이번에 소개할 논문은 ICLR2023에 게재된 논문으로, Self-supervised Learning에서 가장 널리 사용되는 두 가지 기법(Contrastive Learning and Mask Image Modeling)들을 Vision Transformer 학습에 사용할 때 각각 어떠한 경향성이 있는지를 분석한 논문입니다.
본 논문은 예전 ICLR2022 Spotlight에 선정되었던 “How Do Vision Transformer Work?”이라는 논문을 쓴 저자랑 동일 저자이며, 저 논문 역시 상당히 재밌고 흥미로운 내용을 담고 있었기에 이번 논문도 기대하면서 읽어보았습니다. (ICRL2022 논문은 저와 임근택 연구원이 x리뷰로 작성한 적이 있기에 궁금하시면 한번 읽어보셔도 좋습니다만 본 논문의 내용과는 큰 관련이 없기에 반드시 읽으실 필요는 없습니다.)
Intro
일단 본 논문은 위에서도 언급했다시피, 2가지 Self-Supervised Learning(SSL) 방법론이 Vision Transformer(ViT)를 사전학습 하는데 있어 각각 어떤 경향과 성질을 보이는지에 대하여 다룬 논문입니다. 여기서 2가지 Self-Supervised Learning 방식은 각각 Contrastive Learning(CL) 기반 방식과, Masked Image Modeling(MIM) 기반 방식을 의미합니다.
Contrasitve Learning 방식은 아시는 분들은 잘 아시다시피, Anchor가 Positive Sample과는 가깝게, Negative Sample과는 멀리 하도록 학습하는 Metric Learning 기반의 학습 방식입니다. 이러한 CL 기법은 Postivie를 어떻게 선정하는지, Negative는 어떻게 선정하는지, 그리고 Negative 개수는 1개만 둘지, 아니면 N개를 둘지 등등에 따라서 사전 학습된 모델의 성능이 달라집니다.
CL과 관련하여 보다 자세한 내용을 다루면 좋겠지만, 그러기엔 논문 내용이 묻힐 수 있으니 잘 모르시는 분들은 CL은 metric learning으로 학습하는구나! 라고 이해하고 넘어가시면 좋을 것 같습니다. 사실 이정도의 개념만 이해해도 본 논문의 내용을 이해하는데 크게 지장이 없습니다. 이보다 조금 더 자세한 내용들을 알고 싶으시면 예전에 제가 작성해둔 Self-supervised Learning 리뷰를 참고하시면 좋을 것 같습니다.
아무튼 이러한 CL과 더불어서, 최근에는 MIM 기반 방식들이 좋은 성능을 보여주면서 많은 관심을 받고 있습니다. MIM 기반 방식은 제 최근 작성된 X리뷰들을 보신 분들은 아시겠지만 입력 영상을 일정 비율로 마스킹하여 제거해버리고, 모델에게 해당 영역을 복원하는 task를 주어 학습하는 방식입니다.
이러한 학습 방식은 아주 오래전에 제안된 방식이지만, 해당 방식은 CNN 모델에게 활용했을 경우에 좋은 weight을 구할 수 있는 사전학습 기법은 아니었습니다. 하지만 최근에 ViT에서 매우 성공적으로 동작할 수 있다는 것이 밝혀진 뒤로 많은 연구자들이 MIM 기반의 SSL 연구를 지속해오고 있습니다. MIM에 대한 내용 역시 위에 CL 설명에서 말씀드린 것처럼 개념 위주로 이해하고 넘어가셔도 본 논문을 이해하는데 있어 충분하니 이정도만 설명드리고, 혹시 관련 내용에 대해 더 궁금하시면 홍주영 연구원님이 작성해놓은 MIM 논문 리뷰를 참고하시면 좋을 것 같습니다.
How Do Self-Attention BeHave?
그러면 이제 본 논문에 대한 얘기를 좀 다뤄보겠습니다. 먼저 해당 논문의 motivation인 부분부터 살펴보면 저자는 CL과 MIM이 학습하는 방식이 서로 큰 차이가 있기 때문에 동일한 모델(ViT)를 학습하더라도 해당 모델이 동작하는(혹은 집중하는) 과정이 서로 상이할 것이다 라고 판단한 것 같습니다. 실제로 논문에서는 재밌는 결과들을 가져오는데요 그 중 하나는 바로 아래 그림에서 확인할 수 있습니다.
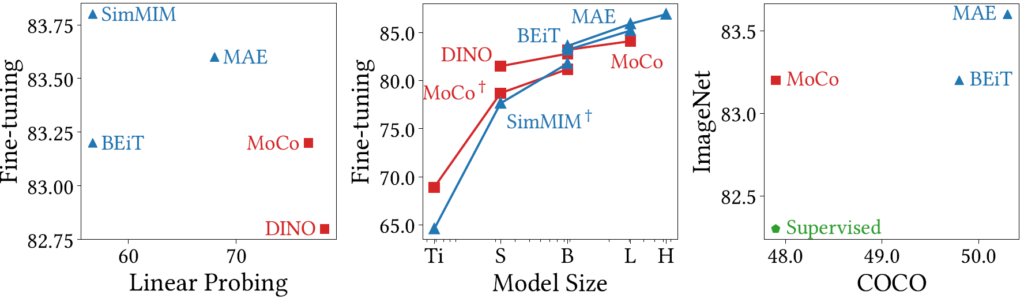
그림3은 CL 방식으로 학습한 ViT와 MIM 방식으로 학습한 ViT의 경향성 차이를 보이고자 한 것입니다. 그림에서도 볼 수 있듯이 크게 3가지 방식에 대하여 실험을 진행하였는데, 하나는 Fine-tuning 성능과 Linear Probing 성능에 대한 결과를, 중앙은 Model Size 대비 Fine-tuning 결과에 대한 결과를, 마지막으로 제일 우측은 Recognition task와 Dense Prediction task에 대한 결과 차이를 보인 것입니다.
