제가 이번에 리뷰할 논문은 6D pose estimation에서 많이 사용되는 LINEMOD 데이터 셋의 논문입니다. 해당 논문은 데이터 셋 논문이라기 보다 방법론 논문에 해당합니다. 그러면 리뷰를 시작하도록 하겠습니다.
Introduction
LINEMOD는 여러 뷰에서 포착한 외관과 3D 형태에 대한 템플릿을 세트로 가지고 있어 depth와 color 정보를 효과적으로 추출할 수 있는 방법론이라 합니다. 그러나 기존의 LINEMOD는
- 템플릿이 온라인으로 학습하여 컨트롤하기 어렵고, 얼룩덜룩하게 예측이 되며,
- 주변 view-point만을 다룰 수 있어 pose를 근사하여 예측해야하며,
- 성능이 좋지만 여전히 false positive가 존재한다고 합니다.
이러한 단점을 해결하기 위해 LINEMOD 기반의 자동 모델링, detection, tracking이 가능한 시스템을 만들었다고 합니다. 저자들은 3D 모델을 이용할 경우 이를 해결할 수 있다는 인사이트를 가지고 방법론을 제안하였다고 합니다. (기존 논문에 의하면 3D 모델은 빠르게 생성할 수 있으며, 상업적으로 상품을 만들기 전에 디테일한 3D 모델을 만들기 때문에 사전에 3D 모델이 필요하다는 것이 단점이 아니라고 합니다.)
따라서 저자들은 해당 논문을 통해 3D 모델이 주어질 경우 어떻게 템플릿을 생성하는지, 3D 모델이 정확한 pose estimation을 위해 어떻게 사용되는지, 템플릿 detection 단계에서 속도를 높이기 위해 유용한 외관/depth 정보를 어떻게 정의하는지를 설명하였습니다. 결과적으로 original LINEMOD보다 성능이 향상되었고, 정확한 pose를 제공하였다고 합니다.
요약하자면, 본 논문을 통해 배치가 쉽고 신뢰할 수 있으며 빠른 pose estimation 프레임워크를 제안하였고, 데이터셋을 제공합니다. 이때 데이터셋은 15개의 object로 구성되며, 각 object는 1100 프레임 이상의 sequence로 구성되어있습니다.
Related Work
3D detection과 localization은 어렵지만 로보틱스에서 중요한 문제입니다. 사용하는 데이터에 따른 관련 연구를 정리한 내용입니다.
Camera Images
이미지를 기반으로 하는 object detection은 (1)학습 기반 방식과 (2) template기반 방식으로 나눠집니다.
우선 학습 기반 방식은 사람 얼굴, 차량, 다른 object 등 특정 class에는 잘 일반화가 되지만, 한정된 object pose 세트와 학습 DB와 시간이 많이 필요하다는 단점이 있으며, 정확한 pose를 예측하기 어렵다고 합니다. 이러한 문제를 해결하고자, 3D 외관을 학습하려 하는 연구들이 등장하였고, 차량의 CAD모델을 이용하는 방식, 기하학적 형태와 pose의 우선순위를 이미지와 함께 이용하는 방식 등이 나왔고, 이러한 방법론은 마찬가지로 잘 작동하고 객체 class로 일반화 되지만 학습이 비싸고, clutter한 경우와 occlusion은 다루지 못하며 이러한 이유로 real-time 작동이 어렵다는 한계가 있습니다. 또한, 윤곽에 의존하며 새로운 feature인 BOB(bag of boundaries, 주어진 이미지를 이미지 윤곽의 바운더리에 대한 histogram으로 나타내는 방식으로, 템플릿 매칭 방법에서 descriptor로 이용됨)를 도입하는 방법론이 있으나, 이는 real-time 작동이 어렵고 정확한 pose를 찾을 수 없다는 단점이 있었다고 합니다.
정리하자면 저자들은 real-time이 가능하며, 새로운 object를 학습할 수 있고, clutter와 occlusion에도 대응 가능하고 한번에 여러 object도 인식할 수 있는 방법론을 제안하였다고 합니다.
