제가 이번에 리뷰할 논문은 6D pose estimation 논문으로 이 분야는 처음 리뷰를 하게 되었습니다. PVNet은 인용수가 현재 728회로, 읽어봐야 할 논문이라 생각하여 리뷰를 하게 되었습니다.
Introduction
우선 6D Pose Estimation이란, 객체의 위치 뿐만 아니라 방향 정보까지 고려하여 객체의 탐지하는 방법론입니다. 본 논문은 단일 RGB에서의 translation과 rotation 정보를 예측하는 방법론으로, 이미지 내의 객체가 occlusion되거나 truncation(이미지에서 객체가 잘린 경우)된 경우에도 잘 작동할 수 있도록 새로운 프레임워크를 제안한 논문입니다.
관련 연구에 대해 정리해보자면 전통적인 방법론은 이미지와 객체 모델간의 대응 관계를 찾는 방식으로, hand-crafted feature를 이용하여 이미지가 변하거나 주변이 어지러운 경우 강인하게 작동하지 않았다고 합니다. 딥러닝 기반 방법론은 이미지를 입력으로 넣고, 대응 pose 정보를 출력으로 하는 end-to-end 방법론이 있으나, 이는 end-to-end 학습을 통해 충분한 representation을 학습하는 지가 불분명하였고 따라서 일반화에 대한 문제가 있다고 합니다. 또한, 당시의 SOTA를 달성했던 일부 방법론들은 CNN을 이용하여 keypoint를 감지하고, 이후 Perspective-n-Point(PnP, n개의 2D-3D 대응쌍을 이용하여 transformation을 추정하는 방식) 알고리즘을 통해 6D pose 정보를 예측하였다고 합니다. 이러한 2-stage 방식이 keypoint 감지에 강인하게 작동하여 SOTA를 달성할 수 있었다고 합니다. 그러나, keypoint를 찾을 수 없는 occlusion이나 truncation 상황에는 잘 작동하지 않았고, 학습된 패턴을 기반으로 보이지 않는 keypoint를 예측하는 방식은 일반화에도 어려움이 있다고 합니다.
저자들은 이러한 occlusion과 truncation에서의 문제를 해결하기 위해 dense prediction 방식을 이용해야한다고 주장하며, 6D pose를 예측하는 새로운 프레임워크인 PVNet(Pixel-wise Votion Network)를 제안하였습니다.
PVNet은 keypoint의 좌표를 바로 찾기보다, 픽셀마다 keypoint로 향하는 방향을 나타내는 백터를 예측하는 방식으로, 이후에 RANSAC 알고리즘을 통해 keypoint 위치를 투표하는 방식입니다. 저자들은 강체의 경우 일부를 보고도 보이지 않는 영역의 방향을 알 수 있다는 점에서 영감을 받아 이러한 방식을 제안하였다고 합니다.
이러한 방식은 keypoint 위치를 찾기 위해 vector-field representation을 생성하게 되고, representation은 주변의 local한 정보와 주변 object와의 관계를 고려하도록 하여 보이지 않는 영역에 대해 추론이 가능하며 입력 이미지의 밖에 있는 keypoint도 표현할 수 있어 occlusion이나 truncation 상황에 잘 작동한다는 장점이 있습니다. 또한, dense prediction 방식을 이용하다보니 정보가 풍부하여 PnP solver에 잘 작동한다고 합니다. 특히, RANSAC 기반의 Voting 방식은 outlier를 제거할 수 있으며, 확률적 분포를 제공하여 PnP에 불확실성 정보를 줄 수 있다고 합니다.(이와 관련해서는 Proposed approach의 Uncertainty-drive PnP를 참고하여 주시기 바랍니다. )
이렇듯 해당 논문의 contribution을 정리하면 다음과 같습니다.
- 새로운 Pose Estimation 프레임워크인 PVNet(Pixel-wise Voting Network)를 제안하여 occlusion과 truncation에도 강인하게 작동하는 2D keypoint 를 위한 vector-field representation을 학습하였다.
- 불확실성에 기반한 PnP 알고리즘을 통해 2D keypoint 위치를 찾는 데 불확실성을 도입하였다.
- LINEMOD, OOCLUSSION과 같은 6D Pose Estimation의 밴치마크에서 SOTA를 달성하였다.
