안녕하세요. 백지오입니다.
이번 x-review는 최근 공개된 CVPR 2023 Accepted Paper이자 공개 직후 엄청난 관심(깃허브 스타 5000+)을 받고 있는 ImageBind입니다. 제가 연구해보고 싶었던 분야인 Multimodal Joint Embedding Space 분야를 연 논문이 아닌가 생각이 듭니다. 이런 게 나오려면 몇 년은 더 걸릴 줄 알았는데, 벌써 나오고 말았네요…
개인적으로 제가 읽어 본 논문들 중 가장 큰 충격을 받은 논문인 것 같습니다. 바로 리뷰 시작해 보겠습니다.
소개
딥러닝 모델들은 어떤 잠재 공간에 데이터를 임베딩하는 함수로 볼 수 있다. 이 임베딩을 비교하여 분류나 회귀와 같은 문제를 풀 수도 있고, 임베딩을 원래 데이터로 복원하는 모델을 통해 압축이나 생성, 변형 등 다양한 task를 수행할 수 있다. 특히, 이러한 임베딩의 성질을 활용한 생성 모델은 텍스트 프롬프트로부터 정교한 이미지를 만들어내거나(Text, Image), 어떤 이미지를 다른 스타일의 이미지로 변환(Image, Image)하는 등 최근 굉장한 속도로 발전하였다. 그러나, 세 가지 이상의 다른 모달리티의 데이터들을 하나의 임베딩 공간으로 묶는 것은 아직까지는 어려운 일이었다.
ImageBind는 이미지를 임베딩 공간을 묶는(Bind) 기준으로 삼아, 6가지의 모달리티를 하나의 공통 임베딩 공간(Joint Embedding Space)으로 임베딩하는 모델이다. ImageBind는 이미지, 비디오, 오디오, 텍스트, 열화상(Thermal) 이미지, IMU 모션 데이터, 깊이(Depth) 데이터를 공통된 임베딩 공간에 임베딩하고, 이 공통 임베딩을 활용하여 다양한 task를 수행한다. 특히, 학습 데이터에 포함되지 않은 데이터에 대한 task인 cross-modal zero-shot recognition task에서 이 모델은 일부 지도학습된 전문가 모델을 뛰어넘는 놀라운 결과를 보인다.
본격적인 논문 리뷰에 앞서, ImageBind의 활용 예시들을 먼저 살펴보자. 저자들이 공개한 데모 페이지에서도 다양한 예시들을 확인할 수 있다.
Cross-Modal Retrieval

ImageBind에서 데이터는 모달리티에 관계없이 공통된 공간에 임베딩되기 때문에, 이를 이용하여 다른 모달 간의 검색을 수행할 수 있다. 기존에는 Cross-Modal Retrieval을 학습시키기 위해 Image-to-Text Retrieval이라면 (Image, Text) 데이터쌍이, Audio-to-Image Retrieval이라면 (Audio, Image) 데이터쌍이 필요했다.
그러나 ImageBind는 검색하고자 하는 모델 간의 쌍이 없어도 검색이 가능하다. 예를 들어, <그림 1>과 같이 화롯가의 오디오 데이터를 통해 동영상을 검색하고자 할 때, 모델 학습에 (오디오, 비디오) 데이터가 없었더라도 검색이 가능하다.
Embedding-Space Arithmetic

임베딩된 데이터의 벡터를 사용해 산술 연산을 수행할 수 있다. <그림 2>에서 어떤 새의 사진과 파도 소리에 더하기 연산을 수행하여 바닷가에 있는 새의 이미지를 검색한 결과를 볼 수 있다.
Cross-Modal Generation

ImageBind의 임베딩 벡터를 다른 생성 모델과 결합하여 콘텐츠 생성에 활용할 수 있다.
ImageBind
한 장의 사진은 많은 경험들을 하나로 묶는 힘을 가지고 있다.
해변가의 사진을 보면, 파도 소리와 모래의 감촉, 바닷바람… 심지어 한 편의 시까지 떠오른다.
