
안녕하세요.
2월 초순부터 계속 틈틈이 해 오던 Segmentation 실험을 연구실 일정 등 이것저것 겹쳐서 한달반정도 진행하지 못했네요. 이제 정말로 빡세게 다시 진행해 봐야 할 거 같습니다 ㅎ..
오늘 리뷰할 논문은 제가 실험중인 task와 매우 흡사해서 어쩔 수 없이 읽게 되었습니다. 열화상만을 가지고 Segmentation을 진행하는 task인데, 거기에 Thermal의 단점을 보완하기 위한 여러 기법들이 적용된 것이죠. 결과부터 말하자면 본 논문을 읽고 막 엄청나게 fancy 하다는 느낌을 받지는 못했습니다. 뭔가 이것저것 붙인거 같은 느낌이 조금 들었기 때문이죠.(개인적인 견해일 수 있습니다)
아무튼 본격적으로 리뷰 시작하도록 하겠습니다.
1. Introduction
Semantic Segmentation이 어떤 task인지는 연구실 분들 대부분이 알것이라 생각됩니다. pixel level로 classification을 수행하는 것이죠.
Semantic Segmentation은 자율주행 or medical 등의 분야에서 scene understanding을 위해 많이 연구되고 있는 분야입니다. 또한 이러한 결과들은 path planning, trajectory prediction등 다양한 downstream task에 많이 적용되곤 하죠.
해당 task 수행을 위해 RGB 만으로 학습과 예측을 수행하는 방법론들이 있는데, 이러한 모델들은 다들 아시다시피 RGB Sensor의 고유한 문제점으로 인해 급격한 조도변화 등의 상황에서 많은 문제점들이 존재합니다. 그래서 대부분의 연구들이 RGB-Thermal fusion을 수행하곤 합니다.
하지만 이러한 multi-modal fusion(RGB-T) 방식에선 정확한 calibration을 요구합니다. RGB-Thermal camera 사이에서 정확한 calibration이 되었다면 이론적으로 완벽하겠지만, 실제론 sensor의 흔들림이나 여러 외적인 요인으로 인해 취득한 dataset의 scene들 사이에서 조금씩 다른 extrinsic parameter 가 구해지죠. 그리고 이는 RGB-T fusion 모델 예측의 성능 하락으로 직결됩니다.
그리고 이 뿐만 아니라 inference 단계에서도 RGB-Thermal 두 stream을 모두 사용해야 하기 때문에 단일 모달 대비 상대적으로 많은 cost가 요구된다는 문제점도 존재합니다.
이를 해결하고자 Domain Adaptation, Knowledge Distillation 기법을 적절히 활용해서 학습 단계에선 RGB, Thermal 두 모달을 모두 사용하고, inference에서는 단일 모달을 사용하는 많은 연구들이 등장하게 됩니다. 보통은 RGB Sensor가 illumination 에 취약하다는 결정적인 단점이 존재하기 때문에 thermal image를 통해 예측을 수행합니다.
(제가 현재 진행중인 실험도 해당 결에 해당합니다)
하지만 thermal 센서도 여러 대표적인 문제점들이 존재하게 되는데요,,, object의 edge부분이 매우 blur 하고, texture가 매우 부족하다는 점입니다. 그래서 본 논문에서는 이러한 thermal의 고유한 단점들을 해결하기 위해 매우 직관적인 모듈들을 설계하게 됩니다. 이에 대해선 아래 method 부분에서 설명 드릴건데, 매우 직관적이라 이해하시기에 어려움이 전혀 없으실겁니다.
논문의 전체적인 pipeline에 대해 간략하게 설명드리자면, 크게 Teacher->Student의 Knowledge Distillation 기법을 사용하게 됩니다. Teacher는 RGB-Thermal의 fusion network를 사용하게 되고, student는 thermal만을 입력으로 받게 되죠. 그리고 thermal의 부족한 edge 정보를 보완해주기 위한 추가적인 두가지 기법이 함께 설계되어있습니다.
각설하고, 아래 method 에서 각각에 대해 설명드리겠습니다.
2. Method
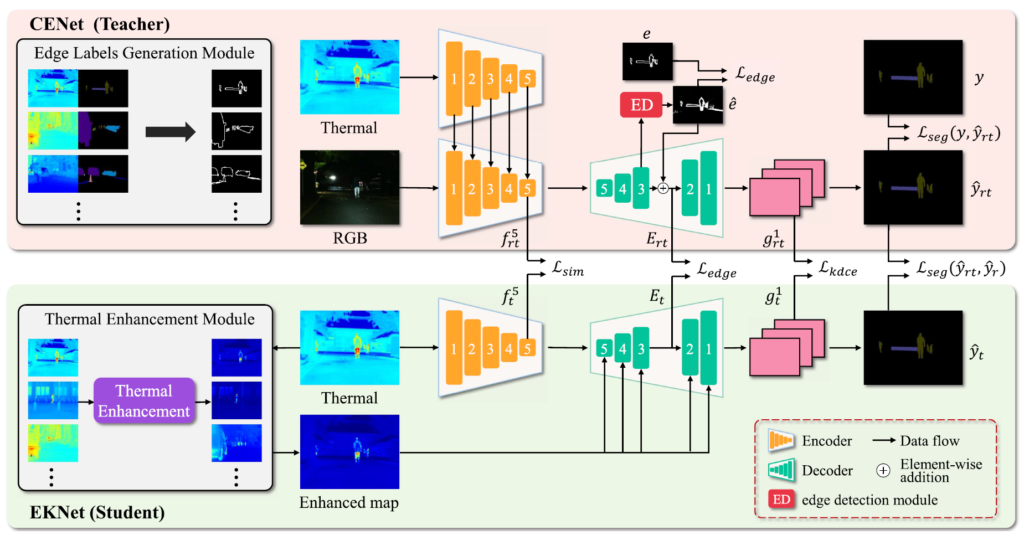
네, 위의 그림은 전체 학습 pipeline의 구조입니다. 매우 직관적으로 표현이 잘 되어 있습니다.