Proposed approach
6D Pose Estimation은 Object 좌표계에서 카메라 좌표계로의 rigid transformation ( R ; \mathbf{t})로 표현되며, R 은 3D rotation, \mathbf{t}은 3D translation을 나타냅니다. 제안된 방법론은 2-stage 방법론으로, CNN을 이용하여 keypoint를 찾아낸 뒤, PnP 알고리즘을 통해 6D Pose 정보를 추정하는 방식입니다.
1. Voting-based keypoint localization
아래의 그림2는 keypoint localization 과정에 대한 오버뷰입니다.
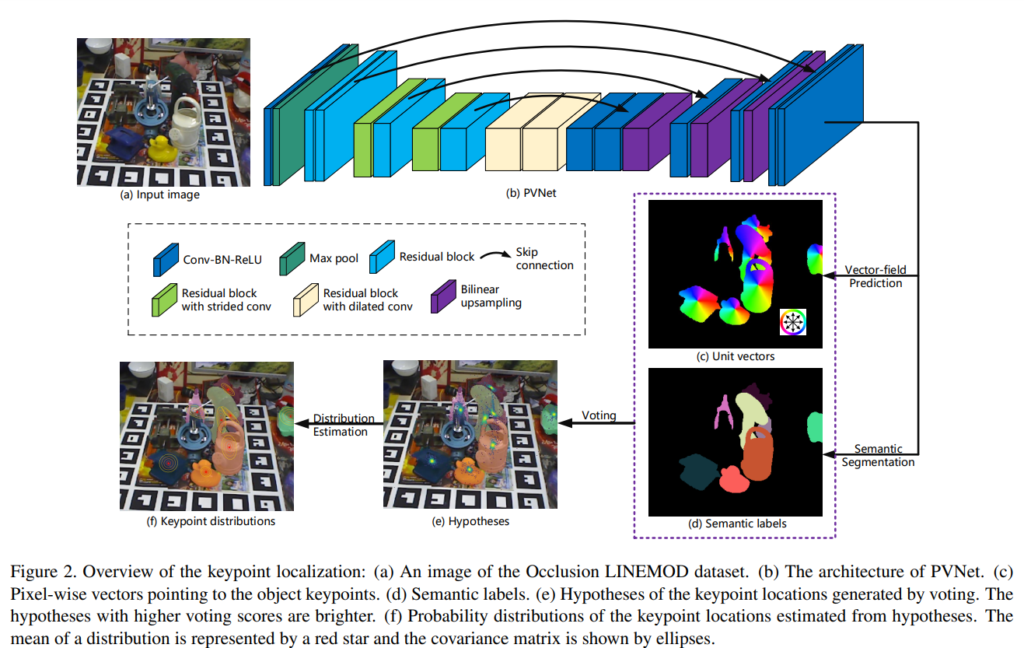
RGB 이미지가 입력으로 들어가고, PVNet을 통해 pixel-wise object label(d-semantic label)과 각 픽셀의 keypoint 방향으로의 representation vector(c-unit vectors)를 얻습니다. obejct에 속하는 모든 픽셀에서 특정 객체의 keypoint 방향이 주어질 경우 RANSAC 기반의 Voting을 통해 신뢰 점수뿐만 아니라 해당 keypoint에 대한 2D 위치 예측을 생성합니다.
즉, PVNet은 2가지 task를 수행합니다: (1) semantic-segmentation (2) vector-field prediction.
각 픽셀 \mathbf{p} 에는 픽셀별 semantic 라벨과, \mathbf{p} 에서 2D keypoint \mathbf{x}_k 로의 방향을 나타내는 vector \mathbf{v}_k(\mathbf{p}) 를 예측하며, \mathbf{v}_k(\mathbf{p}) 는 keypoint와 픽셀의 offset \mathbf{ㅌ}_k - \mathbf{p} 입니다. semantic 라벨과 offset을 이용하여 target 객체의 pixel을 얻고 offset을 추가하여 keypoint에 대한 hypotheses를 생성합니다. 그러나, offset은 객체의 크기 변화에 민감하게 작동하므로, 스케일 불변성을 위한 vector를 추가하여 아래와 같은 식으로 offset을 구합니다.
