Before Review
오늘의 리뷰는 Self-Supervised Video Representation Learning 연구로 준비했습니다. 읽으면서 저랑 조원 연구원이 21~22년도 겨울에 작성했던 TNIP랑 컨셉이 굉장히 비슷하다고 느꼈습니다. 물론 본 논문은 22년에 개제된 논문이기 때문에 21년도부터 연구를 진행하고 있었네요.
비슷한 시기에 비슷한 생각을 하는 게 이 바닥의 특징인가 봅니다. 아이디어를 빠르게 구현하지 못한다면 논문 한편 제대로 내기 힘들겠네요.
리뷰 시작하겠습니다.
Introduction
Self-Supervised Learning의 등장은 다양한 분야에서 굉장히 인상적인 결과들을 만들어내고 있습니다. 개인적으로 요즘 오로지 Supervised Learning으로만 하는 연구는 잘 보지 못한 것 같습니다. Self-Supervised Learning은 다양한 방법으로 활용되고 있습니다. 그 중 널리 활용되는 것은 아래와 같이 정리할 수 있을 것 같습니다.
Pretext-Task
Pretext-Task는 라벨이 필요하지 않은 Task를 고안하고 이를 학습에 이용 하는 것 입니다. 뭐 데이터 도메인 마다 다양한 방법이 있지만 비디오에서 하는 몇가지 Pretext-Task를 아래 그림을 통해 소개하도록 하겠습니다.
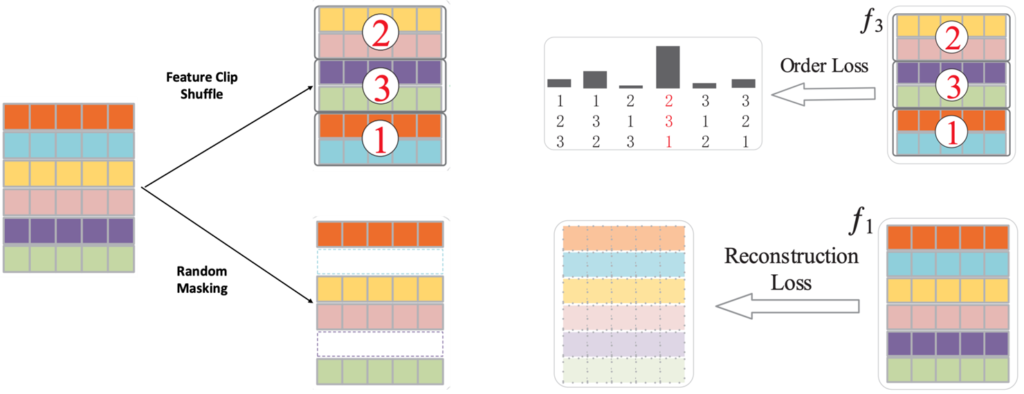
- Feature Clip Shuffle : Clip의 순서를 랜덤하게 섞은 다음에 다시 그 순서를 예측하는 것 입니다. 여기서 원래 데이터 섞는 행위 자체는 라벨을 필요로 하지 않습니다. 하지만 이러한 순서에 대한 정보를 가지고 모델을 학습 시키면 적어도 라벨은 없지만 순서를 예측 하는 과정을 통해 Clip 끼리의 temporal context 정도는 파악할 수 있는 능력이 생기는 것이죠.
- Random Masking : Masking을 통한 비지도 학습은 BERT에서 사용하기 시작하면서 다양한 연구에 도입되기 시작했습니다. 비디오 에서는 랜덤하게 Clip을 Masking 한 다음에 다시 Reconstruction 하는 task를 도입할 수 있겠네요. 역시나 Masking 하는 것 자체는 라벨을 필요로 하지 않지만 모델을 이 Masking 된 영역을 다시 Reconstruction 하는 과정을 통해 Clip 끼리의 spatio-temporal 패턴을 파악할 수 있게 됩니다.
Contrastive Learning
본 논문은 그 중 Contrastive Learning에 집중하고 있습니다. 비디오 분야에서 가장 기본적인 Contrastive Learning Framework는 동일한 비디오에서 나온 Clip 끼리 feature representation은 가까워지도록 만들고 서로 다른 비디오에서 나온 Clip 끼리 feature representation을 멀어지도록 학습하는 것 입니다.
