이번 주차 X-Review에서는 비디오의 또 다른 task인 Generic Event Boundary Detection 관련 논문을 소개해드리고자 합니다. 해당 task는 2021년도에 소개되어 비교적 최근에 등장하였고, 비디오 이해와 관련하여 다양한 의미론적 분석과 인지를 요구하는 난이도 높은 task에 해당합니다.

그러면 바로 논문의 Introduction을 살펴보며 task와 본 논문의 방법론을 알아보겠습니다.
1. Introduction
전세계적으로 비디오 시장이 커짐에 따라 학계에서도 관련 연구가 활발히 이루어지고 있다는 사실은 대부분 알고 계실것입니다. 이에 따라 제가 기존까지 소개해드렸던 비디오 이해와 관련된 다양한 task들을 필두로, 비디오 산업에 인공지능을 적용하기 위한 많은 노력들이 이루어지고 있습니다. 위와 같이 비디오 이해 및 분석을 사람이 분석하는 방식과 유사하게 수행해보자는 접근 방식이 늘어나고 있는 와중에 이와 관련 있는 task가 하나 등장하게됩니다.
인지 과학 분야에서 사람이 비디오를 이해하는 과정에서 자연스럽게 유의미한 unit으로 분할하여 event 경계를 찾아낸다는 점을 밝혀내었습니다. 이에 따라 학계에서도 연구 결과에 맞춰 비디오를 이해하는 연구를 수행하고자 Generic Event Boundary Detection(GEBD) task가 등장하였습니다.
GEBD의 이름에 따르면 비디오 속에서 무언가 event의 경계가 될만한 지점을 찾아내는 것 같은데, 과연 event 경계란 무엇을 의미하는 걸까요? 이를 설명하기 위해 논문에서는 ‘taxonomy-free’라는 용어를 사용하고 있습니다. 일반적으로 taxonomy란, 분류 또는 분류 체계를 의미하는데요, 비디오에서 frame->clip->shot->scene->video 순서대로 작은 단위에서 큰 단위를 일컫는 용어로 사용됩니다.
이러한 포함 관계 또는 일정 단위에 대한 분류 체계를 taxonomy라고 하는데, taxonomy-free라는 것은 GEBD가 일정하게 clip 간 경계만을 찾아낸다거나, scene을 나누는 task가 아니라는 것이죠. Event boundary는 scene이 전환되는 부분, clip 또는 shot 내에서 미세하게 동작이 바뀌는 부분 등등을 모두 포함하여 사람의 인지 과정처럼 비디오 내에서 무언가 변화가 생겼다고 인식할 수 있는 경계를 전부 의미한다는 것입니다.
위와 같이 비디오 내의 미세한 변화부터, 명시적인 경계라고 생각되는 부분까지 모두 찾는다는 것은 굉장히 복합적인 일입니다. 저자는 그래도 이러한 어려움을 공간 다양성, 시간 다양성이라는 두 측면에서 설명해주고 있습니다.
먼저 공간 다양성 측면에서는 low-level, high-level에 속하는 변화로 나눌 수 있습니다. 공간 축에서의 low-level 변화는 단순히 비디오의 색이나 밝기가 변화하는 지점으로 생각할 수 있고, high-level 변화는 비디오에서 의미론적으로 중요한 물체가 등장하거나 사라지는 지점이 해당할 수 있습니다. 이에 반해 시간 다양성과 관련해서는, 주로 action 변화와 관련 있는 지점들이 경계를 만들어내겠죠. 예를 들자면 사람이 천천히 걷다가 갑자기 뛰기 시작하는 지점이나 특정 물체와의 상호작용 방식이 변화하는 지점이 이에 해당할 것입니다.
이러한 event 경계를 모두 잡아내는 것이 어려운 이유는 저자가 이야기한대로 경계 지점에 해당하는 변화가 굉장히 시공간적으로 다양하다는 점을 생각해보았을 때, 학습 시 “걷다가 뛰는 지점” 같은 구체적인 label을 주는 것이 아니라 해당 지점이 단순히 “경계”임을 알려주고, 모델이 사람처럼 event의 경계를 인식해내길 기대하기 때문이라고 생각합니다.
이제 GEBD task에 대한 설명은 마치고, 저자의 방법론과 contribution에 대해 살펴보겠습니다.