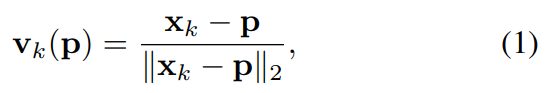
target 객체 픽셀과 단일 vector가 주어질 경우 RANSAC기반의 voting 방식을 통해 keypoint hypotheses를 생성할 수 있습니다.
- 먼저, 랜덤하게 두 픽셀을 고르고 두 백터의 교집합을 keypoint \mathbf{x}_k 에 대한 hypothesis \mathbf{h}_{k,i} 로 표현합니다. N번 반복하여 가능한 keypoint에 대한 representation \{ \mathbf{h}_{k,i} | i=1,2,...,N \}를 생성합니다.
- 이후 객체의 모든 픽셀은 hypotheses를 이용하여 투표하며, 이에 관한 식은 아래의 식(2)와 같이 정의가 됩니다.
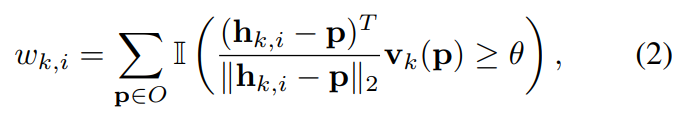
*** \mathbb{I}는 특성함수(특정 값이 집합에 속하면 1, 속하지 않으면 0의 값)를 의미하고, \theta는 threshold(논문에서는 0.99로 설정)로, 투표 점수가 높으면 hypothesis가 예측된 방향과 일치하기 때문에 높은 신뢰도를 갖는다는 것을 의미합니다.
이 결과 hypotheses는 이미지에서 keypoint의 공간적 확률 분포를 특성화 하며, 이는 그림2의 (e)를 통해 확인할 수 있습니다.(아래의 그림으로,점이 확률 분포로, 객체의 keypoint에 뭉쳐있습니다. )

3. 마지막으로 평균값과 분산값은 아랭릐 식으로 계산이 되며, uncertainty-driven PnP에서 사용됩니다.
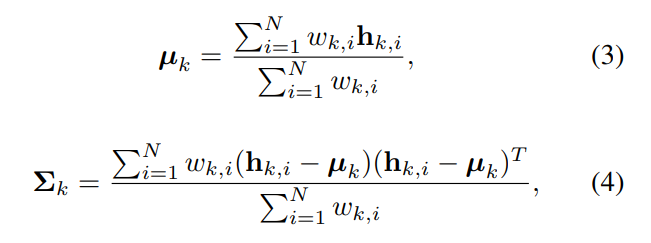
Keypoint selection

keypoint는 3D object model을 기반으로 정의해아하며, 당시의 최근 방법론들은 객체의 3D bounding box의 8개 모서리를 주로 이용했다고 합니다(그림3의 (a)). 그러나, 그림3과 같이, 모서리 점은 실제 객체와 떨어져 있을 수 있다는 문제가 있어서 keypoint와 객체의 픽셀 사이의 거리가 멀수록 localization 오류가 거친다는 문제가 있습니다. 위 그림3의 (b)와 (c)는 PVNet에 의해 생성되는 hypotheses가 어떤 keypoint를 사용하는지에 따른 결과를 시각화한 것으로 (b)는 bounding box를 keypoint로 하는 경우(기존 방법), (c)는 객체 표면에서 선택된 keypoint를 이용할 경우에 대한 결과를 나타냅니다. 결과를 보면 일반적으로 keypoint로 객체 표면을 이용할 때 localization의 분산이 훨씬 작다는 것을 알 수 있습니다.
