
안녕하세요. 열 두번째 X-Review입니다. DETR부터 시작해 몇 주간 Tiny(small)-object detection에 관한 논문을 읽고 있습니다. 지난 주는 2022 CVPR Paper list에서 Tiny-object detection에 관한 논문을, 이번에는 2022 AAAI Paper list에서 Tiny-object detection에 관한 논문을 읽었습니다. 특히 이번 논문의 Contribution 중 하나 (UFP)는 예전 IPIU 실험 때 아이디어 중 하나였는데, 아쉬움도 남습니다.
그렇기에 이번 논문은 흥미있게 읽혔으며, X-review를 2 주차 간 작성하기로 했습니다. 또 하나 드는 생각은 최근 Drone Image를 대상으로 하는 Object detection에 관한 연구가 이전보다도 활발해지는 것 처럼 느껴집니다. Drone Image의 특성 상 Tiny하면서도, ViewPoint가 일반 영상과 다르다보니 Challenge한 Task인 것 같네요.
추가적으로, 해당 방법들에 대해 제가 생각한 문제점 및 고찰과 그로부터 내는 아이디어를 담고 있습니다. 아마 최근에 지속적으로 해당 분야의 논문을 읽어왔기 때문에 아닐까 싶으며 이후의 연구에 적용해보고 싶은 점이 많은데, Small object detection은 제 주된 관심 연구 주제로 오래 남을 것 같습니다. 그럼 리뷰 시작하겠습니다.
Introduction
UAV (Unnamed Aerial Vehicle), 드론은 이동성과 안전성의 상충 관계를 고려했을 때 이목을 끄는 이동체입니다. 드론은 보안, 감시, 항공 사진, 배달, 특히 미국처럼 대지 농장에서의 농산업에서도 자주 사용됩니다. 그렇기에 드론 이미지 기반 object detection은 필수적이자 근본적인 이슈가 되고 있습니다만, 문제점이 있습니다. 그 문제점은 생각해보면 어렵지 않습니다. CNN의 발달과 더불어 object detection 분야는 굉장한 발달을 이루었지만, 드론 이미지는 정확도와 효율성 측면에서 많은 아쉬움이 있습니다.
그 문제점으로 첫 번째는 드론 이미지는 많은 수의 작은 사이즈의 물체를 포함합니다. 이는 드론이라는 특성, 즉 공중에서 촬영했기에 그만큼 FoV와 ViewPoint를 생각하면 영상 내 Instance를 많이 포함한다는 점도, Instance의 사이즈가 작다는 점을 충분히 납득할 수 있습니다. Pascal VOC나 MS COCO는 지상에서 촬영한 영상을 다루고 있었으며, 따라서 드론 영상을 대상으로 하는 detection 연구가 활발하지 않았다는 점도 납득될만합니다. 그도 그럴 것이, Pascal VOC나 MS COCO는 2010년과 2014년에 나온 데이터 셋인 반면, 드론 이미지 데이터 셋의 대표격인 VisDrone은 2019년에 나왔기 때문입니다. 아래 사진 (a)를 통해 확인하시면 좋습니다.

우리는 흔히 Image Pyramid (대표적으로 FPN) 방법을 생각할 수 있지만, 드론 이미지에서는 물체의 크기는 물론 그 수가 많으므로 computing resource를 고려했을 때는 부적합한 방법이며 경쟁력이 없습니다. 대신 근래들어 coarse-to-fine 파이프라인 방법이 대두되었는데, 이에 대해 살펴보고 넘어갈 필요성이 있어보입니다. coarse-to-fine, 직역하면 거친 것에서 미세한 것으로라는 의미로 의미 그대로 이미지에 대해 쓱- 한번 대략적으로 훑는 detection 이후 다시 자세하고 세부적으로 detection 하는 과정을 의미합니다.
다시 말해 coarse detector는 대략적인 객체 감지를 수행하며, 객체의 Bounding box를 Fine-tune 하는 과정, 객체의 클래스를 조정하는 과정보다는 객체의 존재 여부에 관심을 두고 있습니다. 즉 속도와 효율성에 중심을 둔 detection 방법으로 ML 기반 HOG, CNN 기반 YOLO 등이 사용될 수 있습니다.