Positive sample 끼리 feature representation이 비슷해지고, Negative sample 끼리 feature representation이 멀어지는 Loss 함수만 설계할 수 있다면 모델을 결국 라벨이 없는 상황에서도 데이터를 나름 이해할 수 있는 학습을 할 수 있게 되는 것 입니다. 이것이 바로 Contrative Learning 이라고 볼 수 있습니다.
일반적으로 사용하는 Contrastive Loss 함수의 formulation은 아래와 같습니다.
- L=-\frac{1}{N} \sum^{N}_{i=1} log\left( \frac{exp(f(x)\cdot f(x^{+}))}{exp(f(x)\cdot f(x^{+})+\sum^{N-1}_{j=1} exp(f(x)\cdot f(x^{-}))} \right)
Loss가 작아지는 방향은 결국 log 안의 값이 1에 수렴하도록 학습이 되어야 합니다. 1에 수렴하는 방향은 두 가지의 방향성을 띠고 있습니다.
- exp(f(x)\cdot f(x^{+}) 가 무작정 커지는 방향 : 이 방향이라면 분모 분자에서 exp(f(x)\cdot f(x^{+})의 영향력이 가장 크기 때문에 분수 값 자체는 1에 수렴합니다. 이는 Positive Pair끼리 feature similarity가 커지는 방향이죠.
- \sum^{N-1}_{j=1} exp(f(x)\cdot f(x^{-}))가 무작정 작아지는 방향 : 이 방향이라면 분모 분자에서 \sum^{N-1}_{j=1} exp(f(x)\cdot f(x^{-}))이 0에 수렴하기 때문에 분수 전체 값은 1에 수렴합니다. 이는 Negative Pair 끼리 feature similarity가 작아지는 방향이죠.
무튼 Contrastive Learning 얘기를 계속 이어서 하자면 요즘 나오는 Self-Supervised Video Representation Learning 연구들은 Clip 들의 Feature Representation을 가지고 어떻게 만드느냐 에 집중을 하고 있습니다. 가장 간단한 아이디어는 동일한 비디오에서 sampling한 clip끼리는 positive pair로 두고 다른 비디오에서 sampling한 clip끼리는 negative pair로 두는 것 입니다.
기본적으로 비디오는 temporal redundancy(인접한 프레임끼리는 비슷한 정보를 가짐)가 있기 때문에 방금 설명한 방식으로 학습 하면 나름 visual semantics를 학습할 수 있게 됩니다. 하지만 이렇게 학습 하면 서로 다른 비디오 끼리의 visual semantics을 학습할 수는 있지만 동일 비디오 내에서 temporal information에 대해서는 대처하기 어렵죠.
그 이유는 동일한 비디오에서 나온 clip들은 temporal redundancy에 의해 비슷할 수 있지만 또 항상 비슷한 것은 아니기 때문에 좀 더 섬세한 방법론이 필요합니다. 저자는 이러한 문제를 해결하기 위해 굉장히 간단한 방법을 제안합니다.
제목에서도 알 수 있지만 바로 shuffle 해주는 것 입니다.
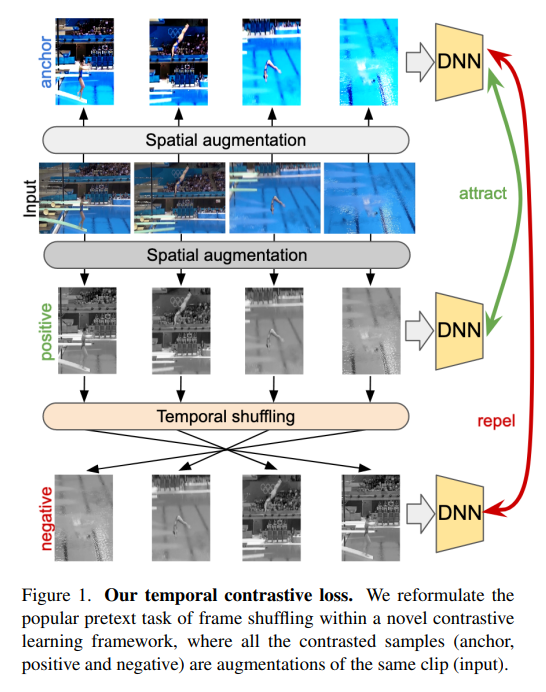
위의 그림을 보면 원래 Input 비디오가 있을 때 Input 비디오에 대해서 Spatial augmentation을 두 번 진행 합니다. 그리고 그 중 비디오 하나를 골라서 Temporal shuffling을 진행합니다. 비디오를 구성하는 내부 Clip들의 순서를 바꾸는 것 이죠.