본 논문에서는 자신들이 제안한 구조를 Cross-modal Edge-priviledged Knowledge Distillation (CEKD) 라고 명명하네요.
우선 크게 RGB-T fusion을 입력으로 가지는 Teacher 모델(CENet)과 thermal 만을 입력으로 가지는 Student 모델(EKNet)로 구성됩니다. 또한 부가적으로 thermal의 부족한 edge 정보를 보완하기 위한 ED module 과, thermal 이미지에서 foreground와 background 의 contrast를 부각하기 위한 TE module 도 존재합니다.
2.1. CENet (Teacher Network)
간단한 구조입니다.
RGB, Thermal 각각이 동일한 구조의 개별적 encoder를 가지고, RGB-Thermal fusion feature를 decoding 하는 하나의 decoder로 구성됩니다.
RGB, Thermal의 encoder에서 각 단계(1~5)의 feature는 element-wise 덧셈 방식으로 fusion이 됩니다. 그리고 그림에는 표현되지 않았지만 Encoder와 Decoder 사이에 skip connection 도 적용됩니다. 해당 방식은 U-Net의 skip-connection 구조라고 생각하시면 됩니다.
그리고 Teacher Network의 Decoder 부분에 표기된 ED 가 보이실텐데, 이는 2.2에서 설명드리겠습니다.
2.2. ED(Edge Detection) module
ED(Edge Detection) 모듈의 경우 thermal 센서의 부족한 edge 정보를 보완해 주기 위해 설계된 모듈입니다.
예측 단계에선 thermal image만 사용하게 될테니 물체의 edge 영역에서 부정확한 예측이 수행되게 되는데, 이를 보완하고자 teacher의 RGB-Thermal fusion feature에서 edge에 대한 정보를 추출 해 student의 학습을 돕게 되는 방식입니다.
Decoder의 3번째 단계 feature가 ED의 입력으로 들어가서 해당 결과를 기존 입력과 element-wise addition 방식으로 더해지게 됩니다. 그림을 통해 직관적으로 이해가 가능하실거라 생각됩니다.
ED 모듈의 구조는 타 논문에서 제안된 구조를 그대로 차용하였는데 아마 매우 shallow한 구조일것이라 추측됩니다.
부가적으로, 왜 3번째 decoder를 통과한 feature를 ED 모듈의 입력으로 설정했는지에 대해선, 실험적인 결과에 기반한 결정이라고 답변 드릴 수 있을 거 같습니다. 이에 대한 Ablation 또한 존재합니다.
2.3. EKNet (Student Network)
학습, 평가때 모두 사용되는 Student Network인 EKNet입니다.
모델 구조는 teacher과 동일합니다.
그리고 그림을 보시면 Enhanced map이 decoder의 각 단계(1~5) 에 더해지는 것을 볼 수 있습니다. 이는 2.4에서 설명드릴, Thermal Enhancement module의 출력값을 decoder의 각 단계에 element wise로 더해주는 것입니다. TE 모듈의 출력은 입력 이미지와 동일 해상도인데, 이를 nearest interpolation 방식으로 downsampling 해서 각 단계에 더해줬다고 합니다.
2.4. TE(Thermal Enhancement) module
결국 thermal를 입력으로 받는 student network는 thermal image의 픽셀값을 보고 segmentation map을 예측하게 됩니다. 그리고 여기서 thermal image의 픽셀값이라 함은 결국 물체의 ‘온도’ 를 의미하겠죠.
결국 모델이 더 정확한 예측을 수행하기 위해선 이미지의 foreground와 background의 pixel value contrast 가 뚜렷해야 함을 의미하고, 이를 위해 해당 모듈을 설계했다고 보시면 됩니다. 해당 모듈을 통해 사람, 자동차 등 열을 내는(?) 물체와 배경의 값 차이를 더 극대화 하기를 원한것이죠. 발상은 매우 직관적입니다.
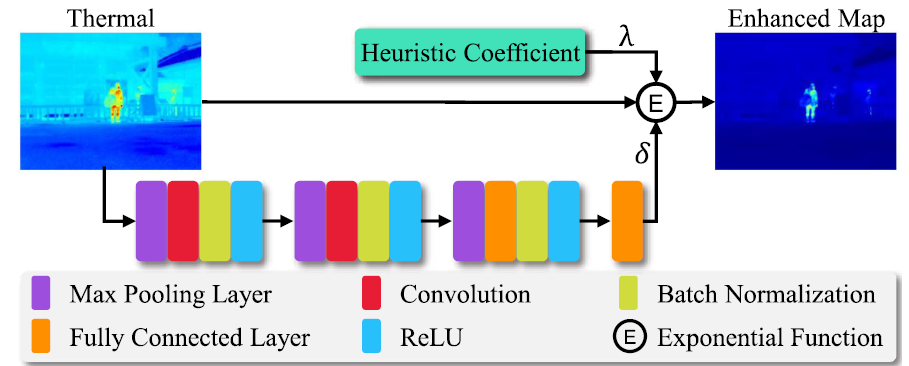
Thermal 이미지는 해당 모듈의 입력으로 들어가서 위와 같은 구조를 거치게 됩니다, 그리고 마지막 Fully Connected Layer를 통과해서 하나의 값 \delta 를 예측하게 됩니다.
