본 논문에서는 rgb와 Depth 정보를 포함하는 데이터 셋인 SUN RGB-D를 소개한다. 기존에는 large-Scale의 3d annotation된 benchmark dataset의 부재를 문제점으로 지적하며 새로운 rgbd benchmark 데이터 셋을 소개하였다. 본 논문에서 소개하는 sun rgbd dataset은 서로 다른 4개의 센서를 통해 취득하였다(실제 직접 사용한 센서는 2개). 146,617개의 2d polygons annotation과 object orientations를 포함하는 64,595개의 3d bounding box를 annotations을 수행했다. 앞으로 데이터셋 취득 예정에 있는데 어떤 방식으로 contribution을 소개하는지, 어떤 방식으로 데이터 셋을 구성하고 평가하는지 참고하기 위해 3d indoor dataset에서 benchmark로 사용되고 있는 sun rgbd 데이터 셋에 대해 알아보고자 했다.
Introduction
당시에 genral한 scene understanding을 위한 데이터 셋이 부재하였다. 하지만 depth sensor가 발전하면서 가격이 낮아져 소비자들이 구매할 수 있을 정도로 상용화가 됨에 따라, depth sensor를 통해 reliable한 depth map을 얻을 수 있어 다양한 vision task나 3d modeling, pose estimation과 같은 task에 대한 연구가 활성화 될 수 있었다.
rgb-d sensor는 다양한 scene understanding task가 빠르게 진보할 수 있도록 했다. color image의 같은 경우에는 인터넷에서 crawling하여 얻기 쉽지만, large-scale의 rgb-d data는 online에서 얻기가 어려웠다. 2012년에 나온 NYU Depth v2와 같은 이미 존재하는 rgb-d recognition benchmark의 경우에는 PASCAL VOC와 같은 rgb image에 대한 recognition dataset보다 작은 크기를 가진다.

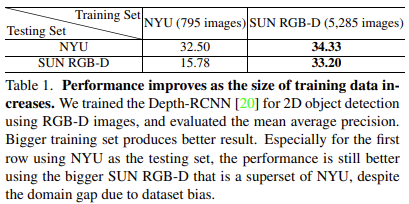
지난 몇 년간 rgb-d scene understanding은 이러한 small dataset을 통한 연구가 진행되어왔는데, 당시에는 이러한 작은 size의 한계를 가지는 데이터 셋이 다음 단계의 advanced 연구를 진행하는데 bottleneck의 원인이 되었다. small size의 데이터 셋은 평가 시 알고리즘의 overfitting을 유발하고 많은 데이터를 필요로 하는 최신 rgb기반 알고리즘 training을 지원할 수 없다. 만약 large scale의 dataset이 존재한다면, rgb-d에서도 rgb기반 방법론들과 동일하게 높은 performace를 보일 것이라고 생각했다. 아래 Table 1에서 rgb-d deep learning 알고리즘이 size가 큰 dataset으로 훈련했을 때 얼마나 performace 향상이 있는지를 보여준다. 당연한 결과로 큰 데이터 셋을 학습을 진행했을 때는 좋은 결과를 보이지만, 작은 데이터 셋으로 학습했을 때 큰 데이터 셋으로 평가를 진행하면 낮은 성능을 보이는 것을 알 수 있다.
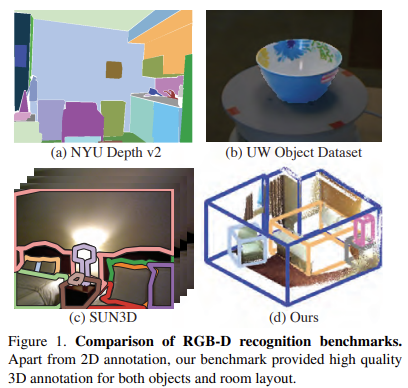
추가로 기존의 dataset의 rgb-d image는 depth map을 포함하고 있지만 annotation이 2d image domain에서 되어있다. 본 논문에서 소개하는 데이터 셋인 sun rgbd에서는 아래 Figure 1과 같이 high quality의 3d annotation을 제공한다.
본 논문에서는 SUN RGB-D dataset을 소개하며 10,335장의 rgb-d image에 2d,3d에 대한 dense annotation이 되어있다. 그리고 dataset을 기반으로 total scene understanding을위한 6개의 중요한 recognition task에 집중했다. 각 task마다 3d metric을 제안하여 sota모델로부터 평가를 진행했다. sensor는 다양한 size와 power를 가지는 rgb-d sensor가 존재하는데,
여기서는 4가지 서로 다른 센서를 사용하여 여러가지 sensor에 generallize한 dataset을 취득하고자 하였다.
