Before Review
이번 논문도 Self-Supervised Video Representation Learning 연구로 준비했습니다. LG, NAVER, KAIST가 공동 연구 진행한 논문 입니다.
제목에서 유추할 수 있지만 Video Representation Learning을 위한 Augmentation 기법을 제안한 논문 입니다. 신호 및 시스템에서 배웠던 푸리에 변환이 제가 관심 있는 연구 분야에서 활용되는 것을 보니 신기하네요.
리뷰 시작하겠습니다.
Introduction
저희가 일상 생활에서 가장 많이 소비하고 생성되는 미디어 콘텐츠는 바로 영상 데이터 입니다. 유튜브 쇼츠, 인스타그램 릴스, 틱톡 등등 저희가 스마트 폰으로 많이 보는 것들이죠. 데이터들은 많이 생성되고 있는데 이러한 데이터들을 기존 지도학습 방법론들을 위해 하나하나 annotation을 하는 것은 굉장히 비용이 많이 드는 일 입니다.
그래서 별다른 annotation 없이도 학습을 가능하게 하여 데이터의 일반적인 표현/패턴/특성을 학습할 수 있는 Self-Supervised Learning이 많이 주목을 받고 있습니다.
그 중 Contrastive Learning은 augmentation을 통해 positive view를 만들어내기 때문에 학습 과정에서 data augmentation이 중요하게 작용됩니다. 어떤 data augmentation을 하느냐에 따라 down-stream task에서의 performance 차이가 많이 발생하기 때문입니다.
기존 Video domain에서 Contrastive Learning을 위한 augmentation들을 거의 image domain에서 활용되는 것을 그대로 비디오의 spatial 축에 적용하는 것이 대부분 이었습니다. 즉, 동일한 augmentation이 근접한 frame에 대해서는 모두 다 동일하게 적용된다는 의미입니다.
그러한 와중에 몇몇 연구들만이 augmentation을 temporal 축에서도 진행하여 비디오 데이터의 특성을 더 잘 이해하려는 시도가 있었습니다. 하지만 방금 설명한 연구들 역시 근본적으로는 sampling 방식에 기반한 방법들이라 spatial bias 문제를 해결하기 어려움이 존재한다고 합니다. 여기서 spatial bias는 비디오 데이터를 이해하는 과정에서 motion informtation을 이해하는 것이 아니라 static한 배경 정보인 spatial information에 편향되어 예측을 수행하는 문제를 말합니다.
물론 이러한 문제들을 해결 하기 위한 연구들도 저의 이전 리뷰에 있으니 관심 있다면 참고 하시길 바랍니다.
- [CVPR 2021] Removing the Background by Adding the Background: Towards Background Robust Self-supervised Video Representation Learning
- [CVPR 2022] Motion-aware Contrastive Video Representation Learning via Foreground-Background Merging
저자는 위의 방법론들도 real world의 비디오들의 비정상 신호들을 모두 일반화 할 수 있는 방법들은 아니라고 지적합니다.
저자는 spatial bias 문제를 해결하기 위한 돌파구로 Discrete Fourier Transform(이하 DFT)을 제안합니다. DFT는 쉽게 말해서 데이터 신호를 주파수 도메인으로 변환하는 방법입니다. 영상 데이터를 분석할 때 보통 이렇게 DFT를 사용하는 데 영상 데이터는 저주파 성분과 고주파 성분으로 구성이 되기 때문 입니다. 쉽게 설명하면 근접한 픽셀 내에서 intensity가 급격하게 변하는 부분은 고주파, 그렇지 않으면 저주파로 보통 나눕니다.

애플 로고를 이용해서 간단하게 설명을 해보자면 Low-Frequency인 부분은 주변과 비슷한 픽셀 명도를 가지는 부분으로 주변과의 차이가 크지 않은 지점들이 해당됩니다.. 반대로 High-Frequency인 부분은 주변과 달라지는 픽셀 명도를 가지는 부분으로 흰색과 검은색이 교차되는 지점(edge)등이 해당됩니다.
저자는 이렇게 DFT를 통해서 영상의 저주파 성분, 고주파 성분을 파악하고 이를 learning signal로 활용하여 motion-sensitive한 representation learning을 할 수 있는 augmentation method를 제안합니다.
자 그럼 영상의 주파수 성분에 대한 이해가 있다면 다음 질문에 답할 수 있을 것 입니다.
“Motion Senstive한 representation을 학습 하기 위해서는 고주파 성분, 저주파 성분 중 무엇이 더 중요할까?”