Spatial augmentation을 한 비디오 끼리는 영상의 순서가 바뀌지 않았기 때문에 motion information은 그대로 유지 된다고 볼 수 있습니다. 하지만 Temporal shuffling 된 비디오는 순서가 변경 되었기 때문에 motion information이 변형되게 됩니다. 저자는 이렇게 shuffling을 가지고 동일 비디오 내에서 motion information이 다른 negative pair를 만들게 됩니다.
여담이지만 저희 논문인 TNIP는 이렇게 shuffling 된 상황에서도 강인하게 작동할 수 있는 pooling 기법을 제안한 것인데 여기서는 shuffling을 진행하고 이를 contrastive learning에서 negative pair로 사용했네요.
사실 본 논문의 Method가 별거 없어서 방금 설명한 게 전부이기는 하지만 그래도 나름의(?) detail이 있으니 같이 한번 확인해보도록 하겠습니다.
Method
method 부분에 Preliminaries on Contrastive Learning 이렇게 쓰고 대충 InfoNCE Loss 설명하는 걸 반 컬럼 정도 먹고 있는데 얼마나 쓸 내용이 없었으면 이랬을 까라는 생각도 드네요….
암튼 방법론에 대해서는 전체적인 구조도를 보면서 설명하도록 하겠습니다.
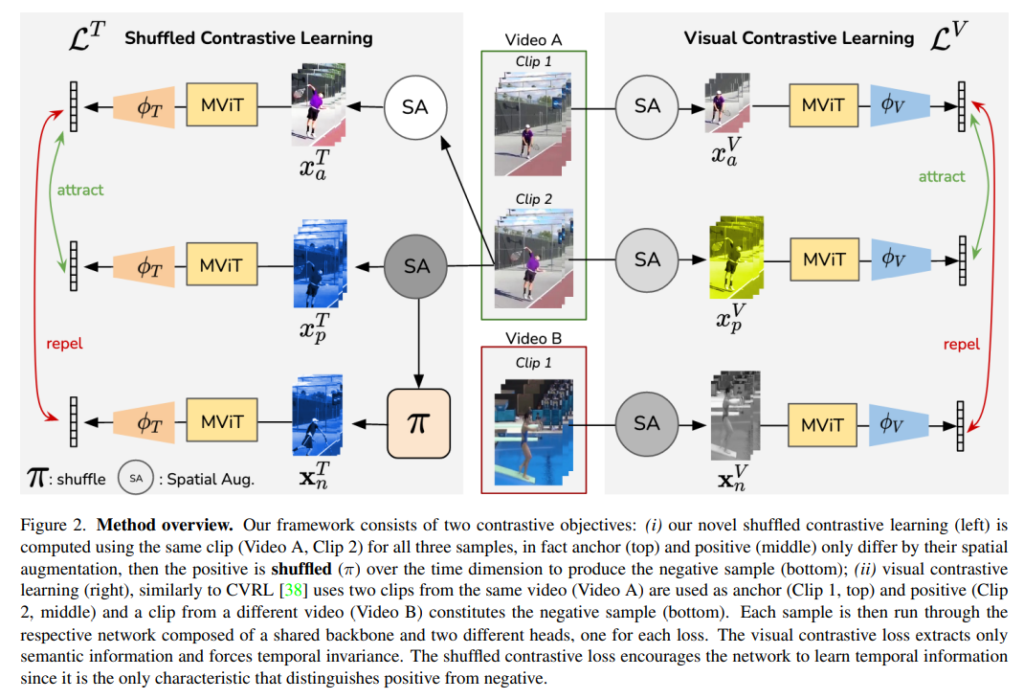
우선 그림의 왼쪽 부분인 Visual Contrastive Learning L^{V} 부분에 대해서 먼저 간단하게 설명하도록 하겠습니다.