Related work
rgb-d scene understanding task에는 semantic segmentation, object classification, object detection, context reasoning, mid-level recognition, surface orientation, room layout estiation 등등 여러가지 task가 존재한다. 또 여러가지 존재하는 rgb-d dataset이 존재한다. 위의 Figure 1이 일부 데이터 셋을 보여주고 있다. 데이터 셋들 중 관련이 있는 것들에 대해 간단히 소개하자면 NYU Depth v2의 경우에는 유명한 natural indoor scene dataset 중 하나인데 1,449개의 frame을 짧은 rgb-d video로부터 추출하여 2d image domain에서 semantic segmentation labeling하였다. Support surface prediction in indoor scenes라는 논문에서 소개한 dataset은 NYU Depth v2를 발전시켜 3d point cloud를 CAD model을 이용하여 annotation을 수행했다. 하지만 3d annotation에 noise가 많아 본 논문에서 소개하는 sun rgbd의 경우 2d segmentation annotation은 그대로 사용하고 3d annotation은 직접 다시 수행했다고 한다. 이게 갑자기 무슨말인가 싶을 수 있는데 sun rgbd데이터 셋의 경우 뒤에서 설명하겠지만 NYU Depth V2, Berkeley B3DO Dataset, SUN3D와 같은 데이터 셋의 일부를 포함시켜서 구성하였다. 다시 돌아와서 NYU Depth v2의 경우 좋은 데이터 셋이지만, 다른 데이터셋에 비해 size가 작다는 문제가 있다고 지적하며 예시로 PASCAL VOC나 ImageNet을 언급한다. NYU Depth v2는 1,449개의 frame이지만 PASCAL VOC와 ImageNet같은 경우에는 각각 17,125개, 120만장의 데이터를 포함하기 때문이다. B3DO dataset은 2d bounding box annotation이 된 rgb-d image로 구성된 데이터셋인데 size가 NYU Depth v2보다 작고 갑자기 floor에 computer mouse가 있는 등 unrealistic scene이 많이 포함되어있다고 한다. Cornell RGBD dataset은 52개의 indoor scene을 포함하며 per-point annotation이 되어있는 point cloud dataset이고 SUN 3D는 rgbd video sequence 중 415개의 key frame을 포함하는 데이터 셋이다. 정리하자면 대체로 전에 존재하는 rgbd dataset은 size가 너무 작거나 poor한 annotation에 대한 불만이 있어 새로운 데이터셋을 제안한다고 한다.
Dataset construction
sunrgbd 데이터셋을 취득하게 된 main 목표는 다양한 rgbd sensors를 가지고 PASCAL VOC와 같은 large scale의 dataset을 구성하는 것이었다. depth map의 quality를 높이기 위해 짧은 길이의 video를 촬영하고 여러 frames를 사용하여 좀 더 refined된 depth map을 얻고자 하였다. object에 대해서는 2d polygons와 3d bounding box로 annotation을 수행하였고 room layout에 대해서는 3d polygons로 annotation하였다.
Sensors
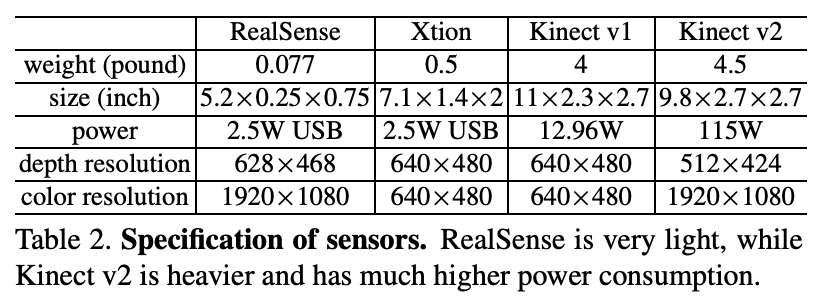
여러가지 다양한 size와 power consumption을 가지는 rgb-d sensors들이 존재하는데, 저자는 총 4가지 sensors를 가지고 dataset을 구성하였다. Intel RealSense 3D Camera, Asus Xtion LIVE PRO, Microsoft Kinect version 1, 2 이렇게 4가지 sensor이다. 실제 직접 촬영한 센서는 RealSense와 Kinect v2이다. 아래 Table 2에서 각 sensor들에 대한 제원을 확인할 수 있다.
각 sensor들에 대해 간단히 살펴보자.
먼저 Intel RealSense의 경우 가볍고 low power consuming한 depth sensor이다. IR(infrared radiation) pattern을 촬영하는 공간에 projection하여 stereo matching을 통해 depth map을 얻을 수 있게 된다. outdoor 환경에서는 자동으로 IR pattern을 사용하지 않고 stereo matching을 하게 되는데, depth map의 quality가 안좋기 때문에 outdoor환경에서는 정확한 object 검출이 어렵다. 따라서 indoor scene을 찍는데만 realsense sensor를 사용했다. 아래 Figure 2에서 확인할 수 있듯이 첫 번째 열이 realsense에 대한 촬영 결과인데 다른 rgb-depth sensor들에 비해 raw depth의 quality가 좋지 않은 것이 대충 보아도 알 수 있다. 또한 reliable한 depth range도 짧은 편이다. 보통 3.5m 정도부터 noise가 심해진다고 한다. 하지만 realsense는 lightweight하기 때문에 다른 portable device에 embedded하기 좋아 가장 상용화가 빠르게 될 것이라고 하였다.


Asus Xtion과 Kinect V1 센서는 near-IR light pattern을 사용한다. indoor환경에 적합할 것이다. Xtion은 Kinect v1보다 color image의 quality가 좋지 않다. 하지만 Kinect v1은 높은 power source를 요구하기 때문에 두 센서의 장단점이 존재한다.


