드디어 저도 CVPR 2023 논문 리뷰를 하네요. 오랜만에 감정인식 논문인거 같습니다. 그럼 논문 리뷰 시작하겠습니다.
<Introduction>
introduction에서는 여타 논문과 마찬가지로 Multimodal Emotion Recognition (여기에서는 MER로 줄여 말합니다)가 중요하다고 언급합니다. 논문에서는 MER의 핵심이 multimodal representation learning과 fusion이라고 말하면서 model이 여러 modality의 repretation을 encode하고 통합하여 raw data의 이면에 있는 감정을 이해하는 것을 목표로 한다고 합니다. MER의 발전에도 불구하고, 다른 modality간의 intrinsic heterogeneities는 여전히 감정 인식을 어렵게 하고 multmodal representation learning을 힘들게 만드는데요. 전형적으로 language가 다른 modality에 비해서 더 중요한 역할을 하면서 다른 modality사이에서 performance discrepancies(성능 불일치)가 발생하게 됩니다.
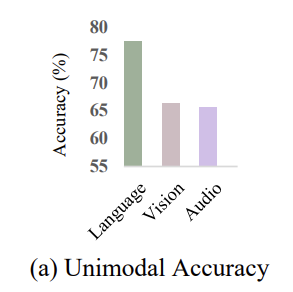
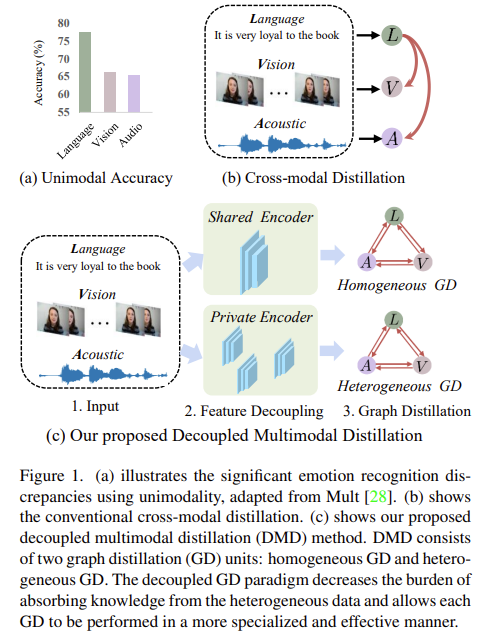
Figure 1에 (a)를 확인해보면 Language쪽이 훨씬 성능이 높은 것을 확인할 수 있죠. 논문에서는 이러한 불균형이 multimodal representation learning을 힘들게 한다고 생각하였습니다.
그리하여서 이러한 modality heterogeneities를 완화하기 위한 방법으로 strong modality에서 weak modality로 reliable하고 generalizable한 knowledge를 distill하는 것입니다. 이것을 시각화하여 설명한 것이 Figure 1에 있는 (b) 그림 입니다.
그런데 분명 문제가 있으니까 (c) 방법이 나와있는 거겠죠? 여기서는 무슨 문제가 있었을까요? (b)의 그림처럼 수동으로 distillation direction 또는 weight를 지정하는 것은 많이 번거롭다는 것입니다. 합치는 방법이 아주 다양했기 때문에 이거를 순수 지정해서 합쳐주는 것은 번거롭다는 것이지요. 또한, modality간 상당한 feature distribution mismatch로 인해서 직접적으로 crossmodal distillation을 주는 것은 최적의 방법이 아닙니다.
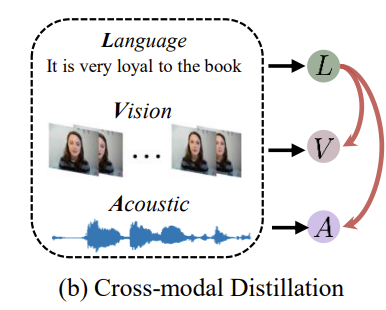
그리하여서 나온 것이 Figure 1에 있는 (c) 입니다.
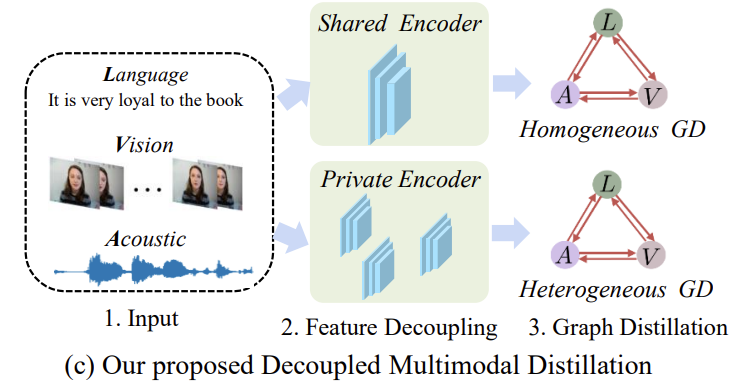
논문의 저자는 modality간의 dynamic distillation을 학습하기 위해서 decoupled multimodal distillation (DMD)를 제안합니다. 일반적으로 각 modality의 feature는 shared encoder와 private encoder를 통해 각각 modality-irrelevant, modality-exclusive space로 분리됩니다. feature decoupling을 하기 위해서 논문의 저자는 self-regresseion mechanism을 고안했는데요. 이 self-regression mehanism은 decoupled modality feature를 예측하고 그런 다음 self-supervisedly하게 regress합니다. 그런 다음 feature decoupling을 통합하기 위해서, margin loss를 사용합니다. margin loss는 modality와 감정간의 representation의 관계를 근접하게 정규화하도록 합니다. 결과적으로, decoupled GD paradigm은 heterogeneous data로부터 knowledge를 흡수하는 부담을 줄이고, 각 GD가 보다 전문적인고 효과적인 방식으로 수행되도록 합니다.