반면 fine(fine-grained) detector는 coarse detection 결과로부터 확인된 객체 영역에 대해 상세히 분석하여 Bounding box를 조정하는 과정, 객체의 클래스를 구별하는 과정에 초점을 둡니다. Bounding box 내 세부 정보를 중점에 둔 detection 방법으로 주로 CNN 기반 Faster R-CNN, SSD, Mask R-CNN 등이 사용됩니다.
coarse-to-fine detection 방법론은 2019년에 등장하였으며 처음 들었을 때는 detector를 중첩해서 두어 속도 측면에서 비효율성이 높지 않을까 생각하여 해당 방법론을 사용한 논문을 몇 편 살펴보았으며, 대표적으로 아래 그림을 살펴보면 Coarse Detection Stage 이전에 영상을 다운샘플링 (Down-sampling)하는 모습을 통해 computing resource 및 효율성에서의 측면을 고려한 방법 혹은 단순히 CNN 두-세 층만을 쌓은 방법도 존재합니다. 해당 파이프라인의 장점은 다른 성격을 갖는 두 detector를 통해 전략을 세울 수 있다는 점입니다.
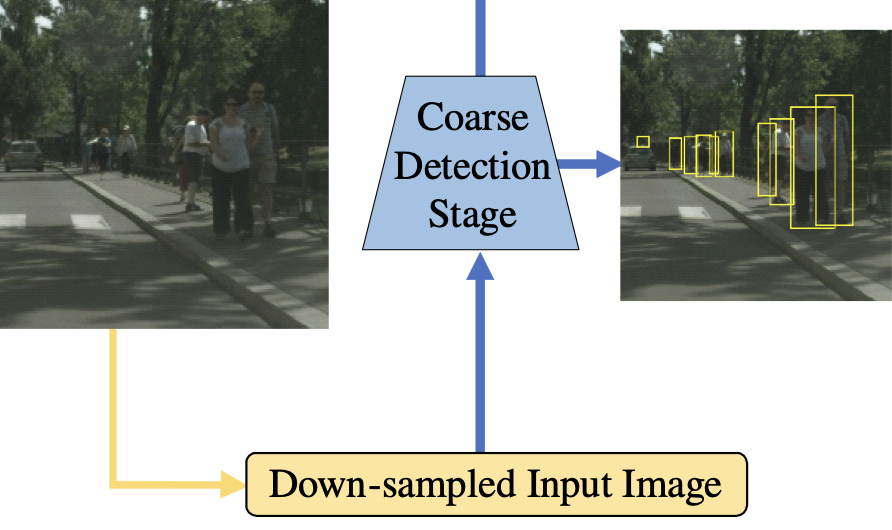
본 논문에서는 coarse detector의 역할을 large-scale instance의 위치를 찾음과 동시에 small instance가 밀집되어 분포되어 있는 sub-region을 찾는 것을 목표로 합니다. 이는 즉 small instance의 위치와 개별 instance를 분리하는 것은 fine detector의 역할로 분리하겠다는 의미입니다. 따라서 fine detector는 해당 sub-region을 입력으로 받아 small size의 instance를 찾는 것을 주 목표로 합니다. 해당 방법은 꽤나 전도유망하지만, coarse detector의 sub-region은 background가 차지하는 비율이 많기에 다소 rough하다는 특징이 있습니다. 이는 다시 효율성의 문제를 불러옵니다.
더욱이 해당 방식처럼 다수의 sub-region (multiple chips)마다 detection 과정을 통과하는 것은 추론 속도와 성능의 하락을 초래합니다. coarse-to-fine detection의 두 단점으로 인해 성능과 효율성의 향상은 고려 대상으로 남아있습니다. 해당 파이프라인에 대해 처음 듣고서 소개하다보니, 꽤 자세히 쓰게 되었네요.
