
안녕하세요, 로보틱스 팀 양희진이라고 합니다. 이번에도 6D pose estimation 논문을 리뷰해보았습니다. 해당 논문은 이전에 리뷰한 PoseCNN에 DeepIM을 적용(?)하여 2018년 당시 SOTA를 달성한 논문입니다. 하지만, 이번 리뷰는 참고할 블로그나 글이 없어 악으로 깡으로 논문을 최대한 이해해보려고 했습니다. 최대한 내용을 풀어서 작성을 하였으니 이해하시는 데에 도움이 되셨으면 좋겠습니다.
오역이 있을 수도 있습니다.
매번 리뷰를 작성할 때, 제가 몰랐던 개념을 연구원분들과 공유하기 위해 Background Knowledge에 담으려고 하니 리뷰를 읽으실 때 참고하시면 좋을 것 같습니다.
Background Knowledge
- ICP(Iterative Closest Points)
- 카메라, 라이다 등을 통해 생성된 3차원 point cloud를 정합하여 실내외 지도를 만드는 데에 핵심적으로 활용되는 알고리즘입니다.
- SLAM(Simultaneous Localization and Mapping)은 ICP를 응용 목적에 따라 수정해 개발한 것이라고 합니다.
- SE3(reference – Lie Theory)
- Special Euclidean Group을 의미합니다. 3D Cartesian space에서 모든 적절한 rigid transformation의 group은 SE 입니다.
- Lie Group 중 하나로, 3차원 공간 상에서 강체의 변환과 관련된 행렬과 닫혀 있는 연산들로 구성된 Group을 의미합니다.
- FlowNetSimple(paper)
- FlowNet의 제일 초기 버전을 의미하는 것 같습니다.
- 딥러닝을 이용하여 optical flow를 estimation하는 network입니다.
- 아래 그림과 같이 픽셀 단위의 움직임(motion)을 나타내는 Vector map(Pixel Displacement)를 의미합니다.

Abstract
영상으로부터 object의 6D pose estimation을 하는 것은 다양한 어플리케이션에서 사용됩니다. 예를 들어, 로봇의 manipulator나 VR(Virtual Reality)에서 사용된다고 합니다. 하지만 이런 pose estimation을 위해서는 영상으로부터 regression을 해야하는데 어려움이 따르게 됩니다. rendered 영상을 입력 영상과 매칭시키면 정확한 결과를 얻을 수 있습니다. 이 논문에서는 DeepIM 이라는 새로운 딥러닝 신경망을 제안하게 됩니다.
pose estimation을 처음에 할 때, 해당 네트워크는 랜더링된 영상과 obseved 영상에 대해 매칭하는 것에 대한 pose를 반복적으로 refinement 할 수 있도록 설계되어 있습니다. 이러한 네트워크는 3D location과 3D rotation의 untangled representation과 반복적인 학습 과정을 사용하여 상대적인 pose transformation 예측하도록 학습을 진행합니다. 실험은 2가지의 벤치마크 데이터셋을 이용하였고 DeepIM이 해당 데이터셋들에서 SOTA를 달성하였다고 합니다.
1. Introduction
영상으로부터 물체의 위치를 localizaing하는 것은 현실 세계에서 중요한 역할을 합니다. 예를 들어 로봇의 매니퓰레이터 관점에서 봤을 때 물체의 6D pose 이용하는 task가 있습니다. 해당 task를 해결하기 위해서는 물체를 어떻게 잡을지가 있을 것이고 경로 계획(motion planning)이 있을 것입니다. 다른 예를 들면, VR 어플리케이션에서는 6D pose estimiation이 사람과 object간의 virtual interaction을 할 수 있습니다. 하지만, 그 당시에는 depth 카메라를 사용하여 object pose estimation을 하는 기법들을 사용하였습니다. 이러한 카메라 들은 한계가 있습니다. Frame rate, filed of view(FOV), resolution, depth range 이러한 한계들이 있었고 작고, 얇고, 투명하고, 빠르게 움직이는 object에 대해 detection하는 것이 어려운 한계가 있었습니다. 6D object pose estimation을 위해 단일 컬러 영상만 사용하는 것은 여전히 문제였고, 영상에서 나타나는 물체는 factor에 따라 달라지는 현상이 있습니다. 여기서 나오는 factor는 lighting, pose variation, occlusion이 있습니다. 추가적으로 robust한 6D pose estimation을 하기 위해서는 texture, textureless object에 대해서도 잘 handling 할 수 있어야 합니다.
이러한 6D pose estimation을 위한 문제들은 object의 3D model에 대해 추출된 local feature들에 대한 매칭으로 해결되었습니다. 2D와 3D의 correspodence를 이용하여 object의 6D pose estimation을 보완할 수 있게 됐습니다. 하지만 해당 방법도 적은 local feature로 인해 textureless object에 대해서 handling 할 수 없는 상황에 직면하게 됩니다. textureless object를 handling하기 위해서는 2가지 접근법이 제안되었습니다.
첫 번째 방법은 입력 영상에서 object의 keypoint 또는 픽셀의 3D 모델 좌표를 추정하는 방법을 학습하는 것입니다. 해당 방법으로 6D pose estimation을 위해 2D-3D간의 대응이 설정됩니다.