대부분의 실험 환경은 다 이해하실 것으로 보이는데, Linear Probing에 대해서만 간략하게 소개드리면 backbone을 SSL 방식으로 사전학습한 후 맨 마지막 단에 Classifier 부분(FC layer)만 학습하고 사전학습된 backbone은 freeze하는 방식을 의미합니다. 그렇다면 Fine-tuning의 경우에는 classifier 부분 뿐만 아니라 해당 backbone까지도 모두 학습하는 것을 의미하겠죠?
아무튼 저 그림 3에서 붉은색 네모는 CL 기반 방식을, 파란색 세모는 MIM 기반 방식을 의미합니다(초록색 오각형은 ImageNet Dataset의 GT Label로 지도학습한 것을 말하는 것이겠죠?) 이러한 이해를 바탕으로 첫번째 실험에 대한 그림을 살펴보시면 CL 기반 방법들(MOCO, DINO)은 Linear Probing에서 MIM 기반 방법들(BEiT, SimMIM)과 비교하여 상당히 좋은 모습을 보여주고 있습니다.
반면에 Fine-tuning 관점에서는 MIM 기반 방법들이 CL 기반 방법들보다 더 좋은 성능을 보여주고 있습니다. 물론 Linear Probing 관점에서는 MI과 CL의 성능 차이가 심하면 accuracy가 20% 정도 넘게 차이나는 것 같은데 Fine-tuning 관점에서는 1%정도 밖에 차이가 나지 않는 것 같지만 그래도 MIM이 CL보다 더 좋다는 사실에 조금 더 집중해보죠.
그리고 그림 3에서 제일 우측에 COCO Dataset에 대한 DownStream task(i.e., Masked R-CNN을 통한 Dense Prediction)에서 역시 MIM이 CL보다 더 좋은 모습을 보여주고 있습니다. 이러한 경향성이 나타난 이유에 대해서 저자는 먼저 각각의 학습 방식으로 인한 ViT의 Self-Attention 행동에 대해 분석하였습니다.
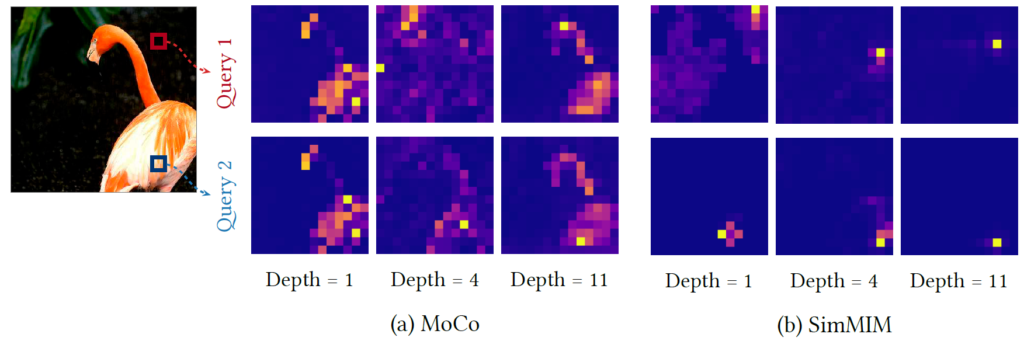
보다 구체적으로, 저자는 query token과 key token 사이에 평균 거리로 계산함으로써 self-attention의 범위를 측정하였습니다. 이러한 self-attention의 범위라는 개념은 CNN에서 Receptive Field의 size를 계산한다는 것과 유사하다고 보시면 될 것 같습니다.
그림 4은 CL 방식과 MIM 방식으로 각각 학습한 ViT의 앞단 layer(i.e., Depth=1)부터 뒷단 layer(i.e., Depth=11)까지의 Attention map을 시각화한 결과입니다. 제일 좌측에 홍학 그림을 기준으로 첫번째 행은 Query 1(붉은색 박스)에 대한 self-attention map을, 두번째 행은 Query 2(푸른색 박스)에 대한 attention map을 나타낸 것입니다.
그림 4에서 CL과 MIM에 사이에 가장 큰 차이점은 CL 방식으로 학습한 모델의 경우 마치 넓은 Receptive Field를 가지는 것처럼 object shape에 집중하는 것을 볼 수 있는 반면에 MIM은 local pattern을 위주로 활성화가 된 것을 볼 수 있습니다. 즉 CL이 더 큰 Attention Distance를 가지고 있다고 볼 수 있는데, 이는 아래 그림5의 정량적 결과를 보시면 더 확연하게 알 수 있습니다.
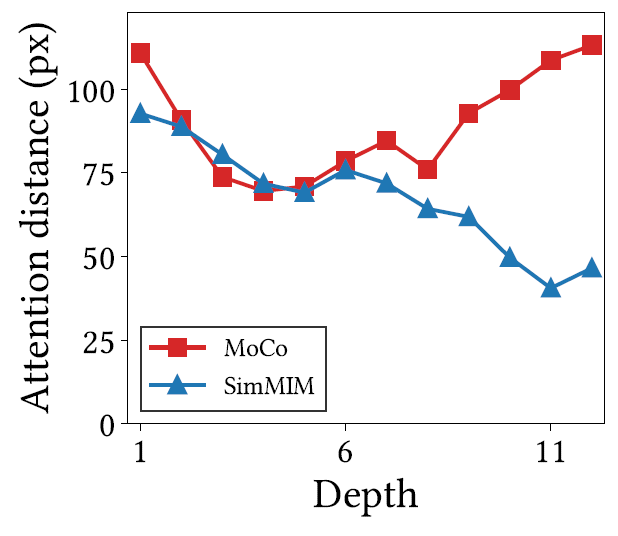
또 다른 차이점으로는 CL의 Self-Attention 방식은 MIM과 달리 균일하다는 점입니다. 이것이 무슨 말이냐면 서로 다른 위치에 해당하는 query token임에도 불구하고(즉 그림 4에 붉은색 박스와 푸른색 박스) 각각의 토큰에서 계산된 Attention map임에도 불구하고 서로 매우 유사한 모습을 보이고 있다는 점입니다.