그리고 해당 값들을 가지고 아래의 exponentional function을 통해 Enhanced Map을 구하게 됩니다.
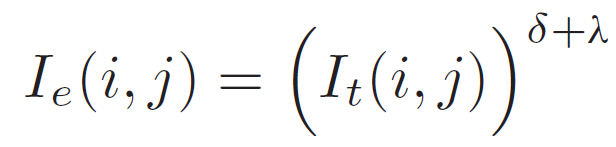
우선 위 모듈의 입력으로 들어가는 thermal image인 I_t는 [0,1] 사이의 범위로 정규화 된 형태입니다. 높은 온도를 가지는 픽셀은 1에 가까운 값을 가지고, 반대로 낮은 온도일 경우 0에 가까운 값을 가지게 되죠.
사실 위 지수함수에서는 지수부가 핵심입니다.
지수에 들어간 값 중 \delta는 모델을 통해 학습되는 adaptive parameter 입니다. 그리고 \lambda는 고정된 값입니다. 하지만 \lambda는 학습 단계에서 위 함수의 지수인 \delta+\lambda가 항상 1보다 큰 값을 가지도록 보장하게 됩니다.
항상 1보다 큰 값을 가지게 함으로써 상대적으로 높은 온도를 가지는 foreground object와, 온도가 낮은 background 영역의 값 차이를 더 부각시키게 됩니다. 가령 background는 0에 가까운 낮은 값을 가지게 될텐데, 이를 지수가 1보다 큰 지수함수를 통과시키면 0에 더 가까워지게 됩니다. 반대로 foreground 영역은 1에 가까운 값을 가지기 때문에 값이 지수함수에 의한 감소폭이 더 적을테고, 값의 대조가 더 커지게 됩니다.
아무튼 이렇게 본 논문에서는 foreground와 background의 값 차이의 대조를 부각하기 위해 위 모듈을 설계하였는데 사실 읽으면서 ‘이게 잘 동작이 될까?’ 라는 생각이 들긴 했습니다. 왜냐면 사람이나 자동차 처럼 열을 내는 object의 경우엔 정규화 이후 1에 가까운 값을 가지기 때문에 효과가 있을테지만, 이를 제외하고 자전거, 표지판 등 열을 내지 않는 물체에서는 오히려 더 부정확한 결과를 낼 것이라는 생각이 들었습니다.
위 TE 모듈의 그림 예시만 봐도 이를 느낄 수 있는데, 사람의 경우엔 기존 입력 이미지 대비 background와의 대비가 더 좋아졌지만, 가드레일 등 다른 영역에 대해선 배경과의 대비가 오히려 줄어들어서 배경과 거의 유사한 파랑색을 가지는 것을 볼 수 있습니다. 이는 실험부분에서 뭐 정량적인 평가로 증명했겠지,, 라는 생각으로 리뷰를 이어서 작성 해 보겠습니다.
2.5. Total Loss
물론 전체적인 학습이 end-to-end로 진행하긴 합니다만, 이해의 편의성을 위해 teacher와 student에 해당하는 loss를 각각 설명드리도록 하겠습니다.
보통 Knowledge Distillation 모델은 teacher와 student를 동시에 end-to-end로 학습하는 경우가 대부분인것으로 알고있는데,,, 본 논문에서는 teacher network의 best performance를 위해 teacher를 먼저 학습하고 그 다음 distillation을 진행했다고 하네요,,,
전체 pipeline 그림에 표기된 loss 기호와 함께 매칭해서 보시면 이해하기에 더 편하실겁니다.
2.5.1. Teacher Loss
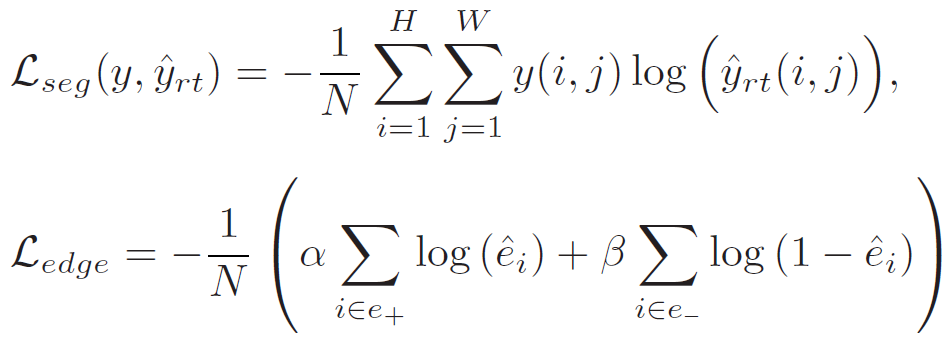
Teacher Network에 적용되는 Loss는 위 2가지입니다. 우선 예측값과 GT Segmentation map 사이의 cross-entropy loss인 L_{seg} 가 있습니다.
그리고 다음으론 Decoder의 ED module에서 예측한 edge 정보와 (pseudo) Edge label 사이의 loss 입니다. Edge label의 경우 미리 학습된 타 방법론을 통해 전처리 단계에서 모두 뽑아놓은 것이라고 생각하시면 됩니다.