두 번째 문제점으로 VisDrone 등의 데이터 셋을 살펴보면 object의 몇몇 클래스가 의미론적으로 굉장히 비슷하다는 점입니다. 예를 들어 아래 사진 (b)를 보면, person과 pedestrian, Awning-tricycle(천막 세발자전거)과 tricycle은 다른 클래스로 분류되어있지만 의미론적으로 보면 혼동이 옵니다. 그 뿐만이 아니라 비행 고도, 시야각, 기상 환경, instance와의 거리 차이 (하나의 클래스, 예를 들어 person이라고 해도 ViewPoint에 따라 크게 보일 수도, 작게 보일 수도 있습니다) 등의 장애물 요소 또한 문제점 중 하나입니다.

위의 두-세 문제점을 요약하자면 inter-class (클래스 간) 유사성이 높다는 점과, intra-class (클래스 내) 다양성이 높다는 점 (특이점이 적다는 점)이 문제로 대두됩니다. 이는 detection task에서는 다소 흔한 일로 클래스 구별을 어렵게 만드는 요인 중 하나입니다만, 현재까지의 연구는 drone 데이터 셋에 관한 연구가 활발히 일어나지 않았기 때문에 이러한 점을 주요 contribution으로 삼지는 않은 모습입니다.
저자는 해당 문제점들을 타파하고자 UFP (Unified Foreground Packing) 모듈과 MP-Det (Multi-Proxy Detection Network) 모듈을 제안합니다. 이 둘을 엮어 UFPMP-Det이라 명하며 이번 Part 1. 리뷰에서는 UFP 모듈에 대해 살펴보겠습니다. 우선 두 모듈에 대해 알려드리자면 UFP는 Two-stage로 구성되며 특정 클러스터링 알고리즘을 통해 foreground sub-region들이 사이즈 별 (small-middle-large scale size) 병합됩니다. 병합된 이미지는 확대되어 Mosaic 방법을 통해 하나의 이미지를 구성합니다. 해당 방식을 통해 이미지 내 small object가 차지하는 비율이 많아지며 동시에 fine-detector를 통한 성능 또한 향상될 수 있습니다. 이는 곧 small-object에 대한 성능 향상 및 속도 향상을 이끕니다.
이후. MP-Det은 Retrieval task의 multi-proxy learning 방법을 object detection에 적용한 방법으로, 복합적이고 유연한 Bounding box 내 클래스의 분류 성능을 향상하는데 초점을 맞춥니다. Bounding box가 복합적이고 유연하다는 의미는 위 UFP를 통한 클러스터링 결과로 생긴 convex bounding box를 의미하는데, 이는 UFP 모듈 설명에서 살펴볼 예정입니다.
특히 MP-Det은 multi-proxy training 과정에서의 collapse phenomenon을 우회하고자 Bag-of-Instace-Words (BoIW)를 통한 최적화 방법이 소개됩니다. 이들은 최적화와 연관된 내용이므로 지금 당장은 이해하기 어려우므로 해당 모듈의 역할이 클래스 분류 성능을 높이는데 초점을 두고 있다는 측면만 이해한 채 넘어가면 좋을 것 같습니다.
Related Work
Related Work에서는 Generic Object Detection, Object Detection on Drone Imagery, Small Object Detection에 대해 말하고 있습니다. Generic Object Detection은 Anchor-based detection (i.e. Faster-RCNN, SSD, YOLO etc)과 Anchor-free detection (i.e. FCOS, GFL, DETR etc)에 대해 소개하므로 넘어가겠습니다.
다음은 Object Detection on Drone Imagery입니다. 위에서 말씀드렸듯이 드론 이미지에 대한 연구는 활발하지 않았으며 흡족할만한 성능 또한 보이지 못하고 있습니다. 이 또한 위에서 언급한 이미지 내 다량의, 분별력이 옅은 small-object로 인해 초래되고 있습니다. FPN, AugFPN과 같은 Image Pyramid 방법도 소개되고 있었지만, CLutDet, DMNet과 같은 sub-region 기반 coarse-to-fine pipeline의 이미지 분할 방법이 대세를 이루고 있습니다. 하지만 해당 방법의 문제점은 이미지를 자르는 도중 instance가 잘려지는 양상을 보인다는 점도 있습니다. 또한 해당 sub-region이 instance보다는 background를 많이 포함한다는 점으로 인해 성능 측면에서는 여전히 아쉬운 점이 있습니다. 하지만 최근까지도 해당 문제점들에 대해 다루는 논문은 많지 않습니다.