이미지는 이러한 묶는(Binding) 속성을 통해, 다양한 모달리티와 함께 학습될 수 있다. 최근 이미지의 시각적 특성과 다른 모달리티의 특성을 연결하는 정말 다양한 연구가 진행되고 있다. (text-image, audio-image 등) 이러한 연구들은 많아야 한 개에서 두 개의 모달리티를 이미지와 묶는데 그친다. 이런 모델들의 한계는 모달리티들을 연결하기 위해 해당 모달리티들의 쌍이 있어야 한다는 것이다. (예를 들어, 이미지와 텍스트를 연결하고자 한다면 이미지와 그 이미지와 연관된 텍스트의 쌍에 대한 데이터셋이, 이미지와 오디오를 연결하고자 한다면 이미지와 연관된 오디오의 쌍에 대한 데이터셋이 필요하다.)
결국 비디오-오디오의 임베딩을 학습한 모델은 이미지-텍스트 task를 수행할 때 전혀 도움이 되지 않고, 그 반대도 마찬가지이다. 이러한 데이터들의 부재야말로 다양한 모달리티를 한 공간에 임베딩하지 못하게 하는 장애물인 것이다.
ImageBind는 Image-Paired 데이터들을 이용해 하나의 공통된 Representation Space를 학습한다. 이를 통해 모든 모달리티가 동시에 존재하는 데이터셋 없이도, 이미지의 묶는 속성을 이용해 서로 다른 모달리티들의 임베딩 공간을 정렬(align)할 수 있다. 각 모달리티들의 임베딩 공간을 이미지의 임베딩 공간과 정렬하여, 결국 모든 모달리티가 같은 공간에 정렬되도록 한다. ImageNet은 web-scale의 대규모 멀티 모달 쌍 데이터셋들 (image, text), (video, audio), (image, depth) 등을 활용해 하나의 공통된 임베딩을 학습한다. 나아가, ImageBind는 CLIP과 같은 대규모 vision-language 모델로 초기화될 수 있어, 조금의 학습만 거치고도 다른 모달리티에서의 task를 수행할 수 있다.
저자들은 6가지 모달리티에서의 학습과 평가를 통해 이 모델의 성능을 실험하였다. 이때 기반이 되는 이미지의 표현(representation)을 잘 학습하고 있을수록 다른 모달리티에서의 성능도 향상되었다. 특히, audio classification과 retrieval 성능에서 ImageBind의 zero-shot classification 성능은 기존에 audio-text에서 지도학습된 ESC, Clotho, AudioCaps를 앞섰으며, few-shot 평가에서도 다양한 지도학습 방법론들을 이겼다.
특히, 저자들은 모델이 학습과정에서 보지 못한 모달리티 쌍들 간의 관계를 추론하는 emergent zero-shot task를 새로 정의하였다. 예를 들어, ImageBind는 모델 학습 과정에서 (이미지, 텍스트), (이미지, 오디오) 데이터 쌍만을 가지고 학습하여도 (텍스트, 오디오) 모달리티 쌍에 대한 task를 수행할 수 있다.
Related Work
저자들은 ImageBind가 기존의 vision-language, multimodal, self-supervised 연구에 기반하였다고 한다. (스윗하다.)
Language Image Pre-training
이미지를 단어나 문장과 같은 언어적 신호와 함께 학습하는 것은 zero-shot, open-vocabulary recognition과 text to image retrieval 등에서 좋은 방법으로 많이 활용되어 왔다. CLIP, ALIGN, Florence와 같은 모델들은 대규모의 이미지와 텍스트 쌍을 수집하여 contrastive learning을 활용해 같은 공간에 임베딩하여 훌륭한 zero-shot 성능을 보인 바 있다. 이 외에도 CoCa, Flamingo, LiT와 같은 모델들이 contrastive learning을 통해 다른 모달리티들을 묶어 좋은 성능을 보였다. 이러한 모델들은 대부분 이미지-텍스트에 집중하였는데, ImageBind는 더욱 다양한 모델에서 zero-shot recognition을 수행할 수 있다.
Multi-Modal Learning
기존의 연구들은 각기 다른 모달리티 간의 학습을 지도학습이나 자기 지도학습 방향으로 수행하고자 했다. 이미지와 언어를 사전학습하는 방법인 CLIP의 성공은, 많은 연구가 이러한 언어적 입력과 다른 모달리티 간의 문맥적 정보에 집중하도록 만들었다. Nagrani et al. 은 weakly-labeled video-audio dataset을 만들고 캡션을 제공하여 이미지-오디오-텍스트 모달 쌍의 데이터를 제공했고, CLIP 프레임워크에 추가적으로 오디오 모달을 넣은 AudioCLIP이 등장하여 zero-shot audio classification이 가능해졌다.