Range Images
Pose 추정에 표준 방식인 ICP(Iterative Closest Point, 서로 다른 두 개의 점군의 정합을 맞추는 방식으로, point들을 매칭하여 오차를 최소화하는 방식이라합니다.) 방식은 처음에 추정값이 필요하며 object detection에는 적합하지 않다고 합니다. 3D feature를 이용하는 방식은 object detection에는 도 적합하지만 pose 조정에 ICP를 이용한다고 합니다. 이러한 방법 에 spin-image를 함께 이용할 경우 연산이 비싸고 장면이 clutter할 경우 예측이 어렵다고 합니다.
RGBD Images
RGBD 영상은 classification, pose estimation, reconstruction등의 task에 사용되었으며, Depth-Encoded Hough Voting for Joint Object[1] 방법론은 depth와 이미지 정보를 통해 허프 트랜스폼을 이용하여 object를 검출하는 방식으로, real-time으로 작동할 수 있으나 학습에 너무 많은 데이터가 필요하다는 단점이 있고, Lei 연구진의 방법론[2]은 카테고리와 인스턴스 레벨에서 문제를 해결하고자 하였고, large 데이터 셋을 제공하였으나, 상당히 clutter한 장면에서 잘 작동하는지와 real-time 작동이 가능한지는 보이지 않았다고 합니다.
[1]Sun, M., Bradski, G.R., Xu, B.X., Savarese, S.: Depth-Encoded Hough Voting for Joint Object Detection and Shape Recovery. In: ECCV. (2010)
[2]Lai, K., Bo, L., Ren, X., Fox, D.: Sparse distance learning for object recognition combining rgb and depth information. In: ICRA. (2011)
Approach
본 논문은 LINEMOD를 기반으로 하는 방법론입니다. LINEMOD란 multi-modal 템플릿에 효과적으로 작동하는 방식으로, color 이미지에 depth map을 할당하는 방식이라 합니다.
LINEMOD의 탬플릿은 object 검출을 위해 가능한 외관 정보를 샘플링하고, dense하게 샘플링된 이미지의 gradient와 depth map을 생성한다고 합니다. 이를 통해 object가 검출되었을 때, 2D 위치 뿐만 아니라 대략적인 pose도 추정한다고 합니다.
이제 논문을 통해 위에서 저자들이 이야기했던 3D 모델이 주어질 경우 어떻게 템플릿을 생성하는지, 3D 모델이 정확한 pose estimation을 위해 어떻게 사용되는지, 템플릿 detection 단계에서 속도를 높이기 위해 유용한 외관/depth 정보를 어떻게 정의하는지를 알아보겠습니다.
1. Exploiting a 3D Model to Create the Templates
먼저 3D 모델로부터 템플릿을 생성하는 방식에 대한 설명입니다. CAD 3D 모델에서 템플릿을 자동으로 구축하는 방식으로 기존의 온라인 방식(필요한 템플릿을 사람이 수동 샘플링을 해주는 방식) 대비, 사람의 시간과 노력이 덜 필요하며, 전체 포즈를 커버할 수 있는 잘 샘플링된 train 셋을 수집하기 좋다는 장점이 있다고 합니다.

Viewpoint Sampling
신뢰성과 효율성을 위해 템플릿의 갯수를 적절하게 조절해야 한다고 합니다. 아래의 그림처럼, 삼각형을 4개의 정삼각형으로 대체하는 과정을 반복하여 fig2의 왼쪽 이미지와 같이 다면체를 샘플링하며, 신뢰성과 효율성을 위해 꼭짓점이 162개일 때까지 반복하였다고 합니다. 각 꼭짓점이 viewpoint가 되도록 샘플링을 합니다.