결국 GEBD에서 찾아야 하는 경계는 spatio-temporal 축 모두에 엮여있다고 볼 수 있는데요, 저자는 이러한 다양성을 최대한 잡아내기 위한 키워드로 motion 정보를 선택합니다. GEBD를 수행하는 기존 연구에서도 motion 정보를 잡아내기 위해 optical flow feature를 사용하거나, 단순히 연속되는 두 RGB 프레임 간의 차이를 사용하였었습니다.
그림 1에서 회색 선이 두 프레임 간의 optical flow 값을 나타내는데, 이러한 방식은 결국 연속되는 두 프레임 간의 움직임 관계만을 고려했다고 볼 수 있습니다. 반면 저자가 제안하는 dense motion representation 방식은 초록 선에 해당하여 자기 자신과 다른 프레임 모두와의 차이(그림 1에서의 초록 선은 일부 생략)를 잡아내는 것을 볼 수 있네요. 비디오의 일반적인 경계를 찾아내기 위해서는 저자가 제안하는 dense motion representation 방식을 활용하여 더 길고 포괄적인 비디오의 흐름을 파악해낼 필요가 있습니다.
또한 motion 정보를 사용하는 기존 방법론들은 최종적으로 RGB 프레임에 대한 정보와 motion 정보를 합쳐서 event 경계를 예측하는데, 합칠 때 단순 concat이나 1:1 fusion 방식을 사용했었다고 합니다. Event 경계의 특성에 따라 두 정보를 adaptive하게 합쳐준다면 성능 향상을 노려볼 수도 있겠죠.
저자가 언급한 event 경계의 spatio-temporal 적 다양성과 기존 연구의 한계 두 가지를 다루기 위해 총 3개의 모듈을 포함하는 DDM-Net을 소개합니다. 논문의 Contribution을 보고 자세한 방법론에 대한 설명으로 넘어가도록 하겠습니다.
Contribution
- We propose dense difference map equipped with multi-level feature bank to leverage richer temporal clues for detection of diverse event boundaries.
- Instead of simple feature fusion methods, progressive attention is employed to aggregate appearance and motion clues from RGB features and DDM, enabling DDM-Net to generate more discriminative representations and learn more complicated semantics.
- Extensive experiments and studies demonstrate that our DDM-Net achieves the state-of-the-art performance on Kinetics-GEBD and TAPOS benchmark, under the setting of the same backbone.
2. Method
2.1 Overview
저자가 제안하는 DDM-Net은 아래와 같은 3가지 주요 모듈로 구성되어 있습니다.
- Spatio-temporal 측면에서 다양하게 포진되어 있는 “Generic event boundary”를 찾아내기 위한 multi-level feature bank
- 비디오의 전체적인 관점에서의 motion 관계를 파악해내기 위한 multi-level dense difference map
- 서로 다른 모달인 RGB feature와 motion 정보를 합치기 위한 progressive attention
이러한 과정을 거쳐 얻은 RGB, motion feature는 각각이 FC layer를 통해 score로 만들어진 후 learnable parameter로 둘을 합쳐 최종 경계 확률로 변환됩니다.