위 L_{edge} 식에서 e_+는 edge label e에서 edge 영역에 해당하는 1의 값을 가지는 픽셀을 의미하고, 반대로 e_- 는 edge가 아닌 background 에 해당하는 0의 값을 가지는 픽셀을 의미합니다.
결국 L_{edge}의 앞쪽 term을 통해서 예측한 edge 정보중 edge label e에서 edge에 해당하는 픽셀은 1로 보내고, 반대로 뒤쪽 term을 통해서는 예측한 edge 정보중 edge label e에서 background에 해당하는 픽셀은 0으로 만들려고 함을 알 수 있습니다.
아래는 teacher에 적용되는 최종 loss 입니다.
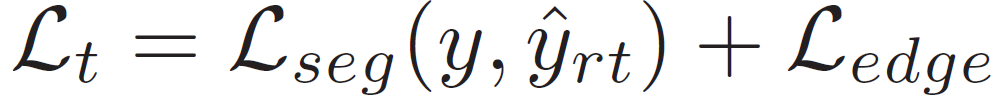
2.5.2. Student Loss
그리고 아래 식은 student에 적용되는 최종 loss 입니다.
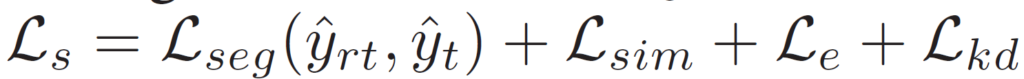
L_{seg}의 동작 방식은 teacher와 동일합니다. 다만 GT가 아닌, student network의 예측과 loss를 계산한다는 점에서만 차이가 있죠.
그리고 두번째는 L_{sim} 입니다. 본 논문에서 제안한 loss는 아닙니다.
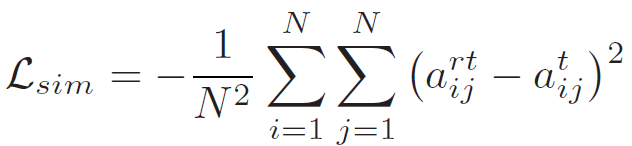
teacher network에서의 similarity matrix인 a^{rt} 와 student network 에서의 similarity matrix인 a^t 사이의 loss 입니다. 그리고 i,j는 pixel 인덱스를 의미하는데, a^{rt}_{ij} 라면 teacher 에서 계산한 similarity matrix에서 i번째 pixel과 j번째 픽셀의 similarity를 의미하는 것입니다.
similarity matrix 계산은 아래 식을 통해서 이루어집니다.
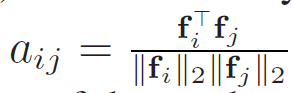
f는 encoder를 모두 거치고 나온 feature map 입니다.
결국 L_{sim} 을 통해 RGB-T fusion 모델인 teacher가 구한 feature map의 similarity 정보를 thermal 모델인 student에게 전이한다고 생각하시면 될 듯 합니다.
그리고 다음은 edge에 대한 loss입니다. 아래 식을 통해 edge map 사이의 loss를 계산하였습니다. 직관적이므로 더 자세한 설명은 생략하겠습니다.
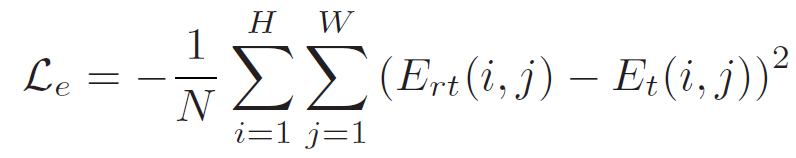
마지막으론 L_{kdce} 라는 loss 입니다.
Experiment
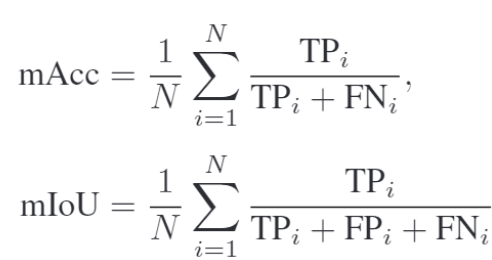
segmentation task의 2가지 대표적인 evaluation metric 입니다. 직관적으로도 이해하실 수 있으실겁니다.
위 식에서 N은 class(자동차,사람,,,,) 의 수를 나타내고, 계산은 픽셀 단위로 이루어집니다.
결국 mACC 는 클래스별 전체 정답 픽셀 중에서, 제대로 찾은 것의 비율을 의미하고,
mIOU는 클래스별 전체 정답 픽셀 + 잘못 찾은(FP) 픽셀 중에서 제대로 찾은 것의 비율을 의미합니다.
그리고 dataset으로는 outdoor scene인 MFDataset을 사용합니다.