두 번째 방법은 6D pose estimation의 문제를 pose space를 discretizing 하여 pose classification 문제 또는 pose regression 문제로 바꾸는 방법입니다. 해당 방법을 통해 textureless object를 다룰 수 있게 됩니다. 하지만, 이런 방법으로도 pose estimation의 높은 정확도를 얻을 수 없습니다. classification, regression를 할 때. 작은 오류는 pose estimation mismatching으로 직접적으로 이어지기 때문입니다. 이런 흔한 방법들을 통해 pose estimation의 성능을 높일 수 있었습니다.
해당 논문에서 제안한 DeepIM은 딥러닝 기반의 6D pose matching을 위한 반복적인 과정을 수행하는 기법입니다. Test image내에 있는 object에 대해 6D pose estimation 을 수행할 때, 해당 모델은 상대적인 SE(3) Transformation을 예측하게 됩니다. 해당 SE(3) transformation은 object의 렌더링된 view에 따른 matching을 하도록 합니다. 반복적인 re-rendering을 수행함으로써 pose estimation의 성능이 올랐는데, 두 개의 입력 영상은 네트워크를 통과하고 좀 더 비슷한 결과를 낼 수 있었고다고 합니다. 즉, 해당 네트워크는 좀 더 정확한 pose estimation의 결과를 보여주는 것을 의미합니다.
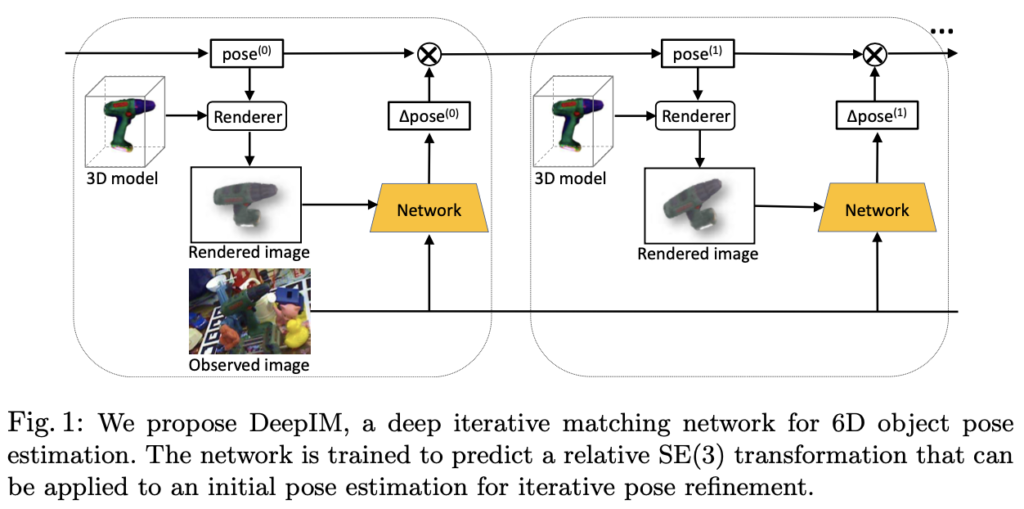
위 그림1은 pose refinement를 위한 반복적인 matching을 수행하는 네트워크 구조를 그림으로 나타낸 것입니다.
저자는 다음과 같은 contribution이 있었다고 합니다.
- hand-crafted가 아닌 내부에서 자동으로 refinement mechanism을 수행하도록 함.
- SE(3) transformation의 untangled representation을 통해 object pose의 정확도 향상
- LINEMOD, Occluded-LINEMOD 데이터셋에 대해 SOTA를 달성하였음
2. Related work
RGB-D based 6D Pose Estimation
해당 RGB-D와 같은 경우는 depth 정보가 있습니다. 이러한 depth와 컬러 영상을 합치면 pose estimation의 성능이 향상되는 것을 아실 거라 생각합니다. depth 영상을 point cloud로 변환하는 방법을 이용하여 3D model과 3D point cloud를 서로 matching을 하게 됩니다. 예를 들면, object의 3D model을 렌더링 하여 templete으로 만들고(벡터장으로 만듦) 해당 templete을 ponit cloud에서 계산된 normal vector 와 비교합니다. 3D model의 3D coordinate를 영상 내에 존재하는 물체에 대해 regression을 수행합니다. depth image가 사용 가능할 때, 3D coordinate를 regression 하는 것은 3D scene point와 3D model point 사이의 correspondence를 만듭니다. 해당 문제는 6D pose estimation은 least-square로 계산됩니다. pose refinement를 하기 위해선 ICP(Iterative Closet Point) 알고리즘이 넓게 initail pose estimate에서 사용되고 있습니다. 하지만, ICP알고리즘은 initial estimatioon을 하기에는 민감하다고 합니다. 그리고 local minima에 빠질 수도 있다고 합니다.