Kinect v2의 경우 time-of-flight를 기반으로 하며 많은 power source를 요구한다. TOF(Time of Flight)는 신호가 날아가서 어떤 물체에 부딪친 후 다시 돌아오는 시간(비행 시간)을 측정하여 사물의 깊이(depth)를 측정하는 것이다. 다른 rgbd sensor에 비해 detail한 depth 차이를 측정할 수 있어 더 정확한 high quality의 raw depth map을 얻을 수 있지만 빛을 흡수하는 검은색으로 된 물체나 반사가 되는 표면을 가진 물체에서 좋지 않은 성능을 보인다. sensor hardware상으로는 더 long distance의 depth range측정이 가능하지만, SDK에서 처리할 때 4.5m에서 depth를 자르고 손실된 object depth에 대해 filtering을 수행한다고 한다.

Sensor calibration
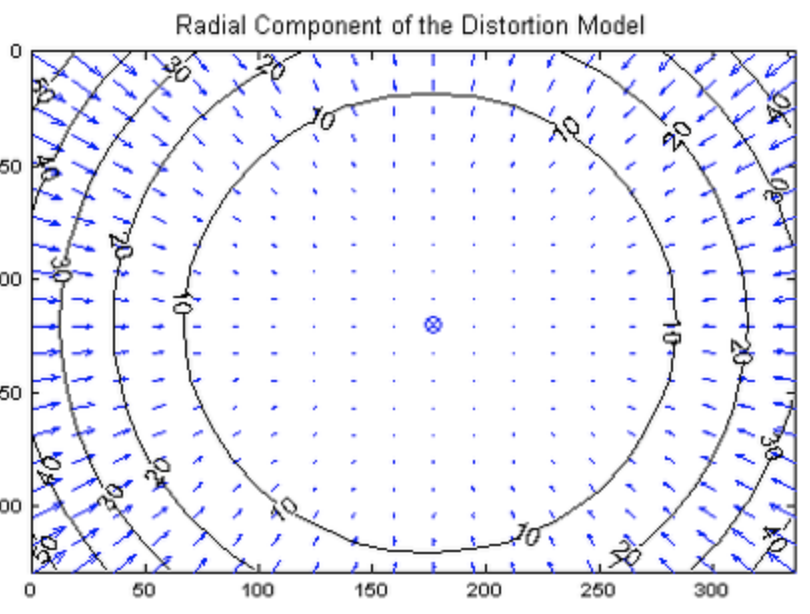
rgb-d sensor의 경우 depth camera와 rgb camera 간 camera intrinsic parameters를 이용하여 calibration을 진행해야한다. intel realsense의 경우 자체적으로 제공하는 default parameter를 사용하였고 asus xtion은 OpenNi 라이브러리를 통해 얻은 parameter를 사용했다고 한다. Kinect v2의 경우에는 radial distortion(방사 왜곡)이 심하기 때문에 모든 카메라에 대해 matlab으로 calibration을 수행했다고 한다. 여기서 radial distortion(방사 왜곡)이란, 볼록렌즈의 굴절률에 의한 현상으로 아래 그림과 같이 영상의 중심으로부터 거리에 의해 결정되는 왜곡이다.
Depth map improvement
위에서 언급된 rgb-d sensors들로 취득한 depth map은 많은 noise를 포함하고 occlusion boundary를 포함하는 등 완벽하지 않다. 모든 RGB-D sensor는 video camera처럼 작동하기 때문에 주변의 frames들을 사용하여 denoise과정과 missing depth를 채우는 과정을 통해 depth map을 개선시킬 수 있다.
저자는 depth map을 개선시키기 위한 multiple rgb-d frame을 integration하는 알고리즘을 제안한다. 시간 축에서 기준 frame과 근접한 frame마다 point를 3d로 사영하고 인접한 points마다 triangulated한 mesh를 얻는다. 그리고 기준 frame과 비교하여 3d rotation과 translation을 예측했다고 한다. 그리고 이렇게 정제된 depth map을 합쳐 robust한 예측이 가능하도록 한다. 각 pixel 위치마다 median depth와 25%,75% percentiles(백분율값)을 구한다. 만약 기준 depth가 없거나(missing) 25%~75% 범위를 넘어가면, 최소 10 frames의 depth map으로부터 median을 구해 그 값을 사용한다. 위의 경우에 해당되지 않으면 original value를 유지해서 oversmoothing을 방지한다. 위의 Figure 2에서 refined points가 위의 설명한 과정을 거친 정제된 depth 정보를 보여준다. 이 알고리즘에서 주변 frame과 기준 frame간 정확한 3D transformation을 예측하는 것이 가장 중요하다고 한다. 정확한 3d transformation을 측정하기 위한 방법으로 우선 SIFT를 통해 두 color image간 point-to-point로 상응하는 위치를 알아낸다. 그리고 raw depth map에서 SIFT keypoint에 해당하는 3d coordinate를 얻고 RANSAC을 통해 rigit 3D rotation과 translation을 예측하게 된다.
Data acquistion
앞에서 말했던 것처럼 PASCAL VOC정도 size를 가지는 dataset을 구축하기 위해 직접 많은 양의 data를 취득하고 이미 존재하는 다른 rgb-d dataset을 합쳤다. Kinect v2로 3,784장의 image를 찍고 Intel RealSense로 1,159장의 image를 찍었다. 그리고 기존에 존재하는 데이터 셋도 포함시켰는데 NYU Depth V2에서 1,449장의 image를 가져오고, Berkeley B3DO Dataset에서 554장의 realistic scene image를 직접 선택했다. 위의 두 개 dataset은 모두 Kinect v1을 통해 취득되었다. 그리고 Asus Xtion 센서를 통해 촬영된 SUN3D videos 데이터로부터 motion blur가 적은 3,389장의 frames를 직접 선택하여 총 10,335장의 RGB-D image를 포함하게 된다. 아래 Figure 5에서 보이는 것처럼 Intel RealSense(a)는 labtop에 붙여 사용하였고 Kinect v2(b,c)는 camera stabilizer를 통해 사용하였다.