한편, ImageBind는 명시적인 멀티모달 데이터 쌍 없이, 이미지를 활용하여 다양한 모달리티를 통합한다.
Feature Alignment
사전학습된 CLIP은 다양한 모델들의 teacher model로 활용되었다. CLIP의 강력한 이미지-텍스트 공통 임베딩은 detection, segmentation, mesh animation 등 다양한 분야에서 그 성능을 과시헀다. PointCLIP은 사전학습된 CLIP 인코더에 3D point cloud를 2D Depth map 형식으로 입력하여 3D Recognition에 사용할 수 있음을 보였다. 신경망 기반 언어 번역에서는 각 언어들을 모두 같은 공간에 임베딩하여, 각 언어 간의 쌍이 없어도 번역이 가능함을 보였다.
Method

ImageNet은 위에서 언급하였듯이, 각 모달을 이미지와 정렬하여, 결과적으로 모든 모달이 같이 정렬되도록 한다. <그림 4>에서 학습에 사용된 멀티모달 쌍들의 예시를 볼 수 있다.
Preliminaries
Aligning specific pairs of modalities
Contrastive Learning은 연관된 샘플(양성)들과 연관되지 않은 샘플(음성)들의 쌍을 이용해, 임베딩 공간을 학습하는 대표적인 방법이다. 필자의 이전 Metric Learning 소개글에서 자세한 내용을 살펴볼 수 있다. 이러한 쌍들을 활용해, 모델은 (이미지, 텍스트), (오디오, 텍스트), (이미지, 깊이) 등의 다양한 모달리티 쌍들을 정렬할 수 있다.
그러나 이러한 방법들은 모달리티 쌍이 존재하는 경우에만 공통 임베딩을 학습할 수 있었기 때문에, (비디오, 오디오)에서 학습된 임베딩은 (이미지, 텍스트)에 바로 사용할 수 없고, 반대도 성립하는 문제가 있었다.
Zero-shot image classification using text prompts
CLIP은 정렬된 (이미지, 텍스트) 공통 임베딩 공간에서의 zero-shot 분류 문제로 인기를 얻었다. 데이터셋에 포함된 클래스에 대한 텍스트 설명이 주어지면, 입력된 이미지가 어떤 설명에 해당하는지 분류하는 것이다. 이는 입력 이미지의 임베딩 벡터와 유사한 텍스트 설명을 찾는 것으로 수행된다.
Binding modalities with images
드디어 대망의 핵심 부분이다!
ImageBind는 이미지 $\mathcal{I}$와 다른 모달리티 $\mathcal{M}$의 쌍 $(\mathcal{I}, \mathcal{M})$을 사용하여 공통 임베딩을 학습한다. 저자들은 대규모 web dataset들을 이용해 (이미지, 텍스트) 쌍을 학습하여 의미론적 개념을 잘 학습한다. 그리고 다양한 모달리티들과 이미지의 쌍들을 이용해 멀티모달 임베딩을 학습한다.
어떤 이미지 $I_i$와 다른 모달리티의 샘플 $M_i$가 주어졌을 때, ImageBind는 각각을 $q_i = f(I_i), k_i = g(M_i)$로 임베딩한다. ($f, g$는 임베딩을 수행하는 신경망이다.) 임베딩과 인코더는 InfoNCE Loss로 학습된다. ($\tau$는 temparture 값)
$$L_{\mathcal{I}, \mathcal{M}} = -\log\frac{\exp(q_i^Tk_i / \tau)}{\exp(q_i^Tk_i/\tau) + \sum_{j\neq i} \exp(q_i^Tk_j/\tau)}$$
위 함수에서, 분자와 분모의 좌측 부분은 양성 쌍, 즉 같은 의미를 갖는 이미지 임베딩 $q_i$와 다른 모달리티의 임베딩 $k_i$의 내적으로, 두 임베딩이 유사하면 1에 가까운 값, 그렇지 않으면 0에 가까운 값을 출력한다. 이 두 값이 커지면 $\log$ 함수에 의해 손실은 0에 가까워진다.
한편 분모의 우측 부분은 미니배치 안에서 $q_i$와 쌍을 이루지 않는 다른 모달리티의 임베딩, 즉 음성 쌍과의 내적이다.