decoupled multimodal feature space를 기반으로, DMD는 graph distillation unit (GD-Unit)를 각 space에서 활용합니다. 이를 통해서 crossmodal knowledge distillation이 보다 전분적이고 효과적으로 수행될 수 있는데요. 그럼 GD-unit이 뭘까요? GD-unit은 modality로부터의 logits 혹은 representation을 나타내는 vertices와 knowledge distillation directions와 weight를 나타내는 edge로 구성된 graph 입니다. modality irrelevant (homogeneous) features의 distribution gap이 충분히 줄었기 때문에, GD는 직접적으로 inter-modality semantic correlation을 잡을 수 있습니다. modality-exclusive (heterogeneous) counterparts에 대해서는, multimodal transformer를 이용합니다. 이를 통해서 semantic alignment를 구축하고 distribution gap을 해소합니다. multimodal transformer에서 cross-modal attention mechanism은 multjmodal representation을 강화하고 다른 modality에 존재하는 high level semantc concepts간의 discrepancy(불일치, 모순)을 줄이는 역할을 합니다. 간단히 하기 위해서 논문의 저자는 decoupled multimodal feature에 대해서 distillation하는 것을 이름을 줄여 부르는데, homogeneous grap knowledge distillation (HomoGD)와 heterogeneous graph knowledge distllation (HeteroGD) 입니다.
이렇게 논문의 소개를 간단히 해봤는데요. 방법론에 대해서 본격적으로 설명하기 전에 논문의 contribution에 대해서 간략히 언급하고 넘어가 보겠습니다. 위의 내용을 압축해서 말한 거기 때문에 논문에 나와있는 그대로 한번 가져와 봤습니다.
- we propose a decoupled multimodal distillation framework, Decoupled Multimodal Distillation (DMD), to learn the dynamic distillations across modalities for robust MER. In DMD, we explicitly decouple the multimodal representations into modality-irrelevant/-exclusve spaces to facilitate KD on the two decoupled spaces. DMD provides a flexible knowledge transfer manner where the distillation directions and weights can be automatically learned, thus enabling flexible knoweldge transfer patterns.
- we conduct comprehensive experiments on public MER datasets and obtain superior or comparable results than the state-of-the-arts. Visualization results verify the feasibility of DMD and the graph edges exhibit meaningful distributional patterns w.r.t. HomoGD and HeteroGD.
<The Proposed Method>
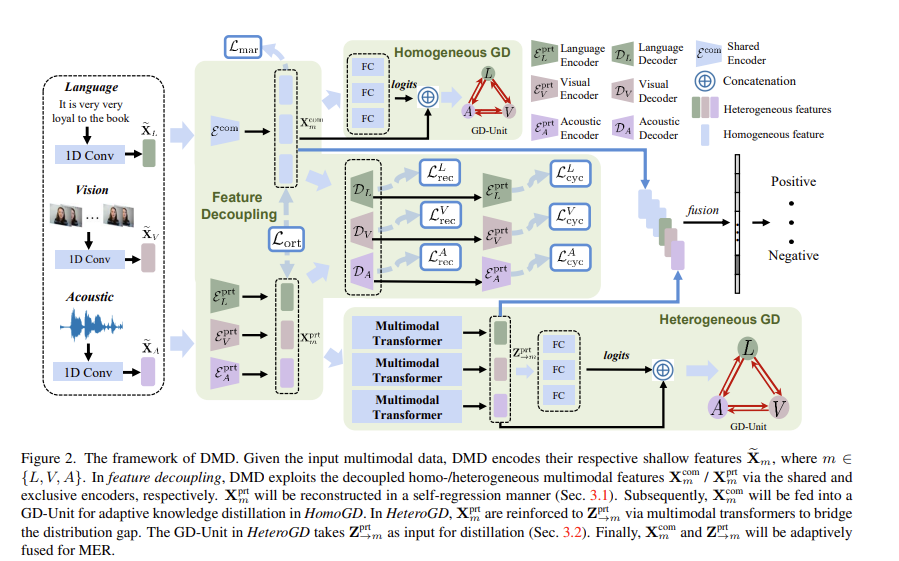
우선 구체적인 방법론을 말씀드리기 전에 이 방법론이 무엇으로 구성되어 있고 대충 어떤 순서로 작동되는지를 말씀드리고자 합니다. DMD는 3개의 part로 구성되어 있는데요. 아래와 같이 구성되어 있습니다.
