Introduction
이미지 처리, 컴퓨터 그래픽 및 컴퓨터 비전의 많은 문제는 입력 이미지를 출력 이미지로 “Translating”하는 것이라고 할 수 있습니다. [그림 1]과 같이 label이 주어진 이미지를 street scene으로 변환하거나 day 이미지를 night 이미지로 변환하는 것과 같은 task들이 있는데, 이전까지는 각각의 task를 각각의 모델을 사용하여 해결하였다고 합니다. 그러나 이러한 task들은 픽셀을 입력으로 픽셀을 예측한다는 공통적인 목적을 가지고 있습니다. 논문에서는 이러한 task들을 해결하기 위한 pix2pix라는 common framework를 제안합니다.

Image Translation task에서 CNN을 기반으로 한 연구가 진행되었으나 효과적인 loss설계에 어려움이 있었고, 기존 loss는 예측된 픽셀값과 실제 픽셀값 간의 euclidean distance를 최소화하는 방식을 사용하였는데, euclidean distance는 출력값의 평균을 내어 최소화하기 때문에 출력 이미지가 blur해지는 단점이 있었다고 합니다.
이러한 문제를 해결하기 위해 이 논문에서는 Conditional GAN을 사용하였습니다. GAN은 discriminator를 통해 이미지의 진위 여부를 판별하고, generator가 진짜에 가까운 이미지를 만들도록 학습이 진행되기 때문에 위와 같은 blur문제를 해결할 수 있다고 합니다.
저자들은 생성자에 U-Net구조를 사용하고, 판별자에는 PatchGAN 분류기를 사용하여 판별기에는 이미지 패치 규모에서만 구조에 불이익을 주는 컨볼루션 “PatchGAN” 분류기를 사용하였습니다. 특히 PatchGAN을 사용하는 판별자는 patch size를 변경하여 보다 넓은 범위에 걸쳐 의미있는 결과를 도출하였습니다.
Method
본격적으로 method에 들어가기 전에 GAN에 관해 간단히 언급하겠습니다.
GAN은 생성 모델로써 random noise vector z를 입력하여 가짜 이미지를 생성하는 generator, 입력받은 이미지가 진짜인지, 가짜인지 판별하는 discriminator로 이루어져 있으며, 서로가 경쟁적으로 학습합니다. 생성자 G가 생성한 이미지를 판별자 G가 판별하게 되는데 이때 G는 점점 더 실제 이미지에 가까운 이미지를 생성하도록 학습되어 D가 판별하기 어렵게 하고, D는 입력된 가짜 이미지를 실제와 더 잘 구분하도록 학습하게 됩니다.
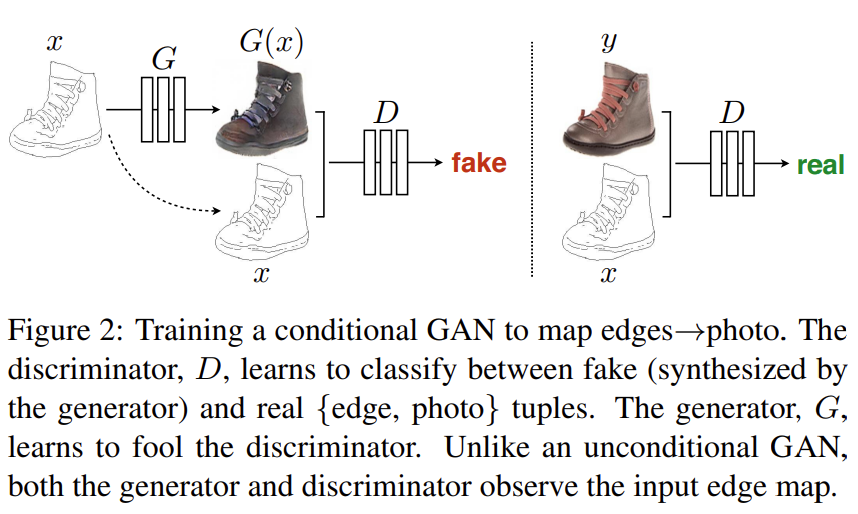
[그림 2]는 논문에서 제안하는 방법으로, Conditional GAN을 사용해 edge map인 x를 조건으로 합니다. 자세한 방법론은 아래에서 설명하겠습니다.
objective
Contitional GAN의 Loss는 아래의 [식1]과 같이 나타낼 수 있습니다.