저자는 이러한 현상을 “attention collapse into homogeneity”라고 명칭하였는데 이러한 collapsing은 CL 방식으로 학습한 ViT의 모든 head와 query토큰에서 발생했다고 합니다. 반면에 MIM의 경우에는 각각의 커리가 자신의 위치를 기준으로 주변부에만 활성화되는 매우 예상가능한? 방식으로 동작하고 있습니다.
Attention collapse reduces representation diversity
저자는 이러한 Self-attention map이 균일한 방향으로 collapsing하는 현상이 토큰들의 표현력을 모두 동일하게 만든다고 추측하였습니다. 이를 증명하기 위해서, 저자는 또 다른 실험을 보이는데 그림 6의 좌측부터 차례대로 self-attention의 head들 사이에 대한 것, self-attention layer 이전과 이후(즉 depth)에 대한 것, 그리고 서로 다른 token에 대한 cosine 유사도를 계산하였습니다.
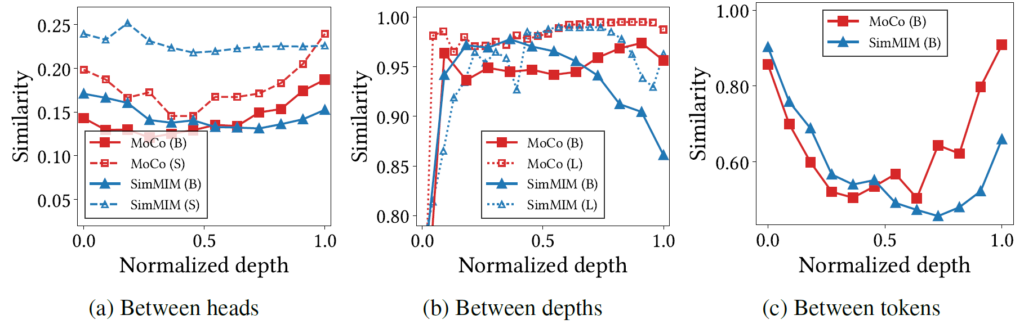
일단 그림 6에서 저자가 하고 싶은 말은 CL로 학습한 ViT의 경우 뒷단 layer로 갈수록 Similarity 값이 MIM과 비교하여 크게 나타나고 있다는 것을 보여주고 있습니다. 사실 그림 6에 대한 결과에 대해서 저자가 주장하고자 하는 바를 확실하게 담는다고 보기는 조금 어렵긴 하지만, 일단 세가지 경우 모두 Depth가 깊을수록 CL이 MIM보다 더 높은 유사도를 가졌다는 점을 염두하시면 좋을 것 같습니다.
지금까지의 내용을 요약해보면 CL 기반의 ViT는 영상의 global pattern과 object shape을 잘 포착하지만, attention 결과가 균일한 방향으로 빠져버리는 collapsing 현상이 발생한다고 볼 수 있습니다. 반면에 MIM의 경우 영상의 local pattern을 위주로 보고 있으며 이 덕분에 attention이 상대적으로 다양성을 지니고 있다고 보시면 될 것 같습니다.
이러한 내용과 관점을 토대로 다시 그림 3의 실험 결과를 설명해보면 다음과 같습니다.
- CL은 MIM보다 Linear Probing task의 성능이 더 좋게 나오며 그 이유는 CL로 학습한 ViT가 영상의 ojbect shape을 잘 포착했기 때문입니다. 보통 object shape은 객체를 인식하고 영상을 구분하는 것에 있어서 매우 중요한 요소이기 때문에 단순히 freeze된 backbone의 feature를 가지고 분류해야하는 분류기 관점에서는 표현의 다양성과 texture 등을 잘 보존하는 MIM의 feature 보다는 CL의 object shape에 대한 information을 활용하는 것이 더 좋은 결과를 나타낼 수 있었던 것입니다.
- 하지만 CL은 다양한 측면(head, depth, token)에서 서로 균일한 결과를 나타내는 현상을 보여줍니다. 이러한 균일한 표현력은 ViT Token의 표현력을 향상시키는데 있어 방해가 되는 요소들이며 결국 이러한 현상 자체가 Down stream task에서 fine-tuning 하였을 때의 성능 자체를 감소시키는 원인이 되었다고 저자는 판단하고 있습니다.
- 따라서 CL은 서로 다른 위치의 토큰들에서 계산된 attention이 서로 균일하기 때문에 Dense predicition task에는 적합하지 않다는 것으로 볼 수 있습니다.
How Are Representations Transformed?
그럼 지금부터는 위에서 보았던 CL과 MIM의 Self-attention 특성들이 어떻게 모델의 표현력에 영향을 끼치는가에 대해 더 자세히 알아보도록 하겠습니다.
CL transforms all tokens in unison, while MIM does so individually.
먼저 저자는 단일 영상으로부터 ViT를 통해 추출한 196개의 (14 x 14 patch) 토큰들에 대하여 self-attention module이 적용되기 이전과 이후에 representation distribution을 확인하였습니다.