RGB based 6D Pose Estimation
보통 단일 컬러 영상에 대한 pose estimation은 local feature 이용한 matching으로 다루어 졌습니다. 하지만 이러한 기법으로는 textureless object에 대해서는 잘 다룰 수 없는 한계가 있습니다. SOTA 를 이룬 방법론은 딥러닝을 기반한 object detection 또는 segmentation 기법들을 pose estimation을 하기 위해 사용되었습니다. 하지만 이러한 기법들은 여전히 RGB-D 기반의 기법과 성능 차이가 크게 납니다. 저자는 어떻게 하면 이렇게 큰 성능 차이를 줄일 수 있을지에 대한 방법을 생각하게 됩니다. 해당 논문에서 제안하는 iterative pose matching network를 통해 단일 컬러 영상에 대해서 pose refinement를 하였습니다. 해당 네트워크 구조는 상대적인 SE(3) transformation을 regression하는 수행하도록 설계되었습니다. 이렇게 하는 이유는 rotation, translation에 대한 untangled representation을 하기 위함과 회전에 대한 reference frame 덕분에 이를 통해 보이지 않는 물체를 일치시킬 수 있습니다. reference frame은 pose estimation의 성능 향상에 중요한 역할을 한다고 합니다.
3. DeepIM Framework
먼저 네트워크의 입력으로 사용되는 observed이미지와 redered 이미지를 확대하는 전략을 제시합니다.
3.1. High-resolution Zoom In

만약 입력 영상이 매우 작으면 영상 내의 object가 매우 작을 것입니다. pose estimation하기 위해 디테일한 정보를 얻기 위선, 저자는 그림 2와 같이 observed image와 rendered 이미지를 네트워크에 전달하기 전에 확대합니다. 특히. iterative matching의 i번째 단계에서, 이전 단계의 6D pose estimaiton이 주어지면, p^{(i-1)} 에 따라 본 3D ojbect 모델을 사용하여 synthetic image에 대해 렌더링을 진행합니다. 추가적으로 배열에 observed image와 rendered image에 대한 마스크를 생성합니다. 4개의 영상들은 observed/rendered mask에 따라서 큰 bounding box로 되어 crop이 된 상태로 사용이 됩니다. bounding box는 같은 입력 영상과 같은 aspect ratio를 가지도록 합니다. 또한 해당 bounding box는 3D model의 원점에 대하여 2D projection으로 중심을 맞춥니다. 마지막으로 zoom in을 할 때는 bilinear up-sampling을 하여 원본 영상과 같은 사이즈로 만들어주었다고 합니다. 여기서 중요한 점은 object에 대한 aspect ratio는 해당 operation을 수행할 때는 변하지 않습니다.
3.2. Network Structure
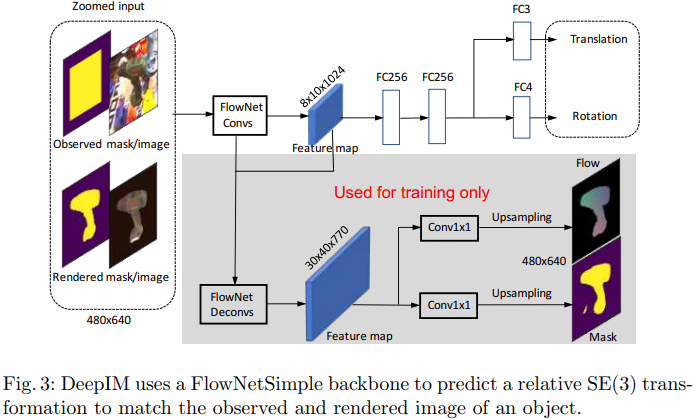
입력 이미지를 보시면 8개의 채널로 된 tensor가 입력으로 들어가게 됩니다. 8개의 채널은 각각 observed : 3채널, mask : 1채널을 의미하고 concat을 하여 8개의 채널을 의미합니다. FlowNetSimple 모델을 backbone으로 사용하고 해당 backbone에서는 두 영상 사이에서 optical flow을 예측하도록 학습을 진행합니다. 뜬금없이 FlowNetSimple을 왜 썼는지에 대한 설명도 저자는 설명합니다. VGG16으로 backbone으로 사용했는데 결과가 매우 안 좋았다고 합니다. 해당 결과를 통해 optical flow와 관련있는 representation은 pose matching에 매우 중요한 역할을 하는 것을 알게되었다고 합니다. pose estimation을 하는 branch에서는 11개의 convolution layer로부터 feature map을 생성한다고 합니다. 마지막의 2개의 FC layer은 각각 3D rotaion과 3D translation에 대한 quarternion을 예측하도록 설계되었습니다. 학습을 할 때는 2개의 auxiliary branch를 사용한다고 합니다. 해당 branch는 feature representation에 대해 regularization을 하는 효과를 주어 학습이 안정적으로 되게끔 설계가 되었다고 합니다.
3.3. Untangled Transformation Representation
relative SE(3) transformation인 \Delta p는 current pose estimate와 target pose 사이에는 network 성능에 영향이 있습니다.
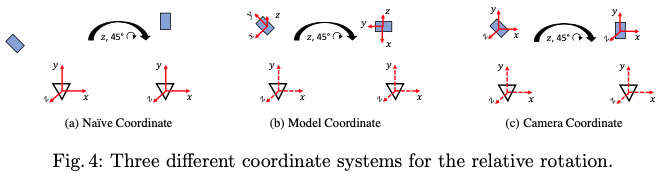
그림4는 각각의 relative rotation에 대한 coordinate system을 나타내는 그림입니다. 카메라 좌표(그림4(a). Naive Coordinate)에서 object pose와 transformation을 나타내는 것을 생각해보면 relative rotation과 translation은 [R_{\Delta}|t_{\Delta}]로 나타내고, source object의 pose를 [R_{\\src}|t_{\\src}] 라고 할 때 변환된 target pose 다음과 같이 나타낼 수 있습니다.