답은 상대적으로 고주파 성분에 더 집중을 해야 동적 변화가 많이 발생하는 motion information을 잘 이해할 수 있을 것 입니다.

위의 그림은 비디오 데이터에 대해서 Spatial 축에 대한 저주파 성분, Temporal 축에 대한 저주파 성분을 제거했을 때 예시 입니다.
Spatial 축에 대해서 저주파 성분을 제거하면 확실히 edge 정보들만 살아나고, Temporal 축에 대해서 저주파 성분을 제거하면 motion이 일어나고 있는 부분들만 살아나고 있습니다. 이렇게 저주파 성분을 죽이고 고주파 성분을 데이터로 넣어주면 자연스럽게 학습은 고주파 성분에 집중하게 되니 더욱 motion sensitive한 representation learning을 기대하는 것이죠.
저자는 이러한 주파수 도메인에서의 필터링 작업을 FreqAug라 정의하고 있고 이는 처음으로 3D spatio-temporal 데이터에 시도되는 augmentation 기법이라고 합니다.
논문의 전반적인 아이디어 대해서는 알아봤으니 제안하는 방법론에 대해서 알아보도록 하겠습니다. 영상 데이터의 주파수 성분에 대한 이해만 있다면 방법론 자체는 어렵지 않습니다.
Method
푸리에 변환 자체는 데이터를 주파수 도메인으로 변환하는 작업이지만 이를 활용하면 특정 주파수 대역의 정보들을 필터링할 수 있습니다. Low Pass Filter(LPF)는 저주파 성분을 살리고 고주파 성분을 걸러주는 필터 입니다. 반대로 High Pass Filter(HPF) 고주파 성분을 살리고 저주파 성분을 걸러주는 필터 입니다.
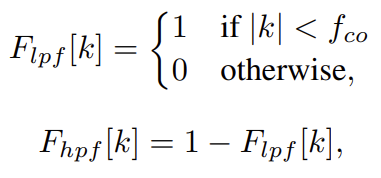
위의 수식을 보면 F_{lpf}는 특정 주파수 f_{co} 보다 낮은 주파수 대역의 정보를 통과 시키는 필터 입니다. 그리고 F_{hpf}는 보수 처리를 통해서 반대의 연산을 처리하고 있습니다.
저자는 비디오 데이터에 대해서 Spatial 축에 대해서는 2D-DFT, Temporal 축에 대해서는 1D-DFT 활용하여 3D-DFT를 stochastic하게 특정 주파수 대역을 제거하는 augmentation을 제안합니다.
위의 연산에서 중요한 것은 f_{co}를 잘 설정하는 것이 중요하겠네요. 중요한 hyperparmeter 입니다.
저자가 제안하는 FreqAug에는 또 다른 중요한 hyperparameter가 하나 더 있습니다. 바로 확률 r 입니다.
Uniform distribution U(0,1)에서 샘플링 한 값을 바탕으로 확률적으로 Augmentation을 진행합니다.
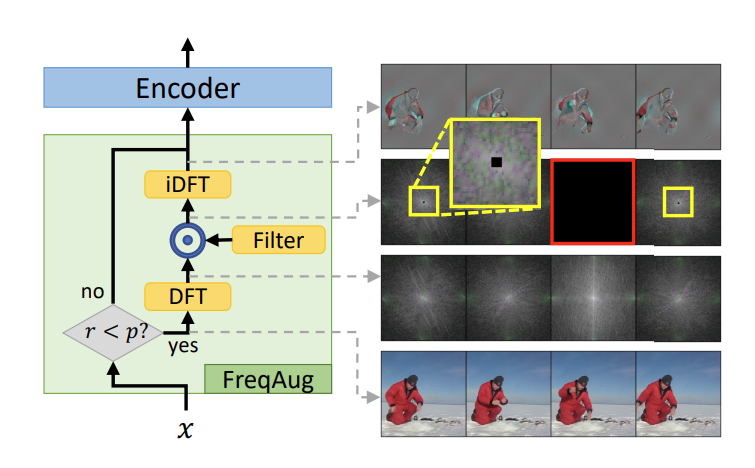
저자는 FreqAug block이 다른 augmentation이나 normalization이 완료된 다음에 배치를 시켰다고 합니다.
입력 데이터 x가 들어 왔을 때 랜덤하게 FreqAug를 진행합니다. 만약 FreqAug를 진행하지 않는다면 데이터가 그대로 Encoder에 전달됩니다.