Small Object Detection에 대해서는, 많이 말씀드렸으나 새로운 한 방법을 살펴보겠습니다. 당연히 Drone Imagery Detection에서 처럼 FPN 기반 방법론들이 많지만 또한 Adversarial network (i.e. GAN)을 통해 small object와 large object 사이의 representation 간극을 줄이는 연구도 존재합니다. 이러한 연구를 Super-resolution을 통한 Object detectioin 연구라고 일컫는데, 해당 방식을 통해 small object의 문제점인 해당 물체를 인식하고자 할 때의 resolution 문제를 극복하고자한 연구입니다. 또 다른 연구로는 small object의 스케일, 사이즈들이 데이터 셋마다 큰 차이를 보이고 있기 때문에, 다른 데이터 셋으로 부터의 object 스케일을 맞추는 Scale Match 연구들이 있습니다.
Method
Unified Forground Packing
UFP 모듈의 목적은 원본 drone 이미지를 모자이크 형태의 통합된 이미지로 표현하여 instance가 포함된 foreground의 비율을 높임과 동시에 small object의 사이즈를 높이는데 있습니다. 모자이크 형태라는 말을 처음 들어봤을 수 있는데, 쉬운 예로 사람들을 잘라 검정색 도화지에 다닥다닥 붙여놓는 것과 같습니다. 해당 방식대로면 background가 많이 사라진다는 장점이 있습니다. 이를 위해서는 아래 Figure 3과 Algorithm 1을 이해해야합니다. 먼저 Figure 3을 통해 전체적인 파이프라인을 살펴보겠습니다.
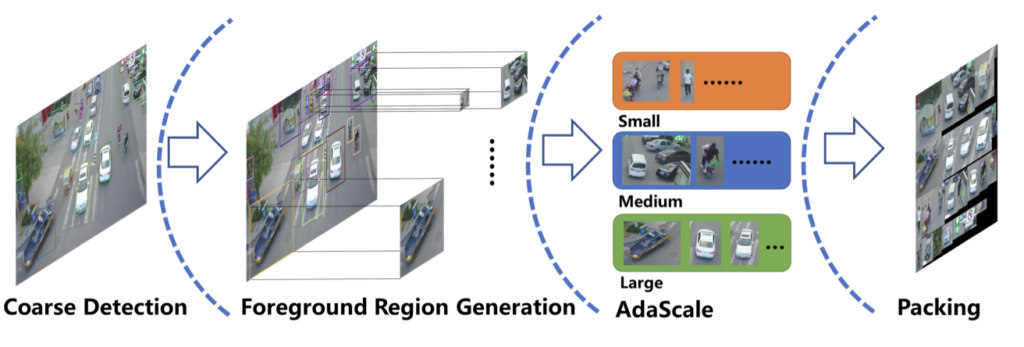
Figure 3을 통해 전체 파이프라인을 살펴보면, 세 스텝을 통과합니다.
(1) Coarse Detection을 통해 이미지 내 객체를 찾아냅니다. 이 때는 객체의 클래스 혹은 Bounding box의 좌표를 조정하는 것 보다 전체 객체를 찾아내는 것에 중점을 둡니다. 물론 Coarse하다고 하지만 해당 Coarse Detection의 성능이 현저히 떨어지면 이후 스텝이 원활하지 않을 수 있습니다. Coarse Detection 이후 객체 (Foreground)들은 scale (size)가 서로 다를텐데, bounding box의 사이즈에 따라 클러스터링됩니다. 해당 과정을 Foreground Region Generation (FRG)로 명합니다.