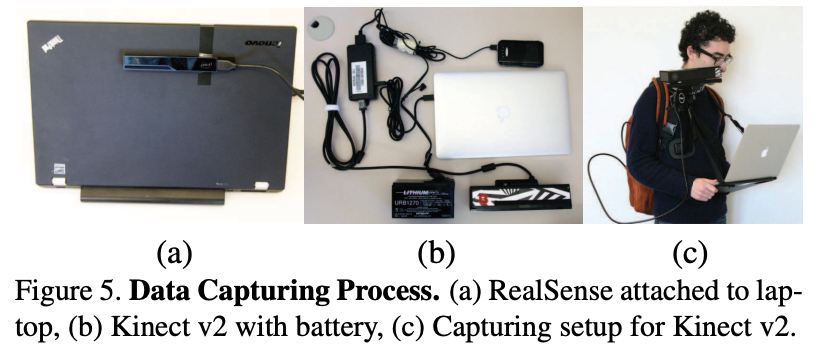
Kinect v2의 경우 많은 power를 소비하기 때문에 12v의 car battery와 5v의 스마트폰 battery를 사용했다고 한다. RGB-D sensor는 indoor에서만 잘 작동하기 때문에 장소를 고려할 때 university, house, furniture store와 같은 곳을 고려했다고 한다. 예시 그림은 아래 Figure 3에서 확인할 수 있다.

Ground truth annotation
각 rgb-d image에서 annotation의 경우 LabelMe style의 2D polygon annotation과 object에 대한 3d bounding box annotation, 그리고 room layout에 대한 3D polygon annotation을 수행했다. LabelMe는 annotaion tool로 PASCAL VOC와 COCO format이 해당된다고 한다. annotation의 quality와 일관성을 위해 다른 dataset에서 가져온 경우 직접 annotation을 수행했다고 한다.
2d annotation은 LabelMe-style tool을 사용했다. high quality의 label을 위해 automatic evalutation을 tool에서 사용했다고 한다. 각 이미지에는 최소 6개의 object에 대한 lable이 존재하고, 모든 object에 대한 annotation의 합집합 영역이 전체 image 영역의 80%이상을 cover할 수 있도록 구성했다. annotation하는데 이미지 한 장당 0.1달러가 들었다는 정보까지 알려준다.
3D annotation의 경우 point cloud가 camera coordinate 기준으로 되어있기 때문에 우선 gravity direction으로 align을 맞추도록 rotate시켜 annotation을 수행한다. 먼저 각 3D point마다 주변에 가까운 25개 points를 고려하여 normal direction을 예측한다. 그리고 histogram을 생성하여 maximun count된 곳을 첫 번째 축으로 한다. 두 번째 축은 첫 번째 축과 orthogonal하게 설정하고 이런 방식으로 얻은 rotation matrix를 통해 point cloud를 gravity direction으로 align을 맞춘다.
Label statistics
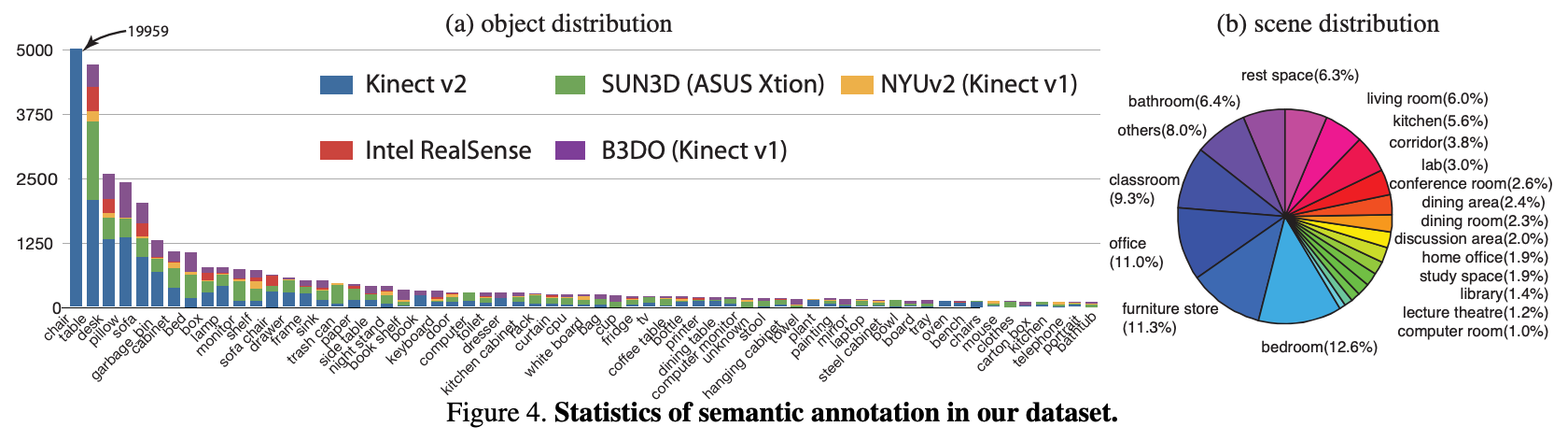
총 10,335장의 rgb-d image에 대해 146,617의 2d polygons와 64,595개의 3d bounding box annotation을 수행했다. 이때 3d annotation은 box의 heading angle까지 추정하는 OBB(Oriented Bounding Box)를 사용했다. 각 이미지에 평균적으로 14.2개의 object가 포함되어있고 총 47개 scene category에 800개 object category를 포함한다. 아래 Figure 4는 대표적인 object들에 대한 semantic annotation 정보의 통계적 분포를 나타낸 것이다.