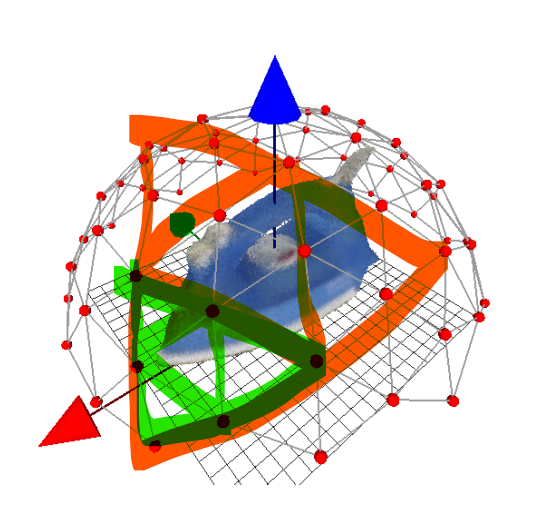
또한, 크기를 다양하게 하여 샘플링을 수행하고 step size를 10cm로 설정하였다고 합니다.(아래의 그림으로 보면, 빨간색, 초록색, 파란색이 서로 다른 스케일에서 view-point 샘플링을 수행한 것입니다.)

Reducing Feature Redundancy
불필요한 중복을 줄이기 위한 과정으로, LINEMOD는 (1)color 이미지에서 계산되는 color gradient와 (2)object 3D 모델에서 계산되는 surface normal이라는 두가지 feature를 이용합니다. (normal은 법선을 의미)
(1) Color Gradient Feature
texture-less의 경우 CAD 3D 모델에서도 texture 정보를 활용할 수 없으므로, 객체 실루엣의 윤곽에 있는 주요 color gradient feature만을 유지합니다. 먼저 샘플링된 pose에 대해 3D 모델을 투영하여 object의 실루엣을 계산한다고 합니다. 그 다음 기울기가 가장 큰 부분부터 시작하여 greedy approach를 이용하여 다음 feature의 위치를 찾아가며, 이때 거리 임계치를 이용해 가까운 feature는 목록에서 제거하는 과정을 반복한다고 합니다.
원하는 수 만큼의 feature 위치를 찾으면, 거리 임계치를 1씩 낮추어 앞서 수행한 프로세스를 반복한다고 합니다. 이때 임계치는 실루엣이 차지하는 면적과 선택해야 하는 피쳐 수의 비율로 초기값이 설정된다고 합니다. (결과는 그림 2의 가운데 이미지의 빨간색에 해당합니다.)
(2) Surface Normal Feature
3D object 를 투영시켰을 때 테두리 부분이 안정적으로 추정되지 않는 문제가 있어 surface normal feature는 object의 실루엣 내부에서 선택하도록 하였다고 합니다.
object의 3D 모델에서 depth map을 계산하여 템플릿을 생성하는 방식으로, 주변 법선 벡터들이 유사한 경우 더 안정적으로 recover 된다는 점에 주목하여 이러한 안정적인 normal을 유지하고, 불안정한 normal은 버리려고 한다고 합니다. 이를 위해 먼저 특정 pose에서 생성된 depth map에서 이산화된 방향의 8가지 값에 대한 각각의 마스크를 생성합니다. 이후, 8개의 마스크 각각에 대해 마스크 경계까지의 거리에 따라 각 normal에 가중치를 부여한다고 합니다. 거리가 멀면 비슷한 normal이 주변에 있다는 의미이고, 거리가 가까우면 다른 normal들이 주변이 있거나 실루엣 경계에 가까운 경우로, 가까운 normal은 제거하였다고 합니다. 이때 단순히 normal의 가중치만을 이용하기보다, 해당 normal이 속한 마스크의 크기에 따라 가중치를 정규화하여 normal을 선택한다고 합니다. 정규화된 가중치에 따라 순위를 매긴 surface normal 목록을 만들고, 유지할 normal을 반복적으로 선택하면 균일하게 퍼진 surface normal을 구할 수 있습니다.(그림2의 가운데 이미지 중 초록색에 해당합니다.)

2. Postprocessing Detections
두번째로 3D 모델이 정확한 pose estimation을 위해 어떻게 사용되는지에 대한 설명입니다.
우선, (1)유사도 점수가 높은 템플릿부터 해당 위치에 있는 color 이미지와 object 색상을 고려하여 결과가 일관성 있는지 확인합니다. 이후 (2)해당 물체의 3D pose를 추정합니다.
3D pose 추정값이 수렴되지 않는 결과들은 모두 제거하고, 모든 테스트를 통과한 첫번째 n개의 감지값 중 최적의 pose를 추정하게 됩니다.