FreqAug를 진행한다면 DFT를 통해서 주파수 성분을 얻고 f_{co} 보다 낮은 주파수 대역의 정보를 필터링 하고 다시 Inverse DFT를 통해서 원래 영상 정보로 변화를 시킵니다.
네 이렇게 Frequency 영역에서 특정 정보를 필터링 하여 motion-sensitive한 representation learning을 위해 제안하는 FreqAug에 대해서 살펴봤습니다. 사실 굉장히 간단해서 방법론에서 더 얘기할 내용은 없네요.

Pytorch 스타일의 의사코드 입니다. 굉장히 간단하네요.
본 논문은 실험 부분에서 인상 깊은 부분이 많았습니다. 방법론은 다 살펴봤으니 실험 부분으로 넘어가도록 하죠.
Experiment
Action Recognition Evaluation Results
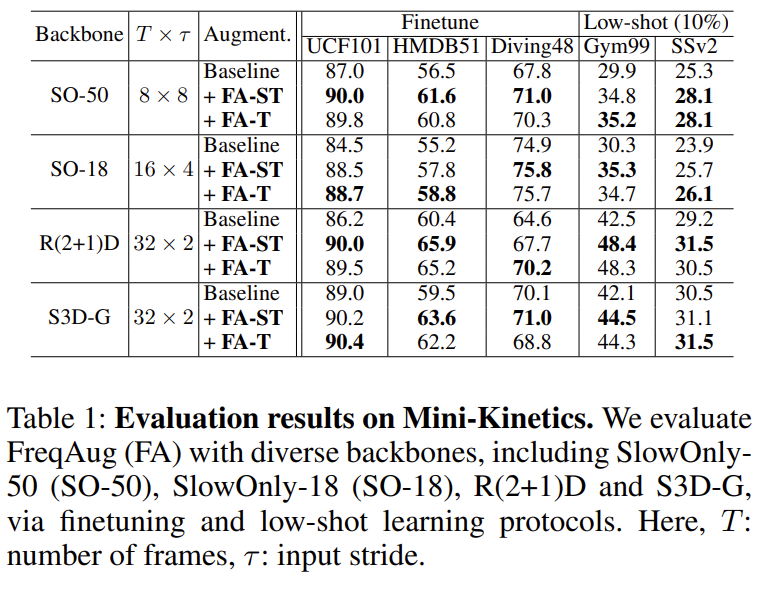
Action Classification에서 성능 실험 입니다. 4가지의 Backbone, 5가지 데이터 셋을 활용했는데 모두 관계 없이 저자가 제안하는 FreqAug를 이용하면 좋은 성능 향상을 보여주고 있습니다.
FA-ST는 Spatial, Temporal 차원에 대해서 둘 다 Augmentation을 진행한 것이고, FA-T는 Temporal 차원에만 Augmentation을 진행한 것 입니다.
Backbone 마다 FA-ST가 더 좋을 때도 있고, FA-T가 더 좋을 때도 있는데 전반적으로는 FA-ST가 더 우수한 성능을 보여주는 것 같네요.
Ablation Study
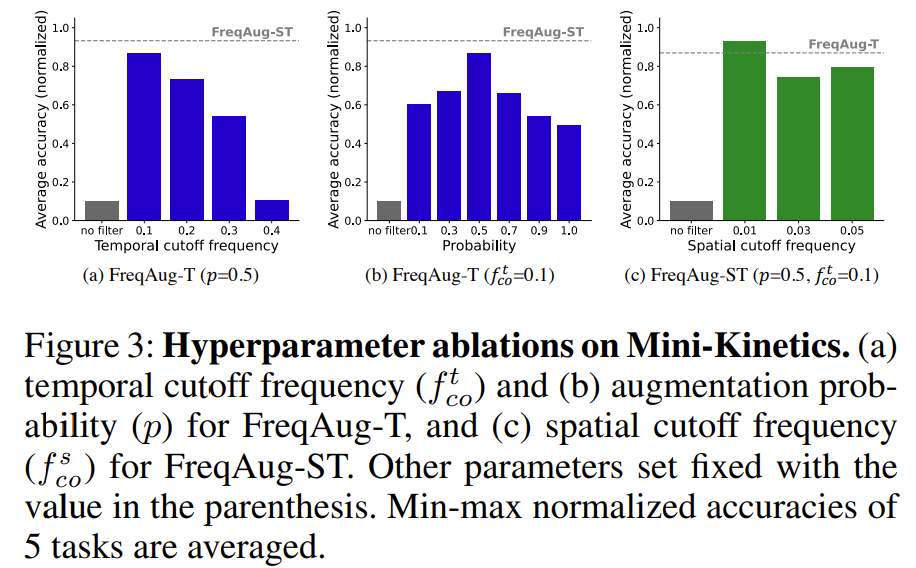
우선 Hyperparameter에 대한 ablation 입니다. 제안 되는 Augmentation 같은 경우는 필터링 과정에서 사용되는 주파수 임계치인 f_{co}와 FreqAug를 랜덤하게 진행하기 위한 확률 값인 p가 있었습니다.