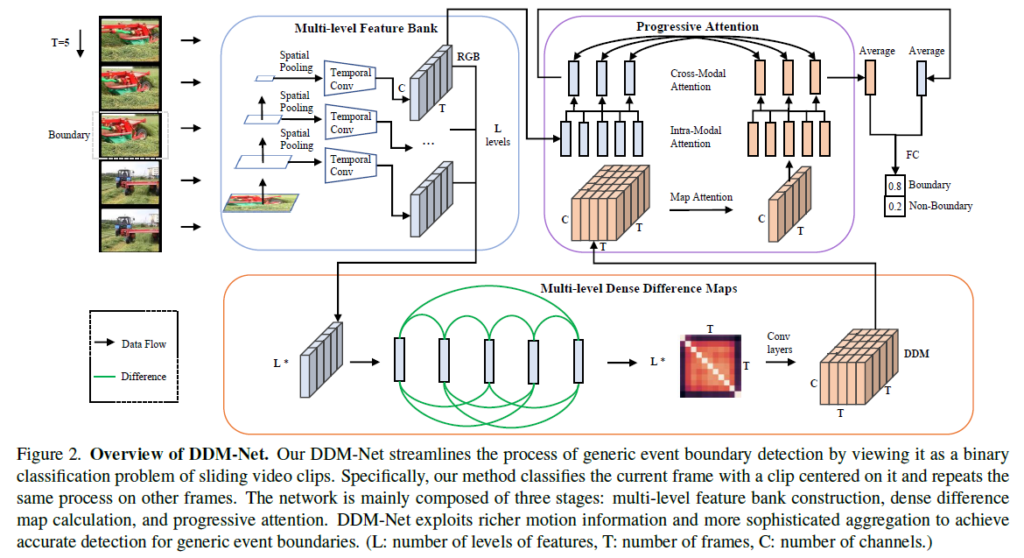
2.2 Multi-Level Feature Bank
Construction of Multi-Level Feature Bank
우선 GEBD의 목적은 비디오 내에서의 event 경계를 프레임 단위로 찾아내는 것입니다. 그러면 하나의 프레임이 경계인지 아닌지를 판단하기 위해 비디오에 속하는 프레임 전체를 살펴봐야 할까요? 이에 대해 저자는 실제 하나의 프레임이 event 경계인지 결정되는 데에는 주변 몇 개의 프레임만 관여한다고 합니다. 아무래도 연산량이나 의미론적 관계를 생각해보았을 때 전체 프레임을 보는 것보다는 크게 관여하는 주변 몇 개의 프레임만을 보는게 효울적이긴 하겠죠. 따라서 저자는 한 프레임의 경계 확률을 얻기 위해 비디오 전체를 사용하지 않고 주변 T개의 프레임만을 clip(또는 snippet)으로 만들어 사용합니다.
Event의 경계를 찾기 어려운 이유가 경계는 공간적, 시간적으로 많은 다양성을 포함하고 있기 때문인데요, 이러한 어려움을 완화하고자 저자는 다양한 spatial, temporal level에 대한 feature를 추출하여 multi-level feature bank를 구축합니다.
비디오의 한 프레임을 기준으로 앞 뒤 프레임을 샘플링하여 총 T개의 프레임으로 이루어진 clip을 만들고 이를 ResNet의 입력으로 주어 feature를 추출합니다. 이 때 m개의 layer를 정하고 여기에서 추출된 feature에 spatial average pooling을 수행합니다. 이렇게 m개의 spatial-level에 대한 feature sequence를 얻었다면, 다음은 각 sequence에 대해 총 n개의 temporal receptive field가 다른 temporal convolution을 적용해줍니다. 결국 총 m \times{} n = L개의 spatio-temporal level을 갖는 feature bank(\in{} \mathbb{R}^{L \times{} C \times{} T})를 구축하였고, 이는 Dense Difference Map, DDM을 만드는 데에 사용됩니다.
2.3 Dense Difference Maps
비디오 내의 event 경계를 찾기 위해 사람, 물체, 사람-물체 등등의 motion 정보를 잡아내어 사용하는 것은 필수적입니다. 기존 연구에서 연속된 두 프레임 간의 관계를 보는 것에서 발전하여, 저자가 제안하는 DDM은 자기 자신의 프레임을 기준으로 타 프레임 모두와의 관계(차이)를 연산하여 활용합니다.
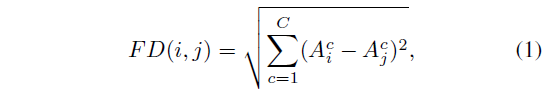
두 프레임 I_{i}, I_{j} 간의 차이를 계산하기 위해 두 프레임의 feature A_{i}, A_{j}를 활용합니다. 여기서 A_{i} \in{} \mathbb{R}^{C \times{} T}는 feature bank 구축 시에도 사용되는 ResNet의 마지막 layer에서 얻은 RGB feature를 의미하고, 수식 1에 따라 하나의 레벨 내 모든 프레임에 대한 서로의 L2 distance를 구해주어 L \times{} T \times{} T 크기의 matrix를 얻을 수 있고, 다시 convolution을 태워 DDM M \in{} \mathbb{R}^{C \times{} T \times{} T}를 최종적으로 얻어냅니다.
2.4 Progressive Attention
앞서 얻은 DDM을 RGB 정보와 합쳐 최종 예측을 수행하기 위해, 저자는 효과적으로 둘을 합치기 위한 progressive attention 기법을 제안합니다.