\mathcal{L}{cGAN}(G, D) = \mathbb{E}{x, y}[logD(x, y)]+\mathbb{E}_{x, z}[log(1-D(x, G(x, z))]\tag{1} 생성자G와 판별자D의 관계를 살펴보면 D는 최소화하는 방향으로, G는 최대화 하는 방향으로 목적함수가 설계되었음을 알 수 있습니다. D는 입력된 영상의 진위 여부를 판펼하는 것으로 real image면 1을, 그렇지 않으면 0을 출력합니다. D(x, G(x, z))의 경우, G(x, z)의 진위 여부를, 즉, 생성자가 생성한 이미지의 진위 여부를 판별하게 됩니다.
저자들은 판별자에 들어가는 조건의 중요성을 알아보기 위해, x를 포함하지 않는 unconditional GAN과의 비교를 수행하였다고 합니다. uncontitional GAN의 loss는 [식 2]와 같이 나타낼 수 있습니다.
\mathcal{L}{GAN}(G, D) = \mathbb{E}{y}[logD(y)]+\mathbb{E}_{x, z}[log(1-D(G(x, z))]\tag{2} gt인 y와 생성자에 의해 생성된 이미지 간의 유사도를 비교할 때, L2 distance를 사용하였습니다.
저자들은 기존 연구에서 GAN의 목적 함수에 L2 distance와 같은 전통적인 유사도 측정 방식을 혼합하여 사용하였고 이 논문에서 역시 비슷한 방식을 사용하였다고 합니다. 기존 연구에서는 L2 distance를 사용하였는데 이 논문에서는 [식 3]과 같이 L2에 비해 blur가 적은 L1을 사용하였습니다.
\mathcal{L}{L1}(G) = \mathbb{E}{x,y,z}[||y-G(x, z)||_1]\tag{3} 최종적인 목적 함수는 [식 4]와 같이 사용하였고, L1loss에 가중치를 적용하였습니다.
G ^* =\arg\underset{G}\min\underset{D}\max\mathcal{L}{cGAN}(G, D) + \lambda\mathcal L{L1}(G)\tag{4} Network architecture
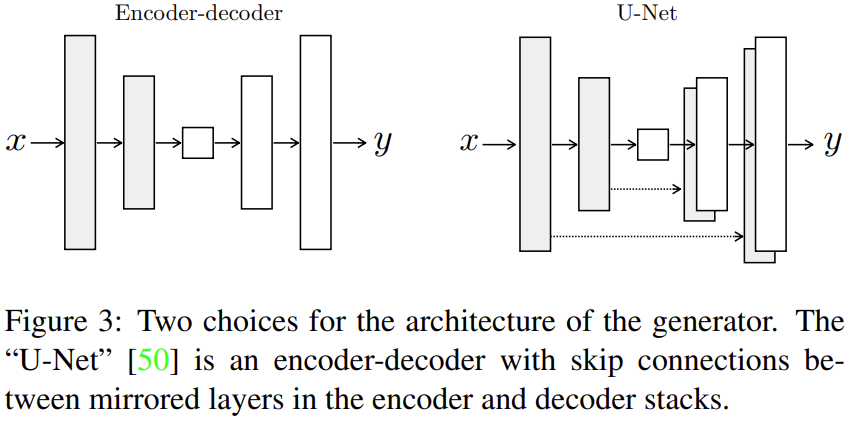
- unet 기반의 encoder-decoder형태
Generator with skips
- skip connection으로 semantic, position 정보 모두 사용
image-to-image translation의 가장 큰 특징이자 문제점은 고해상도의 input을 받고 이를 다시 고해상도의 output으로 만들어야 한다는 것입니다. 또한 입출력의 표현이 달라진다는 점도 고려해야 하며, 이들이 같은 구조의 모델에서 나오게 된다는 것을 명심해야 합니다.