보통 자신들이 제안하는 방법론의 일반성(?)을 주장하기 위해선 최소 2개의 dataset을 사용하는데 1개만을 사용했네요…

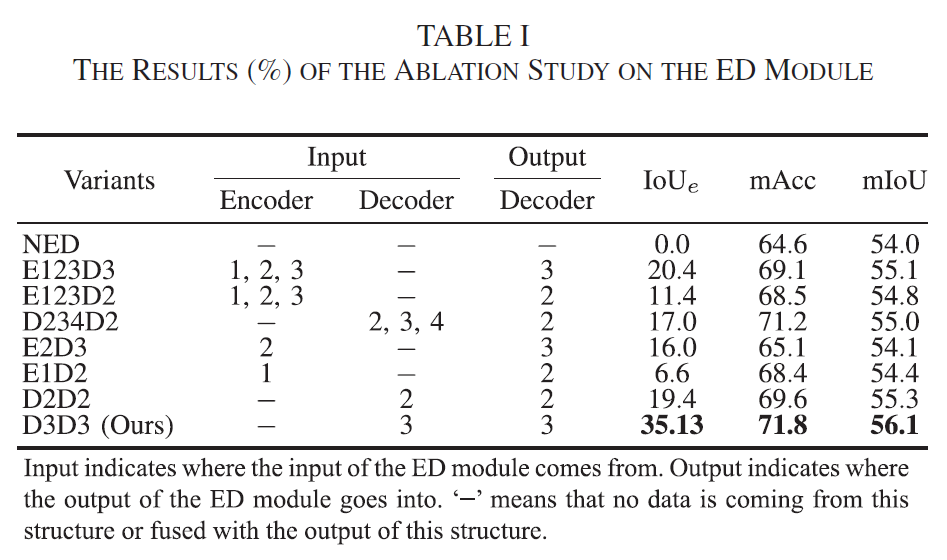
우선 ED module과 관련된 Ablation study 입니다.
Decoder의 3번째 단계에서 ED module을 적용하는 것이 가장 성능이 높음을 보여주고 있습니다.
참고로 위의 실험적 성능들은 teacher 모델인 CENet (RGB-T Fusion)을 통해 예측한 성능입니다.
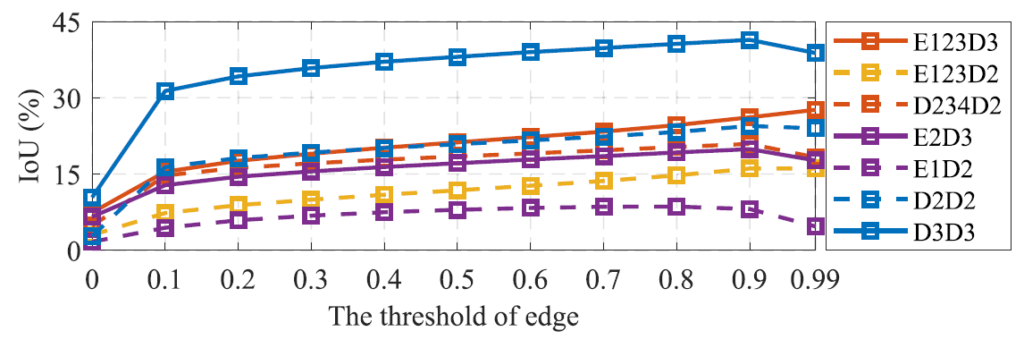
또한 ED module에서는 최종적으로 0과1사이의 값을 픽셀별로 가지게 되는데, edge인지 아닌지를 판별하는 threshold 값에 대한 ablation 실험입니다. 위의 성능 평가는 edge에 대한 IOU_e 로 비교하였다고 합니다.
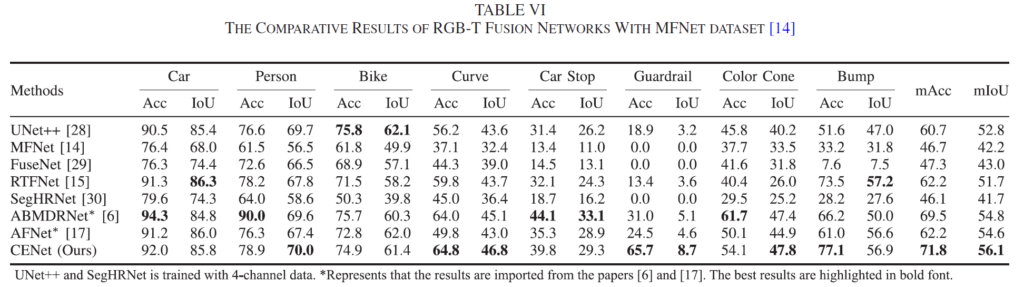
위는 RGB-Thermal fusion 모델인 teacher model CENet의 예측 성능을 리포팅 한 결과입니다.
물론 본 논문이 결국 thermal만을 가지고 예측을 수행하는 task이긴 하지만, RGB-T fusion에 대한 결과도 보여주고 있네요.
Person 클래스에 대해선 Acc가 ABMDRNet 대비 큰 하락폭이 있긴 하지만, 결국 최종적인 mACC, mIOU 성능은 제일 높네요.