Map-Squeezed Attention
현재 DDM M의 shape은 C \times{} T \times{} T이고, RGB feature A의 shape은 C \times{} T입니다. 둘의 shape을 맞춰주기 위해 Map-squeezed attention을 수행합니다.
M의 i번째 행 M_{i} \in {} \mathbb{R}^{C \times{} T}는 i번째 프레임과 현재 클립의 나머지 프레임 T개와의 차이 값을 담고 있기 때문에, 이러한 M_{i}를 aggregate 한 값이 i번째 프레임의 클립 내 타 프레임들과의 차이를 의미하게 될 것입니다.
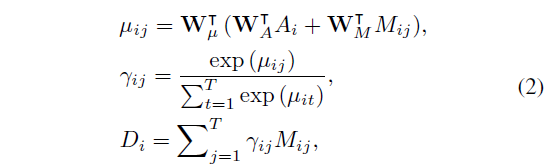
해당 값을 계산해주기 위해 단순 평균 연산을 하지는 않고, RGB feature 값도 함께 사용합니다. 프레임의 RGB feature에 따라 중요도가 다를 수 있기 때문에, 이를 반영해주고자 수식 (2)와 같이 각 값을 project한 뒤 둘을 합쳐 project해주고, softmax를 취해 i번째 프레임의 j번째 프레임과의 score를 만들어 D_{i}를 aggregate해주게 됩니다.
Intra-Modal Attention
앞서까지의 과정을 통해 RGB feature A와 motion feature D 간의 shape이 맞춰졌다면, 이제는 각 모달의 내부적 attention을 연산하기 위한 Intra-Modal Attention과 RGB와 motion간의 attention을 연산하기 위한 Cross-Modal Attention 과정이 남아있습니다.
그 중 Intra-Modal Attention을 먼저 살펴보겠습니다. 여기에선 Transformer의 decoder 구조를 동일하게 2개 가져와 사용합니다.
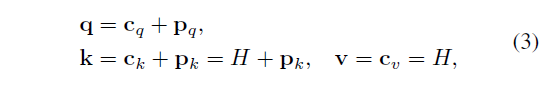
수식 3은 각 decoder에 들어갈 query, key, value를 나타내고 있습니다. c_{q}는 정규분포로 초기화된 learnable query를 의미하고, p_{q}는 learnable sine positional embedding입니다. 식에서 H는 A 또는 D가 각각의 decoder에 들어가게 됩니다. Query를 learnable parameter로 주고, Key와 Value에 동일 도메인의 feature를 입력해줌으로써 각 모달의 내부적인 self-attention 연산을 수행하는 과정임을 알 수 있습니다.
이렇게 학습 가능한 쿼리를 주어 self-attention 연산을 수행함으로써 정제된 q_{A}^{'}, q_{D}^{'}를 얻을 수 있습니다.
Cross-Modal Attention
여기서도 마찬가지로 두 개의 Transformer decoder layer를 가져옵니다. 각각은 RGB-Motion, Motion-RGB 간의 cross-attention 연산을 수행합니다.
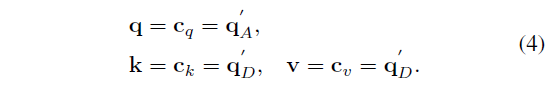
하나의 decoder를 예로 들었을 때 쿼리에는 정제된 RGB query q_{A}^{'}가 들어가고, key, value로는 정제된 motion query q_{D}^{'}가 들어가는 것을 볼 수 있습니다.
위와 같은 과정을 거치면 각각의 decoder로부터 RGB feature와의 관계를 고려한 정제된 motion feature q_{D}^{''}과 multi-level에서의 motion 정보가 고려된 RGB feature q_{A}^{''}를 얻을 수 있게 됩니다.
사실 Intra-, Cross modal attention 모두 transformer의 decoder 구조를 그대로 가져오되 query, key, value값만 다르게 넣어주는 부분이라 크게 설명드릴 것이 없는 것 같습니다. 무엇을 기대하는지 정도만 알면 될 것 같네요.