(2) 클러스터 중, Small cluster region이 적응적으로 확대됩니다. 이는 곧 small object 들이 그 자체만으로는 객체의 크기, 해상도, 정보량 등으로 인한 성능이 좋지 않으므로 사이즈를 확대해주는 역할을 합니다. 뒤에서 언급할 것 이지만, 96 x 96 사이즈로 클러스터 사이즈를 확대합니다.
(3) 세 클러스터를 Packing합니다. Packing이라함은 mosaic 방법을 통해 이미지를 새로 만드는 방법으로 생각하면 됩니다. 이제 해당 Packing된 이미지를 fine-detector에 입력으로 통과하면 Small object에 대한 성능을 높일 수 있습니다.
전체적인 파이프라인을 살펴보았으니, 이제 하나씩 살펴보겠습니다. 먼저 Foreground Region Generation입니다.
Foreground Region Generation
Foreground Region Generation (FRG)을 이해하기 위해서는 사용되는 알고리즘을 이해해야합니다. 우선적으로 해당 방법은 Foreground에 대한 클러스터링을 통한 Cluster region 생성을 목표로 합니다. 이는 coarse detection의 편향을 줄임과 동시에 foreground small object들이 occlusion이 심한 경향을 보이는 것을 완화하고자 함입니다. coarse detection의 편향을 줄인다는 의미는 coarse detection에서는 모든 small object들을 탐지하지 못할 확률이 높으므로 이러한 문제를 완화하고자함입니다. 이를 위해 우선적으로 bounding box의 center로부터 일정 비율로 width와 height를 확대합니다. bounding box를 확대함이 문제가 되지 않는 이유는 해당 bounding box가 최종 detector head에 포함되지 않기 때문입니다. 최종 detection head는 fine-detector에서 결정되기 때문입니다.

FRG의 pipeline을 이해하고자하면, 위의 Algorithm 1을 이해해야합니다. 의사코드만으로는 이해에 어려움이 있을테니, 스텝 바이 스텝으로 살펴보겠습니다. FRG의 Input은 coarse detection의 output인 \beta_c 입니다. output은 Merged region \beta_r 인데, 지금은 이해하기 어려우나 14 번째 줄의 return 구문을 마주했을 때는 알 수 있습니다.
우선 A 를 최소 크기 (minimal size) bounding box로 둡니다. 이는 전체 object 중 coarse detection으로 찾은 bounding box 중 최소 크기를 A 로 둔다는 점인데, 이제 A 를 제외한 나머지 Bounding box \beta_c 에 대해 Bounding box 하나씩 반복합니다. 반복문을 돌며 smallest enclosing convex bounding box인 C 를 찾는 것을 목표로 합니다. smallest enclosing convex bounding box를 처음 들어봤을텐데, 우선 convex bounding box라함은 흔히 아는 square bounding box (아래 그림의 AABB, OBB)가 아닌 convex 형태의 bounding box (아래 그림의 CONVEX HULL)를 의미합니다. 즉 C 는 두 bounding box를 이은 Convex 형태로 표현됩니다.
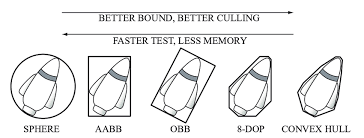
7 번째 줄부터 11번 째 줄의 과정은 만약 Convex bounding box C 보다 A 와 B 의 bounding box의 크기의 합이 크다면, 최소 크기로 지정한 A 를 C 로 정합니다. 처음 과정에서는 A 와 B 의 합이 C 와 같지만, \beta_c가 크기 순으로 정렬되어 있지 않기 때문에 반복문을 돌다보면 C보다 큰 경우가 생길 수 있습니다. 제 고찰에서는 시간 복잡도를 고려한 알고리즘이라고 생각됩니다 (크기 순으로 정렬하는 것과 단순 반복문을 돌며 대입하는 것은 시간 복잡도에서 차이가 납니다. 정렬은 특수한 경우를 제외하고서 O(N)의 시간 복잡도를 이길 수 없기 때문입니다).