- multimodal feature decoupling
- homogeneous GD (HomoGD)
- heterogeneous GD (HeteroGD)
논문의 저자들은 modality의 distribution mismatch를 고려하고자 shared multimodal encoder와 exclusive multimodal encoder를 이용하여 multimodal representation을 homogeneous multimodal features, heterogeneous multimodal features로 분리합니다. 그런다음 flexible knowledge transfer를 쉽게하기 위해서, HomoGD와 HeteroGD로 구성된 homo/heterogeneous feature에서 knowledge를 distill합니다. HomoGD에서, homogeneous multimodal features는 mutually distilled되어서 서로에 대한 representation ability를 보완합니다. HeteroGD에서는, multimodal transformers가 사용되는데, 이를 통해 명시적으로 inter-modal correlations와 semantic alignment를 구축합니다. 최종적으로, ditilling을 통해 refined multimodal features를 fuse하여 감정인식을 수행합니다.
<1. Multimodal feature decoupling>
자 그럼, decoupling 과정에 대해서 자세히 설명해봅시다. 입력으로는 language (L), visual (V), acoustic (A)를 입력으로 받습니다. 처음으로, 3개의 분리된 1D temporal convolutional layer를 통과하여 temporal information을 모으고, low-level multimodal feature를 얻습니다. \tilde{x}_m \in{\mathbb{R}^{T_m\times{d_m}}}으로 표현하고 m \in{{L, V, A}}로 각 modality를 나타냅니다. 이렇게 shallow encoding을 수행했다면 각 modality는 unagliged된 경우와 align된 경우를 동시에 쉽게 처리할 수 있도록 input temporal dimension을 보존합니다. 게다가 모든 modality는 같은 feature dimension을 가지고 있습니다. d_L = d_V = d_A = d라는 말이죠. 이는 뒤에 일어날 feature decoupling을 편하게 하기 위해서 이렇게 설정하였습니다.
multimodal features를 homogeneous (modality-irrelevant) part X_m^{com}과 heterogeneous (modality-exclusive) part X_m^{prt}로 분리하기 위해서, shared multimodal encoder \varepsilon^{com}와 3개의 private encoder \varepsilon^{prt}_m를 이용합니다. shared multimodal encoder와 private encoder는 decoupled된 feature를 예측합니다. 수식으로 표현하면 수식(1)과 같습니다.
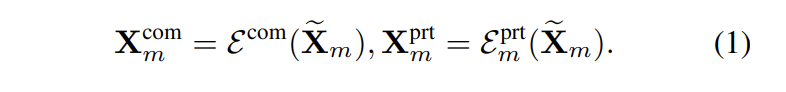
X_m^{com}와 X_m^{prt}의 차이점을 구별하고 feature ambiguity를 완화하기 위해서, vanilla coupled features \tilde{x}_m을 self-regression 방식으로 합성합니다. 수식적으로 말하면, 각 modality에 대한 X_m^{com}와 X_m^{prt}을 concat하고 D_m([X_m^{com},X_m^{prt}])과 같은 coupled feature를 만들기 위해서 private decoder D_m을 이용합니다. 이후, coupled feature는 private encoder \varepsilon^{prt}_m를 통해 re-encode되어 heterogeneous feature를 만듭니다. 수식적으로 vanilla/sysnthesized coupled multimodal feature간의 discrepancy를 표현하면 아래와 같습니다.
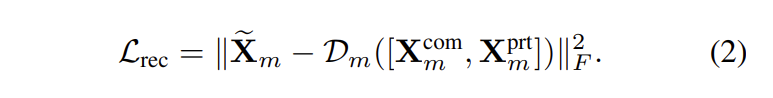
vanilla/sysnthesized heterogeneous features간의 discrepancy를 수식적으로 표현하면 아래와 같습니다.
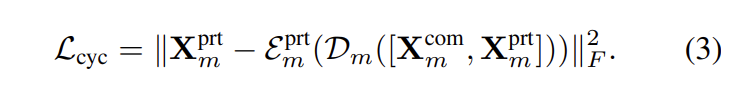
하지만 논문에서는 위의 reconstruction losses만으로는 여전히 완전한 feature decoupling을 보장할 수 없다고 합니다. 사실, information은 representation 간에 자유롭게 유출될 수 있다고 논문에서는 말하는데, 예를 들어, 모든 modality 정보는 단순히 X_m^{prt}로 인코딩되어 디코더가 쉽게 합성할 수 있으므로 homogeneous multimodal features는 무의미합니다. feature decoupling을 통합하기 위해서, 논문에서는 이렇게 말하는데요. 같은 emotion이지만 다른 modality에서 온 homogeneous representation이 다른 emotion 이지만 같은 modality에서 온 representation과 비슷해져야 한다고 주장합니다. 그래서 margin loss를 아래와 같이 설계하였습니다.