$q_i$와 무관한 샘플의 임베딩 $k_j$과의 유사도가 높으면 $sum$에 의해 분모가 커지고, $\log$에 의해 손실값이 커진다.
대칭 형태의 $L_{\mathcal{I}, \mathcal{M}}, L_{\mathcal{M}, \mathcal{L}}$ 손실 함수를 활용해, 각 모달리티와 이미지 간의 공통 임베딩을 학습한다.
Emergent alignment of unseen pairs of modalities
ImageBind는 각 모달리티를 이미지를 기준으로 정렬한다. 즉, $(\mathcal{I}, \mathcal{M})$ 데이터쌍은 모달리티 $\mathcal{M}$을 이미지와 정렬하는 데 사용된다. 이때, 저자들은 $(\mathcal{I}, \mathcal{M}_1)$과 $(\mathcal{I}, \mathcal{M}_2)$를 통해 $\mathcal{M}_1, \mathcal{M}_2$를 각각 이미지와 정렬하는 것이 $(\mathcal{M}_1, \mathcal{M}_2)$ 두 모달리티도 정렬하는 것을 발견하였다. 이를 통해 ImageBind는 별도의 학습 없이 다양한 zero-shot, cross-modal retrieval task를 수행할 수 있게 된다. 특히, 저자들은 zero-shot text-audio classification에서 (audio, text) 데이터쌍을 사용하지 않고 SOTA를 달성하였다.
Implementation Details
ImageBind는 구조적으로 단순하며, 다양한 방법으로 응용할 수 있다. 저자들은 쉬운 후속 연구 및 응용을 위한 vanilla implementation을 소개하고, Ablation Study를 통해 binding에 중요한 요소들을 소개한다.
Encoding modalities
필자의 각 모달리티에 대한 지식이 충분하지 않아, 이 섹션에 대한 자세한 내용은 논문을 참고해 주기 바란다.
저자들은 모든 모달리티의 인코더로 트랜스포머를 사용했다. 이미지와 비디오에는 같은 비전 트랜스포머(ViT)를 사용하였고, 오디오에는 AST: Audio Spectrogram transformer를 사용했다. 오디오 spectrogram이 이미지와 같은 2D 신호로 볼 수 있기 때문에, patch size 16, stride 10의 ViT를 적용하였고, 열화상 이미지(thermal)와 깊이 이미지(depth)는 각각 1 채널 이미지로 보고 ViT를 적용했다. IMU 신호는 샘플링 과정을 거쳐 1D 시퀀스로 만들고, 트랜스포머로 처리하였다. 마지막으로 텍스트에는 CLIP의 디자인을 활용했다.
인코더를 거친 각 모달리티의 데이터는 모달리티 별로 별도의 선형 projection head를 거쳐 고정된 $d$ 차원의 임베딩으로 변환되었다. 이를 InfoNCE Loss로 normalize 하였다. 이 구조에서 인코더는 사전학습된 모델을 사용할 수 있는데, 대표적으로 이미지와 텍스트 인코더로 CLIP 또는 OpenCLIP을 사용하였다.
Experiments
실험에 앞서 저자들은 한층 자세한 실험 환경을 소개한다.
저자들은 자연스럽게 짝지어지는(Naturally paired) 모달리티 쌍의 데이터셋을 사용하였다. (비디오, 오디오) 데이터인 Audioset, (이미지, 깊이) 데이터인 SUN RGB-D, (이미지, 열화상) 데이터인 LLVIP, (비디오, IMU) 데이터인 Ego4D 데이터셋을 사용하였고, 이외에 추가적인 지도(클래스 라벨, 텍스트 등)는 제공하지 않았다. SUN RGB-D와 LLVIP 데이터셋이 상대적으로 작아, 50배 크기로 복제하여 사용하였다.
또한 저자들은 대규모 이미지-텍스트 쌍 데이터를 사용했다. 저자들은 수십억 개의 (이미지, 텍스트) 쌍에서 사전학습된 모델을 사용하였다. 정확히는, OpenCLIP의 사전학습된 비전(ViT-H 630M params) 모델과, 텍스트 인코더(302M params)를 사용했다.