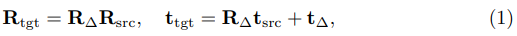
R_{\\tgt}, t_{\\tgt}는 target에 대한 pose를 의미합니다. t_{\\tgt}에서 R_{\Delta}t_{\\src} term은 rotation으로 인해 object가 회전할 뿐만 아니라 translation vector인 t_{\Delta}=0 인 경우에도 영상에서 변화가 된다는 것을 의미한다고 합니다. 또한, translatation(t_{\Delta})은 3D space에서 object의 크기와 거리를 연결해야하므로 network는 object의 크기를 기억해야 합니다. 하지만 이러한 representation은 적절하지 않습니다. 이러한 문제들을 없애기 위해 저자는 R_{\Delta}와 t_{\Delta}를 분리하는 것을 제안합니다. rotation의 경우, 카메라 원점에서 current pose estimation 값으로 주어진 카메라 프레임의 object 중심으로 회전 중심을 이동하고 rotation은 카메라 프레임에서 object의 translation이 바뀌지 않도록 합니다. 이제 rotation을 할 coordinate의 축은 어떻게 선택해야 할까요?
한 가지 방법은 3D object 모델에 지정된 좌표계 프레임의 축을 사용하는 것입니다. 그림4의 (b) Model coordinate 입니다. 하지만, 이러한 representation은 network가 각 object의 coordinate frame을 기억해야 하므로 학습을 더 어렵게 만들고 보이지 않는 object의 매칭되는 pose로 일반화 할 수 없는 상황에 처하게 됩니다. 이러한 문제를 고려하여 저자는 relative rotation을 계산할 때 camera frame의 축과 평행한 축을 사용합니다. 그림4의 (c) camera Coordinate 입니다. 해당 축을 사용하는 경우 network는 3D object model의 coordinate frame과 독립적으로 relative rotation을 잘 estimation 할 수 있도록 학습할 수 있게 된다고 합니다.
translation 을 estimation하기 위해서는 일반적으로 target과 source의 오차를 구하여 얻을 수 있지만 3D space에 있는 relative translation를 구하기에는 depth 정보가 없는 단일 2D image로는 구하기가 쉽지 않습니다. object의 크기를 알아야하고, 물체에 따른 2D에서 3D에 대한 translation map을 recognition 할 수 있어야 합니다. 이러한 representation은 network가 학습하기 어려울뿐만 아니라, 겉모습은 비슷하지만 크기는 다른 unknown object나 일반적인 object를 다룰 때 문제가 발생합니다. network가 3D 공간의 벡터로 직접 regression 하도록 훈련하는 것 대신에, 저자는 2D 이미지 공간의 object change로 regression 하는 것을 제안합니다. 좀 더 구체적으로 말하면 network가 상대적인 변환인 t_\Delta = (v_x, v_y, v_z) 로 regression 하도록 학습하도록 합니다. 해당 notation에 대해 설명을 하자면, (v_x, v_y) 는 x축 및 y축을 따라 object가 이동해야 하는 픽셀의 수를 의미하고 v_z는 object의 스케일 변화를 의미합니다.
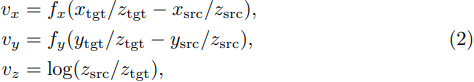
(2)식에서 (f_x, f_y)는 카메라의 focal length 를 의미합니다. 스케일 변화를 의미하는 v_z는 rendered object와 observed object의 거리 사이 비율을 사용하여 객체의 크기 또는 거리와 독립적으로 정의합니다. v_z에 대한 로그(logarithm)를 사용하여 값 0이 크기 또는 거리에 영향이 있는지 확인합니다. 특정 데이터셋에 대해 f_x와 f_y가 일정하다는 사실을 알아내어 학습과 테스트에 대한 과정에서는 1로 고정시켰다고 합니다.
저자가 제안한 relative transformation의 representation은 다음과 같은 advantage가 있습니다.
- rotation은 translation을 estimation하는 데에 영향이 없으므로 translation은 더이상 카메라 중심에 대한 rotation을 통한 movement에 대해 상쇄할 필요가 없습니다.
- (v_x, v_y, v_z)로 간단하게 image space에서 translation과 scale변화에 대해서 representation을 할 수 있습니다
- 위의 representation을 사용하면 사전적으로 object에 대한 knowledge에 대해서 필요하지 않습니다. 해당 representation을 사용하여 DeepIM network는 object의 실제 크기와 내부 모델의 좌표 프레임워크와 독립적으로 작동할 수 있습니다. 즉, rendered image가 observed image와 더 유사하도록 변환하는 방법만 학습하면 됩니다. 여기서 말하는 knowledge는 3.5 에서 설명을 하도록 하겠습니다.