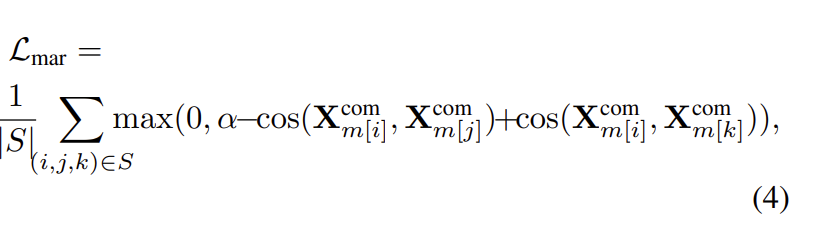
수식(4)에서 S는 triple tuple set을 의미하는데요. S = {(i, j, k)|m[i] \ne m[j], m[i] = m[k], c[i] = c[j], c[i] \ne c[k]}를 의미합니다. 여기서 m[i]는 sample i의 modality를 의미하고, c[i]는 sample i의 class label을 의미한다. 즉, 감정을 의미한다. cos(. , .)은 두 feature vector 간에 consine similarity를 의미한다. 수식(4)에서 loss는 동일한 감정에 속하지만 다른 modality에 속하거나 반대로 homogeneous feature를 제한하여, 사소한 homogeneous feature를 도출하는 것을 방지합니다. \alpha는 margin의 거리를 의미합니다. margin \alpha를 통해 positive sample (same emotion, different modality)의 거리는 negative sample (same modality, different emotion)의 거리보다 작도록 설정됩니다. decoupled features가 각각 modality-irrelevant/-exclusive characteristics를 잘 포착하는 것을 고려하여, 논문의 저자는 homogeneous multimodal features와 heterogeneous multimodal feature간의 정보 중복성을 줄이기 위해서 추가로 soft orthogonality를 공식화하였습니다. 식은 아래와 같습니다.
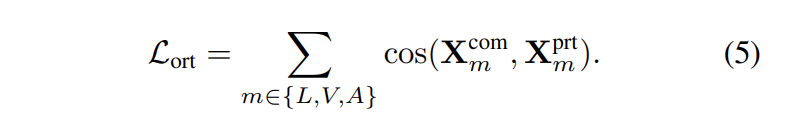
최종적으로, decoupling loss는 아래와 같습니다
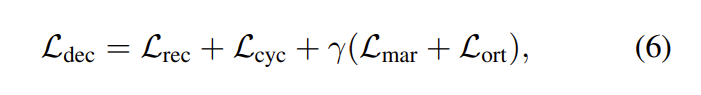
여기서 \gamma는 balance factor 입니다.
<2. GD with Decoupled Multimodal Features>
decoupled homogeneous, heterogeneous multimodal features에 대해서, 논문의 저자는 각각의 feature들이 adaptive knowledge distillation을 수행하도록 graph distillation unit (GD-Unit)을 제안하였습니다. GD-Unit는 directed graph \varrho로 구성되어 있습니다. v_i는 각 modality에 대한 node를 나타내고, w_{i→j}는 modality v_i에서 v_j로의 distillation strength를 의미합니다. v_i에서 v_j로의 distillation은 두 modality에 대응하는 logits간의 차이를 \Epsilon_{i→j}로 표시합니다. E는 E_{ij} = \epsilon_{i→j}로 distillation matrix를 나타냅니다. target modality j에 대해서, weighted distillation loss는 injection edge를 고려함으로서 아래와 같이 공식화할 수 있습니다.
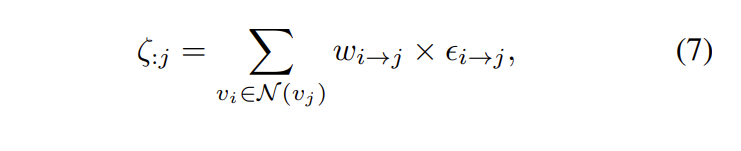
여기서 \mathcal{N}은 v_j에 injected된 set of vertices를 나타냅니다.
distillation strength w에 대응하는 dynamic하고 adaptive한 weight를 학습하기 위해서 논문의 저자는 modality logits와 representation을 graph edge로 encoding하였습니다. 식으로 표현하면 아래와 같습니다.
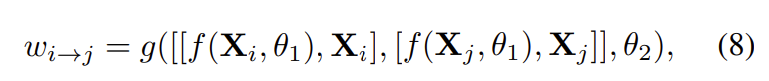
여기서 [ \ldots, \ldots]는 feature concatenation을 의미하고, g는 학습가능한 parameters \theta_2 를 가진 FC layer를 의합니다. f는 parapeter \theta_1를 가진 regressing logits에 대한 FC layer를 의미합니다. W_{ij} = w_{i→j}인 grpah edge wiehts W는 modality의 모든 pair에 대해서 반복적으로 수식(8)을 적용함으로서 학습됩니다. 논문의 저자는 scale effects를 줄이기 위해서, softmax 연산을 통해 W를 normalize해주었습니다. 결과적으로 모든 modalities에 대한 graph distillation loss는 아래와 같이 표현될 수 있습니다.