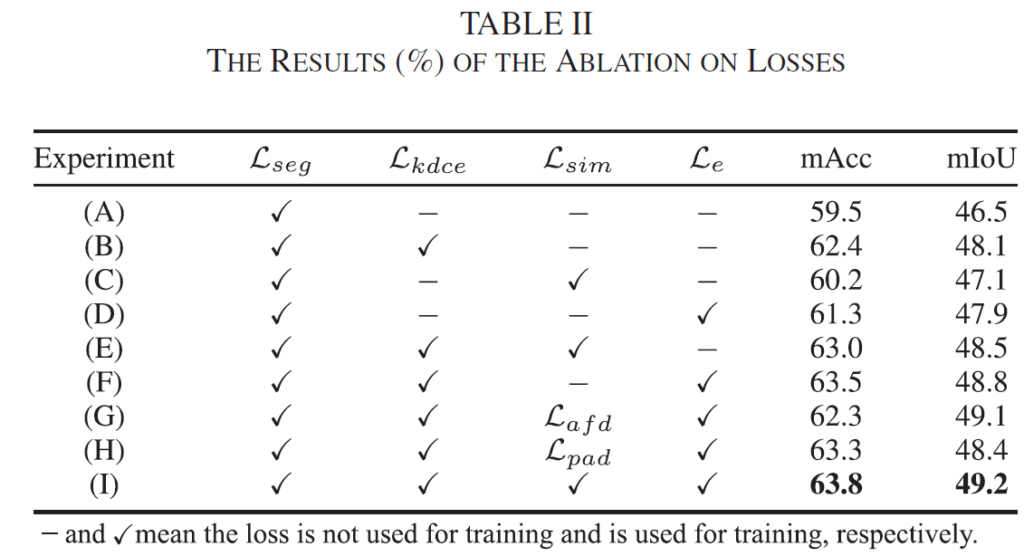
그리고 위 실험은 student를 학습시키는 각 loss에 대한 ablation 실험입니다. 리포팅 된 성능은 student에서의 예측에 대한 성능이구요.
각 loss에 대한 성능 향상폭을 알 수 있고, 특히 (E)와 (I)의 비교를 통해 thermal의 부족한 edge 정보를 어느정도 보완해주는 loss의 효과에 대해 살펴볼 수 있습니다.
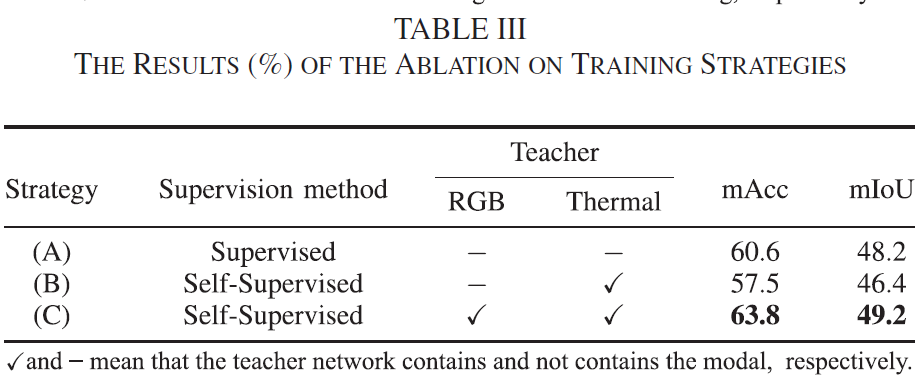
또한 위는 Teacher=>student의 Knowledge Distillation 구조에서 Teacher를 어떤 식으로 구성하느냐에 따른 student 모델의 예측 성능의 변화를 보여주고 있습니다. 예를들어 (C)의 경우는 이미 Teacher가 학습 된 상태에서 student가 학습될 때 teacher의 RGB, Thermal stream을 모두 사용해서 student를 학습 하는 경우입니다.
그런데 여기서 Self-Supervised 라는 키워드는 올바르지 못한 표현인 거 같네요. 물론 student에 대해 학습을 진행할 때에는 gt가 사용되진 않지만, 2-stage 학습방식에서 teacher를 미리 학습시킬 때 동일 데이터셋의 gt를 사용했기 때문이죠. 저 표기는 마음에 안드네요.
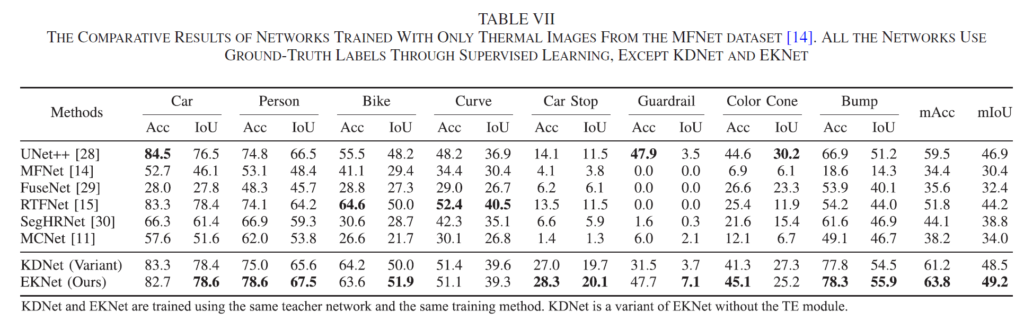
마지막으로, student network로 예측을 수행한 결과를 리포팅 한 것입니다.
본 논문의 student 모델인 EKNet의 경우 thermal만을 사용하기 때문에 pair 한 비교를 위해 기존의 RGB-T fusion 방법론들의 RGB stream을 지우고 thermal 만으로 예측을 수행했다고 합니다.
위 table의 MFNet, FuseNet 등의 방법론들은 원래 RGB-T fusion을 수행하는 방법론들인데 저자가 그냥 임의로 RGB stream을 빼버리고 thermal로만 re-implementation을 한겁니다. 음.,.. 물론 thermal로만 예측을 수행해야 한다는 점을 일치시킨건 맞지만, 기존의 RGB-T fusion 방법론 일부를 마음대로 이렇게 빼는게 정말 fair한건진 모르겠네요…
부가적으로 위 table에서 KDNet은 본 논문의 방법론에서 TE module을 제외한 성능입니다.