따라서 객체 표면으로부터 keypoint를 정해야 하며, PnP 알고리즘을 보다 안정적으로 만들기 위해, keypoint가 객체에 퍼져있어야 한다고 합니다. 이러한 두가지를 고려하여, farthest point sampling(FPS, 점군간에 가장 멀리 떨어져 있는 점을 선택 하는 방식)를 이용하여 객체 위의 K지점을 선택합니다. 먼저 센터를 센터를 추가하여 초기화 한 후, 반복적으로 K개의 먼 점을 찾는 방식입니다. 저자들은 효율성과 정확도를 고려하여 K를 8로 설정하였다고 합니다.(실험적으로 선택한 값)
{kind=link}
2. Uncertainty-driven PnP
2D keypoint가 주어졌을 때 6D pose는 PnP solver를 이용하여 계산이 되며 EPnP를 가장 많이 사용하였다고 합니다. 그러나 이러한 방식은 서로 다른 keypoint가 서로 다른 신뢰도와 불확실성 패턴을 가질 수 있다는 것을 간과한다고 합니다. 이러한 것을 고려하기 위해 저자들은 앞서 Voting 과정에서 구한 평균과 분산을 이용하여 공간적 확률 분포를 고려하였다고 합니다.
마할라노비스 거리를 최소화하도록 6D pose가 추정되며, 아래의 식으로 나타낼 수 있습니다.
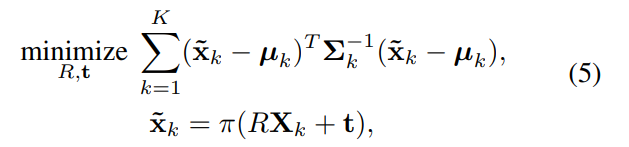
\mathbf{X}_k는 3D 좌표계의 keypoint를 나타내며, \tilde{ \mathbf{x}}_k는 \mathbf{X}_k의 2D projection, \pi는 perspective projection 함수를 나타냅니다.
이렇게 구한 식(5)에 대해 함수 최적화 기법인 Levenberg-Marquardt 알고리즘을 이용한다고 합니다.
Training strategy
smooth l1 loss를 이용하여 unit vector의 학습을 하였다고 합니다.
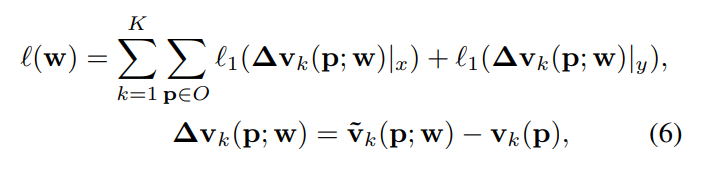
\tilde{ \mathbf{v}}_k는 예측된 벡터, \mathbf{v}_k는 GT unit 벡터를 나타냅니다.
(참고로 테스트를 진행할 때는 후속처리된 벡터의 방향만 사용하므로, 예측 벡터가 unit 벡터일 필요가 없다고 합니다.)
Experiments
Dataset
- LINEMOD
- 6D pose estimation에서 많이 사용되는 밴치마크
- 여러 챌린지한 상황이 포함됨.(복잡한 장면, texture-less 객체, 조도 변화)
- Occlusion LINEMOD
- LINEMOD에서 만들어진 서브셋
- 여러 객체 포함되어있으며, 객체들이 많이 occluded 되어있음.
- Truncation LINEMOD
- 잘린 객체에 대한 평가를 위해 LINEMOD를 무작위로 잘라 만든 데이터셋
- 대상 개체 영역의 40~60%만 영상에 남아있도록 하였다고 합니다.
