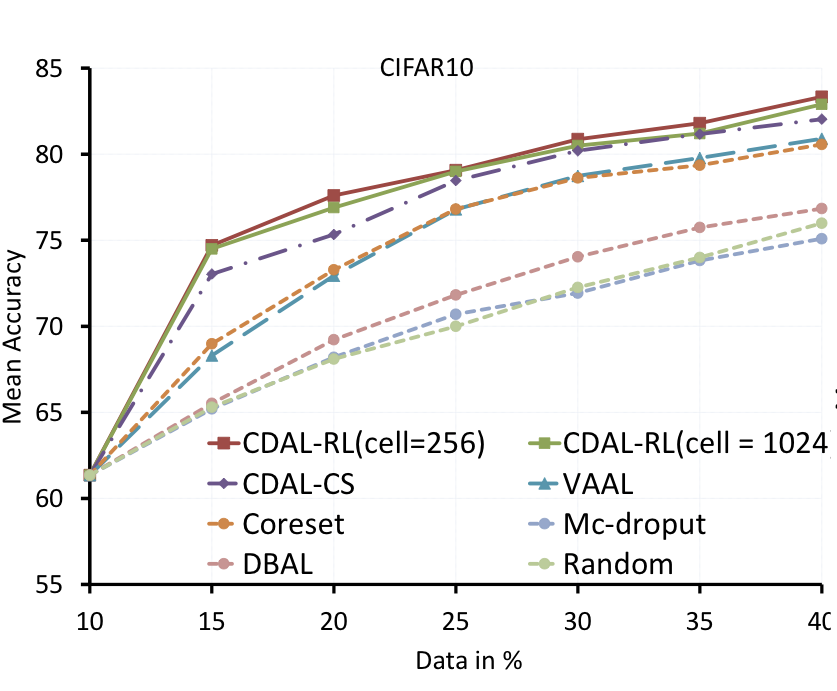
저자는 추가로 AL에서 Contextual Diversity의 효과를 보이기 위한 Ablation study 를 보였습니다. 특히 AL은 라벨링 비용을 아끼기 위해 제안된 연구로서 다른 것도 아닌 segmentation에서 가장 유용할 것이기에 ablation study로 segmentaion을 택했다고 합니다. (약간 청산 유수라고 느꼈던게.. contextual diversity 관점에서 classification에서는 성능 향상이 저조한 것이 당연하기에 ablation study 역시 효과적이지 않았을 테고 당연히 segmentation 결과로 보여야 했을 것 같은데 이걸 이렇게 멋ㄷ스럽게 포장한다 생각이 들었습니다허허)
아래 그림이 Ablation study입니다. 왼쪽 그림이 CDAL-RL에서 보상을 하나씩 제거한 것입니다. 세가지 보상이 있을 대 가장 높은 성능을 보인 것은 사실이지만 저자가 제안하는 CD만을 보상함수로 사용해도 SOTA 였던 VAAL을 능가한 것을 통해 CD가 효과적임을 알수 있었습니다. 게다가 저자는 보상함수에서 VR, SR에 대한 가중치를 특별히 조정한 것이 아닌 CD에 집중하기 위해 단순하게 설정하였기에 유의미한 결과임을 강조하엿습니다.
지금까지 Active LEarning 에서 다양한 확장실험을 진행한 CDAL에 대해 알아보았습니다. 저자의 문제 정의 그리고 해결을 위한 설계 방식 그리고 검증이 최근에 읽은 AL 중 괜찮은 연구에 속하지 않았나 싶습니다.
흥미로운 논문을 소개해주셔서 감사합니다. CD에 대해 질문이 있는데요 그렇다면 해당 논문은 특정 영역에 대해 score를 계산하게 되는 것 인가요? 아니면 이미지 단위로 score를 계산하게 되나요? 여기서 score는 active learning이 데이터를 선별할 때 사용하는 기준을 의미합니다!
안녕하세요 황유진 연구원님 좋은 질문 감사합니다.
Task 에 따라서 다른데요. segmentation, detection은 관심영역 단위로, classification은 이미지 단위로 계산되게 됩니다.
안녕하세요 홍주영 연구원님, 좋은 리뷰 감사합니다. 개인적으로 단순히 ’CNN은 공간 정보를 담고 있으므로 좋다!’ 정도로 알고 있었는데, CNN이 공간적 맥락을 파악할 수 있도록 넓은 receptive field를 가진 건 분명하지만, 공간적으로 가까이 있는 클래스 사이 간섭은 예측값을 더욱 모호하게 만들게 된다는 것은 처음 알았습니다.
제가 이해한 바에 따르면,
1. AL의 핵심 아이디어는 모델의 현재 지식을 이용하여 가장 유익한 샘플(annotation할 고가치 데이터)을 선택하는 것입니다. 이렇게 선택된 일부 데이터로 학습한 모델이 전체 데이터셋으로 학습한 경우에 근접한 성능을 달성하기도 하며 AL연구는 활발하게 진행되고 있습니다.