알고리즘을 통과한 A 는 어떻게 되어있을까요? 최소 크기 Bounding box부터 시작해서, \beta_c 의 Bounding box들과 합쳐지면서, 하나의 Cluster를 구성할 것 입니다. 해당 Cluster는 특정 크기 이상의 Bounding box를 포함하지 않도록 제약을 가합니다. 제약을 가하는 이유는 small object는 medium object와 동일 Cluster로 묶이는 것을 방지하는 효과를 불러오기 때문입니다. 결과적으로 Small object는 Small object끼리, Medium object는 Medium object끼리 클러스터링됩니다.
허나, 클러스터링 시 object의 클래스를 고려하지 않을까?에 대해 의문이 들 수 있습니다. 하지만 클러스터링의 의의를 생각해보면, small object의 resolution을 확대하는 효과와 동시에 Scale Match 효과를 불러오기 위함이므로 현재 과정에서의 클래스는 중요치 않습니다. 물론 해당 부분을 문제점으로 삼을 수도 있습니다. 이는 저의 고찰인데, 결국 Small object의 Scale을 맞춘다 할지언정 Mosaic된 이미지에서 CNN을 적용하면, 여전히 클래스 간 (inter-class)의 분별력이 떨어질 수 있기 때문입니다. 해당 방법을 토대로 연구에 성능 개선의 방법으로 고민해보면 좋을 것 같습니다.
Foreground Region Scale Equalization
위의 FRG 이후 이미지의 Cluster들은 다른 사이즈를 갖고 있습니다. 사실 해당 점에 대해 이전에 말했지만, 주로 Small object에 대해 일어나며, sub-region (cluster)인 \beta_r 에 대해 cluster의 크기를 추정하여 지정한 사이즈보다 작을 경우, 해당 사이즈로 확대합니다. 본 논문에서는 지정한 사이즈를 96 x 96으로 두었습니다. 해당 방식에 대한 또 다른 하나의 고찰로는, 이 때 resolution의 문제로 인한 representation의 차이를 문제삼을 수 있습니다. 해당 문제는 Small object detection에서 언급한 Adversial Network를 통한 Super-resolution을 Small cluster에 대해 적용하는 것으로 극복할 수 있을 것으로 보이나, 저자는 이러한 조치는 취하지 않았습니다. 이 또한 이후의 연구 방향에 도움될 것으로 보입니다.
Foreground Region Packing
본 Part. 1 리뷰의 마지막 부분입니다. 해당 Packing 과정을 통과하면, UFP 모듈을 이해했다고 생각할 수 있습니다. Packing은 저자가 언급한 Drone 이미지에 대해 통용되던 coarse-to-fine pipeline에서 fine-detector가 해당 cluster 등에 대해 따로 적용되는 효율성 및 computation cost를 문제로 삼아 극복하고자 함으로, Mosaic 방법으로 검정색 이미지 내 사전에 구성한 Small-Medium-Large Cluster를 재배치하는 과정을 거칩니다. 본 논문에서는 다섯 줄에 걸쳐 소개하고 끝나지만, 우리는 조금 더 살펴볼 필요가 있습니다. 저자는 위에서 언급한 문제를 피하고자 PHSPPOG 방법을 통한 Mosaic 방식으로 이은 통합된 Region에 대해 fine-detection을 수행하는 방법에 대해 언급합니다. PHSPPOG 방법이란 “A priority heuristic for the guillotine rectangular packing problem, 2016″에 언급된 방법으로,쉽게 생각하면 고정 크기 사각형 내 일정 박스들을 배치(포장)하는 최적화 방법입니다. 아래 코드 및 결과를 통해 살펴보겠습니다. 코드를 보면 phspprg내 width와 boxes들을 넣어, 해당 width에 맞게끔 boxs들을 최적으로 배치하는 결과를 뱉습니다. 해당 방법을 통해 이미지 내 Cluster를 빠짐 없이 배치하고자함이 보입니다.