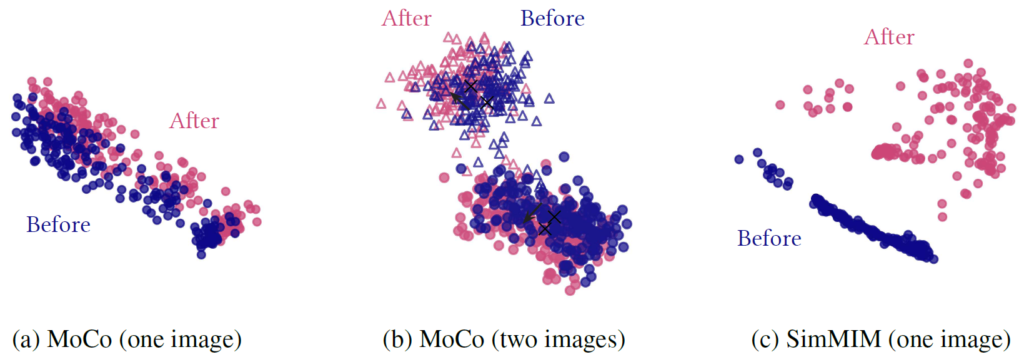
그림 7의 (a)부터 살펴보면, MoCo의 경우 Self-attention을 적용하기 이전과 이후의 차이는 분포들이 조금 translation 된 것 말고 딱히 유의미한 변화가 발생하지는 않은 모습입니다. 이는 위에서도 얘기했듯이 CL의 self-attention map이 매우 균일하기 때문에 발생하는 것이며 이는 곧 self-attention이 영상 내 위치에 따른 query token들에 대해서 상당히 독립적임을 의미합니다.(즉 공간적 차이에 따른 토큰들 간에 관계가 무의미함)
이렇게만 보면 CL의 Self-attention은 그럼 무의미한 연산처럼 보여 질수도 있는데, 저자는 그것은 아니라고 합니다. 그림 7-(b)에서 볼 수 있듯이, 서로 다른 두 영상의 representation 분포에서는 Attention 연산이 적용되었을 때 더더욱 분포의 중심(검정색 x)으로 더 잘 모이려고 하고 있으며, 이러한 현상이 서로 다른 영상에서 추출한 토큰들을 구별하는데 있어서 장점이 된다고 합니다.
반면에 MIM의 경우에는 확실히 attention 연산을 하기 전과 후의 분포의 변화가 상당히 극적인 것을 확인할 수 있습니다. 이는 곧 서로 다른 위치에 있는 token들이 각각 다른 attention을 부여하기 때문에 하나의 영상 내에서 representation 분포가 상당히 넓게 펼쳐지는 것을 확인할 수 있습니다.
CL exploits low-frequencies, and MIM exploits high-frequencies.
저자는 또한 지금까지 봐왔던 여러 결과들을 토대로 한가지 가정을 세웁니다. 바로 CL 방식의 모델은 low frequency 정보에, MIM은 high-frequency 정보를 더 잘 포착한다는 것을 말이죠. 이는 CL의 경우 object shape과 같은 global pattern을 위주로 보고 있으며 반면에 MIM은 texture 혹은 local pattern 등을 더 집중해서 보고 있다는 사실을 Attention Map의 시각화와 기타 다른 실험들을 토대로 확인했기에 내린 당연한 결론일지도 모르겠습니다.
저자는 이러한 가설을 더 확고히 하고자 각 방식에 대하여 Fourier analysis를 수행하였습니다. 특히 feature map에서 가장 높은 주파수와 낮은 주파수 사이에 amplitude 차이를 계산하여 Fourier transform에 대한 상대적 log scale의 amplitude를 계산하였다고 합니다.
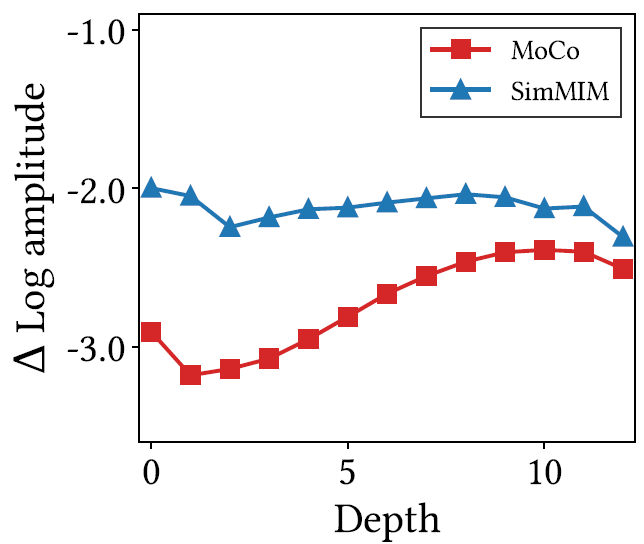
그림 8을 살펴보시면, MIM 학습 방식인 SimMIM의 경우 relative Log amplitude값이 CL 학습 방식인 MoCO보다 대부분 큰 것을 확인할 수 있습니다. 이는 곧 MIM의 경우 좁은 구조적 정보 및 디테일한 텍스쳐 등 고주파 성분에 대한 high frequency 정보를 담고 있음을 의미하며 반대로 CL의 경우에는 global structure, shape 등 low frequency에 해당하는 spatial information을 지니고 있다고 볼 수 있는 것입니다.
하지만 이 실험 및 분석은 제가 논문을 읽으면서 개인적으로 이해가 가지 않은 부분입니다. relative log amplitude라는 것이 가장 높은 주파수와 낮은 주파수 사이에 차이를 통해서 계산이 된다고 했는데 이 차이 값이 더 크다고 해서 고주파를, 더 작다고해서 저주파를 본다는 것은 직관적으로 이해하기 어렵네요. Fourier representation에 대한 amplitude의 특징? 계산 방식? 등에 대해 제가 잘 알지 못해서 그런것인지..
또 다른 흥미로운 점은 MIM의 경우 마지막 일부 레이어들은 특히 더 작은 receptive field를 가지고 있음에도 불구하고 (그림 5 참조) high frequency 성분들이 감소하는 것을 볼 수 있습니다. 저자는 이에 대해서 MIM의 경우 모델 학습 특성상 ViT 모델을 Enocder-Decoder 형식으로 나눌 수 밖에 없기에 뒷단의 일부 layer들이 decoder의 역할을 수행함으로써 그런 특성을 보인다고 주장합니다.
CL is shape-biased, but MIM is texture-biased
제 개인적으로는 조금 만족스럽지 못한 Fourier analysis 실험이었지만, 저자는 해당 결과를 토대로 일관성 있는 주장을 펼칩니다. 바로 CL은 shape에 편향되어 있으며, MIM은 texture에 편향되어 있다는 것을 말이죠. 저자는 이것을 검증하기 위하여 Stylized ImageNet 데이터 셋을 가져다가 모델이 어디에 더 편향되어서 분류를 수행하는지를 평가해봅니다.