2.5 Training
Loss Function
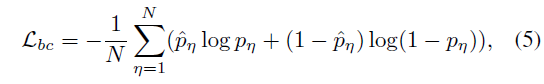
최종적으로는 각각을 FC layer에 태워 현재 프레임의 event 경계 확률을 예측해내고, GT label(0 또는 1)과의 BCE Loss를 통해 학습합니다. 현재 프레임의 event 경계 확률을 예측하는 자세한 과정에 대해서는 바로 아래 절에서 알아보도록 하겠습니다.
2.6 Inference
Linear Fusion of Logits
앞선 progressive attention 과정을 통해 정제된 feature q_{A}^{''}와 q_{D}^{''}를 얻었는데요, 둘을 합쳐 최종적인 score를 만들기 위해 우선 각각을 독립적인 FC Layer에 태워 logit l_{A}와 l_{D}를 얻습니다. 이후 두 score를 합치기 위해 learnable parameter \alpha{}를 사용해 둘을 가중합한 logit l = \alpha{} * l_{A} + (1-\alpha{}) * l_{D}를 얻고, 최종적으로 softmax function을 사용해 0과 1사이의 확률값 p를 만들어냅니다.
Efficient Post-processing Scheme
모든 프레임에 대해 event 경계 확률을 얻었다면, 이제 성능을 측정하기 위해 모델이 실제 event 경계라고 예측한 프레임의 기준을 세워주어야 할 것입니다. 최종적으로 경계 프레임은 아래 두 가지 조건을 만족해야 합니다.
- 0.5 이상의 확률값을 가져야 함
- 사전 정의된 범위 [-5, 5] 내에서 score가 최대여야 함
위와 같은 두 가지 조건을 만족하는 프레임을 모델이 예측한 경계로 지정해줍니다.
3. Experiments
GEBD task의 평가 지표는 F1 score를 사용합니다. 추가로 Relative distance라는 개념이 함께 등장합니다. GEBD에서는 프레임 하나하나 단위로 정확히 0, 1을 지정하여 맞았는지 틀렸는지를 계산하는 것보다는 event 경계에 대해 어느정도 범위를 주고 해당 범위 내에 들어가는지 들어가지 않는지를 기준으로 성능을 측정합니다. 아래 표 1에서 Rel. Dis = 0.05를 기준으로 측정된 F1 score를 예로 들면, 실제 GT label을 기준으로 현재 비디오의 길이 * 0.05 내에 모델이 event 경계를 예측했다면 true positive로 고려되는 상황을 의미합니다. 당연히 Rel. Dis.가 커질수록 조금 더 유하게 true positive를 인정해주기 때문에 성능이 높아지겠죠.
또한 벤치마킹을 위한 데이터셋은 Kinetics-GEBD와 TAPOS를 사용하였습니다.
3.1 Main Results
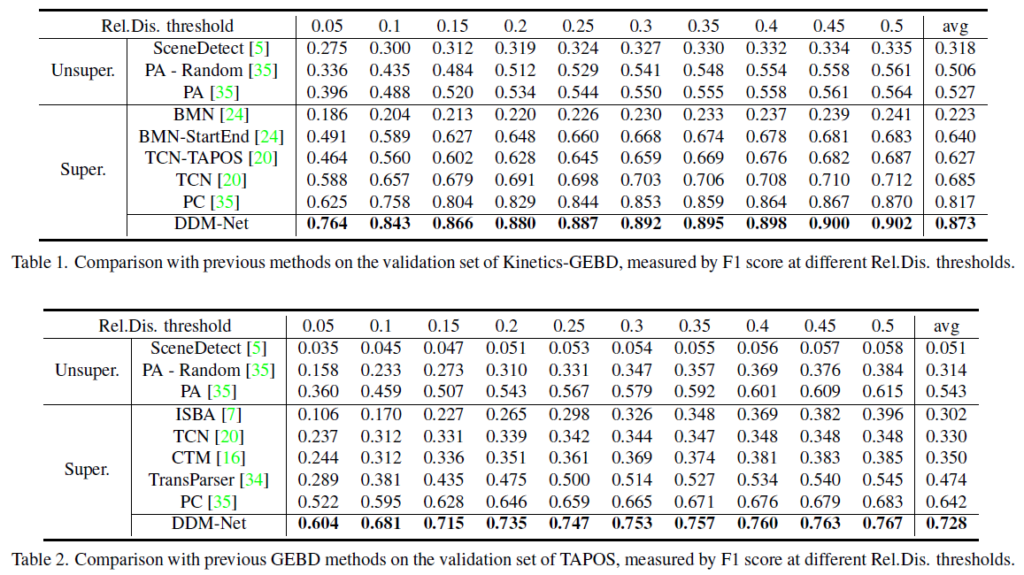
표 1, 2는 각각 Kinetics-GEBD, TAPOS 데이터셋에 대해 측정한 F1 score 벤치마크 표입니다. 두 데이터셋 모두 가장 엄격한 Rel. Dis. 기준인 0.05에서 기존 방법론 대비 F1 score가 8~10% 가까이 올라간 것을 볼 수 있습니다. 사실 개인적으로 Rel. Dis가 0.5일 때 true positive로 인정된다고 해서 실제로 찾아야 하는 event 경계를 잘 찾았다고 볼 수 있는지는 의문이 좀 있기 때문에, 0.05라는 작은 Rel. Dis.에서 성능이 크게 올랐다는 점이 인상 깊은 것 같습니다.