Benchmark design
여기서는 Scene Categorization, Semantic Segmentation, Object Detection, Object Orientation, Room Layout Estimation, Total Scene Understanding 이렇게 6가지 task를 수행할 수 있도록 design되었다.
Scene Categorization은 scene understanding에서 유명한 task라고 한다. rgb-d image가 주어졌을 때 이미지를 하나의 scene category로 classify하는 task이며 average categorization accuracy로 평가한다.
semantic segmentation은 rgb-d image의 각 pixel 마다 semantic label을 예측하는 task이다. 평가는 object categories에 걸쳐 average accuracy를 사용한다.
object detection의 경우 3d iou를 통해 평가를 진행한다.
object orientation은 pose estimation이라고 생각하면 될 것 같다. 이미 object bounding box가 gravity와 align이 맞다고 가정하기 때문에, z축 기준 회전 각도에 대한 yaw angle만 추정하는 1-DOF task가 된다.
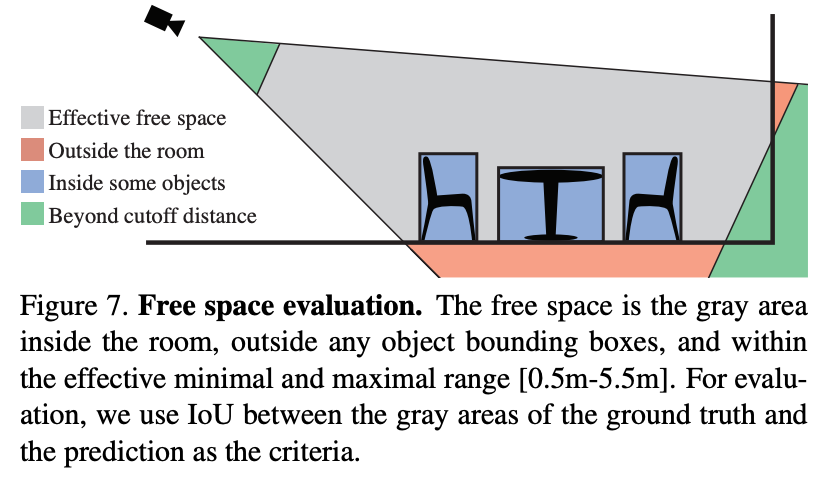
room layout estimation은 어디로 걸어갈 수 있을까? 와 같이 전체 space의 spatial한 layout을 예측하는 것이다. color-based scene understanding task에서는 challenging하지만 depth정보가 추가된다면 좀 더 실현 가능해진다고 한다. 아래 Figure 7을 보면 free space는 1)camera fov안에 들어와야하고 2)effective range에 들어와야하고 3)room 내부여야하고 4)object bounding box를 포함하지 않아야한다. 먼저 voxel grid를 정의하여 해당 voxel이 위에 4가지 조건을 만족하는지 판단하여 예측한다고 한다.
Total Scene understanding은 object와 room layout을 포함하는 전체 scene을 예측하는 task이다. 위의 object detection task와 room estimation task를 합쳐 해당 benchmark task를 제안했다고 한다.
Experimental evaluation
각 task마다 sota 알고리즘을 통해 평가를 진행했고 기존에 존재하는 방법론이 없는 경우 다른 task의 popular algorithm을 사용했다고 한다. train과 test이미지를 split할 때 training에 있던 building이 test에 포함되지 않도록 했다. NYU Depth v2는 기존 데이터셋의 split을 그대로 사용했다고 한다.
Scene categorization의 경우 19개 scene categories를 포함하는 80개 image를 사용했고 GIST와 Place-CNN이라는 방법론으로 평가를 진행했다. 아래 Figure 6에서 평가 결과를 확인할 수 있다. 괄호 안에 숫자는 average classification accuracy score이다. rgb-d를 모두 사용했을 때 더 정확한 예측을 할 수 있었다.