한마디로, KDNet=>EKNet 으로의 성능 향상 폭이 TE module로 얻은 성능 향상 효과라는 뜻입니다.
제가 위쪽 method 부분에서 TE module이 자전거, 가드레일 등 열이 없는 object에 대해서 효과가 있을까,,.? 라는 의문점을 가졌었는데 생각외로 향상 폭이 꽤나 존재했습니다.
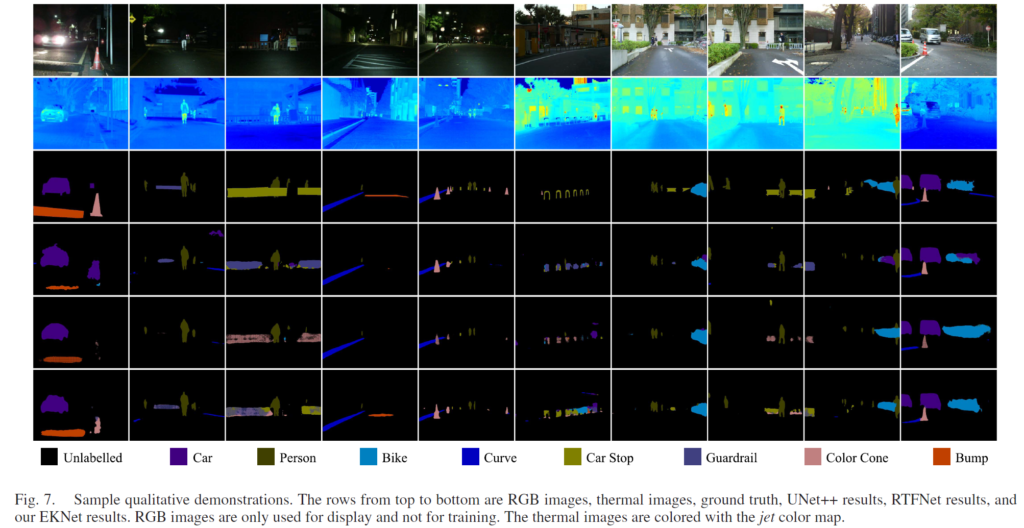
최종 예측에 대한 정성적인 결과입니다.
위에서 부터 RGB 이미지, Thermal 이미지, GT, UNet++결과, RTFNet 결과, 그리고 마지막은 본 논문의 student 인 EKNet으로 예측한 결과입니다.
아무래도 본 논문의 핵심 contribution 이 thermal 의 부족한 edge 정보를 해결하고자 한 것이기 때문에 저는 edge를 위주로 보게 되었습니다. 그런 관점에서 사람, 자동차 등 여러 클래스에서 꽤나 타 방법론 대비 성공적인 예측을 수행하였습니다.
사실, 본 논문의 컨셉 자체가 제가 현재 실험하고 있는 task와 매우 align이 맞아 있기 때문에 꼭 읽어봐야겠다는 생각을 했습니다. 그래서 꽤나 시간 투자를 해서 읽었습니다만, 생각보다 아쉬운 점이 많았던 논문이였습니다.
실험적인 부분에서 뭔가 표기를 헷갈리게 적은 점도 그렇고, 학습이 end-to-end로 한번에 이루어지지 않은 점도 그렇고, 논문을 읽으면서 실험 파트에서 실험 세팅을 이해하는데에 꽤나 어려움이 있을 정도로 글이 잘 읽히지 않았습니다.
그래도, 문제 정의가 직관적이고 실험 part에서 꽤나 많고 다채로운 실험들을 보여줬다는 점에서는 나쁘지 않았습니다.
그럼, 읽어주셔서 감사합니다.
안녕하세요. 작성해주신 리뷰 관련하여 여러가지 얘기할 것들이 있는데 일단 가장 먼저 리뷰 내용 중
“보통 Knowledge Distillation 모델은 teacher와 student를 동시에 end-to-end로 학습하는 경우가 대부분인것으로 알고있는데,,, 본 논문에서는 teacher network의 best performance를 위해 teacher를 먼저 학습하고 그 다음 distillation을 진행했다고 하네요,,,” 라는 부분에 대해서 말씀드리면 원래 Knowledge Distillation의 맨 처음 컨셉은 pretrained teacher를 활용해 student를 학습시키는 2-stage 방식이었습니다.
하지만 이러한 학습 방식은 학습 과정이 번거롭다는 점에서 최근에는 teacher와 student를 mutual learning처럼 동시에 학습할 수 없는지에 대해 연구하고자 하는 것이구요. 그러니 저자가 teacher model을 먼저 학습하고 그 다음 distillation을 하는 것에 있어서 크게 문제가 되거나 잘못된 방향이라고 생각이 되지는 않습니다.(어찌보면 MS-UDA 논문에서도 Pretrained HRNet으로 Pseudo GT 만들잖아요? 그것도 어찌보면 HRNet이라는 teacher model의 knowledge를 distillation 하는 것이니깐요.)
아무튼 두번째는 그래서 해당 논문의 경우 Teacher model을 학습시킬 때 실제 사람이 annotation한 GT label을 활용하는 것으로 보이는데 그렇다면 이 논문은 student를 학습시킬 때는 왜 Teacher model을 학습시킨 GT Label을 사용하지 않고 Teacher model의 pseudo label만을 활용하나요? Supervised이면 Supervised 방법론처럼 작동해야할 것 같고, Self or Unsupervised 방법이면 그 방법으로 가야할 것 같은데 본 논문은 애매한 스탠스를 취하고 있는 것 같아서 참 애매하네요.