흔하게 사용되는 Contrastive Learning의 기본 구조를 그대로 사용합니다. 동일한 비디오는 Positive, 다른 비디오는 Negative 이렇게 Contrastive Pair를 구성 합니다. 그림을 보면 VideoA에서 나온 Clip1, Clip2는 Positive Pair로 서로 feature representation이 유사해지는 방향으로 학습이 됩니다. 그리고 VideoB에서 나온 Clip1은 VideoA에서 나온 Clip들과 Negative Pair로 서로 feature representation이 멀어지는 방향으로 학습이 됩니다. 참고로 이 부분은 저자의 Contribution이 아닙니다.
이제 저자가 제안하는 Shuffled Contrastive Learning에 대해서 살펴보도록 하겠습니다.
VideoA에서만 Clip을 sampling 합니다. Clip2가 sampling 됐는데 여기에 spatial augmentation을 두 번 가해서 서로 positive 관계에 있는 clip 두개를 만들어냅니다. 그 중 clip 하나는 shuffling을 진행해서 motion information이 다른 clip을 하나 만들어내고 이를 negative pair로 사용 합니다.
하지만 위에서 제시한 방법의 한계는 shuffle을 해도 비슷한 clip들이 있다라는 것 입니다. motion의 변화 없이 동일한 장면이 꽤 오래 유지되는 구간이 비디오에는 굉장히 많습니다. Temporal Redundancy가 심한 경우에는 그런 구간이 더욱 많아지겠죠. 저자가 제안하는 Shuffled Contrastive Learning이 잘 동작하기 위해서는 적어도 motion 정보가 활발하게 발생하는 Clip들을 target으로 sampling 해야 한다는 것 입니다.
저자는 이를 위해 Probabilistic targeted sampling을 제안합니다. Clip 각각의 motion 정도를 측정하기 위해서 저자는 optical flow edges를 활용했다고 합니다. 여기서 Sobel Filter를 활용해서 Optical flow edge를 측정하고 magnitude를 계산하여 clip 마다 motion이 얼마나 있는지 확인할 수 있는 값을 만들었습니다.
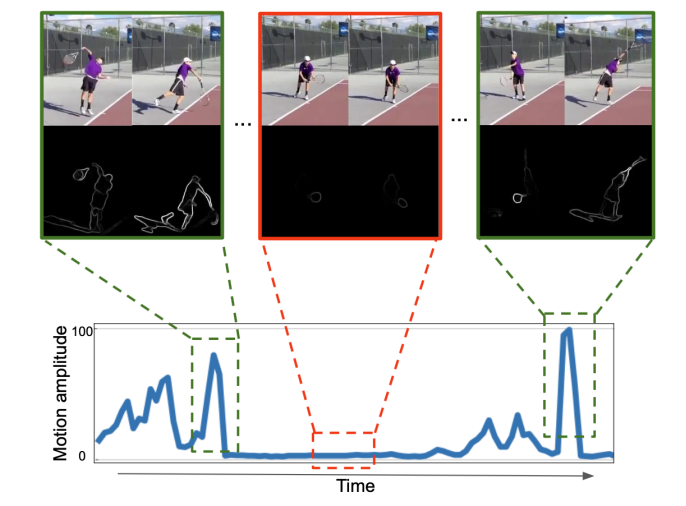
그림을 보면 sobel filter를 통해서 나온 edge들의 magnitude를 aggregate 하여 시간 축에 대해서 뭔가 score를 만들어내고 있습니다. 논문에서는 softmax 함수를 통해 0~1 사이의 확률 값으로 만들었다고 합니다. 그리고 이 확률 분포를 통해 clip을 sampling 하였다고 합니다.
즉, motion이 많이 있을 것 같은 clip들을 더 높은 확률로 sampling 하여 저자가 제안하는 Shuffled Contrastive Learning의 한계를 극복하겠다는 의미 입니다.
최종 Loss는 L^{F}=L^{T}+\lambda L^{V} 입니다.
Experiments
실험 입니다. Implementation, Dataset, Evaluation 설명을 한페이지 하고도 반 컬럼을 더 주면서 설명을 하는 논문은 처음 보네요.