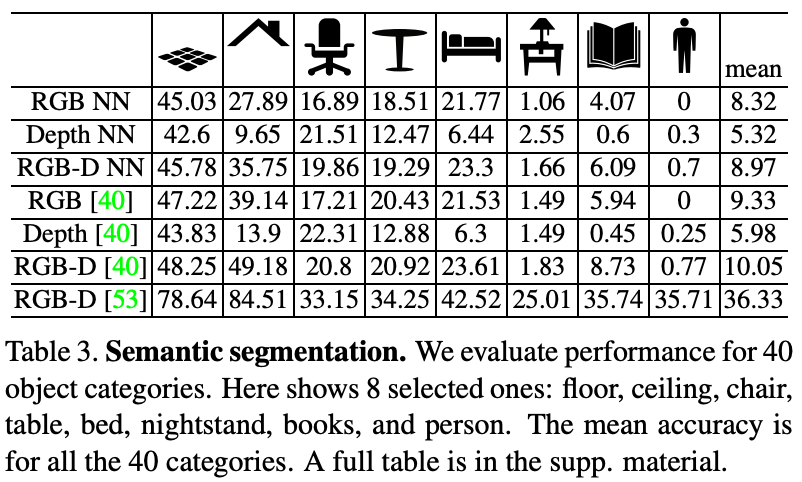
Semantic Segmentation의 경우 아래 Table 3에서 결과를 확인할 수 있다. 먼저 Place-CNN features로 nearest neighbor를 찾고 segmentation을 수행했다고 한다. 결과를 보면 floor, ceiling, bed와 같은 size가 큰 object에 대한 accuracy가 높은 것을 알 수 있다. [40,39]는 SIFT-flow 알고리즘을 적용한 것이라고 한다.
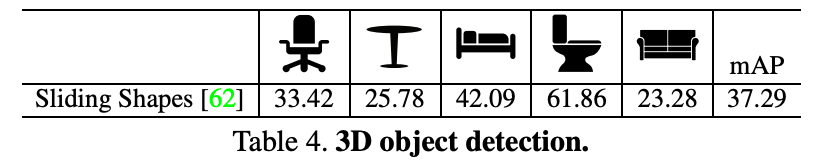
Object Detection은 2d에서는 DPM, Exemplar SVM, RGB-D RCNN, Sliding Shapes 이렇게 4가지 알고리즘으로 평가를 진행했다고 한다. depth 정보를 image channel에 추가해서 color image와 depth를 추가한 것에서 HOG를 구해 concat해서 사용했다고 한다. 아래 Table 5에서 결과를 확인할 수 있다.

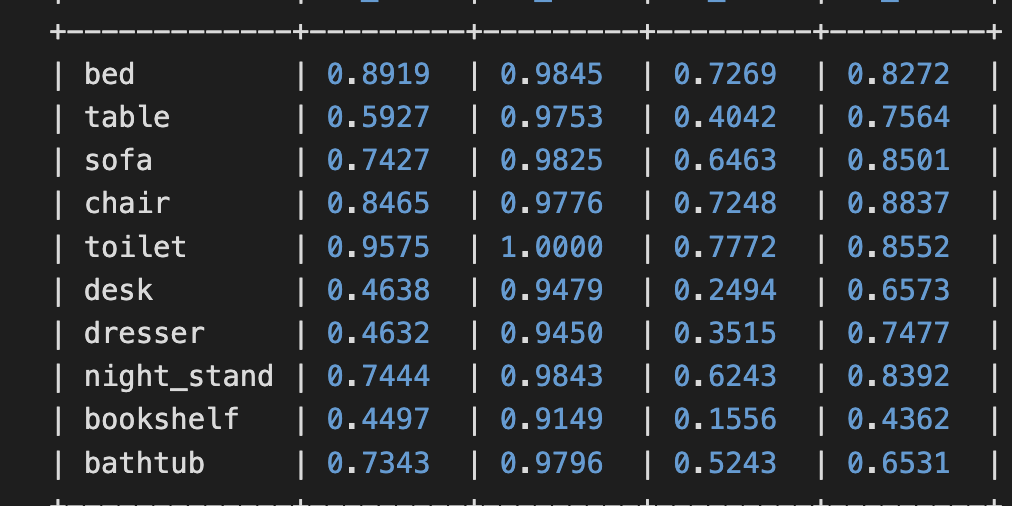
3d의 경우는 Sliding Shape 하나에 대해서만 진행했는데 오래전이기 때문에 3d object detection이 활발히 연구되기 전이라 아마 관련된 알고리즘이 미약했던 것 같다. 아래 Table 4는 논문에서 reporting한 성능이고 그 아래 그림은 최근에 sota모델인 TR3D-ff 모델 대해 직접 평가한 성능이다. TR3D-ff가 rgb, point cloud fusion모델이기는 하지만 대략적인 비교를 위해 첨부해보았다. 의자같은 경우 2배 이상의 성능차이를 보이고 다른 object들도 2배 이상의 큰 성능 차이를 보인다.
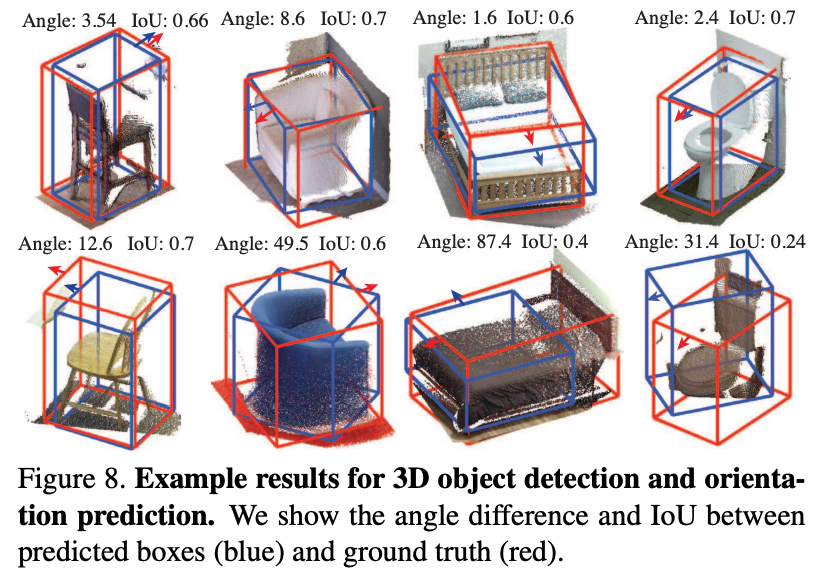
Object Orientation은 Exemplar SVm과 Sliding Shapes를 통해 평가를 진행했다고 한다. 아래 Figure 8에서 성능을 확인할 수 있다. 참고로 round table과 같이 orientation을 정하기 어려운 물체의 경우 평가에서 제외했다고 한다. object의 pose특징이 없는 물체의 경우 6d pose estimation이 굉장히 어려울 것 같고 gt도 부여하기 어려울 것 같다.