Stylelized ImageNet에 대해 간략하기 설명드리면, 해당 데이터 셋은 AdaIn이라는 Style transfer 기법을 통해 ImageNet 데이터들의 style을 변경하여 새로 가공한 셋을 의미합니다. 따라서 해당 데이터 셋은 한 장 당 shape에 해당하는 class 정보와 style 변환에 사용한 style image의 class label을 함께 보유하고 있습니다. 따라서 모델은 해당 영상을 입력으로 하였을 때 shape에 해당하는 class를 예측할지, 아니면 style에 따른 class를 예측할지에 따라서 모델의 bias 정도를 파악할 수 있습니다. (Stylized ImageNet과 이에 대한 모델의 편향도 실험에 대해 더 자세한 내용은 제 예전 논문 리뷰를 보시길 추천드립니다.)
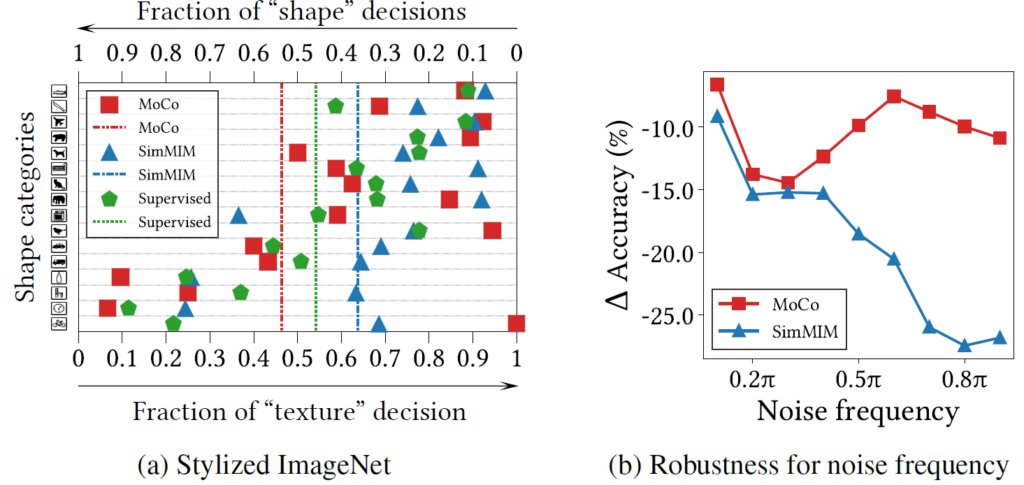
아무튼 저자는 이러한 stylized imaegnet에 대한 실험을 진행하기 위해서 각 학습 방식에 맞게 ViT를 ImageNet으로 사전학습을 시킨 뒤 fc layer만을 재학습시키는 linear probing 방식의 학습 및 평가를 진행하여 그림 9-(a)에 리포팅하였습니다.
그림 9-(a)에 대해 말씀드리면 모델 성능이 좌측에 치우칠수록 모델이 영상 속 대상의 shape을 보고 class를 추론하다는 것을 의미하며, 반대로 우측에 편향될 수록 texture 중심의 class 예측을 수행한다고 보시면 될 것 같습니다.
붉은색, 파란색, 녹색은 각각 CL, MIM, supervised learning을 한 것을 의미하고 점선은 모든 클래스에 대한 평균을 의미하는데 직관적으로 봤을 때 붉은색이 더 좌측에, 푸른색이 더 우측에 위치하는 것을 확인할 수 있습니다. 이는 CL의 경우 shape을 더 뚜렷이 보는 특성이 있으며 MIM의 경우에는 texture에 더 치우쳐있다는 것을 볼 수 있죠.
그림 9-(b)의 경우에는 ImageNet 데이터 셋에 noise를 주는 세기에 따라서 성능 감소가 얼만큼 있는지를 나타낸 결과입니다. Noise라는 개념은 주로 high frequency 정보로 구성되어 있기에 high frequency 정보를 기준으로 추론하는 MIM의 경우 noise 강도가 강해질수록 성능에 큰 drop이 발생하게 됩니다.
반면에 low frequency 정보를 위주로 분류를 수행하는 CL 학습 방식의 모델의 경우 높은 강도의 노이즈를 부여했음에도 불구하고 성능의 감소 폭이 MIM 보다 덜 떨어지는 것을 보여줍니다.
Which Component Plays An Important Role?
지금까지 CL은 image의 global pattern을, MIM은 local pattern을 더 집중적으로 본다는 것에 대해 다양한 측면에서 알아보았습니다. 이번 섹션에서는 ViT의 구조적 특성을 분석하여 왜 이러한 차이가 발생하는지를 알아보겠습니다.
Later layers of CL and early layers of MIM are important
이전에 ViT에 대해 분석하던 여러 연구들에 따르면, ViT의 뒷단에 레이어들은 high-level information을, 앞단에 layer들은 low-level informaton을 포착한다고 합니다. 저자는 지금까지 CL과 MIM이 각각 high-level, low-level information에 집중한다는 결과를 토대로, CL은 뒷단에 layer들에, MIM은 앞단의 layer들이 핵심적인 역할을 수행할 것이라고 주장합니다.
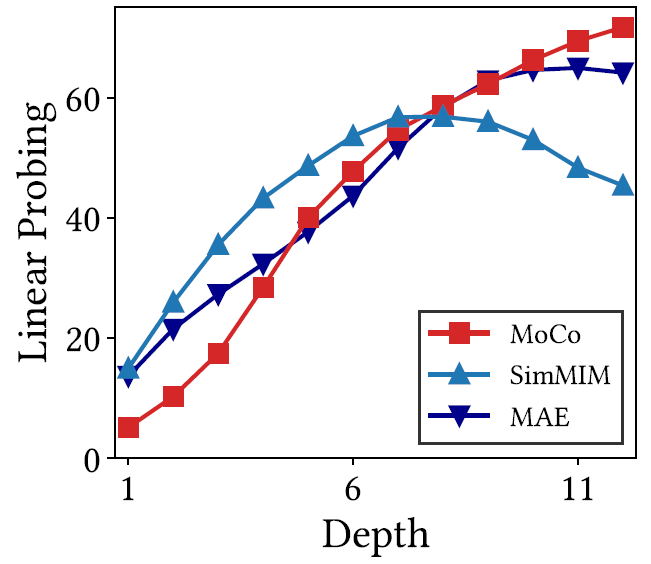
저자는 레이어의 깊이에 따른 feature map의 중요도를 판단하기 위해서 각 깊이 별 특징들들을 활용해 Linear Probing 성능을 보였습니다(그림 10 참조). 그림 10 결과에서 눈여결 볼 점은 다음과 같습니다.