결론적으로는 GridSearch 방식으로 최적의 파라미터를 찾았다고 하네요.
다음으로는 Filtering Method에 대한 ablation 입니다.
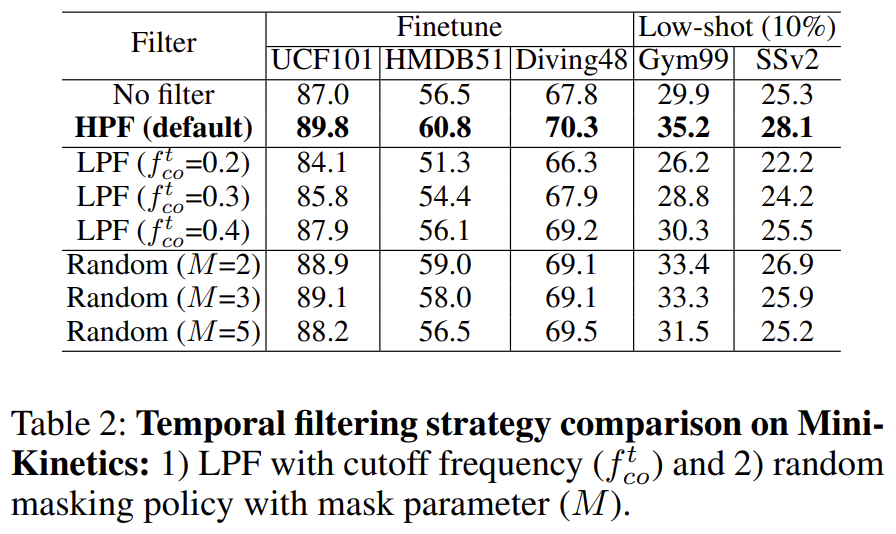
저주파 성분을 살리는 Low Pass Filter를 가지고 Augmentation을 진행하면 오히려 더 성능이 떨어지는 것을 볼 수 있습니다. Motion을 이해하는 데 중요한 성분인 고주파 성분이 다 죽어버렸으니 action understanding을 target으로 하는 downstream task에서는 성능이 더 떨어지고 있네요.
Random Masking을 진행하면 Baseline 보다는 성능이 높지만 High Pass Filter 기반으로 설계된 FreqAug 보다는 성능이 더 낮게 나오고 있습니다.
Comparison with Previous Models
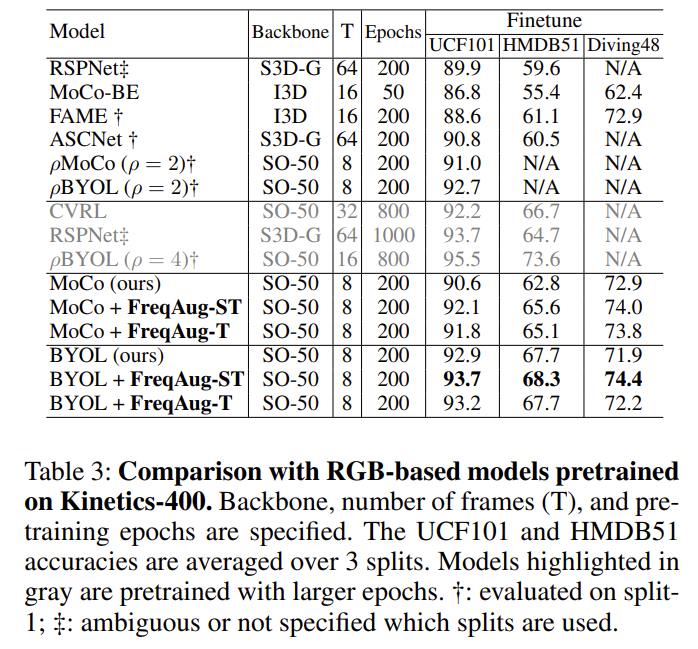
다른 SSL 방식들과의 Benchmarking 입니다. 저자는 fair comparison을 위해 1) augmentation-based, 2) RGB-only, 3) 224×224 spatial resolution이 동일한 방법론들과 비교를 하였다고 하네요.