Dependency on motion information
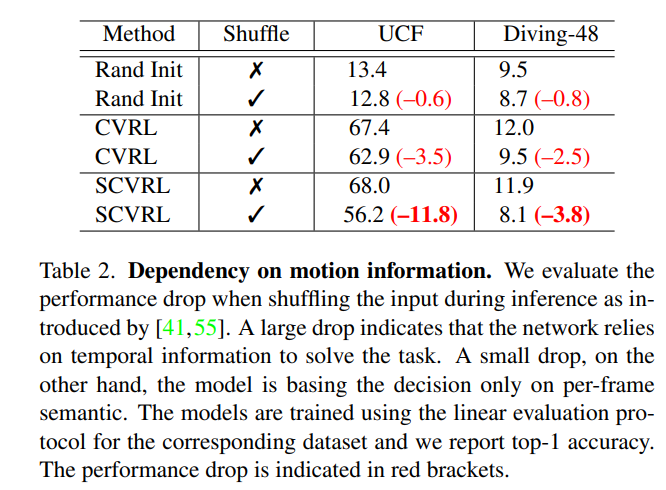
Inference를 할 때 clip을 shuffle 했을 때와 하지 않았을 때를 비교하고 있습니다.
여기서 주목해야 될 부분은 Shuffle을 했을 때도 성능 drop이 크지 않다는 것은 그 방법론이 motion을 이해하고 예측을 내놓는 것이 아니라 다른 visual 적인 정보에 더 집중을 했다는 소리 입니다. 반대로 성능 drop이 크다는 것은 motion에 집중하고 있었고 원래 학습 때 알고 있던 motion pattern이 깨졌고 거기에 민감하게 반응했기 때문에 그런 것이죠.
저자는 여기서 본인들이 제안하는 SCVRL 방식이 이렇게 inference를 할 때 shuffle을 주고 motion information을 깼을 때 성능 drop이 더 크다는 것을 보여주면서 본인들의 방식이 이렇게 motion sensitive한 방법론이다 라고 주장하고 있습니다.
Correlation between motion quantity and performance
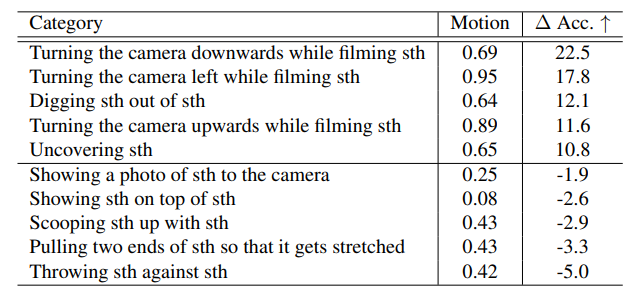
SSV2라는 데이터 셋을 가지고 클래스 마다 motion magnitude를 계산해서 실험을 진행하였네요. 여기서 저자가 확인하고 싶었던 것은 motion이 많이 발생하는 클래스에 대해서 성능이 얼마나 개선되는지 입니다. 확실히 motion이 많이 발생하는 class에 대해서는 Accuracy의 증가 비율이 상당히 높네요. 다만 motion이 적게 발생하는 부분에서는 기존 베이스라인에 비해 미비하지만 성능이 떨어지는 것을 확인할 수 있습니다.
개인적으로 논문이 맘에 들지는 않지만 본인들의 주장을 뒷받침 하기 위해 기존의 실험 세팅 보다는 위의 두개의 실험 처럼 motion magnitude를 활용하여 실험을 설계한 것은 조금 인상 깊습니다.
Video retrieval comparison

Video retrieval 실험 입니다. 기존의 CVRL 같은 경우는 뭔가 시각적으로는 유사하지만 action class가 전혀 다른 비디오들을 검색하고 있는 반면에 SCVRL 같은 경우는 시각적으로 유사하지 않아도 action class가 같은 비디오들을 반환하고 있습니다.
정성적으로 보면 꽤 인상 깊은데, 정량적인 성능이 없기 때문에 저는 그냥 체리피킹이라고 생각하고 있습니다.