표 3은 가져오지 않았지만 21년도 CVPR의 LOVEU 챌린지(GEBD task)가 있었는데, 당시 1, 2, 3등보다 Kinetics-GEBD testing set에서 소폭 더 높은 성능을 기록하였음을 보여주고 있습니다.
3.3 Ablation Study
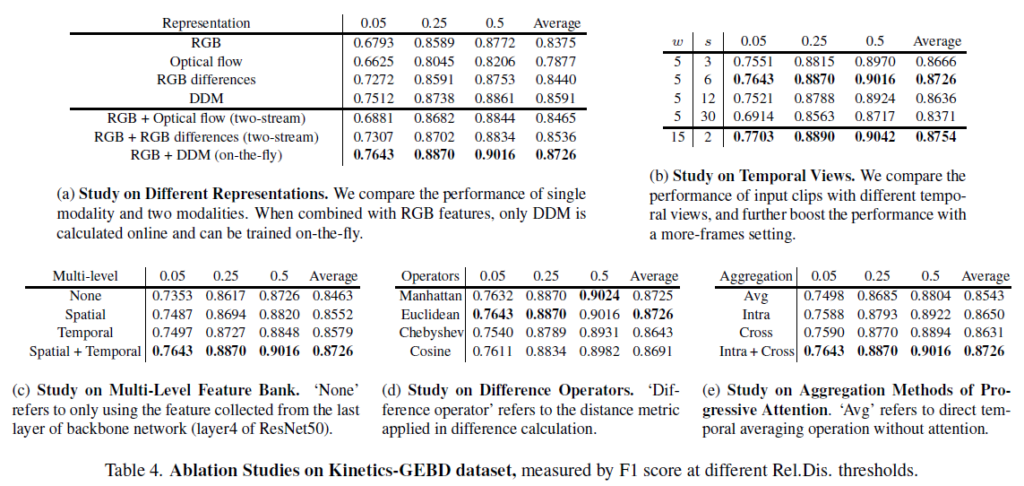
표 4는 다양한 ablation 결과를 보여주고 있습니다.
몇 가지 인상깊은 점에 대해 말씀드리자면, 표 4-(a)는 사용한 feature 별 성능을 보여주고 있습니다. 우선 표에서 윗부분을 보았을 때 단일 모달 기준으로는 DDM만을 사용해도 optical flow를 사용하는 것보다 여러 프레임 간의 관계를 모두 고려하며 높은 성능을 보여준다는 점이 놀랍습니다. 이와 별개로 RGB difference가 optical flow보다 크게 높은 성능을 보여준다는 점도 놀랍네요. 아래 부분에선 RGB 프레임과 더불어 어떠한 motion 정보를 택했는지에 대한 성능인데요, optical flow를 함께 사용하는 경우 해당 feature를 따로 계산해야되는 cost가 있음에도 Multi-level RGB feature로부터 바로바로 계산할 수 있는 DDM보다 더욱 낮은 성능을 보여주고 있습니다.
다음으로 표 4-(c)에서 multi-level feature bank 구축 시 spatial 단일, temporal 단일도 성능을 충분히 올려주긴 하지만 둘을 함께 조합한 다양한 level의 feature를 사용하는 것이 굉장히 큰 성능 향상을 일으킨 것을 알 수 있습니다.