각 모달리티의 인코더는 오디오는 2D mel-spectrogram으로 변환하고, 열화상과 깊이 모달리티는 1 채널 이미지로 취급하여 각각 ViT-B, ViT-S 인코더로 처리했다. 이미지와 텍스트 인코더는 ImageBind의 audio, depth, thermal, IMU 인코더가 학습되는 동안 학습을 진행하지 않았다.(freeze)
CLIP, AudioCLIP과 같은 방법들은 같은 모달리티를 위한 text-prompt를 사용한 zero-shot classification을 위해 (이미지, 텍스트), (오디오, 텍스트) 데이터에서 각각 학습된다. 그러나 ImageBind는 (이미지, 텍스트) (이미지, 오디오)만을 학습하고도 (오디오, 텍스트) zero-shot task를 수행할 수 있다. 저자들은 이러한 task를 emergent zero-shot task라 명명했다.
Emergent zero-shot classification
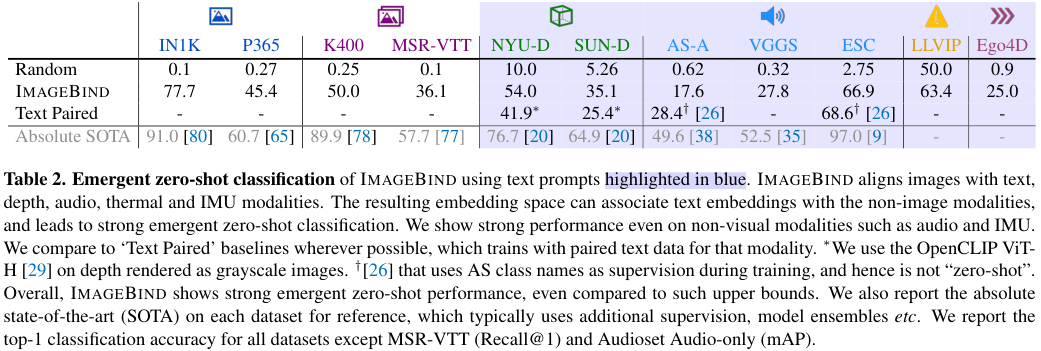
저자들은 ImageBind가 학습 과정에서 보지 못한 모달리티 쌍들을 연관 짓는 능력을 평가하였다. 이는 완전히 새로운 분야이기 때문에 다른 fair baseline은 존재하지 않는다. 그러나 저자들은 텍스트와 모달리티 쌍을 활용하여 학습된 모델과의 비교, 지도학습을 통해 얻어진 성능과의 비교를 수행하였다.
각 벤치마크에서, ImageBind는 강력한 emergent zero-shot classification 성능을 보이며, 특히 일부에서는 지도학습된 모델에 가까운 성능을 보인다. 이는 ImageBind가 주어진 텍스트의 의미를 이미지 모달을 건너 다른 모달리티로 잘 연관지음을 의미한다. 특히, ImageBind는 오디오나 IMU와 같은 분야에서 높은 성능을 보인다. 또한, ImageBind의 이미지&텍스트 인코더가 OpenCLIP 사전학습 모델을 사용하며 이를 동결하였기 때문에, OpenCLIP과 동등한 성능을 보인다.
Comparison to prior work
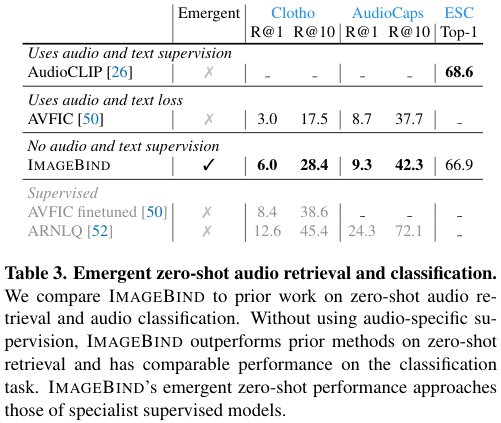
Zero-shot text to audio retrieval and classification에서, ImageBind는 emergent zero-shot 모델임에도 불구하고, Clotho와 AudioCaps 데이터셋에서 비지도학습 기반 모델 중 SOTA를 달성한다. ESC 데이터셋에서는 AudioCLIP에 밀리는 모습을 보이지만, AudioCLIP은 학습 과정에서 AudioSet 데이터셋의 class name을 사용하기 때문에 지도학습 모델임을 고려하면 높은 성능을 보인다.