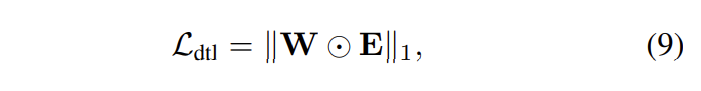
여기서 \odot은 element-wise product를 의미합니다. 정리하자면, GD-Unit에서 distillation graph는 dynamic inter-modality interaction을 학습하는 것에 대한 기반을 마련해줍니다. 동시에 flexible knowledge transfer manner를 쉽게 하도록 해주는데, 여기서 distillation strengths는 automatically하게 학습될 수 있습니다. 따라서 다양한 knowledge transfer patterern도 그릴 수 있게 됩니다. 아래에서는 HomoGD와 HeteroGD에 대해서 디테일하게 말씀드리도록 하겠습니다.
<HomoGD>
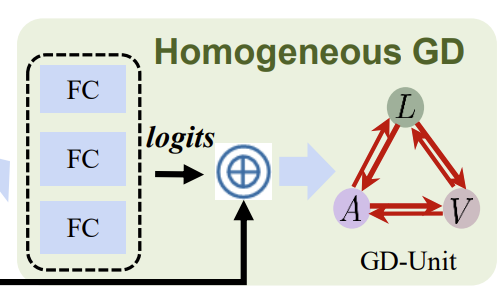
위의 그림은 Figure 2에서 Homogeneous GD 파트를 crop해서 가져온 것입니다. decoupled homogeneous feature X_m^{com}에 대해서, modality간의 distribution gap이 이미 충분히 줄어들었기 때문에, 논문의 저자는 feature X_m^{com}과 대응되는 logits f(X_m^{com})를 GD-Unit의 input으로 주고 graph edge matrix W와 distillation loss matrix E를 수식(8)에 따라서 계산합니다. 그런 다음 전체적인 distillation loss \mathcal{L}^{homo}_{dtl}은 자연스럽게 수식(9)를 통해서 얻을 수 있습니다.
<HeteroGD>
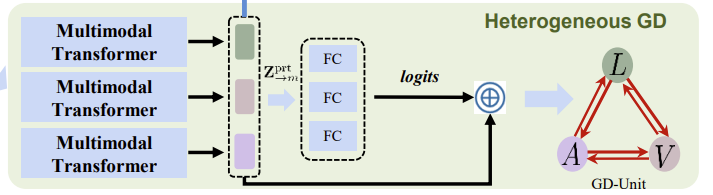
위의 그림은 Figure 2에서 Heterogeneous GD 파트를 crop해서 가져온 것입니다. decoupled heterogeneous features X_m^{prt}는 각 modality의 diversity와 unique characteristics에 집중하였는데요. 그래서 distribution gap이 상당합니다. 이러한 이슈를 완화하기 위해서 논문의 저자는 feature distribution gap을 메우고 modality adaptation을 이루는 multimodal transformer를 사용하였습니다. multimodal transformer의 핵심은 crossmodal attention unit (CA) 인데요, 이는 modality의 pair로부터 feature를 받아서 crossmodal information을 fuse합니다. 더 자세히 말해보도록 해보겠습니다. sorce로서 language modality X_L^{prt}를 주고, target으로서 visual modality X_V^{prt}를 주었다고 해봅시다. 그러면 cross-modal attention은 이렇게 정의될 수 있습니다. Q_V = X_V^{prt}P_q, K_L = X_L^{prt}P_k, 그리고 V_L = X_L^{prt}P_v 여기서 P_q, P_k, P_v는 learnable parameter 입니다. 개별적인 head는 아래와 같이 표현될 수 있습니다.
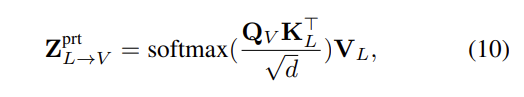
여기서 Z_{L→V}^{prt}는 Langugae에서 Visual로 강화된 feature를 의미하고, d는 Q_V, K_L의 차원을 의미합니다. multimodal emotion recognition에서 3개의 modality에 대해서, 각 modality는 두개의 다른 modality를 통해서 강화되고, resultng freature는 concat됩니다. 각각의 target modality에 대해서, 다른 modality에서 target으로 모두 enhnced된 feature를 강화된 feature로 Z_{→m}^{prt}로 표현합니다. 이는 distillation loss fuction에서 \mathcal{L}^{hetero}_{dtl}로 사용되며, 수식 (9)를 통해 자연스럽게 얻을 수 있습니다.
<Feature fusion>
adaptive feature fusion을 위해 강화된 heterogeneous features Z_{→m}^{prt}와 vanilla decoupled homogeneous features X_m^{com}를 사용하여 fuse합니다. 이 fused feature에 대해서 최종적으로 감정 인식을 진행합니다.
<3. Objective optimization>
위에서 정의한 loss들을 최종적으로 합치면 아래와 같이 표현 가능합니다.
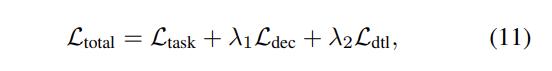
여기서 \mathcal{L}_task는 emotion task 관련된 loss를 의미하고, \mathcal{L}_{dtl} = \mathcal{L}_{dtl}^{homo} + \mathcal{L}_{dtl}^{hetero}는 HomoGD와 HeteroGD의해서 생성된 distillation loss를 의미하고, \lambda_1, \lambda_2는 다른 constraints의 중요성을 control하는 역할을 합니다.