3.4. Matching Loss
DeepIM의 loss function은 rotation, translation에 대해서 각각 분리하여 사용합니다. 예를 들어, 두 회전 사이의 각도 거리를 사용하여 rotation에 대한 오차를 측정하고 L2-distance를 사용하여 translation에 대한 오차를 측정할 수 있습니다. 하지만 이렇게 두개의 다른 loss function을 각각 사용하면 두 개의 loss에 대해서 blance를 맞추기 어려운 상황에 처하게 됩니다. 이전 연구에서 geometirc reprojection 이라는 방법을 제안 되었습니다. pose regression을 위한 loss function으로, GT(Ground Truth) pose를 이용한 scene에 있는 3D point의 2D projection과 estimated pose 사이의 average distance를 계산합니다. 저자는 좀 더 정확한 3D pose의 예측을 위해 수정된 geometic reprojection loss 를 사용하였고, 이러한 loss를 Point Matching Loss라고 칭합니다. 주어진 GT의 pose를 p=[R|t] 라하고, estimation된 pose를 \hat p = [\hat R|\hat t]라고 할 때 Loss function은 다음과 같이 정의합니다.
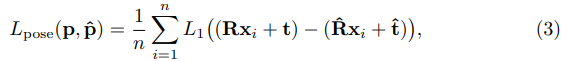
(3)식에 있는 x_i는 object 모델에서 무작위로 선택된 3D point를 의미하고 n은 total point 수를 의미합니다. 실험에서는 3000개의 point를 선택했다고 합니다. Point matching loss는 GT pose에 의해 변환된 3D point와 estimate pose 사이의 average L1-distance를 사용하였다고 합니다.
3.5. Training and Testing
DeepIM의 학습과 테스트는 어떻게 진행하는지에 대해 알아보도록 하겠습니다.
Training
3D object 모델과 GT가 6D object pose로 annotation되어있는 이미지를 가지고 있다고 가정했을 때, GT pose에 noise를 초기의 pose에 추가함으로써, GT pose와 noise pose 간의 pose 차이인 pose 대상의 출력과 함께 필요한 rendered input과 observed input을 network에 생성시킬 수 있습니다. 그 다음에 해당 network는 학습을 진행하게 되고 initial pose와 target pose간의 relative transformation을 예측할 수 있게 됩니다.
Testing
저자는 iterative pose의 refinement가 정확도를 크게 향상시킬 수 있음을 알게 되었습니다.
p^{(i)}를 network의 i 번째 반복 후의 pose estimation 값이라고 할 때, initial pose estimation인 p^{(0)}이 correct pose로부터 상대적으로 멀리있는 경우 rendered image인 x_{\\rend}(p^{(0)})는 observed image인 x_{\\obs} 와는 단지 약간의 viewpoint에 대한 overlap만 있습니다. 이러한 경우는 relative pose transformation인 \Delta p^{(0)}를 직접 정확하게 추정하는 것은 어려운 상황입니다. 해당 문제는 network가 일치시킬 object에 대한 사전의 knowledge가 없다면 훨씬 더 어렵습니다. 일반적으로, 네트워크가 i 번째 반복으로 p^{(i)}를 \Delta p^{(i)}로 업데이트하여 pose estimation인 p^{(i+1)}를 개선한다면 해당 새로운 estimation에 따라 이미지가 rendering이 된다고 가정하는 것이 합리적이라고 합니다. 또한 x_{\\rend}(p^{(i+1)})은 x_{\\rend}(p^{(i)})가 이전 반복에서 있던 거 보다는 observed image(x_{\\obs})와 더 유사하므로 즉, 더 정확하게 일치시킬 수 있는 입력을 제공하게 됩니다.
하지만, 저자는 single step에서 relative pose를 regression하도록 network를 학습시키는 경우 학습된 network의 estimation 결과가 테스트에서 여러 번을 반복해도 개선되지 않는 것을 발견하게 됩니다. 테스트와 유사한 학습을 위해서 현실적인 데이터에 대한 분포를 생성하기 위해서 학습 중에서도 여러 번의 반복을 수행하도록 했다고 합니다. 즉, 각 학습을 위한 영상과 pose에 대해 network에서 예측된 transformation을 pose에 적용하고, 변환된 pose estimation을 다음 반복에서 network에 대한 또 다른 훈련 예시로 사용합니다. 이러한 과정을 여러 번 반복하여 학습 데이터는 테스트에 대한 분포를 더 잘 나타낼 수 있게 되었고 학습된 network는 반복적인 테스트 중에 훨씬 더 나은 결과를 얻을 수 있었다고 합니다.
해당 접근법은 iterative hand pose matching 방법에도 유용하게 사용된다고 하는 것을 보아 해당 기법을 통해 영감을 얻어 문제를 해결한 것으로 보입니다.
4. Experiments
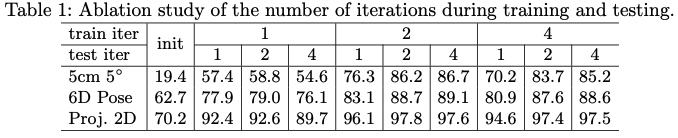
테이블1은 iteration에 대한 성능 평가입니다. 좌측의 5cm \ 5^{\circ}, 6D pose, Proj. 2D는 evaluation metrics를 의미합니다.
- 5cm \ 5^{\circ}rotation에 대한 오류가 5^\circ 이내이고 transformation 오류가 5cm 미만인 경우 estimation이 정확한 것으로 간주합니다.
- 6D poseestimated pose와 GT pose를 사용하여 변환된 3D 모델의 포인트 사이의 거리의 평균을 구합니다. 이전에 제가 리뷰했던 PoseCNN에서 다루었던 ADD evaluation metrics입니다.