그리고 리뷰에서 Edge Module에 대한 구조를 따로 설명하고 있나요? Thermal Enhancement module에 대한 구조는 나와있는 것 같은데 Edge Module에 대한 구조는 없는 것 같아서 구체적인 설명이 있으면 좋을 것 같네요.
loss에 대해서도 한가지 궁금한 점이 teacher model에서 edge 관련 loss를 계산할 때와 student model에서 edge 관련 loss가 서로 다른 것 같은데, 왜 다르게 구성된 것인가요? teacher model과 동일한 방식의 loss로 계산하면 안되나요? 그리고 왜 이 논문에서는 loss 앞에 다 – 부호를 붙이나요? teacher도 마찬가지고 student 도 마찬가지고 모든 loss의 1/N 부분 앞에 – 부호가 붙는데 이러면 total loss 계산 시 – 값으로 표현되는 것 아닌가요?
마지막으로 모델 학습 과정에서 loss 설명이 조금 부족한 것 같아요. Student model에 대한 total loss가 맨 마지막은 L_{kd}인데 밑에 설명에는 L_{kdce}인 것도 그렇고(아마 오타일 것 같네요.) L_{kdce}에 대한 설명이 전혀 없어서 무엇을 하는 loss term인지 모르겠네요.
아하, KD가 원래 2-stage 방식이였군요.
해당 부분에 대해선 몰랐는데 알려주셔서 감사합니다.
Edge Module은 타 논문에서 사용한 구조를 그대로 차용하였고, 별다른 추가적인 설명은 없었습니다. 논문 제목은 ‘Pixel difference networks for efficient edge detection’ 입니다.
그리고 loss 에서 teacher 모델과 student 모델에 적용되는 loss가 서로 다르다 함은, student loss 를 계산할 때에 teacher loss를 계산하는 거 처럼 gt랑 바로 비교해 버리면 안되냐~ 라는 뉘앙스의 질문으로 이해 했습니다. 본 논문이 MS-UDA와 유사한 느낌으로 GT->Teacher->Student의 스탠스를 취하기 때문에 pipeline을 이와 같이 구성한 거 같습니다.
번외로, 리뷰 내 Table3의 (A)와 (C)를 비교해 보면 오히려 gt로 student를 학습시키는 것 보다 본 논문의 방식으로 학습을 시키는 것이 더 성능이 높네요.
그리고, -가 붙는건… 저도 잘 모르겠네요. 이에 대한 언급은 따로 없었습니다. 본 논문에서 오타가 워낙 여러개 있었는지라… 오타가 아닐까요?
그리고 마지막 질문에 대해, 이거도 오타입니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
제가 Knowledge Distillation 모델의 학습 방법을 아직 잘 몰라서 드는 궁금증인 것 같긴 한데, 해당 방법론에서 student model을 학습할 때는 GT를 아예 사용하지 않는것일까요? teacher에서 구한 feature map의 similarity 정보와 student 사이의 학습만을 진행하는 방식으로, GT를 직접적으로 사용하는 부분은 없는 것인지 궁금합니다. 그리고 student model에서 GT를 사용하지 않는다면, knowledge distillation에서의 일반적으로 취하는 방식인건지 아니면 해당 모델에서 특이하게 학습하는 것인지도 궁금합니다.
넵, Knowledge Distillation의 student에서 GT를 직접적으로 사용하냐 마냐에 대한 질문은, 제가 읽은 논문들에 한해서는 보통 사용하지 않긴 했습니다. 보편적으로 본 논문처럼 gt->teacher->student 와 같은 flow를 가집니다. 그래서 student는 teacher의 예측을 보죠.
그런데 제가 생각했을때에도 student가 gt를 함께 보게되면 성능이 더 높게 나올거 같긴 합니다. 그리고 이런 스탠스를 취하는 논문들도 분명히 존재할테구요.!!
안녕하세요 좋은 리뷰 감사합니다.
리뷰에서 언급해주신대로 thermal enhancement 후 열을 내지 않는 물체들의 대비가 더욱 약해지지 않을까 생각했는데, 정량적 결과를 보니 그래도 학습 layer들이 뒷단에서 edge 정보를 보며 중요한 물체를 어느정도 강조하려고 노력하는 것으로 보입니다. 그렇다면 thermal enhancement를 위해 논문에서 사용된 module을 태우는 방식 말고 다른 방식을 사용한 ablation 실험은 없나요?
그리고 decoder로부터 나온 g가 그림에서는 화살표를 거쳐 최종 segmentation 결과가 되는데, 실제로는 어떤 과정을 거치는 것인지도 궁금합니다.
본 논문에서 TE(Thermal Enhancement) module 이라는 것을 새롭게 제안한지라 다른 방식에 대한 비교는 딱히 존재하지 않네요. Thermal의 표현력을 늘려주는 타 방법론과 비교했어도 좋았을 거 같다는 생각이 들긴 합니다.
그리고 모델 그림의 g는 encoder->decoder를 타고 나온 결과 맵입니다, shape으로 설명하면 B,C,H,W죠. 여기서 C는 class(차, 자전거,.,)의 수 입니다.
그리고 여기서 g에다가 class 축으로 argmax를 취해서 각 픽셀별로 class를 classification 하게 된 것입니다. shape은 B,H,W 입니다.