마지막으로 표 4-(e)는 모달 feature의 attention을 연산하여 정제해주는 과정에서의 ablation 성능입니다. 물론 단순히 평균내는 경우에 비해 Intra + Cross가 연산량은 많아지겠지만 정제 과정이 확실히 유효했음을 알 수 있었습니다.
나머지 테이블들은 하이퍼파라미터 관련 또는 단순한 ablation이니 참고하시면 좋을 것 같습니다.
3.4 Qualitative Results
마지막으로 정성적 결과입니다.

그림 3에서 주황색 점은 기존 방법론이 예측한 경계, 연두색 점이 DDM-Net이 예측한 경계, 파란 점이 GT에 해당합니다. 물론 3개의 비디오에 대한 결과를 보여주는 것이긴 하지만 기존 방법론에 비해 FP가 적고, 예측 지점이 GT와 더욱 가깝게 위치하는 것을 알 수 있습니다.
여기서는 결과보단 첫번째 비디오처럼 굉장히 동적인 비디오에서도 일반적인 경계를 잘 찾아야하고, 두 번째 비디오처럼 상대적으로 정적인 비디오에서도 경계를 잘 찾아야한다는 점이 다시 한 번 본 task의 어려움을 알려주는듯 합니다. 물론 DDM-Net은 이러한 경우 모두에 대해서 꽤나 잘 동작하고 있네요.
4. Conclusion
처음으로 리뷰에 작성한 GEBD 논문이었습니다. 다른 주류 task들처럼 매년 많은 논문이 쏟아져 나오고 있지는 않지만, 굉장히 어렵고 복합적인 task인 만큼 아직 갈 길이 멀다고 생각합니다. GEBD task에 대해서 follow-up 하는 과정에서 여러가지 기본적인 지식을 얻을 수 있는 깔끔한 논문이었다고 생각합니다.
이상으로 리뷰 마치겠습니다. 감사합니다.
안녕하세요.
좋은 리뷰 감사합니다. GEBD를 처음 접해보는데 좋은 리뷰였던 것 같습니다.
몇 가지 질문 드리겠습니다.
1. Event Boundary가 frame, clip, shot과 같은 분류 기준들과 같이 명확한 기준이 있기 보다는 조금 모호하게 느껴지는데, 본 task와 같이 event boundary를 모델이 학습하게 하려면 결국 이 boundary를 정의하고 라벨링하여야 할텐데 혹시 이러한 기준이 있나요?
2. feature bank라는 것이 결국 모델이 한 번에 살펴보는 T 길이의 클립에서 추출한 feature를 의미하는 것인가요? bank라는 표현이 새롭습니다.
감사합니다!
1. 느끼신대로 모호하기 때문에 generic 또는 taxonomy-free라는 용어로밖에 표현할 수 없는 것이 사실인 것 같습니다. GEBD task 자체가 사람이 비디오를 볼 때 event의 경계라고 생각되는 부분을 찾아내야 하는 것이기 때문에 명시적으로 모델링할 만한 대상이 아직은 명확하지 않다는 생각도 듭니다. 본 논문도 비디오의 특정한 성질을 모델링했다기보단 여러 attention을 주며 최대한 많은 정보를 모델에게 주입시켰기에 성능이 올라간 것 같네요.
아무튼 GEBD의 라벨은 여러 명이 비디오를 보고 주관적으로 본인이 느끼기에 event boundary라고 생각되는 프레임을 라벨링하고, 모델의 성능을 평가할 때는 각각 한 명의 annotation을 기준으로 f1 score를 계산합니다. Annotator가 5명이면 5개의 f1 score가 산출되고, 그 중 가장 높은 f1 score를 리포팅하는 방식을 사용합니다.
2. feature bank라는 단어가 다른 프레임워크에서 사용되는 memory bank와 유사하게 생각될 수 있지만, 실제로 본 방법론에서 feature를 저장하거나 큐 형태로 구성된 것은 아닙니다. 말씀해주신대로 클립 내 T개의 프레임 각각을 다양한 spatio-temporal level로 추출한 feature 묶음을 “bank”라고 칭한 것으로 생각하시면 될 것 같습니다.