일단 저자가 설정한 베이스라인 자체가 다른 방법론들에 비해 높아서 최고 성능을 찍었다는 의미가 크게 없는 것 같고 높은 베이스라인이지만 그 와중에도 성능 향상폭이 꽤 높다는 것이 인상적이네요.
아마 제대로 fair comparison을 하려면 Model FLops랑 Batch size 등등 더 다양한 요소들을 동일하게 고정하고 비교해야 하는데 그렇게 까지는 진행하지 않은 모양입니다.
Other Downstream Evaluation Results
Action Segmentation
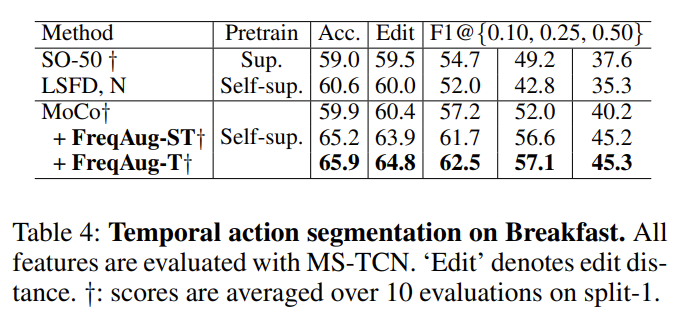
Action Recognition이 아니라 Temporal Action Segmentation이라는 또 다른 down stream task를 진행할 때 모든 지표에서 가장 좋은 성능을 보여주고 있습니다. 저자는 SO-50이라는 지도학습 보다 우리의 성능이 더 높기 때문에 우수함을 주장하지만 애초에 SSL 베이스라인 자체가 지도학습을 이미 이기고 있네요…?
뭐 그럼에도 FreqAug를 적용했을 때 발생하는 성능 향상이 높아서 충분히 설득력은 있는 것 같습니다.
Action Localization
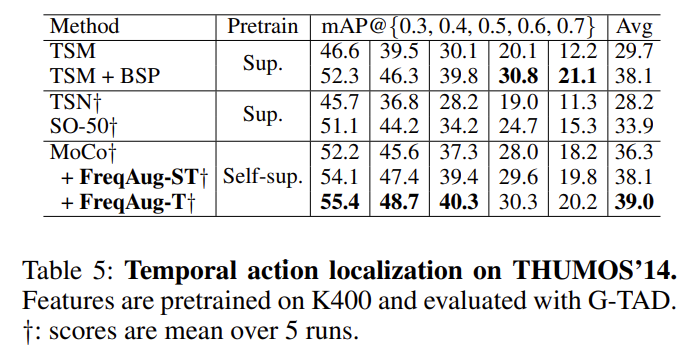
Action Localization에서 실험 성능입니다. BSP라고 해서 제가 이전에 리뷰했던 연구가 있는데 Localization을 target으로 하는 지도학습 기반의 사전학습 연구 입니다. 그럼에도 저자가 제안하는 SSL 기반의 사전학습이 더 높은 성능을 보여주고 있습니다.
물론 BSP에서의 실험 백본은 TSM이고 SSL상황에서 실험 백본은 MoCo 이기 때문에 이러한 구조적 차이로 인한 Upper 성능이 차이가 날 수 있는 거겠지만 그럼에도 지도학습을 이겼다는 것은 인상적 입니다.
Discussion
지금부터는 조금 분석적인 실험 내용들입니다. 개인적으로는 이 부분의 실험들이 마음에 들었네요.
FreqAug for Supervised Learning
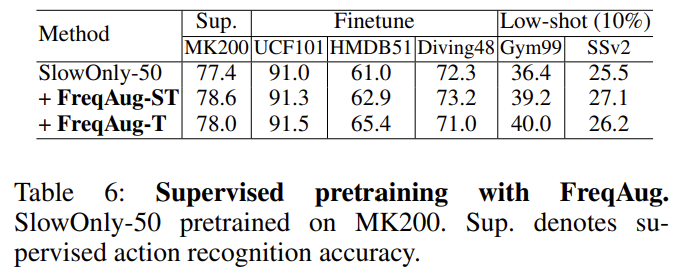
저자는 FreqAug가 Self-Supervised Learning에서만 잘 동작하는 거 아니냐 이러한 의문을 해결하기 위해 지도학습 상황에서도 FreqAug를 적용한 실험 결과를 reporting 했습니다.
결론적으로 5가지 데이터 셋에서 모두 FreqAug를 적용했을 때 지도 학습이라도 효과적인 모습을 보여주고 있습니다.