Text to audio and video retrieval에서, 저자들은 MSR-VTT 1k-A 벤치마크를 수행해 성능을 평가하였다. 오디오만을 사용하였을 때, ImageBind는 MIL-NCE와 유사한 높은 emergent zero-shot 성능을 보인다. 특히, 오디오와 비디오 모달리티를 함께 사용한 경우, 기존 모델들을 앞서는 훌륭한 retrieval 성능을 보여준다.
Few-shot classification

저자들은 ImageBind의 오디오, 깊이 인코더를 사용하여 Few-shot Classification 성능을 측정하였다. few-shot 오디오 분류 문제에서, 저자들은 Audioset 데이터셋에서 자기 지도학습된 AudioMAE 모델과 지도학습된 AudioMAE 모델을 파인튜닝하여 오디오 분류 성능을 비교하였다. 두 베이스라인 모두 ImageBind와 같은 ViT-B 오디오 인코더를 사용하는데, ImageBind는 4-shot 이하의 실험에서 최대 40%의 top-1 정확도 차이로 자기지도학습 AudioMAE 모델을 앞섰고, 지도학습 모델과도 유사한 성능을 보였다. 특히, ImageBind의 emergent zero-shot 성능이 2-shot 미만에서의 지도학습 성능까지 앞선 것이 주목할 만하다.
Few-shot depth classification 문제에서는 이미지, 깊이, sementic segmentation 데이터에서 학습된 멀티모달 MultiMAE ViT-B 모델과의 비교를 수행하였다. ImageBind는 MultiMAE 대비 모든 few-shot 설정에서 앞섰다.
이러한 실험들은 ImageBind의 높은 generalization 성능을 보여준다.
Analysis and Applications

임베딩 벡터 간의 산술연산이 가능하다. <그림 5>에 이를 활용한 이미지 검색 결과가 나타나 있다. 예를 들어, 테이블 위에 놓인 과일 이미지에 새들이 지저귀는 소리를 더하여 새들이 앉아있는 과일나무 사진을 찾은 것을 볼 수 있다. 이미지 인코더는 학습이 진행되지 않기 때문에, CLIP 임베딩을 사용하는 비전 모델에 오디오를 비롯한 타 모달리티의 ImageBind 임베딩을 추가적인 학습 없이 적용할 수 있다.
텍스트 기반 detector를 오디오 기반으로 업그레이드할 수 있다. CLIP기반 클래스 임베딩을 사용하는 Detic과 같은 모델에, ImageBind의 오디오 임베딩을 입력하도록 수정하면 별도의 학습 없이 오디오 기반 모델로 변환할 수 있다.
텍스트 기반 디퓨전 모델을 오디오 기반으로 업그레이드할 수 있다. 사전학습된 DALLE-2와 같은 이미지 생성 디퓨전 모델의 프롬프트 임베딩을 ImageBind의 오디오 임베딩으로 교체하여 오디오로 이미지를 생성하도록 할 수 있다. 저자들은 DALLE-2 제작자들에게 private reimplementation 모델을 받아 실험했다고 한다.
Ablation Study
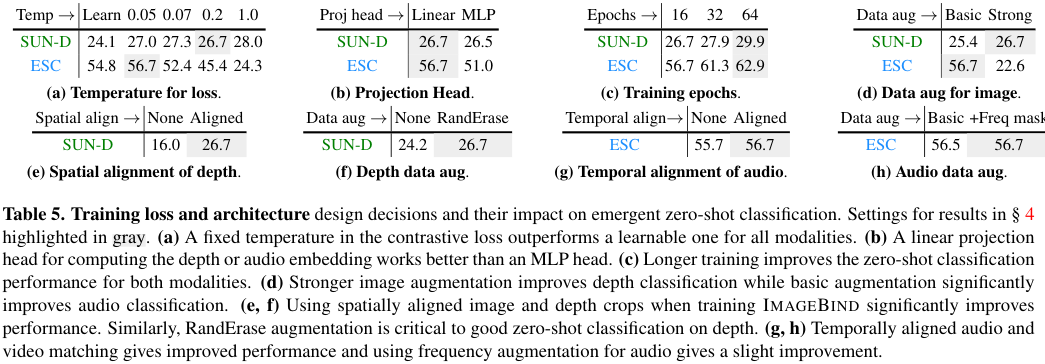
저자들은 여러 가지 비교 실험을 진행하였는데, 이때 시각적, 공간적 정보를 잘 대표하는 깊이(depth) 모달리티와 비시각적, 시간적 정보를 잘 대표하는 오디오 모달리티를 중점적으로 살펴보았다. 저자들은 이러한 모달리티에 집중하는 것이 ImageBind를 강건하고 transferable 하게 만든다는 것을 발견하였다.