일반적으로 이러한 image-to-image translation에서는 encoder-decoder 구조를 사용합니다. encoder-decoder구조는 [그림 3]의 왼쪽 그림과 같이 downsampling이 진행되는 encoder, upsampling이 진행되는 decoder, 그리고 둘 사이를 연결하는 bottleneck으로 구성됩니다. decoder에서 upsampling을 진행하면 encoder에서 downsampling된 저해상도의 feature를 고해상도의 이미지로 복원합니다. 이때 encoder의 low level feature를 전달하기 위한 skip connection을 적용하였습니다. skip connection을 추가한 생성자의 모델 구조는 [그림 3]의 오른쪽 그림과 같으며 총 n개의 레이어가 존재할 때, i번째 레이어와 n-i번째 레이어에 skip connection을 넣어 대칭적인 구조를 설계하였습니다.
Markovian discriminator (PatchGAN)

[그림4]를 보면 L1 loss를 사용했을 때 생성 이미지에 blur가 발생하는 것을 알 수 있습니다.
일반적으로 image generation에 L1과 L2 loss를 사용하면 결과 이미지가 blur하다는 특징이 있다고 합니다. 이는 L1, L2가 high-frequency성분은 잘 잡아내지 못 하기 때문입니다. 그러나 이들은 low-frequency 성분을 잘 찾는다는 특징이 있어 저자들은 high-frequency를 모델링하기 위해 PatchGAN을 제안하였습니다.
PatchGAN은 판별자의 구조로써, 이미지를 N\times N의 patch로 쪼갠 뒤, 각 patch의 진위 여부를 판별합니다.
Experiments
저자들은 conditional GAN의 보편성을 확인하기 위해 다양한 task와 dataset으로 실험을 진행하였습니다. 해당 task들에는 photo generation과 같은 graphic이나 semantic segmentation과 같은 vision task가 포함되어 있으며 각 실험 결과는 아래와 같습니다.
Analysis of the objective function
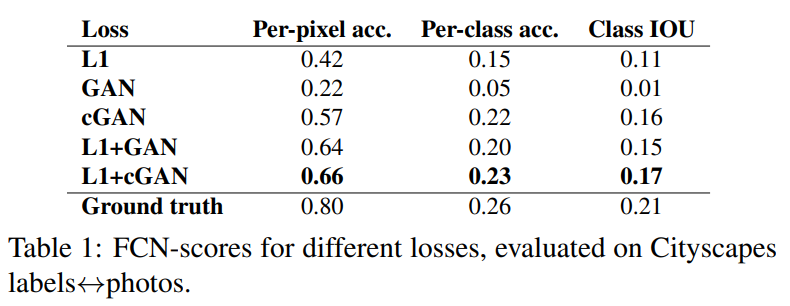
[표 1]은 [식 4]의 loss중 어떤 요소가 가장 성능에 영향을 끼치는지 알아보기 위햔 ablation study 결과입니다. L1 Loss와 cGAN loss를 같이 사용했을 때의 성능이 가장 높은 것을 확인할 수 있습니다. 정성적 결과는 위의 [그림 4]에 나타나 있습니다.
Analysis of the generator architecture

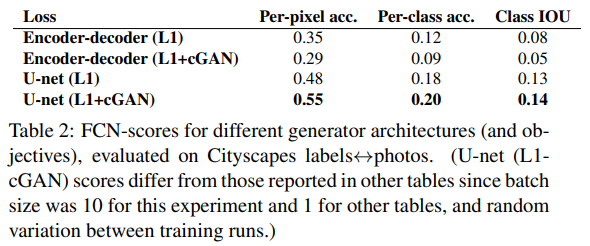
[표 2]는 생성자의 구조에 따른 성능을 나타냅니다. 단순 encoder-decoder 구조와 skip connection이 추가된 U-Net과의 성능 차이를 살펴보면 u-net은 encoder앞부분에 포함된 detail정보를 더 잘 살리는 것을 확인할 수 있습니다.