이제 각 과정에 대해 더 자세히 알아보겠습니다.
(1) Coarse Outlier Removal by Color
템플릿은 색상 정보를 이용하여 포즈에 대한 대략적인 추정치를 제공합니다. 예상 색상을 가지는 픽셀 수를 계산하는 방식으로, 템플릿 영상의 색상 픽셀 수와, object의 픽셀 수를 계산하여 두 값의 차이가 임계값보다 작을 경우 오탐지로 고려하여 detect 결과를 제거하게 됩니다.(해당 논문에서는 70%를 기준으로 설정하였다고 합니다.)
(2) Fast Pose Estimation and Outlier Rejection based on Depth
오탐지가 아닌 추정치들에 대한 pose estimation을 수행하는 과정입니다. 빨리 수행하기 위해 일부를 subsampling하여 ICP 방법을 이용하여 pose를 추정하며, 견고성을 위해 각 반복(i) 과정에 inlier 3D 포인트만을 이용하여 alignmet를 계산하도록 하였다고 합니다. inlier 포인트는 3D 모델과의 거리가 임계치 t_i 내에 있는 점으로, t_0는 object의 크기로 크기로 초기화되며, t_{i+1}은 i시점의 3D 모델에 대한 inlier의 평균 거리의 3배로 설정된다고 합니다.
모든 detection 결과에 대한 테스트를 진행하거나 3개의 detection 결과가 이 과정을 통과할 때 까지 반복합니다. 이후 모든 포인트의 depth map에 대한 ICP를 적용하여 느리지만 정확한 최적의 detection 결과를 도출해냅니다. 최적의 detection 결과는 3D 모델과의 평균 거리와 inlier 점의 수를 비교하여 결정됩니다.
여기에 최종 depth 테스트를 수행합니다. 최종 pose 추정치에 따라 object를 투영시켜 object의 픽셀 수를 계산하여 영상의 픽셀 값이 투영된 object 영상의 픽셀값과 일정 임계치 이하일 경우 최종적으로 오탐지로 보고, 임계치 이상일 경우 최종 pose로 예측됩니다.
Experiments
15개의 texture-less object로 구성된 대규모 데이터 셋(LINEMOD로, 이후 pose estimation에서 많이 사용되는 데이터셋)을 만들었다고 합니다. 각 object는 3D 모델 및 이미지 획득을 위해 마커(GT Pose정보를 얻기 위해 기준)가 부착된 평면 보드의 중앙에 두었고, 각 시퀀스는 다양한 view-point에서 촬영된 1100장 이상의 이미지로 구성됩니다. 또한 샘플링이 잘 분산되도록 하기 위해, 물체의 상반구를 균일하게 동일한 거리의 조각으로 나눠 각 조각당 한장의 이미지를 촬영하였다고 합니다.
Robustness
평가를 위해 아래의 식을 이용하여 matching score를 구하였다고 합니다. \mathbf{R ,T}는 각각 GT rotation,과 translation을 의미하며, \mathbf{\tilde{R} ,\tilde{T}}는 각각 예측된 rotation,과 translation을 의미합니다.
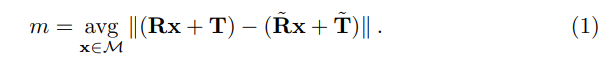
\mathcal{M}은 3D 모델을 의미하며, k_md≥m에 해당할 경우 올바르게 pose가 추정된 것으로 봅니다. 이때 k_m은 coefficient로 Table 1에서는 0.1로 설정되었으며, d는 Object의 직경을 의미합니다.
또한, ”cup”,”bowl”,”box” and ”glue”와 같이 객체의 방향을 알기 어려운 경우에 대해서도 별도의 matching score를 정의하였으며, 아래의 식으로 정의가 됩니다.