저자들은 Contrastive Loss에 적용된 Temperature $\tau$를 0.07로 초기화되어 학습 가능하게 하는 것과, 고정된 어떤 값을 사용하는 것을 비교하였다. 그 결과, 깊이, 오디오, IMU에 대해서는 고정된 temperature가 좋다는 것과, 깊이, 열화상, IMU 인코더에는 높은 temperature, 오디오에는 낮은 temperature가 좋다는 것을 알았다.
각 모달리티의 Projection Head를 선형으로 설계하는 것과, 768개의 은닉 차원을 갖는 MLP로 설계하는 것의 차이를 비교하였는데, SimCLR와 같은 일반적인 자기 지도학습 모델들과 달리 선형 projection이 더 좋은 성능을 보였다.
데이터 증식을 일반적인 방법들(크롭, color jitter)로 수행하는 것과 강한 증식(RandAugment, RandErase)까지 수행하는 것을 비교하였을 때, 강한 증강은 깊이 모달리티가 적은 SUN RGB-D 데이터에서 학습하는데 도움이 되었지만, (오디오, 비디오) 데이터쌍은 문제를 너무 어렵게 만들어 좋지 않았다고 한다.
Discussion and Limitations
ImageBind는 여러 모달리티의 공통 임베딩 공간을 학습하는 간단하면서도 실용적인 방법이다. 이로 하여금 cross-modal retrieval과 text-based zero-shot task들과 같은 emergent alignment task들을 수행할 수 있게 되었다. 또한 저자들은 다양한 멀티 모달리티가 조합된 task들을 수행하거나, Detic이나 DALLE-2 같은 일반적인 비전 모델을 이러한 멀티 모달 모델로 업그레이드하는 방법을 선보였다.
ImageBind를 개선할 방법으로 저자들은 다음을 제시한다.
- image alignment loss를 text와 같은 모달 간의 조합 데이터셋 (텍스트, IMU 등) 도 활용하여 강화
- ImageBind가 별다른 downstream task와 함께 학습되지 않아 전문가 모델들에 비해 성능이 떨어지는 문제 해결
- 각 task를 위한 general purpose embedding 추가 연구
- 새로운 벤치마크 제시 (저자들은 emergent zero-shot task를 새로 정의하였으나, 아직 이에 대한 벤치마크가 없다.)
막연히 만들어보고 싶다고 생각만 하던 것들을 누군가 만드는 일이야 요즘같이 발전이 빠른 세상에 흔한 일이지만, 이렇게까지 빨리 등장할 줄 몰랐던 논문이기도 하고, 방법론이 생각보다 아주 간단하면서도 깔끔해서 많이 충격적이었던 논문이었습니다.
필자는 항상 문제를 복잡하게 생각하고, 더 복잡한 풀이를 시도하는 경향이 있는데, 이를 고쳐나가야겠다는 생각을 한번 더 하게 만드는 논문이었던 것 같습니다.
안녕하세요 지오님. 리뷰 잘 읽었습니다.
우선 질문에 앞서 저 또한 연차가 오래되지 않았지만 이전 리뷰에서 글 쓰는 방식 등에서도 말씀해주셨기에, 사견을 남깁니다.
첫 번째로는 X-Review의 특성 상 독자가 저희 연구실 인원임에 모든 인원들의 이해 수준이 낮을 수도, 높을 수도 있습니다만, 현재 리뷰는 지오님 블로그에서 작성하시는 문체의 향수가 느껴집니다. 따라서 리뷰를 읽다보면 InfoNCE Loss 등에 대해서는 자세하고도 풀어 설명해주시는 반면 논문의 몇몇 부분은 제가 평소 몰랐거나 이해하지 못한 부분에 대한 설명이 빈약한 느낌이 들었습니다. 물론 논문을 읽으신 지오님과 저의 관심 분야와 배경 지식이 달랐기에 그렇게 느껴졌을 수 있지만, 연구원에게 편한 어투로 개인적인 고찰도 담으며 설명해주시면 더욱 풍부한 이해력을 전달하는 리뷰가 되지 않을까 생각합니다.