MIM의 경우 상대적으로 앞단~중간 단계의 특징을 활용하는 것이 CL 보다 더 좋은 Linear Probing 성능을 보여준다는 점 + 후반부 레이어의 특징을 활용할 경우 성능이 감소한다는 점이 있으며, 반대로 CL은 레이어의 깊이가 깊으면 깊어질수록 Linear Probing이 점진적으로 증가합니다.(즉 깊이와 성능이 선형적임).
이러한 결과는 우선 MIM의 경우 앞단 feature map이, CL은 뒷단의 feature map이 더 중요하다는 것을 의미합니다. 그렇다면 MIM은 왜 뒷단에 특징들이 오히려 중간 단계 특징보다 좋지 못한 성능을 보이는 것일까요? 저자는 이러한 현상에 대해 MIM의 뒷단 레이어들은 Decoder로써 역할을 수행하기 때문이라고 주장합니다.
논문에서는 그저 디코더의 역할을 수행하기에 이러한 현상이 발생한다는 식으로의 설명만이 반복됩니다. 이에 대해 구체적으로 설명을 하지 않은 것이 의도한 것인지는 잘 모르겠으나, 제 나름대로 설명을 붙여보면 보통 인코더-디코더 구조에서 상대적으로 인코더가 feature representation의 핵심적인 역할을 수행하고, decoder는 대부분 손상된 정보를 복원하는 수준의 매우 기본적인 과정을 수행합니다.
따라서 decoder는 encoder에 비해 모델 구조 및 크기도 가볍고 단순하죠. 게다가 Linear Probing에서 수행하는 task가 영상 분류라는 관점에서 살펴볼 때, 영상의 가장 큰 특징들을 추출하기 위해서는 뚜렷한 feature representation이 필요로 할 것이며 이는 곧 decoder보다는 encoder가 더 잘 수행하는 역할이라고 생각할 수 있습니다. 따라서 encoder 역할을 수행하면서 나름대로 깊이가 깊은 feature map인 중간 단계의 특징들이 Linear Probing 성능이 가장 좋았던 것이 아닐까 싶네요.
The explicit decoder helps ViTs further leverage the advantages of MIM.
그림 10에서 SimMIM가 아닌 MAE 방법론의 경우에는 재밌게도 ViT의 깊이가 길어질수록 CL 방식과 유사하게 Linear Probing 성능이 향상되는 것을 확인할 수 있습니다. MAE는 SimMIM의 baseline 방법이자 MIM의 성공을 알리는 MIM의 근본 방법론임에도 불구하고 어째서 SimMIM과 다른 경향성을 나타낼 수 있던 것일까요?
이러한 차이가 발생한 이유는 MAE와 SimMIM의 디코더 설계 방식에 차이가 있습니다. 단순히 ViT model 뒤에 fc layer 몇 개를 붙여서 decoder를 대체한 SimMIM과 달리, MAE는 ViT Encoder와 ViT Decoder를 명확하게 나누어 학습을 진행합니다. 게다가 이러한 디코더에 입력으로 들어가는 마스크 토큰에 대해서만 복원을 수행하는 식으로 학습을 진행하죠.
이렇게 Encoder와 Decoder의 경계를 보다 더 명확하게 차이를 두게 되면, Encoder에 해당하는 부분이 본인의 역할을 더 잘 수행함으로써 ViT의 layer가 깊어질수록 Linear Probing 성능이 더 크게 오르는 것이죠.
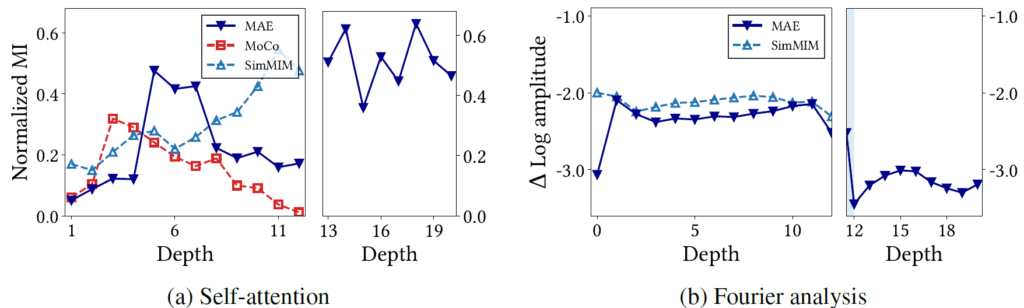
그림 11은 MAE의 개별적인 디코더의 특성을 더 잘 보여줍니다. 먼저 a의 경우 self-attention의 특성에 대해서 분석된 결과로 MAE의 Mutal Information(MI)이 encdoer에서는 SimMIM보다 상대적으로 작은 편에 속하며(중간 단계 레이어 제외), 반대로 Decoder 파트에서는 SimMIM과 유사하게 큰 것을 볼 수 있습니다.
b 의 Fourier analysis의 경우, Encoder에서 대부분 SimMIM과 유사하게 high frequency 정보를 활용하다가 Decoder에 가면 CL 방식의 모델과 유사하게 Log amplitude의 변화량이 큰 폭으로 줄어드는 것을 확인할 수 있습니다. 이러한 경향성은 decoder의 경우 low frequency 정보에 집중하고, MI도 커진다는 점이며 이는 ViT layer의 뒷단을 Decoder로 활용하는 SimMIM이 뒷단에 갈수록 MI가 커지고 amplitude 값은 줄어드는 현상과 유사하다고 볼 수 있습니다.