Influence on Video Representation Learning
앞서 정량적인 실험 결과를 통해 FreqAug가 효과적인 Augmentation 방법이라는 것에 대해서는 어느 정도 근거가 있지만 저자는 그렇다면 왜 효과적인지에 대해서 분석하기 위해 두가지 정성적 실험 결과를 논문에 첨부합니다.
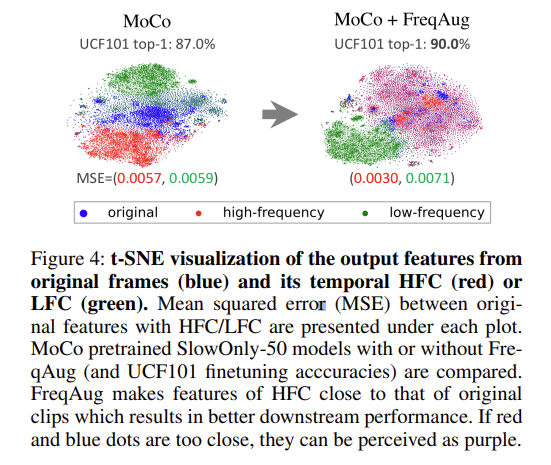
위의 그림을 보면 Augmentation을 하기 전에 clip feature들의 T-SNE 시각화를 보면 original, low-frequency, high-frequency가 각각 분리된 representation을 가지는 것을 볼 수 있습니다.
그리고 Augmentation을 진행했을 때 T-SNE 시각화를 보면 original과 high frequency가 비슷한 representation을 보여주고 있습니다. 이 말은 FreqAugmentation이 진행되지 않은 원본 original 비디오를 넣어도 feature representation이 high frequency에 해당되는 feature representation과 비슷하고 이는 모델이 high frequency 성분에 집중을 했기 때문에 발생한 결과라고 볼 수 있습니다.
그러한 상황에서 전반적으로 original + high frequency / low frequency 이렇게 두 가지로 예쁘게 구분이 되고 있으니 비디오의 전경과 배경을 파악하는데 적합한 representation을 학습 한 것 같습니다.
다음은 GradCAM 입니다. Motion Sensitive한 representation learning을 다룬 논문들에서 빠지지 않는 실험이죠.
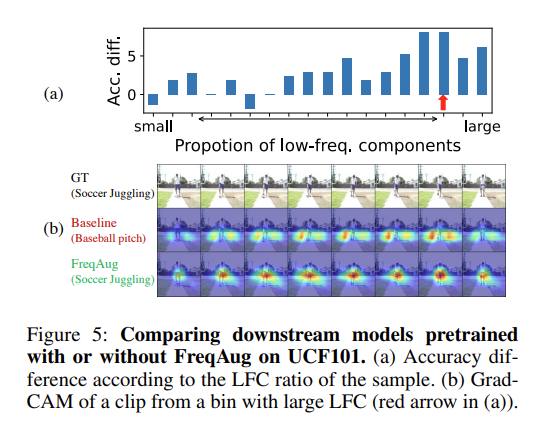
일단 위의 그림에서 (a)를 보면 영상에서 상대적으로 low-frequency 성분이 많은 비디오에 대해서는 성능 향상이 더 크게 발생하고 있습니다. 아마도 기존의 학습 방식으로는 low-frequency가 많은 비디오에 대해서는 제한된 motion 정보만을 가지고 예측을 수행해야 할 텐데 이러한 능력이 없었던 것이 더 높은 향상폭을 만들어낸 것이 아닐까 싶습니다.
다음으로 (b)를 보면 CAM을 찍었을 때 기존 Baseline은 Motion이 일어나는 부분이 아닌 다른 배경에 높은 activation이 발생하는 반면에 FreqAug는 실제로 Motion이 일어나고 있는 부분에 Activation이 크게 발생하여 모델이 Motion에 집중하고 있음을 보여주고 있습니다.
Analysis on Temporal Filtering
마지막으로 조금 해석하기 어려웠는데 저한테도 굉장히 도움이 됐던 실험 결과였습니다.
저자는 본인들이 제안한 방법론이 비교적 검출하기 쉬운 Background 에서만 잘 작동하는 것이 아님을 보이기 위해 재밌는 실험을 고안합니다. 덕분에 Kinetics 데이터 셋에 대한 새로운 특징도 알게 되었네요.
그렇다면 비교적 검출하기 쉬운 Background는 무엇을 의미할까요?