이렇게 방법론에 대해서 정리해봤는데요. 제가 graph 논문은 처음 읽어서 제대로 정리했는지 잘 모르겠네요^^; 너그럽게 봐주시고 이해 안되는 부분 있으시면 질문 부탁드립니다.
<Experiments>
<Datasets>
논문에서 사용한 데이터셋에 대해서 아주 간략히 말씀드리고 넘어가도록 하겠습니다.
- CMU-MOSI : 2,199 short monologue video clip
- CMU-MOSEI : 22,856 samples of movie review video clips from YouTube
이 두개의 데이터셋은 word-aligned 버전과 unaligend 버전 두가지가 있는데 논문에서는 두 버전의 데이터셋을 비교하여 실험했다고 합니다. 논문에서는 성능 리포팅할 때 3개의 metrics를 사용하는데 ACC_7 (7-class accuracy), ACC_2 (binray accuracy) 그리고 F1 Score 입니다.
<Results>
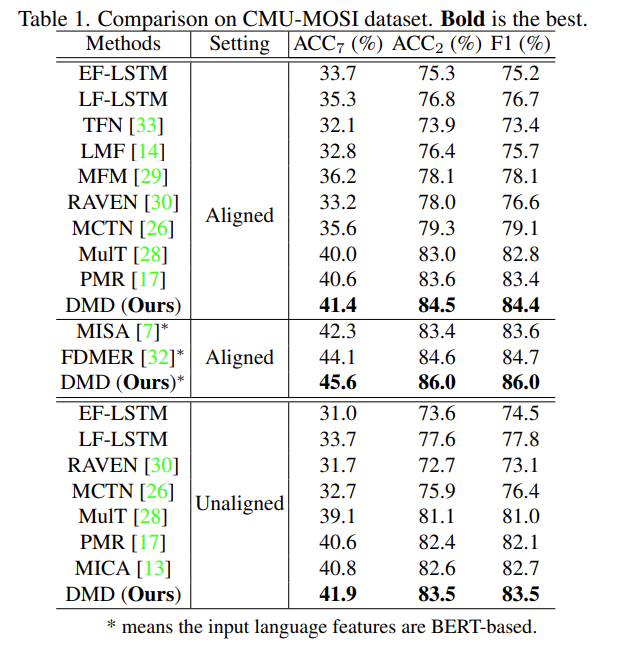
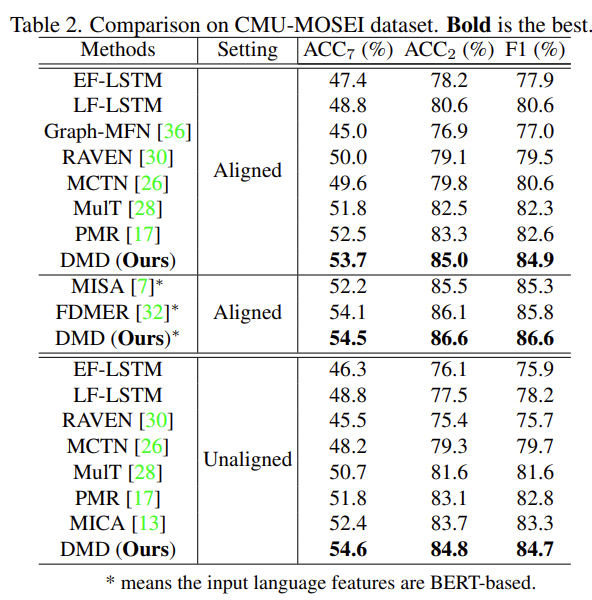
Table 1과 Table 2는 CMU-MOSI와 CMU-MOSEI 데이터셋에서의 성능 테이블입니다. 두 데이터셋 모두에서 논문의 저자가 제안한 방법론이 가장 성능이 높은 것을 확인할 수 있습니다. unaligned와 aligned 모두에서 성능이 높은 것을 확인할 수 있습니다.
DMD는 crossmodal interaction을 학습하고 multimodal fusion을 수행한 13, 17, 28 방법론에서 좋은 성능을 보였는데 논문의 저자는 두가지의 이유를 말합니다.
(1) DMD가 modality-irrelevant/-exclusive space를 고려하였기 때문이고 feature decoupling을 통해서 information redundancy를 줄였기 때문이다.
(2) DMD가 modality간에 adaptively하게 knowlege를 distill하는 twin GD-Units를 사용했기 때문이다.