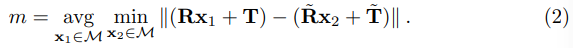
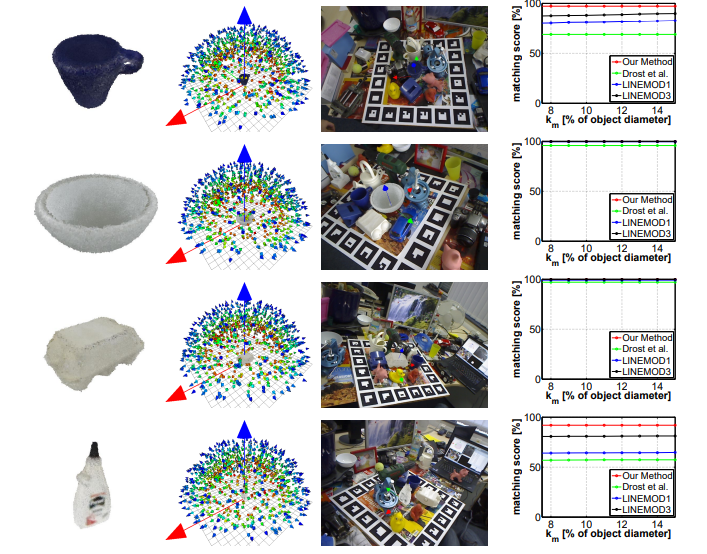
Table 1을 통해 저자들이 제안한 방식이 가장 좋은 성능을 나타내는 것을 확인하였습니다. (postprocessing 과정을 통해 pose를 추정한 방법) Drost 연구진의 방법론과 비교했을 때 평균 17.3% 성능이 좋았으며, 기존 LINEMOD에 비해서는 평균 13% 향상되었다고 합니다.
Speed
Table 1의 결과를 통해 저자들의 방식은 평균 119ms가 소요되며, Drost 연구진의 방식보다 53배 빠른 결과를 확인할 수 있음을 보였습니다.
좋은 리뷰 감사합니다.
2012년이면 꽤 오래된 LINEMOD 데이터셋으로부터 지금까지 6D pose estimation에 대한 연구가 이루어진 것을 처음 알게 되었습니다.
viewpoint sampling 과정에 대해 질문이 있습니다.
신뢰성과 효율성을 위해 꼭짓점이 162개 일 때까지 반복한다고 하는데 영상 내에 있는 모든 object에 대해서 162개를 하는 게 맞는가요? 만약 맞다면, small object에 대해서도 동일하게 162개를 생성할 수 있는지도 궁금합니다.
감사합니다.
우선 마지막 그림을 보았을 때, 모든 object에 대한 162개의 view-point를 고르는 것이 아닌, 중심에 있는 object를 기준으로 162개의 view-point를 구하는 것으로 이해하였습니다.
리뷰 잘읽었습니다!
이번 논문이 데이터 셋 논문으로 이해해서 어떻게 구성했는지를 주안점으로 보고 있었는데 그 내용보다는 검출 방법론이 주된 내용인 것 같네요.
혹시 제가 잘못읽은 걸까요?
데이터셋을 보완한 논문이 아닌거죠?
맞습니다. 저도 데이터 셋 논문인 줄 알고 있었는데, 해당 논문이 데이터 셋을 구축하고 공개한 것은 맞지만, 데이터셋에 대한 구체적인 설명보다는, 방법론에 대한 설명이였습니다.
또한, LINEMOD라는 용어가 방법론을 의미할 때도 있고(방법론이 2011 ICCV에도 동일 저자가 공개한 내용이 있었습니다.) 데이터셋을 의미할 때 도 있는데, 해당 논문이 최근에 흔히 말하는 LINEMOD인 것으로 파악하였습니다.
안녕하세요 승현님 좋은 리뷰 감사합니다!!
Color Gradient Feature 부분에서 질문이 있는데 ‘샘플링된 pose에 대해 3D 모델을 투영하여 object의 실루엣을 계산’ 하는 부분에서 object의 실루엣의 계산은 어떻게 이루어지는 설명해주실 수 있나요?? 그리고 원하는 수 만큼의 feature 위치를 찾고 거리 임계치를 1씩 낮추는 이유는 낮은 거리 임계치를 사용해서 더 작은 간격으로 feature를 추출하여 객체의 다양한 부분에서 더 많은 윤곽을 찾기 위함이 맞나요??
감사합니다!