아래 그림을 보면 left clip은 장면 전환이 갑작스럽게 발생하면서 정적인 Background 검출이 어려운 상황입니다. 그에 반해 right clip은 비교적 background가 정적이고 명확하네요.
저자는 이러한 두 가지 케이스를 DFT 후 주파수 도메인에서의 intensity spectrum을 통해 분석을 진행합니다. 쉽게 정리하면 intensity spectrum의 표준편차가 작으면 구분하기 어려운 Background이고, 표준편차가 크면 구분하기 쉬운 Background라 생각하시면 됩니다.
이러한 상황에서 사전 학습으로 정말 많이 사용되는 Kinetics라는 intensity spectrum의 표준편차가 낮은(0.05) clip의 비율이 절반 정도 있는 것을 확인할 수 있습니다.
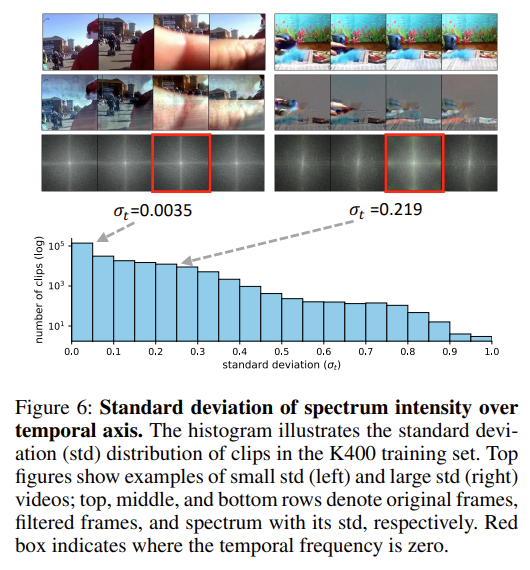
그렇다면 이제 이렇게 표준편차가 낮은 클립들이 FreqAug를 활용한 학습 과정에서 어떠한 영향을 끼치는지 확인하면 본인들이 제안한 방법론이 비교적 검출하기 쉬운 Background 에서만 잘 작동하는 것인지 아닌지 확인할 수 있겠네요.
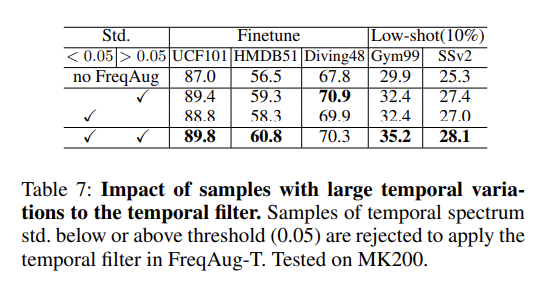
0.05라는 값을 기준으로
- 표준편차가 낮은 clip들만 쓰거나
- 표준편차가 높은 clip들만 쓰거나
- 둘 다 쓰거나
이렇게 정리할 수 있는데 어떤 경우든 간에 기존 Baseline 보다 더 높은 성능을 보여주고 있습니다.
이러한 실험을 통해 저자가 제안한 FreqAug가 다양한 Background에 상관 없이 강인하게 잘 작동하는 것을 보여주고 있습니다.
Conclusion
Simple is Best 라는 말은 이러한 연구에 쓰는 말인 것 같습니다. Motion Sensitive한 representation learning을 위해서 몇몇 연구들이 있었는데 이번 논문이 제일 인상 깊었던 것 같습니다.
Trimmed Video Representation Learning에서는 Motion Sensitive Pretraing을 위해 연구가 진행되는 것 같고 Untrimmed Video Representation Learning에서는 Context Understanding Pretraining을 위해 연구가 진행되고 있는 것 같습니다.
다음에는 Untrimmed Video Representation Learning 관련 논문을 리뷰하도록 하겠습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
결론에서 언급하신 것처럼 정말 간결하면서도 좋은 논문인 것 같습니다.
그림 4의 시각화 관련하여 약간 헷갈리는 부분이 있어 질문 드리겠습니다.
해당 시각화가 “신경망을 통과한 original/high/low 클립들의 feature들을 시각화하여 Augmentation을 적용하지 않은 모델은 각각을 다르게 임베딩하는 반면 Augmentation을 적용하니 일반적인 모델을 임베딩하는데 high-frequency 정보들에 집중하여 결과적으로 original clip과 high frequency clip을 유사한 영역에 임베딩하고 있음을 보여주는 것으로 이해하였는데요.