Are the Two Methos Complementary to Eacher Other?
자 그러면 지금까지 CL과 MIM의 특성 및 이러한 차이에 대한 원인을 다양하게 분석하였습니다. 그렇다면 최종적으로 두 학습 방식의 결과를 상호보완적으로 활용할 수 있는 방법은 없을까요?
앞에 분석에 너무 많은 힘을 쏟아서인지 논문에서는 두 학습 방식을 조합하기 위한 실험으로 매우 단순하게 두 목적 함수를 함께 활용하는 multi-task learning 방식 실험만을 수행합니다. 즉 아래 수식과 같이 람다 값을 통해 loss에 비율을 정하는 방식으로 말이죠.
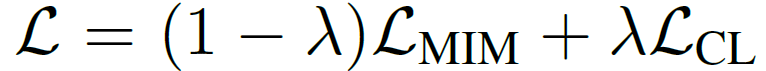
이러한 단순히 두 목적 함수를 섞어서 학습하는 방식은 상당히 흥미로운 결과를 보여주었습니다. 먼저 그림 12-(a)를 살펴보면 위 수식 람다값의 비율에 따른 ImageNet의 Fine-tuning과 Linear Probing 성능을 보여줍니다.
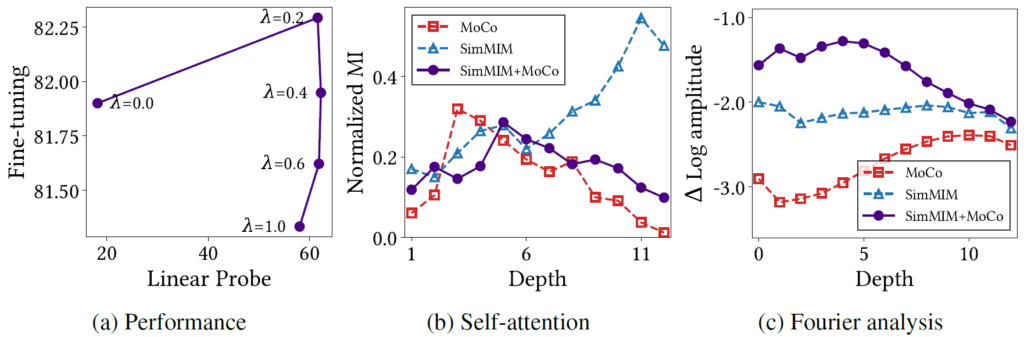
람다 값이 0인 경우에는 MIM 방식으로만 학습을 하는 것을 의미하며, 람다 값이 1인 경우에는 CL 방식만으로 학습하는 것을 의미하는데, 재밌는 점은 둘을 함께 섞어서 학습하게 될 경우(특히 람다가 0.2인 경우)에 각각을 따로 학습하는 방식과 비교하여 Fine-tuning과 Linear Probing 성능이 더 높은 것을 볼 수 있습니다.
특히 이러한 학습 방식은 (b)와 (c)의 모델 분석에서 볼 수 있듯이 앞~중간 부분에는 MIM의 경향성을 유지하다가 뒷단에는 CL의 경향성을 따라하는 등 두 학습 방식의 경향성을 잘 물려받은 것으로 확인되어집니다.
하지만 이러한 성능 향상에 대해 한가지 의문점은 저자가 보인 그림12-(a)의 성능과 리뷰 초반에 소개드린 SimMIM, MOCO v3의 성능(그림3 참조)이 서로 상이하다는 점입니다. 저자는 두 목적함수를 잘 조합해서 학습하는 것이 단일 학습 방식을 적용한 것보다 더 성능이 좋다고 얘기하며 82.25를 조금 넘는 수치를 보여주지만 실제 SimMIM은 83.75 이상, MOCO는 83 부근대의 정량적 수치를 달성하기에 저자가 보인 82.25보다 더 좋은 결과를 보여줍니다.
아무래도 본인들이 다시 SimMIM과 MOCO v3의 성능을 reimplementation 하였을 때 성능 원복이 안되고 감소가 된 것 같으며 이를 기준으로 좋고 나쁨을 평가한 것 같은데… 학습 세팅을 어떻게 했는지 디테일하게 보이지 않고 있고, 성능도 원복이 안됐다는 점에서 걸리는 부분이 좀 많네요.
결론
CL과 MIM의 학습 방식에 따른 특성 차이를 나름대로 잘 분석하였으며 저자의 주장을 뒷받침할만한 흐름이 나름대로 연결이 되는 것 같지만 중간중간 경향성을 벗어나거나 명쾌하게 설명하지 않은 부분들, 특히 마지막에 정량적 결과에 대한 의문등이 남이있어서 조금은 아쉬운 논문입니다.
안녕하세요.
좋은 리뷰 감사합니다.
실험 부분에 아쉬움은 있지만 정말 흥미로운 논문인 것 같습니다.
논문 후반부에서 CL과 MIM 방법을 혼합한 모델을 제안하는데, 그렇다면 이 모델은 Contrasitve Learning을 위한 임베딩과 Making 복원을 모두 수행하고, 해당 task들에 대한 손실 값을 모두 사용하는 것인가요?
그렇다면 입력 이미지 자체를 masking된 이미지로 받게 될 것이고 이를 이용하여 임베딩을 수행해야 하기 때문에 람다가 1일 때도 MOCO 대비 성능이 안 나오는 것일 수도 있겠다는 생각이 듭니다.
감사합니다!
리뷰 봐주셔서 감사합니다.