- YCB-Video
- YCB 객체에서 수집된 영상
- 다양한 조명 조건, noise와 occlusion으로 인해 챌린지한 데이터셋
Metric
- 2D projection metric
- 추정된 pose와 GT pose 사이의 평균 distance
- 5픽셀 이내일 경우 정답으로 간주
- ADD metric
- 추정된 pose와 GT pose를 이용하여 평균 거리를 계산
- 거리가 모델 직경의 10% 미만일 경우 정답으로 간주
- 대칭적인 객체에 대해 ADD-S를 이용하여 평가
Performance on the LINEMOD dataset
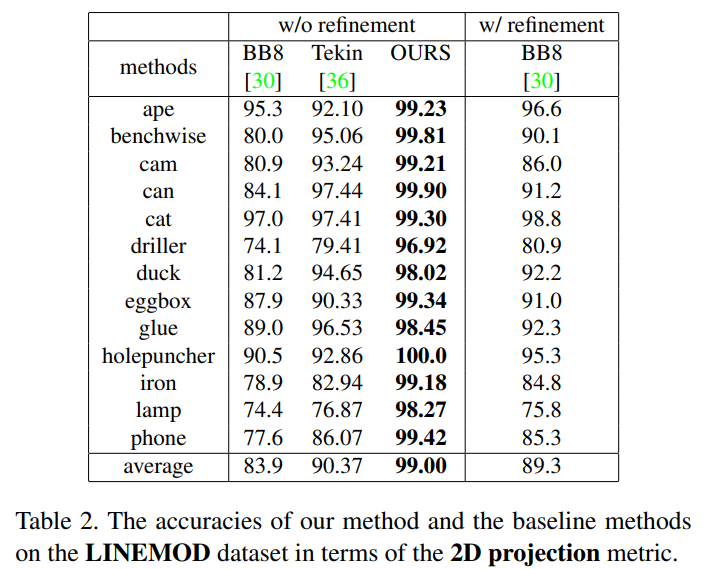
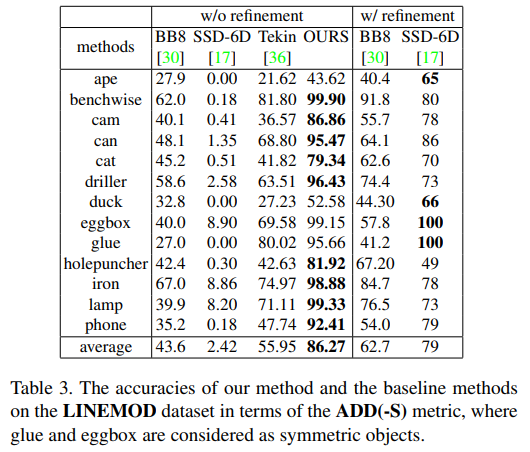
기존 방법론들은 regression을 이용하여 keypoint를 예측한 방법론입니다. regression을 바로 이용하는 방법론들과 비교했을 때, 성능 향상이 상당히 일어난 것을 확인할 수 있습니다.
Robustness to Occlusion
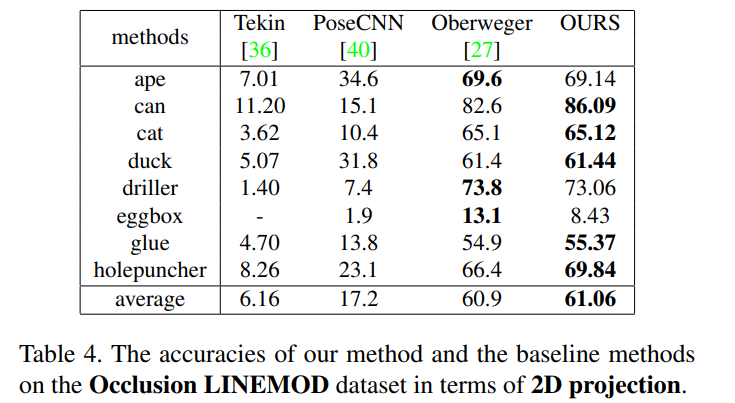
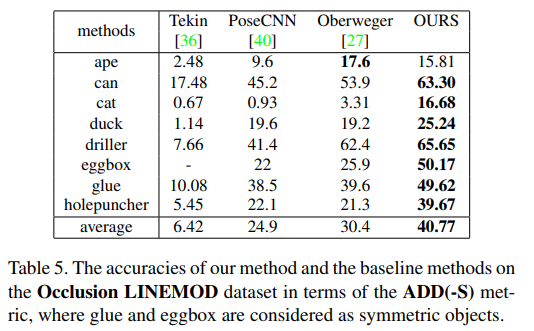

Occlusion에서의 실험 결과로, 대부분의 object에서 해당 논문의 방법론이 잘 작동하였다고 합니다.
Robustness to truncation
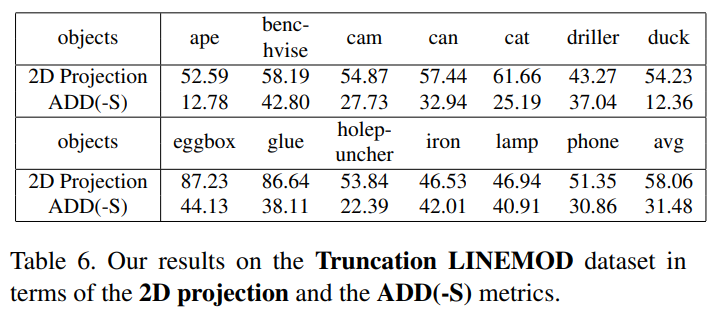

위의 실험 결과들을 통해, 객체의 일부분이 보이지 않는 경우에도 voting기반의 6d pose estimation을 이용할 경우 보다 더 정확한 포즈 예측이 가능함을 확인할 수 있었습니다.