boxes = [
[5, 3], [5, 3], [2, 4], [30, 8], [10, 20],
[20, 10], [5, 5], [5, 5], [10, 10], [10, 5],
[6, 4], [1, 10], [8, 4], [6, 6], [20, 14]
]
width = 10
height, rectangles = phspprg(width, boxes)
visualize(width, height, rectangles)
print("The height is: {}".format(height))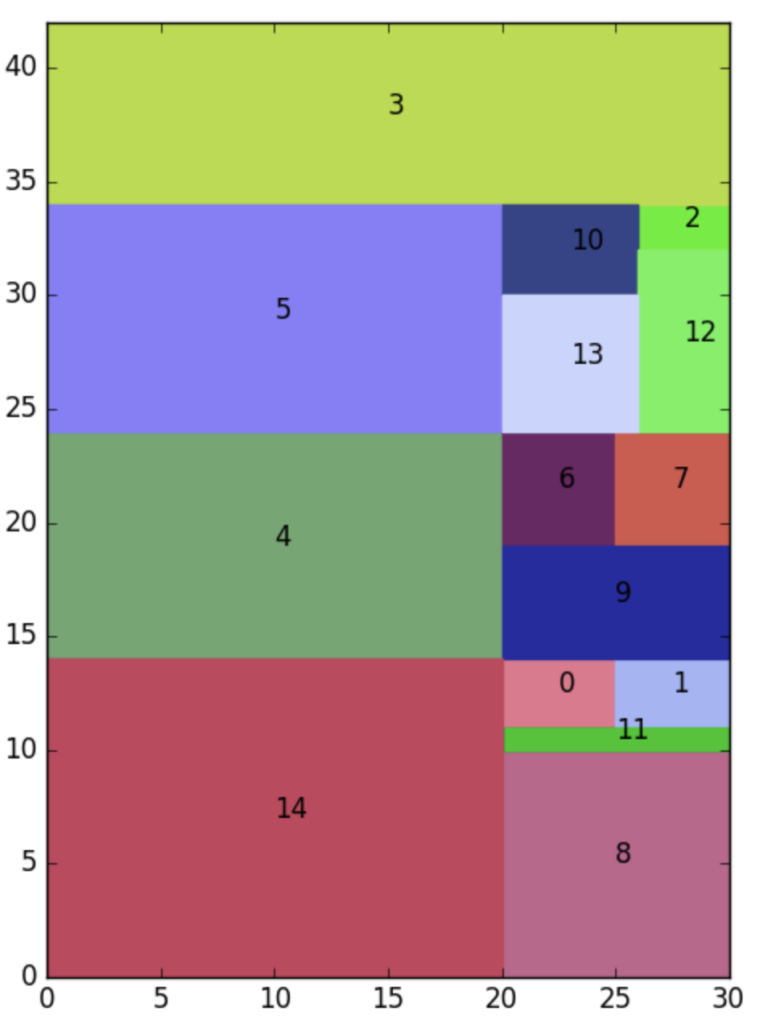
해당 방법에 대한 고찰로는, 해당 PHSPPOG 방법을 끌고 오는 것은 굉장히 좋았으나, 이렇게 배치함으로써 object들의 location information이 소실되는 우려에 대해서는 고려하지 않고 있습니다. 이에 대한 저자의 고찰은 담겨있지 않아 아쉬운 것 같습니다.
이상으로 Part. 1 리뷰를 마치겠습니다. 다음은 MP-Det으로, 처음 들어보는 개념도 많으며 수식도 많이 등장하니 해당 지점까지 완벽히 이해했다 믿으며, Part. 2를 금주 내 작성토록 하겠습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
읽으면서 궁금한 점으로는 Foreground Region Generation 방법이 foreground small object들이 occlusion이 심한 경향을 보이는 것을 완화한다는 것이 잘 와닿지 않았는데요, FRG pipeline에서 어떤 부분을 통해 occlusion이 완화되는 것인지 설명 부탁드려도 괜찮을까요 ?