일단 CL과 MIM의 hybrid loss 방식으로 multi-task learning하는 방법의 구체적인 구성을 논문에서 표시하고 있지 않기에 입력 영상을 마스킹하여 CL 방식의 loss를 계산하는지에 대해 확신이 안서긴 합니다. 일단 제 개인적인 견해로는 보통 MIM의 마스킹 비율이 전체 영상의 75%나 되기 때문에 마스킹된 영상으로 CL 기반 학습을 수행하는 것은 상당히 어려울 것으로 보입니다. 그래서 실제 학습 방식은 CL과 MIM 학습 방식 각각에 맞게 영상 데이터를 가공하고 해당 영상들을 개별적으로 모델에 태워서 학습하지 않았는가 합니다.
위의 관점에서 바라볼 때, 람다가 1인 경우는 결국 MIM 기반 학습을 전혀 하지 않는 것이기 때문에 마스킹된 영역의 이미지를 굳이 넣을 이유가 없다고 생각합니다. 즉 람다가 1인 경우==CL로만 학습한 것으로 저자는 설명하는데 만약 그렇다면 CL의 학습 framework을 온전히 따라야하는 것이지, MIM의 학습 Framework(즉 영상의 마스킹 처리)를 함께 적용하여 학습하는 것은 CL(MOCO)만 적용하였을 때라고 볼 수 없게 되는 것이죠.
정리하자면, 논문에는 구체적인 실험 구성을 설명하지 않기에 학습을 어떻게 하였는지는 저자만이 알겠지만.. 만약 지오님이 말씀하신 대로 학습이 되었다면 마스킹 비율이 너무 높기 때문에 마스킹된 영상을 활용한 람다1의 학습 성능 감소 폭이 MOCO와 비교하여 매우 큰 폭으로 떨어졌을 가능성이 높다는 것이 제 생각이며, 이러한 실험 구성은 너무 저자의 주장에 유리한 설계 방향이 아닐까 합니다(즉, CL 혹은 MIM이 학습에 단독적으로 쓰이는 경우(람다가 1 또는 0인 상황)의 성능이 하이브리드 방식 보다 더 낮게 나오는 것.).
지금 생각해보면 epoch 수 혹은 배치 사이즈이 저자의 연산 환경에 맞게 조정이 되어 이로 인한 성능 차이가 생긴 것이 아닐까 싶기도 하네요.
안녕하세요 ! 좋은 리뷰 감사합니다.
SimMIM 방법론의 레이어 깊이에 따른 linear probing 성능을 보면, 앞단~중간 단계 layer들이 성능이 높은데, MAE 방법론의 경우에는 depth가 깊어질수록 linear probing 성능이 높은 결과가 상당히 흥미로웠습니다.
SimMIM, MAE 이외의 다른 MIM 기반 방법론을 가지고 같은 실험을 한 경우는 없었나요? MIM 방법론 중 MAE의 경우에만 Encoder와 Decoder를 명확하게 나누어 학습을 진행하는 건지….
만약 다른 MIM 기반 방법론으로 실험했을 때 MAE와 같은 결과를 보인다면, 앞단 실험에서 MIM와 CL을 비교할 때 계속 SimMIM과 MoCo를 가지고 비교해왔는데 앞단의 실험들이 유의미한 결과를 갖는다고 할 수 있는지 의문이 듭니다 . . .
감사합니다 ! !
댓글 감사합니다.
일단 논문에서는 SimMIM을 MIM 기반 학습 방식의 대표격으로 많이 활용하고 있으며 MAE에 대한 성능은 리뷰에서도 나와있듯이 논문 후반부 실험에 한두번씩 나오게 됩니다. 그 이유에 대해서는 ImageNet에 대해서 Pre-training을 하고, fine-tuning 등과 같은 부과적인 학습도 진행해야하니 학습 속도 및 연산량 관점에서 상당히 부담을 느꼈을 것입니다(본 논문에서는 ViT를 pretraining할 때 A100 GPU 8장 정도 사용했다고 하네요).
이러한 관점에서 다른 MIM 기반 학습 방식을 실험하는 것은 시간적, 연산량적으로 보았을 때 쉽지 않으며 저자가 SimMIM을 주로 사용하게 된 이유 역시 SimMIM의 논문 컨셉 및 목표가 Simple한 MIM 학습 framework을 제안한 것이기에 상대적으로 더 적은 메모리와 빠른 학습 속도를 보이기에 활용한 것으로 보입니다.
그리고 말씀해주신대로 MAE와 SimMIM의 뒷단 경향성은 조금 다르긴 하지만 결국 저자가 주장하고 싶은 바는 MIM 방식으로 학습하게 되면 ViT 앞단 레이어들이 유의미한 특징을 가지게 된다는 주장을 하고 싶은 것이라 저자의 주장 및 결과에 대한 큰 흐름이 변경되지 않을 것으로 판단됩니다.
안녕하세요 신정민 연구원님 좋은리뷰 감사합니다.
이 저자의 지난 논문에서도 느꼈다만 설득력과 논리가 대단하네요 읽으면서 이 집 연구 잘하네 싶었습니다
그나저나 저도 그림 8 에서의 고주파 저주파 가설에 대한 푸리에 변환 관련 수식이 궁금했는데, 여력이 된다면 어떻게 구한 것인지 알려주시면 좋겠네요 허허
그런데 제가 혹시 놓친건지 simMIM은 어떻게 설계된 방식인가여? 기본 MAE 라고 생각했는데, 그것과는 다르개 설계되었다는 언급이 있어 질문드립니다.
퓨리에 변환 관련 내용은 해당 논문 저자의 예전 논문인 ‘How Do Vision Transformer Work?” 논문에서 처음 제안한 방법이라 해당 논문을 참고해주시면 좋을 것 같습니다.
그리고 SimMIM 역시 제가 예전에 x리뷰로 작성하였기에 해당 리뷰를 참고해주시면 좋지 않을까 합니다. (http://server.rcv.sejong.ac.kr:8080/2023/03/12/cvpr2022-simmim-a-simple-framework-for-masked-image-modeling/) << 그냥 간단하게 요악하면 MAE 학습 방식을 더 간단하게 만들 수는 없을까 라는 관점에서 architecture 구조, loss 함수, reconstruction target 등등 여러가지 방면에서 실험하여 심플하게 MIM 기반 학습이 가능하도록 한 논문입니다.