- Proj. 2Destimated pose와 GT pose를 사용하여 영상에 projection된 3D 포인트의 평균 거리를 계산합니다. 평균 거리가 5픽셀보다 작으면 estimated pose가 정확한 것으로 간주합니다.
evaluation metrics를 알아보았으니, 이제 iteration에 대한 성능 평가를 확인해보겠습니다. 해당 표를 보시면 좀 이상합니다. iteration을 많이 반복하면 더 성능이 좋을 것 같은데 train_iter=2, test_iter=2가 오히려 train_iter=4, test_iter=4 보다 성능이 더 좋은 것을 볼 수 있습니다. 해당 결과는 LINEMOD 데이터셋이 3회 또는 4회의 반복을 진행하여 추가적인 성능을 개선하기에는 충분히 어렵지 않은 데이터이기 때문에 그럴 것이라고 저자는 생각합니다. 각 데이터셋에서 사용할 반복 횟수를 결정하는 것이 간단하지 않기 때문에 다른 모든 실험에서 학습 및 평가에 대해 4회 반복을 고정으로 사용하기로 했다고 합니다.
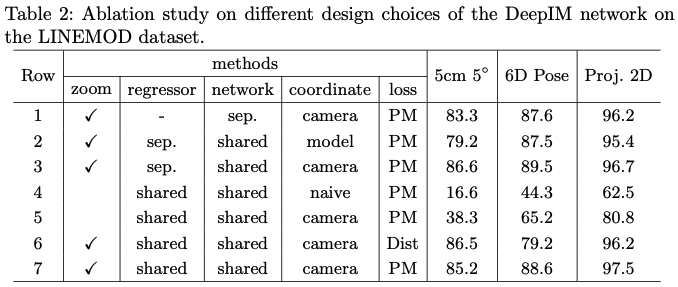
- zoom
전체 이미지를 입력으로 사용하는지 아니면 원래 이미지 크기로 upsampling된 zoom in 된 bounding box를 사용하는지를 의미합니다. 5, 7 행을 비교했을 때 high-resolution을 적용했을 때 성능이 큰 폭으로 증가한 것으로 볼 수 있습니다.
- regressor
여기서 나오는 regressor는 모든 object에 대해 공통적으로 학습을 하여 특정 입력 object와 독립적인 pose 변환을 생성하는 경우 “shared”라고 표기되어 있고, 그림3에 있는 최종 FC256 layer 다음으로 각 object에 대해 별도의 FC layer를 사용하여 각 개별 object에 대해 서로 다른 6D pose estimation regression을 수행한 경우 “sep”으로 설정을 하였다고 합니다. 이를 비교한 것은 3, 7행을 서로 비교해보면 두 접근 방식이 거의 구별할 수 없는 결과를 제공하지만, 저자는 shared network가 약간의 효율성을 제공한다고 말합니다.
- coordinate
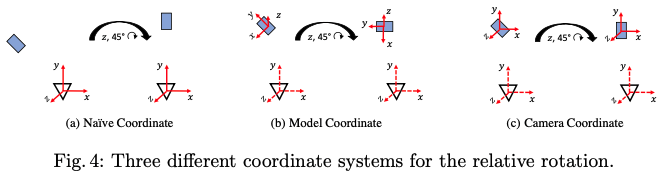
그림4의 coordinate들에 따른 성능 비교를 위한 열입니다.
- naive는 object pose에 대한 representation으로, 카메라의 reference frame을 선택할 때 결과를 제공한다고 합니다.
- model은 rotation의 중심을 object model로 이동시키고 object model의 coordinate frame을 선택하여 rotation을 예측합니다.
- camera는 rotation을 위한 camera coordinate frame을 유지하면서 중심을 object 모델로 이동하는 접근 방식입니다.
먼저 2, 3행을 비교해보면 model vs camera인데 camera roation이 좀 더 성능이 좋은 것을 알 수 있습니다.
또한, 저자는 “camera”의 접근방식만이 보이지 않는 unseen object에 동작하는 점을 유의해야 한다고 합니다. 4행과 5행을 비교해보면 naive를 카메라를 reference frame으로 선택하여 예측하는 naive 접근법 보다는 camera coordinate representation이 큰폭으로 성능이 향상된 것을 알 수 있습니다.
- loss
“Dist”는 Distance Loss를 의미하며, 일반적으로 사용되는 evaluation metrics입니다. “PM”은 Point Matching Loss를 의미합니다.
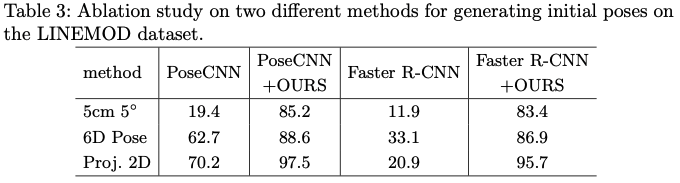
테이블3은 다른 pose estimation network로 DeepIM을 initialization할 때의 결과를 제공하는 표입니다.
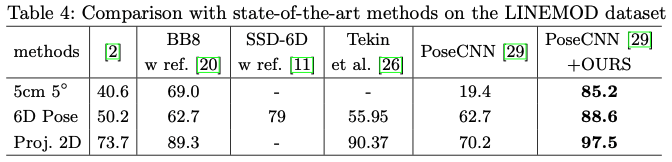
테이블4를 보시면, 다른 이전의 SOTA 모델들과 비교했을 때, PoseCNN + DeepIM가 성능이 좋은 것을 볼 수 있습니다.