Action Classification on Diving-48
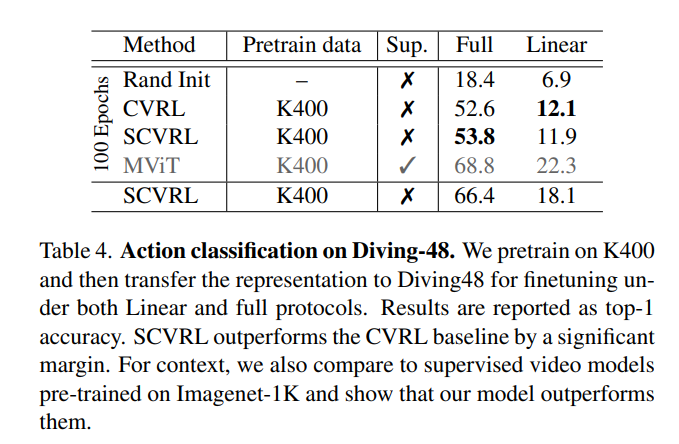
Diving-48이라는 데이터 셋에서의 Classification 벤치마킹 입니다. 테이블을 보시면 100 Epochs 기준으로 CVRL과 SCVRL의 차이를 주목해서 보시면 됩니다. 개인적으로는 차이도 미비하고 심지어 Linear evaluation을 할 때는 성능이 더 낮은데 어떻게 붙은 건가… 의문이 조금 듭니다. 100 Epochs 아래에 있는 성능은 500 Epochs 까지 학습한 성능인데 뭐 비교군이 없으니 의미가 있나 싶기도 하네요.
Low-shot learning on SSV2
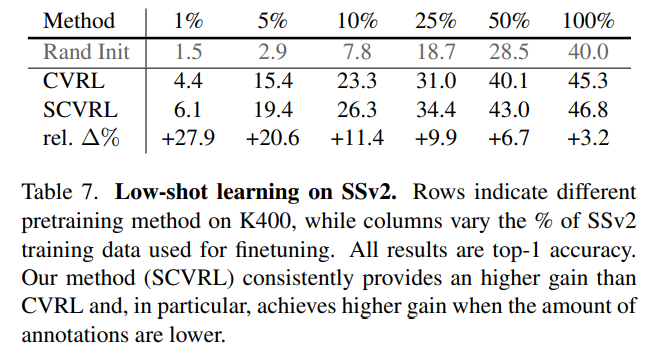
Method를 보면 1%, 5%, 10% 등등 일부 라벨을 활용한 Semi-Supervised로 학습했을 때 CVRL과 SCVRL을 비교하고 있습니다. 이미 SCVRL의 베이스 성능 자체가 CVRL에 비해 더 높을 텐데 이러한 실험이 의미가 있는 지는 모르겠습니다. SCVRL과 베이스 성능이 비슷한 방법론과 비교했을 때 진짜 Low-shot 상황에서 성능 차이를 얘기할 수 있는 건데 이러한 실험이 의미가 있는지 모르겠네요.
Conclusion
이번 논문은 조금 아쉬움이 남는 논문이네요. 내용이 너무 없어서 본문도 거의 1시간이면 다 읽었던 것 같습니다. 저자가 주장하는 shuffling 기법은 사실 21년도에도 이미 사용되고 있던 augmentation 방법이라 제 생각엔 방법론에 있어서도 novelty가 전혀 없는데 어떻게 CVPR에 억셉 됐는지 모르겠습니다. 성능이 엄청 높은 것도 아니고 실험이 풍부한 것도 아니고, 그렇다고 supple을 제공한 것도 아닌데…. 흠 리뷰어를 잘 만났나 봅니다.
다음 논문은 좀 더 알찬 내용의 논문을 준비하도록 하겠습니다.
안녕하세요 좋은 리뷰 감사합니다.
글을 읽고나니 실제 CVPR에 올라가기엔 novelty가 조금 떨어지는것 같기도 하네요..
벤치마크에서 나타나는 SCVRL의 성능은 (Shuffle CVRL + 기존 CVRL)인 것으로 보이는데, 저자가 제안하는 Probabilistic targeted sampling 기법이 기존 CVRL에 사용할 클립을 샘플링하는 데에도 사용된건가요?
그리고 논문의 베이스라인과 관련하여, (Shuffle CVRL + 기존 CVRL) 말고 Shuffle CVRL 만의 성능도 ablation에서 리포팅하고 있는지 궁금합니다.
지금 보니깐 workshop 페이퍼 였네요. 어쩐지 내용이 너무 부실했습니다.
1. 아뇨 SCVRL에만 사용됐습니다.
2. 리포팅 되어 있지 않습니다. 아마 Shuffle CVRL만 사용하면 기본적인 CVRL 성능 보다는 낮게 나올 거 같네요. 아무래도 visual semantics를 어느정도 학습을 하는 과정에서 shuffling이 학습을 보조하는 느낌이라 학습을 main으로 했을 때는 성능이 잘 안나올 것 같습니다.