2. 학습 모델에 비교적 유익한(high value) 데이터를 판단하는 관점은 크게 ‘Uncertainy’ 와 ‘Diversity’가 있습니다. ‘Uncertainty’는 모델 예측 신뢰도(Confidence)가 얼마나 낮은지를 기준으로 데이터를 선별하는 것인데, 이런 불확실성 기반 데이터 선택은 선택 셋이 편향되는 문제점이 있습니다. 이에 대응하여 등장한 것이 ‘Diversity’ 기반 AL입니다.
3. ‘Diversity’ 기반의 연구들은 ‘전체 데이터셋을 대표하는 subset이 가장 유익하다’라는 전제를 갖고 있습니다. 하지만 저자는 ‘diversity 기반의 연구 역시 (image 내 spatial and semantic context를 파악하기에는)여전히 충분하지 않다’ 라고 합니다. feature 기반 sample 선택은 공간적 위치 정보를 보존하지 못해 local 정보를 파악하기 명확하지 않기 때문입니다.
4. 이 근거로 CNN기반 모델의 경우 object의 spatial context에 취약하다는 점을 꼽으며. 기존에 제안된 연구들은 이미지의 공간적, 의미적 맥락의 다양성을 전혀 커버할 수 없다는 점을 문제삼습니다. 저자의 주장을 정리하면, ‘object 근처에 어떤 것이 있는지도 굉장히 중요한 요소이기 때문에 공간적 맥락을 파악해서 하위 데이터셋을 선택할 때 되도록 다양한 물체가 포함된 이미지를 선택하는 것이 중요하다’ 정도일 것 같습니다. 저자는 새로운 AL 모델을 제안한 것이 아니라, 기존 연구에 추가적으로 고려할 수 있는 CD를 제안한 것입니다(이는 기존 연구에 접목되어 큰 성능 향상을 보였습니다)
5. 이에 저자는 dataset의 다양한 object class의 공간적, 의미적 맥락 다양성을 파악하기 위해 새로운 (정보이론적)거리 측정 방식인 ‘Contexual Diversity’를 제안했습니다. 이를 Core-set과 함께 사용하여 SOTA를 달성하였고, RL 프레임 워크에서 CD를 보상 기능으로 사용함으로써 추가의 성능 개선을 가져올 수 있었습니다. uncertainty와 diversity를 동시에 고려한 AL을 제안하기 위해 데이터의 공간적, 의미론적 맥락을 기반으로 모델 예측의 불확실성을 샘플 간의 다양성과 통합한 프레임 워크를 제안한 것입니다. (공간적 맥락을 정의한 것이 contextual Diversity이고, 이를 기존 연구들과 결합했더니 상당한 성능 개선을 이루었습니다)
6. 저자는 CD에 의거하여 Unlabled pool에서 샘플들을 선택하고, 두 가지 strategy에 따라 AL을 제안하였습니다. 1.첫번째는 Core-set이라는 DIversity 기반의 대표적인 AL방법론에서 영감을 얻은 CDAL-CS이고, 2.두번째는 강화학습 프레임워크를 사용한 CDAL-RL 입니다.
7. CNN이 공간적 맥락을 파악할 수 있도록 넓은 receptive field를 가진 건 분명하지만, 공간적으로 가까이 있는 클래스 사이 간섭은 예측값을 더욱 모호하게 만들게 됩니다. 저자는 이러한 class-specific confusion을 정의하여 예측값의 ambiguous를 정량화하고자 하였습니다.
8. 저자가 제안한 CD는 기존 방법론들에 추가적으로 접목되어, segmentation, detection, classification task에서 상당한 성능 개선을 이루었습니다.
리뷰를 읽다 보니 object 근처에 무엇이 있는지도 중요한 요소라는건 이해했는데, 이게 왜 ‘되도록 다양한 물체가 포함된 이미지를 선택하는것이 중요하다’로 이어지는지 흐름이 이해하기 어렵습니다. 혹시 이 부분에 대해 추가적인 설명을 해 주실 수 있으실까요?
안녕하세요 허재연 연구원님 좋은 질문 감사합니다.
저의 리뷰 내용을 굳이 안보고 재연님 요약문만 봐도 될 정도로 잘 요약을 하셨군요 … 허허
한 가지 보완할 부분만 언급하고 질문에 답변드리도록 하겠습니다.
[2] “‘Uncertainty’는 모델 예측 신뢰도(Confidence)가 얼마나 낮은지를 기준으로 데이터를 선별하는 것인데” 라고 하셨는데, Uncertainty 기반의 방법론 중 예측 신뢰도를 사용하지 않는 경우도 존재합니다! 하나의 예시로 봐주시면 좋을 것 같습니다.
이제 질문에 대해 답변드리도록 하겠습니다. 우선 object 근처에 어떤 것이 있는지에 따라 중요한 지는 이해하셨으니 이를 기반으로 설명드리겠습니다. 보행자 주변에 Fence, Bicycle 등 어떤 것이 있는지에 따라 성능이 좌지우지 될 겁니다. 그런데 모델이 계속 Fence 이 주변에 있는 이미지만 선택하게 된다면 바이어스될테니, 조금더 클래스가 다양한 이미지를 선택하겠다는 의미입니다. 그렇기 때문에 ‘되도록 다양한 물체가 포함된 이미지를 선택하는 것이 중요하다고’ 서술한 것이죠! 답변이 되었기를 바랍니다!