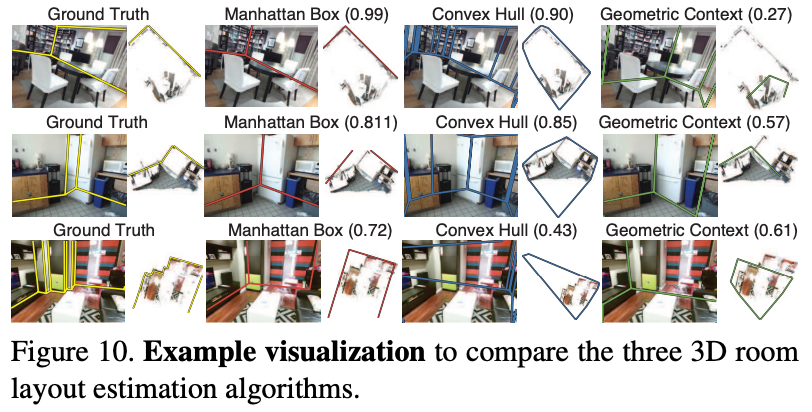
Room layout estimation은 기존에 존재하는 알고리즘이 있지만 open source가 아니어서 Convex Hull이라는 simple baseline으로 평가하고 stronger baseline으로 Manhattan box를 사용하여 평가했다고 한다. 그리고 color-based approach에서 비교하기 위해 Geometric Context라는 모델을 사용하여 비교하였다. 아래 Figure 10에서 visualize 결과를 확인할 수 있다. Manhattan Box가 가장 좋은 성능을 보이고 있다.
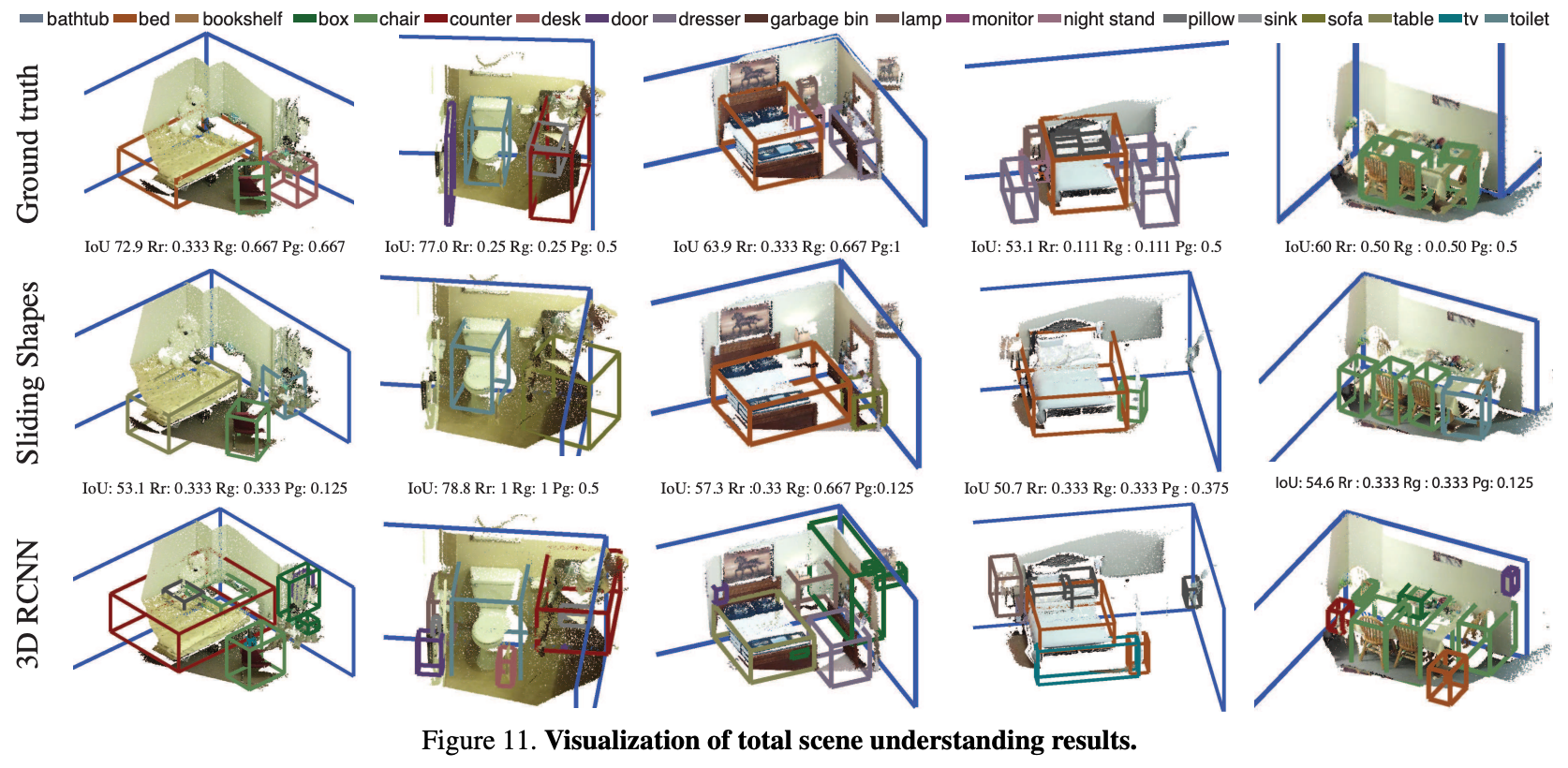
Total Scene Understanding task는 RGB-D RCNN과 Sliding shapes를 object detection 평가에 사용하고 room layout estimation task에선 Manhattan Box을 사용하여 둘을 combine했다. Figure 11에서 visualize 결과를 확인할 수 있다.