6D pose estimation 방법론에 대한 논문은 처음 읽어보는데, 저자들이 보이지 않는 영역에 대해 고려하기 위해 각 픽셀에서 keypoint로의 방향을 예측하는 방식을 도입한 것이 인상 깊었습니다. (입력 이미지 영역 밖의 정보도 고려할 수 있도록 프레임워크를 디자인한 것이 놀라웠습니다.)
안녕하세요, 좋은 리뷰 감사합니다.
PVNet도 궁금했었는데 이승현 연구원님께서 리뷰를 해주셔서 잘 읽었습니다.
식(2) w_{k, i}를 구할 때 voting score 에 대한 threshold를 논문에서 0.99로 설정을 하셨다고 하셨는데 보통 threshold는 0.5 정도로 잡을 것 같은데 꽤 높은 수치를 잡은 것에 관련된 리포팅이 있는지 궁금합니다.
감사합니다.
댓글 감사합니다. 우선 threshold의 수치를 선정한 이유나 다른 값으로 실험을 하지는 않은 것 같습니다. threshold수치에 대해서는 다른 논문을 살펴보았을 때 inlier인지 결정하는 데 사용하기 때문에 높은 값으로 설정한 것으로 이해하였습니다.(참고한 논문 https://arxiv.org/pdf/2003.00188.pdf)
안녕하세요 ! 좋은 리뷰 감사합니다.
2D projection metric으로 평가한 성능인 table2를 보면 전반적인 object에 대해 pose를 잘 추정하고 있는 것 같은데, ADD metric으로 평가한 성능 결과인 table3을 보면 ape와 duck의 accuracy가 이전에 비해 많이 떨어진 것으로 보이는데 이유가 무엇인지 알 수 있을까요 ? ?
또한 ADD metric을 설명해주신 부분에서 대칭적인 객체에 대해서는 ADD-S를 이용해서 평가한다고 적어주셨는데 ADD-S가 무엇인지 궁금합니다.
감사합니다.
우성 말씀하신대로 ape와 duck에 대해서 refinement를 적용한 ssd-6d보다 성능이 조금 떨어지기는 하지만, 이는 refinement의 적용 유무에 따른 결과이므로 성능이 하락했다고 보기는 어려운 것 같습니다. (여기서 refinement는 예측 후에 post processing 과정으로, edge alignment를 수행한 결과라 합니다.)
또한, ADD-S는 대칭적인 구조의 경우(예를들어 그릇 같은) pose rotation에 대한 예측 결과가 모호하여, 이를 해결하기 위해 PoseCNN(https://arxiv.org/pdf/1711.00199.pdf, 식(6))에서 제안된 것입니다. 링크를 참고하시면, rotation에 대한 식이 조금 다른것을 확인하실 수 있고, distance가 작은 point를 이용하여 오차를 계산하게 됩니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
실험 파트에서 Robustness to Occlusion 실험 결과를 나타내는 Table 4를 보면 본 PVNet이 이전의 방법론들과 비교했을 때 Oberweger과 근소한 차이가 나거나 더 좋은 성능을 보이고 있는데 eggbox에 대해서는 다른 object에 비해 성능 차이가 많이 나는 것이 눈에 띄는 것 같습니다.혹시 이러한 성능이 나오는 이유에 대해 논문에서 언급된 것이 없을까요?
또한 keypoint를 정할 때 K를 실험적으로 8을 선택해서 사용한다고 말씀해주셨는데 제 생각에는 object의 모양을 따라 좀 더 많은 점을 keypoint로 사용하면 보다 높은 성능이 나올 수 있을 것 같은데 K 값을 바꿔가면서 성능을 확인한 실험은 없었는지 궁금합니다.