시각화의 좌측(augmentation 미적용)에서 original/high/low가 꽤나 명확하게 분리되는데, augmentation을 주니 original/high는 완전히 유사해지고 low는 여전히 분리되는 것이 신기합니다. 혹시 augmentation이라는 것이 original/high를 positive로 하는 contrastive learning이 적용된 것인가요?
감사합니다!
본 논문이 제안하는 방법은 augmentation이기 때문에 SSL framework를 contrastive learning으로 할수도 있고 Pretext task로 할수도 있습니다. 백본마다 다르기 때문에 Appendix에 있는 Implementation detail을 확인하면 알 수 있습니다.
좋은 리뷰 감사합니다. 분야가 분야인지라 리뷰를 완벽히 이해하기는 어려웠지만 논문에서 주장하는 바가 깔끔하고 명확해서 재밌게 읽었습니다.
2가지 정도 질문이 있는데 먼저 마지막 실험 관련해서 제가 제대로 이해한 것이 맞는지 여쭙습니다. kinetics dataset에서 intensity spectrum의 표준편차가 작은 경우가 대부분이고 (즉 background 구분이 어려운 클립들이 많이 분포된 데이터 셋), 결국 background 구분이 쉽든 어렵든 상관없이 저자가 제안하는 augmentation 기법을 사용하면 좋은 효과를 볼 수 있다는 것이죠?
그렇다면 이 background가 확 바뀌는 상황과 유사하게 복잡한 scene에서도 해당 기법이 잘 통한다는 실험 혹은 저자의 고찰은 없을까요? 제가 비디오쪽 데이터 셋에 대해 문외한이라 잘 모르지만 리뷰에 있는 정성적 그림들을 보면 영상들이 ImaegNet 혹은 COCO 데이터셋처럼 object centric한 경향성이 좀 있는 것 같은데, 혹시 자율주행과 같이 다양한 물체들이 오밀조밀 모이는 복잡한 상황들도 filtering이 잘 되는지 등이 개인적으로 궁금하네요.
두번 째 질문은 DFT 구현과 관련된 내용인데 이게 temporal 축에 대해 필터링을 한다는 것이 좀 와닿지가 않네요. pseudo 코드가 있긴 하던데 저 filter가 실제로 어떤식으로 구성되는 것인가요? 마치 1×1 convolution처럼 spatial한 부분 각각에 대해 temporal 축 내의 고주파 성분을 쭉 훑는 것인가요?
다양한 물체들이 오밀조밀 모이는 복잡한 상황들도 filtering이 잘 되는지 등이 개인적으로 궁금하네요.
=> 이러한 케이스가 Background가 어려운 case 들인데 저자가 이러한 케이스에 대해서도 잘 작동한다는 실험을 보여주었기 때문에 어느정도 효과가 있을거라 생각이 듭니다.
temporal 축에 대해 필터링은 결국 앞 뒤 프레임간 차이에 대한 미분을 계산하는 것이라 보면 됩니다. Motion이 발생하는 부분은 앞 뒤 프레임간 차이가 발생하기 때문에 고주파성분이고 Motion이 발생하지 않는 background는 앞 뒤 프레임간 차이가 적기 때문에 저주파성분입니다.
안녕하세요 좋은 리뷰 감사합니다.
저자가 제안하는 freq augmentation은 다른 augmentation들이 모두 수행되고 가장 마지막에 랜덤을 수행된다고 하였는데, 이렇게 순서를 특정한 이유가 언급되어 있나요? 또한 기존에 연구되었던 temporal augmentation도 freq augmentation과 동시에 사용될 수 있는 것인지 궁금합니다.
그리고 discussion의 첫 번째로 보여주신 실험이, self-supervised 조건에서만 잘 동작하는게 아닌지에 대한 의문을 해소하기 위한 것으로 이해하였습니다. 이 의문은 타 trimmed self-supervised video representation learning에서는 못보던 내용인 것 같은데, 혹시 이러한 의문 자체가 왜 생길 수 있는지에 대해 설명해주시면 감사하겠습니다.
순서를 특정한 이유가 언급되어 있나요? => 언급되어있지 않습니다. 그냥 Plug and Play 방식으로 쉽게 적용하기 위해 다른 방법론들의 순서를 건드리지 않는 선(즉, 가장 마지막에 하면 됨) 적용한 것 같습니다.
그런 접근은 많이 있습니다. Video에서 사용하는 SSL 방식을 Image로 내려서 검증하는 등의 방법은 몇 있었는데 그런 관점에서 SSL에 사용하는 방식을 Supervised로 내리는 검증 방법 역시 자연스러운 발상인 것 같네요.