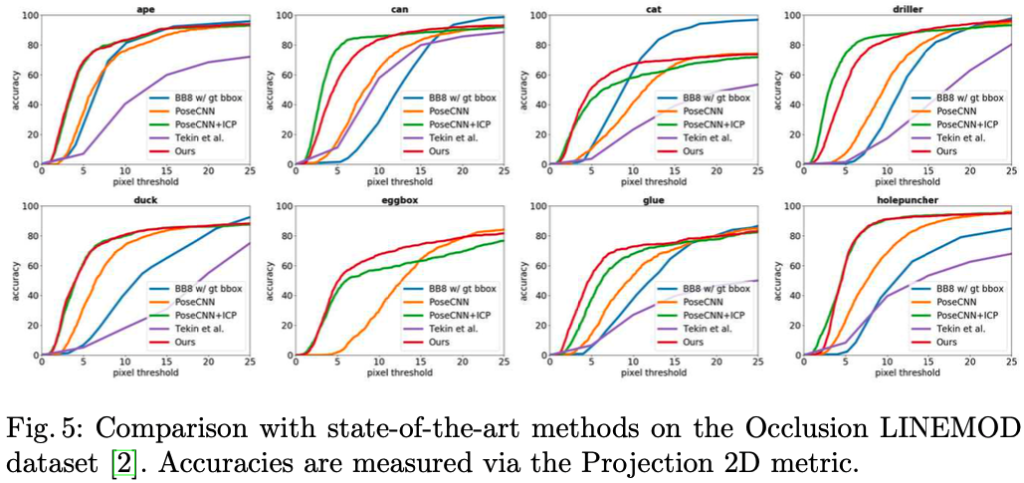

그림5는 SOTA 모델을 OcclusionLINEMOD 데이터셋에서 비교한 모습입니다. 해당 표의 evaluation metrics는 Proj 2D라고 합니다. 그림5에 있는 라벨에 대한 결과를 그림6에서 시각화를 통해 보여주는 그림입니다.
5. Conclusion
이번 논문에서는 DeepIM 이라는 새로운 오직 컬러 이미지만으로 iterative pose matching을 하는 framework를 소개했습니다. object의 6D pose estimation이 초기에 주어졌을 때, pose estimation을 refinement하는 relative pose transformation을 직접 output으로 나오도록 새로운 network를 설계하였습니다. 해당 network는 자동으로 학습하는 동안 object pose를 matching 시킵니다. 또 untangled pose representation이라는 개념을 도입하여 3D object의 크기, coordinate frame과도 무관하도록 하였습니다. 이러한 접근법을 사용하면 unseen object에 대해서도 mathcing을 시키는 것을 실험을 통해서 보았습니다. 여러가지 SOTA 모델들과 비교하였을 때, 해당 방법을 사용하여 좀 더 성능을 개선하였습니다.
저자는 stereo vision을 사용한 DeepIM은 pose estimation을 하는 것에 대해 좀 더 향상된 pose estimation 결과를 낼 것으로 기대합니다. 또 DeepIM은 단일 컬러 이미지만 사용하여 정확한 6D pose estimation을 생성할 수 있음을 나타내면서 넓은 시야로 높은 속도로 고해상도 이미지를 캡처하는 카메라를 사용할 수 있기 때문에 로봇의 manipulator와 같은 여러가지 어플리케이션에서도 유용하게 estimation을 할 수 있을 것이라고 합니다.
안녕하세요. 리뷰 감사합니다.
희진님의 악으로 깡으로 리뷰한 글 잘 보았습니다ㅎㅎㅎ설명이 튼실해서 덕분에 이해하지 못하고 넘너간 부분이 적었던 것 같습니다. 궁금한 점이 있는데요. fig 3를 보면 observed mask/image, rendered mask/image가 입력으로 들어가는 것을 확인할 수 있는데 mask는 어떻게 생성이 되는 걸까요? 단순히 배열에 마스크를 추가한다는 표현으로만 작성하여서 어떻게 masking을 진행하는지 궁금하네요. (설마 사람이 직접 masking하는 것은 아닐것 같아 질문드립니다)
감사합니다
안녕하세요, 주연님. 리뷰 읽어주셔서 감사합니다.
해당 부분에 대한 자세한 설명은 논문에 나와있지는 않지만, 제 생각으로는 해당 논문은 PoseCNN에 DeepIM을 추가적으로 사용하여 성능을 향상시켰으므로 기반은 PoseCNN의 network를 사용하고 난 이후의 과정이라고 생각하면 될 것 같습니다. PoseCNN의 과정 중 segmentation 과정과 bounding box 외에는 배경으로 처리하는 과정을 사용하여 각각 observed mask, rendered mask로 사용한 것으로 보입니다.
감사합니다.
좋은 리뷰 감사합니다.
친절한 설명 덕분에 이해가 잘 되었습니다.