From PixelGANs to PatchGANs to ImageGANs

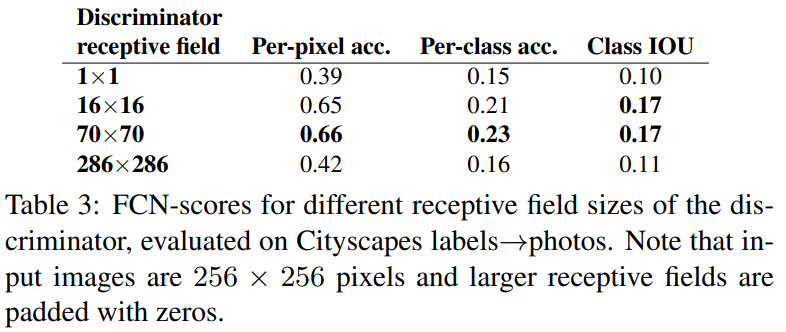
[표 3]은 PatchGAN의 patch size에 따른 성능 비교입니다. input image size는 256 \times 256이고, 70 \times 70를 사용하는 것이 가장 좋은 성능을 내는 것을 확인할 수 있습니다. 한 가지 특이한 것은 full image인 256 \times 256보다 70 \times 70의 성능이 더 좋다는 것입니다. 저자들은 full image의 경우 더 많은 수의 parameter와 depth를 가져 학습이 어렵기 때문에 더 낮은 성능을 보여주었다고 주장하였습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
image-to-image translation의 문제점인 고해상도의 input을 받아 downsampling을 진행한 후 다시 고해상도로 output을 내보낼 수 있는지에 대한 것인데, 본 논문에서는 원래의 encoder-decoder 구조에서 skip connection을 추가한 것으로 이 문제점을 해결한 것일까요? skip connection을 통해 downsampling 되기 이전의 low level feature을 고화질의 output을 만들 때 사용하는 것으로 이해해도 되는지 궁금합니다.
넵 맞습니다. 질문해 주신 두 가지 모두 generator에 사용된 U-Net에 관한 것인데, 해당 backbone은 이미 semantic segmentation분야에서 사용되던 구조로, decoder에서 upsampling시 pixel level의 정확도를 확보하기 위해 각 scale마다 skip connection을 추가한 것이 특징입니다. 해당 블로그에 pix2pix의 generator와 u-net에 관한 설명이 있으니 참고하셔도 좋을 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
리뷰를 읽고 정리해보니 논문의 주요 컨트리부션이 common 아키텍쳐를 고안했다는 것, loss를 새로 만들었다는 점인거 같습니다. patchGAN에 대해서 궁금한게 있는데 patchGAN과 그냥 GAN과의 차이점이 무엇인가요? 단순히 GAN이 생성자와 판별자로 구별되어 작동한다는 것은 알고 있는데
1) 보통 GAN에서 생성자로 U-Net을 많이 사용하는지 궁금합니다. (U-Net이 많이 사용되었기 때문에 논문에서도 U-Net을 사용한 것일까요?)
2) 판별자로 patchGAN의 판별자를 사용했다고 하셨는데 patchGAN의 판별자는 어떻게 구성되어 있는 것인가요?
감사합니다.
1. GAN 논문을 이번에 처음 읽어본거라 잘 모르겠습니다. 그러나 pix2pix의 경우 image-image translation을 진행하는 task이기에 generator에 output이미지와 동일한 사이즈의 input을 넣어 준다는 특징이 있어 U-Net을 사용하였습니다. GAN같은 경우는 랜덤한 latent vector z를 바탕으로 이미지를 생성합니다. 즉, generator단계에서 고해상도의 input이 들어오지 않기 때문에 생성자에는 u-net을 backbone으로 사용하지 않습니다.
2. PatchGAN discriminator는 4개의 conv로 이루어진 단순한 모델입니다. GT와 generated image를 concat 하여 input으로 사용하고, cnn레이어를 통과한 후 30*30의 output을 도출하도록 구성되어 있습니다. output의 각 요소는 cnn의 receptive field인 70*70영역의 진위 여부를 나타내며 전체 이미지의 진위 여부는 output의 평균값을 사용하였다고 합니다.