<Ablation Study>
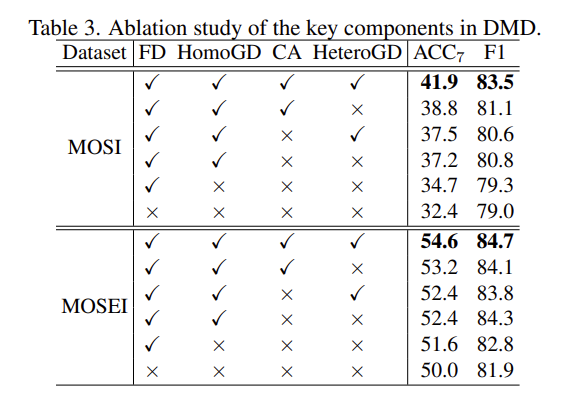
ablation study에서는 feature decoupling (FD), HomoGD, crossmodal attention unit (CA), HeteroGD 이렇게 4가지 요소에 대해서 ablation을 진행하여 정량적으로 성능을 측정하였습니다. (Table 3 참고)
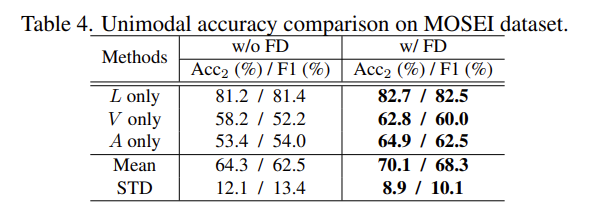
FD는 MER 성능을 크게 향상시켰는데요. 이것을 더 디테일하게 알아보기 위해서 Table 4로 FD가 있을 때와 없을 때를 비교하여 성능을 측정하였습니다. Table 4를 통해서, FD가 각 unimodality에게 consistent improvement를 가져왔다는 것과, 3개 modality에서 performance gap이 줄었다는 것을 확인할 수 있습니다.
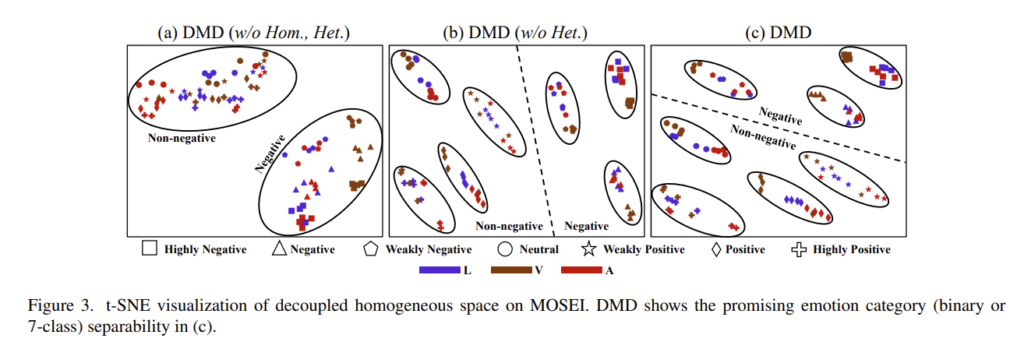
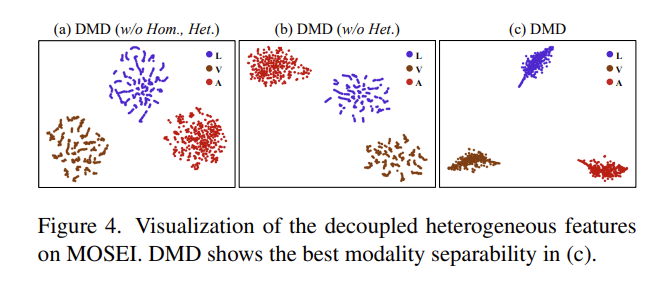
또한 논문의 저자는 t-SNE를 시각화하여 얼마나 잘 분류하는지에 대해서 확인하였는데요. 모든 요소가 다 갖춰져 있는 DMD가 가장 분류가 깔끔하게 되는 것을 확인할 수 있습니다. Figure 4는 각 modality 마다 분류가 아주 깔끔하게 되어 있는 모습을 확인할 수 있는데 정말 대단한 것 같습니다.
이렇게 CVPR 2023 감정인식 논문을 리뷰해봤는데요. 그래프가 나오는 논문은 처음 읽어서 어렵게 읽은 것 같습니다. 읽으면서 감탄했던 것이 각 modality 마다 감정 인식에 기여하는 바가 다르다는 것은 저도 인지하고 있는 사실이었는데 이를 확장하여서 decoupling feature가 나오고 HomoGD, HeteroGD 이렇게 쭉쭉 확장되는 것을 보고 이런 논문이 CVPR을 하는구나…. 싶었습니다? 저도 논문을 써야 하는 시기가 다가오고 있는 와중에 이렇게 대단한 논문을 리뷰하게 되니 자신감이 뚝 떨어지는 느낌도 나네요? 논문에서 분석도 아주 잘해서 대단한 학회에 대단한 논문이다 싶었습니다. 성능 리포팅보다 시각화 같은 분석에 훨씬 더 분량이 많은 것을 보면서 저도 분석을 잘하고 싶은 마음도 들었네요. TMI가 많았던 것 같습니다. 이만 마무리하겠습니다. 읽어주셔서 감사합니다.
재미있는 리뷰 감사합니다. 질문이 몇가지 있는데요 Figure 1의 (b)그림에서 strong modality에서 weak modality로 reliable의 reliable 과정이 하이퍼 파라미터를 통한 가중치 합으로 이해하였는데 맞는지 궁금합니다. 다음으로 Figure1의 (c)에서 shared encoder와 private encoder의 두 갈래로 나뉘었는데, margin loss가 어디에 적용되는 것인지, 두 브랜치 간의 정보 교환을 위한 설계가 있는지 궁금합니다.