리뷰를 읽으며 몇가지 궁금한 점이 생겨 질문 남깁니다.
backbone을 optical flow로 이용했다고 하셨는데, VGG16으로 backbone으로 사용했는데 결과가 매우 안 좋았다는 결과는 다른 논문을 인용한 것인지 궁금합니다. 또한, optical flow와 관련있는 representation이 어떤것인지 논문에 설명이 되어있는지 궁금합니다. 혹은 다른 segmentation 백본이나 다른 task를 적용해보려는 시도는 없었는 지 궁금합니다.(segmentation의 백본도 VGG16과 같은 네트워크일 수 있으나 segmentation을 위해 학습된 backbone을 사용할 경우 잘 나올 수 있지 않을까 하는 생각이 들었습니다.)
마지막으로 해당 논문의 중요 컨셉 중 하나가 refinement를 반복적으로 수행하는 것으로 보이는데, 그렇다면 real-time요소는 고려하지 않는 것인지도 궁금합니다.
안녕하세요, 승현님. 리뷰 읽어주셔서 감사합니다.
1. backbone을 optical flow로 이용했다고 하셨는데, VGG16으로 backbone으로 사용했는데 결과가 매우 안 좋았다는 결과는 다른 논문을 인용한 것인지 궁금합니다.
-> 해당 논문에서 실험한 결과, 안 좋았다고 합니다. 해당 실험을 통해 optical flow와 관련된 representation이 pose matching에 유용하다는 것을 알게 되었다고 합니다.
2. optical flow와 관련있는 representation이 어떤것인지 논문에 설명이 되어있는지 궁금합니다.혹은 다른 segmentation 백본이나 다른 task를 적용해보려는 시도는 없었는 지 궁금합니다.(segmentation의 백본도 VGG16과 같은 네트워크일 수 있으나 segmentation을 위해 학습된 backbone을 사용할 경우 잘 나올 수 있지 않을까 하는 생각이 들었습니다.)
-> segmetation의 결과는 이미 PoseCNN을 통해 얻었으므로 추가적인 representation을 이용하기 위해 optical flow라는 개념을 도입한 것 같습니다. 해당 optical flow에 대한 자세한 내용이나 representation은 설명이 되어있지 않아 찾아본 결과 해당 FlowNetSimple 이 영상 내 object의 optical flow를 예측하는 network이므로 해당 network를 사용한 것으로 보입니다. segmentation의 정보만으로는 성능을 향상시킬 수 없어 이러한 과정을 한 것으로 고찰하고 있습니다.
3. 해당 논문의 중요 컨셉 중 하나가 refinement를 반복적으로 수행하는 것으로 보이는데, 그렇다면 real-time요소는 고려하지 않는 것인지도 궁금합니다.
-> 아쉽게도 해당 논문에 나와있는 모든 실험에 대한 결과에 inference time에 대한 이야기는 없습니다.
감사합니다.
좋은 리뷰 감사합니다.
간단히 질문 드리자면 수식(2)에서 vx, vy는 object의 translation에 대한 식이고 vz는 object scale 변화를 나타내는 식인 것으로 이해를 했습니다만, 그러면 보통 6d pose estimation에서는 각각 x,y,z축에 대한 회전(roll,pitch,yaw)을 예측하는 것으로 알고있는데 vx,vy,vz는 각 축에대한 회전과는 어떻게 관련이 있는건가요? 그리고 평가 metric에서 6D pose는 예측된 pose와 GT pose간 변환된 3D 모델의 포인트 사이의 거리의 평균이라고 하셨는데 이 값이 그럼 특정 범위 내 값을 가지는건가요 아니면 데이터 셋이나 평가하는 모델마다 달라지는 건가요? 예를 들어 accuracy의 경우 0~100사이를 갖는 것처럼 어떤 특정 범위가 정해져있는지 궁금합니다.
감사합니다.
안녕하세요, 도경님. 리뷰 읽어주셔서 감사합니다.
1. 수식(2)에서 vx, vy는 object의 translation에 대한 식이고 vz는 object scale 변화를 나타내는 식인 것으로 이해를 했습니다만, 그러면 보통 6d pose estimation에서는 각각 x,y,z축에 대한 회전(roll,pitch,yaw)을 예측하는 것으로 알고있는데 vx,vy,vz는 각 축에대한 회전과는 어떻게 관련이 있는건가요?
-> 도경님이 말씀하신대로 v_x, v_y, v_z에 대한 정보는 맞습니다. 하지만, 식(2)은 translation을 estimation 하기 위한 식입니다. rotation에 대한 관련된 식은 식(1)을 참고하시면 될 것 같습니다. rotation에 따른 서로 다른 coordinate들을 비교하여 Camera Coordinate를 사용하면 relative rotation을 잘 estimation 할 수 있게 된다고 합니다.
2. 평가 metric에서 6D pose는 예측된 pose와 GT pose간 변환된 3D 모델의 포인트 사이의 거리의 평균이라고 하셨는데 이 값이 그럼 특정 범위 내 값을 가지는건가요 아니면 데이터 셋이나 평가하는 모델마다 달라지는 건가요? 예를 들어 accuracy의 경우 0~100사이를 갖는 것처럼 어떤 특정 범위가 정해져있는지 궁금합니다.
-> 도경님의 말씀대로 데이터셋, 모델마다 달라집니다. 일반적으로 거리 측정은 미터 단위로 이루어지므로 결과 범위는 0이상의 실수가 됩니다. estimation의 결과가 우수할수록 ADD는 0에 수렴하는 값을 나타내는 구조입니다. 점 사이 거리의 평균값이 물체 직경의 10% 이내면 옳은 것으로 간주한다고 합니다.