또 FRG algorithm에서 coarse detection으로 찾은 bounding box 중 최소 크기를 제외한 나머지 bounding box를 반복문으로 돌며 smallest enclosing convex bounding box를 찾는다고 하셨는데, square bounding box가 아닌 convex 형태의 bounding box로 찾는 이유가 있는 것인지 궁금합니다. convex bounding box의 크기는 어떻게 계산할 수 있는 것인지 , , , ,
또한 알고리즘을 도는 과정에서 Convex bounding box보다 A+B의 bounding box의 크기의 합이 크면 A를 C로 업데이트 하게 되는데, 다 돌고 나온 A는 최소 크기 bounding box부터 시작해서, B_c의 bounding box와 합쳐지면서 하나의 Cluster를 구성한다는 것에 의문이 듭니다. 알고리즘의 return 부분을 보면 B_r이 반환되고 있는데 FRG 과정을 거쳐 나온 Cluster은 B_r이 아닌 건가요 ? ? ?
감사합니다 !!
네 안녕하세요. 리뷰 읽어주셔서 감사합니다.
1. Q: Foreground Region Generation 방법이 foreground small object들이 occlusion이 심한 경향을 보이는 것을 완화한다는 것이 잘 와닿지 않았는데요, FRG pipeline에서 어떤 부분을 통해 occlusion이 완화되는 것인지 설명 부탁드려도 괜찮을까요 ?
>> 제 고찰에서 이 부분은 object의 overlap, occlusion이 심하면 coarse-detector 뿐만 아니라 fine-detector에서도 일부가 검출되지 않을 수 있습니다. 그런데 coarse-detector의 결과로 이미지를 마치 패치 단위로 클러스터링 한다면, 검출되지 않았던 object들도 해당 클러스터 안에 들어갈 수 있게 되겠죠. 이후 이미지를 확대한 후 다시 fine-detector로 검출하면, Occlusiong 된 객체들이 더욱 크게 보일 것이며 보다 명확한 Representation을 가지게 될 것이니 검출하지 못했던 몇몇 Object들을 검출할 수 있을 것이라 생각합니다.
2. Q: FRG algorithm에서 coarse detection으로 찾은 bounding box 중 최소 크기를 제외한 나머지 bounding box를 반복문으로 돌며 smallest enclosing convex bounding box를 찾는다고 하셨는데, square bounding box가 아닌 convex 형태의 bounding box로 찾는 이유가 있는 것인지 궁금합니다. convex bounding box의 크기는 어떻게 계산할 수 있는 것인지 , , ,
>> convex 형태라한다고해서, Flexible한 원과 유사한 원형 형태는 아닌 것으로 보입니다. convex bounding box는 coarse-detector로 부터 검출된 Object들이 Square-shape Bounding box를 가지고 있을 때, 두 Bounding box의 합집합의 형태라고 생각하시면 좋을 것 같습니다. 네모 둘을 겹쳐 그리면 다각형의 형태를 띄는데, 이렇게하지 않고 두 Bounding box의 끝점을 포함하는 큰 Square-shape Bounding box를 생성한다면 우리가 찾고자하는 Object 이외에 Background를 많이 포함하게 될 것 입니다. 그렇다면 유의미한 Cluster (Patch)로 평가받기엔 어려울 것 입니다.
3. Q: 알고리즘을 도는 과정에서 Convex bounding box보다 A+B의 bounding box의 크기의 합이 크면 A를 C로 업데이트 하게 되는데, 다 돌고 나온 A는 최소 크기 bounding box부터 시작해서, B_c의 bounding box와 합쳐지면서 하나의 Cluster를 구성한다는 것에 의문이 듭니다. 알고리즘의 return 부분을 보면 B_r이 반환되고 있는데 FRG 과정을 거쳐 나온 Cluster은 B_r이 아닌 건가요 ? ? ?
>> Cluster는 B_r이 맞습니다. 처음 공집합이던 B_r이, 12 번째 줄을 살펴보면 A와 합집합으로 대입된다고 하니 곧 A == B_r이 되는 것이죠. 그렇기에 B_r을 return해주게 됩니다.