안녕하세요. 댓글 감사합니다.
1) (b)에서의 과정은 사실 논문에서 자세히 다루지 않기 때문에 잘 알지 못하지만 유진님께서 생각하시는 것이 맞는 것 같습니다.
2) margin loss는 식(4)를 참고하시면 쉽게 이해할 수 있을 것 같습니다. margin loss는 positive sample(같은 감정인지만, 다른 모달리티)와 negative sample(같은 모딜리티이지만, 다른 감정)과 marglin α를 통해 구성됩니다.
3) 두 브랜치 간의 정보 교환이 무엇을 의미하는지 정확히 모르겠지만 제가 이해한 바로 설명하면 loss를 통해서 이뤄진다고 생각하면 될 듯 합니다. 두 브랜치간의 직접적인 정보를 교환하지 않고 각 브랜치의 loss를 구하여 사용하기 때문입니다.
감사합니다
안녕하세요 김주연 연구원님 좋은 리뷰 감사합니다.
CVPR에도 감정인식 연구가 있다니!
우선 오랜만에 읽으려니 용어에 대한 질문이 먼저드는 것 같습니다. 용어 말고도 몇가지 궁금한 점들에 대해 질문드리겠습니다~!
1. Language는 Text겠지요..? 처음엔 영어 한국어 이런 언어일 줄 알았는데ㅋㅋ 다소 낯설어서 질문드려봤습니다.
2. intrinsic heterogeneities의 정의가 무엇일까요..? 참고로 해당 용어는 Introduction 중 “다른 modality 간의 intrinsic heterogeneities” 에 등장합니다. 뭔가 느낌상 모달 간의 이질성 혹은 성능 갭 같은 느낌인데요, 그렇다면 이쪽분야의 연구진들은 이걸 어떻게 정의하고, 정량화하는지 알 수 있을까요? (설마 그림 (a)가 전부는 아니겠죠…?)
2-1. 이런 질문을 드리는 이유는, 김주연 연구원님이 데이터를 분석하는 데에 도움이 될 것 같아서 질문 드립니다. 추가로 모달 간의 차이나 모달 간의 특성을 파악하는 다른 분석 법은 없는지도 같이 찾아보면 좋을 것 같습니다.
3. 제가 잘 이해한 건진 모르겠지만 모달간 공유할 피처, 공유하지 않을 피처로 나눔으로써 학습을 진행한 것 같습니다. (homo, hetero와 같은 디커플링 부분을 보고 말씀드립니다.) 그런데.. 어떻게 이렇게 설계하였는지…. 너무 궁금하네요… 그러니까 문제 정의와 문제 해결 그 중간 과정이 훅 건너간것 같아서 혹시 설계한 이유에 대해 추가로 설명해주실 수 있을까요… 허허
4. 그나저나 성능 보니 압승이네요 ..ㅋㅋ 아 그나저나 ACC_2는 성능을 어떻게 측정하나요? 그리고 여기서는 ACC_7 어떻게 평가하는지도 알수 있나요? 성능 봐서는 멀티라벨로 평가하는 것 같지는 않아서요!
답변 주시면 감사하겠습니다!
안녕하세요. 댓글 감사합니다.
작년에는 감정 인식 논문이 저어어엉말 없었던 것 같은데 이번에는 그래도 꽤 감정인식 논문이 있더라구요. (기분이 좋네요)
1) 맞습니다. 보통 3가지 모달리티를 말할때 text를 language로 말하기도 하는데 제가 설명이 부족했던것 같군요.
2) 설마 했던 그림 (a)가 전부 입니다ㅜ 저도 주영 연구원님이 말씀하신 대로 비슷하게 이해하였는데요. 제가 본 감정인식 논문에서 ablation study로 성능 리포팅을 할때 3가지 모달리티가 동일하게 비슷한 성능을 보이지는 않았는데요. 이 논문에서는 이러한 차이가 모달리티간의 본질적인 차이 때문이라고 말하는거 같고 이를 intrinsic heterogeneities이라 표현한 것 같습니다. 실제로 요즘에는 이러한 부분에 집중을 많이 하는거 같은 것이 논문 서베이를 진행하면서 distill, decoupling이라는 표현이 많이 보이더라구요.
3) 어떠한 이유로 이렇게 방법론을 제안한 것인지는 나오지 않아서 좀 급전개된 부분이 없지 않아 있지만….figure1에서 (a)에서 (b)로 (b)에서 (c)로 넘어가는 부분을 좀더 참고하시면 좋을 듯합니다.
4) ACC_7는 sentiment score classification을 의미하며, ACC_2는 positive/negative sentiments를 의미합니다. 이 메트릭 등장 배경은 “Multimodal Transformer for Unaligned Multimodal Language Sequences”를 확인해주시면 되겠습니다. 그나저나 이 논문이 정말 많이 인용되는 것을 보니 꼭 리뷰해야겠다는 생각이 드는군요.