Conclusions
본 논문에서는 PASCAL VOC scale에 버금가는 2d와 3d annotation을 포함한 새로운 RGB-D benchmark인 SUN RGBD를 소개하였다. SUN RGBD가 2015년에 등장했지만 여전히 많은 3D Indoor task에서 benchmark로 사용되고 있다는 것은 그만큼 잘 만들어진 데이터셋이며 다른 3d annotation dataset에 비해 large scale의 데이터셋이기 때문에 많이 사용한다고 생각이 된다. 3d indoor object detection task를 보았을 때 많은 방법론들이 data-driven한 방법을 통해 문제를 해결하고 있다는 것을 느꼈다. rgbd 센서가 depth 정보를 취득했을 때 불완전한 depth map을 보여주고 있기 때문에 hardware가 더 발전한 현 시점에서 더 좋은 quality의 3d annotation을 수행한 large scale의 데이터셋이 등장할 수 있을 것이라 생각해본다. SUN RGB-D의 예시 이미지를 끝으로 마무리하겠다.

안녕하세요 김도경 연구원님, 좋은 리뷰 감사합니다.
며칠 전에 depth 카메라로 무언가 하고 계신것을 봤는데, 데이터셋 취득을 위해서 알아보시는 중이셨군요, 데이터셋 취득 관련 논문도 열심히 읽으시는것 보니 나중에 취득할 데이터셋이 기대됩니다. 저에게는 URP때 읽었던 Kaist dataset 논문이 이 리뷰를 이해하는데 많은 도움이 되었습니다. Kaist dataset의 RGB-Thermal image 취득 과정에서 thermal 카메라가 depth로 바뀐 것으로 이해했습니다.
몇 가지 질문이 있습니다.
1. Polygons annotation 이 무엇을 뜻하는 것인가요?
2. figure 8에서, orientation은 구체적으로 무엇을 의미하는 것인가요?
감사합니다.
댓글 감사합니다.
1. polygon annotation이란 단어 그대로 polygon이 다각형이라는 뜻으로 Figure 4에서 보면 2d, 3d모두 다양한 크기와 모양을 가지는 다각형 형태의 box annotation이 되어있는 것을 확인하실 수 있을 것입니다.
2. orientation은 object가 향하고 있는 방향 정보를 의미합니다. 다른 indoor dataset의 경우 카메라를 바라보는 방향으로 각도가 맞춰진 형태인 AABB(Axis Align Bounding Box)로 annotation되어있는데 sun rgbd의 경우 z축기준 물체의 회전된 각도를 고려한 OBB(oriented bounding box)형태의 annotation을 하여 물체의 heading angle 정보까지 제공합니다.
좋은 리뷰 감사합니다!
해당 데이터셋이 6가지 태스크를 타겟으로 설계되었다고 설명을 보았습니다.
각 태스크에 대한 어노테이션을 어떻게 진행했는지에 대한 정보 공유 가능할까요?
댓글 감사합니다
SUN RGBD는 Scene Categorization, Semantic Segmentation, Object Detection, Object Orientation, Room Layout Estimation, Total Scene Understanding 이렇게 6가지 task를 target으로 설계되었습니다. 각 task에서 annotation에 대해 논문에서 자세하게 설명하고 있지 않아 데이터 파일과 코드를 참고하여 확인한 내용으로 말씀드리겠습니다. Scene Categorization은 전체 scene이 어떤 category에 속하는지 나타냈고 semantic segmentation은 pixel level로 annotation되어있습니다. object detection과 orientation의 경우에는 이미지마다 class이름, 2d box 좌표(xmin,ymin,xmax,ymax), centroid(x,y,z), w, l, h, orientation(x,y)이렇게 구성되어있습니다. room layout estimation의 경우 벽이나 바닥에 대해 3d로 annotation을 수행했습니다. total scene understanding의 경우 detection과 room layout annotation을 합쳐 사용했습니다. ‘https://www.youtube.com/watch?v=fOQdC7aeIr8’ 해당 유튜브 링크에서 보면 직접 annotation tool을 사용하여 top, side, front view를 한 번에 annotation을 수행하는 것을 알 수 있습니다.