해당 논문의 아이디어는 지오님께서도 예전에 관심 있다 혹은 미래는 이렇게 되지 않을까 말씀하셨던 기억이 나는데, 2023 CVPR에 발표되어 연구의 시발점을 알리는 느낌이 나네요. 결국 논문의 핵심은 Text, Video, Image, Audio 등등 어떤 것이라도, 서로가 이해될만한 고정된 차원으로 임베딩하는 것으로 보이는데, 그렇다면 임베딩을 위한 각 인코더들은 저자가 실험적으로 사용해본 것들인가요? 그 이유로는 어떤 입력이라도, 어떤 출력을 위해서라도 다양한 모달리티가 사용되기 위해서는 각 임베딩된 벡터들이 의미론적으로 서로의 모달리티에 납득(?)될만하고 학습될만해야한다고 느껴지는데, 해당 실험에서는 ViT 등을 사용한 것이 현재의 SoTA에 유사한 모델들을 인코더로 사용한 것으로 보이기 때문입니다.
추가적으로, 해당 논문의 Contribution과 데모를 봤을 때 굉장히 인상깊네요. 그렇기에 방법론이 조금 더 궁금한데, 해당 리뷰의 내용을 조금 더 풀어서 써주시면 감사하겠습니다. (제가 이해력 수준으로 인하여.. 뭔가 임베딩된 벡터? 공통된 InfoNCE Loss로 학습한다는 것의 의의? 실험 테이블에 대한 이해가 부족했습니다.)
새 시대를 열 수도 있을 좋은 논문인 것 같네요. 리뷰 감사합니다.
안녕하세요. 이상인 연구원님.
세심한 의견과 질문 감사드립니다.
다음 리뷰는 조금 더 독자를 고려하여 작성할 수 있도록 노력해보겠습니다.
질문에 대해 답변을 드리겠습니다.
1. ImageBind 방법론
ImageBind는 OpenCLIP이라고 하는 대규모 pre-trained Image-Text 모델을 기반으로 다양한 모달리티의 임베딩 공간을 OpenCLIP의 임베딩 공간으로 묶습니다. 즉, Image와 Text Encoder는 사전 학습된 OpenCLIP 모델에서 가져와 학습을 더 진행하지 않습니다. 사전 학습된 OpenCLIP 이미지 인코더와 텍스트 인코더는 <강아지 사진>과 “DOG” 텍스트를 유사한 벡터로 임베딩합니다.
여기에 새로운 (image, audio) 데이터셋을 가져와 해당 데이터셋의 <강아지 사진>은 OpenCLIP 이미지 인코더를 통과시키고, <강아지 소리>는 새로운 오디오 인코더를 통과시켜 임베딩합니다.
이때 InfoNCE Loss를 통해, <강아지 소리>의 임베딩 벡터가 OpenCLIP 이미지 인코더를 통과한 <강아지 사진>의 임베딩 벡터와 비슷해 지도록 오디오 인코더를 학습 시킵니다.
<강아지 소리>의 임베딩 벡터가 <강아지 사진>과 정렬되면서, 자연스럽게 “DOG”와 <강아지 소리>의 임베딩도 유사해집니다.
2. 트랜스포머를 사용한 이유
위와 같은 ImageBind의 방법론을 활용하면 각 모달리티에 어떤 모델을 사용하여 임베딩하여도 결국 임베딩 벡터의 차원만 같다면 품질의 차이는 있을지언정, 인코더의 구조와 상관없이 공통된 임베딩 공간을 얻을 수 있습니다. 논문에서 트랜스포머 구조를 사용한 것에 대한 상세한 이유나 비교 실험 등이 있지는 않습니다만, 제가 생각하기에 인코더 모델의 비교를 진행하는 것이 논문의 contribution인 “여러 인코더의 임베딩 공간을 한 공간으로 묶는 것”과 직접적인 연관이 없고, ImageBind에서 중요하게 사용한 CLIP이 트랜스포머 구조이기도 하고, 상인님께서 언급하신 것처럼 트랜스포머가 SOTA이기도 해서 사용한 것으로 보입니다.
감사합니다.