감사합니다.
eggbox 클래스의 성능이 떨어지는 것에 대해서는 따로 언급하지 않았고, average score를 통해 성능이 향상되었다고 언급되어있습니다.
또한, K를 8로 설정한 이유가 정확도와 속도의 균형을 맞추어 설정하였다고 합니다. keypoint의 갯수를4,8,12로 바꿔가며 실험을 진행하였는데, 제가 ablation study 내용을 가져오지 않았습니다.. 4/ 8 / 12에 대해 각각 17.96 / 39.76 / 39.92 의 성능이 리포팅 되었으며, 8과 12의 차이는 거의 없어 효율성을 고려해 8로 설정하였다고합니다.
좋은 리뷰 감사합니다.
혹시 어떤 클래스 내 물체들이 다양한 object size로 존재할텐데 keypoint를 찾아 이미지 전체영역에 대해 알고리즘을 통해 찾는 과정이기 때문에 object size의 다양성에 의한 pose 추정은 문제가 되지 않나요?
그리고 voting score threshold가 0.99인데 높은 수치인 것 같아서 threshold를 적용하였을 때에 대한 ablation study는 나타나있지 않나요?
감사합니다
말씀하신 크기 다양성 문제를 해결하기 위해 식 1에 스케일 불변성을 갖도록 offset을 설정해줍니다.(크기만큼 나눔)
또한, threshold 수치에 따른 ablation study는 존재하지 않습니다.
좋은 리뷰 감사합니다.
몇 가지 궁금증이 생겨 질문 드립니다.
1. 예측하는 키포인트는 PDF 방식을 이용한 8개의 point cloud가 맞을까요?
2. 그림 2와 그림 3에서는 센터를 기준으로 찾는 것으로 묘사되는 걸로 보이는데, 추론에서도 8개의 points를 예측하는 것이 맞는 건가요?
3. table 3.을 보면 제안하는 방법론의 성능이 월등하게 좋게 표현됩니다. 특히, SSD-6D과 제안하는 방법론의 차이는 99이상 차이날 정도로… 이상한데.. 이에 대한 설명이 없을까요?
댓글 감사합니다.
1~2. 네 맞습니다. 제가 이해하기로 FPS 방식을 적용하여 3D 표면 위의 8개 keypoints를 찾아냅니다. 이때 8개의 점을 구하는 과정이 먼저 point들로부차이가 크게 납니다.터 중심을 찾고 FPS를 적용하기 때문에 센터도 하나의 기준이 됩니다. 그림3의 경우 하나의 keypoint에 대해 시각화를 수행한 것으로 보입니다..
3. 이야기하신대로 table3에서 SSD-6D(without refinement)의 성능과 저자들의 방법론은 성능 차이가 크게 나지만, refinement(post-processing과정인 edge alignment)를 적용할 경우의 SSD-6D와 비교한 것으로 보입니다. 저자들에 따르면 refinement 없이도 좋은 결과를 보인다는 이야기를 합니다.
안녕하세요 승현님!
좋은 리뷰 감사합니다.
저도 지금 PVNet 논문을 읽고 있는데.. 상당히 많은 도움받고 갑니다.
회전과 평행이동 변환 행렬을 추정하는 과정에서 3차원 모델에서의 포인트 좌표와 2차원 이미지 상 물체의 포인트의 좌표를 안다는 전제하에 대응되는 점을 가지고 구해지는 것 같은데 2차원 이미지에서도 동일하게 8개의 키포인트가 (3차원 포인트와 동일한 위치에서) 검출되어야 하나요? 3차원 모델에 대해 8개의 포인트를 결정하는 것은 매번 똑같이 나오나요 아니면 매번 다른 위치에 찍힐 수도 있는건가요?
질문 감사합니다.
넵 2차원 이미지에서 8개의 대응되는 keypoint를 찾아야 합니다. 3차원 모델에 대한 8개 포인트는 코드상으로 사전에 FPS를 통해 8개로 정해두고, 이를 GT pose를 이용하여 2D 이미지로 투영시키는 과정을 통해 영상에서의 keypoint의 위치를 알 수 있게 됩니다. 동일 모델에 대해서는 동일 영상에서 일정한 keypoint를 예측할 수 있어야 합니다.